📍 "면접을 위한 CS 전공지식 노트 (저: 주홍철)"을 읽고 정리
📍 4장 데이터베이스
4.1. 데이터베이스의 기본
- 데이터베이스: 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되는 데이터의 모음이다.
- 해당 데이터베이스를 제어, 관리하는 통합 시스템을 DBMS(Database Management System)라고 하며, 데이터베이스 안에 있는 데이터들은 특정 DBMS마다 정의된 쿼리 언어를 통해 삽입, 삭제, 수정, 조회 등을 수행할 수 있다.
4.1.1. 엔티티
- 엔티티: 사람, 장소, 물건, 사건, 개념 등 여러 개의 속성을 지닌 명사를 의미한다.
- 엔티티의 속성은 서비스의 요구 사항에 맞춰 정해진다.- 약한 엔티티와 강한 엔티티:
- A가 혼자서는 존재하지 못하고 B의 존재 여부에 따라 종속적이다.
- A는 약한 엔티티, B는 강한 엔티티
- 약한 엔티티와 강한 엔티티:
4.1.2. 릴레이션
- 릴레이션: 데이터베이스에서 정보를 구분하여 저장하는 기본 단위이다. 엔티티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리한다.
- 관계형데이터베이스에서는 릴레이션을 '테이블'이라고 한다. 예를 들어, MySQL의 구조는레코드-테이블-데이터베이스로 이루어져 있다.
- NoSQL 데이터베이스에서는 릴레이션을 '컬렉션'이라고 한다. 예를 들어, MongoDB의 구조는도큐먼트-컬렉션-데이터베이스로 이루어져 있다.

사진 출처: 링크
4.1.3. 속성
- 속성(attribute): 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보이다. 서비스의 요구 사항을 기반으로 관리해야 할 필요가 있는 속성들만 엔티티의 속성이 된다.
- 도메인(domain): 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합을 말한다. 예를 들어, 성별이라는 속성이 있다면 이 속성이 가질 수 있는 값은 {남, 여}라는 집합이 된다.
4.1.5. 필드와 레코드
- 앞에서 설명한 것들을 기반으로 데이터베이스에서 필드와 레코드로 구성된 테이블을 만들 수 있다.
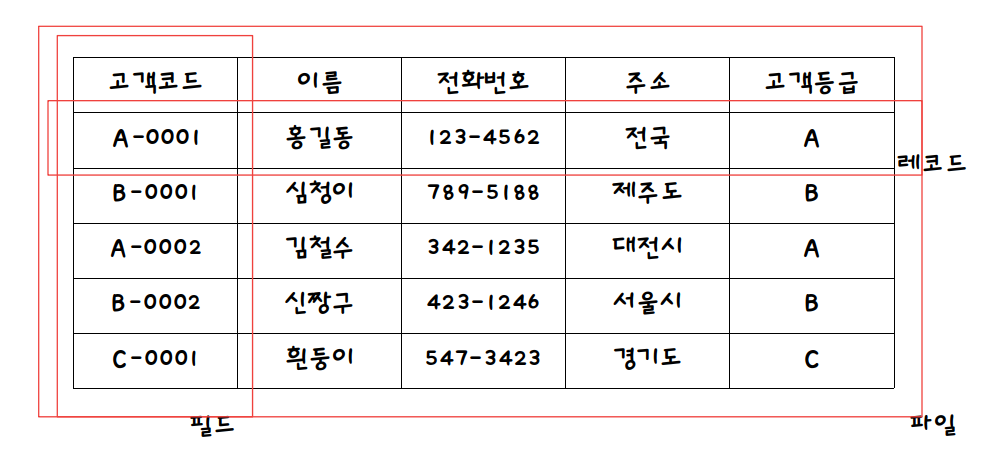
사진 출처: 링크
- 필드: 테이블의 속성. 고객코드, 이름, 전화번호 등이 필드이다.
- 필드 타입: 필드는 타입을 가진다. DBMS마다 다른 타입들을 가진다.
- MySQL의 필드 타입:
- 대표적으로 숫자 타입, 날짜 타입, 문자 타입이 있다.
- 숫자 타입
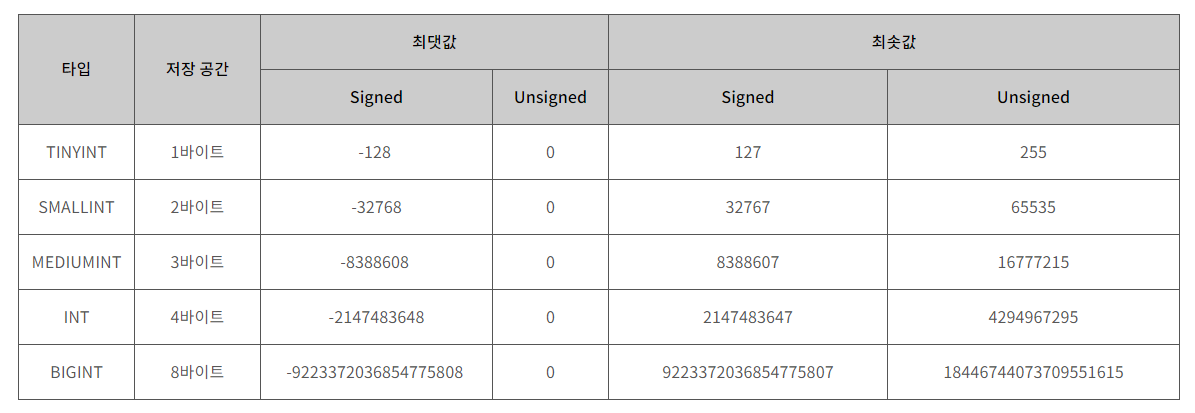
사진 출처: 링크 - 날짜 타입
- DATE: 날짜 부분은 있지만 시간 부분은 없는 값에 사용된다. 범위는 1000-01-01~9999-12-31이다. 3바이트의 용량을 가진다.
- DATETIME: 날짜 및 시간 부분을 모두 포함하는 값에 사용된다. 지원되는 범위는 1000-01-01 00:00:00에서 9999-12-31 23:59:59이다. 8바이트의 용량을 가진다.
- TIMESTAMP: 날짜 및 시간 부분을 모두 포함하는 값에 사용된다. 1970-01-01 00:00:01에서 2038-01-19 03:14:07까지 지원된다. 4바이트의 용량을 가진다. TIMESTAMP는 DATETIME과 달리 timezone에 따라 값이 바뀐다. 따라서, 글로벌 서비스에서는 TIMESTAMP를 사용하는 것이 좋다.
- 문자 타입
- CHAR와 VARCHAR: CHAR 또는 VARCHAR모두 그 안에 수를 입력해서 몇 자까지 입력할지 정한다.
- CHAR는 테이블을 생성할 때 선언한 길이로 고정되며 길이는 0에서 255 사이의 값을 가진다. 레코드를 저장할 때 무조건 선언한 길이의 값으로 '고정'해서 저장된다.
- VARCHAR는 가변 길이 문자열이다. 길이는 0에서 65,535 사이의 값으로 지정할 수 있으며, 입력된 데이터에 따라 용량을 가변시켜 저장한다. 예를 들어 10글자의 이메일을 저장할 경우 '10글자에 해당하는 바이트 + 길이기록용 1바이트'로 저장하게 된다.
Q. 언제 CHAR 또는 VARCHAR를 사용하는 것이 좋을까?
A. 속도 면에서 CHAR가 이점이 있고 공간 면에서 VARCHAR가 이점이 있다.
하지만 CHAR와 VARCHAR는 속도 차이가 거의 없기 때문에 VARCHAR가 좀 더 선호되는 추세이다.
- TEXT와 BLOB: 두 개의 타입 모두 큰 데이터를 저장할 때 쓰는 타입이다.
- TEXT: 큰 문자열 저장소에 쓰며 주로 게시판의 본문을 저장할 때 쓴다.
- BLOB: 이미지, 동영상 등 큰 데이터 저장에 쓴다. 그러나 보통은 아마존의 이미지 호스팅 서비스인 S3를 이용하는 등 서버에 파일을 올리고 파일에 관한 경로를 VARCHAR로 저장한다.
- ENUM과 SET: ENUM과 SET 모두 문자열을 열거한 타입이다.
- ENUM: ENUM 타입에 열거한 문자열 중 하나만 선택하는 단일 선택만 가능하다. ENUM 리스트에 없는 잘못된 값을 삽입하면 빈 문자열이 대신 삽입된다. ENUM을 이용하면 0,1 등으로 매핑되어 메모리를 적게 사용하는 이점을 얻습니다.
- SET: ENUM과 비슷하지만 여러 개의 데이터를 선택할 수 있고 비트 단위의 연산을 할 수 있으며 최대 64개의 요소를 집어넣을 수 있다.
- CHAR와 VARCHAR: CHAR 또는 VARCHAR모두 그 안에 수를 입력해서 몇 자까지 입력할지 정한다.
- MySQL의 필드 타입:
- 필드 타입: 필드는 타입을 가진다. DBMS마다 다른 타입들을 가진다.
- 레코드: 테이블에 쌓이는 행 단위의 데이터. 다른 말로는 '튜플'이라고 한다.
4.1.6. 관계
- 데이터베이스에는 여러 개의 테이블이 있고 이러한 테이블은 서로의 관계가 정의되어 있다. 대표적으로 1:1, 1:N, N:M 관계가 있다.
4.1.7. 키
-
테이블 간의 관계를 조금 더 명확하게 하고 테이블 자체의 인덱스를 위해 설정된 장치로 기본키, 외래키, 후보키, 슈퍼키, 대체키가 있다.
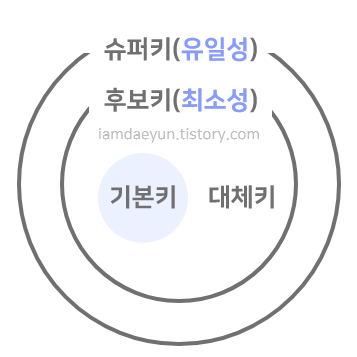
사진 출처: 링크 -
기본키(Primary Key): 유일성과 최소성을 만족하는 키이다. 테이블의 데이터 중 고유하게 존재하는 속성이기 때문에 중복되어서는 안된다. 기본키는 자연키 또는 인조키 중에 골라 설정한다.
-
자연키: 중복된 값들을 제외하며 중복되지 않은 것을 '자연스레' 뽑다가 나오는 키를 자연키라고 한다. 자연키는 언젠가는 변하는 속성을 가진다.
-
인조키: 인위적으로 아이디를 부여한다. 이를 통해 고유 식별자가 생겨난다. 오라클은 sequence, MySQL은 auto increment 등으로 설정한다.
-
외래키(Foreign Key): 다른 테이블의 기본키를 그대로 참조하는 값으로 개체와의 관계를 식별하는 데 사용한다. 외래키는 중복되어도 괜찮다.
-
후보키(candidate key): 기본키가 될 수 있는 후보들이며 유일성과 최소성을 동시에 만족하는 키이다.
-
대체키(alternate key): 후보키가 두 개 이상일 경우 어느 하나를 기본키로 지정하고 남은 후보키들을 말한다.
-
슈퍼키(super key): 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키이다.
4.2. ERD와 정규화 과정
- ERD(Entity Relationship Diagram): 데이터베이스를 구축할 때 가장 기초적인 뼈대 역할을 한다. 릴레이션 간의 관계들을 정의한 것이다.
4.2.1. ERD의 중요성
- ERD는 시스템의 요구 사항을 기반으로 작성되며 이 ERD를 기반으로 데이터베이스를 구축한다.
- 설계도 역할을 담당한다.
- 하지만 ERD는 관계형 구조로 표현할 수 있는 데이터를 구성하는 데 유용할 수 있지만 비정형 데이터를 충분히 표현할 수 없다는 단점이 있다.
Q. 비정형 데이터란?
A. 비구조화 데이터를 말하며, 미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보를 말한다.
4.2.3. 정규화 과정
- 정규화 과정: 릴레이션 간의 잘못된 종속 관계로 인해 데이터베이스 이상 현상이 일어나서 이를 해결하거나, 저장 공간을 효율적으로 사용하기 위해 릴레이션을 여러 개로 분리하는 과정이다.
- 정규화 과정은 정규형 원칙을 기반으로 정규형을 만들어가는 과정이며, 정규화된 정도는 정규형(NF, Normal Form)으로 표현한다.
- 기본 정규형인 제 1정규형, 제2정규형, 제3정규형, 보이스/코드 정규형이 있고 고급 정규형인 제4정규형, 제5정규형이 있다.
- 정규형 원칙: 같은 의미를 표현하는 릴레이션이지만 좀 더 좋은 구조로 만들어야 하고, 자료의 중복성은 감소해야 하고, 독립적인 관계는 별개의 릴레이션으로 표현해야 하며, 각각의 릴레이션은 독립적인 표현이 가능해야 하는 것을 말한다.
- 제1정규형: 릴레이션의 모든 도메인이 더 이상 분해될 수 없는 원자 값(atomic value)만으로 구성되어야 한다. 릴레이션의 속성 값 중에서 한 개의 기본키에 대해 두 개 이상의 값을 가지는 반복 집합이 있어서는 안 된다.
- 제2정규형: 부분 함수의 종속성을 제거한 형태를 말한다. 부분 함수의 종속성 제거란 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속적인 것을 말한다.
- 제3정규형: 제2정규형이고 기본키가 아닌 모든 속성이 이행적 함수 종속(transitive FD)을 만족하지 않는 상태를 말한다.
Q. 이행적 함수 종속이란?
A. A->B와 B->C가 존재하면 논리적으로 A->C가 성립하는데, 이때 집합 C가 집합 A에 이행적으로 함수 종속이 되었다고 한다.
- 보이스/코드 정규형(BCNF): 제3정규형이고, 결정자가 후보키가 아닌 함수 종속 관계를 제거하여 릴레이션의 함수 종속 관계에서 모든 결정자가 후보키인 상태를 말한다.
- 데이터베이스 이상 현상: 삭제나 삽입할 때 의도한 대로 삭제나 삽입이 이루어지지 않는 현상을 말한다.
- 정규화 과정을 거쳐 테이블을 나눈다고 해서 성능이 100% 좋아지는 것은 아니다. 성능이 좋아질 수도 나빠질 수도 있다. 테이블을 나누게 되면 어떠한 쿼리는 조인을 해야 하는 경우도 발생해서 오히려 느려질 수도 있기 때문에 서비스에 따라 정규화 또는 비정규화 과정을 진행해야 한다.
4.3. 트랜잭션과 무결성
4.3.1. 트랜잭션
- 트랜잭션: 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위. 즉 여러 개의 쿼리들을 하나로 묶는 단위
- 특성
- 원자성(atomicity): 트랜잭션과 관련된 일이 모두 수행되었거나 되지 않았거나를 보장하는 특징이다.
- 일관성(consistency): 데이터베이스에 기록된 모든 데이터는 여러 가지 조건, 규칙에 따라 유효함을 가져야 한다.
- 격리성(isolation): 트랜잭션 수행 시 서로 끼어들지 못하는 것을 의미한다. 복수의 병렬 트랜잭션은 서로 격리되어 마치 순차적으로 실행되는 것처럼 작동되어야 하고, 데이터베이스는 여러 사용자가 같은 데이터에 접근할 수 있어야 한다. 격리성은 여러 개의 격리 수준으로 나뉘어 격리성을 보장한다.
- 격리 수준에 따라 발생하는 현상
- 팬텀 리드(phantom read): 한 트랜잭션 내에서 동일한 쿼리를 보냈을 때 해당 조회 결과가 다른 경우를 말한다.
- 반복 가능하지 않은 조회: 한 트랜잭션 내의 같은 행이 두 번 이상 조회가 발생했는데, 그 값이 다른 경우를 가리킨다. 팬텀 리드와 다른 점은 반복 가능하지 않은 조회는 행 값이 달라질 수 있는 점이고, 팬텀 리드는 다른 행이 선택될 수 있다는 점이다.
- 더티 리드(dirty read): 반복 가능하지 않은 조회와 유사하며 한 트랜잭션이 실행 중일 때 다른 트랜잭션에 의해 수정되었지만 아직 '커밋되지 않은' 행의 데이터를 읽을 수 있을 때 발생한다.
- 격리 수준
- SERIALIZABLE: 트랜잭션을 순차적으로 진행시키는 것을 말한다. 여러 트랜잭션이 동시에 같은 행에 접근할 수 없다. 매우 업격한 수준으로 해당 행에 대해 격리시키기 때문에 교착 상태가 일어날 확률도 많고 성능이 떨어지는 격리 수준이다.
- REPEATABLE_READ: 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만 새로운 행을 추가하는 것은 막지 않는다. 따라서 이후에 추가된 행이 발견될 수도 있다.
- READ_COMMITTED: 가장 많이 사용되는 격리 수준으로 MySQL8.0, PostgreSQL, SQL Server, 오라클에서 기본값으로 설정되어 있다. READ_UNCOMMITTED와는 달리 다른 트랜잭션이 커밋하지 않은 정보는 읽을 수 없다. 즉 커밋 완료된 데이터에 대해서만 조회를 허용한다. 하지만 어떤 트랜잭션이 접근한 행을 다른 트랜잭션이 수정할 수 있다.
- READ_UNCOMMITED: 가장 낮은 격리 수준으로, 하나의 트랜잭션이 커밋되기 이전에 다른 트랜잭션에 노출되는 문제가 있지만 가장 빠르다. 이는 데이터 무결성을 위해 되도록이면 사용하지 않는 것이 이상적이나, 몇몇 행이 제대로 조회되지 않더라도 괜찮은 거대한 양의 데이터를 '어림잡아' 집계하는 데는 사용하면 좋다.

사진 출처: 링크
- 격리 수준에 따라 발생하는 현상
- 지속성(durability): 성공적으로 수행된 트랜잭션은 영원히 반영되어야 하는 것을 의미한다.
- 특성
4.3.2. 무결성
- 무결성: 데이터의 정확성, 일관성, 유효성을 유지하는 것을 말하며, 무결성이 유지되어야 데이터베이스에 저장된 데이터 값과 그 값에 해당하는 현실 세계의 실제 값이 일치하는지에 대한 신뢰가 생긴다.
- 무결성 종류
- 개체 무결성: 기본키로 선택된 필드는 빈 값을 허용하지 않는다.
- 참조 무결성: 서로 참조 관계에 있는 두 테이블의 데이터는 항상 일관된 값을 유지해야 한다.
- 고유 무결성: 특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우 그 속성 값은 모두 고유한 값을 가진다.
- NULL 무결성: 특정 속성 값에 NULL이 올 수 없다는 조건이 주어진 경우 그 속성 값은 NULL이 될 수 없다는 제약 조건이다.
- 무결성 종류
4.4. 데이터베이스의 종류
4.4.1. 관계형 데이터베이스
- 관계형 데이터베이스(RDBMS): 행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스이다. SQL 언어로 데이터베이스를 조작한다.
- MySQL
- MySQL은 대부분의 운영체제와 호환되며 현재 가장 많이 사용하는 데이터베이스이다.
- C, C++로 만들어졌으며 MyISAM 인덱스 압축 기술, B-트리 기반의 인덱스, 스레드 기반의 메모리 할당 시스템, 매우 빠른 조인, 최대 64개의 인덱스를 제공한다.
- 대용량 데이터베이스를 위해 설계되어 있고 롤백, 커밋, 이중 암호 지원 보안 등의 기능을 제공하며 많은 서비스에서 사용한다.
- 모듈식 아키텍처로 쉽게 스토리지 엔진을 바꿀 수 있다.
- 데이터 웨어하우징, 트랜잭션 처리, 고가용성 처리에 강점을 두고 있다.
- 쿼리 캐시를 지원해서 입력된 쿼리 문에 대한 전체 결과 집합을 저장하기 때문에 사용자가 작성한 쿼리가 캐시에 있는 쿼리와 동일하면 서버는 단순히 구문 분석, 최적화 및 실행을 건너뛰고 캐시의 출력만 표시한다.
- PostgreSQL
- PostgreSQL은 MySQL 다음으로 개발자들이 선호하는 데이터베이스 기술이다.
- 디스크 조각이 차지하는 영역을 회수할 수 있는 장치인 VACUUM이 특징이다. 최대 테이블의 크기는 32TB이며 SQL뿐만 아니라 JSON을 이요해서 데이터에 접근할 수 있다. 지정 시간에 복구하는 기능, 로깅, 접근 제어, 중첩된 트랜잭션, 백업 등을 할 수 있다.
- MySQL
4.4.2. NoSQL 데이터베이스
- NoSQL(Not only SQL): SQL을 사용하지 않는 데이터베이스를 말한다.
- MongoDB
- JSON을 통해 데이터에 접근할 수 있고, Binary JSON(BSON) 형태로 데이터가 저장되며 와이어드타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐먼트 기반의 데이터베이스이다.
- 확장성이 뛰어나며 빅데이터를 저장할 때 성능이 좋고 고가용성과 샤딩, 레플리카셋을 지원한다.
- 스키마를 정해 놓지 않고 데이터를 삽입할 수 있기 때문에 다양한 도메인의 데이터베이스를 기반으로 분석하거나 로깅 등을 구현할 때 강점을 보인다.
- 도큐먼트를 생성할 때마다 다른 컬렉션에서 중복된 값을 지니기 힘든 유니크한 값인 ObjectID가 생성된다.
- redis
- redis는 인메모리 데이터베이스이자 키-값 데이터 모델 기반의 데이터베이스이다.
- 기본적인 데이터 타입은 문자열(string)이며 최대 512MB까지 저장할 수 있다. 이 외에도 set, hash 등을 지원한다.
- pub/sub 기능을 통해 채팅 시스템, 다른 데이터베이스 앞단에 두어 사용하는 캐싱 계층, 단순한 키-값이 필요한 세션 정보 관리, 정렬된 셋(sorted set) 자료 구조를 이용한 실시간 순위표 서비스에 사용한다.
- MongoDB
4.5. 인덱스
4.5.1. 인덱스의 필요성
- 인덱스는 데이터를 빠르게 찾을 수 있는 하나의 장치이다.
4.5.2. B-트리
- 인덱스는 보통 B-트리라는 자료 구조로 이루어져 있다.
- 이는 루트 노드, 리프 노드, 그리고 루트 노드와 리프 노드 사이에 있는 브랜치 노드로 나뉜다.
Q. 인덱스가 효율적인 이유는?
A. 인덱스가 효율적인 이유는 효율적인 단계를 거쳐 모든 요소에 접근할 수 있는 균형 잡힌 트리 구조와 트리 깊이의 대수확장성 때문이다.
대수확장성이란 트리 깊이가 리프 노드의 수에 비해 매우 느리게 성장하는 것을 의미한다. 기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가한다.
4.5.3. 인덱스를 만드는 방법
- 인덱스를 만드는 방법은 데이터베이스마다 다르다.
- MySQL
- 클러스터형 인덱스와 세컨더리 인덱스가 있다.
- 클러스터형 인덱스는 테이블당 하나를 설정할 수 있다. primary key 옵션으로 기본키로 만들면 클러스터형 인덱스를 생성할 수 있고, 기본키로 만들지 않고 unique not null 옵션을 붙이면 클러스터형 인덱스로 만들 수 있다.
- 세컨더리 인덱스는 보조 인덱스로 여러 개의 필드 값을 기반으로 쿼리를 많이 보낼 때 생성해야 하는 인덱스이다.
더 자세한 사항은 다음 자료를 참고하자.
- MongoDB
- 도큐먼트를 만들면 자동으로 ObjectID가 형성되며, 해당 키가 기본키로 설정된다. 그리고 세컨더리키도 부가적으로 설정해서 기본키와 세컨더리키를 같이 쓰는 복합 인덱스를 설정할 수 있다.
4.5.4. 인덱스 최적화 기법
-
인덱스 최적화 기법: 데이터베이스마다 조금씩 다르지만 기본적인 골조는 똑같다. 여기서는 MongoDB를 기반으로 인덱스 최적화 기법을 설명한다.
1. 인덱스는 비용이다.
- 인덱스는 두 번 탐색하도록 강요한다. 인덱스 리스트, 그 다음 컬렉션 순으로 탐색하기 때문이며, 관련 읽기 비용이 들게 된다.
- 컬렉션이 수정되었을 때 인덱스도 수정되어야 한다. 이때 B- 트리의 높이를 균형 있게 조절하는 비용도 들고, 데이터를 효율적으로 조회할 수 있도록 분산시키는 비용도 든다.
- 그렇기 때문에 쿼리에 있는 필드에 인덱스를 무작정 다 설정하는 것은 답이 아니다.
- 컬렉션에서 가져와야 하는 양이 많을수록 인덱스를 사용하는 것은 비효율적이다.
2. 항상 테스팅하라
- 인덱스 최적화 기법은 서비스의 특징에 따라 달라진다. 서비스에서 사용하는 객체의 깊이, 테이블의 양 등이 다르기 때문이다.
- 그렇기 때문에 항상 테스팅하는 것이 중요하다.
3. 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순이다.
- 보통 여러 필드를 기반으로 조회를 할 때 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다. 같음, 정렬, 다중 값, 카디널리티 순으로 생성해야 한다.
4.6. 조인의 종류
4.7. 조인의 원리
