웹 로봇은 사람과의 상호작용 없이 연속된 웹 트랜잭션들을 자동으로 수행하는 소프트웨어 프로그램이다. 방식에 따라 크롤러, 스파이더, 웜, 봇 등 다양한 이름으로 불린다.
9.1 크롤러와 크롤링
웹 크롤러는, 먼저 웹 페이지를 한 개 가져오고 그 다음 그 페이지가 가리키는 모든 페이지를 가져오고, 다시 그 페이지들이 그리키는 모든 웹 페이지들을 가져오는 일을 재귀적으로 반복하는 방식으로 웹을 순회하는 로봇이다.
크롤러들이 어떻게 동작하는지 더 자세히 살펴보자.
9.1.1 어디에서 시작하는가: '루트 집합'
크롤러가 방문을 시작하는 URL들의 초기 집합을 루트 집합(root set)이라고 부른다.
일반적으로 좋은 루트 집합은 크고 인기 있는 웹 사이트, 새로 생성된 페이지들의 목록, 그리고 자주 링크되지 않는 잘 알려지지 않은 페이지들의 목록으로 구성되어 있다.
이것은 시간이 지남에 따라 성장하며 새로운 크롤링을 위한 시드 목록이 된다.
9.1.2 링크 추출과 상대 링크 정상화
크롤러는 웹을 돌아다니면서 꾸준히 HTML 문서를 검색하며, 검색한 각 페이지 안에 들어있는 URL 링크들을 파싱해서 크롤링할 페이지들의 목록에 추가해야 한다.
또한 간단한 HTML 파싱을 통해 이들 링크들을 추출하고 상대 링크를 절대 링크로 변환할 필요가 있다.
9.1.3 순환 피하기
로봇이 웹을 크롤링 할 때, 루프나 순환에 빠지지 않도록 매우 조심해야 한다.
순환은 로봇을 함정에 빠뜨려 멈추게 하거나 진행을 느려지게 하므로, 이를 방지하기 위해 반드시 로봇이 어디에 방문했는지 알아야 한다.
9.1.4 루프와 중복
순환은 다음과 같은 이유로 크롤러에게 해롭다.
- 순환은 크롤러를 꼼짝 못하게 만들 수 있다.
- 크롤러가 같은 페이지를 반복해서 가져오면 고스란히 웹 서버의 부담이 된다.
- 비록 루프 자체가 문제가 되지 않더라도, 크롤러는 많은 수의 중복된 페이지들을 가져오게 된다. 이로 인해 크롤러의 애플리케이션은 쓸모없는 중복된 콘텐츠로 넘쳐나게 될 것이다.
9.1.5 빵 부스러기의 흔적
불행히도 방문한 곳을 지속적으로 추적하는 것은 쉽지 않다.
만약 전 세계 웹 콘텐츠의 상당 부분을 크롤링하려 한다면, 수십억 개의 URL을 방문할 준비가 필요할 것이다. 이말은 즉, 복잡한 자료 구조를 사용해야 한다.
다음은 대규모 웹 크롤러가 그것을 관리하기 위해 사용하는 몇가지 유용한 기법들이다.
- 트리와 해시 테이블
- 느슨한 존재 비트맵
- 체크포인트
- 파티셔닝
9.1.6 별칭(alias)과 로봇 순환
올바른 자료 구조를 갖추었더라도 URL이 별칭을 가질 수 있는 이상 어떤 페이지를 이전에 방문했었는지 알기 쉽지 않을 때도 있다.
예를 들어 첫 번째 URL이 http://www.foo.com/bar.html이고 두 번째 URL이 http://www.foo.com:80/bar.html일 경우, 기본 포트가 80번인 상태라면 같은 URL을 가리키게 된다.
9.1.7 URL 정규화하기
대부분의 웹 로봇은 URL들을 표준 형식으로 정규화 함으로써 다른 URL과 같은 리소스를 가리키고 있음이 확실한 것들을 미리 제거하려고 시도한다.
로봇은 다음과 같은 방식으로 URL을 정규화된 형식으로 변환한다.
- 포트 번호가 명시되지 않았다면, 호스 트명에 ':80'을 추가한다.
- 모든 %xx 이스케이핑된 문자들을 대응되는 문자로 변환한다.
#태그들을 제거한다
URL 정규화는 이처럼 기본적인 문법의 별칭을 제거할 순 있지만, 이러한 것으로도 제거할 수 없는 다른 URL 별칭도 만나게 될 수 있다.
9.1.8 파일 시스템 링크 순환
파일 시스템의 심벌링 링크는 사실상 아무것도 존재하지 않음에도 끝없이 깊어지는 디렉터리 계층을 만들 수 있기 때문에 매우 교묘한 종류의 순환을 유발할 수 있다.
9.1.9 동적 가상 웹 공간
웹 마스터들은 로봇들을 함정으로 빠뜨리기 위해 복잡한 크롤러 루프를 악의적으로 만들 수 있고, 악의가 없지만 자신도 모르게 심벌릭 링크나 동적 콘텐츠를 통한 크롤러 함정을 만들 수도 있다.
9.1.10 루프와 중복 피하기
모든 순환을 피하는 완벽한 방법은 없지만, 웹에서 로봇이 더 올바르게 동작하기 위해 사용하는 기법들은 다음과 같다.
- URL 정규화
- 너비 우선 크롤링
- 스토틀링: 로봇이 웹 사이트에서 일정 시간 가져올 수 있는 페이지 숫자 제한
- URL 크기 제한
- URL/사이트 블랙리스트
- 패턴 발견
- 콘텐츠 지문: 페이지의 콘텐츠에서 몇 바이트를 얻어내어 체크섬 계산
- 사람의 모니터링
9.2 로봇의 HTTP
많은 로봇이 그들이 찾는 콘텐츠를 요청하기 위해 필요한 HTTP를 최소한으로 구현하려고 하므로 많은 로봇이 요구사항이 적은 HTTP/1.0 요청을 보낸다.
9.2.1 요청 헤더 식별하기
로봇 개발자들은 로봇의 능력, 신원, 출신을 알려주는 다음과 같은 신원 식별 헤더를 사이트에 보내주는 것이 좋다.
- User-Agent: 서버에게 요청을 만든 로봇의 이름을 알려준다
- From: 로봇의 사용자/관리자의 이메일 주소를 제공한다
- Accept: 서버에게 어떤 미디어 타입을 보내도 되는지 말해준다
- Referer: 현재의 요청 URL을 포함한 문서의 URL을 제공한다
9.2.2 가상 호스팅
로봇 개발자들은 Host 헤더를 지원할 필요가 있다. 만약 요청에 이 헤더를 포함하지 않으면 로봇이 어떤 URL에 대해 잘못된 콘텐츠를 찾게 만든다.
9.2.3 조건부 요청
로봇들은 때때로 극악한 양의 요청을 시도할 수도 있기 때문에, 로봇이 검색하는 콘텐츠의 양을 최소화하는 것은 상당히 의미있는 일이다.
9.2.4 응답 다루기
단순히 GET 메서드로 콘텐츠를 요청하는 대다수의 로봇들은 응답 다루기라고 부를 만한 일을 거의 하지 않지만, 종종 HTTP의 조건부 요청과 같은 특정 몇몇 기능을 사용하는 로봇들 또는 웹 탐색이나 서버와의 상호작용을 더 잘 해보려고 하는 로봇들은 여러 종류의 HTTP 응답을 다룰줄 알아야 한다.
9.2.5 User-Agent 타기팅
웹 관리자들은 많은 로봇이 자신의 사이트를 방문하게 될 것임을 명심하고, 그 로봇들로부터의 요청을 예상해야 한다.
최소한 로봇이 그들의 사이트에 방문했다가 콘텐츠를 얻을 수 없어 당황하는 일은 없도록 대비해야 한다.
9.3 부적절하게 동작하는 로봇들
로봇들이 저지르는 실수 몇 가지와 그로 인해 초래되는 결과는 다음과 같다.
폭주하는 로봇
만약 로봇이 논리적인 에러를 갖고 있거나 순환에 빠졌다면 웹 서버에 극심한 부하를 안겨줄 수 있다.
길고 잘못된 URL
순환이나 프로그램명상의 오류로 인해 로봇은 웹 사이트에게 크고 의미없는 URL을 요청할 수 있다. 이러한 문제는 웹 서버 처리 능력에 영향을 주고, 접근 로그를 어지럽게 채울 수 있다.
호기심이 지나친 로봇
사적인 데이터에 대한 URL을 얻어 그 데이터를 인터넷 검색엔진이나 기타 애플리케이션을 통해 쉽게 접근할 수 있도록 만들 수도 있다.
동적 게이트웨이 접근
게이트웨이 애플리케이션의 콘텐츠에 대한 URL로 요청을 할수도 있다.
9.4 로봇 차단하기
1994년, 웹 마스터에게 로봇의 동작을 잘 제어할 수 있는 메커니즘을 제공하는 단순하고 자발적인 기법이 제안되었다.
이 표준은 "Robots Exclustion Standard"라고 이름 지어졌지만, 종종 그냥 robots.txt라고 불린다.
이 robots.txt의 아이디어는 단순하다. 웹 서버의 문서 루트에 해당 이름이 붙은 선택적인 파일을 제공한다. 이 파일은 어떤 로봇이 서버의 어떤 부분에 접근할 수 있는지에 대한 정보가 담겨있다.
9.4.1 로봇 차단 표준
로봇 차단 표준에는 세 가지 버전이 존재한다.
- v0.0
- v1.0
- v2.0
오늘날 대부분의 로봇들은 v0.0이나 v1.0을 채택한다.
9.4.2 웹 사이트와 robots.txt 파일들
웹 마스터는 웹 사이트의 모든 콘텐츠에 대한 차단 규칙을 종합적으로 기술한 robots.txt 파일을 생성할 책임이 있다.
9.4.3 robots.txt 파일 포맷
# this robots.txt file allows Slurp & Webcrawler to crawl
# the public parts of our site, but no other robots...
User-Agent: slurp
User-Agent: webcrawler
Disallow: /private
User-Agent: *
Disallow:9.4.5 robots.txt의 캐싱과 만료
로봇은 매 파일 접근마다 robots.txt 파일을 새로 가져오는 것이 아닌, 주기적으로 파일을 가져와서 그 결괴를 캐시해야 한다. 캐시된 사본은 robots.txt 파일이 만료될 때까지 로봇에 의해 사용된다.
로봇 명세 초안은 Cache-Control 지시자가 존재하는 경우 7일간 캐싱하도록 하고 있지만, 실무에서 보면 이것도 너무 길다.
9.6 검색엔진
9.6.1 넓게 생각하라
웹 전체를 크롤링하는 것은 쉽지 않은 도전이다. 복잡한 크롤러를 여러개 사용해야 한다.
9.6.2 현대적인 검색엔진의 아키텍처
'full-text indexes'라고 하는 복잡한 로컬 데이터베이스에 크롤링하는 데이터를 쌓는다. 그러나 웹 사이트는 오늘도 내일도 변하기 때문에 기껏해야 특정 순간의 스냅샷에 불과하다.
9.6.3 풀 텍스트 색인
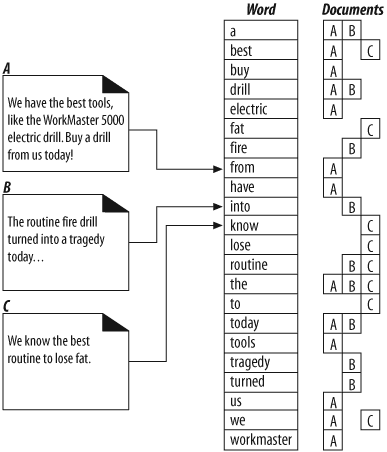
풀 텍스트 색인은 단어 하나를 입력받아 그 단어를 포함하고 있는 문서를 즉각 알려줄 수 있는 데이터베이스다. 이 무서들은 색인이 생성된 후에는 검색할 필요가 없다.
9.6.4 질의 보내기
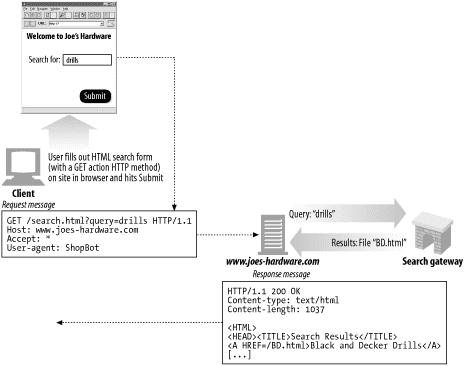
사용자가 질의를 웹 검색엔진 게이트웨이로 보내는 방법은, HTML 폼을 사용자가 채워넣고 브라우저가 그 폼을 HTTP GET이나 POST 요청을 이용해서 게이트웨이로 보내는 식이다. 게이트웨이 프로그램은 검색 질의를 추출하고 웹 UI 질의를 풀 텍스트 색인을 검색할 때 사용되는 표현식으로 변환한다.
9.6.5 검색 결과를 정렬하고 보여주기
검색 결과에는 적으면 몇개 많으면 수백개 수천개가 보일 수 있다. 사용자가 검색한 결과에 가장 적절한 결과를 보여줘야 하기 때문에 크롤러가 해당 페이지에 대한 설명을 정확히 이해하기 위해 자세히 적어야 한다.
9.6.6 스푸핑
가짜 페이지가 크롤러를 더 잘 속이고, 이에 따라 크롤러도 진화하는 끊없는 싸움을 스푸핑이라 한다.
📌 데이빗 고울리, 브라이언 토티, 마조리 세이어, 세일루 레디, 안슈 아가왈 공저 이응준, 정상일 공역, 『HTTP 완벽 가이드: 웹은 어떻게 동작하는가』, 인사이트(2014)
