이번에 회사에서 직면했던 복제지연 문제에 관한 내용을 공유하고자 글을 남깁니다.
문제 발생
저희 회사에서는 database replication을 통해 부하를 분산하여 성능을 높히는 방식을 사용하고 있습니다.
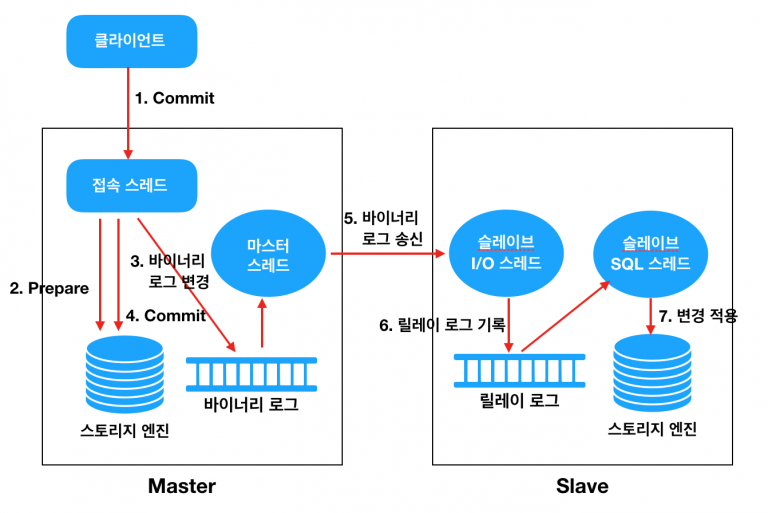
시스템은 Master-Slave 구조의 Active-Active 이중화로 구성되어 있으며, ProxySQL을 통해 SELECT 문은 Slave로, INSERT, UPDATE, DELETE 문은 Master로 전송됩니다. 이후 Master에서 변경된 데이터는 Slave로 동기화됩니다.
이 구조를 통해 부하를 분산하고 성능을 향상시키고 있었으나, 여기서 종종 발생하는 문제 중 하나가 바로 "복제 지연 문제"입니다.
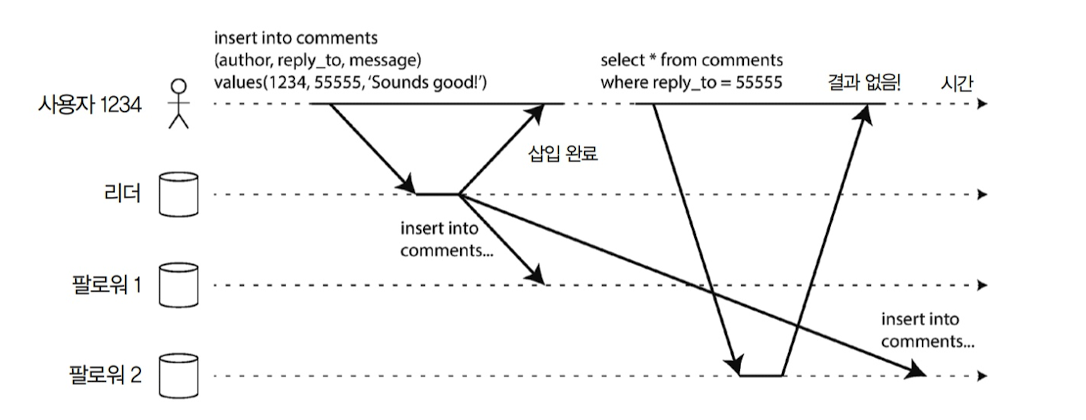
예를 들어, 사용자가 INSERT 작업을 수행한 직후에 SELECT를 호출할 때, Slave에 데이터 동기화가 완료되지 않았다면 사용자 입장에서는 데이터가 누락된 것처럼 보일 수 있습니다.
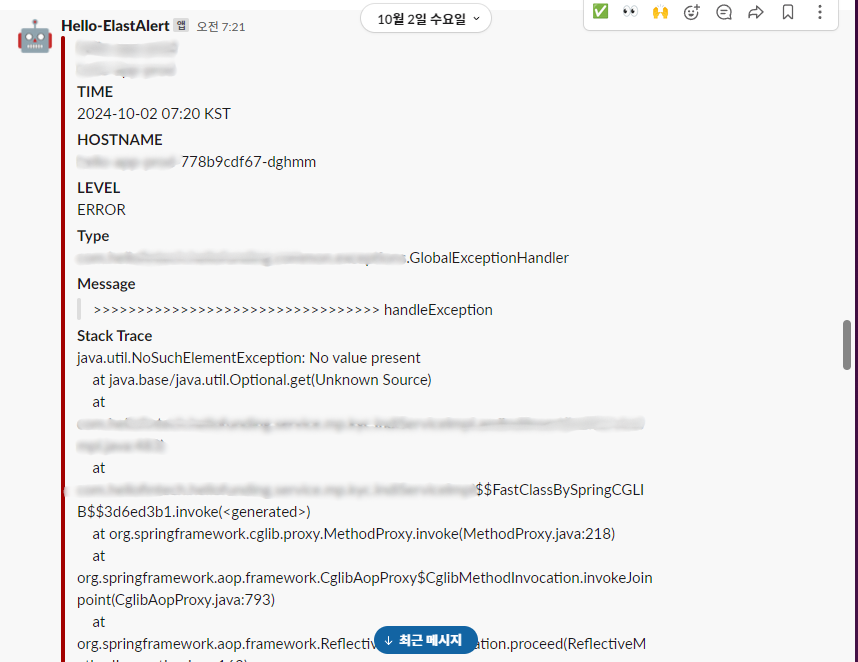
위 예시는 관련 문제로 발생한 예외 메시지가 Slack에 전송된 화면입니다.
해결 방법
회사는 복제 지연 문제를 해결하기 위해 여러 가지 방법을 고민했습니다. 일반적으로 고려할 수 있는 해결 방안은 다음과 같습니다.
- 자신이 쓴 데이터 읽기(Read-Your-Own-Write)
- 단조 읽기(Monotonic Reads)
- 일관된 순서로 읽기(Consistent Reads)
하지만, 저희 회사가 처음에 선택한 방법은 간단하고 직관적인 방식이었습니다.
주요 비즈니스 로직을 다루는 애플리케이션의 경우 ProxySQL을 사용하지 않고 Master만 바라보도록 한다.
이 방법을 채택한 이유는 크게 세 가지였습니다.
- 일시적인 문제로, 데이터가 동기화되면 더 이상 문제는 발생하지 않기 때문.
- 주요 비즈니스 로직에서는 INSERT 후 SELECT가 필요한 경우가 많아 문제 발생 가능성을 낮출 수 있었기 때문.
- 다른 개발 일정이 우선시되었기 때문에 추가적인 디버깅 및 개발 시간을 절약해야 했기 때문.
이 방법은 복제를 통한 부하 분산이라는 목표와는 다소 거리가 있었지만, 당장의 문제를 해결하기 위해서는 현실적인 대안이었습니다.
더 내용적인 해결 방법 고민 및 적역
더 나은 해결책에 대한 필요성을 느끼고 있었던 저는, 일정에 여유가 생기자 이 문제를 직접 해결해보겠다고 자청했습니다. 관련 자료를 찾아보며 참고한 주요 레퍼런스는 다음과 같습니다.
이 자료들을 바탕으로 AbstractRoutingDataSource를 사용하여 해결하는 방법을 도입했습니다. 이 방식을 통해, INSERT 후 SELECT 작업이 필요할 수 있는 로직이 포함된 부분에서는 Master를 바라보도록 구현했습니다.
적용 방법
-
AbstractRoutingDataSource, AOP 적용:
INSERT후SELECT작업이 필요한 부분을 구분해, 해당 로직 내에서는 Master를 바라보도록 설정했습니다.
-
트랜잭션 도입:
- ProxySQL을 사용하는 경우 트랜잭션 내에서는 기본적으로 Master만 바라보게 됩니다. 이를 활용하여, 개별적인
INSERT작업이 이뤄지는 곳에서도 자연스럽게 Master를 바라보도록 했습니다.
- ProxySQL을 사용하는 경우 트랜잭션 내에서는 기본적으로 Master만 바라보게 됩니다. 이를 활용하여, 개별적인
-
주요 비즈니스 로직에만 Master 사용:
- 일부 주요 비즈니스 애플리케이션의 경우 ProxySQL을 거치지 않고 Master에만 직접 연결하도록 했습니다.
이 방식은 여전히 몇 가지 문제의 소지를 남겼습니다. 예를 들어, 사용자가 A와 B가 거의 동시에 데이터를 삽입하고 조회하는 경우, A가 INSERT한 데이터를 B가 바로 조회하려고 할 때 문제가 발생할 수 있습니다. 그러나 이러한 케이스는 빈번하지 않을 것이라고 판단했습니다.
또한, 주요 비즈니스 로직은 Master에만 연결해 두었기 때문에 사용자 입장에서 문제를 느낄 가능성은 매우 낮았습니다.
느낀 점
사실 복제지연 문제는 Replication 구조를 가지고 있거나 서로 다른 DB간 데이터 복제가 이루어져야할 때 맞이할 수 밖에 없는 고질적인 문제라고 생각합니다.
항상 나중에 해결해야지 해결해야지라는 생각으로 미뤄왔지만 이번에 NAVER 컨퍼런스인 DAN24에 다녀오면서 NAVER FINANCIAL Tech에 김진한님 세션 네이버페이 결제 시스템의 성장과 변화를 듣고 아 나도 회사 돌아가면 복제지연 문제를 해결해보고 싶다라는 생각이 들어 해결하게 됐습니다.
굉장히 좋은 세션과 발표였습니다.
위 본문 내용중 정확하지 않은 내용이 포함돼 있을 수 있습니다.
저는 2년차 백엔드 개발자로 스스로 굉장히 부족한 사람이라는 점을 인지하고 있는지라
제가 적은 정보가 정확하지 않을까 걱정하고 있습니다.
혹여 제 정보가 잘못 됐을 수 있으니 단지 참고용으로만 봐주시고 관련된 내용을 한번 직접 알아보시는 걸 추천합니다.
혹여 잘못된 내용이 있거나 말씀해주시고 싶은 부분이 있으시다면 부담없이 적어주세요!
수용하고 개선하기 위해 노력하겠습니다!
Reference
https://drunkenhw.github.io/java/select-database/
https://velog.io/@ghkvud2/AbstractRoutingDataSource-%EC%A0%81%EC%9A%A9%ED%95%98%EA%B8%B0
https://velog.io/@kimtjsdlf/%EB%B3%B5%EC%A0%9C2-%EB%B3%B5%EC%A0%9C-%EC%A7%80%EC%97%B0
