해시(hash)법이란?
해시법이란? 검색뿐만 아니라, 데이터의 추가와 삭제도 효율적으로 수행하는 방법이다.
임의의 길이를 갖는 데이터를 고정된 길이의 데이터로 매핑(mapping)하는 단방향 함수를 일컫는다. 쉽게 말하자면 아무리 큰 수를 넣어도 정해진 크기의 숫자가 나온다.
이러한 해시 함수를 적용해서 나온 고정된 길이의 값을 해시값, 해시 코드, 해시섬(sum), 체크섬(checksum)등으로 부르게된다.
자료구조에서는 주로 HashTable, HashMap, HashSet등에 사용되며, 블룸 필터(+카운팅 필터)에 사용되며, 자료구조 외에서는 캐시(cash), 레코드 검색, 유사 문자열, 데이터 위/변조 탐지, 보안등에 사용되는 매우 광범위한 기술이다.
바로 아래에서 해시를 사용해 정렬된 배열에 값을 추가하는 방법을 살펴보고 이를 통해 해시에 대해 자세히 알아보자.
※ hash는 한국어로 '다진 고기 요리', '뒤범벅', '뒤죽박죽', '잡동사니'라는 뜻이 있다. 짜장범벅이 먹고싶어지는 이름이다.
정렬된 배열에 해쉬법으로 값 추가하기
일단 아래와 같은 배열이 있다고 가정하고, 해당 배열에 일반적인 방법을 사용해서 요소 35를 추가해보자. 다만 오름차순 정렬이 풀리면 안된다.
a {5,6,14,20,29,34,37,51,69,75,-,-,-}
b {5,6,14,20,29,34,35,37,51,69,75,-,-}
↑ 35 추가시, 이후 모든 요소를 이동.a 배열에 35를 오름차순이 풀리지 않게 추가하는 과정은 다음과 같다.
- 삽입할 위치가 a[5] - a[6]사이임을 binarysearch로 조사한다.
- a[6]를 포함 뒤의 모든 요소를 한칸씩 뒤로 옮긴다.
- a[6]에 35를 대입한다.
요소 이동에 필요한 복잡도는 O(n)이므로 비용이 적지않게 들어간다. 물론 데이터를 삭제할 때에도 똑같이 들어가는 비용이다.
이럴 때 해시법을 사용하면?
해시법(hasing)은 데이터를 저장할 위치(index)를 간단한 연산을 통해 검색, 추가, 삭제를 효율적으로 수행할 수 있게 만들어준다.
위 배열a의 키값(각 요소의 값)을 배열의 요솟수 13으로 나눈 나머지를 정리하면 아래의 표와 같은데, 이렇게 표에 정리한 값을 '해시값(hash value)'라고 하며, 이 해시값을 통해 데이터에 매우 빠르게 접근한다.

↑ 키값과 해시값의 대응표
위 해시값을 인덱스로 하여 원래의 키값을 저장한 배열을 바로 아래 그림의 '해시 테이블(hash table)'이라 한다.
위 표의 해시 테이블은 아래 그림의 A이다.

35 나누기 13의 나머지는 9이다. 따라서 35의 해시값인 9를 이용해서 a[9]에 35를 저장한다. B해시 테이블을 완성한다.
처음 일반적인 배열에 35를 추가할 때는 추가하는 곳 부터 뒤의 모든 요소를 한 칸씩 밀었어야 했던 경우와 달리, 해시 테이블과 해시법을 사용하면 다른 배열 요소를 뒤로 옮기지 않아도 된다.
이 과정에서 키값(35)을 해시값(9)로 변환하는 과정을 '해시 함수(hash function)'이라고 한다.
해시 함수는 보통 여기서 살펴봤듯 '나머지를 구하는 연산' 또는 이런 '나머지 연산을 다시 응용한 연산'을 사용한다.그리고 해시 테이블의 각 요소를 '버킷(bucket)'이라고 한다. 이제부터는 해시 테이블의 요소를 버킷이라고 하겠다.
충돌
이어서 위 해시 테이블에 새로운 값인 18을 추가해 보자. 18을 13으로 나눈 나머지값, 즉 해시값은 5가된다. 따라서 버킷 a[5]은 이미 채워져있다.
이 경우에서 볼 수 있듯 키값과 해시값의 대응 관계는 반드시 1:1이 아니다.
이렇게 저장할 버킷이 중복되는 현상을 '충돌(conllision)'이라고 한다.
그러므로 해시 함수는 가능한 해시값이 치우치지 않도록 고르게 분포된 값을 만들도록 해야 한다.

해시와 해시 함수 알아보기
만약 충돌이 전혀 발생하지 않는다면, 해시 함수로 인덱스를 구하는 것만으로 검색, 추가, 삭제가 거의 완료되므로 시간 복잡도는 언제나 O(1)이 된다.
이런 방식을 지향하기 위해 해시 테이블을 크게하면 충돌 발생을 크게 억지할 수 있으나, 해시 테이블의 크기만큼 메모리를 쓸데없이 많이 차지하게 된다. 즉, ''시간과 공간의 절충(trade-off)' 문제가 상시 존재한다.충돌을 피하기 위해서는 해시 함수가 해시 테이블 용량 이하의 정수를 되도록 한쪽으로 치우치지 않게 만들어 내야 한다. 그래서 해시 테이블의 용량은 '소수'가 좋다고 알려져 있다.
키값이 정수가 아닌경우에는 해시값을 구할 떄 좀더 신경을 써서 방법을 모색해야 한다. 예를들면 실수 키값에 대해 비트 연산을 한다거나, 문자열 키값에 대해 각 문자 코드에 곱셈과 덧셈을 하는 방법으로 해시 함수를 만든다.
충돌 대처법
충돌이 발생할 때 다음 2가지 방법을 대처할 수 있다.
- 체인법 : 해시값이 같은 요소를 연결 리스트로 관리한다.
- 오픈 주소법: 빈 버킷을 찾을 때까지 해시를 반복한다.
체인법
체인법(chaining)은 해시값이 같은 데이터를 사슬(chain) 모양의 연결 리스트로 연결하는 방법으로, 오픈 해시법(open hashing)이라고도 한다.
연결 리스트(Linked List)를 모른다면 관련 글을 읽고오자.
해시값이 같은 데이터를 저장
체인법은 해시값이 같은 데이터를 사슬 모양의 연결 리스트로 연결한다. 배열(해시 테이블)의 각 버킷에 저장하는 값은 그 인덱스를 해시값으로 하는 연결 리스트의 첫 번째 노드에 대한 참조이다.
예를 들어 아래 그림에서 69와 17의 해시값이 모두 4라고 하자, 이 경우 이들을 연결하는 연결 리스트의 첫 번째 노드(69)에 대한 참조를 C[4]에 저장한다. 또, 데이터가 하나도 없는 버킷값은 null 참조로 둔다.
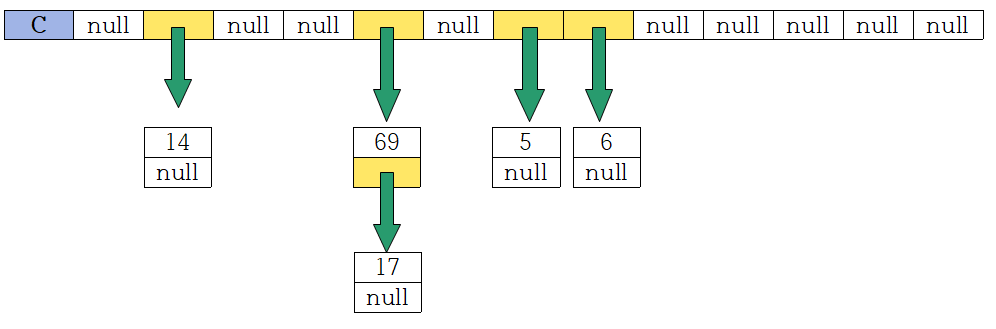
이렇게 사슬모양으로 연결하는것이 바로 체인법 혹은 오픈 해시법이라고 한다.
위 그림에서 {(69,머리노드) -- (17,꼬리노드)}는 한개의 연결 리스트이며, C[4]에는 해당 리스트의 머리노드(값69)를 참조할 주소가 저장되고 머리노드는 다음 노드로 꼬리노드(값17)를 참조한다.
똑같이 {(14)}도 한개의 연결 리스트이고, C[1]에 머리노드 14를 참조시키나, 14는 머리노드이자 꼬리노드이기에 다음 노드에 대한 참조가 null임을 볼 수 있다.
오픈 주소법
또 다른 해시법인 오픈 주소법(open addressing)은 충돌 발생시 재해시(rehashing)를 수행하여 비어 있는 버킷을 찾아내는 방법으로, 닫힌 해시법(closed hashing)이라고도 한다.
요소 삽입

해시 테이블 A에 새로운 값인 18을 넣으려고 했을때, 충돌이 발생했다 오픈 주소법은 이러한 상황에서 재해시를 한다. 재해시 할 때 해시 메서드는 자유롭게 결정할 수 있다. 여기서는 키값에 1을더하고 다시 13으로 나눈 나머지를 재해시 함수로 사용했다.

위에서 지정한 재해시 함수대로 (18 + 1) % 13을 한 결과 재해시 값으로 6이 나왔지만 이미 해당 버킷에는 값이 있기에 또 재해시 한다.

다시 재해시하여 (19 + 1) % 13을 한 결과 재해시 값으로 7이 나왔고 해당 버킷에 18을 삽입한다.
이러한 과정을 거쳐 충돌 문제를 해결하는게 '오픈 주소법'이다.
요소 삭제
이제 인덱스가 5인 값을 삭제하는 과정을 살펴보자. A[5]버킷을 비우기만 하면 될 것 같지만, 18을 다시 검색하면 18은 재해시로 인해 A[7]에 가 있지만 18의 버킷위치를 검색하는 과정은 이를 알 수 없기 때문에, A[5]위치를 조사하고 해당 버킷이 비어있음을 알리고 끝난다 따라서 각 버킷에 다음 속성 중 하나를 부여한다.
- 데이터 저장
- 비어 있음 속성값 (-)
- 삭제 마침 속성값 (★)
자, 버킷이 한번도 채워진적 없이 비워져 있다면 '-'로, 있었다가 삭제됐으면 '★'로 표기한다면 아래와 같은 해시 테이블 그림이 나온다.

A[0], A[2]등은 한번도 채워지지 않은 '-'로 표기했고,
A[5]의 경우 원래 무언가가 있다가 없어졌기에 '★'로 표기했다.
요소 검색
이 상태에서 값 15를 검색해보자, 15 % 13은 2로, A[2]는 현재 '-'이다. 따라서 해당 버킷에는 아무런 값도 들어온 적이 없어서 검색 실패다. 이번엔 18을 검색해보자.
위 그림에서 18은 원래 A[5]버킷에 존재해야 하지만, 재해시로 인해 A[7]까지 밀렸다.
따라서 검색 로직은 A[5]버킷을 조사하지만 여기에는 값이 없고 대신 값이 있었다는 표시인 '★'이 있는것을 확인하기에 재해시를 통해 검색을 이어나간다.
A[6]에는 값이 들어있으므로 다시한번 재해시를 통해 검색을 이어나가고, A[7]에 도달해서 값 18을 찾아낸다.
예제 코드들
체인법 예제 코드
public class ChainHash<K,V> {
// 해시를 구성하는 노드
class Node<K,V> {
private K key;
private V data;
private Node<K,V> next;
Node(K key, V data, Node<K,V> next) {
this.key = key;
this.data = data;
this.next = next;
}
K getKey() {
return key;
}
V getValue() {
return data;
}
@Override
public int hashCode() {
return key.hashCode();
}
}
private int size; // 해시 테이블의 크기
private Node<K,V>[] table; // 해시 테이블
// 생성자
public ChainHash(int capacity) {
try {
table = new Node[capacity];
this.size = capacity;
} catch (OutOfMemoryError e) {
this.size = 0;
System.out.println("메모리 초과 오류 발생!");
}
}
// 해시값을 구함
public int hashValue(Object key) {
return key.hashCode() % size;
}
// 키값이 key인 요소를 검색해서 해당 노드의 데이터를 반환
public V search(K key) {
int hash = hashValue(key); // 검색할 데이터의 해시값
Node<K,V> p = table[hash]; // 선택 노드
while (p != null) {
if (p.getKey().equals(key))
return p.getValue(); // 검색 성공
p = p.next; // 다음 노드 선택
}
return null; // 검색 실패
}
// 키값이 key이고 데이터가 data인 요소를 추가
public int add(K key, V data) {
int hash = hashValue(key); // 추가할 데이터의 해시값
Node<K,V> p = table[hash]; // 선택 노드
while (p != null) {
if (p.getKey().equals(key)) // 이 키값은 이미 등록됨
return 1;
p = p.next; // 다음 노드를 선택
}
Node<K,V> temp = new Node<K,V>(key, data, table[hash]);
table[hash] = temp; // 노드를 삽입
return 0;
}
// 키값이 key인 요소를 삭제
public int remove(K key) {
int hash = hashValue(key); // 삭제할 데이터의 해시값
Node<K,V> p = table[hash]; // 선택 노드
Node<K,V> pp = null; // 바로 앞의 선택 노드
while (p != null) {
if (p.getKey().equals(key)) { // 찾으면
if (pp == null)
table[hash] = p.next;
else
pp.next = p.next;
return 0;
}
pp = p;
p = p.next; // 다음 노드를 선택
}
return 1; // 그 키값은 없음
}
// 해시 테이블을 덤프
public void dump() {
for (int i = 0; i < size; i++) {
Node<K,V> p = table[i];
System.out.printf("%02d ", i);
while (p != null) {
System.out.printf("→ %s (%s) ", p.getKey(), p.getValue());
p = p.next;
}
System.out.println();
}
}
}체인법으로 해시 테이블을 만들어 사용하는 코드이다. 각각의 필드에 대한 설명은 아래를 참고하자.
노드 클래스 Node<K,V>
체인법이기 때문에 각각의 버킷은 연결리스트의 Node<K,V>로 구성돼 있다.
위의 내부 클래스 Node<K,V>{}가 그것이다. Node클래스는 내부에서 Object클래스의 메서드인 hashCode()를 오버라이드했다.
@Override를 붙히는 습관을 들이자, 해당 어노테이션이 붙은 메서드는 상속받은 메서드를 오버라이드 했다는 뜻으로, 만약 내가 hashhCode()처럼 오타가 섞였을 경우 이를 감지해서 컴파일 타임에 잡아낸다.
hasshCode()는 모든 클래스의 조상 Object에는 없는 메서드이다. 따라서 @Override 어노테이션이 컴파일 타임에 잡아내어 우리가 수정하면, 실행중 오류가 나지 않는다! (최악의 경우가 배포 후 실행 했는데 오류..)
각 노드는 일반적인 연결 리스트(Linked List)와 구현 방식이 같다.
해시 클래스 ChainHash<K,V>
- 변수 size : 해시 테이블의 용량(배열 table의 요솟수)
- 변수 table : 해시 테이블을 저장하는 배열
- 생성자 ChainHash(capacity);
생성자인 ChainHash()가 있다. capacity라는 용량 매개변수를 받아 해당 capcity의 값을 토대로 해시 테이블의 최대 크기를 지정하고, table변수에 Node[capacity] 배열을 참조시킨다.
따라서 ChainHash(13) 으로 인스턴스를 만들면, 위와같은 해시 테이블이 만들어진다.
- 메서드 hashValue(Object key)
매개변수로 받은 Object타입의 key의 hashCode()메서드를 실행하고, 리턴값을 size변수로 나누어 이를 해시값으로 지정한다.
key의 타입이 Object이기 때문에, 위의 Node<K,V>에서 오버라이드한 hashCode()메서드와는 아무 상관이 없이 Object클래스에 정의된 hashCode()가 실행된다.
- 메서드 search(K key)
매개변수로 받은 K타입의 key가 해시 테이블에 있는지 검색한다.
바로 위 메서드의 hashValue에 key를 인자로 건내어 받은 해시값을 통해 해당 key가 있어야할 해시 테이블 위치를 찾는다.
해시 테이블의 크기가 13이고, 33을 검색한다고 하면 33의 해시값은 7이다. table[7]의 위치에 있는 연결 리스트의 노드들을 조사하고 33이 key값으로 존재한다면 검색 성공이다.
- 해시 함수로 키값을 해시값으로 변환. 33 -> 7(해시값)
- 해시값을 인덱스로 하는 버킷을 선택. a[7]
- 선택된 버킷의 연결 리스트를 선형 검색함. 연결 리스트의 노드들 중 key값이 33인 노드가 있으면 검색 성공, 실패시 null을 반환
- 메서드 add(K key, V data)
해시 테이블에 키값이 key이고 데이터가 data인 요소를 삽입하는 메서드
(참고로 이런 데이터형의 대표는 Collection의 Map인터페이스임.)
매개변수로 받은 key를 hashValue()메서드에 넣어 해시값을 알아낸다.
table[hash]에 노드가 존재하는지, 존재한다면 중복되는 키값은 아닌지 확인한다.
해당 table[hash]의 머리 노드에 new Node(K key,V data, table[hash])를 삽입.
- 해시 함수로 키값을 해시값으로 변환한다. 46 → 7(해시값)
- 해시값을 인덱스로 하는 버킷을 선택한다. a[7]
- 선택한 버킷의 연결 리스트를 선형 검색한다. 키값과 같은 값을 찾으면 삽입실패한다. 끝까지 스캔하여 키값을 찾지 못하면 리스트의 맨 앞에 노드를 삽입한다. a[7] → 46 → 20 → 33
- 메서드 remove(K key)
hashValue()메서드를 통해 key의 해시값을 알아냄. 13이라면 해시값은 0
해시 테이블에서 얻은 해시값을 인덱스로하여 접근 a[0]
버킷a[0]의 노드들 중 key값이 13인 요소 있으면 삭제, 없으면 삭제 실패
- 메서드 dump()
해시 테이블의 내용을 통째로 출력한다. 해시 테이블의 모든 요소 table[0] ~ table[size - 1]까지에 대하여 다음에 오는 노드를 차례로 따라가며 키값과 데이터를 출력하는 작업을 반복한다.
오픈 주소법 예제 코드
public class OpenHash<K,V> {
// 버킷의 상태
enum Status {OCCUPIED, EMPTY, DELETED}; // 상태 열거형(데이터 저장, 비어있음, 삭제 마침)
// 버킷
static class Bucket<K,V> {
private K key; // 키값
private V data; // 데이터
private Status stat; // 상태
// 생성자
Bucket() {
stat = Status.EMPTY; // 버킷이 비어있음
}
// 모든 필드에 값을 설정
void set(K key, V data, Status stat) {
this.key = key;
this.data = data;
this.stat = stat;
}
// 상태를 설정
void setStat(Status stat) {
this.stat = stat;
}
// 키값을 반환
K getKey() {
return key;
}
// 데이터를 반환
V getValue() {
return data;
}
// 키의 해시값을 반환
public int hashCode() {
return key.hashCode();
}
}
private int size;
private Bucket<K,V>[] table;
// 생성자
public OpenHash(int size) {
try {
table = new Bucket[size];
for (int i = 0; i < size; i++)
table[i] = new Bucket<K,V>();
this.size = size;
} catch (OutOfMemoryError e) {
this.size = 0;
}
}
// 해시값을 구함
public int hashValue(Object key) {
return key.hashCode() % size;
}
// 재해시 값을 구함
public int rehashValue(int hash) {
return (hash + 1) % size;
}
// 키값이 key인 버킷을 검색
private Bucket<K,V> searchNode(K key) {
int hash = hashValue(key); // 검색할 데이터의 해시값
Bucket<K,V> p = table[hash]; // 선택한 버킷
for (int i = 0; p.stat != Status.EMPTY && i < size; i++) {
if (p.stat == Status.OCCUPIED && p.getKey().equals(key))
return p;
hash = rehashValue(hash); // 재해시
p = table[hash];
}
return null; // 재해시 하고도 못찾음
}
// 키값이 key인 요소를 검색하여 데이터만 반환
public V search(K key) {
Bucket<K,V> p = searchNode(key);
if (p != null)
return p.getValue();
else
return null; // 검색 실패
}
// 키값이 key이고 데이터가 data인 요소를 추가
public int add(K key, V data) {
if (search(key) != null)
return 1; // 중복된 키값임
int hash = hashValue(key); // 추가할 데이터의 해시값
Bucket<K,V> p = table[hash]; // 선택한 버킷
for (int i = 0; i < size; i++) {
if (p.stat == Status.EMPTY || p.stat == Status.DELETED) {
p.set(key, data, Status.OCCUPIED);
return 0;
}
hash = rehashValue(hash); // 저장시 겹치면 재해시
p = table[hash];
}
return 2; // 해시 테이블이 가득 참
}
// 키값이 key인 요소를 삭제
public int remove(K key) {
Bucket<K,V> p = searchNode(key); // 선택한 버킷
if (p == null)
return 1; // 이 키값은 없음
p.setStat(Status.DELETED);
return 0;
}
// 해시 테이블을 덤프
public void dump() {
for (int i = 0; i < size; i++) {
System.out.printf("%02d ", i);
switch (table[i].stat) {
case OCCUPIED:
System.out.printf("%s (%s)\n", table[i].getKey(), table[i].getValue());
break;
case EMPTY:
System.out.println("-- 비어 있음 --"); break;
case DELETED:
System.out.println("-- 삭제 마침 --"); break;
}
}
}
}위의 체인법의 코드와 틀은 다르지 않으니 설명은 생략.
