
🔥 SQL vs NoSQL
일단 DynamoDB를 이야기하기 전에 SQL과 NoSQL의 차이부터 설명을 하고 시작을 해야할 것 같습니다.
🤔 SQL은 무엇일까?
SQL은 관계형 데이터베이스(RDB)를 제어하는데 사용되는 언어를 의미하지만, 여기서는 RDB를 SQL이라고 부르도록 하겠습니다.
SQL의 경우 Schema가 존재하여 Schema 단위로 내부에 Table을 만들어서 정해진 Table의 규격에 맞춰서 Insert, Update, Select 등의 쿼리를 수행할 수 있습니다.
대표적으로 SQL 진영에는 MySQL, SQLite 등이 있습니다.
다음으로는 NoSQL에 대해서 알아보겠습니다.
🤔 NoSQL은 무엇일까?
대충 NoSQL 이라는 이름을 들어보면 SQL의 반대 진영에 있는 아이구나 라고 생각을 하시게될겁니다.
사실 NoSQL의 의미는, Not Only SQL 이라는 뜻으로, SQL처럼 정해진 테이블 형식을 따르지 않는다는 뜻입니다.
말 뜻 자체가 Not SQL 이기 때문에 NoSQL의 범주는 너무나도 다양합니다. NoSQL의 범주에는 DocumentDB. Key-Value DB, Graph DB가 존재합니다.
DocumentDB의 대표적인 데이터베이스는 MongoDB가 있고, Key-Value DB에는 Cassandra DB, DynamoDB가 있고, Graph DB의 경우에는 페이스북에서 자체적으로 만든 DB인 Tao가 대표적이라고 볼 수 있습니다.
🤔 Why NoSQL? (NoSQL은 왜 사용할까요?)
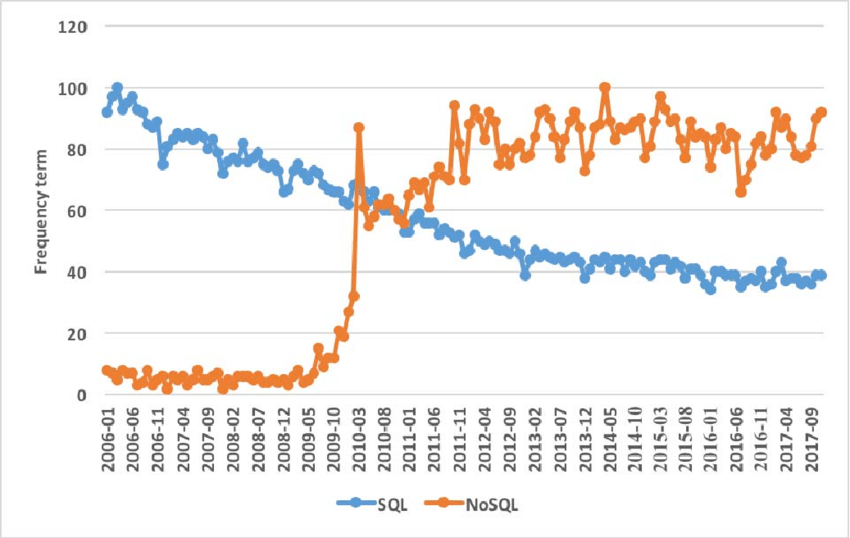
위의 그림은 SQL vs NoSQL에 대한 구글트렌드 자료입니다. 그러면 왜 많은 사람들, 그리고 회사들이 SQL을 두고 NoSQL을 사용하려고 할까요? 이유야 많겠지만 일단 몇 가지를 소개해드리겠습니다.
❗️ NoSQL은 Horizontal Scalability(수평적 확장)에 유리하다
사실 이 이유가 가장 크다고 볼 수 있겠습니다. 최근에는 서비스들의 규모가 매우 커지다보니 덩달아서 DB의 규모도 엄청 커지는 경향을 보이고있습니다.
그런 경우에는 엔지니어 입장에서는 Vertical하게 scaling을 할 것인지 (흔히 Scale-up을 한다고 표현합니다), 혹은 Horizontal하게 scaling을 할 것인지(흔히 Scale-out을 한다고 표현합니다)에 대해서 결정을 내려야합니다.
그런데 엔지니어 입장에서는 scale-out을 하고싶을겁니다. 이유는 다양하지만, 대표적인 이유는 아래와 같습니다.
- CPU, RAM과 같은 하드웨어는 일정 용량을 넘어서는 순간 cost가 미친듯이 올라갑니다.
- 한 대의 장비의 성능을 계속 올리게되면 Power wall 현상에 부딪히게됩니다. 따라서 이에 따른 쓰로틀링 현상이 벌어져서 오히려 성능을 악화시킬 수도 있습니다.
- 하나의 장비를 scale-up을 해서 관리를 하려고하면, 트래픽은 결국에 한 곳에 계속 몰리기 때문에 위험 부담이 커집니다.
위의 이유 때문에 일정 임계점부터는 scale-out을 선택하는 것이 기업 입장에서는 더욱 유리하다는 것입니다.
물론 이런 생각을 가진 분들도 계실겁니다.
🤔 SQL도 Sharding을 이용하면 scale-out이 가능하지 않아요?
물론 SQL도 샤딩을 통해서 수평적 확장이 가능하기는합니다. 그러나 SQL을 샤딩하는 것은 매우 어렵습니다.
따라서 거대해져가는 서비스를 운영하는 입장에서는 NoSQL도 고려해볼만 하더라...이겁니다!
❗️ NoSQL은 속도가 빠르다
NoSQL은 흔히 SQL에 비해서 속도가 빠르다고들 이야기를 많이합니다. 이유를 말씀드리겠습니다.
데이터베이스에 대해서 배워보신 분들은 아시겠지만, SQL은 인덱스 구조를 B-Tree(Balanced Tree)를 가지고 구현을 합니다. 따라서 RDB에서는 하나의 컬럼을 탐색하는데 이라는 시간복잡도가 소모됩니다.
그러나 NoSQL의 경우는 이야기가 다릅니다. NoSQL의 경우에는 Hash Table 구조를 사용하기 때문에 의 시간복잡도가 소모됩니다. 따라서 이 들어가는 SQL보다는 NoSQL이 속도적인 측면에서는 우월하고 볼수있는 것입니다.
❗️ NoSQL은 유연하다
NoSQL의 경우에는 스키마리스(Schemaless) 이기 때문에 단지 테이블만 존재할 뿐, 스키마가 존재하지 않습니다.
게다가 DynamoDB의 경우에는 Key-Value DB이기 때문에 Key만 정형화된 데이터 형식을 가지지, Attribute의 경우에는 형식의 자유도가 매우 높습니다.
따라서 NoSQL의 경우에는 비정형 데이터를 쌓기가 매우 유리하다는 측면도 존재합니다.
🤔 그러면 NoSQL은 만능이에요?
그렇지는 않습니다. NoSQL은 SQL의 장점을 포기하고 얻은 것들이 많습니다. 컴퓨터 공학에서는 무조건 좋은건 그렇게 많지 않습니다. 항상 trade off 관계가 있는 법이니까요.
NoSQL이 가지는 단점으로는 아래의 것들이 있습니다.
- Join 연산이 불가능하다.
- Primary Key, GSI(Global Secondary Index)가 아닌 Attribute에 대해서 Conditional Check를 수행할 때는 SQL보다 느릴수도 있다. (느릴수도 있다가 아니다. 사실 대부분의 경우에서 느리다!)
- 이러한 두번째 특징 때문에 설계 이전에 테이블을 어떻게 사용할지에 대해서 미리 고민을 해야한다.
이 외에도 NoSQL이 가지는 단점들이 많지만, 수평적 확장이 유리하며, 잘만 쓰면 SQL보다 속도가 빠르다는 점 때문에 NoSQL은 잘 사용되고 있다고 볼수있겠다! 물론 그 과정에서 잔머리를 많이 굴려야한다
🤗 이제 소개하겠습니다. Dynamo DB!
우선 AWS 공식 사이트에서 소개하는 Amazon DynamoDB의 정의를 먼저 소개하겠습니다.
여기서 저희가 주목해야할 부분은 높은 가용성 및 내구성 파트입니다.
DynamoDB의 경우 테이블의 Partition Key를 기준으로 AWS 리전에 분산 저장이 됩니다. 그리고 multi-AZ(Available Zone, 가용영역)로 저장이 되기 때문에 고가용성과 높은 데이터 내구성을 가진다는 특징도 가지고 있습니다.
그리고 DynamoDB의 경우에는 클러스터링이 자동으로 관리가 되며(위에서 말했듯이, DynamoDB는 알아서 분산 저장이 되기 때문이죠!) 게다가 별도의 설정을 하지 않는이상 Auto-Scaling을 지원하기 때문에 개발자 혹은 시스템 운영자들이 고민할 거리가 줄어든다는 장점도 존재합니다.
그러면 이제부터 DynamoDB의 구조에 대해서 알아보겠습니다.
👉 DynamoDB의 작동 구조
DynamoDB의 경우에는 테이블 단위로 데이터를 정의합니다. 다음은 AWS 공식 사이트에 나온 DynamoDB의 구성요소에 대한 설명입니다.

사실 여기까지는 SQL과 다르게 스키마가 존재하지 않더라 라는 느낌만 받으실겁니다. 사실 SQL에서 컬럼 -> 항목(item) 만 차이점이 없어보이기 때문이죠.
그런데 진짜 차이점은 여기에 있습니다.

DynamoDB의 경우 SQL과는 다르게 Primary Key를 Partition key(Hash key)만 사용하거나, 혹은 Partition Key와 Sort Key(Range Attribute)의 조합으로 사용합니다.
Partition Key만을 사용할 때는 Partition Key는 문자열, 숫자, 이진수만 할당이 가능하다는 것을 제외하면 사실 SQL과 느낌이 많이 비슷합니다.
그러나 Partition Key와 Sort key를 조합한 형식인 복합 기본키 형태로 사용하는 경우는 일반적인 SQL과는 느낌이 많이 다릅니다. NoSQL에서 복합 기본키를 사용하는 경우에는 Partion key + Sort key가 Primary Key가 되기 때문에 Partition Key가 중복이 있더라도 Partition key, Sort key의 조합은 globally unique(글로벌 테이블에서 유일하게 존재해야한다) 해야하기 때문입니다.
그리고 SQL과 DynamoDB의 제가 느끼기에 가장 큰 차이점은 여기에 있습니다.
❗️ DynamoDB에는 보조 인덱스가 존재한다
DynamoDB에는 두 가지의 보조인덱스가 존재합니다.
- LSI(Local Secondary Index): 소속된 테이블과 Partition Key가 동일하지만 Sort Key가 다른 인덱스
- GSI(Global Secondary Index): 소속된 테이블과 Partition Key와 Sort Key가 모두 다를 수있는 인덱스
DynamoDB에서는 글로벌 보조 인덱스는 20개까지 할당이 가능하고, 로컬 보조인덱스는 5개까지만 할당이 가능하기 때문에 보통은 LSI보다 GSI를 많이 사용하는것이 추세입니다.
그리고 보조 인덱스를 이용하여 Join 연산이 불가능하다는 NoSQL의 단점을 상쇄시키는 것이 가능합니다. 보조 인덱스를 이용하면 테이블간의 연관관계를 구현하는 것이 가능하기 때문입니다.

🌈 DynamoDB를 활용하는 개발자가 알아두면 좋은 것들
이 문단에는 DynamoDB를 활용하는 개발자가 알아두면 좋은 것들을 기술하겠습니다.
1️⃣ DynamoDB Query API에는 Transaction Read/Write 기능이 존재한다
말 그대로 DynamoDB의 Query API에는 쿼리 수행에 있어서 ACID(Atomicity(원자성), Consistency(일관성), Isolation(격리성), Durability(영속성))를 보장해줄 수 있는 메소드를 제공합니다. 즉, Read/Write의 여러 쿼리를 하나의 묶음으로 트랜잭션 단위로의 처리가 가능하다는 뜻입니다.
그러나 대용량의 데이터를 한번에 read/write를 하는 경우에는 batchWrite/Read 기능을 이용해서 처리를 하는 것이 cost 측면에서는 매우 유리합니다. (Amazon 공식 문서에서도 위와 같이 추천하고있습니다)
2️⃣ DynamoDB의 Hot Key 현상은 쓰로틀링을 유발한다. 따라서, Partition Key가 아무리 중복이 허용된다고 할지라도 Partition Key는 Unique하게 정의하는게 좋다
DynamoDB의 경우 Partition Key를 기준으로 테이블 항목을 분산 저장/처리를 수행합니다. 그리고 개발자들은 분산 저장/처리로 인해서 even하게 모든 이벤트가 처리되기를 기대합니다. (여러 곳으로 분산이 되었으면, 트래픽도 동일 수준으로 분산이 되기를 기대한다는 뜻)
그러나, Partition Key에 중복이 발생하는 경우에는 Hot Key 현상이 벌어집니다. Hot Key 현상이란, 특정 Partition Key를 가진 항목에 트래픽이 몰리는 현상을 의미합니다.
이러한 현상은 Partition Key가 중복되는 경우에도 벌어질 수가 있는데요, 따라서 Partition Key의 경우에는 최대한 유일성을 보장해주는 것이 매우 좋다고 볼수있습니다.

3️⃣ Hot data와 Cold data는 섞지마라.
Hot data란, 상대적으로 다른 항목에 비해서 트래픽이 많은 항목을 의미하며, 반대로 Cold data란 다른 항목들에 비해서 상대적으로 호출 횟수가 적은 데이터를 의미합니다.
Hot data와 Cold data를 섞어서 보관하는 경우에는, 어떤 곳에는 트래픽이 많이 쏠리고, 어떤 곳에는 트래픽이 적게 쏠리는 현상이 벌어집니다. 이는 개발자가 원치 않는 상황일겁니다.
따라서 해결책은 아래의 방법들이 있습니다.
1. 기간별로 Table을 나눠서 항목을 보관해라
2. Cold Data는 가능하면 S3로 마이그레이션해서 보관해라. 혹은, RDB로 마이그레이션을 해서 보관해라.
3. Hot Data의 경우 Cache로 저장을 해라. (여기서는 Redis가 좋은 선택지가 될수도 있겠다!)
여기까지 DynamoDB에 대한 설명입니다. 자세한 내용은 AWS 공식 사이트 혹은 AWS Summit을 보시면 되겠습니다!
다음 포스트에서는 DynamoDB를 이용한 간단한 CRUD 구현을 소개하겠습니다. (트랜잭션 read/write는 구현하지 않을 생각이에요) 다음 포스트에서 뵙겠습니다!
🌟 References
