학교 수업 프로젝트
주제 선정 계기
인공지능 프로그래밍 시간에 간단한 데이터 분석 프로젝트를 하게 되었다.
프로젝트의 큰 주제는 스포츠였다. 내가 가장 먼저 생각한 주제는 축구 경기에서 가장 활동량이 많은 포지션을 주제로 하려고 하였다.
BUT, 축구 경기 데이터를 찾을 수가 없었고 카글이라는 사이트에서 마라톤 경기 데이터를 찾아서 마라톤 경기를 주제로 하자라고 생각하였다.
그래서 결정된 주제가 마라톤 경기 1등 선수의 구간별 페이스이다.
프로젝트 시작
일단 먼저 csv파일에 어떤 column들이 존재하는지 확인을 하였다.
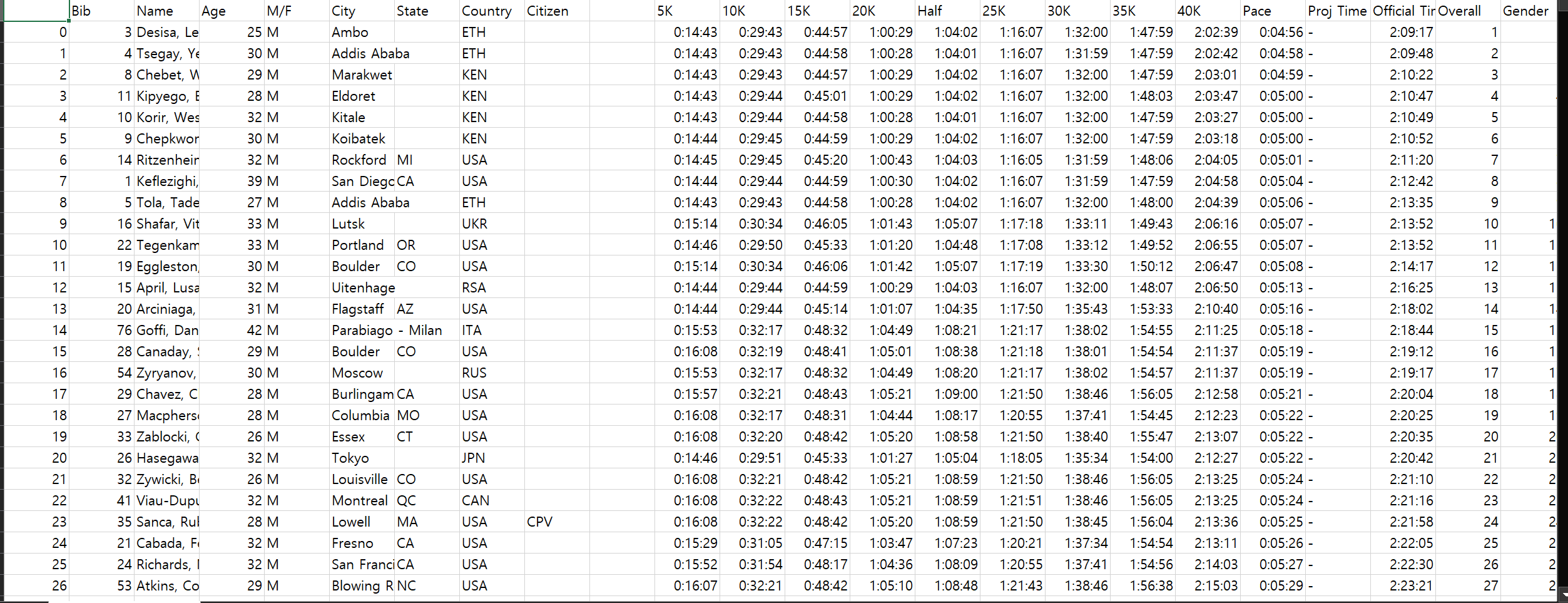
일단 1등 선수의 페이스를 확인 하기 위해서는 거리에 도달하는데 시간이 얼마나 걸렸는지를 알아야 했기 때문에 5k, 10k, 15k, 20k, half, 25k, 30k, 35k, 40k라는 column이 존재했다. 또한, 1등 선수를 찾아야 하기에 overall도 필요했다.
확인을 해보니 내가 필요한 column들은 전부 존재하는 것을 확인 할 수 있었다.
프로젝트 과정
일단 시각화를 할 때 matplotlib을 사용할 것이기에 나눔 폰트로 한글 패치를 해주었다.
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rfimport matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic') 그리고 pandas를 사용해서 csv파일을 불러왔다.
import pandas as pd
# CSV 파일 경로
file_path = 'marathon_results_2015.csv'
# 데이터 불러오기
data = pd.read_csv(file_path)
# 데이터 확인
data.head()그 후 1등인 선수의 데이터만 가져오기 위해서
# 1등 선수의 데이터 필터링
first_place_data = data[data['Overall'] == 1]
# 1등 선수의 데이터 확인
first_place_data이러한 코드를 작성해주었다.
# 필요한 열 선택 (예: 구간별 시간)
splits = ['5K', '10K', '15K', '20K', 'Half', '25K', '30K', '35K', '40K']
split_times = first_place_data[splits].values.flatten()
# 각 구간까지의 누적 거리 (km)
distances = [5, 10, 15, 20, 21.0975, 25, 30, 35, 40]
# 시간 변환 함수 (hh:mm:ss 형식 -> 분 단위)
def time_to_minutes(time_str):
h, m, s = map(int, time_str.split(':'))
return h * 60 + m + s / 60
# 구간별 시간(분) 계산
split_minutes = [time_to_minutes(t) for t in split_times]
# 페이스 계산 (분/km)
paces = [split_minutes[0] / distances[0]] + [(split_minutes[i] - split_minutes[i - 1]) / (distances[i] - distances[i - 1]) for i in range(1, len(distances))]
# 데이터프레임 생성
pace_df = pd.DataFrame({
'Distance (km)': distances,
'Pace (min/km)': paces
})
print(pace_df)splits로 구간별로 나눠주고 values.flatten()으로 1차원 배열로 만들었다.
그리고 구간까지의 거리를 distance에 넣어주고, 시간 변환 함수를 만들어서 구간별 시간을 분 단위로 바꿔준다.
페이스 계산 같은 경우에는 첫 번째 구간은 시간 나누기 거리를 해주고 나머지 구간은 이전 구간 시간 - 현재 구간 시간 나누기 이전 구간 거리 - 현재 구간 거리를 해주면 된다. 이렇게 구간을 이동하는 평균 시간을 구할 수 있다.
그리고 시각화를 편하게 하기위해서 데이터 프레임을 생성해준다.
import matplotlib.pyplot as plt
# 시각화
plt.figure(figsize=(10, 6))
plt.plot(pace_df['Distance (km)'], pace_df['Pace (min/km)'], marker='o', linestyle='-')
plt.title('1등 선수의 구간별 페이스')
plt.xlabel('거리 (km)')
plt.ylabel('페이스 (min/km)')
plt.grid(True)
plt.show()그리고 시각화를 해주면 끝이 난다.
결과
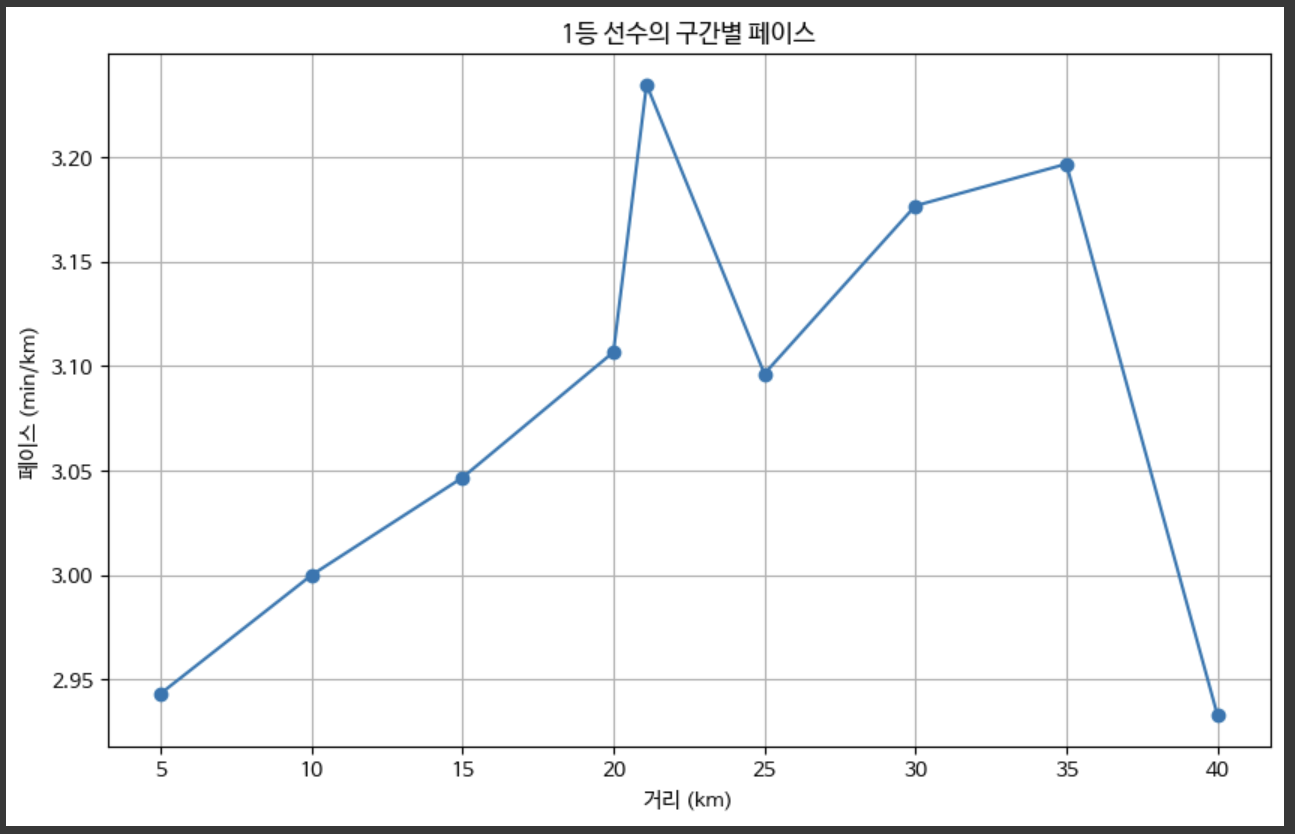
그러면 이런식으로 시각화된 그래프를 얻을 수 있다!
