
SQL 작동 순서
FROM → ON → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY
SQL 쿼리가 실행되는 순서를 이해한다면 에러가 발생했을 때, 어디에서 문제가 발생했는지 빠르게 찾아 잘못된 부분을 효율적으로 수정할 수 있다.
순서를 고려하지 않고 쿼리를 작성하면, 의도한 결과와 다른 결과를 얻게 될 수 있다.
WHERE 절과 HAVING 절의 작동 순서와 개념의 차이에 따른 결과값의 차이
- where 절을 사용해서 조건을 넣었을 때
SELECT department, AVG(salary) as avg_salary FROM employees WHERE AVG(salary) >= 5000 GROUP BY department;에러 발생💥
→ WHERE 절은 테이블의 원본 데이터에 대해 조건을 적용한다.
또한 GROUP BY 절보다 먼저 실행 되기 때문에, 아직 평균 급여가 계산되지 않은 상태에서 조건을 적용할 수 없다.
- having 절을 사용해서 조건을 넣었을 때
SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department HAVING AVG(salary) >= 5000;정상적 실행✔️
→ HAVING 절은 GROUP BY 절에 의해 생성된 그룹에 대해 조건을 적용한다.
또한 GROUP BY 절 이후에 실행되므로, GROUP BY 절에 따라 부서별 평균 급여가 계산된 상태에서 조건을 적용한다.
윈도우 함수
윈도우 함수는 각 행의 관계를 정의하기 위한 함수로, 그룹 내의 연산을 쉽게 만들어준다.
일반적인 집계 함수와는 달리 여러 행들을 함께 고려한 계산이 가능해진다.
복잡한 서브쿼리문을 이용하거나 여러 번의 연산을 수행해줘야 할 때 사용한다.
📌 윈도우 함수 기본 구조
윈도우 함수명(__) OVER (PARTITION BY 그룹 기준 컬럼 ORDER BY 정렬 기준)
윈도우 함수명과 OVER 키워드가 항상 함께 사용되며, 이후에 특정 기준으로 그룹화하기 위한 PARTITION BY 와 정렬 순서를 지정하기 위한 ORDER BY 를 사용한다.
상황에 따라 PARTITION BY와 ORDER BY는 빠지는 경우가 있지만 함수명과 OVER는 짝꿍처럼 떨어지지 않는다.
대표적인 윈도우 함수
ROW_NUMBER()
: 각 행에 순차적으로 번호를 매긴다. 그룹 내에서 순서를 정할 때 주로 사용된다.RANK()
: 각 행의 순위를 매긴다. 동일한 값이 있는 경우 동일한 순위를 반환하고, 다음 순위는 건너뛴다.DENSE_RANK()
: RANK()와 유사하지만, 동일한 값이 있는 경우에도 순위를 건너뛰지 않고 연속적으로 순위를 매긴다.NTILE(n)
: 전체 행을 n개의 그룹으로 균등하게 나눈다. 각행에 해당 그룹 번호를 할당한다.SUM(),AVG(),MAX(),MIN(),COUNT()
: 일반적인 집계 함수이지만, 윈도우 함수로 사용하면 그룹 내에서 누적 계산이 가능하다.
예제1 RANK()
음식 타입별로 주문 건수가 가장 많은 상점 3개씩 조회하기
- 음식 타입별, 음식점별 주문 건수를 집계한다.
- 윈도우 함수를 적용한다.
- 순위에 따라 3위까지 조회하고 음식 타입별, 순위별로 정렬한다.
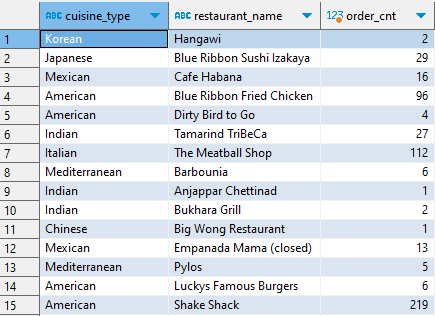
1. 음식 타입별, 음식점별 주문 건수를 집계한다.
= 베이스 데이터
SELECT cuisine_type, restaurant_name, COUNT(1) order_cnt FROM food_orders GROUP BY 1, 2;
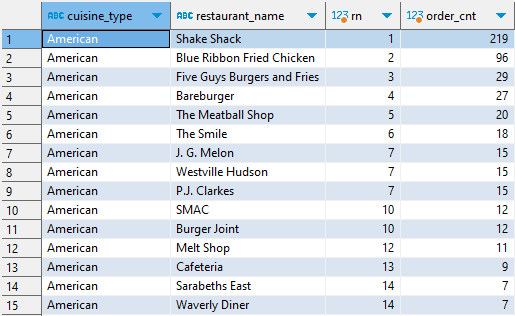
2. 1번 쿼리를 서브쿼리로 사용하고 윈도우 함수 RANK()를 적용하여 주문 건수에 따른 순위를 구한다.
SELECT cuisine_type, restaurant_name, RANK() OVER (PARTITION BY cuisine_type ORDER BY order_cnt DESC) AS rn order_cnt FROM ( SELECT cuisine_type, restaurant_name, COUNT(1) order_cnt FROM food_orders GROUP BY 1, 2) a;
3. 2번 쿼리를 다시 서브쿼리로 사용하고 순위에 따라 3위까지 음식 타입별, 순위별로 정렬한다.
SELECT cuisine_type, restaurant_name, order_cnt, rn AS "순위" FROM ( SELECT cuisine_type, restaurant_name, RANK() OVER (PARTITION BY cuisine_type ORDER BY order_cnt DESC) AS rn, order_cnt FROM ( SELECT cuisine_type, restaurant_name, COUNT(1) order_cnt FROM food_orders GROUP BY 1, 2) a ) b WHERE rn<=3 ORDER BY 1, 4;
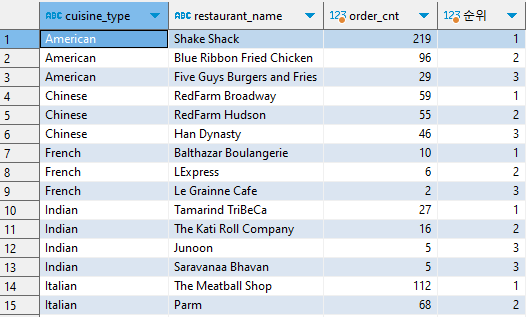
음식 타입이 Indian인 경우, 주문 건수가 동일한 항목이 두 개 존재하기 때문에 3위 순위가 중복되어 출력된다.
예제2 SUM( __ )
각 음식점 주문 건수가 해당 음식 타입에서 차지하는 비율을 구하고, 주문 건수가 낮은 순으로 정렬했을 때 누적합 구하기
- 음식 타입별, 음식점별 주문 건수를 집계하여 베이스 데이터를 만든다.
- 윈도우 함수를 적용하여 각 음식 타입별 주문 건수의 합계를 구한다.
- 윈도우 함수를 적용하여 각 음식 타입별 누적 주문 건수를 구한다.
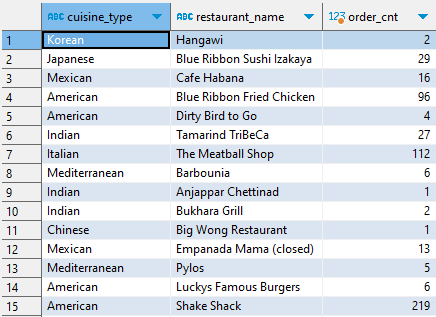
1. 음식 타입별, 음식점별 주문 건수를 집계하여 베이스 데이터를 만든다.
SELECT cuisine_type, restaurant_name, COUNT(1) AS order_cnt FROM food_orders GROUP BY 1, 2 ;
2. 1번 쿼리를 서브 쿼리로 사용하고 윈도우 함수 SUM(order_cnt)를 적용하여 각 음식 타입별 주문 건수의 합계를 구한다.
SELECT cuisine_type, restaurant_name, SUM(order_cnt) OVER (PARTITION BY cuisine_type) AS sum_cuisine_type FROM ( SELECT cuisine_type, restaurant_name, COUNT(1) AS order_cnt FROM food_orders GROUP BY 1, 2 ) a ;
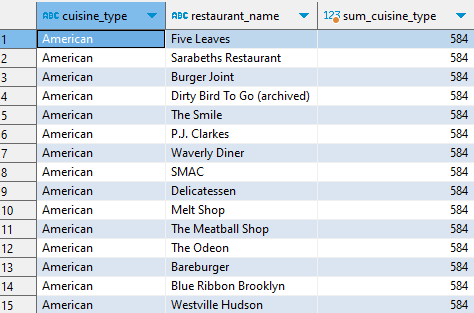
3. 추가적으로 윈도우 함수 ORDER BY 요소를 이용하여 각 음식 타입별 누적 주문 건수를 구한다.
= 정렬된 순서대로 주문 건수가 누적되어 계산된다.
SELECT cuisine_type, restaurant_name, SUM(order_cnt) OVER (PARTITION BY cuisine_type) AS sum_cuisine_type, SUM(order_cnt) OVER (PARTITION BY cuisine_type ORDER BY order_cnt, restaurant_name) AS cum_cuisine_type FROM ( SELECT cuisine_type, restaurant_name, COUNT(1) AS order_cnt FROM food_orders GROUP BY 1, 2 ) a ;
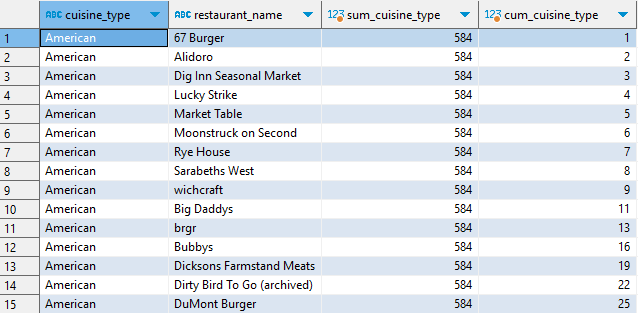
American 음식 타입의 cum_cuisine_type은 sum_cuisine_type과 동일한 값이 나올 때까지 누적되어 출력되고, 두 개의 값이 동일해지면 이후 다음 음식 타입의 데이터가 출력된다.
