[ 트러블슈팅 ] Kubernetes Pod Scale In 과정에서 실패한 Graceful Shotdown, 소실된 비동기 로직 탐색 여정
이번에 회사에서 직면했던 실패한 Graceful Shotdown에 관한 내용을 공유하고자 글을 남깁니다.
문제 발생
평소에는 예외상황이나 문제상황들을 Slack으로 많이 접하는 편인데요.
오늘은 평소와 다르게 문제를 접하게 됐습니다.
이번 문제는 백오피스 사용자의 문의로부터 시작됩니다.
"데이터가 하나가 안맞는 거 같아요...!"
바로 부랴부랴 데이터를 확인해보기 시작했습니다.
확인 결과 특정 테이블에서 각 튜플의 상태값을 나타내는 Flag 컬럼중 하나가 기대했던 값과는 다른 상태였습니다.
서비스에 큰 영향이 있을 정도의 Flag는 아니였기 때문에 급하게 해결해야 하는 문제는 아니였다는 점에서는 아주 다행이였습니다.
그러나 Flag 컬럼이 어째서 기대했던 값과 달랐던 것인지 정확히 분석할 필요가 당연히 있었습니다.
해당 서버를 담당하시는 개발자 분이 확인해본다고 하셨고 어떤 이유에서인지 들을 준비를 하고있었습니다만 그 분이 열심히 원인을 찾다가 말씀해주셨습니다.
해당 Flag 컬럼을 업데이트하는 로직이 포함돼 있는 요청을 던진 Request가 정상적으로 Response까지 뱉었는데 이게 왜 Update가 안됐는지 모르겠네...? 뭐지???
자... Debug 여행의 시작이였습니다.
public ResponseModel someMethod(){
// 특정 로직들 수행
flagColumnAsyncUpdateMethod();
return new ResponseModel();
}
@Async
public void flagColumnAsyncUpdateMethod(){
// Flag Column update
}해당 Flag 컬럼이 업데이트되는 로직은 다음과 같았습니다.
사실 이렇게 보면 별거 없는 로직입니다.
그래서 처음에는 더 이해가 안됐습니다.
이게 Response까지 정상으로 반환했는데
Flag 컬럼만 업데이트 안될 이유가 뭐가 있지...? 도대체?
원인을 생각하고 로그를 막 뒤져보다 문득 이건가? 하고 떠오르는게 있었습니다.
이미 제목에서 힌트를 얻으신 분들은 눈치 채셨을지도 모르겠습니다만 저때는 생각도 못하고 있었기 때문에 찾는데 조금 시간이 걸린 것 같습니다.
생각의 흐름은 이러했습니다
1. 혹시 로직이 돌다 죽었나?
2. 서버가 죽을 일이 뭐가 있지?
3. Kubernetes HPA가 있겠구나
4. 근데 설정해놔서 Pod 죽일때 Graceful Shutdown할텐데?
5. Graceful Shutdown이 제대로 안됐나? 왜 안됐지?
6. 아 비동기...!Kubernetes HPA란
HPA(HorizontalPodAutoscaler)는 CPU, Memory 등 리소스가 정해둔 임계치를 초과할 경우 자동으로 스케일 아웃(Pod의 리소스를 증가 시키지 않고, Pod 개수 자체를 늘려줌) 해주는 기능을 갖추고 있습니다. HPA 컨트롤러가 리소스를 체크하며 정해둔 replicas 수에 맞춰 Pod를 줄이거나 늘려줍니다.
출처: https://nirsa.tistory.com/187 [Nirsa:티스토리]
Graceful Shutdown이란
우아한 종료라고 직역하면 뭔가 어색하지만, 그 역의 경우를 생각해보면 제법 어울리는 표현이라는 생각이 듭니다. 우아한 종료는 프로그램이 종료될 때 최대한 side effect가 없도록 로직들을 잘 처리하고 종료하는 것을 말합니다.
출처: https://csj000714.tistory.com/518
원인 파악
Kubernetes HPA가 Pod가 더이상 필요하지 않다 생각해 Delete를 날리게 되면 Pod 를 삭제하기 전에 Pod 내의 컨테이너에 SIGTERM시그널을 날리게 됩니다.
시그널을 보내고, 일정 시간(기본적으로 30초) 동안 대기하다가 만약 일정 시간 내에 컨테이너가 종료되지 않으면 kubelet 은 SIGKILL 시그널을 보내어 강제로 컨테이너를 종료시킵니다.
스프링 부트 내장 WAS인 Tomcat은 Option을 설정할 경우 Graceful shutdown을 지원하는데
해당 서버는 잘 설정돼 있는 상태였기 때문에 SIGTERM을 받는다면 Request를 받았던 요청들을 완료한 후 Rsponse를 반환하고 서버를 종료하게 됩니다.
그래서 저는 해당하는 메소드가 비동기 로직을 Call해놓고는 Response를 반환했기 때문에 Tomcat 입장에서는 정상적으로 끝났다 생각하고 종료한 거 아닐까? 라는 생각이 들었습니다.
바로 Pod가 죽는 시점쪽을 중점으로 로그를 까봤습니다.
아니나 다를까 정답.
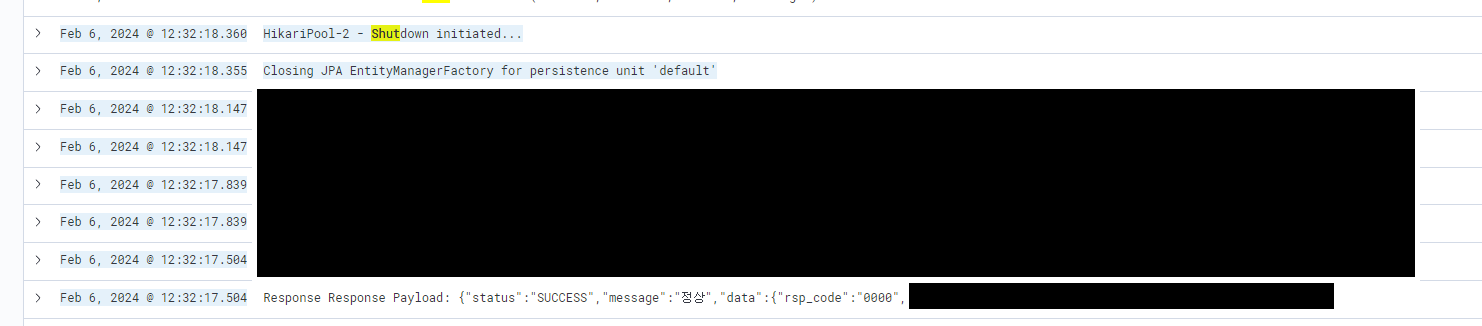
Response 이후에 바로 서버가 Shutdown 되기 시작하는 모습을 볼 수 있었습니다.
스프링 애플리케이션이 비동기 async 로직을 다 수행하지 않았음에도 종료된 것이죠.
그리고는 관련한 이슈를 찾아봤습니다 결과적으로 비슷한 케이스를 찾을 수 있었죠
해결 방법 또한 찾을 수 있었습니다. 저또한 마찬가지로 다음과 같은 방법으로 해결했습니다. (관련 글)
정리
시퀀스 다이어그램으로 정리하자면 다음과 같았습니다.
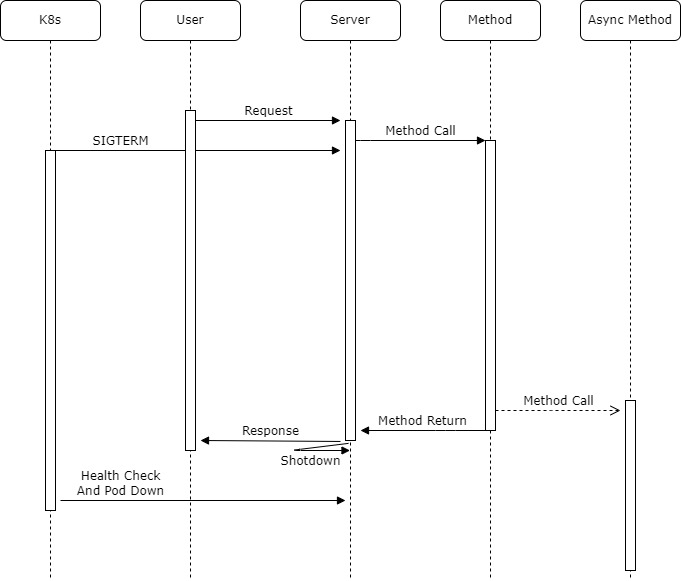
글로 정리하자면 다음과 같았죠
- 12시 30분에 Request
- Request 직후 k8s pod delete
- 해당 pod request 더이상 안받음
- spring graceful 설정 돼 있기 때문에 response 줄때까지 shutdown 대기
- 로직 돌며 Async로직 만났을때 비동기 던지고 response 줌
- response 줬기때문에 shutdown
- Async 로직 안돔 ( 문제 상황 발생 )재미있는 트러블슈팅이였습니다. Gracefult shutdown에 대해 한번 더 자세히 보게 된 계기가 됐고, Health Check나 비동기에 대해서도 한번 더 고심하게 되는 트러블 슈팅이였습니다.
최근들어 인프라쪽을 보게되는 일이 많았는데 K8s 파드가 오토스케일링 된다는 점을 생각하지 못했다면 디버깅하는데 좀더 시간이 걸렸을 수도 있겠다 싶었습니다.
위 본문 내용중 정확하지 않은 내용이 포함돼 있을 수 있습니다.
저는 1년차 백엔드 개발자로 스스로 굉장히 부족한 사람이라는 점을 인지하고 있는지라
제가 적은 정보가 정확하지 않을까 걱정하고 있습니다.
혹여 제 정보가 잘못 됐을 수 있으니 단지 참고용으로만 봐주시고 관련된 내용을 한번 직접 알아보시는 걸 추천합니다.
혹여 잘못된 내용이 있거나 말씀해주시고 싶은 부분이 있으시다면 부담없이 적어주세요!
수용하고 개선하기 위해 노력하겠습니다!!!
Reference
https://leehosu.github.io/kubernetes-delete-pod
https://hudi.blog/springboot-graceful-shutdown/
https://velog.io/@dongvelop/Springboot-Graceful-Shutdown
https://findmypiece.tistory.com/321
https://peterica.tistory.com/184
https://kth990303.tistory.com/464
https://saramin.github.io/2022-05-17-kubernetes-autoscaling/
