
사용 데이터: 캐글/스포티파이 사용자 행동 데이터
목표
12-20세 이용자의 콘텐츠별 팟캐스트 선호 길이 데이터 전처리 및 시각화
데이터 전처리 과정
엑셀 파일을 판다스 데이터프레임으로 불러오기
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_excel('./Spotify_data.xlsx')
df = pd.DataFrame(data)- 판다스와 맷플롯립을 불러왔다.
- 스포티파이 사용자 행동 데이터 엑셀 파일을 data로 불러오고, 불러온 data를 판다스 데이터 프레임으로 변환했다.
팟캐스트 선호 길이 데이터 전체 결측치 확인하기
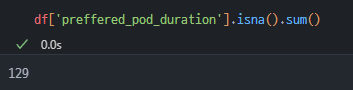
- 내가 사용할
preffered_pod_duration, 팟캐스트 선호 길이 컬럼 전체에서 결측치가 129개 있다는 것을 확인했다.
팟캐스트 선호 길이 데이터 중 12-20세 데이터 선택해서 총 개수 확인하기
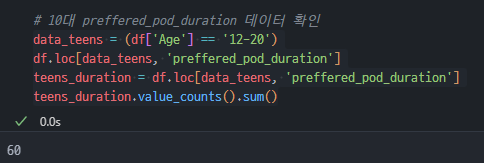
Age컬럼의 12-20세 이용자를 data_teens 라고 정의했다..loc메서드를 이용해 12-20 이용자의 팟캐스트 선호 길이 데이터를 teens_duration 이라 정의했다.- 이후 teens_duration의 값 개수를 확인했고, 총 개수가 60개라는 것을 파악했다.
12-20세 팟캐스트 선호 길이 결측치 확인하기
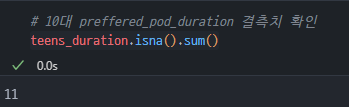
- teens_duration의 결측치를 확인했고, 결측치가 11개라는 것을 파악했다.
음악을 선호하는 12-20세의 팟캐스트 선호 길이 결측치 확인하기

Age가 12-20이고,preferred_listening_content를 Music 으로 선택한 데이터를 data_teens_music 이라고 정의했다.- 이후 data_teens_music의 팟캐스트 선호 길이 데이터 중 결측치를 확인했고, 결측치가 10개라는 것을 파악했다.
음악을 선호하는 12-20세의 팟캐스트 선호 길이 결측치 처리하기
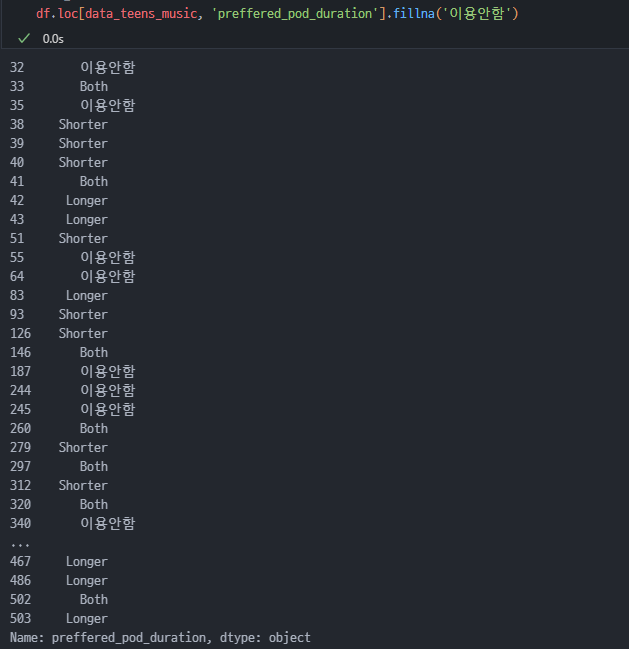
- 해당 결측치 데이터는 선호 콘텐츠로 Music을 선택했고, '팟캐스트 다양성 만족도'를 제외한 팟캐스트 관련 모든 컬럼에 NaN값을 가졌다.
- 이에 따라 음악을 선호하는 12-20세의 데이터 중 결측치의 값을 팟캐스트를 이용하지 않는다고 해석해, '이용안함' 값으로 대체했다.
영어 데이터값 한글 데이터값으로 바꾸기
 |  |
- '이용안함'으로 결측치를 대체한 후, data_teens_music의 팟캐스트 선호 길이 값과 값의 개수를 확인했다.
- 결측치를 대체한 12-20세의 팟캐스트 선호 길이를 df_music이라고 정의했다.
- 이후 시각화의 가독성을 위해
.replace메서드를 이용해 영어 값을 한글로 변경하고 값을 확인했다. preffered_pod_duration컬럼에 관한 설명이 '짧은 팟캐스트 에피소드(30분 미만) 또는 긴 에피소드(30분 이상)를 선호합니까?' 이기에 'Longer'는 '30분 이상', 'Shorter'는 '30분 미만', 'Both'는 '상관없음'으로 번역했다.- 이후 최종 데이터를 df_music이라 정의했다.
팟캐스트를 선호하는 12-20세의 팟캐스트 선호 길이 결측치 확인하고 처리하기
 |  |
Age가 12-20이고,preferred_listening_content를 Podcast 로 선택한 데이터를 data_teens_pod 이라고 정의했다.- 이후 data_teens_pod의 팟캐스트 선호 길이 데이터 중 결측치를 확인했고, 결측치가 1개라는 것을 파악했다.
- 해당 데이터는 이미 팟캐스트를 선호하는 이용자이기 때문에, 이용자가 데이터를 제출할 당시에 팟캐스트 길이에 관한 선호가 명확하지 않았을 가능성을 고려해 'Both', 즉 '상관없음'로 통합했다.
하지만 현재 정리를 하면서 느낀 점은, 결측치가 'Both'의 의미와는 맞지 않는 것 같다.
통합하기 보다는.dropna()를 이용해서 결측치를 처리하는 과정이 필요하지 않았을까싶다.
영어 데이터값 한글로 바꾸기
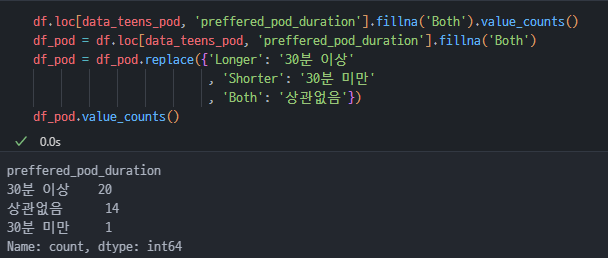
- 시각화의 가독성을 위해
.replace메서드를 이용해 영어 값을 한글로 변경하고 값을 확인했다. - 이후 최종 데이터를 df_pod이라 정의했다.
데이터 시각화
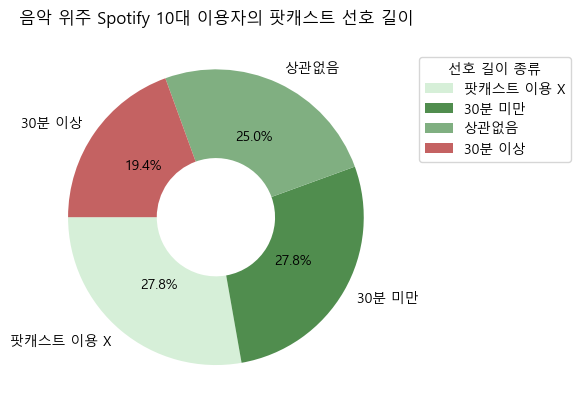
음악 위주로 스포티파이를 사용하는 10대 이용자
df_music.value_counts()
pod_duration_music = df_music.value_counts()
pod_duration_music
# 한글 폰트 설정
plt.rc('font', family= 'Malgun Gothic')
plt.pie(pod_duration_music, labels = pod_duration_music.index
, autopct = '%1.1f%%' #autopct= '%1.1f%% : 비율 소수점 첫째자리까지 표현
, startangle = 180 #시작점
, wedgeprops = {'width': 0.6} #도넛
, colors = ['#D6EFD8', '#508D4E', '#80AF81', '#c46262']
plt.title('음악 위주 Spotify 이용 10대 고객')
plt.legend(loc = (1.05, 0.65), title = '선호 길이 종류')
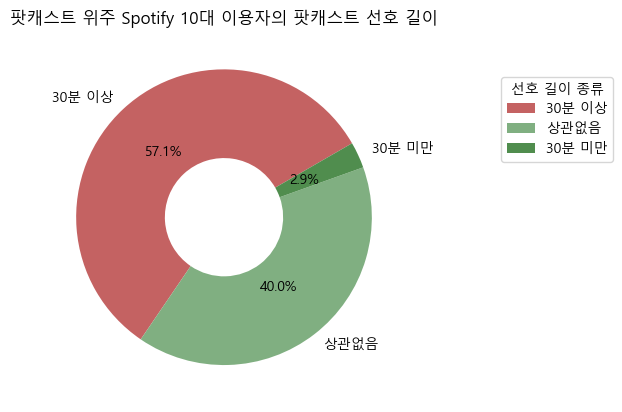
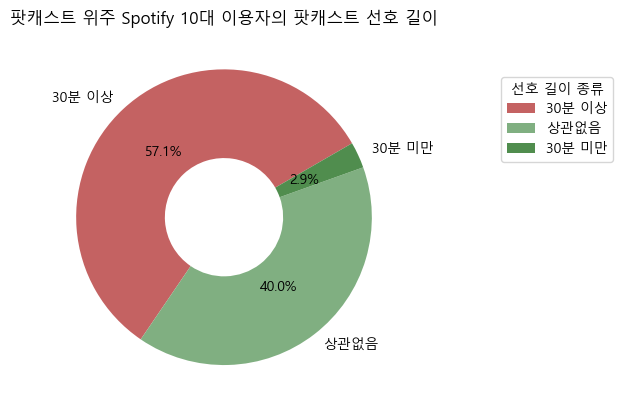
plt.show()팟캐스트 위주로 스포티파이를 사용하는 10대 이용자
pod_duration_pod = df_pod.value_counts()
pod_duration_pod
plt.rc('font', family= 'Malgun Gothic')
plt.pie(pod_duration_pod, labels = pod_duration_pod.index
, autopct = '%1.1f%%'
, wedgeprops = {'width': 0.6}
, colors = ['#c46262', '#80AF81', '#508D4E']
, startangle=30)
plt.title('팟캐스트 위주 Spotify 이용 10대 고객')
plt.legend(loc = (1.25, 0.65), title = '선호 길이 종류')
plt.show()데이터 해석
| 음악 위주 | 팟캐스트 위주 |
|---|---|
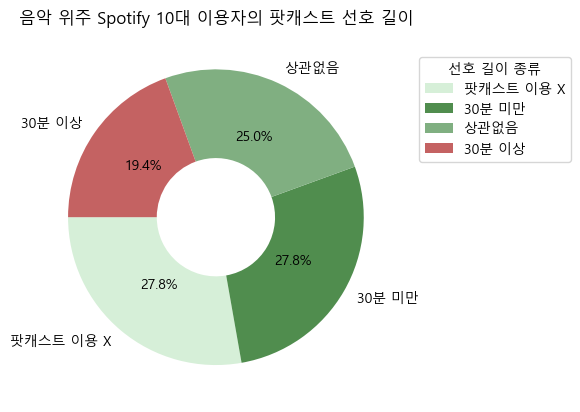 |  |
- 음악 위주로 스포티파이를 사용하는 10대 이용자는 팟캐스트 길이에 대한 선호가 뚜렷하지 않다.
- 이에 반해, 팟캐스트 위주로 스포티파이를 사용하는 10대 이용자는 과반수가 넘는 비율(57.1%)로 길이가 긴 것을 선호하는 것으로 나타났다.
- 따라서 한 에피소드의 길이가 긴 팟캐스트를 제작하거나 수입한다면 기존 이용자 유지 및 신규 이용자 유입이 가능할 것이다.
팟캐스트를 이용하지 않는 이용자의 조각은 연한 색상을 선택하고, 결과를 도출해낼 중요한 조각인 '30분 이상'은 붉은 색상을 선택했다.
시각화를 하는 과정에서 도넛의 크기, 테두리 색상, 범례의 위치, 그림자의 유무, 파이차트 조각내기 등 다양한 선택지가 있었다.
그중에서 데이터 해석의 오해를 불러오지 않으면서 적당한 시각화를 구현해보았다.

데이터 분석 공부중