Kafka가 높은 가용성과 데이터 일관성을 유지할 수 있는 이유는
Replication(복제) 구조가 매우 강력하게 설계되어 있기 때문이다.
Replication Factor, ISR, LEO/HW, ACKS, commit 조건 등을 정확히 이해하면
다음과 같은 상황을 스스로 분석할 수 있다.
- 데이터가 언제 “정말로 안전하게 저장되었는지”
- 브로커 장애 시 어떤 Replica가 Leader가 되는지
- 왜 메시지가 중복/유실되는지
- ack=all이 왜 중요한지
- 복제 지연(replica lag)이 왜 문제가 되는지
이번 편에서는 Kafka 복제 구조의 핵심 개념을 아주 상세하게 설명한다.
1. Replication Factor
Replication Factor는 하나의 Partition이 몇 개의 복제본(replica)을 가지는지 의미한다.
예: Replication Factor = 3
→ Leader 1개 + Follower 2개
복제본이 많을수록 장애에 강해지지만, 그만큼 저장 비용·네트워크 비용이 증가한다.
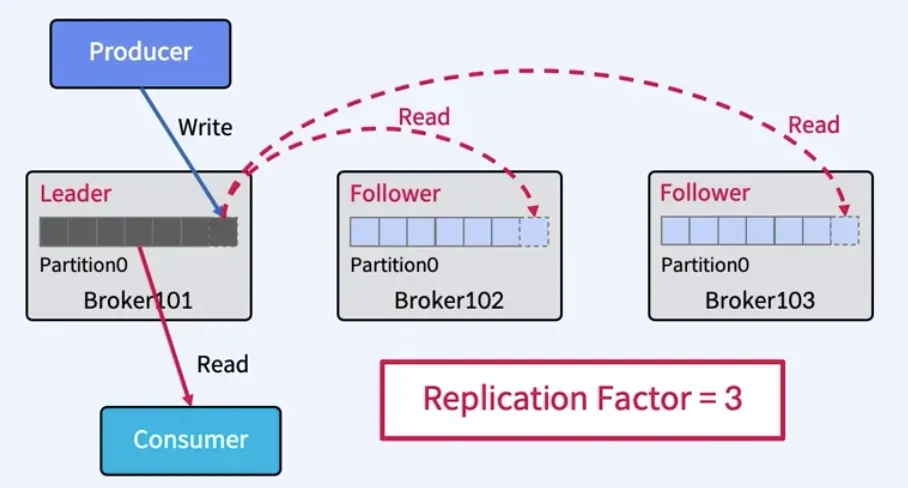
그림으로 다시보자.
1편에서도 등장했던 그림이다.
- Producer는 Leader(브로커101)에만 데이터를 기록하고, Follower들은 이를 그대로 복제한다.
- Consumer는 기본적으로 Leader에서 읽지만, 필요하면 Follower들도 동일한 데이터를 가진다.
- Replication Factor=3이므로 동일한 파티션 데이터가 브로커 3대에 저장되어 장애에도 안전하다.
2. Leader–Follower 구조
각 Partition은 여러 replica를 가지지만,
그중 Leader만 Producer/Consumer의 읽기·쓰기 요청을 처리한다.
Leader
- 유일하게 기록(write)을 처리
- Consumer가 읽는 대상
Follower
- Leader의 로그를 그대로 복제
- Leader가 새 메시지를 append하면 Follower는 pull 방식으로 따라감
- Lag가 너무 크면 ISR에서 제외됨
Kafka의 복제는 “push가 아닌 pull 구조”이기 때문에
Follower가 빠지거나 느려져도 Leader가 성능 저하 없이 움직일 수 있다.
3. ISR(In-Sync Replica)의 조건
ISR은 “Leader와 거의 동일한 데이터를 가진 Replica들의 집합”이다.
ISR에 포함되기 위한 조건(핵심):
- Leader와 LEO 차이가
replica.lag.time.max.ms를 넘지 않을 것 - Follower가 장애 상태가 아닐 것
- Follower의 네트워크 지연이 너무 크지 않을 것
ISR에 포함된 Replica만 데이터 일관성이 있다고 본다.
ISR의 특징
- Leader는 메시지를 append한 뒤, ISR 내 replica들이 따라올 때까지 기다린다.(ACK=all일 경우)
- ISR이 1개(=Leader 혼자)만 남아도 Kafka는 쓰기 작업을 진행할 수 있다.
- ISR 밖 Replica는 “데이터가 뒤쳐진 상태”로 간주되며, Leader 장애 시 새로운 Leader로 승격될 수 없다.
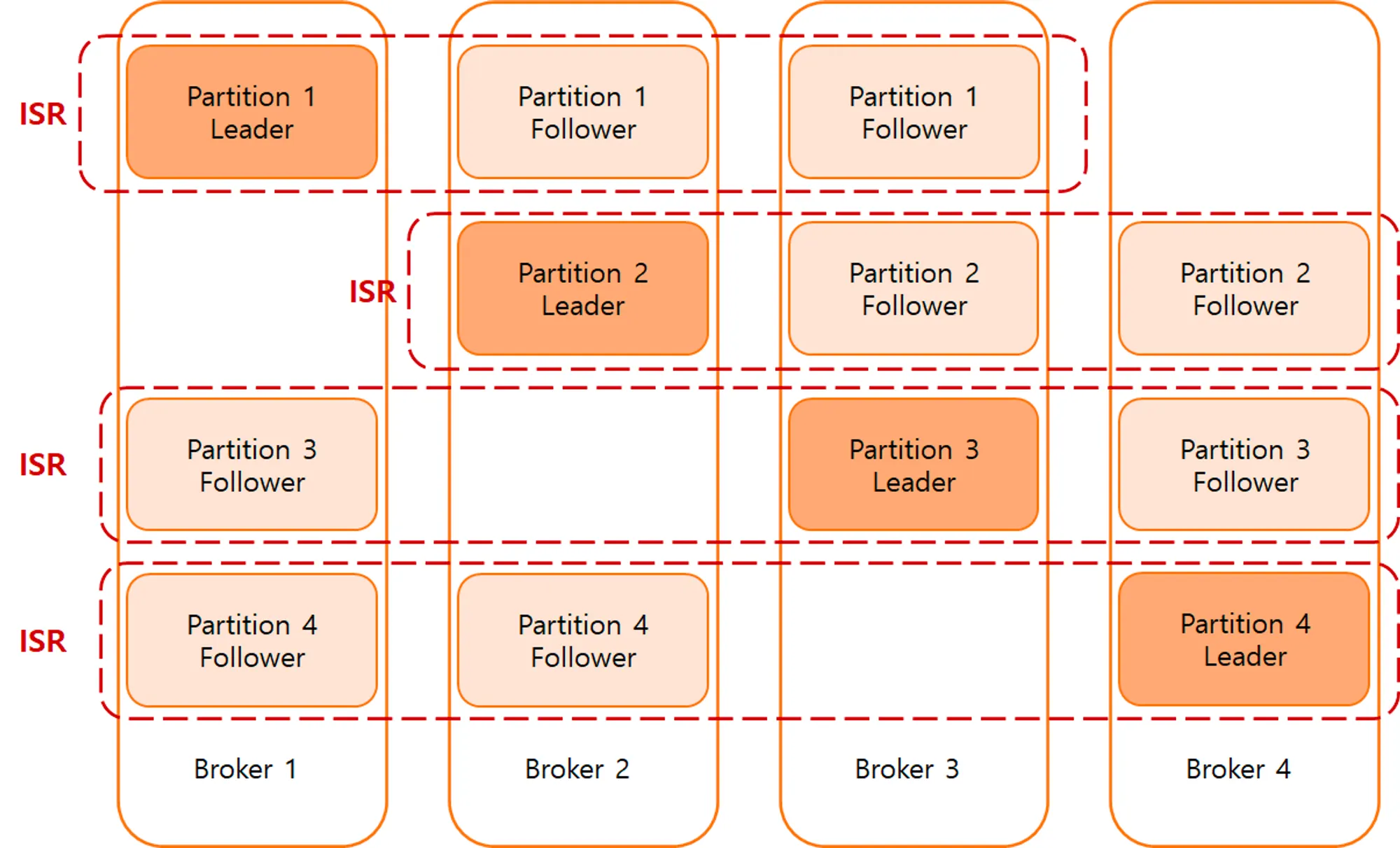
그림으로 다시보자.
- 각 Partition마다 Leader는 하나, Follower는 여러 개이며 이 전체가 ISR(In-Sync Replica) 그룹을 이룬다.
- ISR 안의 Leader만이 Producer/Consumer 요청을 처리하고, Follower들은 Leader의 로그를 뒤에서 따라간다.
- Broker들이 여러 대일 때 Partition의 Leader가 분산되어 클러스터 전체에 부하가 균형 있게 퍼진다.
4. LEO(Log End Offset) vs HW(High Watermark)
Replication 구조를 이해하려면 LEO와 HW의 차이를 반드시 이해해야 한다.
LEO(Log End Offset)
Replica가 가진 “마지막 메시지의 Offset + 1”
→ Replica는 Leader와 Follower 전체를 의미한다.
쉽게 말해
- LEO = “내 로그는 여기까지 도착했다.”
예시:
- Leader가 offset 0, 1, 2까지 메시지를 append했다면 → Leader의 LEO = 3
- Follower는 replication이 밀려서 offset 0, 1까지만 복제했다면 → Follower의 LEO = 2
Leader와 Follower 각각 LEO를 가진다.
HW(High Watermark)
클라이언트가 읽을 수 있는 최대 Offset
즉, “모든 ISR replica에 복제 완료된 가장 마지막 위치”
Leader는 HW까지만 Consumer에게 데이터를 노출한다.
정리하면
- LEO = 각 Replica의 로그 끝
- HW = 모든 ISR에서 공통으로 가진 위치
- Consumer는 “HW 이하” 데이터만 읽을 수 있다
즉, 메시지가 LEO에 append되었다고 해서 바로 Consumer가 읽을 수 있는 것은 아니다.
ISR 전체가 복제 완료되어야 HW가 증가한다.
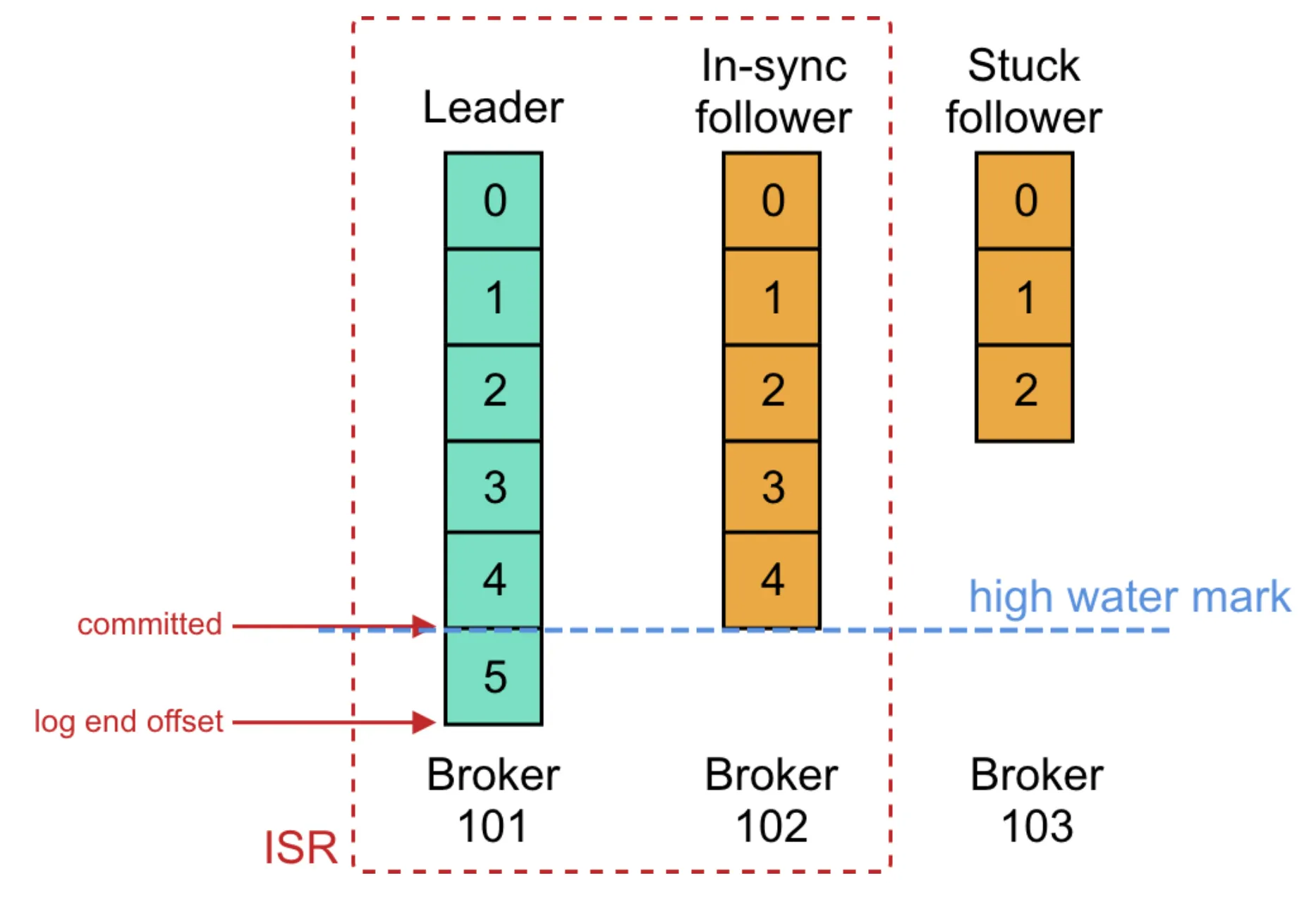
그림으로 다시보자.
- Leader와 In-Sync Follower(ISR)는 offset 0~4까지 동일하게 복제되어 있고, Leader는 5까지 도달해 LEO가 더 크다.
- ISR 모두가 공통으로 가진 마지막 offset(=4)이 High Watermark(HW)로 설정된다.
- Stuck Follower는 ISR에서 제외되며, Consumer는 HW(=4) 이하의 메시지만 읽을 수 있다.
5. 메시지는 언제 “커밋”되는가?
Kafka에서 말하는 "commit"은 다음 상태를 의미한다.
메시지가 ISR 모든 Replica에 복제되면 → HW 증가 → Consumer가 읽을 수 있게 됨
이 상태가 Kafka의 commit이다.
commit = HW가 그 메시지를 포함하도록 이동한 시점 Producer가 Leader에 append한 시점이 아니라,
ISR의 모든 replica가 해당 메시지를 가져가서 LEO를 끌어올린 순간 commit된다.
Producer가 메시지를 보낸 시점 < HW 포함된 시점
이 둘은 완전히 다른 사건이다.
6. Producer ACKS=all과 ISR의 관계
Producer는 메시지를 전송할 때 다음과 같은 ACK 모드를 선택할 수 있다.
- acks=0
- acks=1
- acks=all (or -1)
각 설정은 Replication과 밀접하게 연결된다.
acks=0
- Leader에 기록되었는지 확인하지 않음
- 최저 지연 / 최대 유실 위험
acks=1
- Leader에 기록되었음을 확인
- Follower 복제는 무시
- Leader 장애 시 데이터 유실 발생 가능
acks=all (or -1)
- Leader와 ISR 모든 replica에 복제되어야 성공 응답
- Follower가 살아 있어야 함
- 높은 내구성(Durability)
- 유실 방지 → 실무에서 가장 권장
즉, Replication 구조를 제대로 활용하려면 “acks=all”은 사실상 필수이다.
특히 금융/결제/주문 시스템은 반드시 acks=all 사용
7. Replication이 깨질 때 발생하는 문제들
Replication 문제는 대부분 Follower lag이나 브로커 장애에서 시작된다.
아래는 실제 운영 환경에서 자주 발생하는 문제들이다.
A. Follower lag 증가 → ISR에서 제외
Follower가 Leader 속도를 따라오지 못하면 ISR에서 빠진다.
결과:
- acks=all 모드에서는 Producer write 실패
- 리더 혼자 ISR이 되어 durability 약화
B. Leader 장애 → 새로운 Leader 선출
새 Leader는 ISR에 포함된 Replica 중 하나에서만 선출된다.
ISR 밖에 있던 Replica는 데이터가 뒤쳐져 있으므로 선출 불가
문제는?
- ISR이 Leader 혼자만 있던 상황이면 → Leader 장애 시 Partition이 잠시 동안 unavailable
- Replication Factor 1이면 → 아예 데이터 유실
C. Unclean Leader Election
설정을 잘못하면 Kafka는 ISR이 아닌 Replica를 Leader로 승격할 수 있다.
un clean leader election = true 일 때
- 뒤쳐진 Replica가 Leader가 됨
- 데이터 역순서, rollback, 복구 불가능한 유실 발생
그래서 실무에서는 반드시 다음처럼 설정한다.
unclean.leader.election.enable=falseD. Network partition으로 인한 split-brain
Leader가 잘 살아 있지만 Follower들이 네트워크 단절로 ISR에서 빠지는 현상
잘못된 설정 시 데이터 충돌이나 재조정 지연 발생
E. Replica 재동기화 비용 급증
Follower가 매우 뒤쳐져 있을 경우
Leader와 오랜 시간 동안 대량 데이터 동기화를 해야 함 → 성능 저하 & Rebalance 지연
8. 정리
Kafka의 Replication 구조는 단순한 백업 기능이 아니다.
다음의 중요한 역할을 모두 수행한다.
- Leader–Follower 구조로 고가용성 확보
- ISR로 Replica 정합성 유지
- HW와 LEO로 데이터의 “안전한 상태” 구분
- Producer ACK 설정에 따라 durability가 크게 좌우
- Follower lag, ISR 축소, Leader 장애는 운영 핵심 이벤트
- unclean leader election 설정은 반드시 OFF
Replication 구조를 제대로 이해하면
Kafka에서 발생하는 유실·중복·지연·Failover 문제의 90% 이상을 설명할 수 있다.
