
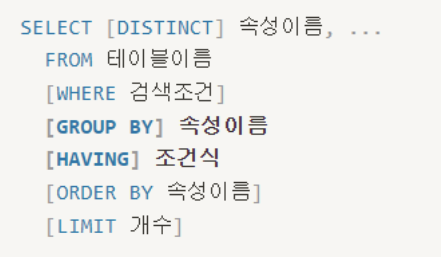
SELECT 문
- 데이터를 검색하는 기본 문장
- 질의어 (query) 라고도 함
- SQL 문 중 가장 많이 사용되는 문법데이터베이스 이름을 지을 때는 규칙이 있다.
-> 소문자와 언더바를 사용한다.
명령어들에 대해 알아보자.
-- 현재 존재하는 데이터베이스를 확인하는 명령어
SHOW DATABASES;
-- smartfactory 데이터베이스를 사용하는 명령어 (시작할 때 무조건 한번 써야함)
USE smartfactory;
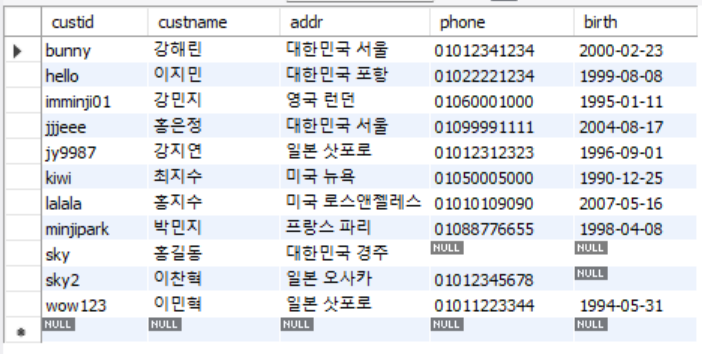
-- 고객 테이블의 모든 정보를 조회
SELECT * FROM customer;
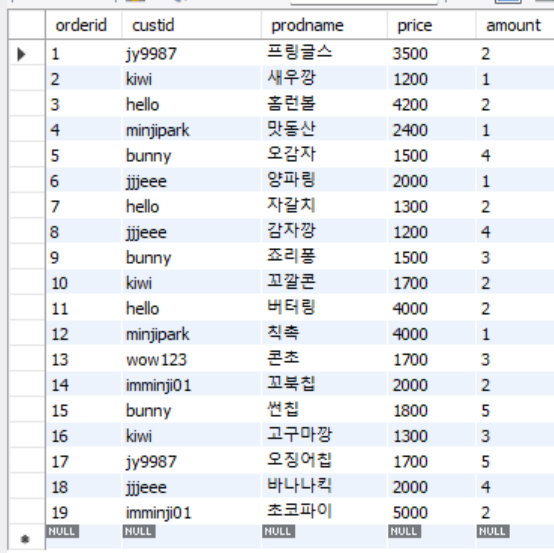
-- 고객 테이블의 모든 정보를 조회
SELECT * FROM orders;테이블 만들기
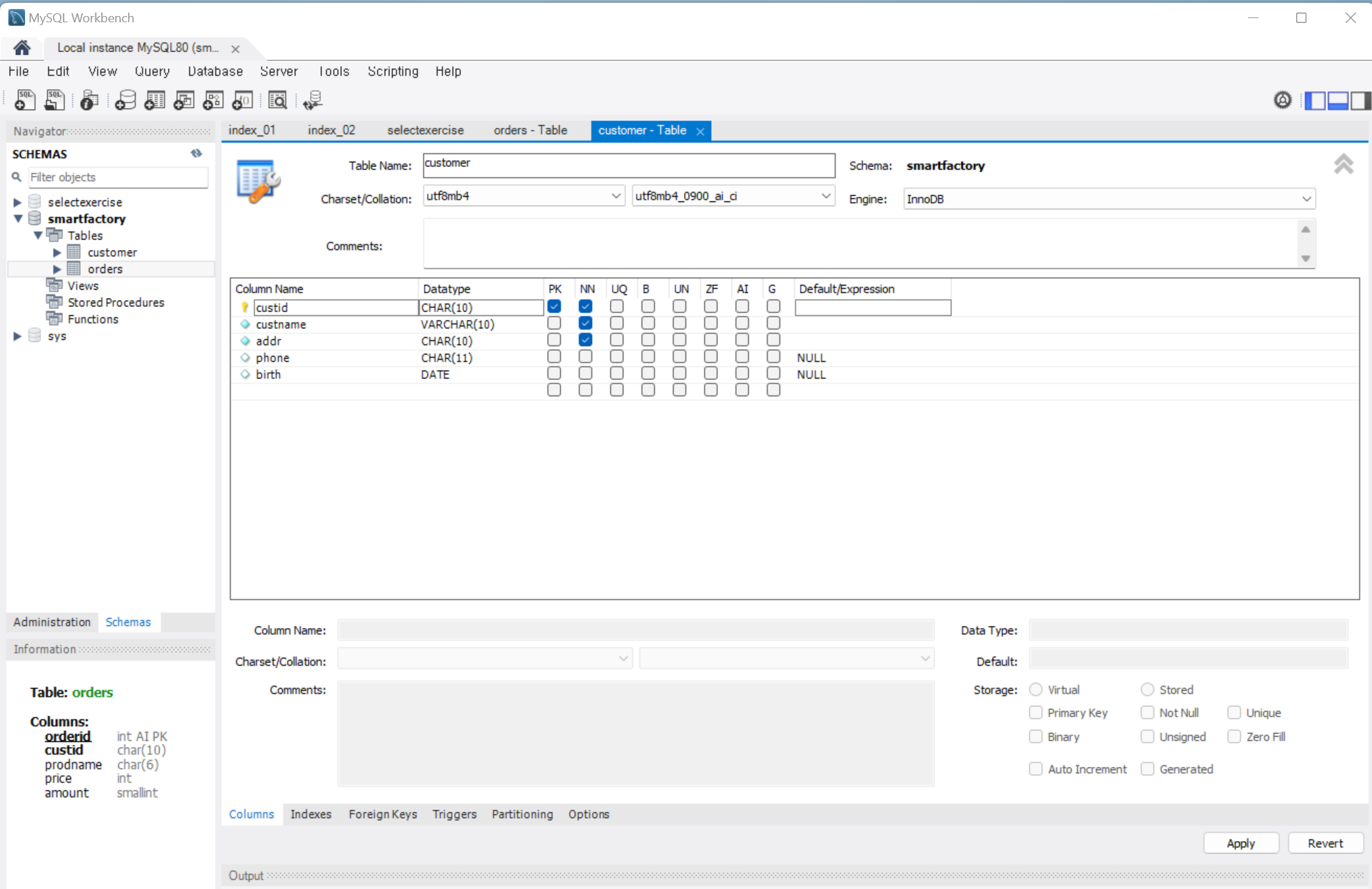
위 사진과 같이 테이블을 만든다.
PK = 기본키 (Primary Key)
NN = NULL이 아니다. (Not Null)
AI = 자동으로 증가 (Auto Increment)
Fk (외래키) 설정은 아래와 같이 한다.
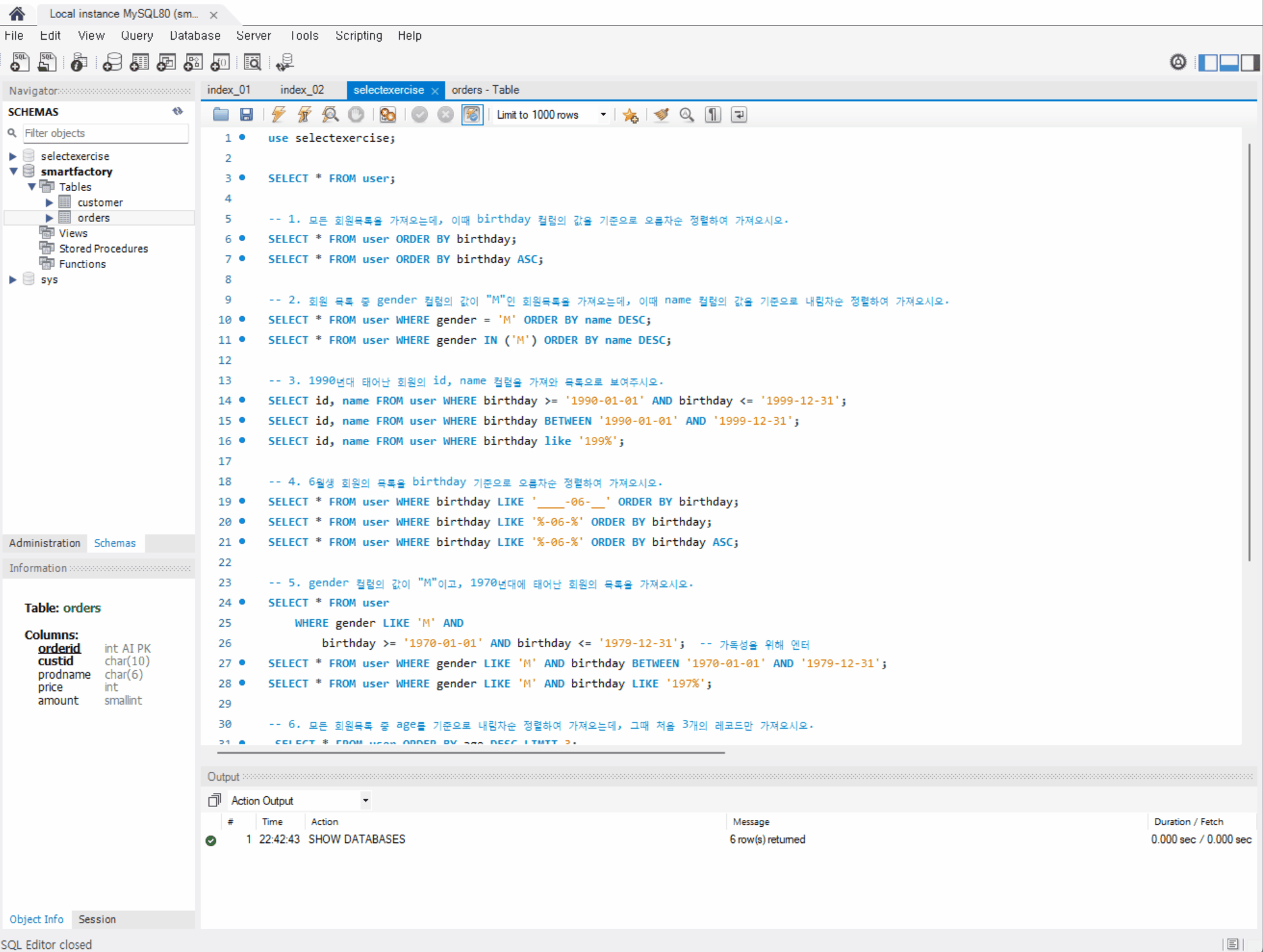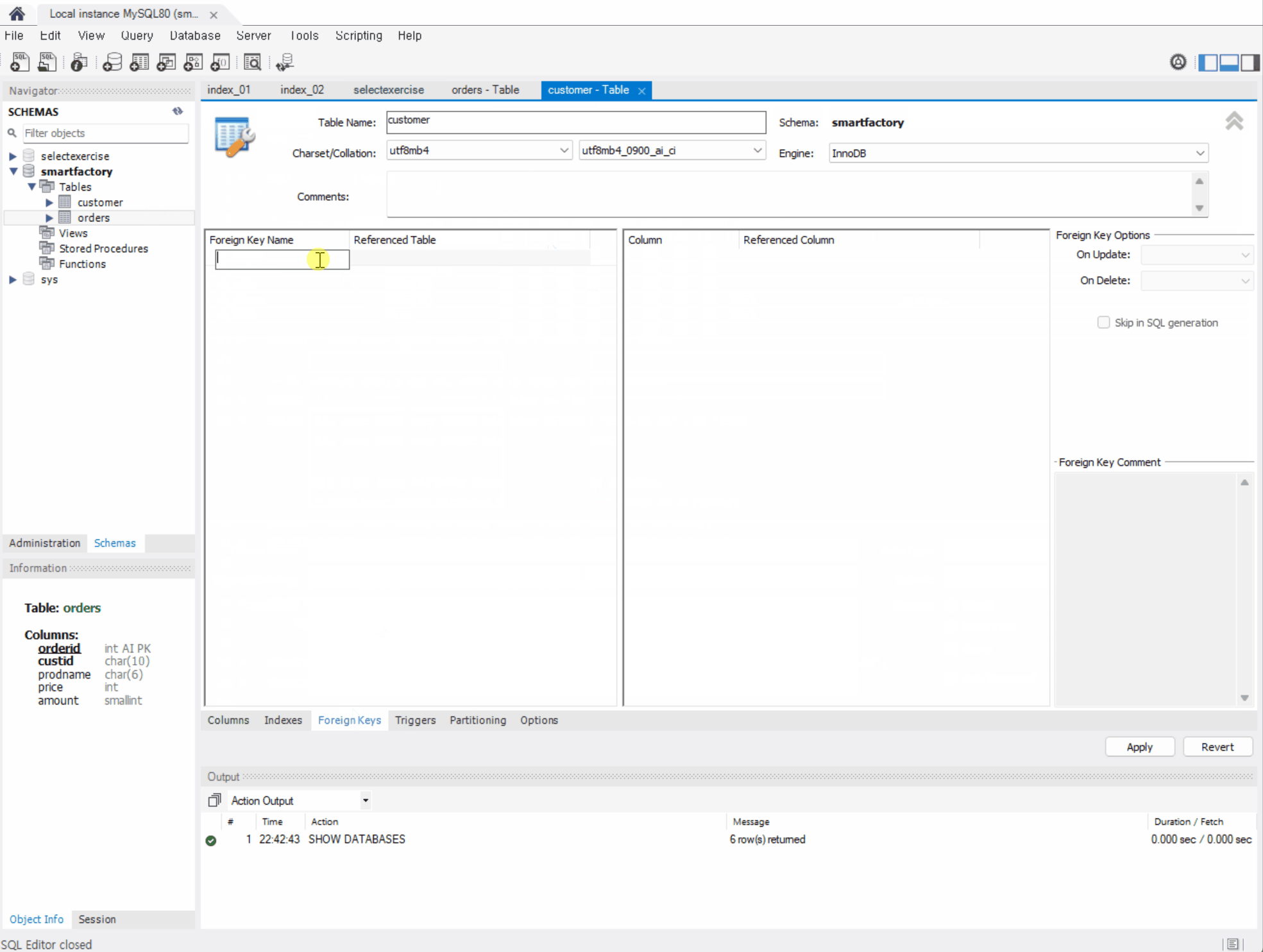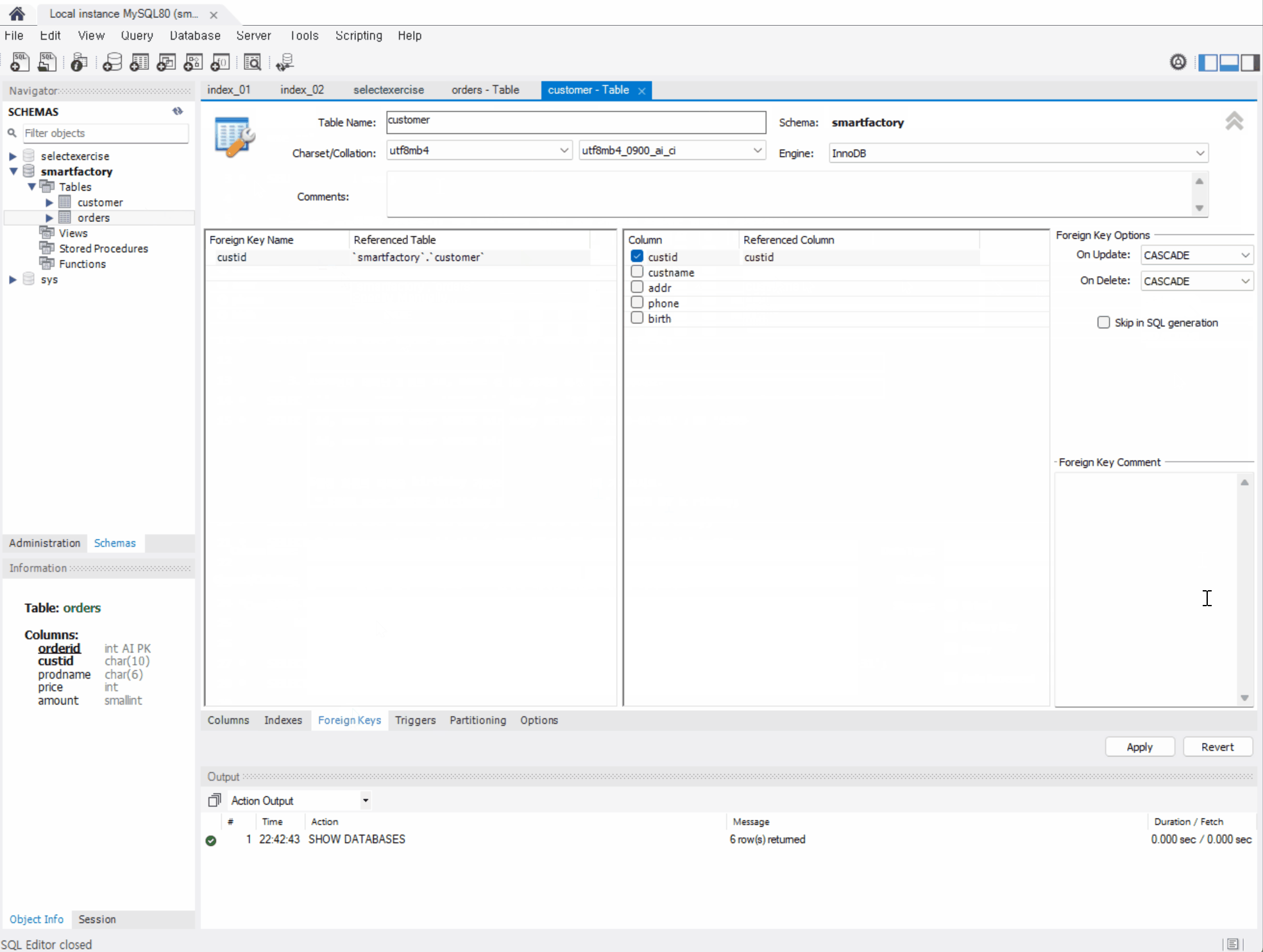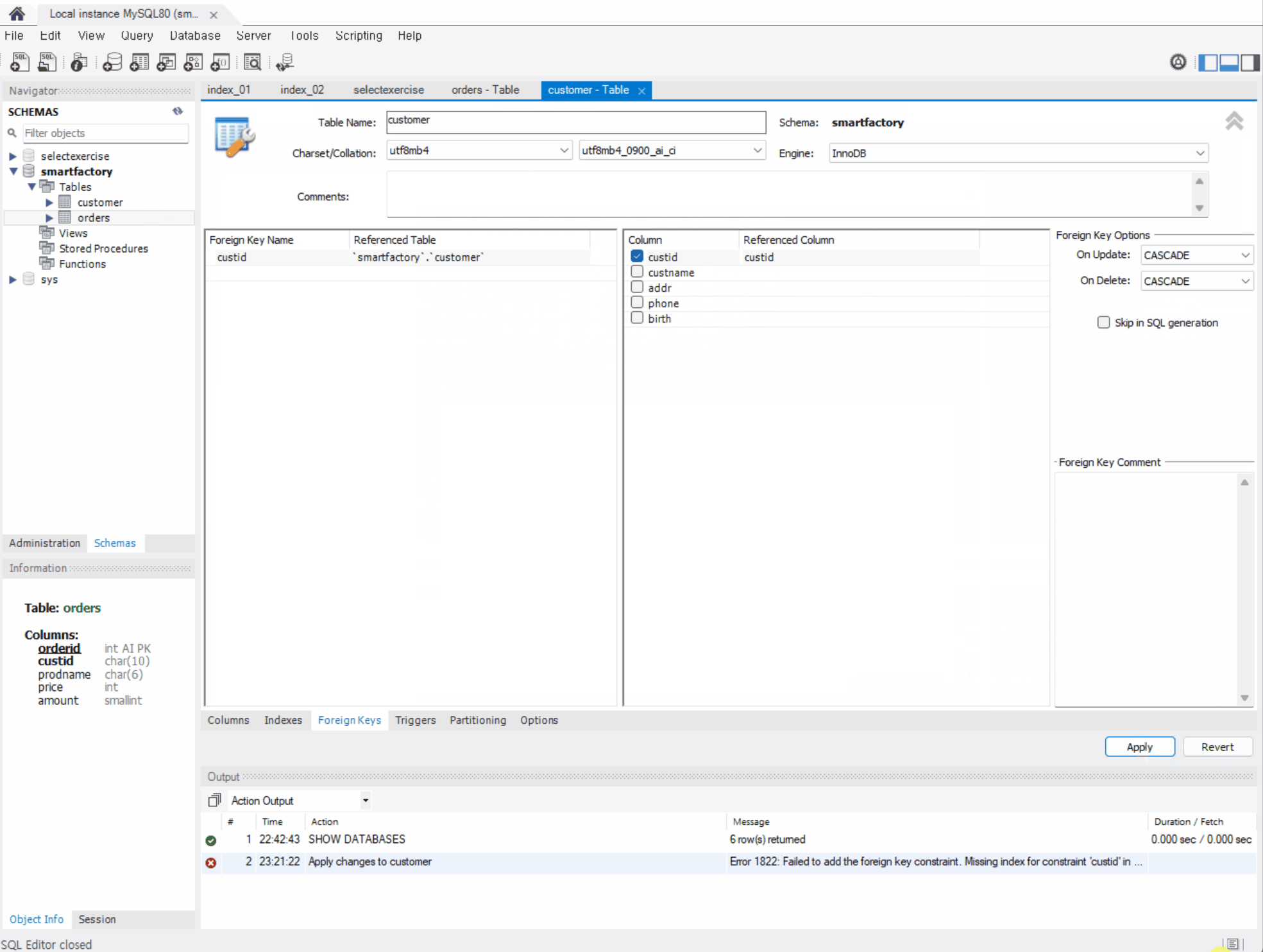
( 이미 해당 속성을 외래키로 설정했던 상태여서 오류가 뜬듯 하다. )
customer 테이블
orders 테이블
SQL 내부 실행 순서
1. 조회 테이블 확인 (FROM)
2. 데이터 추출 조건 확인 (WHERE)
3. 컬럼 그룹화 (GROUP BY)
4. 그룹화 조건 (HAVING)
5. 데이터 추출 (SELECT)
6. 데이터 순서 정렬 (ORDER BY)예를 들어
SELECT * FROM customer WHERE birth >= '2000-01-01' ORDER BY addr DESC;위 문장의 SQL 내부 실행은 아래 사진처럼 실행이 된다.

SELECT 문 구성 요소

WHERE 절은 검색 조건이다.
뒤에는 아래와 같은 조건이 붙는다.
BETWEEN a AND b : a와 b의 값 사이에 있으면 참 (a와 b도 포함)
IN ( list ) : 리스트에 있는 값 중에서 어느 하나라도 일치하면 참
LIKE '비교문자열' : 비교문자열과 형태가 일치하면 사용 (%,_사용)
%: 0개 이상의 어떤 문자
_: 1개의 단일문자
IS NULL : NULL 값인 경우 true, 아니면 false
이외에도 AND, OR, NOT, =, >, >=, <, <=, != ^=, <> 등이 있다.
Ex) 고객 이름 세번째 글자가 '수'인 고객 검색
SELECT * FROM customer WHERE custname LIKE '__수%';
ORDER BY는 결과가 출력되는 순서를 조절하는 기능을 한다.
단, WHERE 절 뒤에 나와야 한다.
ORDER BY 절을 사용하지 않는 경우, pk 기준으로 정렬 (숫자순, 문자순 정렬)
ORDER BY 뒤에 여러 개의 속성을 줄 수 있음
ASC: Ascending, 오름차순 (기본값)
DESC: Descending, 내림차순
Ex) 2000년 이후 출생자 중에서 주소를 기준으로 내림차순 검색
SELECT * FROM customer WHERE birth >= '2000-01-01' ORDER BY addr DESC;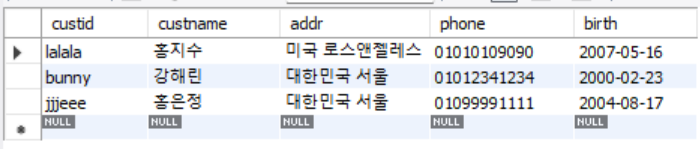
DISTINCT는 중복된 데이터 제거를 한다.
Ex) 고객 테이블에 있는 중복을 제외한 주소 검색
SELECT DISTINCT addr FROM customer;
LIMIT은 출력 개수를 제한하는 역할을 한다.
LIMIT 형식: LIMIT 시작, 개수 == LIMIT 개수 OFFSET 시작
주의) LIMIT에서 시작은 0임을 잊지 말자!
Ex. LIMIT 2 == LIMIT 0,2 == LIMIT 2 OFFSET 0
LIMIT은 가장 마지막에 씀
Ex) 2000년 이후 출생 고객 중에서 앞에 2건만 조회하고 싶은 경우
SELECT * FROM customer WHERE birth >= '2000-01-01' LIMIT 2; 
집계함수
SUM() : 합계
AVG() : 평균
MAX() : 최소값
MIN() : 최대값
COUNT() : 행 개수
COUNT(DISTINCT) : 중복 재외한 행 개수
Ex) 고객별로 주문한 총 주문액 구하기
SELECT custid AS '아이디', SUM(price * amount) AS '총 주문액' FROM orders GROUP BY custid;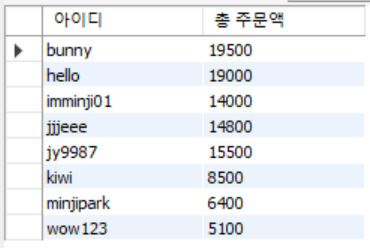
GROUP BY는 속성이름끼리 그룹으로 묶는 역할을 한다.
having : group by절의 결과를 나타내는 그룹을 제한
:GROUP BY 절과 반드시 함꼐 사용
:절보다 뒤에 나와야 함.
Ex) 총 주문액이 10000원 이상인 고객에 대해 고객별로 주문한 상품 총 수량 구하기 (단, custid가 'bunny'인 경우 제외)
SELECT custid AS '아이디', SUM(amount) AS '주문 수량', SUM(price * amount) AS '총 주문금액'
FROM orders
WHERE custid != 'bunny'
GROUP BY custid
HAVING SUM(price * amount) >= 10000;
Git Bash 이용
마지막으로 간단하게 Git Bash를 사용해보자.

후기
다 하고 나서 느낀 것은 같은 내용을 실핼함에도 불구하고 너무나 다양하게 코드를 사용할 수가 있다. 특히 where 절에서 많이 다르게 사옹할 수 있었던 것 같다. 지금은 투플의 수가 적어서 실행 속도 차이가 느껴지지 않지만, 투플을 큰 상황을 대비해서 어떻케 코드를 작성해야 실행 속도가 빠르게 할 수 있을지 찾아보며 해야할 것 같다.
예를 들어 where절의 LIKE에서 %를 앞에 붙이게 되면 문자열을 다 검색해야 해서 연산의 시간이 증가하므로 %를 가급적 뒤에 붙이는 것이 좋은것 처럼 말이다.
그리고 GUI환경이 역시 더 편한 것 같다.
그치만 Git bash나 cmd같은 환경도 매력있는 것 같다.
