
⭐️ 카프카의 탄생 배경 (카프카는 왜 필요해요?)
우선 다들 MSA라는 단어들은 익히 들어봤을겁니다. 일반적인 기업들에서 서비스의 규모가 커짐에 따라서 서비스를 쪼개서 운영할 필요가 생겼고, 클라우드 시스템의 발전에 의해서 MSA라는 단어는 우리나라의 IT기업들에서 최근 엄청 핫한 키워드가 되었습니다.
MSA는 Micro Service Architecture 의 줄임말으로, 말 뜻에서 직관적으로 알수있듯이, 기존의 서비스들을 잘게 쪼개서 서비스를 운영하는 기법 입니다.
그런데 서비스를 잘게 쪼개면 다양한 이슈들이 발생합니다. 대표적으로는 아래의 이슈들이 있을겁니다.
- 서비스를 잘게 쪼개면서 서버 간에 상호작용이 많아진다. 이는 큰 오버헤드를 불러온다.
- 서비스를 잘게 쪼갬과 동시에 데이터 파이프라인의 복잡도가 증가한다. 이는 해당 기업에 커다란 기술부채 (Technical Debt) 를 불러왔으며, 이러한 기술부채는 유지보수 및 운영에 커다란 악영향을 끼친다.
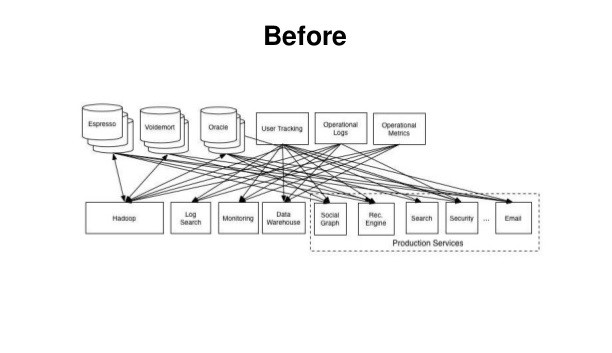
그림 보기만해도 어질어질하다 그죠?
서비스의 규모가 거대해짐에 따라서 위의 그림과 같이 데이터 파이프라인 의 양상이 매우 복잡해지는 것을 확인할 수 있습니다.
이를 해결하기 위해서 링크드인의 데이터팀에서는 어떻게든 데이터 파이프라인의 파편화 현상을 개선하려고 하였으나, 기존의 메시징 플랫폼 등으로는 도저히 개선이 되지 않았습니다.
결국에 링크드인 데이터팀은 기존의 메시징 플랫폼을 이용하여 데이터 파이프라인의 파편화 현상을 개선하는 것이 아니라, 차라리 새로운 시스템을 개발하여 해결을 시도했습니다. 이 과정에서 나오게된 결과물이 아파치 카프카(Apache kafka) 입니다.
이름에는 별 뜻이 없다고해요. 그냥 대학 교양에서 들어본 학자 이름이 멋지길래 거기서 따왔다네요...
아파치 카프카는 자바와 스칼라 언어를 기반으로 제작되었습니다. 그리고 아파치 카프카는 데이터 파이프라인을 파편화시키지 않고 데이터를 중앙 집중화 시키는 전략을 채택하였는데요, 결론적으로 카프카는 대용량 데이터를 수집, 처리하고 사용자들이 데이터를 실시간 스트림으로 소비할 수 있도록 잘 동작하였습니다.
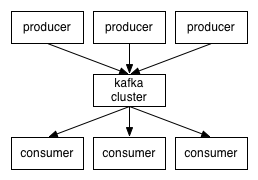
🤔 카프카를 쓰면 뭐가 좋아요?
1️⃣ 소스 어플리케이션과 타겟 어플리케이션 간의 의존도를 낮춰주었다. (Dependency에 있어서 둘 간의 Decoupling이 발생하였다)
말 그대로입니다. 소스 어플리케이션과 타겟 어플리케이션 간에 의존도가 낮아졌습니다. 이는 어쩌면 당연한 말일수도 있습니다.
객체지향에서도 DIP에 따르면, 객체의 추상화를 통해서 의존 관계를 약화시킬 수 있다 라는 말이 존재합니다. 여기서도 마찬가지일겁니다. 소스 어플리케이션과 다겟 어플리케이션 사이의 데이터 파이프라인을 카프카가 추상화시키는 역할을 하기 때문에, 둘 간의 의존도는 낮아질 수 밖에 없습니다.
따라서, 둘 간의 데이터를 주고받을 때 있어서 신경쓸 요소들이 줄어들었다고 보시면 되겠습니다.
2️⃣ 카프카는 높은 처리량을 가지고 있기 때문에 실시간 대량의 로그데이터를 처리하는데 적합하다.
카프카의 경우 프로듀서로부터 브로커를 향해 데이커를 송신할 때, 혹은 컨슈머가 브로커로부터 데이터를 수신받을 때 데이터가 배치의 형태로 묶여서 왔다갔다거리는 특징을 가지고 있습니다.
아무래도 데이터가 하나하나 단위로 파편화 된 상태로 트랜잭션이 맺어지는 것과는 Batch의 형태로 하나로 데이터가 묶여서 트랜잭션이 맺어지면 아무래도 네트워킹에 있어서 비용이 많이 줄어들게 됩니다.
또한, Batch로 처리하면 데이터의 처리가 빠르기 때문에 대용량의 로그데이터를 처리하는데 있어서 강점을 가진다고 볼 수 있겠습니다.
3️⃣ 확장성(Scalability)가 높습니다.
카프카는 클러스터 단위로 묶어서 관리를 할 수 있다는 특징이 있습니다. 따라서 서비스에 트래픽이 몰릴 때는 Cluster의 Node 개수를 늘려서 수평 확장을 하고, 트래픽이 적어질 때는 Cluster의 Node 개수를 줄여버림으로써 유연하게 트래픽을 처리할 수 있습니다.
4️⃣ 영속성을 지니고 있습니다. 따라서 Kafka Cluster에 장애가 발생하더라도 장애 복구가 쉽습니다.
Kafka의 경우 데이터를 Topic에 담아서 저장을 하는 형태로 데이터를 보관하는데요, Kafka에서는 데이터를 저장하기 위해서 OS 레벨에서의 파일시스템을 이용합니다.
다들 OS 수업을 들어보셨다면 아시겠지만, 운영체제에서는 파일의 입출력 성능을 향상시키기 위해서 Page Cache 영역을 메모리에 따로 생성하여 page 단위로 메모리를 할당시킵니다. 운영체제는 페이지 캐시 메모리 영역을 사용해서 한번 읽은 파일 내용은 메모리에 임시 저장을 해두었다가 나중에 다시 사용하는 방식을 채택합니다.
Kafka는 바로 OS의 이러한 시스템을 이용하여 데이터를 저장하는데요, 이러한 특성 때문에 데이터의 처리 속도가 높은 특성을 지니고있으며, 또한 카프카 클러스터에 일시적인 장애가 발생하더라도 프로세스를 재시작해서 데이터를 다시 처리할 수 있는 것입니다.
🔥 카프카의 과거와 미래, 그리고 카프카를 어떻게 사용할 것인가?
우선 카프카가 걸어온 길부터 살펴보겠습니다.
1️⃣ 람다 아키텍처 (Lambda Architecture)
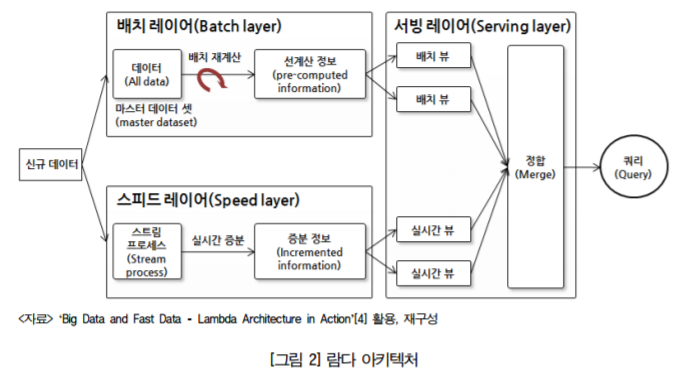
우선 람다 아키텍처부터 보겠습니다.
람다 아키텍처의 경우 데이터를 일괄처리하는 Batch Layer, 실시간성을 가지고 데이터를 처리하는(Processing Real-time data) Speed Layer, 그리고 타겟 어플리케이션에 데이터를 뿌려주는 Serving Layer 로 구성이 되어있습니다.
배치레이어에서는 일정한 지연을 가지고 데이터를 일괄처리를 수행하고, 스피드 레이어는 배치 데이터에 비해서 낮은 지연도를 가지고 실시간성 데이터를 처리하는 역할 수행합니다. 그리고 이렇게 처리된 데이터를 서빙 레이어로 보내서 타겟 어플리케이션을 향해 데이터를 제공하는 기능을 수행합니다.
여기서 Kafka는 Speed Layer에 위치할겁니다. 아무래도 높은 처리속도를 가지고있기 때문이겠죠?
그런데 람다 아키텍처는 뼈아픈 단점을 하나 가지고 있습니다. 바로, Batch Layer와 Speed Layer로 분리된 것 자체가 단점으로 돌아옵니다.
이유는 아래와 같습니다.
- Batch Layer에서도 데이터를 가공, 처리, 분석을 하고, Speed Layer에서도 데이터를 가공, 처리, 분석을 수행한다. 하는 일은 비슷한데, Layer가 2개로 분리되어있기 때문에 비효율적이다. 단지 차이점은, 실시간성이냐, 아니면 묶음 처리를 하느냐 뿐이다
- 만일, 실시간성 데이터와 배치데이터를 엮어서 데이터를 처리해야할 때가 제일 골치가 아프다. Batch Layer와 Speed Layer가 명확하게 구분이 되기 위해서는 두 개의 레이어에서 각각 처리되는 데이터는 독립적 이어야 의미가 있는데, 두 데이터를 엮어서 처리하려고 하면 중간에 레이어가 하나 더 끼어들거나, 혹은 데이터 파이프라인이 지저분해지는 문제를 불러온다.
따라서 현 컨플루언트 CEO는 새로운 형태의 아키텍처를 제안했는데, 그것이 바로 카파 아키텍처(Kappa Architecture) 입니다.
2️⃣ 카파 아키텍처 (Kappa Architecture)
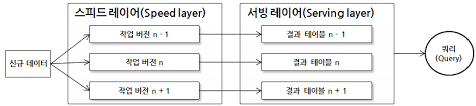
카파 아키텍처에서는 람다 아키텍처와 다르게 Batch Layer가 사라진 모습을 확인할 수 있습니다. 정확히 말하면, 기존의 Batch Layer는 Speed Layer에 흡수되었다 라고 말하는게 적절할 것 같습니다.
카파 아키텍처는 기존의 람다 아키텍처에서 단점으로 꼽혔던 로직의 파편화에 대한 이슈를 해소해주었습니다. 그로 인해 개발자, 그리고 엔지니어들은 서버의 운영, 그리고 개발에 있어서 효율성을 가져갈 수 있게 되었습니다.
그런데 컴퓨터 공학에서는 이런 명언이 있습니다.
There's no silver bullet.
위의 뜻은, 컴퓨터 공학에 있어서 만능 열쇠 라는 것은 존재하지 않는다는 뜻입니다. 왜 없어 ㅠㅠㅠ
따라서 카파 아키텍처도 명확한 단점은 존재하는데요, Batch Layer가 존재하지 않기 때문에 프로듀서에서 던져주는 모든 데이터를 실시간 스트림 처리를 해야한다 라는데 있습니다.
하지만 카프카는 이러한 단점도 어느 정도 해결을 하는 모습을 보여줍니다. 바로 모든 데이터를 데이터로 바라보는게 아니라, 데이터도 하나의 log라고 바라보는데서 단점을 해결했습니다
카프카는 모든 데이터를 Topic의 Partition에 나눠서 저장을 합니다. 그런데 Partition에 저장된 데이터를 까보면, 마지막으로 읽은 시점 등과 같이 저장이 되는 모습을 확인해볼수 있습니다. 이러한 특징을 이용하면 배치 데이터의 처리 기록을 시간 순서대로 마킹을 함으로써 실시간 스트림으로 데이터가 처리가 되더라도 배치 데이터를 표현할 수 있게되는 것입니다.
그런데 컨플루언트 CEO는 여기서 멈추지 않았습니다.
3️⃣ 데이터 레이크 아키텍처 (Data Lake Architecture)
직역하자면, 데이터의 호수 아키텍처입니다.
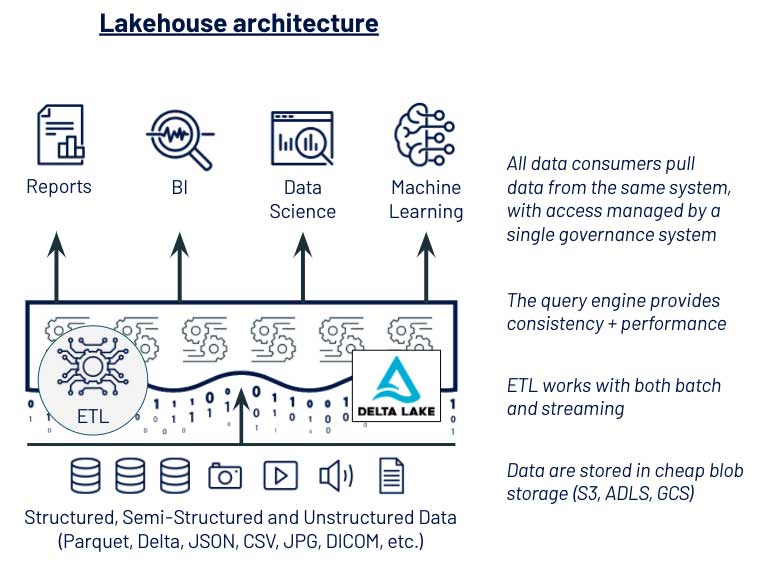
위의 그림은 Data LakeHouse Architecture에 관한 사진인데요, 여기서는 이전의 kappa Architecture와는 다르게 Serving Layer가 존재하지 않는 모습을 확인할 수 있습니다.
이는 고전적인 Data Warehouse를 버리겠다는 소리와 같은데요, 쉽게 말하자면 기존에 데이터베이스를 주렁주렁 다는 아키텍처에서 탈피하겠다 라는 뜻으로 통하기도 합니다.
이를 통해서 Speed Layer는 단일 진실 공급원으로써 역할을 수행하기 때문에, 굳이 기존의 Serving Layer의 저장소(하둡, S3, etc...)에 카프카에서 이미 처리된 데이터를 따로 저장할 필요가 없어지게됩니다.
그런데 이 또한 단점은 명백하게 존재합니다. 단점은 아래와 같습니다.
- Kafka는 데이터를 저장하기 위해서 OS 레벨의 File System을 활용하게 되는데, 이는 브로커의 메모리 자원, 스토리지 자원을 사용해버리기 때문에 비용이 상대적으로 비싸다. 그리고 Kafka 내부에 존재하는 Cold Data에 대해서도 이러한 브로커의 비싼 리소스를 과연 사용해야하는가?
그래서 아직까지는 완벽한 Data Lake를 사용하지 않고, 대신에 Speed Layer에다가 추가적으로 S3와 같은 값싼 오브젝트 스토리지를 붙여서 보조적으로 사용하고 있는것으로 알고있습니다. (현재 아마존의 MKS 서비스를 이용하면 Cold Data를 S3에 연동해서 보관할 수 있도록 기능을 지원하고 있습니다)
🌲 글을 정리하며
다음 포스트에서는 카프카를 ec2에 설치해서 Kafka CLI를 실습해보는 것에 관해서 다뤄볼 예정입니다.
다음 포스트에서 뵙겠습니다!
