ArrayList
ArrayList는 컬렉션에서 가장 많이 사용되는 클래스일 것이다. 이름에서 알 수 있듯 List인터페이스를 구현하여 데이터의 저장순서를 유지하고 중복을 허용한다.
ArrayList는 기존의 Vector를 개선한 것으로 구현원리, 기능적인면 모두 같다고 할 수 있다. 지금 JDK에 남아있는 Vector는 구 버전 코드의 호환성을 위해 남겨두고 있을 뿐이기에 사용을 권장하진 않는다.
ArrayList는 Object배열을 이용하여 데이터를 순차적으로 저장하고, 배열에 더 이상 저장할 공간이 없으면 더 큰 Object배열을 만들어 데이터를 복사해서 늘리는 방식으로 작동한다.
ArrayList↓
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable {
...
transient Object[] elementData; // Object배열
...
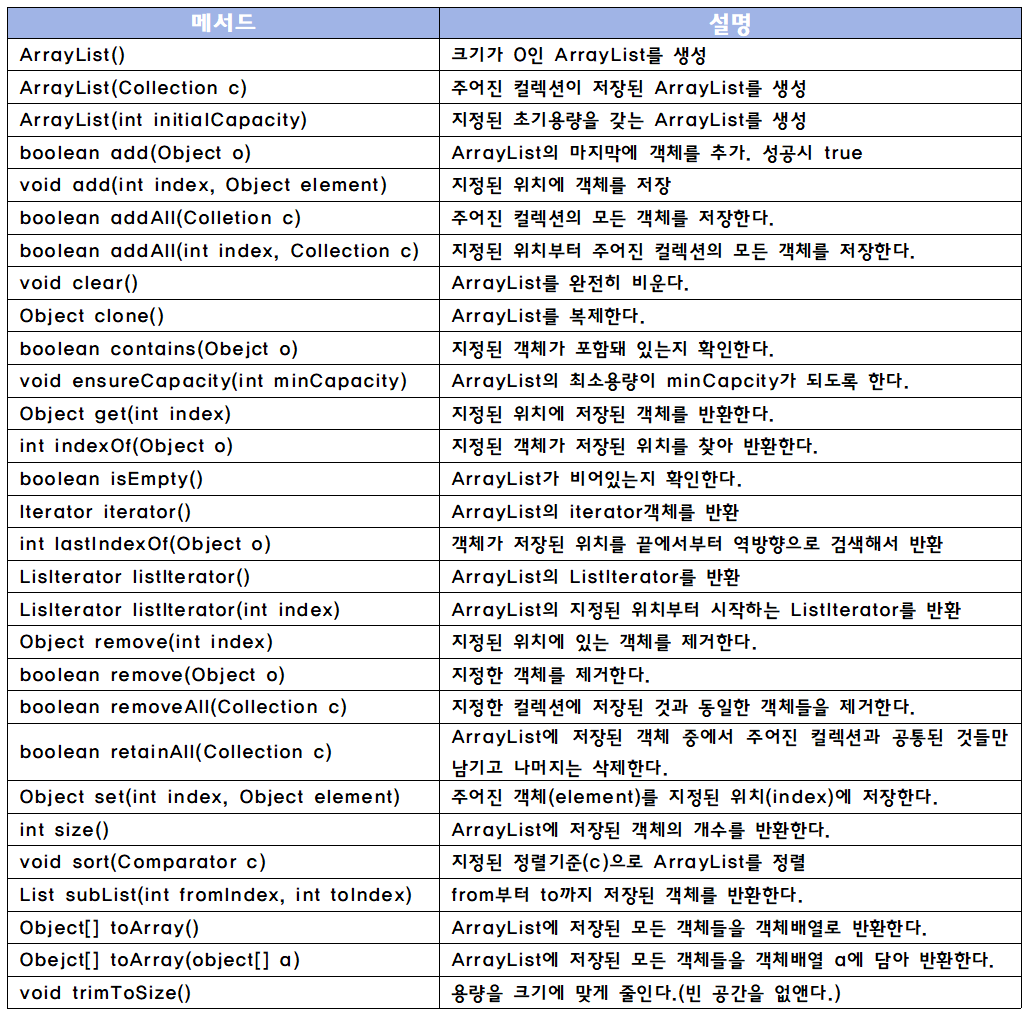
}ArrayList의 메서드들
ArrayList 예제
import java.util.*;
public class ListExample {
public static void main(String[] args) {
ArrayList list1 = new ArrayList(10);
list1.add(new Integer(5));
list1.add(new Integer(4));
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
ArrayList list2 = new ArrayList(list1.subList(1, 4));
print(list1, list2);
Collections.sort(list1); // list1과 list2를 정렬한다.
Collections.sort(list2); // list1과 list2를 정렬한다.
// Collections는 클래스이고 Collection은 인터페이스이다.
print(list1, list2);
System.out.println("list1.containsAll(list2):" + list1.containsAll(list2));
//위 containsAll은 ArrayList의 메서드가 아니다.
list2.add("B");
list2.add("C");
list2.add(3, "A"); // 인덱스가 3인 곳에 A를 추가, 뒤로 밀림
print(list1, list2);
list2.set(3, "AA"); // 인덱스가 3인 곳에 A를 설정, 기존 값 삭제
print(list1, list2);
// list1에서 list2와 겹치는 부분만 남기고 나머지는 삭제한다.
System.out.println("list1.retainAll(list2):" + list1.retainAll(list2));
print(list1, list2);
// list2에서 list1에 포함된 객체들을 삭제한다.
for(int i = list2.size() - 1; i >= 0; i--) {
if(list1.contains(list2.get(i)))
list2.remove(i); // 인덱스가 i인 곳에 저장된 요소를 삭제
}
print(list1, list2);
}
static void print(ArrayList list1, ArrayList list2) {
System.out.println("list1: " + list1);
System.out.println("list2: " + list2);
System.out.println();
}
}위 코드에서 Collections / Collection을 혼동하지 말고 containsAll은 ArrayList의 메서드가 아님에 유의하자.
ArrayList의 추가와 삭제
ArrayList의 요소를 삭제하는 경우, 삭제할 객체의 바로 아래에 있는 데이터를 한 칸씩 위로 복사해서 삭제할 객체를 덮어쓰는 방식으로 처리한다. ArrayList의 마지막 요소를 삭제한 경우에는 복사하지 않고 그냥 null로 덮어씌운다.
ArrayList에 새로운 요소를 추가할때에도 먼저 추가할 위치 이후의 요소들을 모두 한칸씩 이동시킨 후에 저장해야 한다.
성능 차이가 발생한다는 이야기이다 :D
LinkedList
배열은 가장 기본적인 형태의 자료구조로써 구조가 간단하며 사용하기도 쉽고 데이터 접근 시간이 가장 빠르다는 장점을 가지고 있지만 다음과 같은 단점을 가지고 있다.
- 크기를 변경할 수 없다.
- 크기를 변경할 수 없으므로 새로운 배열을 생성해서 데이터를 복사해야한다.
- 실행속도를 향상시키기 위해서는 충분히 큰 크기의 배열을 생성해야 하므로 메모리가 낭비된다.
- 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
- 차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠르지만, 배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터들을 복사해서 이동해야 한다. - 성능 감소
이러한 배열의 단점을 보완하는게 바로 LinkedList이다. 배열은 모든 데이터가 연속적으로 존재하지만 LinkedList는 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성돼 있다.
LinkedList의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성돼 있다.
class Node {
Node next; // 다음 요소의 주소를 저장
Object obj; // 데이터를 저장
}LinkedList의 추가와 삭제
LinkedList에서의 데이터 삭제는 간단한데, 그저 삭제하고자 하는 요소의 이전요소가 삭제하고자 하는 요소의 다음 요소를 참조하도록 변경하기만 하면 된다. 배열처럼 데이터를 이동하기 위해 복사하는 과정이 없어 매우 빠르다.
새로운 데이터를 추가할 때는 새로운 요소를 생성한 다음 추가하고자 하는 위치의 이전 요소의 참조주소를 새로운 요소의 주소로 바꾸고 새로운 요소가 그 다음 요소를 참조하도록 변경하기만 하면 된다.
ArrayList와 LinkedList의 비교
배열의 경우 n번째 인덱스 원소값을 얻어 오고자 한다면 아래와 같은 수식을 계산하기만 할 뿐이다.
- 인덱스가 n인 데이터의 주소 = 배열의 주소 + n * 데이터 타입의 크기
Object배열이 선언됐을 때 arr[2]에 저장된 값을 읽으려 한다면 n은 2, 모든 참조형 변수의 크기는 4byte이므로 생성된 배열의 주소가 0x100일 때 3번째 데이터가 저장 돼 있는 주소는 0x100 + 2 x 4 = 0x108이 된다.
배열은 각각의 요소들이 메모리 상에 연속적으로 존재하기에 이러한 간단한 계산 만으로 원하는 요소의 주소를 얻어 저장된 데이터를 읽어올 수 있지만, LinkedList는 불연속적으로 위치한 각 요소들이 서로 연결된 것이라 첫 노드부터 n번째 노드까지 직접 접근 해 봐야 원하는 값을 얻을 수 있다.
그래서 LinkedList는 저장해야하는 데이터가 많아지면 많아질수록 접근시간이 길어진다.

다루고자 하는 데이터의 개수가 변하지 않는 경우라면, ArrayList가 최상의 선택이 되겠지만, 데이터 개수의 변경이 잦다면 LinkedList를 사용하는 것이 더 나은 선택이 될 것이다.
Java API 보는법
Vector클래스와 같이 Java API에서 제공하는 기본 클래스의 실제 소스를 보고 싶다면, JDK를 설치한 디렉토리에서 src.zip파일을 찾을 수 있다. src.zip이라는 파일의 압축을 푼 다음, 패키지 별로 찾아 들어가면 원하는 클래스의 실제 소스를 볼 수 있다. 예를 들어 Vector클래스는 java.util패키지에 있으므로 'src\java\util\Vector.java'가 소스파일이다. Java API의 소스는 오랜 경력의 전문 프로그래머들에 의해 작성된 것이기 때문에 어떻게 작성하였는지 보고 따라하는 것은 프로그래밍 실력을 향상시키는데 매우 큰 도움이 될 것이다.
