

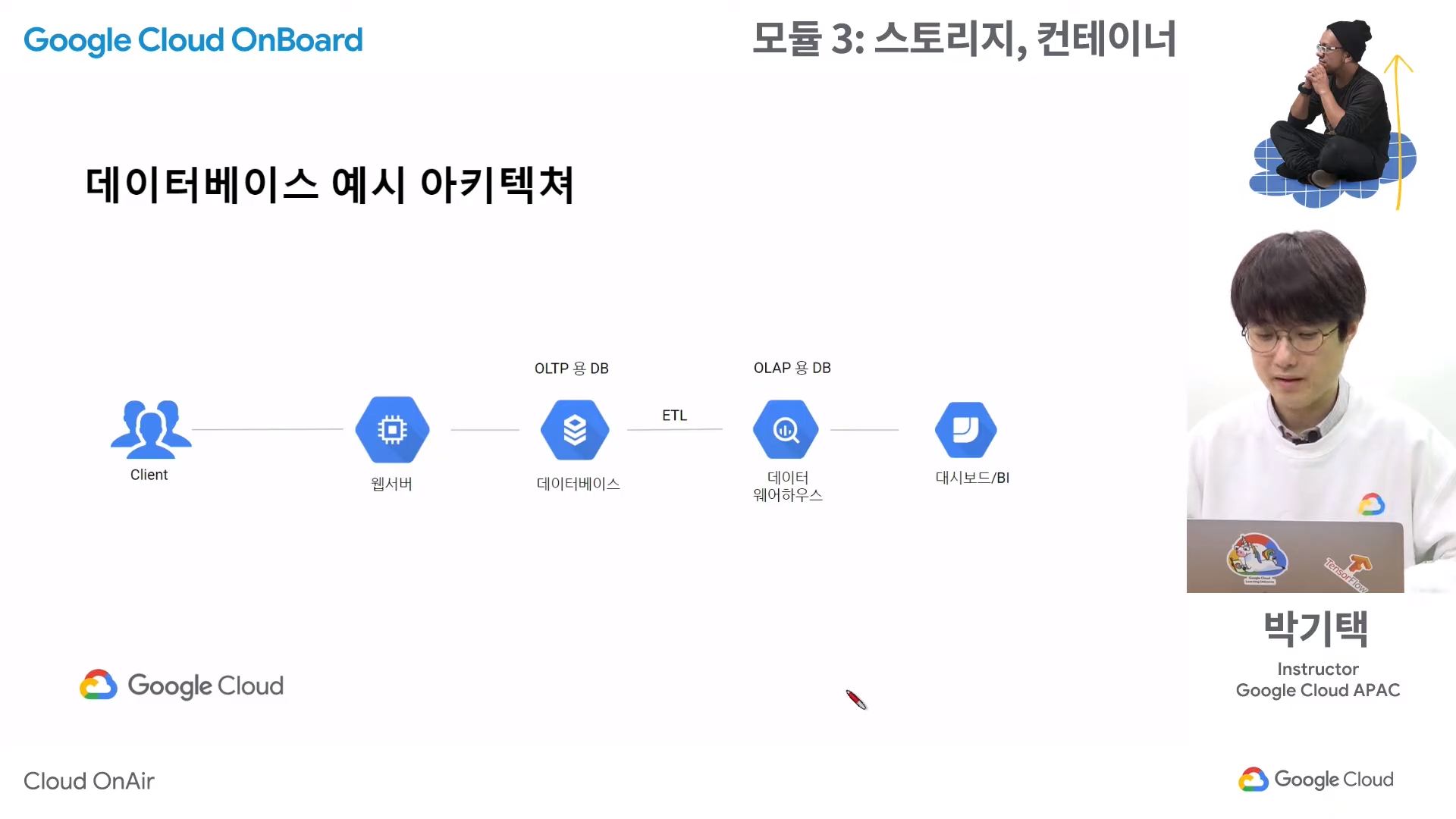
데이터베이스 예시 아키텍처
OLTP(On-Line Transaction Processing)
- 온라인 업무 처리 형태의 하나로 네트워크상의 여러 이용자가 실시간으로 데이터베이스의 데이터를 갱신하거나 검색하는 등의 단위 작업을 처리하는 방식.
- 온라인 뱅킹, 주문, 직원 세부정보 업데이트 등과 같은작업을 예로 들 수 있으며 일반적으로 단일 레코드와 관련된 작업이다.
OLAP(On-Line Analytical Processing)
- 다차원으로 이루어진 데이터로부터 통계적인 요약 정보를 분석하여 의사 결정에 활용하는 방식
- OLAP는 OLTP에 비해 더 적은 사용자들이 사용하지만 더 많고 복잡한 쿼리와 긴 처리 시간을 가진다. 왜냐하면 일반적으로 단일 레코드를 처리하는 OLTP와는 달리 전체적인 많은 레코드 단위를 분석하는 작업이기 때문.
ETL
- 추출, 변환, 적재(Extract, transform, load)
- 조직에서 여러 시스템의 데이터를 단일 데이터베이스, 데이터 저장소, 데이터 웨어하우스 또는 데이터 레이크에 결합하기 위해 일반적으로 허용되는 방법
- 기업이 전 세계 모든 곳의 수많은 팀에서 관리하는 구조화된 데이터와 구조화되지 않은 데이터를 비롯한 전체 데이터를 가져와 비즈니스 목적에 실질적으로 유용한 상태로 변환하는 엔드 투 엔드 프로세스를 의미한다.
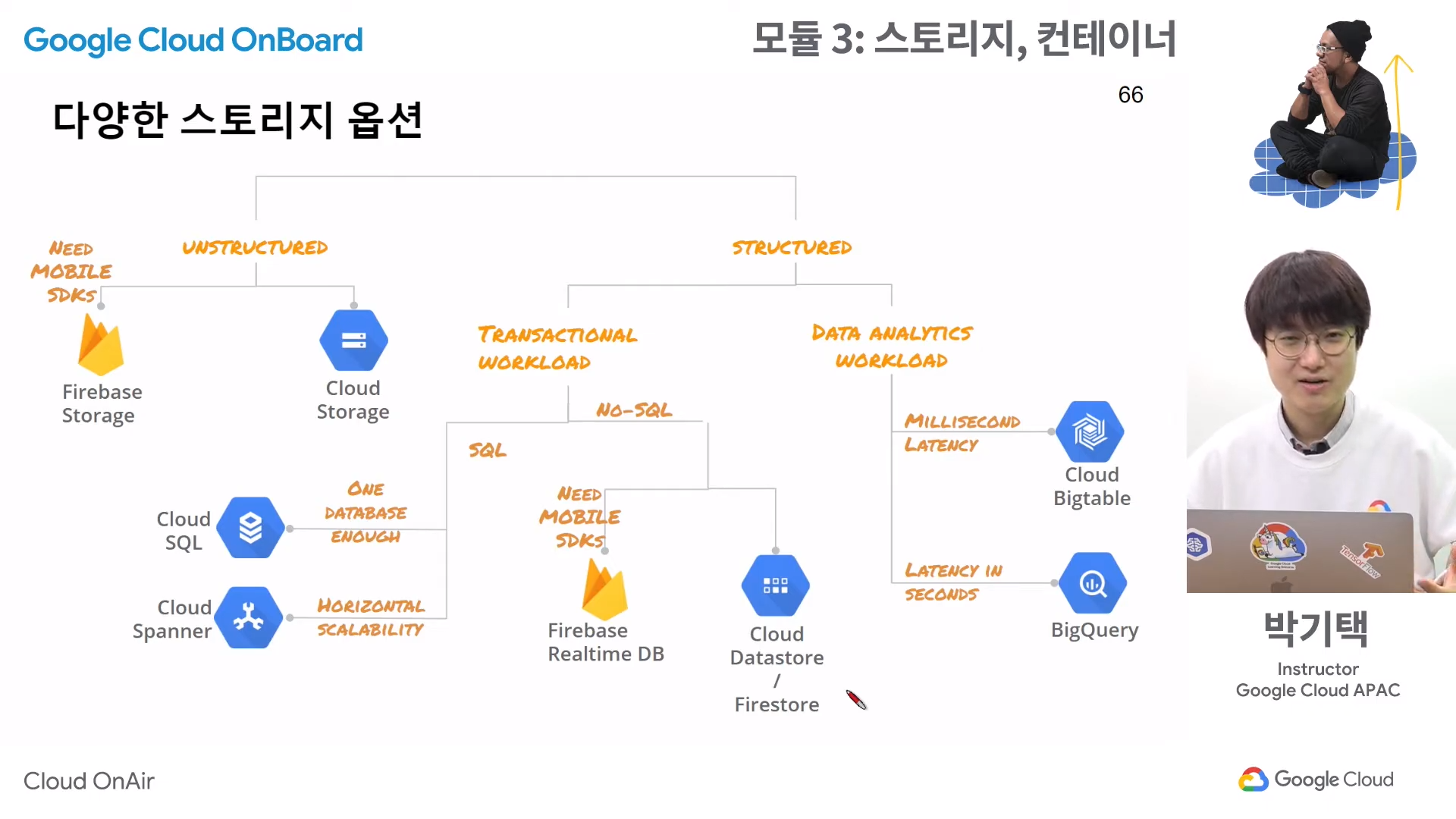
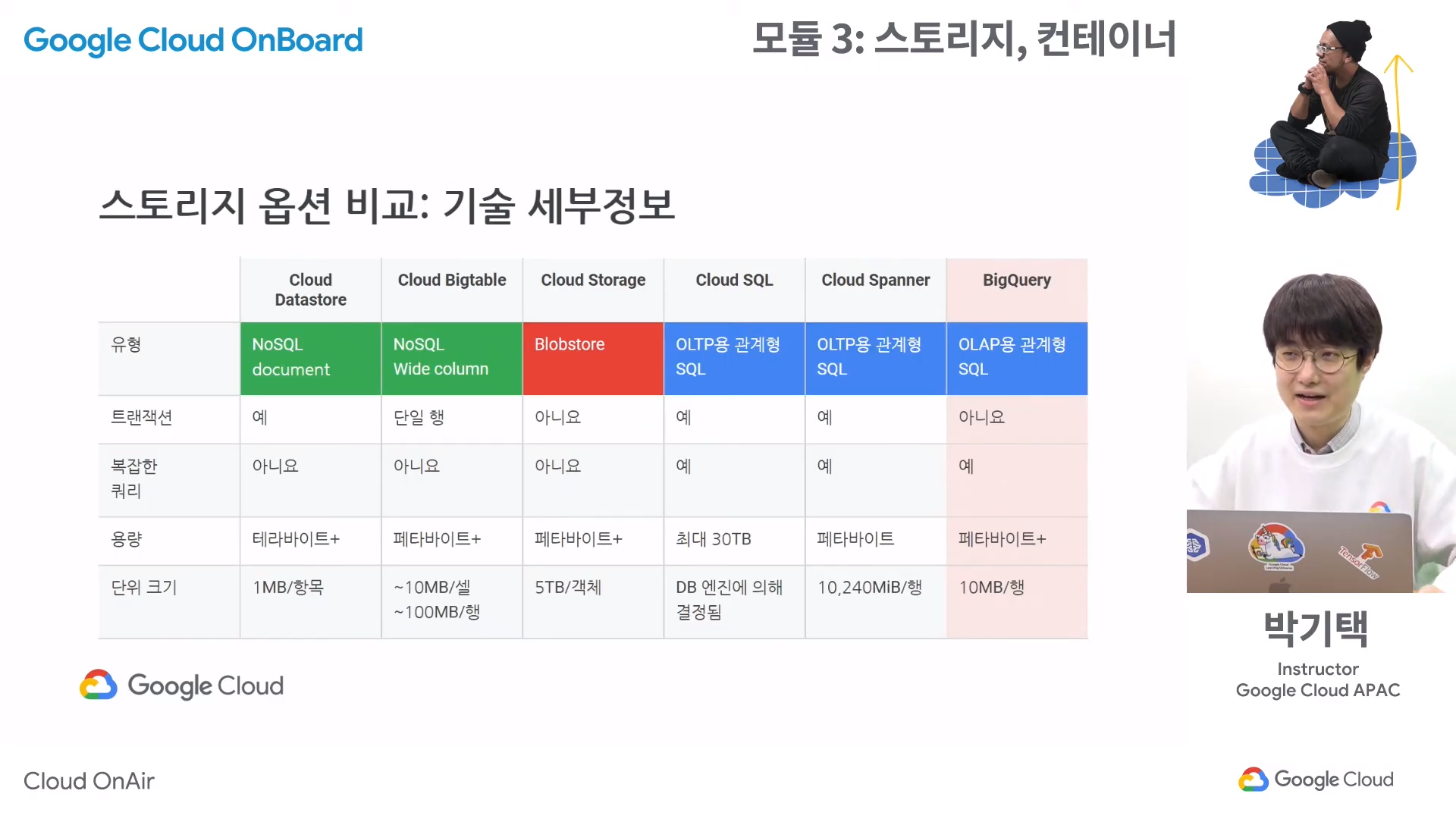
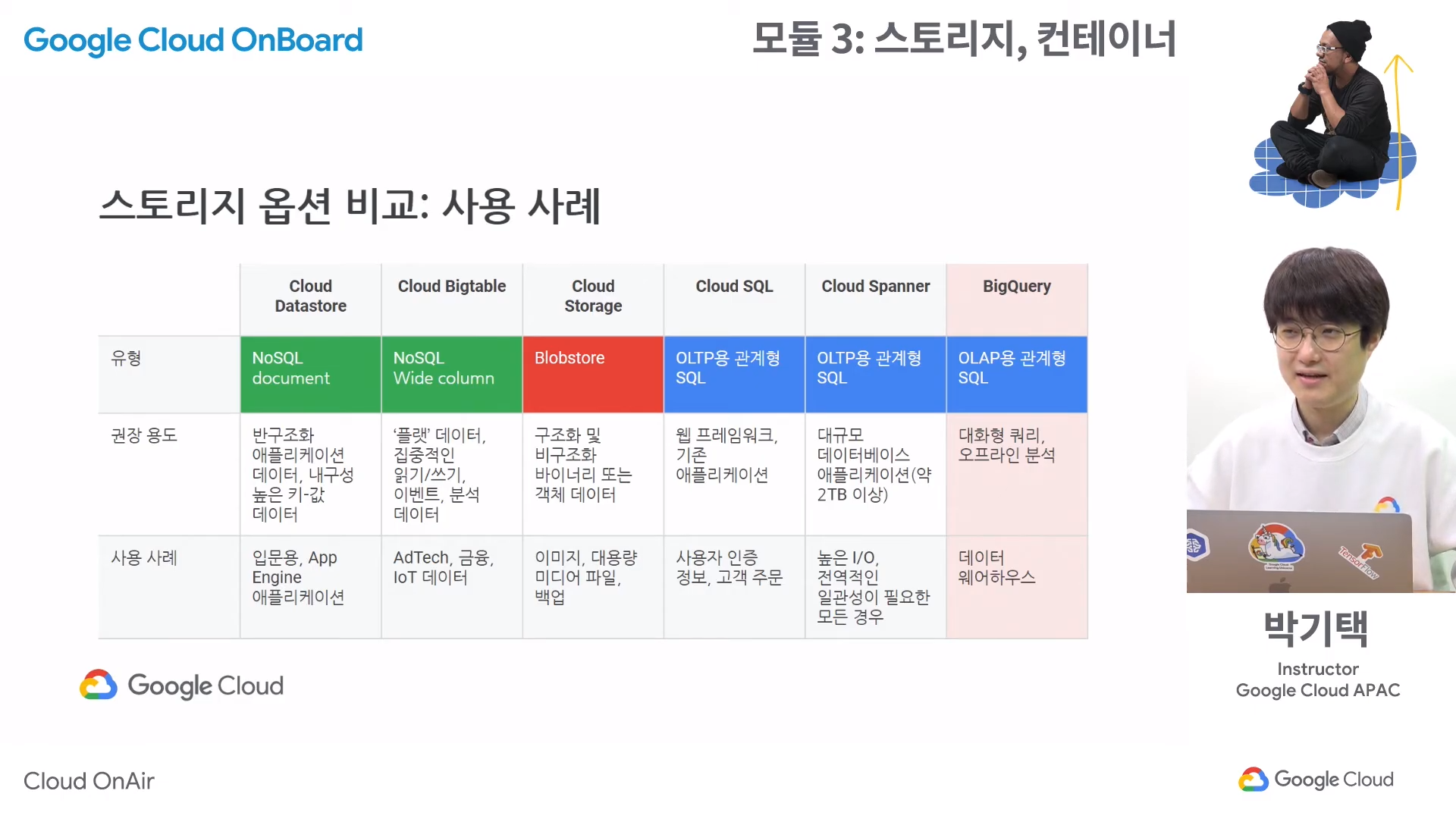
다양한 스토리지 옵션
Unstructured Data
- 비정형 데이터
- 정해진 규칙이 없어서 값의 의미를 쉽게 파악하기 힘든 경우
- 흔히, 텍스트, 음성, 영상과 같은 데이터가 비정형 데이터 범위에 속해있다.
Structured Data
- 정형 데이터
- 데이터베이스의 정해진 규칙(Rule)에 맞게 데이터를 들어간 데이터 중에 수치 만으로 의미 파악이 쉬운 데이터
SQL
- Structured Qurey Language(구조적 질의 언어)의 줄임말로, 관계형 데이터베이스 시스템(RDBMS)에서 자료를 관리 및 처리하기 위해 설계된 언어이다.
No-SQL
- Not Only SQL의 약자로 기존 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미한다.
Data Lake
- 가공되지 않은 다양한 종류의 데이터를 한 곳에 모아둔 저장소의 집합
- 최근에는 기업마다 빅데이터에 대한 활용도가 높아지며 각종 빅데이터를 확장하고 관리, 통제하는 데에 가장 필요한 시스템으로 주목 받고 있다.
- 즉 빅데이터를 분석하기 이전에 최대한 데이터를 모아두고 적절하게 활용되도록 하는 창고 역할을 하는 것이다.
Data Warehouse
- 급증하는 다량의 데이터를 효과적으로 분석하여 정보화하고 이를 여러 계층의 사용자들이 효율적으로 사용할 수 있도록 한 데이터베이스
Data Mart
- 전사적으로 구축된 데이터 웨어하우스로부터 특정 주제나 부서 중심으로 구축된 소규모 단일 주제의 데이터 웨어하우스
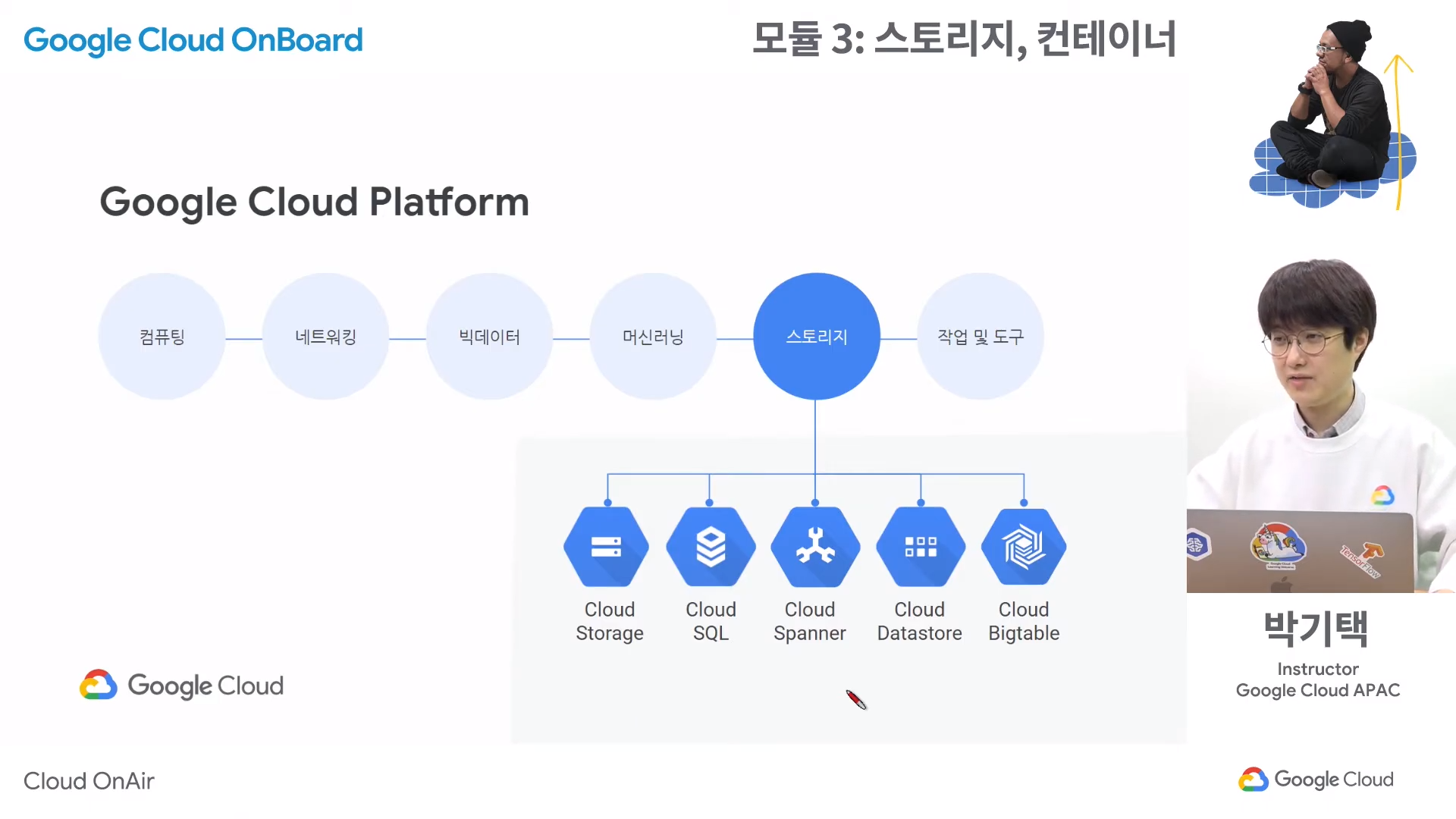

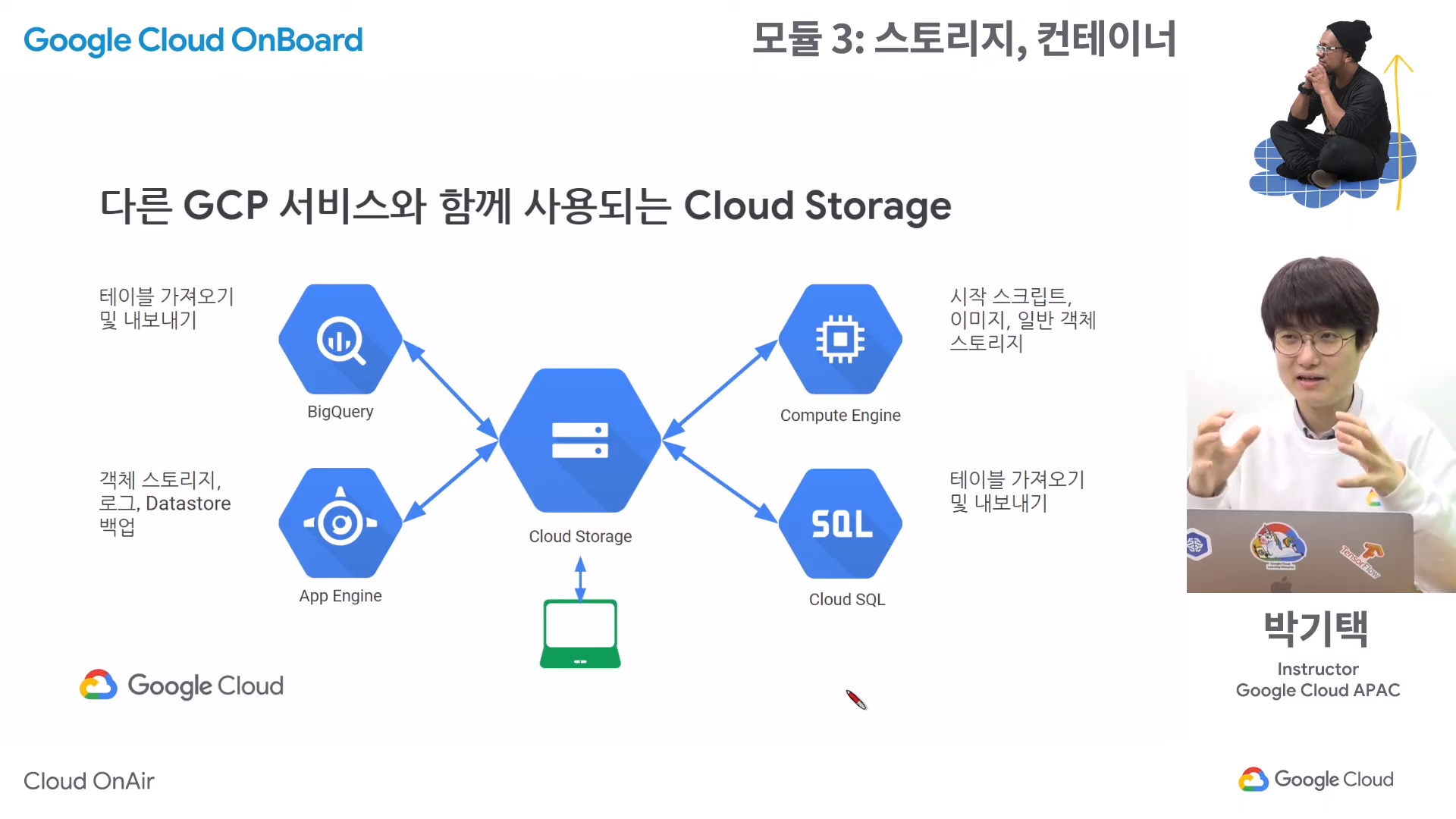
GCS(Google Cloud Storage)란?
- 데이터 양에 관계 없이 언제, 어디서나 데이터를 저장하고 가져올 수 있는 스토리지
- 컨텐츠를 제공하거나, 백업 데이터를 저장하거나, 사용자에게 대량의 데이터 객체를 배포 하는 등의 다용도로 사용할 수 있다.

GCS의 주요 개념
- 프로젝트
- GCP의 프로젝트와 같은 개념으로 GCS의 모든 개념은 프로젝트에 속하게 된다.
- 버킷
- 객체를 담는 컨테이너. 데이터 파일을 담는 개념이라고 이해하면 된다.
- 폴더나 디렉터리의 개념과 다르게 버킷 안에 또 다른 버킷을 만들 수 없다.
- 전역에서 고유해야 하기 때문에 GCP 전체에서 고유한 이름을 사용해야 한다.
- 객체
- 버킷에 저장되는 파일들
- 버킷에 저장되는 파일들
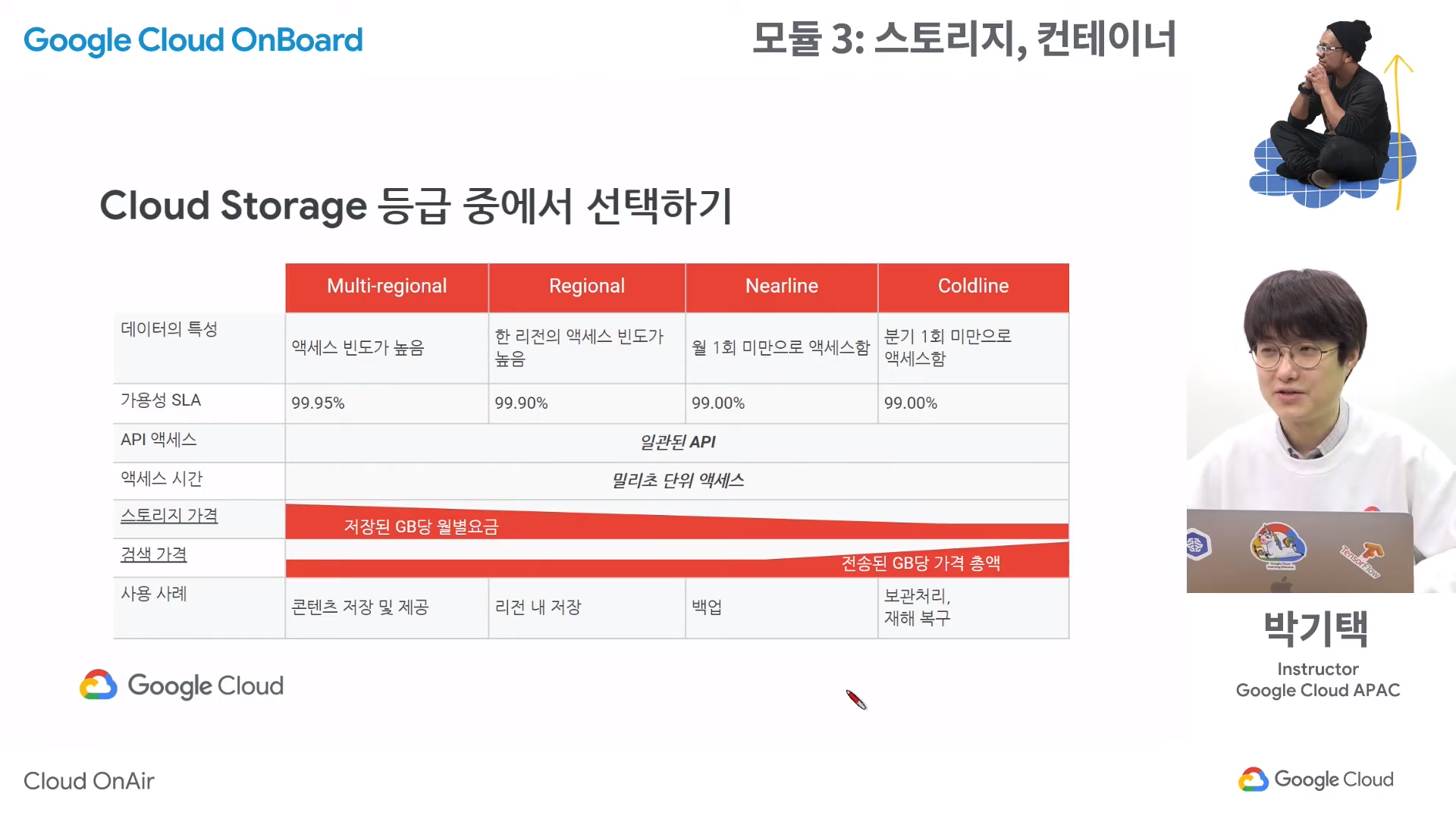
스토리지 클래스
- 버킷을 만들 때 저장할 데이터의 특징에 따라 나뉘어지는 등급
1. Standard Storage
- 자주 액세스되거나 짧은 기간 동안만 저장되는 데이터에 가장 적합한 클래스
2. Nearline Storage
- 액세스 빈도가 낮은 데이터를 저장하기 위한 저가의 내구성 높은 스토리지 서비스
- 평균적으로 한 달에 한 번 정도 읽거나 수정할 계획인 데이터를 저장하는 데 적합하다.
3. Coldline Storage
- 자주 액세스하지 않는 데이터를 저장하기 위한 매우 저렴하고 내구성 높은 스토리지 서비스
- 분기당 최대 1회 읽거나 수정할 데이터에 적합하다.
4. Archive Storage
- 데이터 보관처리, 온라인 백업, 재해 복구를 위한 가장 저렴하고 내구성 높은 스토리지 서비스
- 다른 클라우드 공급업체에서 제공하는 가장 높은 수준의 '콜드' 스토리지 서비스와 달리 데이터는 몇 시간 또는 며칠이 아닌 밀리초 이내에 제공된다.
- 가용성 SLA가 없지만 일반적인 가용성은 Nearline Storage 및 Coldline Storage와 비슷한 수준이다.
- 1년에 한 번 미만으로 액세스하려는 데이터에 적합하다.

gsutil
- CLI 환경에서 GCS에 액세스 할 수 있는 명령어로, 다음과 같은 작업이 가능하다.
- 버킷 생성 및 삭제
- 객체 업로드, 다운로드, 삭제
- 버킷 및 객체 나열
- 객체 이동, 복사 및 이름 바꾸기
- 객체 및 버킷의 ACL 수정

Bigtable이란?
- 대규모 분석 및 운영 워크로드를 위한 확장 가능한 완전 관리형 NoSQL 데이터베이스 서비스


사용이 적합한 경우
- 구조화 되지 않은 키/값 데이터에 대한 매우 많은 처리량과 높은 확장성이 필요한 애플리케이션
사용이 부적합한 경우
- 고도로 구조화된 데이터, 트랜잭션 데이터, 소량 데이터(1TB 미만), SQL 쿼리 및 SQL과 유사한 조인이 필요한 경우
- 빅테이블은 한 서버의 데이터베이스에 작성한 내용을 즉시 다른 서버로부터 읽으면 방금 작성한 서버로부터 읽는 것과는 같은 결과를 보지 못할 수도 있다는 의미의 궁극적 일관성(Eventual consistency)를 보장하기 때문에 OLTP 데이터에는 적합하지 않다.
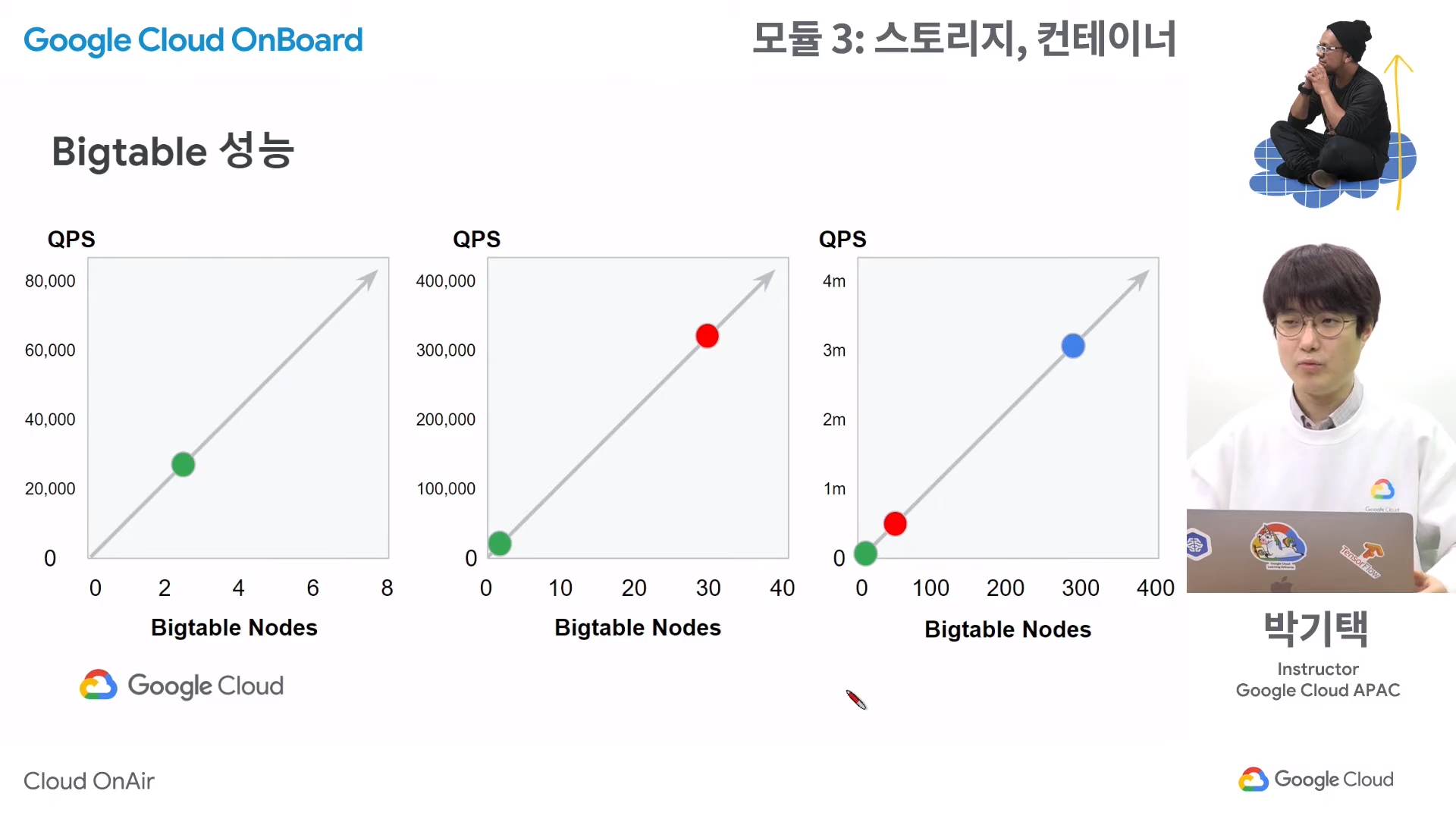
Bigtable 성능
- Bigtable에서는 Colossus라고 하는 파일 시스템에 데이터를 저장한다. 저장 이후 사용자가 데이터를 읽기 위해 요청을 보내면 바로 Colossus로 요청이 가는 것이 아니라 중간에 있는 '노드'를 거쳐 가게 된다. 노드는 메타데이터 값을 저장하고 있어 데이터의 위치를 가리키는데, 이때 노드의 수가 늘어나면 늘어날수록 초당 처리할 수 있는 쿼리의 수가 기하급수적으로 늘어난다.
- QPS(Queries per second): 초당 처리할 수 있는 쿼리 수

Cloud SQL이란?
- 관계형 데이터베이스인 MySQL과 PostgreSQL
- GCP에서 유지 및 관리를 해주는 완전 관리형 데이터베이스로, 손쉽게 설정과 유지보수 및 관리가 가능하다.
- 고성능, 확장성, 편의성을 제공하기 때문에 데이터베이스 관리는 GCP에 맡기고 애플리케이션 개발에 집중할 수 있다.


Cloud Spanner란?
- 무제한 확장, 강력한 일관성, 최대 99.999%의 가용성을 갖춘 완전 관리형 관계형 데이터베이스
- 많은 용량이 필요하거나 전 세계 단위로 비즈니스를 하는 경우 적절

Datastore란?
- OLTP, NoSQL
- 가장 큰 장점은 확장이 자유로움


클라우드의 컨테이너

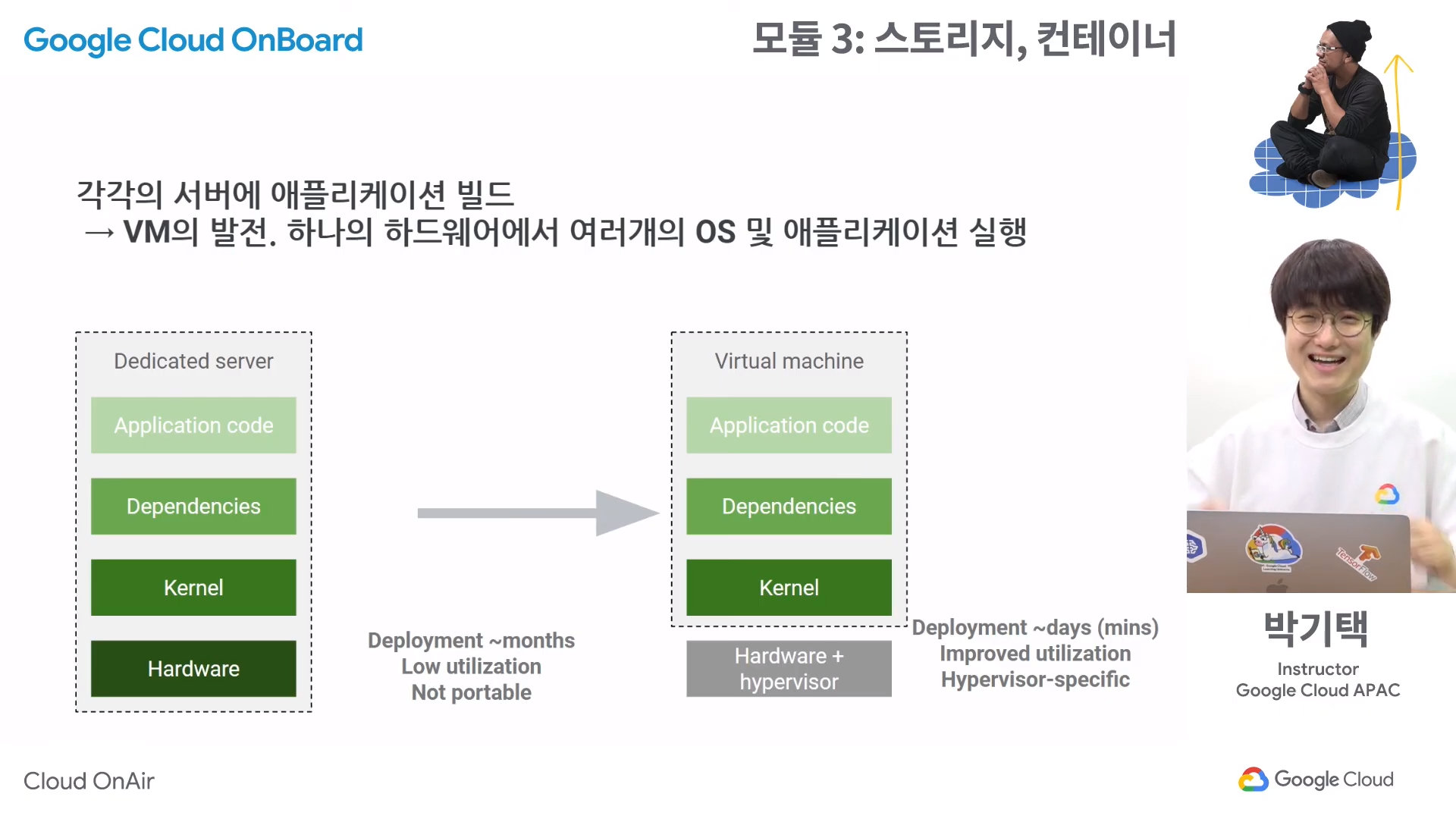
- 전통적으로 서버를 이용해서 서비스를 제공할 땐, 가장 밑단에는 하드웨어가 존재한다. 그리고 그 위에 운영체제를 설치하게 되는데, 운영체제의 핵심이 커널이기 때문에 슬라이드에는 커널이라고 표기되어 있다.
- 커널 위에는 어플리케이션이 설치 되는데, 그 사이에 Dependencies라는 것이 존재한다. 이것은 라이브러리로, 어플리케이션과 운영체제의 커뮤니케이션을 도와주는 역할을 한다.
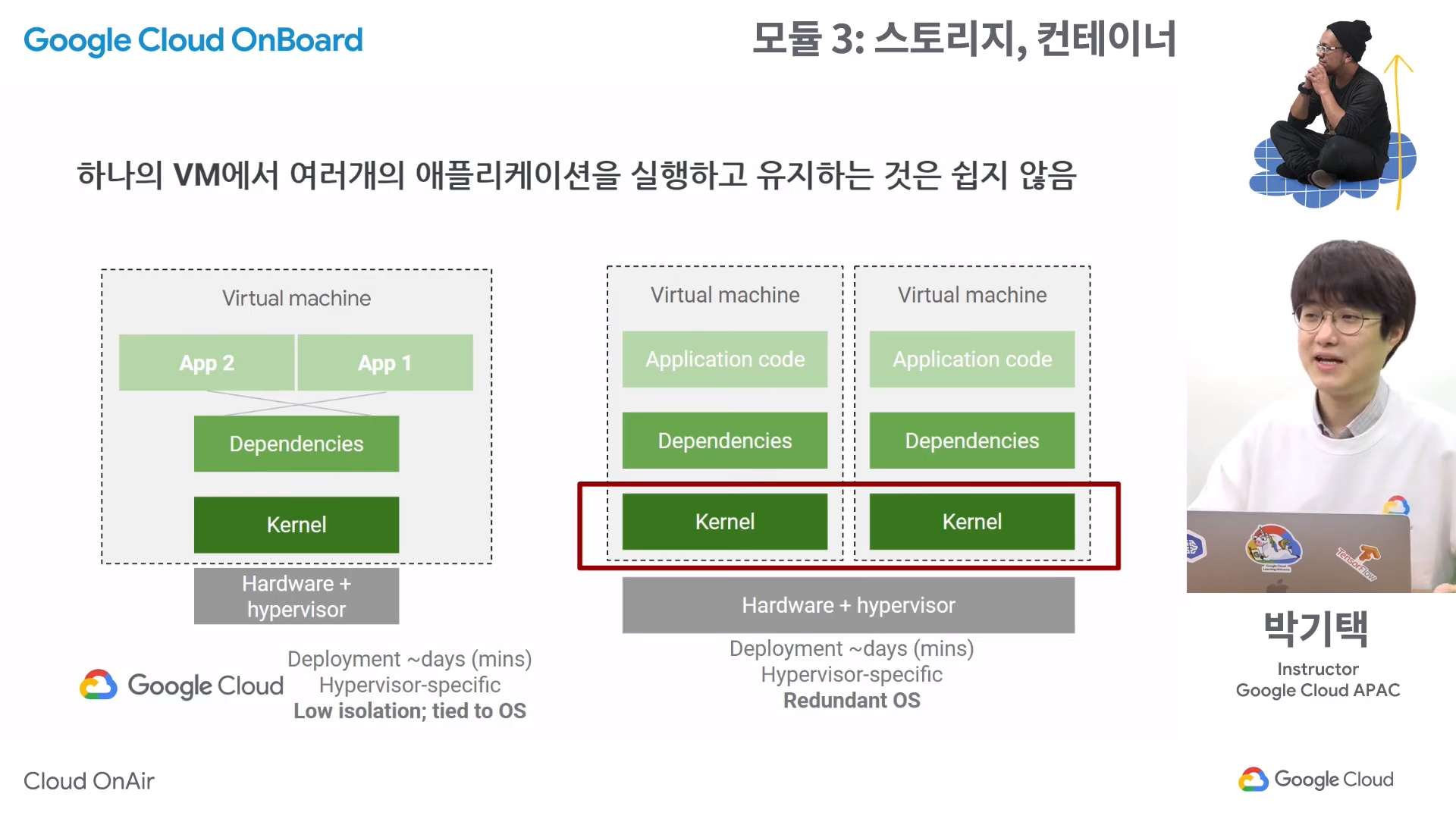
- 하지만 이러한 방법은 Utilization이 너무 낮다. 이 문제를 해결하기 위해 가상화가 등장했고, 하나의 하드웨어 위에 운영체제(커널), 디펜던시, 어플리케이션을 하나로 합친 버추얼머신(VM)을 만들었다.
- (우측 그림) 하나의 하드웨어 위에 두 개의 VM을 올릴 수 있기 때문에 전통적인 방식보단 Utilization이 올라간다. 허나 무거운 운영체제 여러 개가 동시에 돌아가면서 무거워지는 문제가 발생한다.
- (좌척 그림) 그렇다면 하나의 운영체제 위에 두 개의 어플리케이션을 올리면 문제가 해결되지 않을까? 이 경우에는 두 개의 어플리케이션이 하나의 디펜던시를 공유하기 때문에 서로 영향을 너무 많이 주게 되고, 버전 관리의 어려움이 생긴다.
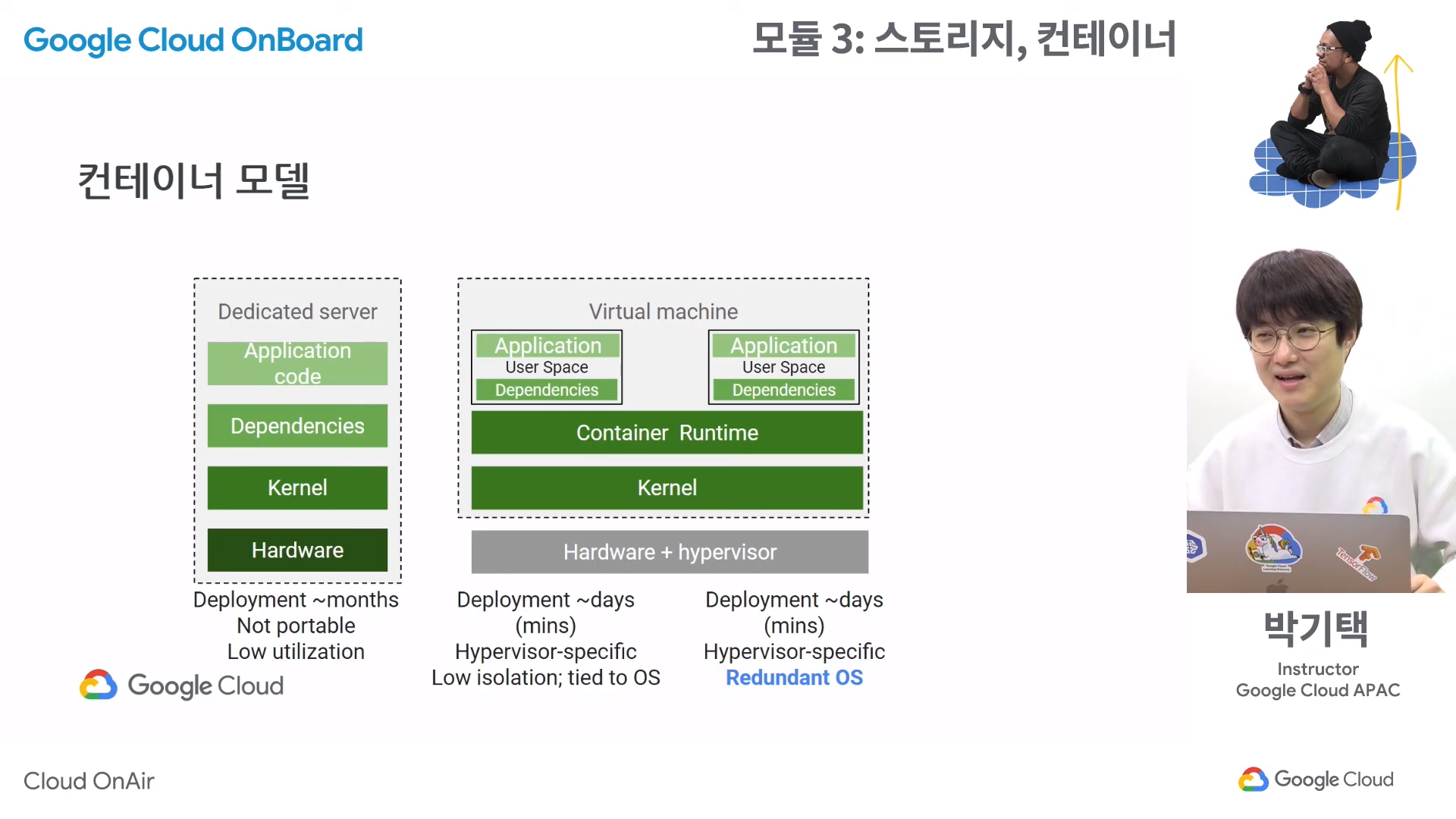
- 그래서 나온 해결책이 컨테이너 모델. 하드웨어 위에 하나의 운영체제를 올리고, 디펜던시와 어플리케이션을 하나로 묶어서 컨테이너를 만드는 것이다. 이렇게 될 경우 운영체제가 하나이기 때문에 가볍고, 어플리케이션끼리 독립되어 있기 때문에 서로 영향을 미치지 않는다.
- 컨테이너의 장점은 규격화 되어 쉽게 이동 가능. 운영체제로부터도 독립적이다.


- 구글에서는 모든 것이 컨테이너에서 실행되는데, 이렇게 많은 컨테이너를 쉽게 조정할 수 있는 개념이 쿠버네티스이다.
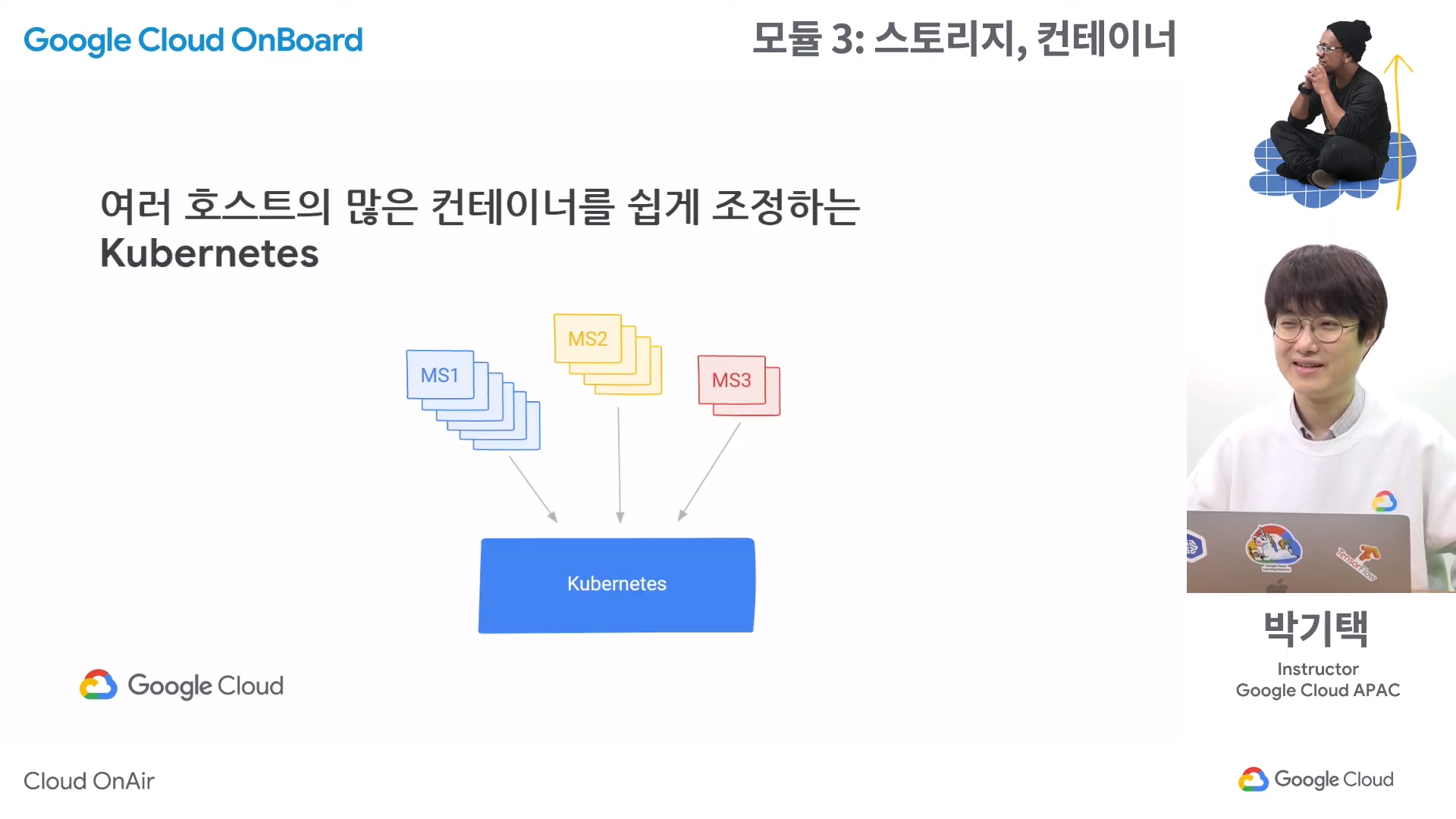

- 쿠버네티스는 파이썬으로 개발되었다.
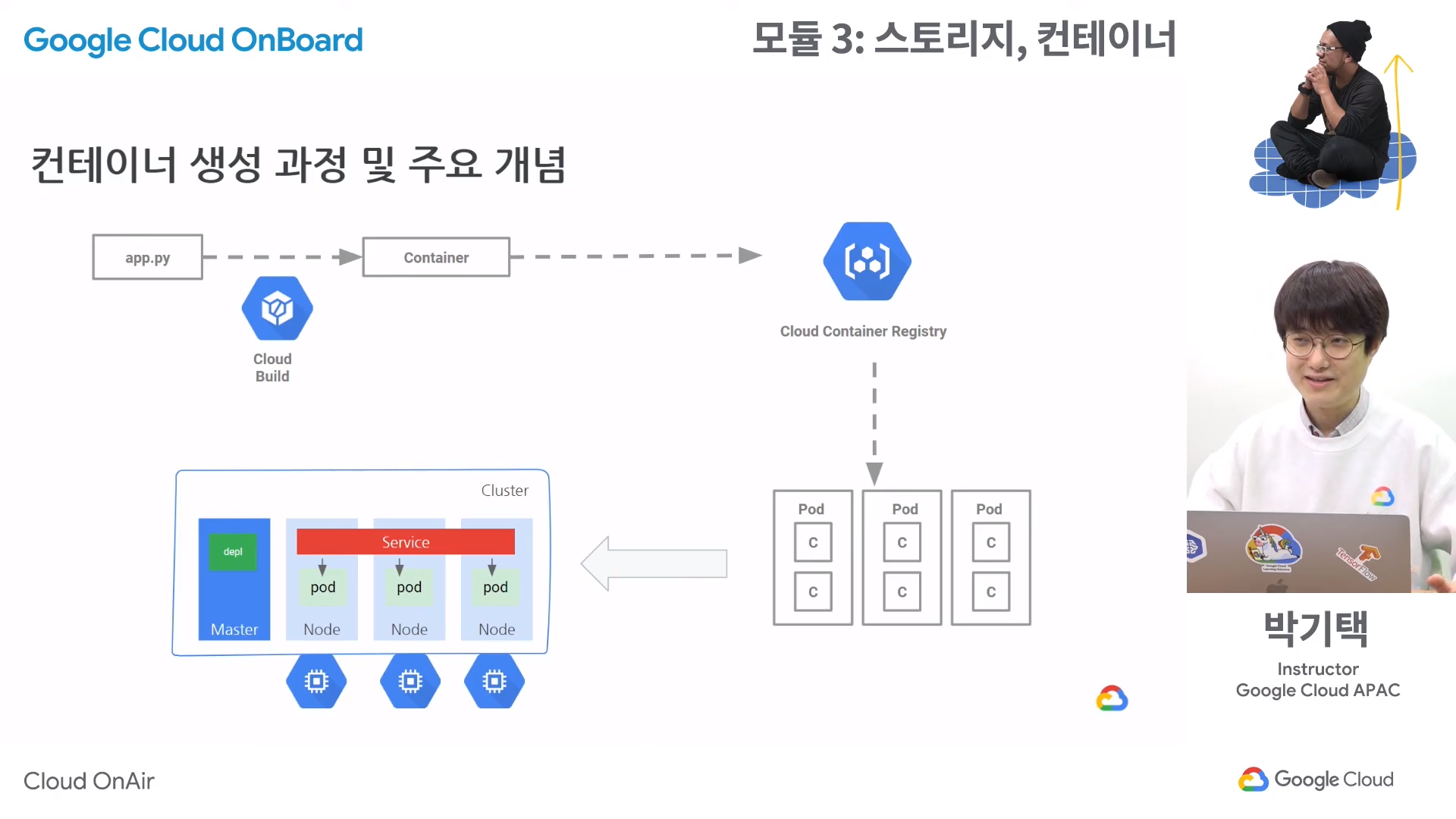
- 컨테이너 생성 과정
1. 개발한 코드를 클라우드 빌드 서비스를 이용하여 컨테이너로 만든다.
2. 컨테이너로 만든 결과물을 컨테이너 레지스트리에 업로드하여 사용하고 싶을 때 레지스트리에서 가져온다. - 쿠버네티스에서의 마스터와 노드 개념 숙지가 필요하다.
- 오픈소스인 쿠버네티스를 사용하면 마스터 관리를 사용자가 직접 해야하지만, GKE를 이용할 경우 구글이 마스터를 관리하기 때문에 개발자는 개발에만 집중 할 수 있다.

- 쿠버네티스
- 컨테이너를 관리하는 것
- 오픈소스
- GKE
- GCP의 서비스
- 구글에서 마스터를 관리해줌
- Istio
- 파드 끼리의 의사소통을 위한 보안인증을 담당하는 프록시 관리 툴
- 오픈소스
- Anthos
- 하이브리드 클라우드를 위한 서비스







우당탕탕 좌충우돌 인프라 여행기