
🤔 Kotlin Coroutines를 포스팅하게 된 이유?
이번부터 코틀린 코루틴을 다루려고 합니다.
Backend에서는 이미 Spring Webflux와 Reactor라는 강력한 비동기 처리 라이브러리를 이미 지원하고 있습니다. 그러나 제가 Spring Webflux 대신에 Coroutine을 공부하려는 이유는 아래와 같습니다.
1️⃣ Webflux를 사용해서 코드를 작성하는 것보다 매우 직관적이다
우선 RxJava를 이용한 코드를 하나 소개하겠습니다.
fun onCreate() {
disposables += getNewsFromApi()
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.map {news -> news.sortedByDescending {
it.publishedAt
}
}.subscribe {sortedNews -> view.showNews(sortedNews)}
}위의 코드를 보시고 직관적으로 어떻게 데이터가 처리되고 있는지 감이 오지 않습니다. 물론 Callback을 이어 붙여서 코드를 작성하는 것보다는 훨씬 낫지만, 코드의 직관성이 매우 떨어지기 때문에 초반 러닝커브가 너무 높습니다.
RxJava로 작성된 코드를 Coroutine으로 전환해서 작성하면 아래와 같이 될겁니다.
val scope = CoroutineScope(Dispatchers.Main)
fun onCreate() {
scope.launch { updateNews() }
scope.launch { updateProfile() }
}
suspend fun updateProfile() {
val user = getUserData()
view.showUser(user)
}위의 코드와 유사한 로직을 가진 코드임에도 불구하고 이를 코루틴으로 작성하면 절차지향적으로 코드를 작성함에도 불구하고 비동기의 효과를 불러올 수 있습니다.
2️⃣ Callback hell 현상을 막을수있다
이는 Spring Webflux 대신에 코루틴을 사용하는 이유라기 보다는, 코루틴이 효율적인 이유라고 볼 수 있겠습니다.

보통은 Multi-thread로 비동기 처리를 수행하면 Callback을 주렁주렁 달게될겁니다. 그런데 이렇게 Callback을 주렁주렁 달아서 비동기를 처리하면 문제가 생깁니다.
1. 코드가 직관적이지 못해서 알아보기 힘들다
2. Callback 중간에 Exception이 터지면 트래킹하기 어렵다
그러나 코루틴의 경우 비동기 처리를 직렬적으로 수행할 수 있기 때문에 Callback을 주렁주렁 다는 방식보다는 코루틴을 사용해서 처리하는게 매우 효율적입니다.
다음 단락부터는 Coroutine의 원리를 알아보고자합니다.
👉 본격적으로 Coroutine에 대해서 소개해보고자 합니다.
본격적으로 Coroutine에 대해서 소개를 시작해보고자합니다. 제가 보고있는 책에서는 코루틴의 핵심 기능을 아래와 같이 소개하고 있습니다.
🔥 The core functionality that Kotlin coroutines introduce is the ability to suspend a coroutine at some point and resume it in the future.
위의 글을 해석해보면, 코루틴의 핵심 기능은 코루틴을 특정 시점에서 멈추고 미래에 재실행이 가능하다는 점에 있다 라는 뜻입니다.
실제로도 coroutine을 이용해서 코드를 짜면 메소드 앞에 예약어로 suspend를 항상 붙이는 모습을 볼 수 있습니다. 이 뜻은, 이 함수는 특정 시점에서 멈추고 재실행이 가능한 함수 라는 뜻입니다. 함수를 특정 시점에서 멈추고 재실행할 수 있다는 것은, 쓰레드에서 특정 로직을 처리함에 있어서 block이 걸렸을 때 함수를 즉시 멈추고 다른 task를 할당해서 실행할 수 있는 능력을 가질수 있다 라는 뜻도 됩니다.
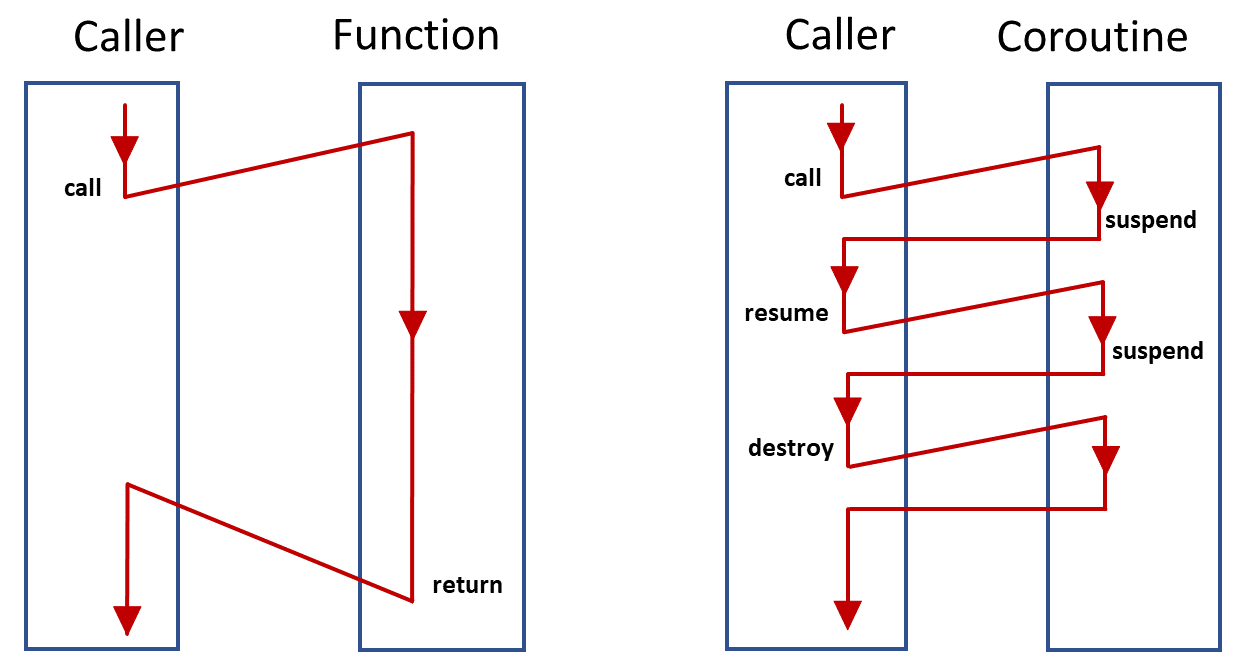
위 그림에서 왼쪽은 코루틴 없이 동기식으로 작성됐을 때의 흐름, 그리고 오른쪽의 경우 코루틴을 적용하여 비동기식으로 작성했을 때의 흐름입니다.
Coroutine을 적용하게 되면 함수에서 block이 걸렸을 때 즉시 suspend를 걸어서 함수 실행을 멈추고, Caller를 재실행하고, Coroutine에서 block이 풀리게되면 다시 재실행하고 반복하면서 쓰레드를 효율적으로 사용할 수 있게 됩니다.
하나의 코드 예시를 들어보도록 하겠습니다. 이 코드는 Android에서 뉴스의 모든 페이지를 동시에 처리해서 view에 띄우는 함수 예시입니다.
// all pages will be loaded simultaneously
suspend fun showAllNews() {
viewModelScope.launch {
val allNews = (0 until getNumberOfPages())
.map {page -> async { getNewsFromApi(page) } }
.flatMap { it.await() }
.view.showAllNews(allNews)
}
}위의 코드를 조금만 분석해보자면, 페이지를 로드하는데 모든 페이지를 async 블록을 통해서 뉴스를 동시에 호출하고 모든 호출이 끝날 때까지 await을 걸었다가 모든 페이지가 로드되면 view에 띄우는 로직입니다.
이처럼 코루틴을 사용하면 매우 직관적으로 쓰레드를 비동기적으로 제어할 수 있게됩니다.
게다가 코루틴은 일반적인 쓰레드를 사용하는 것보다 cost가 낮습니다. 그거는 아래의 코드 예시만 봐도 알수있습니다.
일반적인 쓰레드를 사용한 비동기 처리
fun main() {
repeat(10000) {
thread {
Thread.sleep(1000L)
print(".")
}
}
}코루틴을 이용한 비동기 처리
fun main() = runBlocking {
repeat(10000) {
launch {
delay(1000L) // suspending
print(".")
}
}
}제가 사용하고있는 컴퓨터를 기준으로 위의 두 코드를 실행해보면 첫번째 코드의 경우 7초, 두번째 코드의 경우 1초도 안되서 실행이 끝납니다. 어디서 이런 차이가 발생하는 것일까요?
정답은, 첫번째 코드의 경우 한정된 개수의 쓰레드로 코드를 실행하기 때문에 모든 쓰레드에서 block이 걸리면 대기할 수 밖에 없는것이고, 두번째 코드의 경우 쓰래드에 block이 걸리면 즉시 함수를 중단하고 다른 task를 받아서 실행하기 때문입니다. 여기서 일반적인 Thread를 이용해서 비동기를 처리하는 것의 성능과 코루틴을 이용해서 비동기를 처리하는 것이 차이가 발생하는 것입니다.
게다가 일반적인 쓰레드를 이용한 비동기 프로그래밍은 쓰레드를 유지하는데도 cost가 발생하기 때문에 더더욱이나 코루틴을 이용하면 cost도 낮다는 것도 알수있습니다.
이제부터 본격적으로 Coroutine이 어떤 방식으로 동작하는지 알아보겠습니다.
🤔 How does suspension work?
우선 제가 보고있는 책에서는 suspending functions에 대해서 아래와 같이 강조하고있습니다.
🔥 Suspending functions are the hallmark of Kotlin coroutines.
The suspension capability is the single most essential feature upon wich all other Kotlin Coroutines concepts are built.
위의 말을 번역해드리자면, 코루틴에 있어서 suspension capability는 코틀린 코루틴이라는 개념이 설립된 이래로 가장 중요한 특징이다 라는 뜻입니다. 따라서 코루틴에 있어서는 suspension capability가 처음이자 끝이라는 뜻이기도 하지요.
그러면 이제부터 궁금해집니다. 과연 코루틴은 suspension capability를 어떻게 확보를 했는지를요. 우선 결론부터 말해드리자면, 코틀린 코루틴은 state를 담은 Continuation이라는 변수를 반환해서 suspend point와 resume point를 저장합니다. 이를 통해 state machine이 동작하는 것처럼 함수를 중단시켰다가 다시 실행할 때 다시 Continuation에 저장한 상태를 기반으로 다시 코드를 재실행할 수 있게됩니다.
간단한 예시를 통해서 우선 몸을 풀겠습니다.
suspend fun main() {
println("Before suspending")
suspendCoroutine<Unit> { continuation ->
println("Before too!!")
continuation.resume(Unit)
}
println("After suspending")
}suspendCoroutine 함수의 경우 continuation 이라는 파라미터를 람다로 받아내서 메소드의 실행 흐름이 suspend 되기 전에 취해야할 로직을 정의합니다. 따라서 suspendCoroutine에 의해서 suspend되기 전에 Before too!!를 먼저 호출하고 coroutine의 실행 흐름을 suspend 하게됩니다. 그리고 continuation을 통해서 resume이 호출이 되면 그 때되서야 suspend가 풀리면서 아래의 After suspending 이라는 문자열이 출력되게 됩니다.
여기서 우리가 추측할 수 있는것은, Continuation 이라는 클래스가 코루틴에서 suspending을 제어할 수 있구나 입니다.
참고로 Continuation 클래스의 경우 Kotlin 1.3부터 아래와 같이 resume이 구현되어있습니다.
inline fun <T> Continuation<T>.resume(value: T): Unit = resumeWith(Result.success(value))
inline fun <T> Continuation<T>.resumeWithException(
exception: Throwable,
): Unit = resumeWith(Result.failure(exception))그리고 resume 함수는 아래와 같이 사용이 가능하기도합니다.
suspend fun main() {
val num: Int = suspendCoroutine<Int> { cont ->
cont.resume(42)
}
println(num) // 42
}다음 단락에서는 본격적으로 코루틴이 low level에서는 어떻게 동작하고 있는지에 대해서 설명을 드리도록 하겠습니다.
🔥 Coroutines under the hood (suspend fun이 정확하게 뭐야?)
우선 제가 보고있는 책에서는 이렇게 말을 해주고있습니다.
- Suspending functuons are like state machines, with a possible state at the beginning of the function and after each suspending function call.
-> 함수의 시작과 각각의 suspend point마다 state를 매겨서 state machine처럼 동작한다.- Both the number identifying the state and the local data are kept in the continuation object.
-> Continuation 객체에 state와 local data를 저장한다.- Continuation of a function decorates a continuation of its caller function; as a result, all these continuations represent a call stack that is used when we resume or a resumed function completes.
-> Continuation 객체는 Call stack과 유사한 동작을 하기 위해서 caller function의 continuation 또한 조작한다.

아마 이 단락을 처음 보신분들은 위와 같은 표정을 지을지도 모르겠습니다. 사실 저는 원서로 공부하고 있기 때문에 더 그렇지 ㅠ
대충 위의 설명을 요약하자면, Kotlin Coroutine은 suspending을 위해서 Continuation 객체에 함수의 상태를 저장하는 방식을 채택하였다 정도로 보시면 되겠습니다.
그리고 Kotlin Team은 이러한 Continuation 구현 방식을 Continuation-passing style 이라고 설명을 하고있습니다. 그리고 Continuation-passing style(아래에서 부터는 CPS 라고 부르도록 하겠습니다.)는 아래와 같이 설명이 되어있습니다.
🔥 CPS means that continuations that is explained at the previous are passed from function to function as the arguments.
위를 번역하자면, CPS는 continuation 객체를 함수와 함수간에 파라미터의 형식으로 전파함으로써 suspending을 구현하고있다는 뜻입니다.
이를 자세히 설명을 하기 위해서 예시를 몇개 들도록 하겠습니다. 간단한 예시부터 시작해볼까요?
suspend fun getUser(userId: String): User?위와 같은 메소드가 존재한다고 가정하겠습니다. 그런데 이를 디컴파일을 해보게 되면 아래와 같이 변환되어있는 모습을 확인해볼 수 있습니다.
fun getUser(userId: String, continuation: Continuation<*>): Any?뭔가 이상합니다. 디컴파일된 결과에는 suspend는 사라졌고, 파라미터로는 continuation이 추가되어있고, 반환형도 User? 가 아닌 Any? 로 변환이 되어있습니다.
우선은 반환형이 왜 Any? 로 바뀌었는지부터 설명을 드리겠습니다. suspend 함수는 경우에 따라서 COROUTINE_SUSPENDED 라는 마커를 반환하게됩니다. 이는 User? 타입은 아니기 때문에 둘을 동시에 포함할 수 있는 반환형인 Any? 로 변환이 되어서 디컴파일이 됩니다.
다음 예시를 통해서 더욱 깊게 설명을 드리겠습니다. 이전의 예시보다는 좀 복잡합니다.
suspend fun myFunction() {
println("Before")
delay(1000L)
println("After")
}그리고 가정하겠습니다. myFunction 자체가 가지는 Continuation 객체를 MyFunctionContinuation이라고 하겠습니다. 이전에 설명드렸듯이, 코루틴은 suspend를 구현하기 위해서 caller의 continuation을 조작한다고 말한 바 있습니다.
실제로 myFunction()이 실행될 때 continuation 객체가 새로 할당이 되는데요, continuation 객체가 할당될 때 caller의 continuation를 파라미터로 받아서 새로 continuation을 생성해야하기 때문에 myFunction 함수가 실행되는 시점에서는 아래와 같이 할당이 이뤄질겁니다.
// 파라미터로 전달되는 continuation은 caller의 continuation이다.
val continuation = MyFunctionContinuation(continuation)그런데 이러한 할당은 함수의 최초 실행 지점에서 이뤄지는 것이지, 함수의 resume 지점에서는 저렇게 할당이 되지 않습니다. resume 지점에서는 파라미터로 자기 자신의 continuation을 그대로 돌려받기 때문에 resume 지점에서는 MyFunctionContinuation 타입을 가지게됩니다.
따라서 위의 코드 스니펫을 아래와 고치겠습니다.
val continuation = continuation as? MyFunctionContinuation
?: MyFunctionContinuation(continuation)위와 같이 작성을 해주게되면 쓰레드 점유권을 돌려받은 코루틴이 continuation을 비정상적인 할당 없이 사용할 수 있게됩니다.
그리고 myFunction() 메소드의 body에 대해서 자세하게 이야기를 해보겠습니다. continuation은 분명히 state와 로컬 변수를 저장한다고 이전에 이야기 하였습니다. 코루틴에서 저장하는 state를 이제부터는 label 이라고 부르도록 하겠습니다.
코루틴을 state를 관리하기 위헤서 label을 아래와 같은 방식으로 저장하게됩니다.
- 실행 시점에서는 continuation에서 받은 label을 그대로 사용합니다.
- 실행 직후에는 label에 다음 state를 저장합니다.
- suspend되면 label은 다음 state를 저장하고 있기 때문에 resume 시점에서는 다음 state로 이동할 수 있게됩니다.
따라서 myFunction()은 아래와 같이 변경됩니다.
fun myFunction(continuation: Continuation<Unit>): Any {
val continuation = continuation as? MyFunctionContinuation
?: MyFunctionContinuation(continuation)
if (continuation.label == 0) {
println("Before")
continuation.label = 1 // save the next state
if (delay(1000, continuation) == COROUTINE_SUSPENDED)
return COROUTINE_SUSPENDED
}
if (continuation.label == 1) {
println("After")
return Unit
}
error("Impossible")
}
class MyFunctionContinuation(
val completion: Continuation<Unit>
): Continuation<Unit> {
override val context: CoroutineContext
get() = completion.context
var label = 0
var result: Result<Any>? = null
override fun resumeWith(result: Result<String>) {
this.result = result
val res = try {
val r = myFunction(token, this)
if (r == COROUTINE_SUSPENDED)
return Result.success(r as Unit)
} catch (e: Throwable) {
Result.failure(e)
}
completion.resumeWith(res)
}
}따라서 suspend function에 대해서는 thread에 blocking이 걸리게되면 blocking 상태가 이전의 continuation으로 전파가 이뤄지는 방식이기 때문에 state machine 기반으로 coroutine이 진행되게됩니다. 그리고 이러한 구현 덕분에 Continuation 자체가 함수의 call stack의 역할도 수행할 수 있기 때문에 suspend를 해가면서 함수 실행 흐름을 자유롭게 오갈 수 있게되는 것입니다.

위의 그림과 같이 Continuation 간의 상태 전파를 통해서 Continuation 자체가 하나의 function call stack의 역할을 수행하기 때문에 coroutine의 suspending에 대해서 capability가 확보됩니다.
🌲 마치며
다음 포스팅부터는 코루틴 라이브러리에 대해서 알아보겠습니다.
긴 글 읽어주셔서 감사합니다!
참고도서: Coroutines Deep dive
