
🤗 이전까지 해본것들 회고
이전 포스트까지는 Kafka를 CLI로 제어하는 것에 대해서 다뤄보았습니다. CLI로 다뤄본 내용은 크게 아래의 것들입니다.
- Kafka-console-producer
- Kafka-console-consumer
- 카프카 속성 제어 (dynamic 속성들, 정적인 속성들)
그러나 저희가 원하는 것은, Server Application에서 Kafka를 이용해서 이벤트를 발행하고, 구독을 함으로써 효율적인 아키텍처를 구성하는 것일겁니다. 따라서 지금의 포스트에서는 코틀린을 이용해서 Kafka Client중 Producer를 다뤄보는 것을 다뤄볼겁니다.
🔨 우선 실습 환경부터 알려드리겠습니다.
우선 제가 하고있는 내용들을 따라하기 위해서는 이것만 있으면됩니다.
- Kafka 2.5.0이 설치된 EC2
- 로컬에 설치된 Kafka 2.5.0
- IntelliJ IDEA ULTIMATE -> (물론 Community version도 Gradle 사용은 가능해요)
우선 Gradle 기반으로 프로젝트를 만들고 root project의 build.gradle.kts를 아래와같이 수정합니다.
👉 build.gradle.kts
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
buildscript {
repositories {
mavenCentral()
}
}
plugins {
kotlin("jvm") version "1.5.10" apply false // 저는 1.5.0 버전으로 올렸지만, 더 높여도 상관없어요
}
allprojects {
group = "team.brian" // 이건 원하는대로 수정하세요
version = "1.0.0"
tasks.withType<KotlinCompile> {
kotlinOptions {
freeCompilerArgs = listOf("-Xjsr305=strict")
jvmTarget = "11"
}
}
tasks.withType<Test> {
useJUnitPlatform()
}
}
subprojects {
repositories {
mavenCentral()
}
}그리고 하위에 모듈 하나를 생성해서 생성된 모듈의 build.gradle.kts를 아래와같이 수정해줍니다.
👉 build.gradle.kts
plugins {
kotlin("jvm")
}
dependencies {
implementation(kotlin("stdlib-jdk8"))
implementation(kotlin("reflect"))
implementation("org.apache.kafka:kafka-clients:2.5.0")
implementation("org.slf4j:slf4j-simple:1.7.30")
}
tasks.register("prepareKotlinBuildScriptModel") {}위의 build.gradle.kts 작성을 통해서 저희는 kafka를 실습할 수 있게되었습니다.
🔥 우선 가장 간단한 Producer 실습부터 해보겠습니다
SimpleProducer.kt를 생성해서 아래와 같이 따라쳐봅시다.
👉 SimpleProducer.kt
class SimpleProducer {
// logger 선언
private val logger = LoggerFactory.getLogger(this::class.java)
// 저장하고자하는 토픽의 이름을 지정
private val TOPIC_NAME = "test"
// 카프카 브로커가 올라가있는 host의 이름과 port 번호를 기입
private val BOOTSTRAP_SERVER = KafkaInfo.BOOTSTRAP_SERVER
fun testSimpleProducer() {
val configs = Properties()
configs[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVER
// 직렬화/역직력화 정책을 카프카 라이브러리의 StringSerializer로 선택한다
configs[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
configs[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
// properties를 kafkaProducer의 파라미터로 전달하여 producer 인스턴스를 생성한다.
val producer = KafkaProducer<String, String>(configs)
val messageValue = "testMessage"
// 메시지 키가 선언되지 않은 상태로 메시지 값만 할당하여 record를 생성하였다.
// ProducerRecord의 제네릭 2개는 각각 key/value의 타입을 의미한다
val record = ProducerRecord<String, String>(TOPIC_NAME, messageValue)
// procuder.send()는 즉각적으로 전송하는게 아니라 배치 타입으로 전송을한다.
producer.send(record)
logger.info("$record")
// flush() 메소드를 통해서 프로듀서 내부 버퍼가 가지고있던 모든 레코드 배치를 브로커로 전달한다
producer.flush()
// producer instance의 모든 리소스를 안전하게 종료시킨다
producer.close()
}
}위의 예제는 test라는 이름을 가지는 topic에다가 partition을 지정하지 않은 상태로 testMessage라는 메시지 키값이 없는 레코드를 날리는 예제입니다.
여기서 중요하게 짚고넘어갈 부분은, producer가 어느 시점에 record를 카프카로 넘기느냐입니다.
저번에도 설명드렸다시피 Kafka는 Batch type으로 데이터를 프로세싱하기 때문에 처리 속도가 빠르다고 한 바 있습니다. 그렇기 때문에 별 특별한 설정이 없이는 Batch로 묶여서 record가 처리될겁니다.
이제 Producer Application이 정확하게 어떤 순서로 record를 카프카로 넘기는지 설명을 드리도록 하겠습니다.
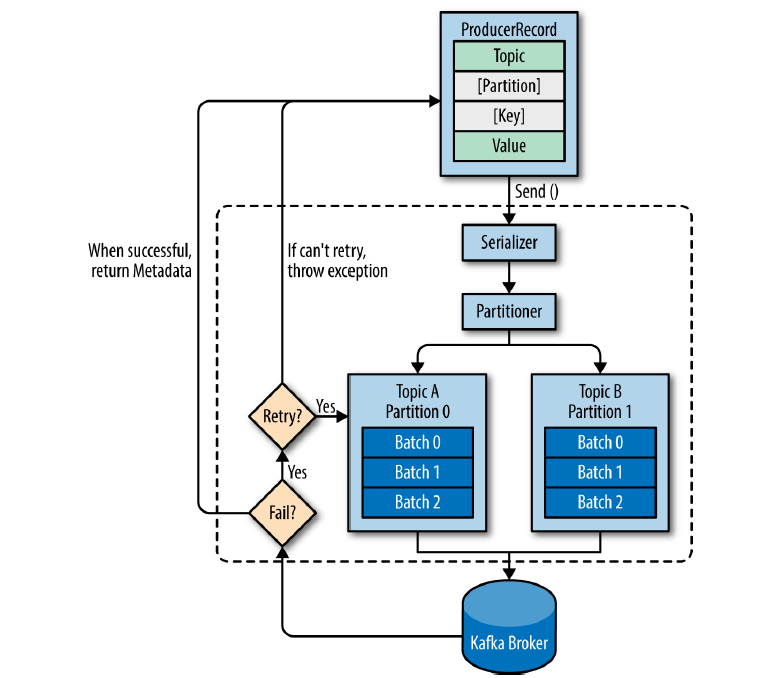
- send()가 호출이 되면 Serialize 과정을 거친 다음에 Partitioner에서 토픽의 어느 파티션으로 저장이 될지 지정을한다. 이 때, Partitioner를 커스텀하지 않았다면 Round-robin 방식으로 지정될것이다.
- 저장될 Partition의 위치가 결정되었다면 Accumulator에서 record가 임시 저장된다.
- producer가 flush()를 호출하면 Accumulator 버퍼에 쌓여있던 모든 배치 레코드들이 Sender thread를 거쳐서 Kafka Broker로 전송이된다.
🥰 [알아두면 좋은 소소한 팁]
Kafka Producer는 압축 옵션을 통해서 Broker로 Record를 전송할 때 압축 방식을 정할 수 있습니다. 그러나 압축을 시행하면 네트워크의 처리량 관점에서 이득을 볼 수 있다는것은 명백한 장점이지만, 압축 과정에서 Producer의 resource를 사용하게되고, 압축 해제 과정에서 Consumer측에서 resource를 소모하게됩니다. 압축 정책에는 명백한 trade-off가 존재함을 알아두셨으면 좋겠습니다!
🔥 이제는 Message Key값을 할당해서 record를 날려봅시다
방법은 간단합니다. record를 선언할 때 ProducerRecord의 파라미터로 (TOPIC_NAME, KEY, VALUE) 순서로 넣어주기만하면 끝입니다.
👉 수정된 부분
val record = ProducerRecord<String, String>(TOPIC_NAME, "Apple", "Macbook")그리고 CLI를 통해서 확인을 해주면 되겠습니다.
👉 Command
bin/kafka-console-consumer.sh --bootstrap-server [my-kafka-host]:9092 --topic test --property print.key=true \
--property key.separator="-" --from-beginning👉 결과
null-testMessage
Apple-Macbook다음으로는 Partitioner를 이용해서 특정 message key를 가진 경우 특정 Partition으로 할당하는 방법에 대해서 알아봅시다.
🔥 Partitioner를 커스텀해봅시다
일단 저번에 설명드렸던 것을 회고해봅시다. 특정한 Record가 Kafka Broker로 날아가면 Kafka Broker는 해당 메세지의 키값을 보고 키값의 해시값을 바탕으로 할당되는 파티션을 결정한다고 알고있습니다. 그래서 파티션이 늘어나게된다면 기존의 메세지 키값이 이전에 들어가던 파티션으로 다시 들어간다는 보장을 못한다고 설명을 드린 바도 있었습니다.
이제 Producer Application에서 Partitioner를 커스텀해서 원하는 메세지 키 값이 원하는 파티션으로 날아가도록 해보겠습니다.
우선 가정하기를, test라는 토픽으로 날아가는 모든 record는 key값을 무조건 가지고 있도록 만들겁니다. 이를 전제로 코드를 작성해봅시다.
👉 CustomPartitioner.kt
class CustomPartitioner: Partitioner {
override fun configure(configs: MutableMap<String, *>?) {
}
override fun close() {
}
/**
* 레코드를 기반으로 파티션을 정하는 로직을 정하는 메소드
* @return 주어진 레코드가 들어가는 파티션 번호
*/
override fun partition(
topic: String?,
key: Any?,
keyBytes: ByteArray?,
value: Any?,
valueBytes: ByteArray?,
cluster: Cluster?
): Int {
// 키 값이 존재하지 않는 레코드는 비 정상 레코드로 간주하고 에러를 뱉어낸다
requireNotNull(keyBytes) {
InvalidRecordException("Need message key!!")
}
// 메시지 키가 Apple인 경우 0을 반환시킨다. -> 파티션 0으로 보낸다
check((key as String).equals("Apple")) {
return 0
}
val partitions = cluster!!.partitionsForTopic(topic)
val numPartitions = partitions.size
// 그 외의 메시지 키는 메시지 키의 해쉬값을 기반으로 특정 파티션에 꽂히도록 설정한다
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions
}
}저희가 주목할 부분은 partition() 이라는 메소드입니다. 여기서 Key값에 따른 Partition 할당 정책을 구현합니다.
우선 requireNotNull이라는 구문을 통해서 Key가 Null인 경우를 잡아내서 예외 처리를 수행합니다. 그러면 Key가 Null이 아닌 경우만 예외 처리 없이 처리를 거칠겁니다.
여기서 key가 Apple과 일치한다면 0번 파티션으로, 그 외의 경우에는 기존의 정책을 따르도록 구현을 해두었습니다.
그리고 이렇게 정의한 partitioner는 configs로 등록만 하면 Custom된 Partitioner를 사용할 수 있습니다.
👉 CustomKeyValueProducer.kt
class CustomKeyValueProducer {
private val logger = LoggerFactory.getLogger(this::class.java)
private val TOPIC_NAME = "test"
private val BOOTSTRAP_SERVER = KafkaInfo.BOOTSTRAP_SERVER
fun testProducer(keyValue: String, messageValue: String) {
val configs = Properties()
configs[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVER
configs[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
configs[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
// configs에 Partition을 등록시킨다
configs[ProducerConfig.PARTITIONER_CLASS_CONFIG] = CustomPartitioner::class.java
val kafkaProducer = KafkaProducer<String, String>(configs)
val record = ProducerRecord<String, String>(TOPIC_NAME, keyValue, messageValue)
// producer.send()의 반환 형태는 RecordMetaData이다.
kafkaProducer.send(record)
kafkaProducer.flush()
kafkaProducer.close()
}
}여기서 저희는 record가 Kafka Broker로 잘 전송이 되었는지 확인을 하기 위해서는 분명히 CLI를 이용해서 테스트를 했어야했습니다. 그러나 Producer Application 측에서 레코드가 잘 전송되었는지 확인하는 방법은 크게 두 가지 방식이 있습니다.
- 동기처리를 통한 확인 -> send()를 통해 반환된 record의 metadata를 까본다
- 비동기처리를 통한 확인 -> Callback을 실체화시켜서 send() 파라미터로 싣기
그러나 각자의 장단점이 존재합니다.
1️⃣ 동기처리를 통한 전송 체크의 장단점
👉 장점
1. 전송 체크에 대해서 순서성이 확실하게 보장이된다.
👉 단점
1. Blocking이 되어있다. 다른 말로 말하면, 전송이 완료되고나서 전송이 완료되었는지 체크가 된다는 것이다. 이는 데이터 처리 속도를 저하시킨다.
2️⃣ 비동기처리를 통한 전송 체크의 장단점
👉 장점
1. Non-Blocking한 방식이기 때문에 데이터 처리 속도 측면에서 우월하다
👉 단점
1. Callback으로 구현이 되기 때문에 전송 체크 이후에 후속조치가 필요한 경우 Callback hell에 빠뜨릴 위험이 존재한다.
2. 만일 이전의 레코드가 전송 실패하고, 바로 다음의 레코드 전송이 성공하고, 이전 레코드의 재전송이 성공되었다면 레코드의 순서성이 박살난다.
Kotlin 언어의 경우 Coroutine이 언어 레벨에서 지원이 되며, 이는 비동기 처리에 있어서 코드 직렬화가 가능해지기 때문에 Callback을 엮어서 구현하여 Callback hell을 일으켜야했던 기존의 방식에서 벗어날 수 있습니다. 이러한 Kotlin Coroutine은 나중에 알려드리겠습니다!
나도 잘 모르니까 ㅠ
🌲 글을 마치며
지금까지 Kafka client의 Producer에 대해서 실습을 해보았는데요, 다음 포스트에서는 Consumer에 대해서 실습을 진행하겠습니다.
다음 포스트에서 뵙겠습니다!!
🔨 실습 코드가 위치한 Github repository
👉 실습 코드
