카프카의 성능, 확장성, 메시지 처리 구조를 이해하려면 Partition이라는 개념을 완전히 이해해야 한다.
Partition은 단순히 Topic을 쪼개는 구조가 아니라, 카프카가 대규모 스트림을 병렬로 처리하고 순서를 유지하며 빠르게 동작하는 이유를 모두 담고 있다.
이 글에서는 Partition의 역할부터 내부 구조, 메시지 라우팅 방식, 순서 보장 규칙, Sticky Partitioner, Partition 수를 결정하는 실무 기준까지 자세하게 정리한다.
1. Partition은 왜 필요한가? (가장 근본적인 이유)
Partition은 다음 세 가지 목적을 동시에 충족시키기 위해 존재한다.
1) 병렬 처리 (Parallelism)
Topic을 여러 Partition으로 나누면, 각 Partition을 서로 다른 Consumer가 동시에 읽을 수 있다.
- 파티션 1개 → Consumer 1개만 처리 가능
- 파티션 6개 → Consumer 6개까지 병렬 처리 가능
즉, Partition 수가 Kafka 성능의 상한선을 결정한다.
2) 분산 저장
Partition은 하나의 Broker에 몰리지 않고 여러 Broker에 균등하게 나누어 저장된다.
즉, Topic 전체 데이터가 1개의 서버에 집중되는 것이 아니라, Partition 단위로 물리적으로 분산된다.
이 덕분에 Topic이 매우 큰 규모로 성장하더라도 저장과 처리 부담이 여러 Broker로 자동 분산되어, 개별 Broker에 과도한 부하가 몰리는 일을 방지할 수 있다.
3) 확장성
처리량이 부족하면?
- Consumer 개수 추가
- Partition 개수 증가 = 처리량 바로 상승
Partition은 카프카의 스케일아웃 구조를 뒷받침하는 핵심이다.
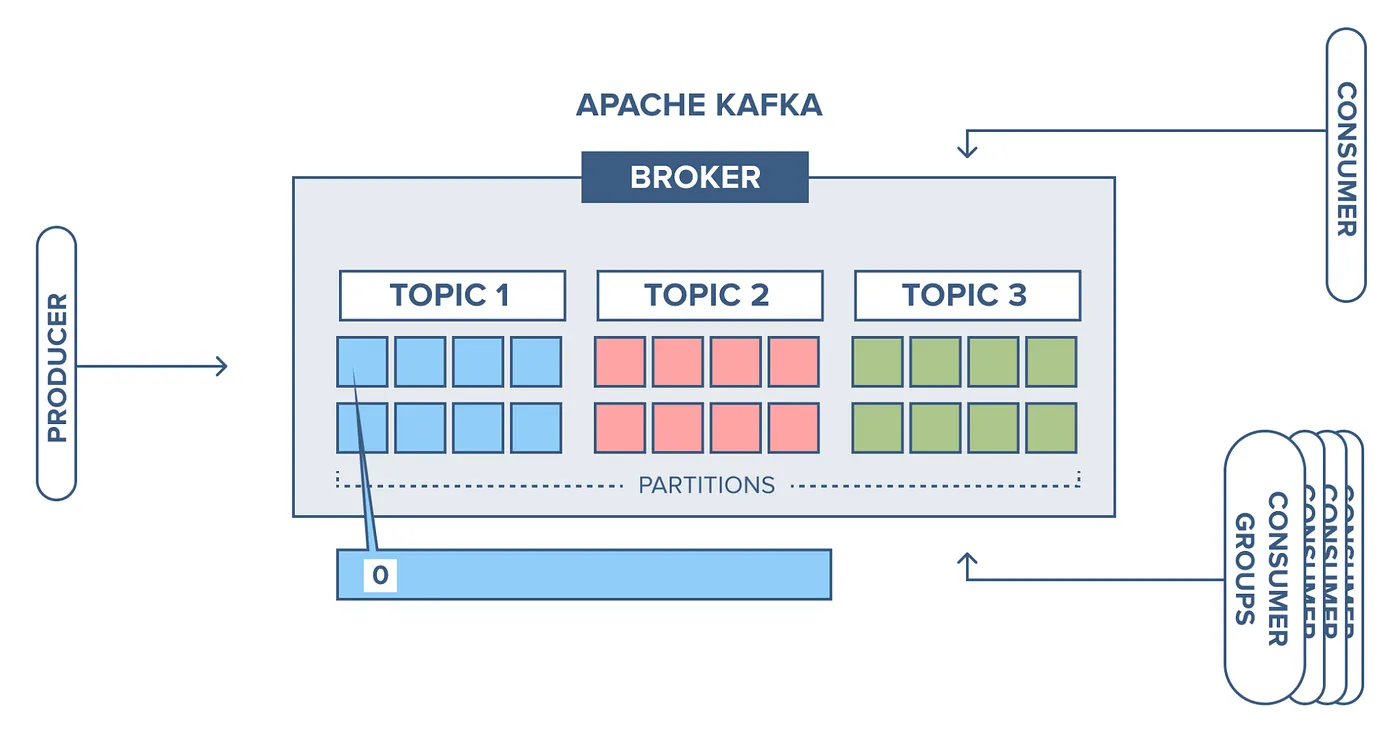
그림으로 다시보자.
Producer가 보낸 메시지는 Kafka Broker 내부에서 Topic별로 구분되고, 각 Topic은 여러 Partition으로 나누어 저장된다.
Partition들은 병렬 처리를 위해 Consumer Group 내의 여러 Consumer에게 나누어 전달된다.
즉, 이 구조는 Kafka가 데이터를 Topic으로 분리하고, Partition으로 분산해 저장하며, Consumer Group으로 병렬 소비하는 전체 아키텍처를 설명한다.
2. Partition 내부 구조
Partition은 내부적으로 append-only 로그이며, Segment 파일로 구성된다.
이 구조는 1편에서 설명했지만, Partition 관점에서 조금 더 상세히 보면 다음과 같다.
Partition 내부 구성
- 메시지는 오프셋 순서대로 파일 끝에 추가된다
- Partition은 여러 Segment로 나뉘어 저장된다
- 각 Segment는 로그 파일(.log) + 인덱스(.index, .timeindex)로 구성된다
중요한 점
Partition은 서로 독립적이며,
하나의 Partition에 저장된 메시지는 다른 Partition과 독립된 순서/타임라인을 가진다.
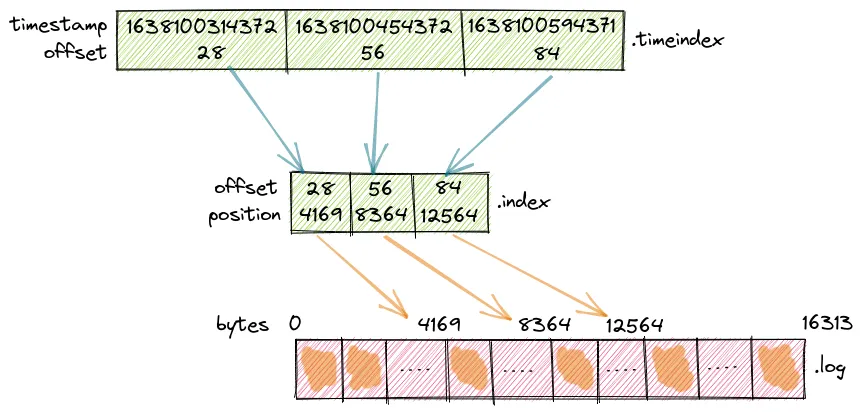
1편에서도 등장했던 그림인데 이만한 그림이 없다. 다시보자.
Kafka의 Partition 내부에서 timeindex → index → log 순서로 timestamp 기반 메시지 검색이 이루어지는 구조를 보여준다.
timeindex는 timestamp로 offset을 찾고, index는 offset으로 log 파일의 byte 위치를 찾으며, log 파일에서 실제 메시지를 읽어오는 전체 탐색 과정을 시각적으로 나타낸 그림이다.
3. 메시지 순서 보장 범위는 “Partition 단위”다
Kafka의 가장 중요한 규칙 중 하나는 순서 보장은 Topic 전체가 아니라 Partition 단위라는 점이다.
왜 Topic 전체 순서를 보장하지 않나?
Topic 전체의 순서를 보장하려면 다음이 필요하다.
- 메시지 한 줄로만 처리
- Consumer 1개만 읽을 수 있음
- 병렬 처리 불가
이러면 Kafka의 장점이 완전히 사라진다.
그래서 카프카는 Partition 내부에서만 순서 보장이라는 현실적인 구조를 선택했다.
순서 보장을 원하는 경우
Key를 지정해서 특정 Partition으로만 메시지가 가도록 해야 한다.
예시)
- 같은 User ID 이벤트가 항상 동일 Partition으로 들어가야 함
- 같은 Order ID 이벤트는 한 Partition으로 몰아야 함
이게 바로 Key Based Routing이다.
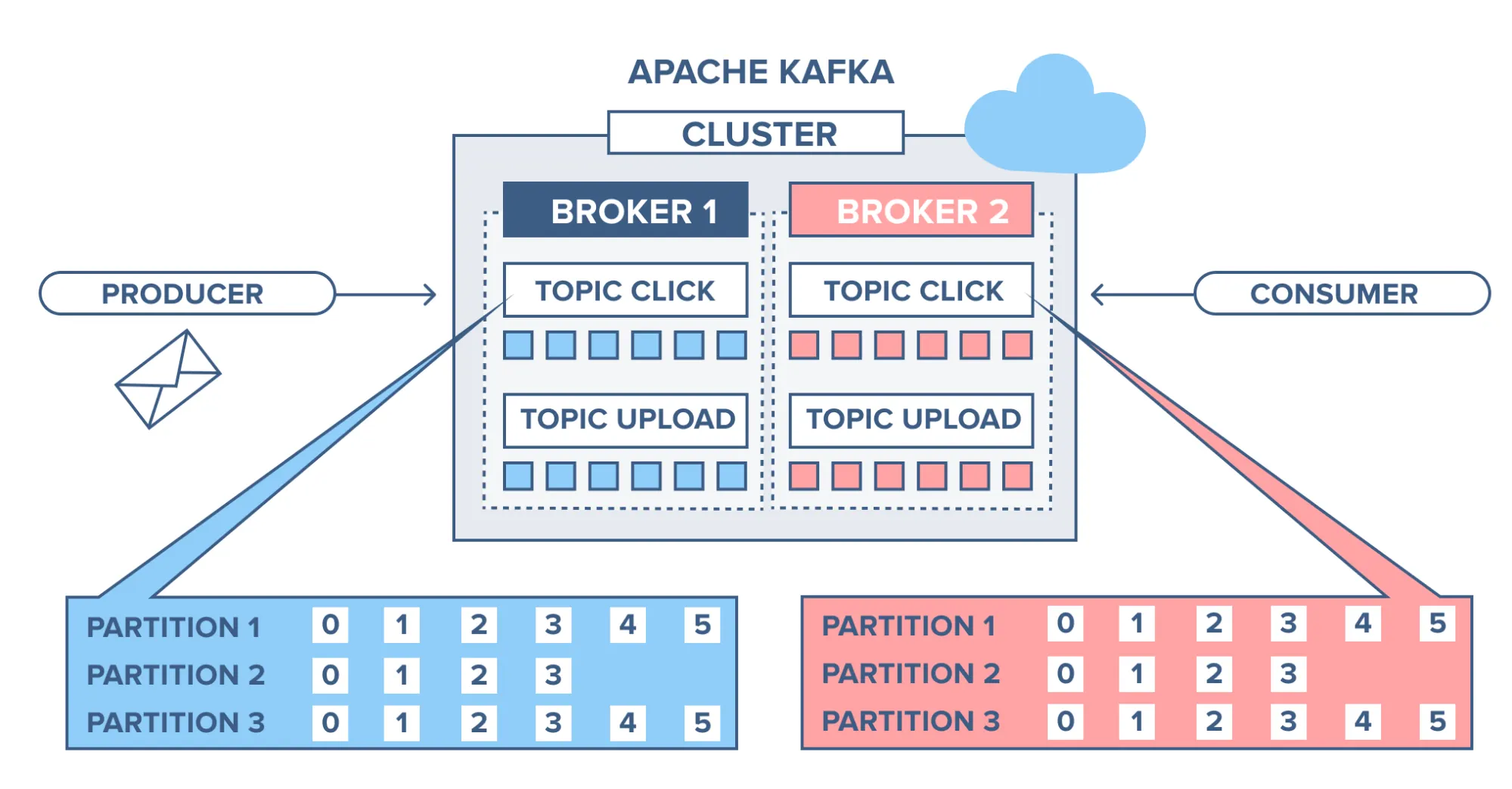
그림으로 다시보자.
- Producer가 Topic으로 메시지를 보내면 Kafka는 이를 여러 Partition으로 나누어 Broker 1, Broker 2에 분산 저장한다.
- 각 Partition 내부에서는 메시지가 0 → 1 → 2 → … 순서대로 append 되며, Partition 간에는 순서가 독립적이다.
- Consumer는 Broker들에 분산 저장된 Partition들을 병렬로 읽으며 높은 처리량을 유지한다.
4. Key 기반 Partitioner 동작 방식
Producer는 메시지를 보낼 때 Partition을 직접 지정하지 않으면 카프카 내부 Partitioner가 Partition을 결정한다.
Key가 있을 때
String topic = "user-login-events";
String key = "user_1001"; // userId
String value = "{ \"event\": \"LOGIN_SUCCESS\", \"ip\": \"10.10.0.2\" }";
ProducerRecord<String, String> record =
new ProducerRecord<>(topic, key, value);
producer.send(record);위처럼 key(userId)를 지정하면 ..
기본 Partitioner는 다음 알고리즘 방식으로 partition을 정한다.
hash(key) % 파티션 개수즉, 같은 Key는 항상 같은 Partition으로 간다.
→ 동일한 key에 대해서는 같은 hash 결과를 도출하기 때문에 항상 같은 Partition으로 가는것.
이 덕분에 Key 단위 순서 보장이 가능해진다.
예시)
- user-1001 → Partition 0
- user-1002 → Partition 1
- user-1003 → Partition 0 (hash값이 같으면)
Key가 필요할 때
- 유저 단위 액션 처리
- 주문 단위 이벤트 처리
- 특정 그룹의 트랜잭션 순서 유지
이런 케이스에서는 반드시 Key를 설정해야 한다.
But, Key가 없다면 ?
P0 → P1 → P2 → P0 → P1 → ...이렇게 돌아가면서 메시지를 분배한다.
즉 Round-robin 방식으로 Partition을 골라넣는다.
다음 내용에서 더 자세하게 알아보자.
Kafka를 적용할 업무에 대한 순서의 중요도를 잘 판단하여 Key의 유무를 선택하면 되겠다.
5. Sticky Partitioner: Kafka 2.4 이후 기본 Partitioner
Kafka의 Producer는 여러 메시지를 Batch 단위로 묶어서 보내면 성능이 크게 향상된다.
하지만 기존 Round-Robin 방식은 이 batch 효율을 깨뜨리는 문제가 있었다.
Sticky Partitioner는 이 문제를 해결하기 위해 나온 설계다.
기존 Round-Robin 문제점
Kafka 2.4 이전에는 Key가 없을 때 partition을 이렇게 정했다:
P0 → P1 → P2 → P0 → P1 → P2 …즉, 매 메시지마다 다음 partition으로 넘어가는 방식
문제는?
Producer는 내부적으로 아래 구조를 가진다.
- partition별로 batch buffer가 따로 존재한다
- 같은 partition에 메시지가 많이 들어와야 batch 크기가 커진다
Round-Robin은 메시지를 골고루 흩뿌리기 때문에
- 모든 partition의 batch가 1~2개씩밖에 쌓이지 않음
- batch 사이즈가 작아서 네트워크 호출이 증가함
- Producer 성능 저하
즉, 너무 균등하게 분산하는 바람에 오히려 성능이 떨어졌음.
Sticky Partitioner의 핵심 아이디어
“일단 한 Partition에 몰아서 보내자”
Sticky Partitioner는 이렇게 동작한다.
- 현재 선택된 Partition이 하나 있다
- Key가 없는 모든 메시지가 당분간 그 Partition에 계속 append됨
- batch가 꽉 차거나 timeout이 지나면
- 그제서야 다른 Partition으로 스위칭
[단계 1] P0에 계속 보내기 → batch 크기 크게
→ Flush / 전송 후
[단계 2] P1에 계속 보내기 → batch 크기 크게
→ Flush 후
[단계 3] P2에 계속 보내기 → …이 구조라서 균등 분산 + 높은 batch 효율을 모두 얻는다.
Sticky Partitioner의 장점
-
batch 크기 증가 → Producer TPS 상승
- 같은 partition에 몰아서 보내므로 큰 batch가 만들어진다.
- 큰 batch = 네트워크 호출 횟수 감소 = TPS 증가
-
Broker/Network 효율 향상
큰 batch는 압축 효율도 좋아서
- throughput 증가
- 네트워크 사용량 감소
-
partition 편중 문제 없음
처음 들으면 "한 partition에 몰아서 보내면 한쪽이 터지는거 아니야?"라고 걱정하지만 Kafka는 다음을 기준으로 자연스럽게 partition을 변경한다.
- batch.max.size
- linger.ms
- buffer pool pressure
그래서 장기적으로는 Partition 분산이 이루어진다.
6. Partition 수 설계 기준 (실무 관점)
실무에서 Partition 개수를 어떻게 정하는가?
아래는 실제 Kafka 운영팀에서 사용하는 기준들이다.
1) 필요한 처리량 기준
Partition 하나는 대략 다음 정도 처리한다:
- SSD 기준: 초당 5~50MB
- HDD 환경: 초당 2~10MB
필요한 Topic 처리량 / Partition 성능 = Partition 개수
예를들어, 로그성 데이터가 초당 300MB 들어오는 Topic이 있다면
필요 처리량 300MB/s
SSD 파티션 1개 성능 약 30MB/s 라고 하면
300 / 30 = 10개의 파티션 필요즉, 이 Topic은 최소 10 partition이 필요하다는 계산이 나온다.
2) Consumer 확장성
Consumer Group 확장 한계는 Partition 수이다.
예를들어,
Partition이 12개 → Consumer 최대 12개까지 병렬 처리 가능
Consumer를 20대까지 늘리고 싶다면 Partition을 20개 이상 만들어야 한다.
3) Replication 비용 고려
Replication Factor가 3이고 Partition이 30개라면?
브로커 전체에 총 90개의 파티션 replica가 저장됨
Partition 수가 많아질수록
- 복제 트래픽 증가
- 재배치(rebalance) 비용 증가
- Broker 메모리 관리 비용 증가
적당한 선에서 잡아야 한다.
4) 운영 난이도
Partition이 너무 많으면 다음이 문제가 된다.
- Rebalance 오래 걸림
- Controller 부하 증가
- Cluster 재시작 시 재할당 시간 증가
- Monitoring key 수 증가
진짜 대규모(high throughput) 서비스가 아니라면 무작정 Partition을 늘리는 건 오히려 해가 된다.
5) 일반적인 권장치
Kafka 운영 경험이 많은 기업들은 다음과 같은 기준을 사용한다.
| 서비스 규모 | Partition 개수 | 설명 |
|---|---|---|
| 일반적인 업무 서비스 | 6–12개 | 웹 로그, 인증 이벤트 등 평범한 트래픽 |
| 고부하 이벤트 스트림 | 24–48개 | 주문, 결제, 센서 스트림 등 고처리량 |
| 초대규모 트래픽 | 100개 이상 | 전문 Kafka 운영팀 + 자동화 툴 필수 |
| 대기업 데이터 플랫폼 | 300~1,000개 | (하지만 운영 난이도 매우 높음) |
대부분의 서비스는 사실 6~24개만 돼도 충분하다.
7. 정리
Partition은 Kafka의 성능과 확장성을 만들어내는 가장 중요한 구조다.
핵심 포인트는 다음과 같다.
- Partition은 병렬 처리의 기본 단위다.
- 순서 보장은 Partition 내부에서만 이루어진다.
- Key 기반 routing은 순서를 유지하는 핵심이다.
- Kafka 2.4 이후에는 Sticky Partitioner가 기본
- Partition 개수는 처리량·복제 비용·운영 난이도를 종합해서 결정해야 한다.
Partition 구조를 확실히 이해하면 Offset, Consumer Group, ACK, Replication 같은 다음 개념들이 훨씬 명확해진다.
