📍 10분 테코톡 - 안돌의 INDEX를 보고 정리한 내용이다.
1. What is index?
인덱스란 검색을 위해 임의의 규칙대로 부여된 임의의 대상을 가리키는 무언가이다.
Index in Database
- 데이터베이스는 내가 원하는 데이터를 어떻게 찾아오는 걸까?
- 왜 데이터가 많아질수록 점점 느려질까?
- 왜 조인만 수행하면 느릴까?
- 왜 쿼리가 느릴까?
이러한 경우엔 인덱스를 고려해보자.
2. Clustered vs Non-Clustered
기본 용어
- Cluster: 군집
- Clustered: 군집화
- Clustered Index: 군집화된 인덱스
-
Clustered Index
- 순서대로 정렬되기 때문에 한 테이블 당 하나의 기준으로만 정렬 가능하다. 보통은 PK(Primary Key)를 기준으로 조회를 많이 하기 때문에 PK를 Clustered Index로 설정하는 경우가 많다.
- 범위 검색에 유리하다.(공간 지역성)
- 존재하는 PK 사이에 insert할 경우 대참사가 발생한다. 넣어야할 index 위치부터 마지막까지를 하나씩 뒤로 밀어야 한다. 그래서 대참사를 막기 위해 보통 PK를 auto increment로 설정한다.
-
Non-Clustered Index
- 순서가 상관 없다.
- 한 테이블에 여러개 존재할 수 있다.
- 추가 저장 공간이 필요하다.(약 10%)
- insert할 경우 추가 작업이 필요하다.(인덱스 생성)
- Cardinality가 높을 수록 index 사용을 고려하는 것이 좋다.
3. Example

이메일을 PK로 설정할 경우, 새로운 이메일이 들어올 때마다 인덱스를 재정렬해야 하고 DB 성능이 저하된다.
별도의 아이디를 만들어서 해당 문제를 해결할 수 있다.
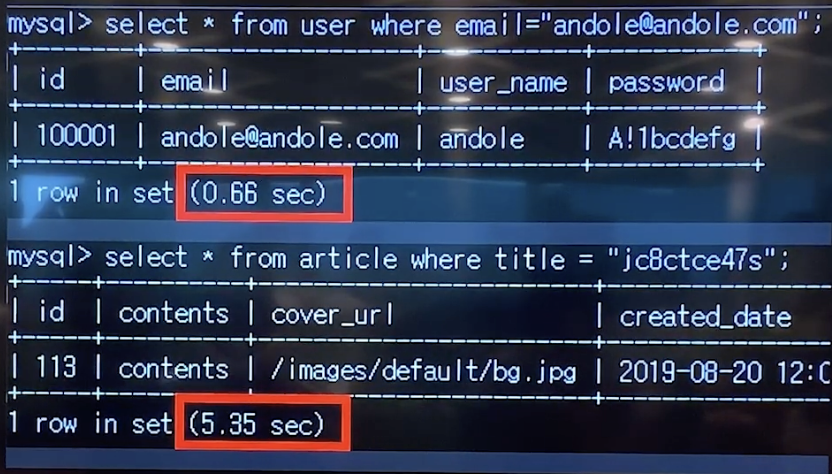
인덱스 적용 전
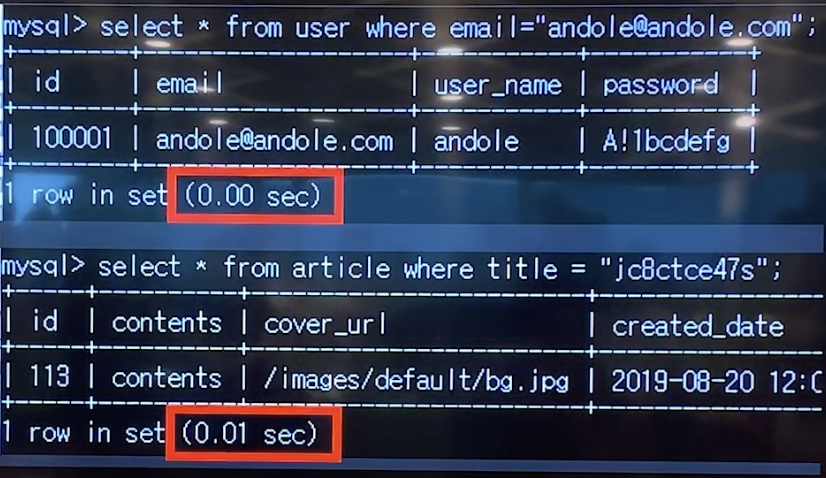
인덱스 적용 후
더 알아보기
- Explain(실행 계획)
- B-Tree, Page(Block) in InnoDB
- Cardinality
- Composite key
- InnoDB buffered pool size
- log throttle queries not using indexes

이전의 기록들 👉 https://blog.naver.com/reviewerkyj
인덱스의 기본 개념을 확인할 수 있었습니다! 인덱스의 자료 구조와 인덱스 생성 쿼리에 대해서도 작성하면 더 좋을 것 같습니다!