리뷰가 아니라 거의 해석이 된거같은...
1. Introduction
Dense prediction task는 크게 인코더와 디코더 구조로 나뉜다.
인코더는 주로 pretrained 된 classification network를 feature extractor로 사용하고 이를 backbone이라고 부른다.
인코더는 classification task에서 연구되는 network를 주로 사용하므로, dense prediction의 초점은 주로 디코더에 맞춰진다.
하지만, 인코더에서의 feature extraction 과정에서 손실된 정보는 decoder가 아무리 잘 설계되어도 복구하기 힘들기 때문에 backbone(인코더) 구조에 따른 네트워크의 성능 차이 역시 현저하게 발생한다.
Convolutional backbone은 low level feature들을 더 작은 수의 추상적 high level feature로 표현해서, receptive field를 천천히 늘려가는 방식으로 구성된다.
이러한 과정이 큰 영향을 미치지 않는 task도 있지만, dense prediction에서의 경우, downsampling 과정에서 feature의 resolution이 감소해 정보 손실이 있다는 큰 문제가 있다.
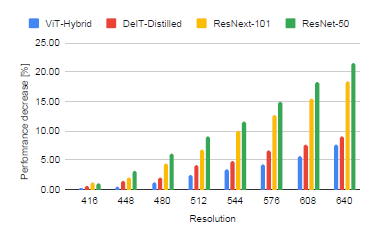
일전에 Monodepth에 high resolutional input을 넣든 low resolution의 input을 넣든 output의 정확도 차이가 거의 없었기 때문에, 이를 인코더에서 디코더로 정보를 잘 전달하지 못해서로 보고 인코더의 feature을 디코더에서 더 잘 반영할 수 있도록 HR depth에서 U++net 구조를 사용했다고 발표했는데, 그 원인에 대해 명확히 설명하지 못한 것 같다.
지금 생각해보니, input resolution을 높이면 downsampling 과정에서 resolution의 손실이 발생해도 중요한 부분은 보존될 가능성이 크다는 이유로 이를 설명할 수 있는 것 같다.
이를 해결하기 위해 dilated convolution, high resolution image의 사용, multiple stage에서의 skip connection(U++net) 등의 방법을 사용했지만, convolutional block의 근본적 문제점을 해결할 수는 없었다.
개별적 convolution에서는 receptive field가 한정되어 있기 때문에, image context나 representational power(이미지 전체를 대표할 수 있는 성질) 을 위해서는 convolutional block을 깊게 쌓아야 한다.
하지만 이 방법은 중간중간 많은 feature representation을 생성하고 이를 저장하기 위한 많은 메모리를 필요로 한다.
본 논문에서는 dense prediction task의 backbone을 vision transformer로 대체한 Dense Prediction Transformer(DPT)를 제안한다. DPT에서는 convolutional block 대신 transformer을 기본적 computational block으로 설정한다.
VIT의 bag of words representation(순서는 신경쓰지 않고 feature의 발생 빈도에만 신경을 쓴 representation)를 대응되는 dense prediction에 합치는 형식의 인코더-디코더 구조로 구성된다. 또한 인코더를 convolutional block으로 구성할 경우 지속적으로 downsampling을 하는 반면 본 논문에서는 인코더에서 transformer을 이용해 dimensionality를 유지하는 방식을 사용한다.
이를 통해 모든 stage에서 global receptive field를 사용하고, 좀더 세밀하고 feature간의 연관성이 분명한 prediction을 얻어낼 수 있다는게 본 논문의 핵심이다.
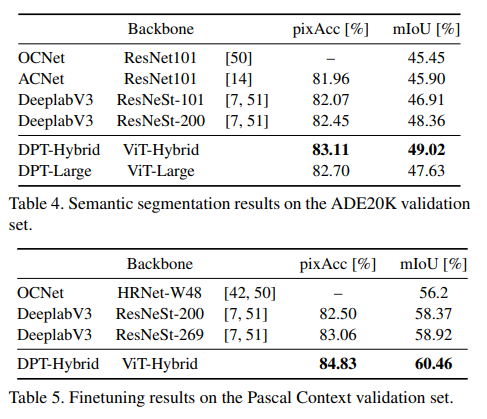
본 논문에서는 Sementic segmentation과 Monocular depth estimation task에 DPT를 적용했다. 두 작업 모두 sota를 훌쩍 뛰어넘는 결과를 보여줬다고 한다.
2. Related work
Dense prediction task는 초기에 fully convolution network로 시작했다.
거의 모든 dense prediction task는 인코더-디코더(downsamplig-upsampling, convolution-subsampling)로 구성되며 앞서 언급한 dilated convolution, different stage에서의 feature aggregation 및 low resolution representation 여러개로 high level representation을 표현하는 방법 등 다양한 방법이 제안되었다.
Transfomer은 self attention에서 출발해서 자연어 처리 분야에서 좋은 성능을 보였으며, 충분히 많은 데이터가 제공될 때 vision 분야에서도 좋은 성능을 보인다는 것이 입증되었다.
3. Architecture
본 논문에서는 dense prediction의 기본 구조인 encoder-decoder 구조는 유지한 채로 backbone만 transformer로 바꾸어 실험을 진행했다.
Transformer encoder
이미지를 패치 단위로 나눴을 때 각 patch는 기존 transformer에서 'word'의 역할을 하고 임베딩 된 word들을 token이라고 부른다.
Transformer에서는 multi-head-self-attention(MHSA, 이하 MHSA)을 이용해 지속적으로 token들을 변환하는데, 이때 각 token간의 연관성을 고려해 representation이 계속 변한다.
Backbone에서 stage를 거침에 따라 token의 수는 변하지 않는다. Token은 이미지 패치와 1:1로 대응하기 때문에 초기 임베딩에 대한 spatial resolution이 변하지 않는다고 해석할 수 있다.
또한 MHSA는 기본적으로 global한 연산이기 때문에, 모든 토큰이 서로에게 영향을 미쳐 모든 stage에서 glabal한 receptive field를 가진다. 이는 convolutional network와 대조되는 성질이다.
Embedding 과정에서 ResNet50을 거친 feature map을 token으로 사용하기도 하며, 트랜스포머 자체는 position에 관한 정보를 내포하지 않기 때문에 학습 가능한 positional embedding을 추가한다. 또한, NLP에서 나왔듯, input image에서 파생되지 않은 classification token(readout token) 역시 positional embedding과 함께 추가된다.
결과적으로 토큰은
=readout token, =output_after transformer layer)
=embedding dimension)
형식으로 표현된다.
본 논문에서는 3가지 종류의 VIT를 사용했다.
-
ViT-Base: Patch-based embedding과 12개의 transformer layer 사용, feature size=768
-
ViT-Large: Patch-based embedding과 24개의 transformer layer, ViT base보다 큰 feature size(1024) 사용
-
ViT-Hybrid: Resnet-50 based embedding과 12개의 transformer layer 사용
여기서 embedding feature인 768과 1024는 모두 patch의 pixel size보다 큰 값으로, 기존의 정보중 유익한 정보를 보존하면서 더욱 많은 정보를 반영할 수 있다는 장점이 있다. 전체 네트워크의 구조는 아래와 같다.
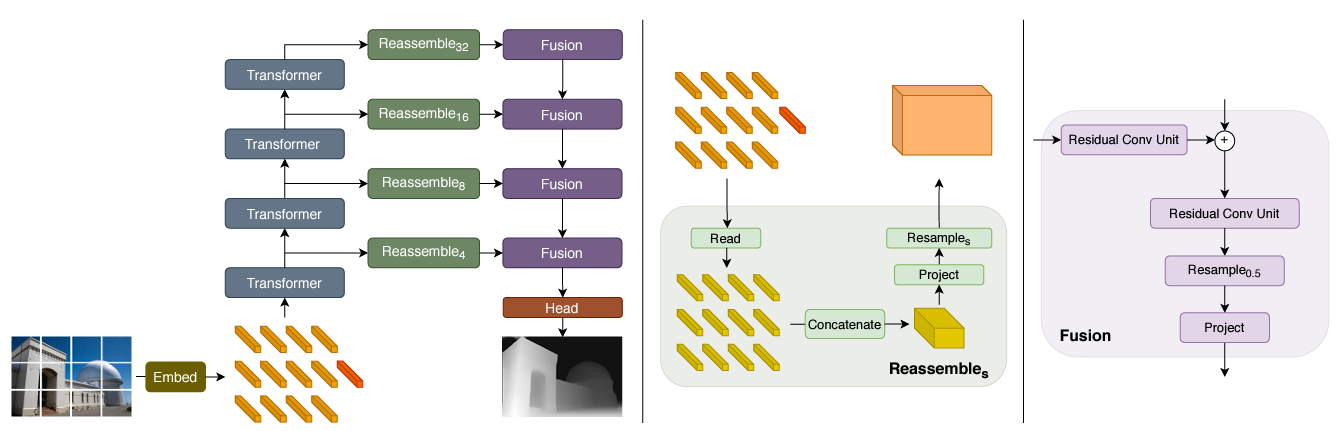
Convolutional decoder
디코더에서는 feature representation들이 점진적으로 최종 dense prediction 부분에 합쳐지는데, 이는 아래 Reassemble operation으로 표현할 수 있다.
s는 size ratio로, input image size 대비 output size를 의미하며 는 output feature dimension을 의미한다.
Read 연산은 의 dimension을 로 변경하는 연산으로, output dimesion에 concat이 가능하도록 shape를 변경하는 역할을 한다. Read 연산에는 대표적으로 아래와 같은 종류가 있다.
Read =
Read =
Read = mlpcat mlp(cat(
Read 연산을 거친 후, output size와 맞추기 위해 Concatenate, Resample 연산을 거치는데, 아래와 같다.
Concatenate: R R
Resample: R R
Resample 연산은 기본적으로 1x1 convolution 으로 를 로 mapping하고, s와 p의 크기에 따라 3x3 convolution 또는 transpose convolution을 적용하는 과정으로 진행된다.
(s>=p: 3x3 conv, s<p: 3x3 transpose conv)
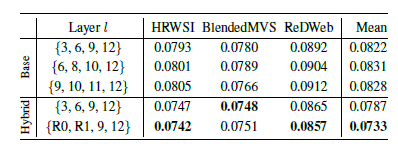
본 논문에서 backbone 및 디코더는 4개의 stage로 구성된다.
- ViT Large 에서는 ={5, 12, 18, 24}
- ViT Base 에서는 ={3, 6, 9, 12}
- Vit Hybrid 에서는 Resnet의 첫 번째와 두 번째 building block, 그
리고 = {9, 12} 의 feature map을 decoder의 stage와 결합한다. 또한, 는 256을 사용한다.
각 fusion stage 마다 upsampling이 동반되며, 마지막 representation size는 input image 절반의 resolution을 가진다.
Handling varying image sizes
Fully convolution network와 유사하게, DPT는 다양한 이미지 크기를 다룰 수 있다. 이미지 크기를 p로 나눌 수 있기 때문에 다양한 수의 를 처리할 수 있다.
하지만 positional embedding은 위치 정보를 포함하기 때문에 이미지 크기에 영향을 받는데, 이는 interpolation을 통해 적절한 크기로 계속해서 변경할 수 있다.
4. Experiments