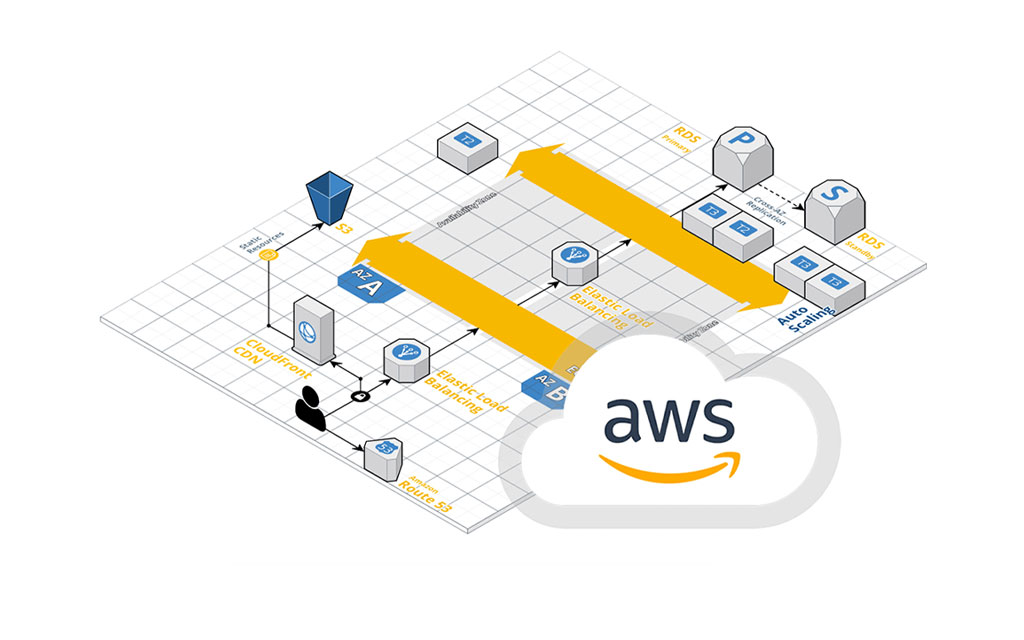
AWS Auto Scaling 그룹을 이용한 다중 서버 구성
AWS 인프라 구축 가이드 p44
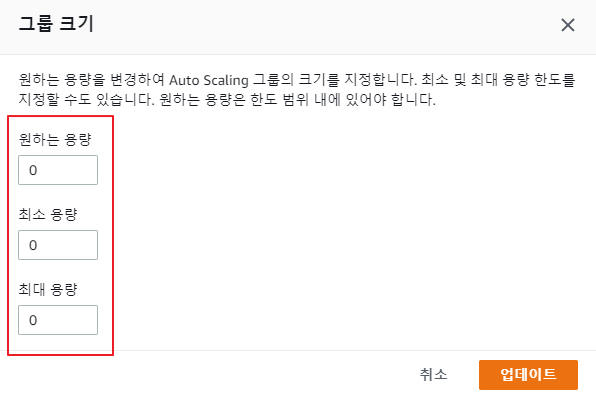
1. Auto Scaling 그룹 생성(p48)
-
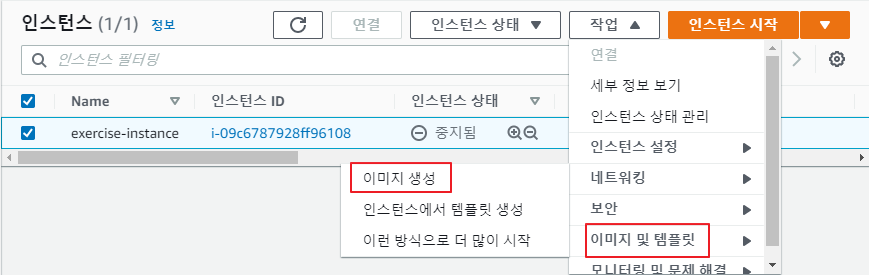
인스턴스 중지

-
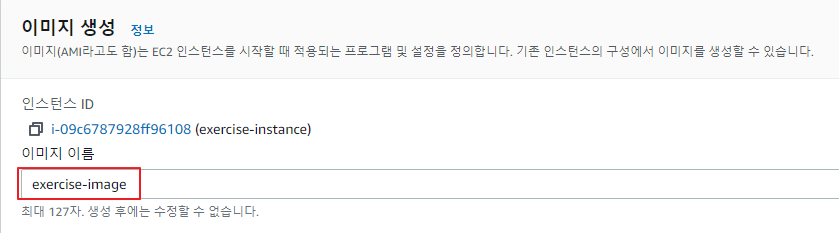
스냅샷 생성
-
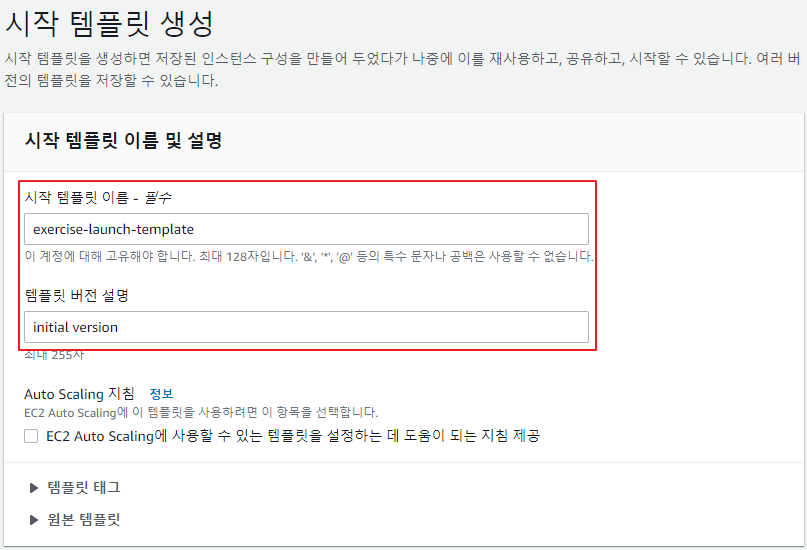
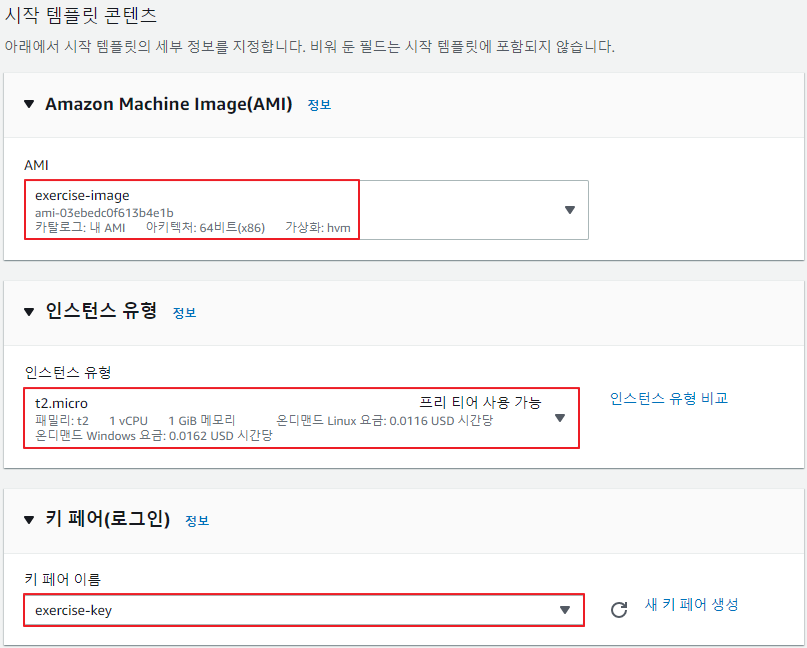
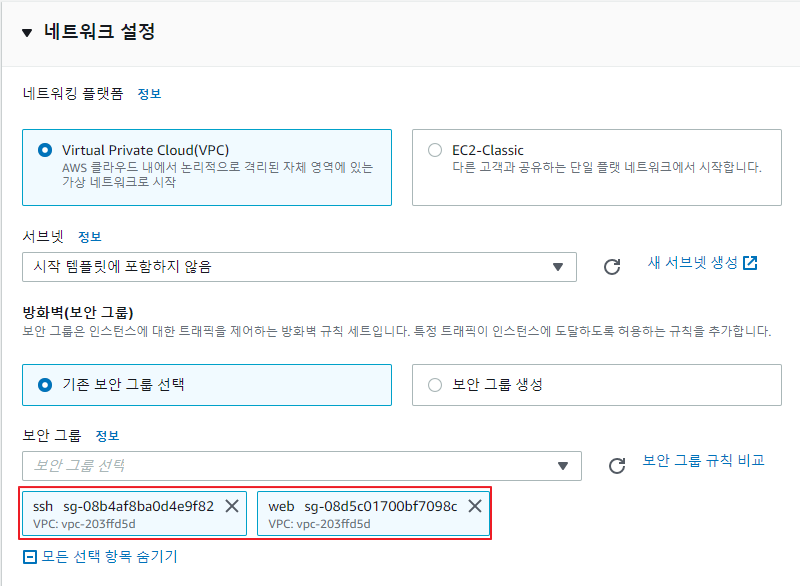
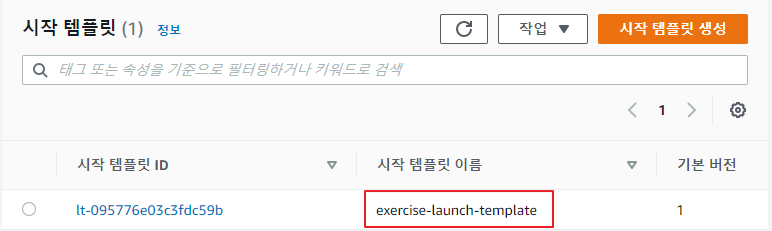
시작 템플릿 생성

-
Auto Scaling 그룹 생성

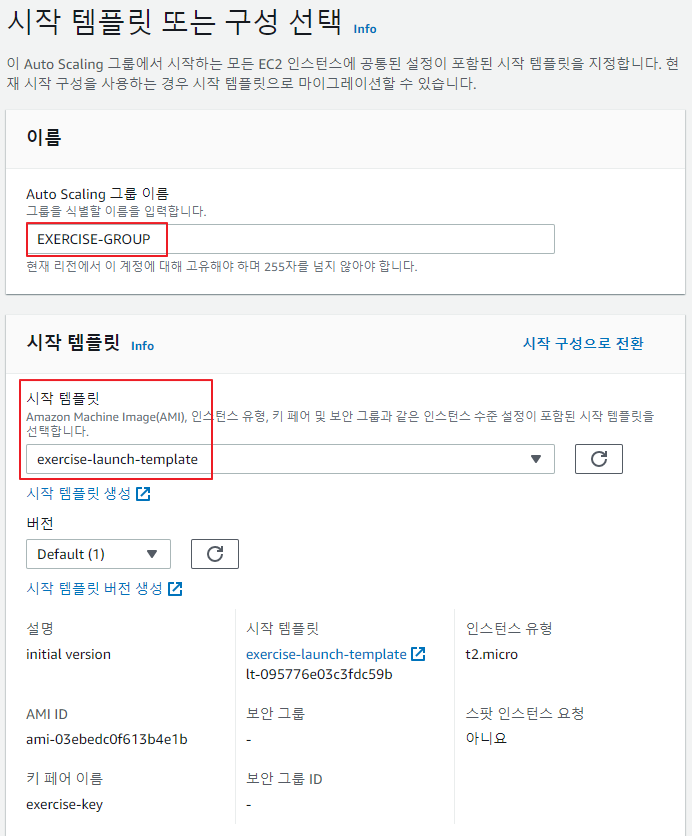
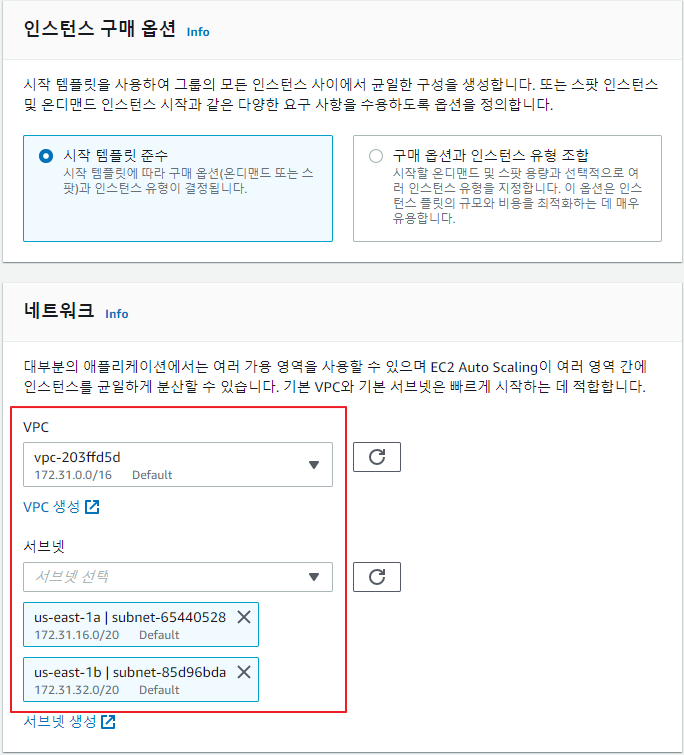
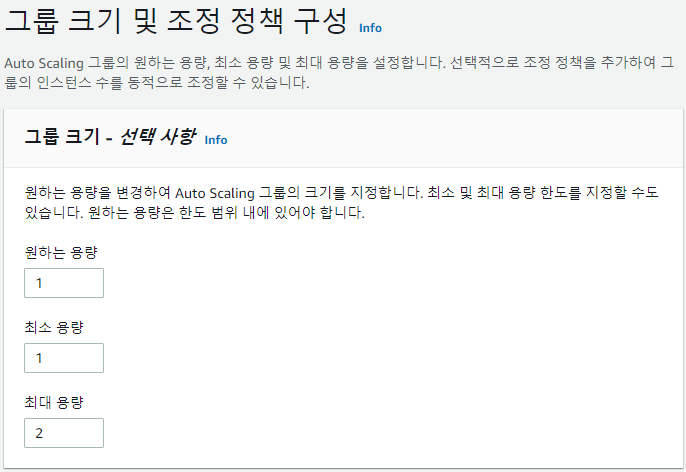
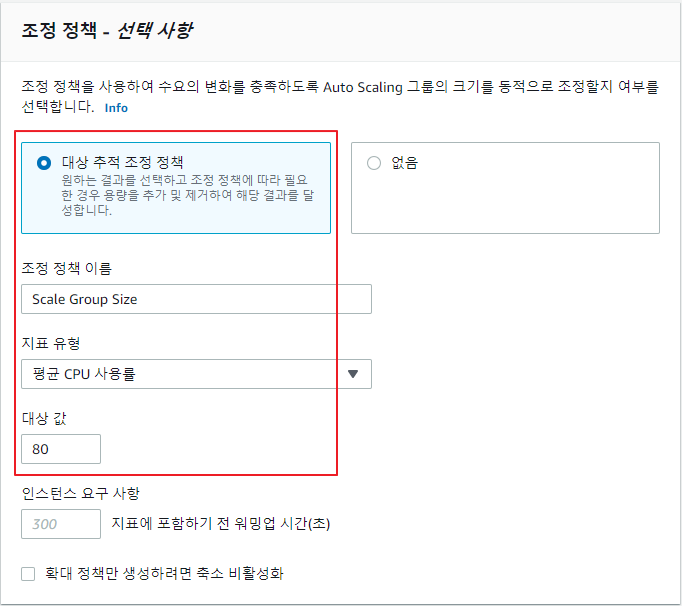
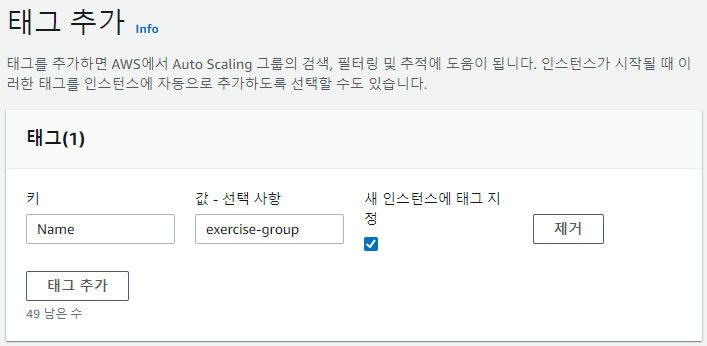
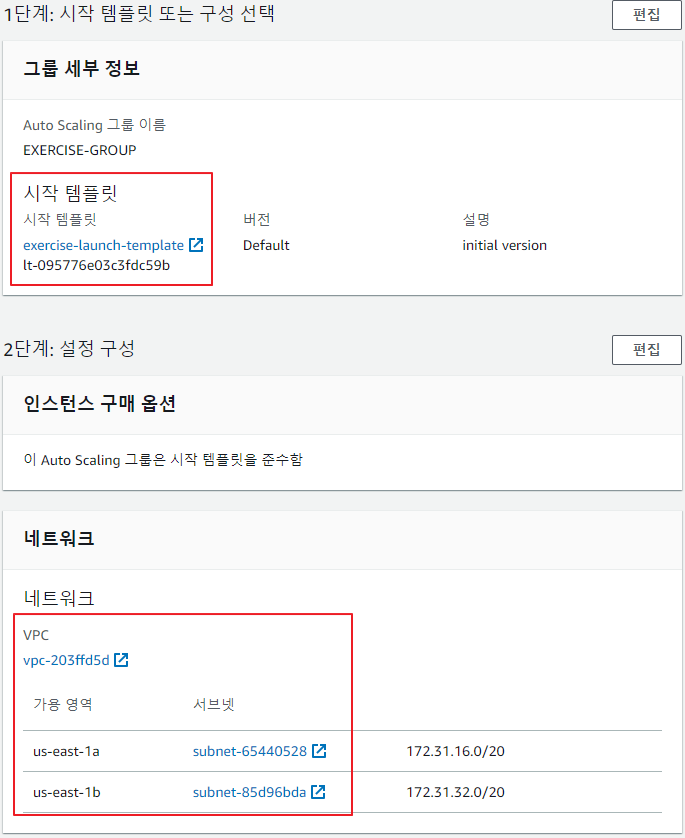
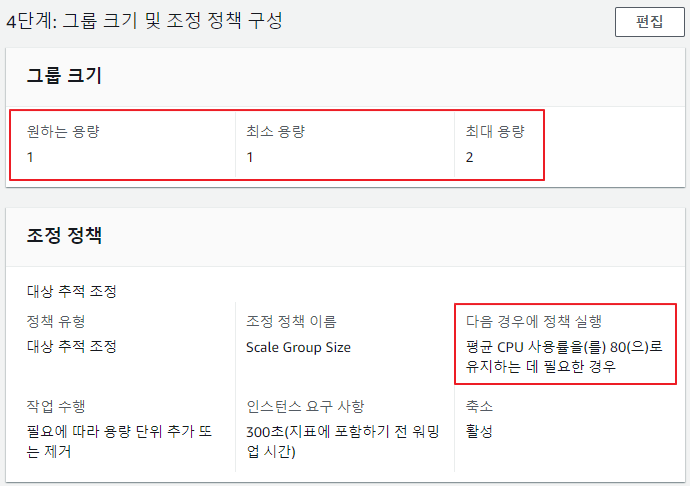
-
Auto Scaling Group 설정에 인스턴스를 모두 종료
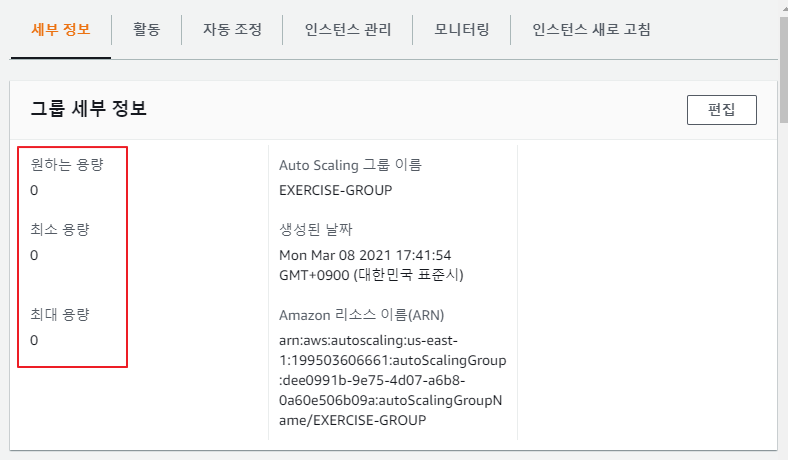
2. CPU 사용 부하를 주어 auto scaling 기능 확인
-
다시 Auto Scaling 그룹 구성을 변경
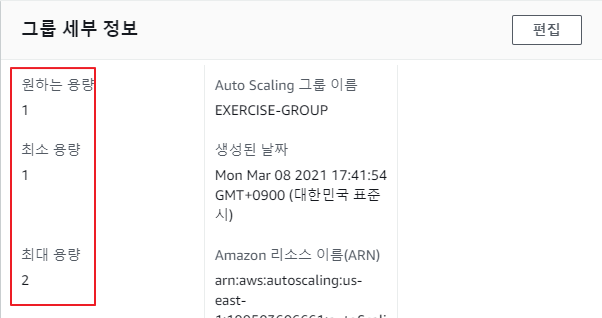
-
인스턴스 실행을 확인
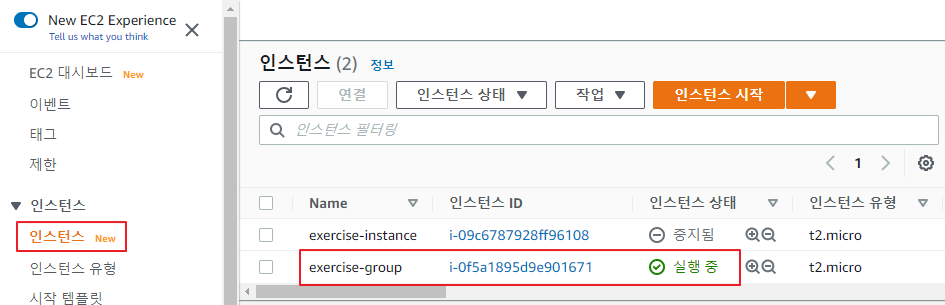
-
실행 중인 인스턴스에 SSH 접속
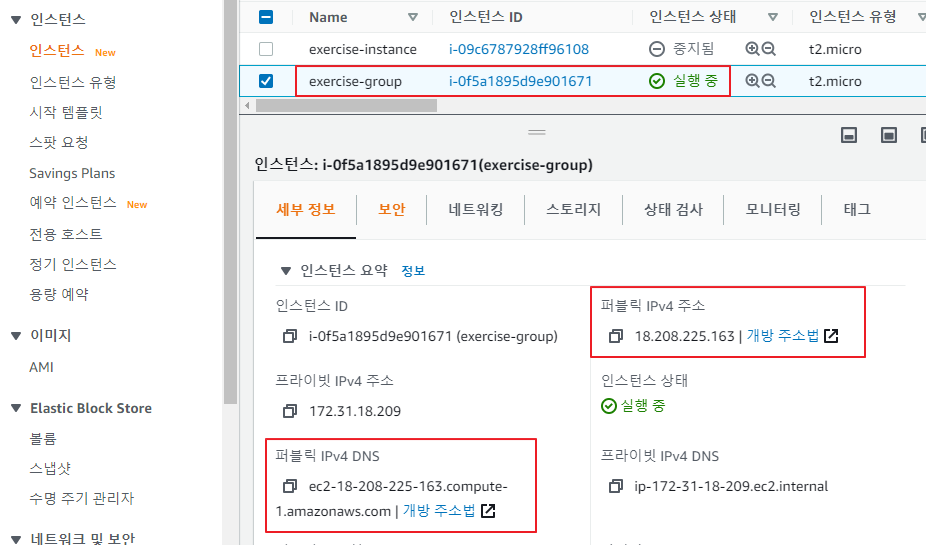
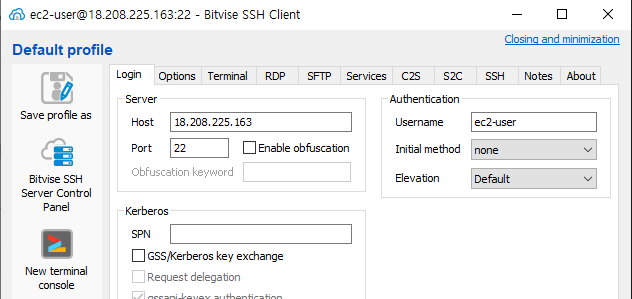
-
stress 프로그램을 이용해서 CPU 사용량을 증가
-
$
sudo yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm -
$
sudo yum install stress -y -
$
stress --cpu 1 --timeout 600
-
-
인스턴스의 증감을 모니터링
-
$
top -
CPU 사용량 100%로 증가
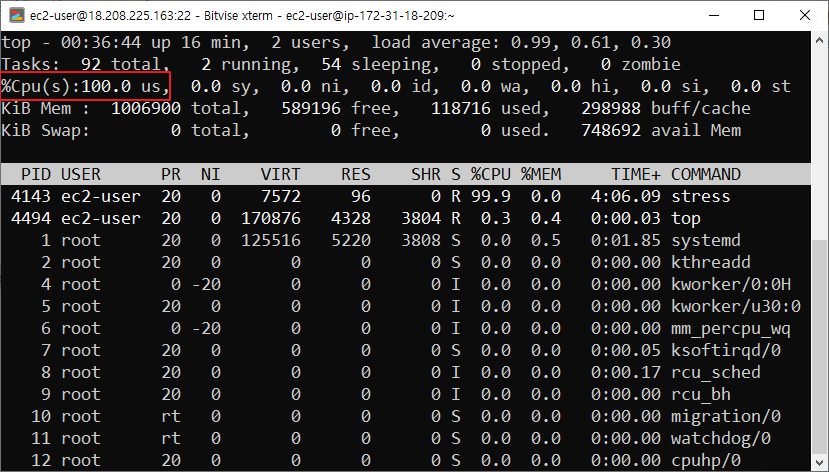
-
자동으로 인스턴스가 추가된 것을 확인
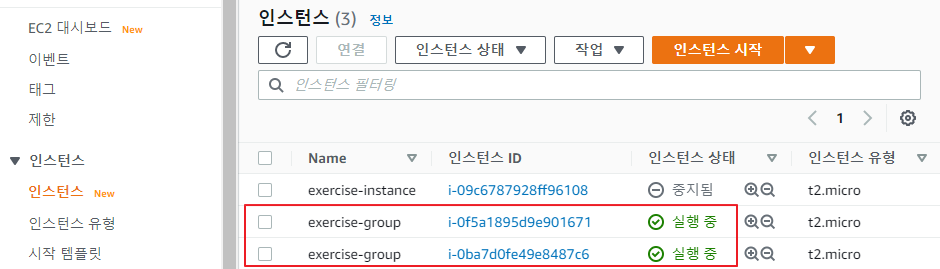
-
부하가 감소하면
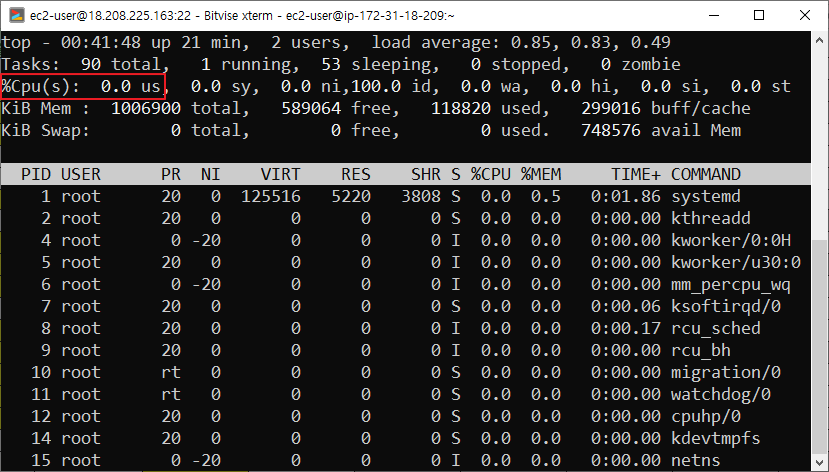
-
자동으로 인스턴스가 감소하는 것을 확인

-
3. AWS ELB(Elastic Load Balancing)을 이용한 서버 트래픽 분산 관리(p62)
-
로드 밸런서 생성



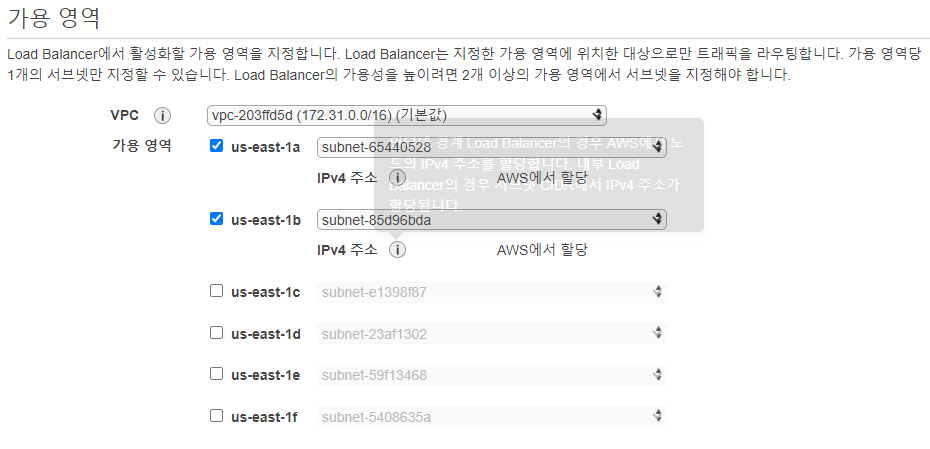
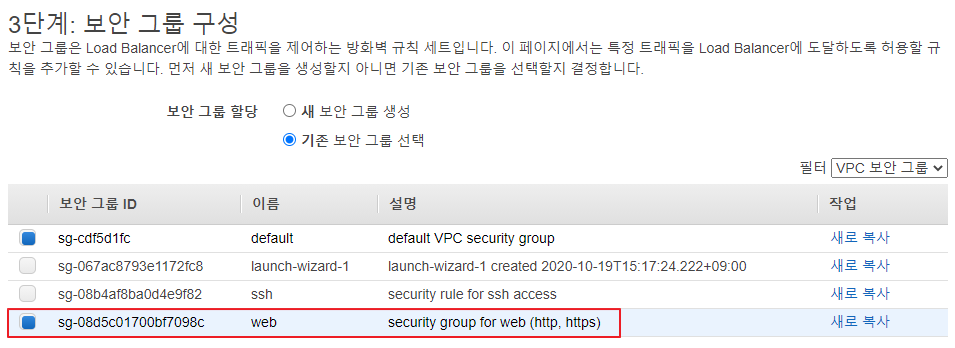
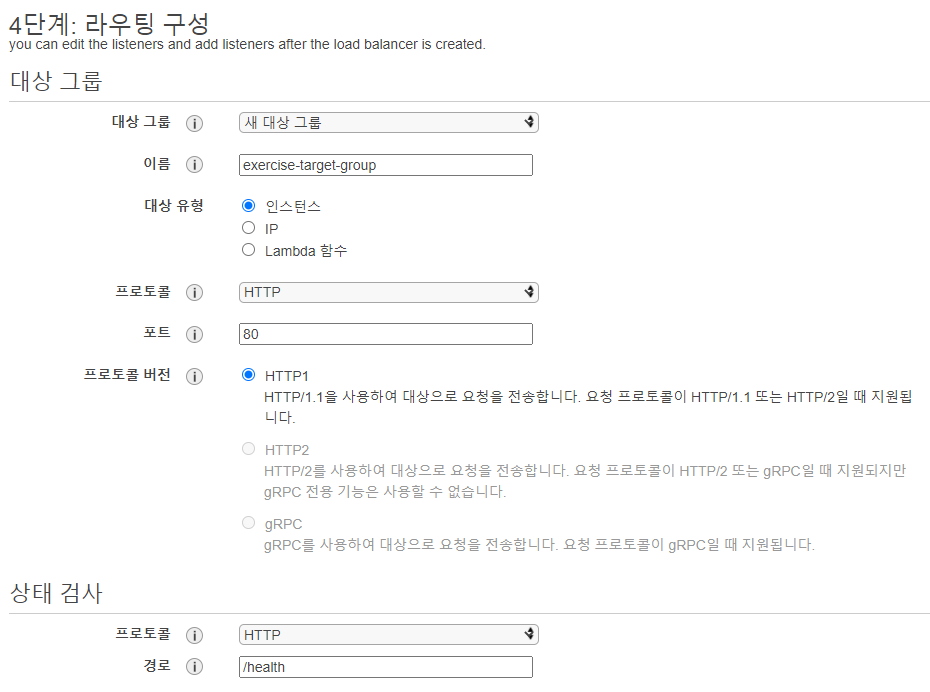
-
app.js 파일에 헬스 체크 URL 확인
app.get('/health', (req, res) => { ⇐ /health 로 GET 방식의 요청이 들어오면 res.status(200).send(); 응답 상태코드의 값을 200으로 설정해서 반환 }); -
대상 그룹에 Auto Scaling Group을 추가할 예정이므로, 인스턴스를 직접 추가하지 않는다.
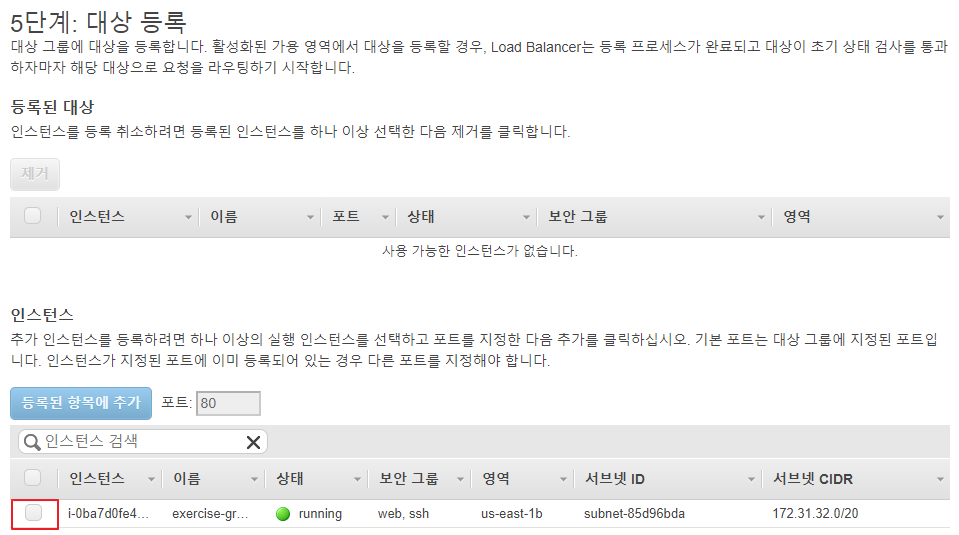
-
로드 밸런서 생성
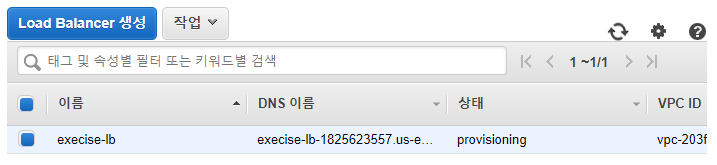
4. Auto Scaling 그룹을 로드 밸런싱 대상 그룹에 추가
-
Auto Scaling Group에서 로드 밸런싱 편집
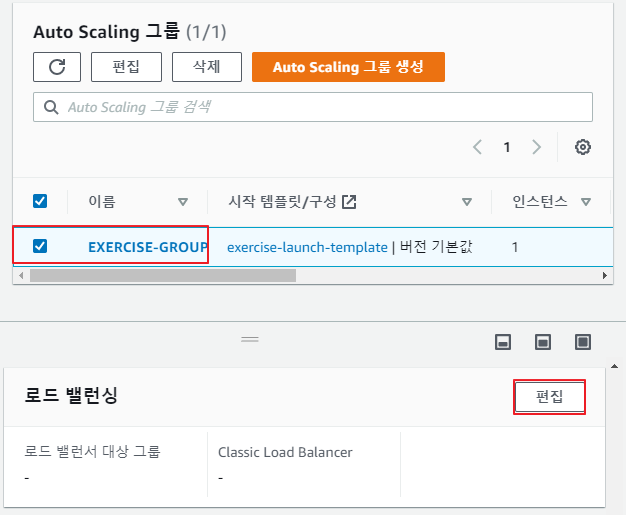
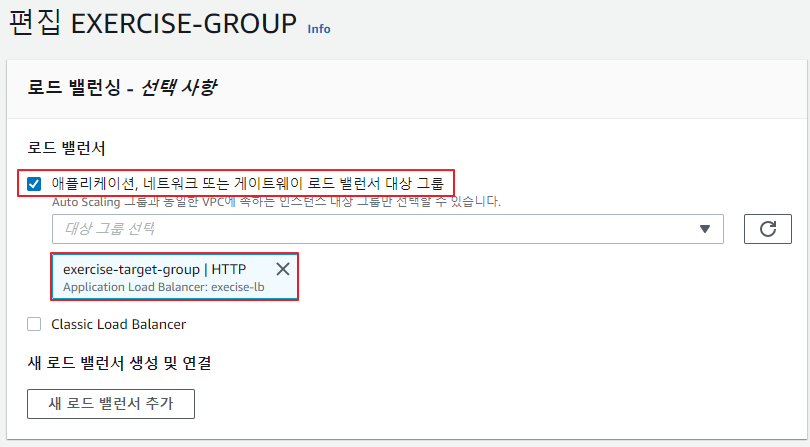
-
헬스 체크 확인
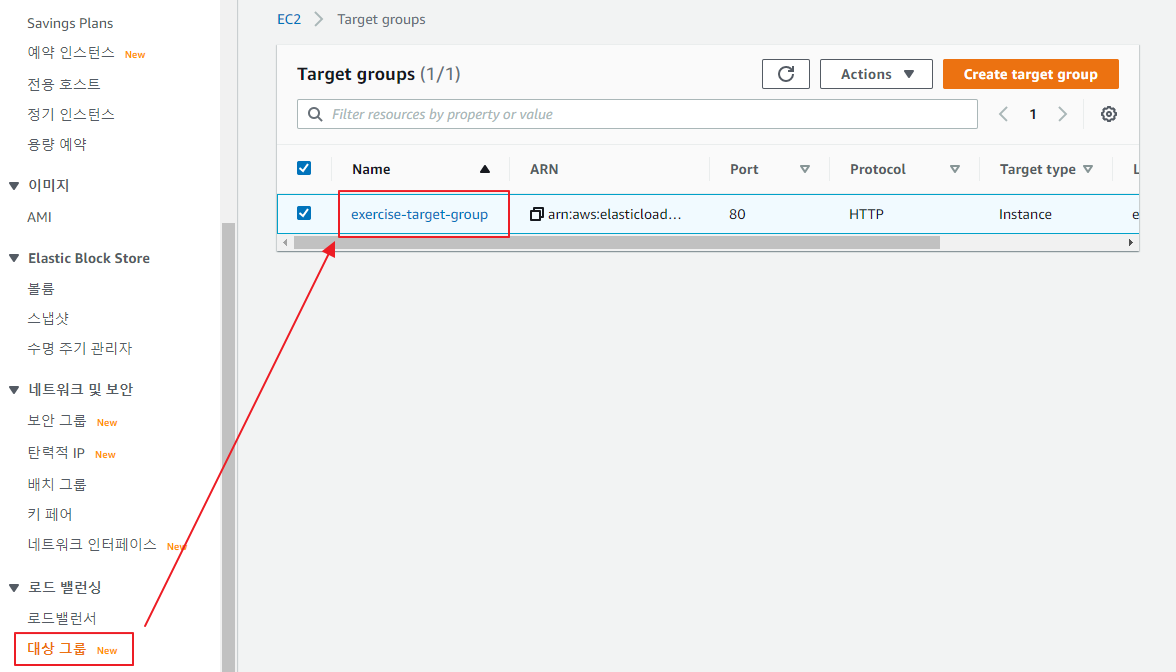
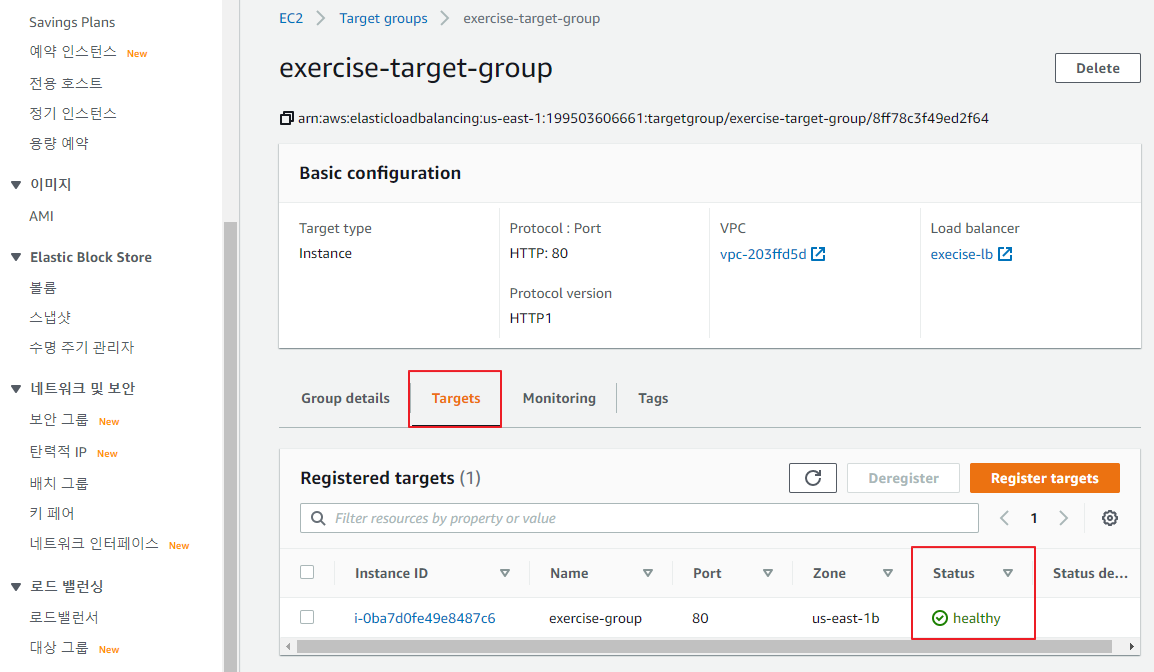
-
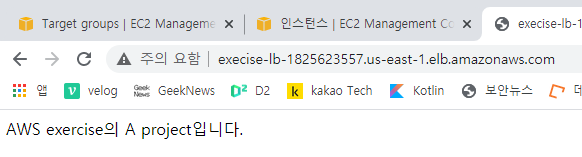
로드 밸런스를 통한 접속 확인
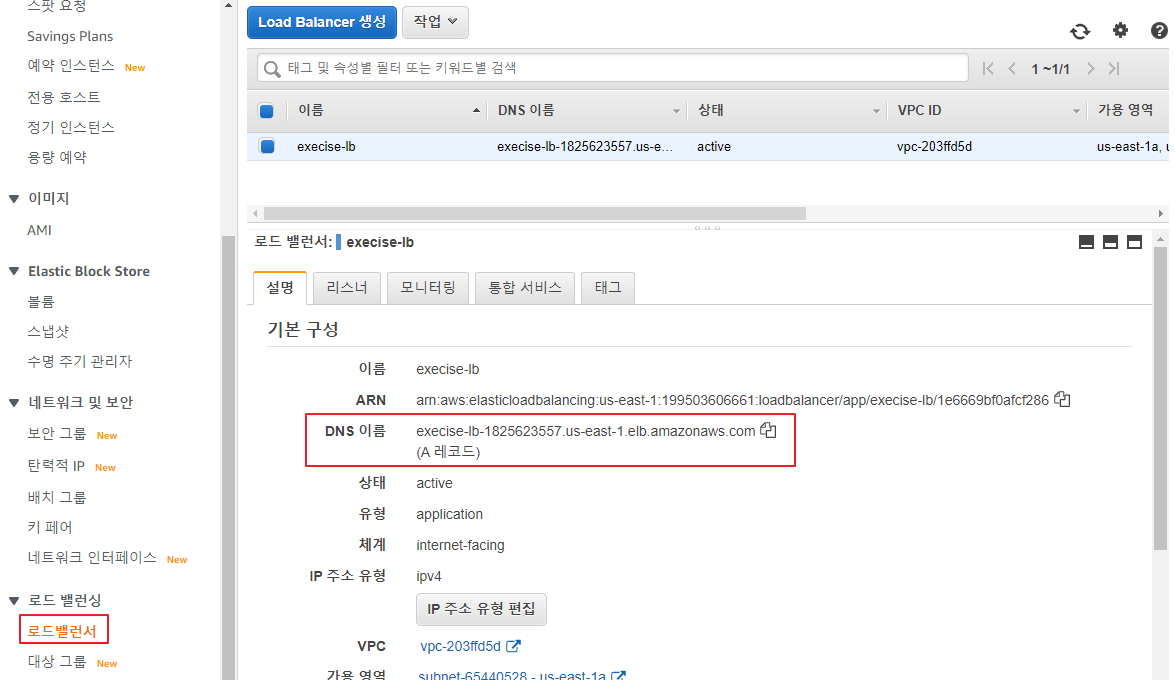
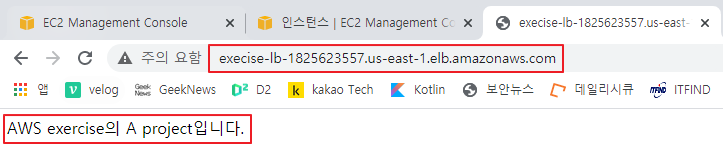
5. ASG(Auto Scaling Group)과 ELB(Elastic Load Balancer)를 이용한 장애 조치 (p73)
-
대상 그룹의 헬스 체크 설정 변경
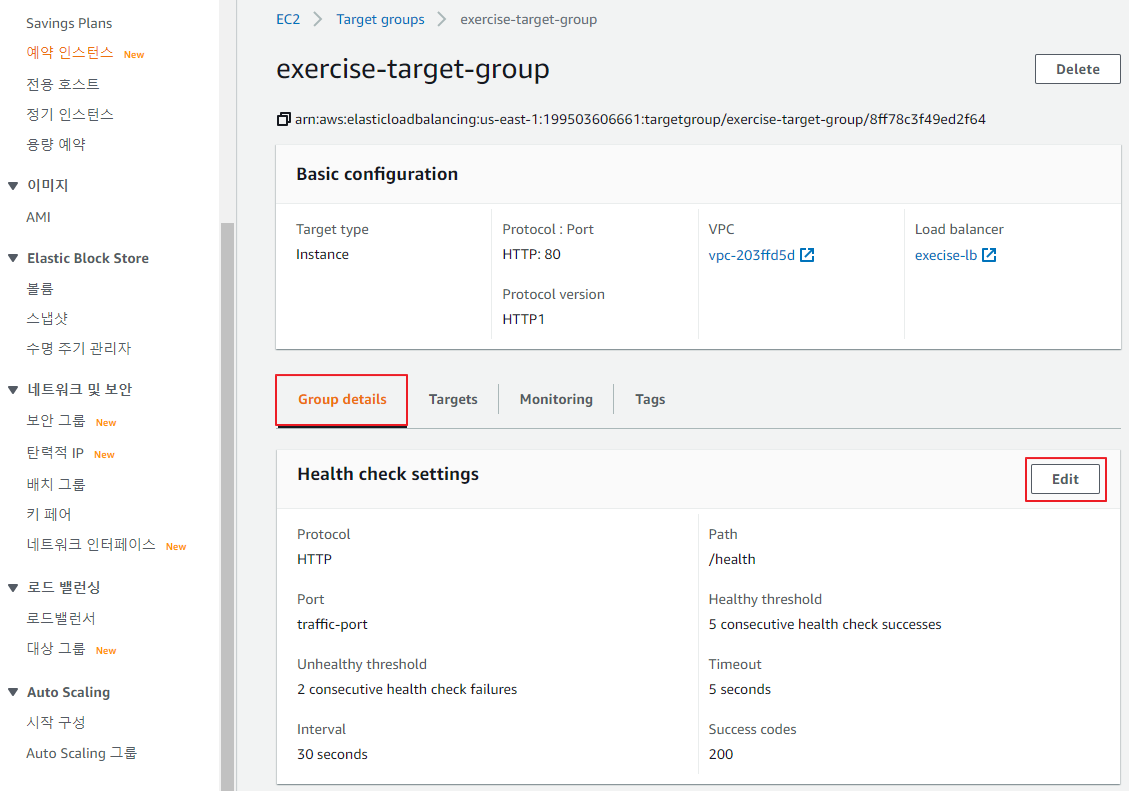
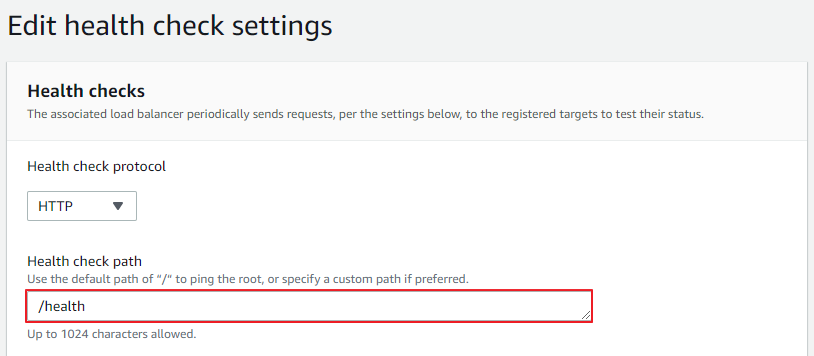
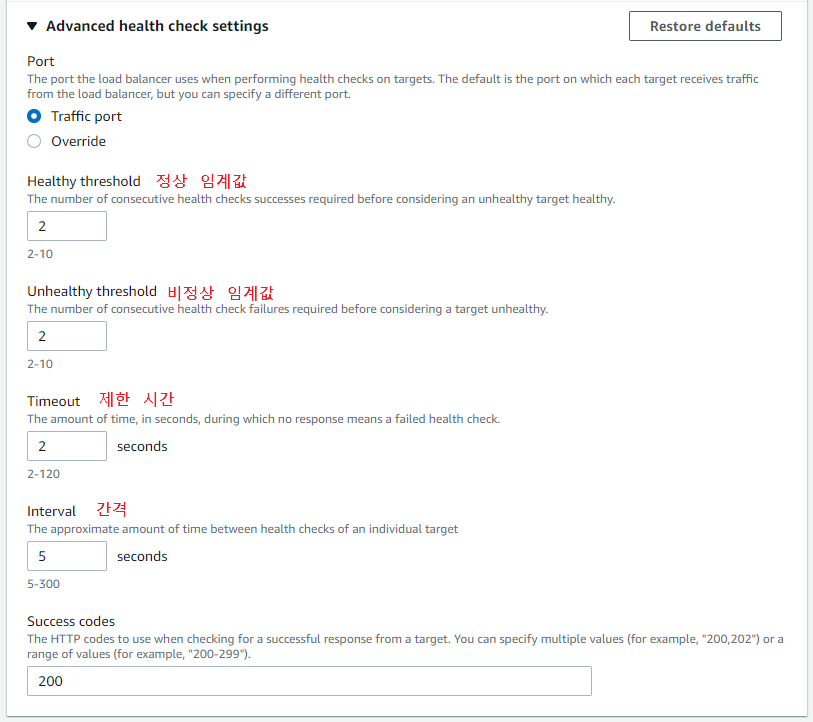
-
ASG의 용량을 변경
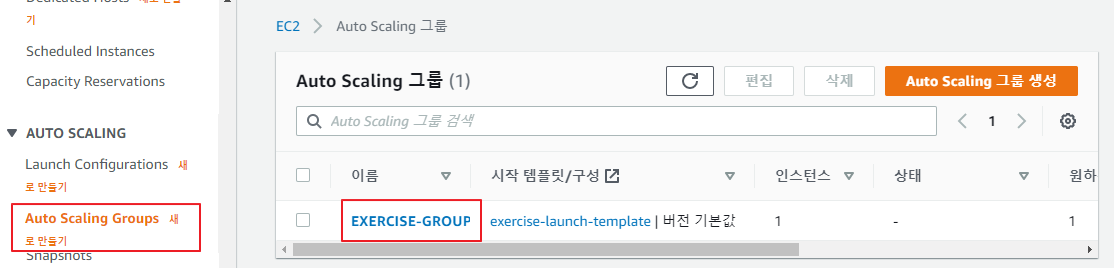
- 항상 인스턴스가 2개 실행되도록 설정을 변경
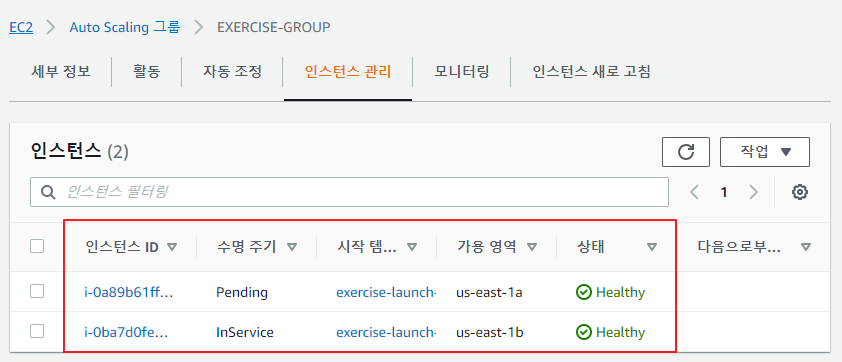
-
각 인스턴스로 SSH 접속해서 헬스 체크 확인
-
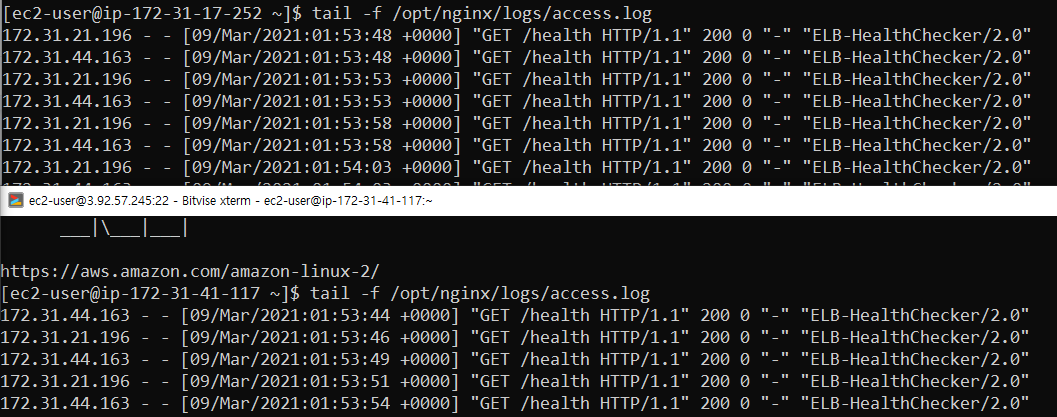
/opt/nginx/logs/access.logs 파일을 통해 헬스 체크 요청이 5초 간격으로 발생하는 것을 확인
tail -f /opt/nginx/logs/access.logs
-
-
인스턴스 중 하나의 nginx 서비스를 중지
-
$
sudo service nginx stop -
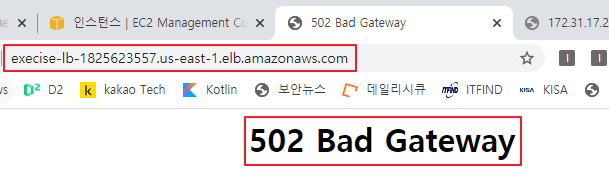
nginx 서비스 중지와 동시에 로드밸런서 퍼블릭 DNS 주소로 접속을 시도하면 502 Bad Gateway 오류가 발생
-
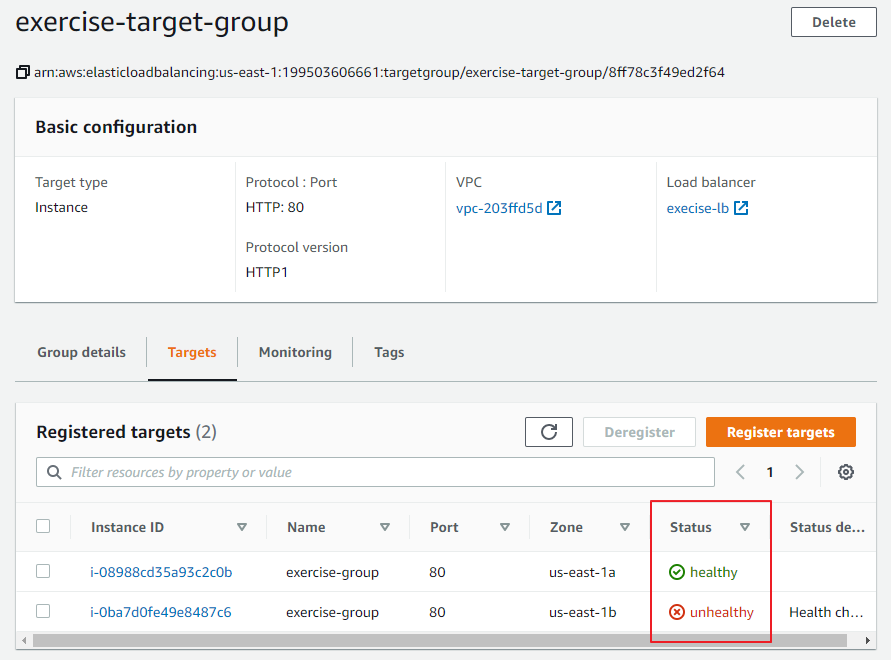
시간이 지난 후에는 정상적으로 동작하는 것을 확인
-
⇒ 정상적으로 동작(healthy)하는 인스턴스로만 요청을 전달
-
-
-
모든 인스턴스를 종료