🤔 이번 포스트에선 무엇을 소개할것인가?
제가 이전에 제 프로젝트 레포지토리가 이러한 이슈를 날린적이 있었습니다.
Query 로직에서 DynamoDB에 크게 의존하고 있는 현상
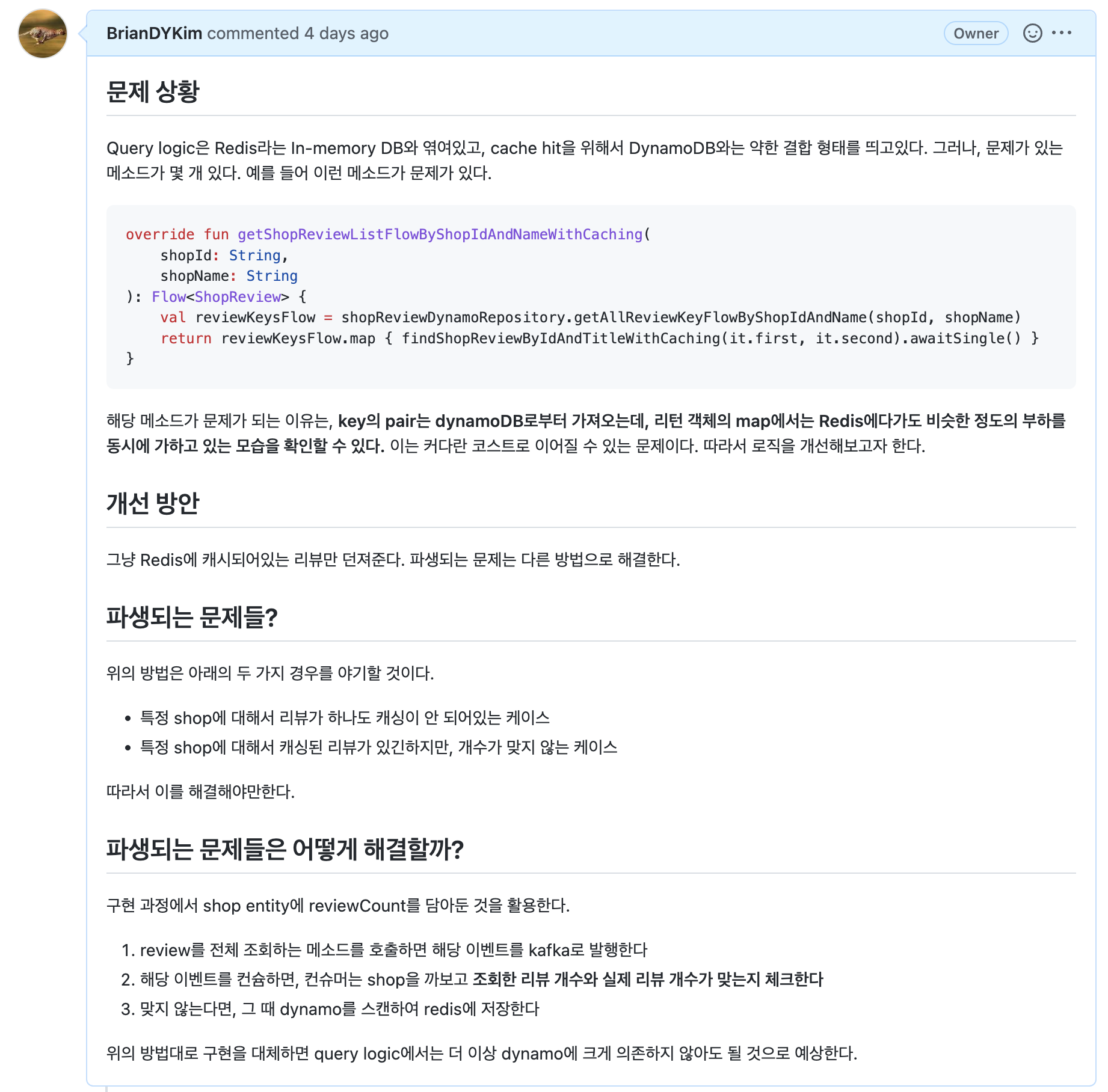
이번에는 이 문제를 해결하기 위해서 어떤 개선을 거쳤는지 알려드리겠습니다.
😭 아...생각보다 쉽지 않아요! ㅋㅋ
저는 정말 이 이슈를 해결하는게 쉬울줄 알았지만, 생각보다 난관이 많았습니다.
우선 첫번째 문제는 아래와 같습니다.
여기서 Kafka Config은 어디에 있었을까요? 정답은, Application-command 내부에 모두 위치하고 있었습니다. 여기서 모든 문제가 시작되었습니다. 과거의 내가 너무 밉던 순간이다
우선 첫번째, Query 어플리케이션에서도 KafkaTemplate를 이용해서 이벤트를 프로듀싱 해야하는데, 이 모든 템플릿들이 Application-command 내부에 있다보니 이를 분리해야했습니다.
Kafka Logic을 분리하는건 크게 3종류가 있습니다.
- KafkaTemplate들이 정의되어있는 ProducerConfig
- KafkaTopics, KafkaConsumerGroups 등의 설정 정보
- EventListener 로직들
이제 각각을 어디에 위치시킬지를 결정해야하는데요, 저는 다음과 같이 결정을 하게되었습니다.
- ProducerConfig, KafkaTopics, KafkaConsumerGroups의 경우 domain layer에 위치를 하기로 결정하였습니다. Application logic을 모르는 코드들이지만, domain에는 어느 정도 관여를 하기 때문입니다.
- EventListener의 경우 Application logic에 관여를 하는 코드이기 때문에 Application layer(정확히 말하면, Presentation + Application 이겠지만요!)에 위치를 시키기로 결정하였습니다.
1️⃣ domain-kafka
우선 domain-kafka의 계층 구조는 아래와 같습니다.

수평적으로는 client-query, client-command를 모두 참조하고, domain-dynamo 보다는 상위의 레이어로 위치시켜서 domain-query, domain-command 와 동일 레벨로 모듈을 맞춰주었습니다.
그리고 디렉토리 구조는 아래와 같이 만들었습니다.

그러면 다음 차례, EventListener는 어떻게 분리시켰는지 알려드리겠습니다.
2️⃣ application-kafka
우선 application-kafka의 계층 구조는 아래와 같습니다.
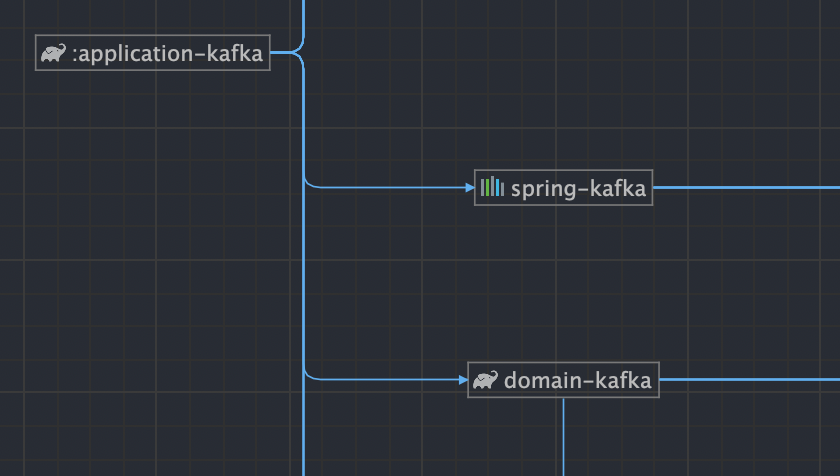
정확하게 domain-kafka만 참조하여서 application layer에 위치시킨 모습을 확인할 수 있습니다.
그리고 디렉토리 구조는 아래와 같습니다.
정말 단순하다!
다음으로, 목록을 뽑아오는 로직을 어떻게 수정하였는지 알려드리겠습니다.
🤔 어떻게 바꿨을까?
기존의 코드가 어떻게 구성되어있는지 알려드리겠습니다.
🔨 ShopReviewReader.kt
override fun getShopReviewListFlowByShopIdAndNameWithCaching(
shopId: String,
shopName: String
): Flow<ShopReview> {
val reviewKeysFlow = shopReviewDynamoRepository.getAllReviewKeyFlowByShopIdAndName(shopId, shopName)
return reviewKeysFlow.map { findShopReviewByIdAndTitleWithCaching(it.first, it.second).awaitSingle() }
}위의 코드는 reviewReader에 있었던 코드입니다. 위 코드의 로직은 대충 아래와 같았습니다.
- Dynamo로부터 review의 key 값을 모두 스캔하여 가져온다
- 이를 Redis에다가 Cache hit 하면서 모조리 캐싱하면서 가져와버린다.
위 설명만 들어도 뭔가 잘못된 것이 느껴지시죠? Query logic 주제에 쓰기 DB인 Dynamo에도 큰 부담을 쥐어주고 있었습니다. 동시에 Redis에도 부담을 주고 있었습니다.
매우 불합리한 상황이기 때문에 개선이 필요했습니다. 제가 선택한 개선 방법은 아래와 같습니다.
- 그냥 redis에 있는 review만 보내준다
- response를 날리기 직전에 이벤트를 발행하여, redis에 있는 리뷰 개수를 kafka로 날려준다
- 이를 Consumer가 구독하여 redis에 있는 리뷰 개수와 dynamo에 있는 리뷰 개수를 체크하여 정합성을 맞춰준다
저는 여기서 3번 과정만 설명드리겠습니다. 1, 2번까지 설명하기에는 포스트가 너무 길어질 우려가 있기 때문에 생략토록 하겠습니다. 글쓰는거 생각보다 힘들어요 ㅠ 양해 부탁드립니다!
👉 이벤트 구독 처리
이전에 제가 이런 말을 한적이 있습니다.
😭 Spring Kafka는 Continuations를 생성하지 못하기 때문에 Event 구독은 모두 Webflux로 처리를 해줘야한다!
이를 참고하시고, 코드를 소개해드리겠습니다.
🔨 ShopReviewEventListener.kt
// shopReview의 개수 정합성을 따지기 위해 이벤트를 구독하는 메소드
@KafkaListener(
topics = [KafkaTopics.reviewCountValidateTopic],
groupId = KafkaConsumerGroups.checkShopReviewCountGroup
)
fun checkShopReviewCount(countEvent: ShopReviewQuery.CountEvent) {
/*
1. review의 개수를 dynamo로부터 뽑아온다
2. 둘을 비교한다 (reviewCountDto와 dynamo에서의 개수) -> 개수가 안 맞으면 dynamo로부터 풀 스캔해서 가져온다
*/
when (countEvent.count) {
0 -> with(countEvent) {
shopReviewDynamoRepository.getAllReviewFlowByShopIdAndName(shopId, shopName).asFlux()
.flatMap { shopReviewRedisRepository.cacheReview(it) }
.subscribe()
}
else -> with(countEvent) {
shopReviewDynamoRepository.getAllReviewFlowByShopIdAndName(shopId, shopName).asFlux()
.count()
.flatMapMany {
when (it == count.toLong()) {
true -> Flux.empty()
false -> with(countEvent) { cacheAllReviews(shopId, shopName) }
}
}
.subscribe()
}
}
}나중에 리팩토링 해야할것들...
우선 첫번째는, client에게 내려준 리뷰가 0개인지, 그 외의 케이스인지 검사부터 해서 0개인 경우에는 바로 Dynamo로부터 데이터를 읽어내서 redis로 모두 저장시키는 로직을 태웠습니다.
그 외의 경우에는, redis에 개수가 정확하게 들어가있는 경우에는 아무 동작도 안하도록 로직을 구성하였고, 그렇지 않고 정합성이 틀어져있는 경우 역시 dynamo를 탐색하여 redis에 모조리 저장시키는 로직을 태웠습니다.
이 로직을 이용해서 Application-Query에서 Dynamo에 큰 부담을 주는 현상을 해결하게 되었습니다.
🤔 다음에 뭘 해야할까?
다음 포스트에서는 아래의 이슈를 해결해볼 예정입니다.
Spring Webflux에서 Functional Endpoint로 코드를 작성시 ExceptionHandler를 사용 불가능한 현상
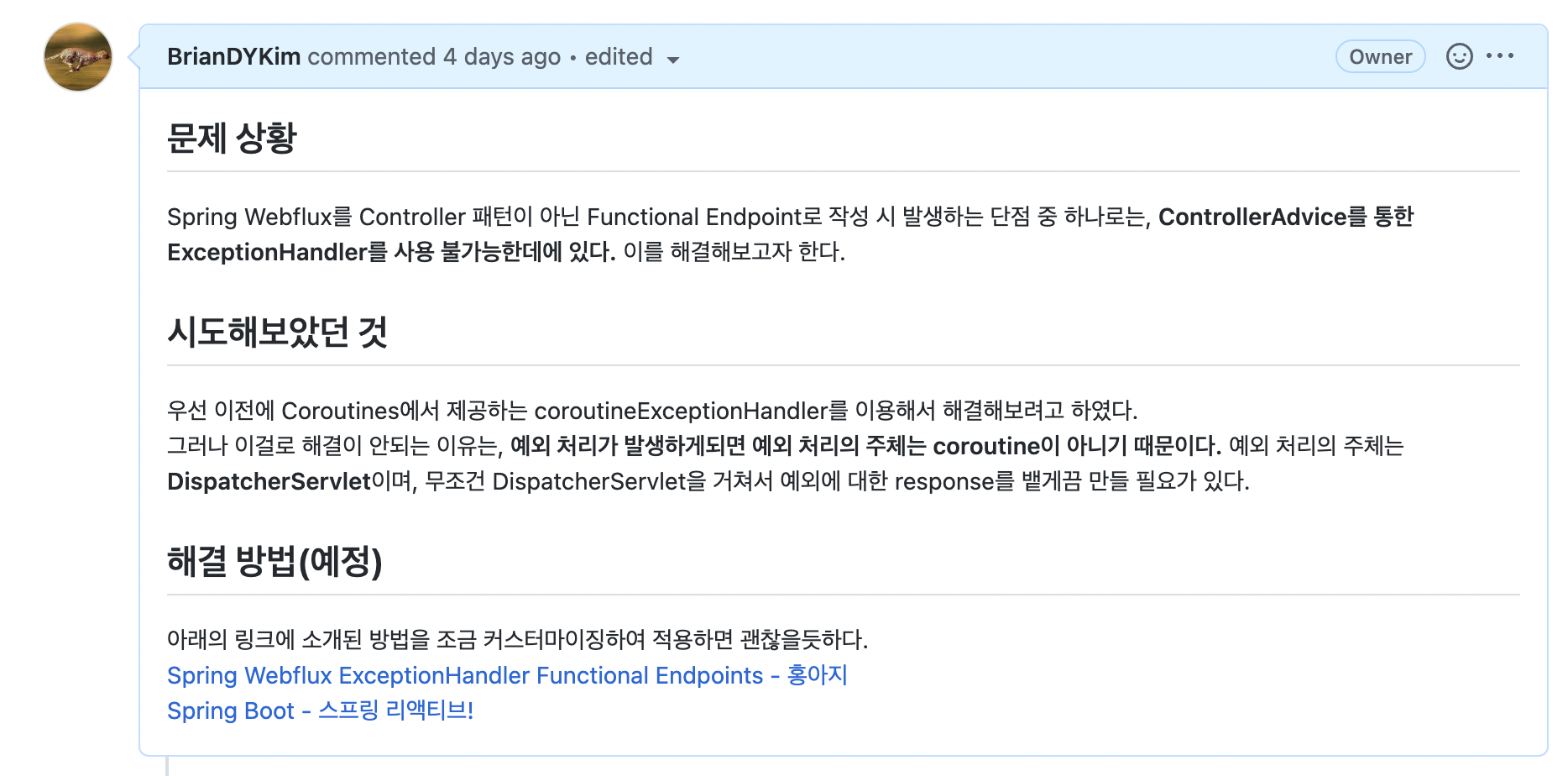
기존의 Spring MVC에서는 RestController 대상으로 ControllerAdvice를 이용해 바로 exceptionHandler를 선언하는 것이 가능했습니다.
그러나, Spring Webflux에서는 ControllerAdvice가 통하지 않기 때문에 다른 방법으로 해결을 해야합니다.
다음 포스트에서는 위의 문제를 어떻게 해결해야하는지에 관해서 다뤄보겠습니다.
