굉장히 기본적인 개념이라고 할 수 있는 프로세스와 스레드에 대해 자세히 알아보고자한다.
모르던 개념은 아니라 원래 알던 개념을 먼저 적어볼까 한다.
좀 더 자세히 공부하기 전 알던 개념
프로세스란 하드웨어로부터 자원을 할당받아 실행되고 있는 상태의 프로그램을 프로세스라고 한다.
스레드란 CPU에서 프로세스가 실행되는 단위를 스레드라고 한다.
라고 알고있다.
그렇다면 이제 좀 더 자세히 공부해보자.
프로그램? 프로세스? 스레드?
일단 프로그램과 프로세스의 차이는 뭘까?
위키백과에는 다음과 같이 적혀있었다.
프로그램은 일반적으로 하드 디스크 등에 저장되어 있는 실행코드를 뜻하고, 프로세스는 프로그램을 구동하여 프로그램 자체와 프로그램의 상태가 메모리 상에서 실행되는 작업 단위를 지칭한다. 예를 들어, 하나의 프로그램을 여러 번 구동하면 여러 개의 프로세스가 메모리 상에서 실행된다.
어떻게 보면 클래스와 인스턴스같다는 생각이 들었다.
여기서 조금 재미있는 건 프로그램이란 컴퓨터에서 실행될 때 특정 작업을 수행하는 일련의 명령어들의 모음이라는 것이다.
결국 프로그램이란 일련의 작업을 수행할 수 있는 코드 덩어리 라는 것이다.
대부분의 프로그램들은 하드디스크 등의 매체에 바이너리 형식의 파일로 저장되어 있다가 사용자가 실행시키면 메모리로 적재되어 실행된다.
내가 생각했던 프로그램은 훨씬 무거운 느낌이였는데, 위 사실을 알고나니 뭔가 신기했다.
한가지 위 본문에서 조금 의문이였던 건 사실 CPU에서 실행되는 단위는 스레드라고 알고있기 때문인데, 스레드가 생기기 전에는 프로세스가 CPU에서 실행되는 단위였기 때문에 저렇게 적혀있는게 아닌가 싶다.
영문 버전을 보면
In computing, a process is the instance of a computer program that is being executed by one or many threads.
라고 한다. 대충 해석하자면
컴퓨팅에서 프로세스는 하나 이상의 스레드에 의해 실행되는 컴퓨터 프로그램의 인스턴스 입니다.
라고 해석할 수 있겠다.
클래스와 인스턴스같다고 느낀게 잘못된건 아니였나보다.
결국 스레드란 프로세스 내에서 실제로 작업을 수행하는 주체를 의미하는 것이다.
한가지 재미있는 사실은 옛날에는 오직 하나의 프로세스만 실행할 수 있었으나 컴퓨터가 발전하면서 멀티태스킹을 이용하여 여러개의 프로세스를 띄울 수 있게 되었다고 한다.
두 개 이상의 프로그램을 실행시키지 못했다니, 지금으로는 상상하기도 어렵다.
또한 프로세스는 완벽히 독립적이기 때문에 보통의 경우 메모리 영역을 다른 프로세스와 공유를 하지 않지만, 쓰레드는 해당 쓰레드를 위한 스택을 생성할 뿐 그 이외의 Code, Data, Heap영역을 공유한다.
프로세스의 상태
그렇다면 프로세스가 생성되는 과정은 어떻게 될까?
사용자가 프로그램을 시작해달라는 요청을 보내면 OS는 하드디스크에서 해당 프로그램을 메인 메모리로 로드하면서, 필요한 자원을 할당한다.
굉장히 잘 설명된 그림이 있어서 가져와 봤다.

출처 : https://wisdom-and-record.tistory.com/85
프로세스의 메모리 구조는 잠시 후 살펴도록하고 상태부터 살펴보자.
커널 내에는 준비 큐, 대기 큐, 실행 큐 등의 자료 구조가 있으며 커널은 이것들을 이용하여 프로세스의 상태를 관리한다.

-
생성(create) : 프로세스가 생성되는 중이다.
-
실행(running) : 프로세스가 CPU를 차지하여 명령어들이 실행되고 있다.
-
준비(ready) : 프로세스가 CPU를 사용하고 있지는 않지만 언제든지 사용할 수 있는 상태로, CPU가 할당되기를 기다리고 있다. 일반적으로 준비 상태의 프로세스 중 우선순위가 높은 프로세스가 CPU를 할당받는다.
-
대기(waiting) : 보류(block)라고 부르기도 한다. 프로세스가 입출력 완료, 시그널 수신 등 어떤 사건을 기다리고 있는 상태를 말한다.
-
종료(terminated) : 프로세스의 실행이 종료되었다.
이는 곧 프로세스 스케줄링과 컨텍스트 스위칭과도 관련있는 데 이는 차후에 다루도록 하겠다.
뭐 대충 보면 모든 상태가 어떻게 보면 당연한 것들이라는 생각이 든다.
프로세스의 메모리 구조
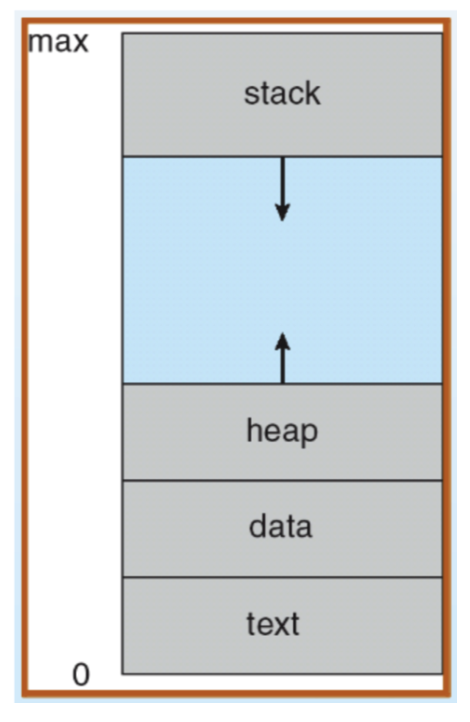
출처 : https://velog.io/@gndan4/OS-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4-%EA%B5%AC%EC%A1%B0
프로세스의 일반적인 구조는 위의 그림과 같다.
-
text(CODE): 컴파일된 소스 코드가 저장되는 영역
-
data: 전역 변수/초기화된 데이터가 저장되는 영역
-
stack: 임시 데이터(함수 호출, 로컬 변수 등)가 저장되는 영역
-
heap: 코드에서 동적으로 생성되는 데이터가 저장되는 영역
정확하게는
출처: http://www-01.ibm.com/support/knowledgecenter/SSLTBW_1.12.0/com.ibm.zos.r12.euvmo00/euva3a00451.htm

위 그림의 오른쪽 구조에 가까울 것이다.
왜냐면 이제는 프로세스가 하나 이상의 스레드에 의해 실행되기 때문이다.
스레드란
위키백과에는 다음과 같이 적혀있다.
스레드(thread)는 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다. 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있다. 이러한 실행 방식을 멀티스레드(multithread)라고 한다.
프로세스간 컨텍스트 스위칭보다 같은 프로세스 내에 있는 스레드끼리의 콘텍스트 스위칭이 비용이 저렴한데, 그 이유는 멀티프로세스에서 각 프로세스는 독립적으로 실행되며 각각 별개의 메모리를 차지하고 있는 것과 달리 멀티스레드는 프로세스 내의 메모리를 공유해 사용할 수 있기 때문이다.
컨텍스트 스위칭이란?
멀티프로세스 환경에서 CPU가 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선 순위의 프로세스가 실행되어야 할 때 기존의 프로세스의 상태 또는 레지스터 값(Context)을 저장하고 CPU가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값(Context)를 교체하는 작업을 Context Switch(Context Switching)라고 한다.
이는 차후 다시 좀 더 살펴보기로 하자.
스레드의 장단점
장점
- 응답성
- 하나의 스레드가 blocked 상태인 동안(I/O를 기다리거나)에서도 다른 스레드가 실행(running)되어 빠른 응답성을 가질 수 있다.
- (예) 크롬같은 웹 브라우저에서 렉이 걸릴 때 이미지보다 글이 먼저 불러와지는 것과 비슷하다. 그림을 가져오는 것은 blocked이지만 text를 가져오는 것은 따로 진행되기 때문에 글이라도 먼저 볼 수 있는 것이다.
- 자원 공유
- code 영역, data 영역, OS resources 들을 공유하여 자원을 효율적으로 사용한다.
- 경제적
- 스레드를 생성하는 것이 프로세스를 생성하는 것보다 비용이 적다.
- 프로세스 간의 문맥 교환은 스레드 간의 문맥 교환보다 오버헤드가 더 크다.
(프로세스 문맥 교환시 TLB가 flush 되기 때문. 스레드는 Stack 영역만 처리하면 된다.)
- 병렬성
- 멀티 코어 환경에서 서로 다른 스레드가 서로 다른 CPU에서 병렬적으로 처리되어 높은 처리율과 성능 향상을 기대할 수 있다.
- 커널의 도움없이 상호간에 통신이 가능
- Stack을 제외한 메모리 공간을 공유하므로 스레드간 통신이 간단하다.
단점
- 각 스레드가 Stack을 제외한 메모리 공간을 공유하기 때문에 동기화 문제가 발생할 수 있다.
- 하나의 스레드에 문제가 발생하면 프로세스 전체가 영향을 받는다.
- 주의 깊은 설계가 필요하며 디버깅이 까다로움 (프로그래머의 역량)
- 스레드를 많이 생성하면 context switching이 많이 생겨 성능 저하 발생할 수 있다.
모르는 것을 알게 됐다기 보다 알고있던 개념을 정리 할 수 있었던 것 같다.
이제 컨텍스트 스위칭과 프로세스 스케줄링에 대해 알아보도록 하겠다.
커널 레벨 스레드, 유저 레벨 스레드
커널 레벨 스레드
-
커널 스레드는 OS에서 구현된다. 운영체제가 프로세스 내에 여러 스레드가 있다는 것을 알고 있기 때문에 커널이 스레드의 생성 및 스케줄링 등을 관리한다. (유저 스레드 1개당 커널 스레드 1개)
-
한 스레드가 중단되어도, 같은 프로세스 내의 다른 스레드들을 계속 실행가능하다. 사용자 레벨 스레드에 비교하여 생성 및 관리가 느리다.
-
장점
- 커널이 각 스레드 개별적으로 관리할 수 있음
- 동작중인 스레드가 System Call(커널 호출)해도 해당 프로세스 내 다른 스레드가 계속 실행될 수 있음.
-
단점
- 스케쥴링과 동기화를 위해 System Call(커널 호출)하는데 오래 걸림
- 유저모드와 커널모드 간 전환이 빈번하여 성능 저하
사용자 레벨 스레드
-
스레드 기능을 제공하는 라이브러리 활용하는 방식(#include 등을 통해). 커널에 진입하지 않아도 된다. 사용자 영역에서 스레드연산을 수행한다.
-
운영체제는 프로세스 안에 여러 스레드가 있다는 것을 모르기 때문에 커널은 하나의 프로세스로 인식한다. 따라서 하나의 스레드가 중단되면 같은 프로세스 내의 모든 스레드가 중단된다.
-
동일한 메모리 영역에서 스레드가 생성, 관리되므로 속도가 빠르다.
-
장점
- 스케쥴링과 동기화를 위해 System Call(커널 호출)하지 않기 때문에 오버헤드 적음.(Context Switching을 프로세스 내부에서 진행하면 됨)
커널이 스레드 존재를 모르기 때문에 유저모드와 커널모드 간 전환이 없음 -
단점
- 스케쥴링 우선순위를 지원하지 않으므로 어떤 스레드가 먼저 동작할지 모름
하나의 스레드가 System Call(커널 호출)하면 해당 프로세스 내 모든 스레드가 중단됨(Blocking System Call)
별첨 : https://ko.wikipedia.org/wiki/%EC%BB%B4%ED%93%A8%ED%84%B0_%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%A8
https://velog.io/@zerone015/thread
https://en.wikipedia.org/wiki/Process_(computing)
