
조건에서의 연산자
| <> 혹은 != | NOT 혹은 ! | LIKE | NOT IN | IS NOT NULL |
|---|---|---|---|---|
| n<>10 n!=10 | NOT A !A | LIKE('%과자%') | A NOT IN B | A IS NOT NULL |
| n이 10이 아닌 값 | A가 아닌 값 | 문자열이 ~와 같을 때 (%가 앞뒤에 붙으면 완전히 똑같은 값, 앞/뒤에 붙으면 ~로 끝나는/시작하는 값 ) | B에 A가 포함되어 있지 않은 값 | A값이 비어있지 않는 값 |
where 절에서 사용할 때 조건이 여러 개면 각 조건들을 and 로 묶는다.
현업에서는 보통 AWS라고 하는 클라우드의 S3 저장소에 데이터를 보관한다. Athena를 이용해 S3 저장소에 있는 데이터를 사용하는데, 아테나는 쿼리로 스캔한 데이터 양에 따라 요금이 청구된다.
조건문을 자세히 작성하지 않으면 불필요한 비용이 발생되는 것이기 때문에 (요금폭탄💣!) 조건문을 자세히 작성하는 것이 중요!
group by 와 having
group by에서 잡아야 하는 기준
group by는 특정 컬럼을 기준으로 데이터를 요약해서 비교하고 싶을 때 사용하는 절인데, 집계함수를 작성했을 때는 꼭!! group by를 작성해야 한다!
이 부분에 대한 이해가 부족해서 SQL 코딩테스트 할 때 오류가 많이 발생했다.
작성 방법:
1. select 뒤 기준컬럼 작성
2. 집계함수 작성
3. group by 기준 컬럼 작성!
데이터를 select 할 때 집계함수는 여러 데이터로부터 하나의 행을 반환하지만, select 된 기준컬럼은 n개의 값을 반환하기 때문에, group by 절을 사용하여 기준컬럼 당 값 1개를 반환할 수 있도록 명시해야 한다.
성별을 기준으로 여러가지 집계함수 사용.
select 성별, count(*), avg(나이), max(나이), min(나이), sum(나이) from theglory group by 성별 ;

having
헷갈렸던 개념 중의 하나. group by에 의한 결과를 필터링할 때 사용된다.
where절은 group by 전 데이터를 기준으로 필터링을 한다면, having절은 group by 후 결과값을 기준으로 필터링하는 것이 차이점!
내가 원하는 데이터가 어떤 것이냐에 따라 필터링하는 방법이 달라지므로 잘 판단해야 한다.
having 절은 group by 없이 사용해도 오류가 나지 않는다. 그렇지만 비표준적인 방법. 테이블 전체가 하나의 그룹이 되고 집계함수가 사용됐다면 group by 없이도 having 사용 가능.
pay_type 별 최소 pay_amount를 구하고, 그 값이 500이상인 경우를 추출
group by, having을 사용한 경우select pay_type, min(pay_amount) from payment group by 1 having min(pay_amount)>=500 ;
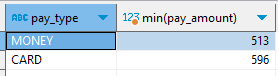
where 절을 사용한 경우select pay_type, min(pay_amount) from payment where pay_amount >= 500 group by 1 ;
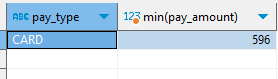
having절은 select 문에서 데이터를 선택할 때부터 조건이 들어갔기 때문에 최소 결제 금액이 500 이상인 데이터 중에서 가장 작은 결제 금액을 출력한다.
현금은 최소 결제 금액이 500을 넘지 않기 때문에 출력되지 않는다. (현금의 최소 결제 금액: 20)
그에 비해 where절을 사용한 경우는 전체 데이터에서 추출했기 때문에 결제 금액이 500 이상인 최소 결제 금액이 출력된다.
substr, concat을 이용한 문자 변경
substr
substr(조회할 컬럼 이름, 시작 위치, 글자 수)
: 특정 문자만 추출할 때 사용한다.
서울 지역의 음식 타입별 평균 주문 금액 구하기
select substr(addr, 1, 2) "지역", cuisine_type "음식 종류", avg(price) "평균 금액" from food_orders where addr like '서울%' group by 2 ;

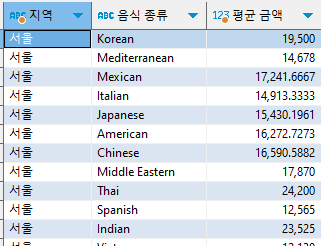
where 절을 이용해 addr 컬럼에서 서울로 시작하는 데이터만 뽑고, addr 속 데이터의 첫 번째 글자부터 두 번째 글자까지만 출력하도록 substr(addr,1,2)를 사용했다.
concat
concat(붙이고 싶은 값1, 붙이고 싶은 값2, ... )
: 여러 문자를 합하여 포맷팅할 때 사용한다. 컬럼의 값끼리도 붙일 수 있다.
‘[지역(시도)] 음식점이름 (음식종류)’ 컬럼을 만들고, 총 주문건수 구하기
select concat ('[', substr(addr, 1,2), ']', restaurant_name, ' (', cuisine_type ,')') "바뀐 이름", count(1) "주문 건수" from food_orders group by 1 ;
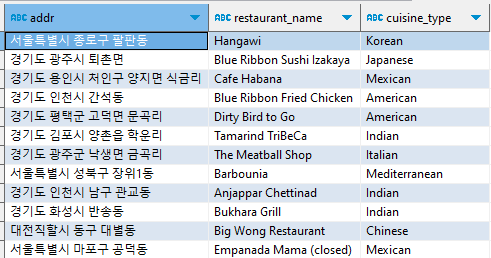

substr을 활용해 지역 부분만을 추출하고 concat으로 [ ]로 감싸주었다. 그리고 주어진 조건들을 함께 붙여주었다.
union과 join을 활용한 테이블 결합
union 함수
select 컬럼명
from 테이블명1
union(all)
select 컬럼명
from 테이블명2여러 개의 select 문의 결과를 하나의 테이블로 연결해서 보고 싶을 때 사용한다.
union과 union all 으로 두 가지 종류가 있다.
두 개 다 두 쿼리문을 하나로 수직결합하는 공통점이 있지만 union은 중복된 항을 하나로 표기하고 union all은 중복을 제거하지 않고 모두 표기한다.
주의점: 열의 갯수와 순서가 모든 쿼리에서 동일해야 하고, 데이터 형식 또한 일치해야 한다.
join 함수
select 조회 할 컬럼
from 테이블1 a inner join 테이블2 b on a.공통컬럼명=b.공통컬럼명
# 예시는 inner join이다. left join도 같은 구조로 사용한다.join 함수는 공통 컬럼을 기준으로 두 테이블을 합쳐주는 용도로 사용한다.
union 함수와 비교해서 수평결합한다고 볼 수 있다. 엑셀의 vlookup과 유사하다.
inner join과 left join을 가장 많이 사용한다.
inner join: 공통 컬럼을 기준으로, 두 테이블 모두에 있는 값만 조회된다. 교집합.
left join: 공통 컬럼을 기준으로, 하나의 테이블에 값이 없더라도 모두 조회된다. (NULL값으로 출력됨) 부분집합.
서브쿼리와 join함수 동시에 활용하기
50세 이상 고객의 연령에 따라 경로 할인율을 적용하고, 음식 타입별로 원래 가격과 할인 적용 가격 합을 구하기
- 할인 : 나이-50*0.005
- 고객 정보가 없는 경우도 포함하여 조회, 할인 금액이 큰 순서대로 정렬
select cuisine_type, sum(price), sum(price*distcount_rate) discounted_price from ( select f.cuisine_type, f.price, c.age, (c.age-50)*0.005 distcount_rate from food_orders f left join customers c on f.customer_id=c.customer_id where c.age>=50 ) a group by 1 order by 3 desc ;서브쿼리문 출력 결과
전체쿼리 출력 결과
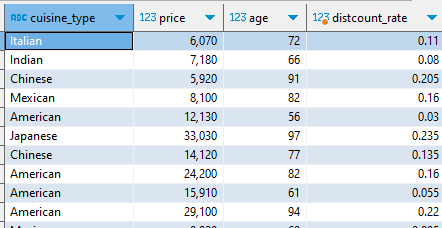
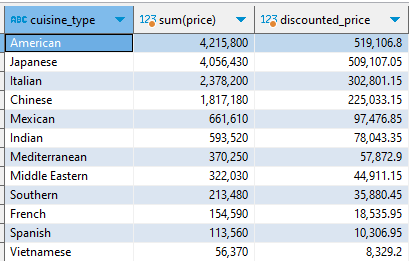
서브쿼리 안에서 left join을 활용하여 두 개의 테이블을 합치고 할인율을 구했다.
이후 본쿼리에서 음식 종류별로 원래 가격의 합과 할인 적용 가격의 합을 출력하도록 했다.
할인 적용 가격이 낮을수록 할인 금액이 큼에 따라서 order by 에는 desc 조건을 붙였다.
고객 정보가 없는 경우도 포함하여 조회하라는 조건에 의해 left join을 사용했지만, food_orders와 customers 테이블의 customer_id 개수가 같았으므로 inner join을 사용해도 상관없다고 한다.
tip!
select distinct 절을 먼저 적어서 전체적으로 어떤 데이터가 있는지 먼저 알아두면 더 좋은 쿼리를 쓸 수 있을 것이다.
