
내가 졸업 프로젝트를 하는 날이 오다니…😱😱
우리 팀의 프로젝트 주제는 AI 기반 영어 말하기 분석 어플리케이션으로, 사용자가 영어로 말한 내용을 STT(Speech-To-Text) 기술을 활용하여 텍스트로 변환한 후 이를 활용하여 문법 검사, 발음 평가 등 다양한 분석 기능을 제공하고자 한다.
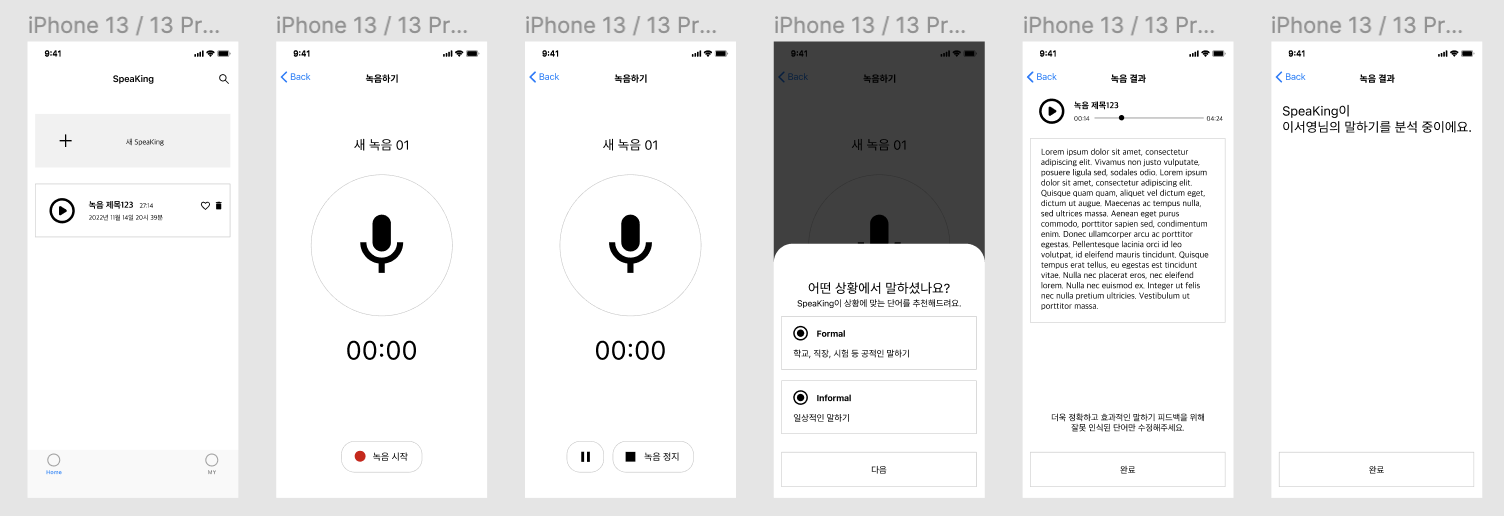
⬆️ 프로젝트의 와이어프레임
나는 클라이언트 담당으로, Swift를 활용하여 iOS 어플리케이션을 개발할 예정이다.
본격적으로 개발을 시작하기 전 iOS에서 Speech Recognition 및 발음 평가 API를 사용하는 방법을 알아보고자 한다. 👀
그럼 시작!
✏️ STT란?
음성 인식(Speech Recognition) 또는 STT(Speech-to-Text)란 사람이 말하는 음성 언어를 컴퓨터가 해석해 그 내용을 문자 데이터로 전환하는 처리를 말한다.
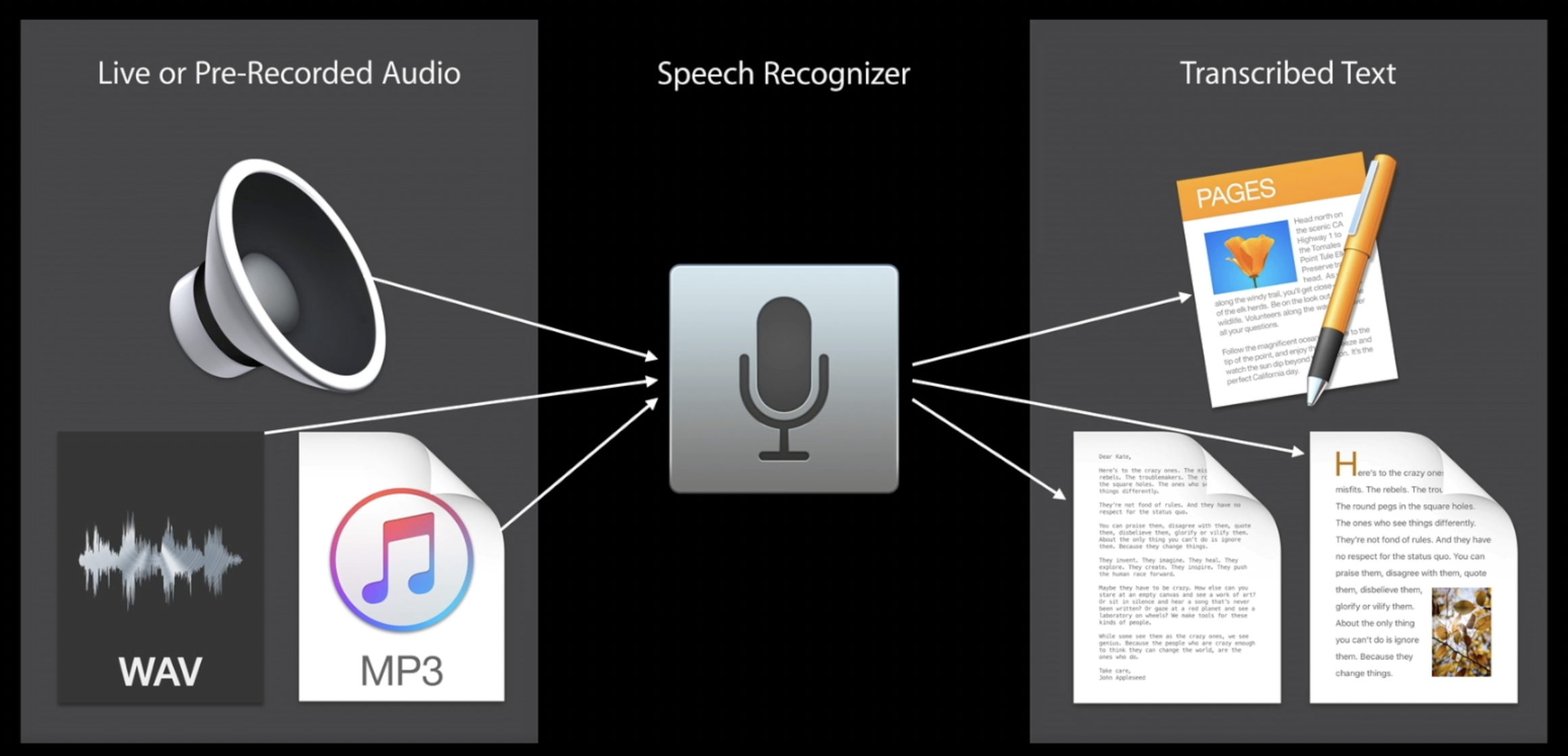
iOS에서 사용할 수 있는 대표적인 STT API는 다음과 같다.
우리 프로젝트에서는 이 API들 중 Apple Speech를 사용해 STT를 구현하기로 하였다.
Apple Speech는 일단 무료(!!)이다. 또한 Apple에서 기본적으로 제공하는 프레임워크인 만큼 iOS 애플리케이션 내에서 구현하기 훨씬 수월할 것이라고 생각했다. 무엇보다 confidence levels, speaking rate, average pause duration 등 다양한 분석 결과를 제공하기 때문에 우리 프로젝트에서 유용하게 사용할 수 있을 것이라고 생각했다.
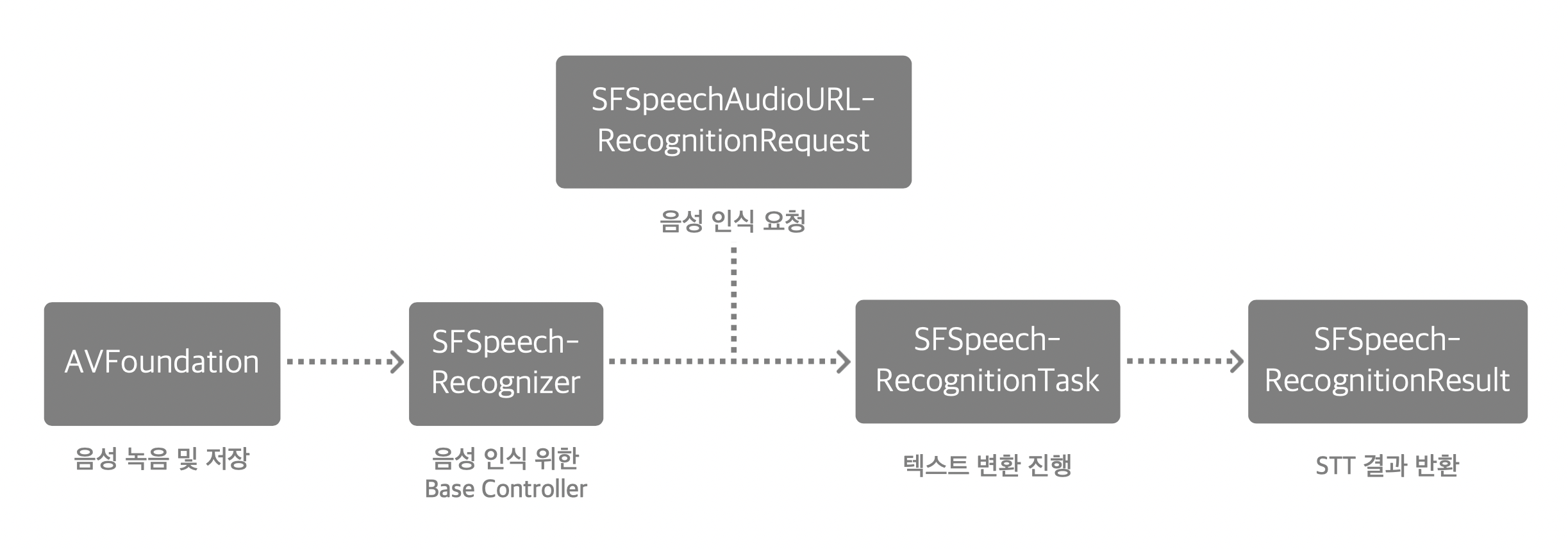
Speech 프레임워크를 사용한 Speech Recognition 과정은 위와 같다.
🔒 Privacy 설정하기
앱 내에서 사용자의 음성을 녹음하고 STT를 사용하기 위해서는 먼저 사용자로부터 권한을 부여받아야 한다.
iOS에서는 사용자의 프라이버시를 매우 중요하게 여긴다. 사용자의 정보를 얻기 위해서는 반드시 사전에 사용자의 동의를 얻어야 한다. 또한 사용자 정보 보호를 위한 적절한 단계를 거쳐야 하고, 사용 이유를 명확하게 밝혀야 한다.
실제 배포시에도 Privacy 관련 이슈로 reject이 되기도 한다니 처음부터 꼼꼼하게 설정해두자.
자세한 정보는 Apple Developer Documentation 에서 확인할 수 있다.
우리는 음성 녹음과 STT 두 가지 기능을 사용할 것이기 때문에 각각 Microphone Usage와 Speech Recognition Usage에 대한 권한이 필요하다.
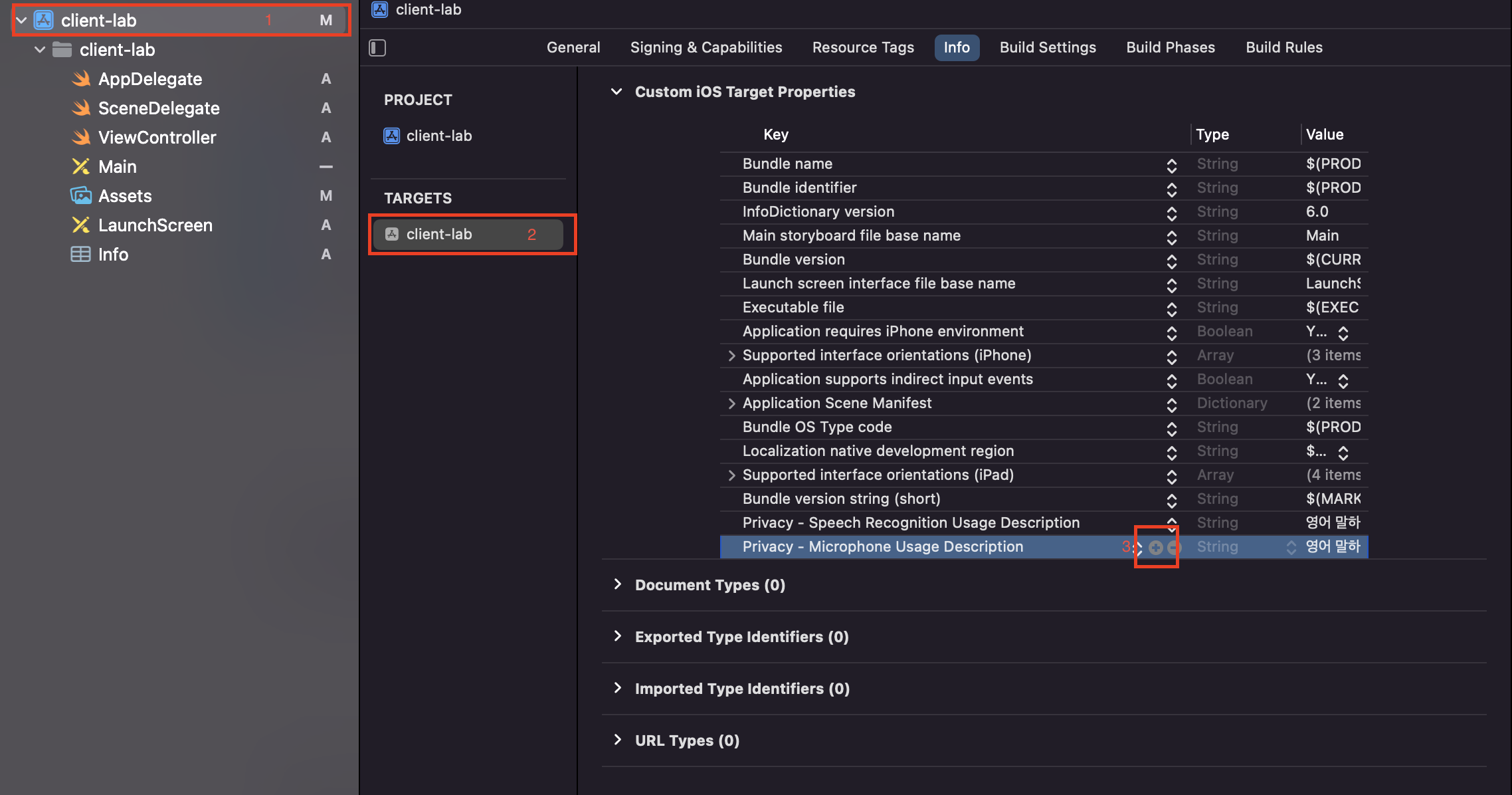
Privacy 설정을 하기 위한 방법은 아래와 같다.
- 프로젝트 내비게이터(Xcode 좌측 파일 목록)에서 프로젝트를 선택
- Targets을 선택하고 Info tab을 클릭한다.
- 아무 Key를 선택한 후 우측에 있는 + 버튼을 눌러 새 Key를 추가한다. 이때
Privacy - Speech Recognition Usage Description key와Privacy - Microphone Usage Description두 가지 Key를 추가하고, Value에는 이 기능을 사용해야 하는 이유를 작성한다.
🎙 AVFoundation을 사용해서 음성 녹음하기
어떤 API를 사용해야 할까?
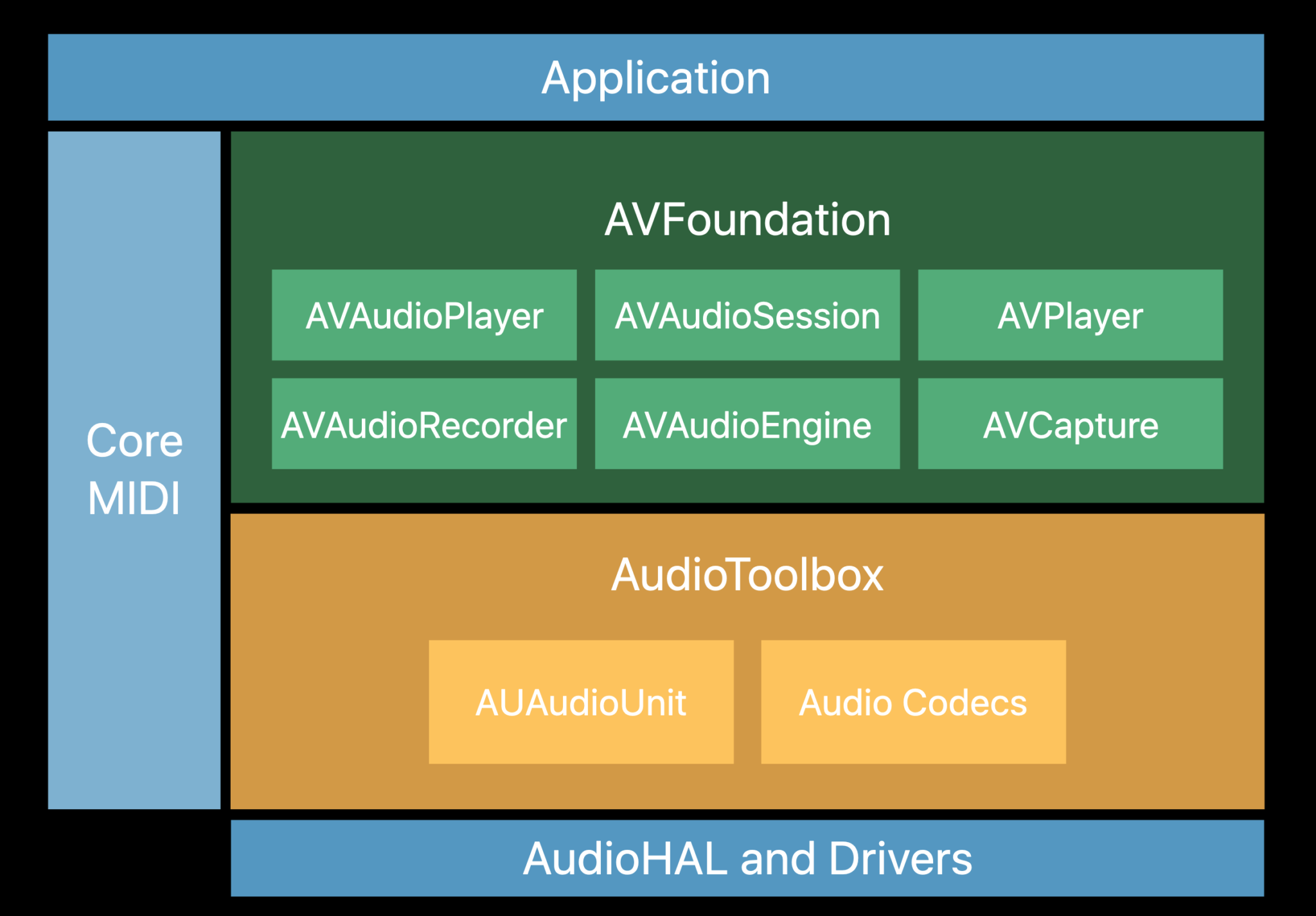
AVFoundation은 Apple 플랫폼에서 시청각 미디어를 검사, 재생, 처리 등 다양한 작업을 도와주는 기술들이 포함된 프레임워크이다.
AVFoundation 내에는 음성 녹음 기능이 포함된 클래스들이 여러 가지가 있다. 그래서 iOS에서 음성 녹음을 구현하는 방법을 검색해보면 사람들마다 다 다른 클래스를 사용해서 구현하고 있어 매우 혼란스러웠다. 🤯
나처럼 혼란을 겪을 분들을 위해 잠깐 음성 녹음과 관련된 클래스들의 특징을 정리하고 넘어가고자 한다.
- AVAudioRecorder
- iOS에서 음성 녹음을 구현할 수 있는 가장 간단한 API이다.
- 녹음 중 오디오 샘플 버퍼를 제공하지 않기 때문에 파일로 저장되기 전에는 음성을 분석하거나 처리할 수 없다. 또한 비디오 녹화를 지원하지 않는다.
- AVCapture
- AVCaptureDevice, AVCaptureDeviceInput, AVCaptureSession, AVCaptureOutput으로 구성되어 있다.
- 간단한 프로세싱 아키텍처 같은 input, output 노드 그래프의 정도를 제공한다.
- 샘플 버퍼를 사용해서 분석 및 처리가 가능하고 비디오 캡쳐도 할 수 있다. 그래서 주로 카메라 앱을 만드는 데 사용되는 것 같다.
- 직렬 신호 분석 및 처리를 위해 설계되지 않았으며, 몇몇 필요한 설정들이 포함되지 않는다.
- AVAudioEngine
- iOS/macOS에서 사용되는 low-level 소프트웨어 오디오 모듈이다. 오디오 캡쳐/녹음/재생의 시작을 관리할 수 있는 프레임워크를 제공하며, Apple에서 가장 권장하는 API이다.
- 동적으로 오디오 그래프와 프로세싱 체인을 만들고 TAP을 사용해서 오디오 버퍼를 보고 분석할 수 있다. 오디오 프로세싱을 하려면 그래프에 프로세싱 노드를 추가해야 한다.
- AudioUnit App Extension으로 사용해서 다른 오디오 앱의 프로세싱 플러그인 역할을 할 수 있다.
- 다양한 설정을 할 수 있으며 사용 가능한 기본 프로세싱 노드들이 있다.
- 그러나 네이티브에서 비디오 캡쳐를 지원하지 않고, 버퍼 관리 등의 오디오 엔지니어링 지식이 필요하기 때문에 구현이 어렵다.
- AudioToolbox
- iOS/macOS에서 사용되는 low-level C 프로그래밍 인터페이스이다. 녹음, 재생, 파싱 등을 할 수 있다.
- 다양한 설정이 가능하지만 사용하기 어렵다.
- input, output, 프로세싱 노드를 관리하는 기능이 없으며, 네이티브 비디오 캡쳐를 지원하지 않는다.
- 일반적으로 사용이 되지 않는 것 같다.
| 샘플 버퍼 접근 | 비디오 지원 | 난이도 | |
|---|---|---|---|
| AVAudioRecorder | X | X | 낮음 |
| AVCapture | O | O | 중간 |
| AVAudioEngine | O | X | 높음 |
| Audio Toolbox | O | X | 매우 높음 |
네 가지 API를 비교해본 결과, 우리 프로젝트에서는 녹음된 음성 데이터가 필요할 뿐, 복잡한 가공이 필요하지 않기 때문에 가장 간단한 AVAudioRecorder를 사용하기로 하였다.
음성 녹음 구현해보기
AVAudioRecorder를 사용하기 위해 가장 먼저 ViewController 파일에서 AVFoundation 프레임워크를 import 해준다.
import AVFoundation그리고 AVAudioRecorder와 관련된 프로퍼티를 선언해준다.
var recordingSession: AVAudioSession!
var audioRecorder: AVAudioRecorder!-
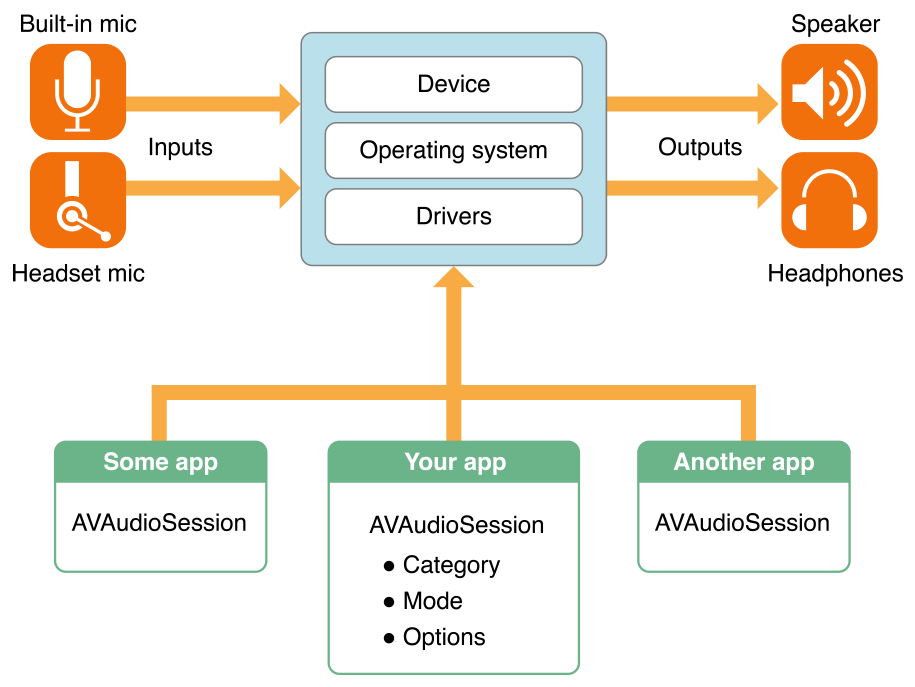
- 앱 내의 오디오 동작을 설정하기 위한 앱과 운영체제의 중개 역할을 담당한다.
- 오디오 하드웨어와의 디테일한 상호작용은 신경 쓰지 않아도 된다.
- 오디오 사용 여부 등을 운영체제에게 알려준다.
override func viewDidLoad() {
super.viewDidLoad()
// ...
// Singleton 인스턴스를 얻어온다.
recordingSession = AVAudioSession.sharedInstance()
do {
// 오디오 세션의 카테고리와 모드를 설정한다.
try recordingSession.setCategory(.playAndRecord, mode: .default)
try recordingSession.setActive(true)
// 음성 녹음 권한을 요청한다.
recordingSession.requestRecordPermission() { allowed in
if allowed {
print("음성 녹음 허용")
} else {
print("음성 녹음 비허용")
}
}
} catch {
print("음성 녹음 실패")
}
}ViewController의 viewDidLoad 메소드 내에서 audio session 싱글톤 인스턴스를 얻어온 후 음성 녹음과 관련된 권한을 요청하는 메소드를 호출한다.
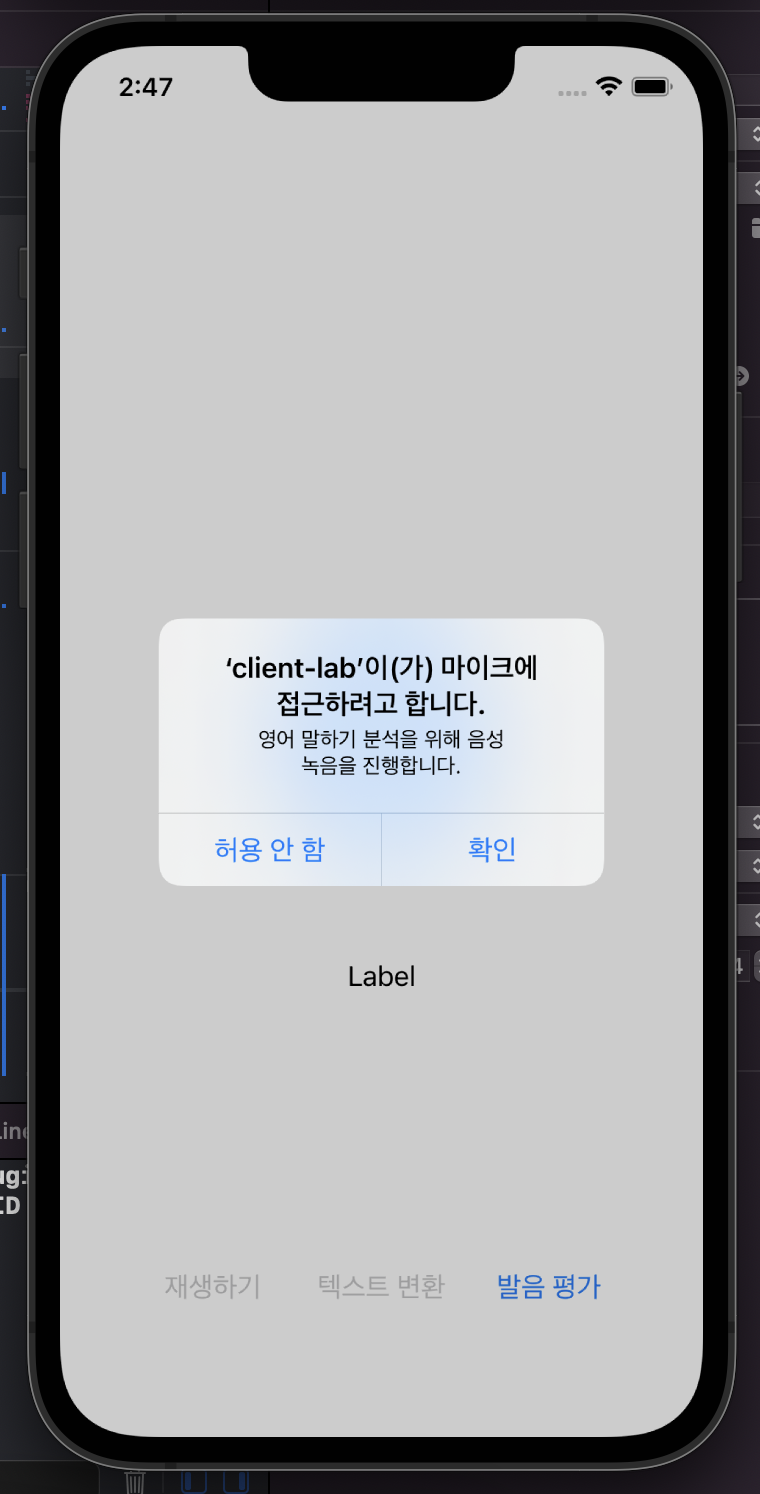
위 코드를 작성한 후 시뮬레이터에서 애플리케이션을 실행하면 마이크 권한을 요청하는 팝업이 뜬다.
그리고 가운데 마이크 버튼을 누르면 녹음이 시작 또는 정지되도록 하였다.
@IBAction func recordButtonTapped() {
if let recorder = audioRecorder {
if recorder.isRecording {
finishRecording(success: true)
} else {
startRecording()
}
} else {
startRecording()
}
}녹음 시작하기
func startRecording() {
let audioFilename = getDocumentsDirectory().appendingPathComponent("recording.wav")
let settings = [
AVFormatIDKey: Int(kAudioFormatLinearPCM),
AVSampleRateKey: 16000,
AVNumberOfChannelsKey: 1,
AVEncoderAudioQualityKey: AVAudioQuality.high.rawValue
]
do {
audioRecorder = try AVAudioRecorder(url: audioFilename, settings: settings)
audioRecorder.delegate = self
audioRecorder.record()
print("녹음 시작")
} catch {
finishRecording(success: false)
}
}
func getDocumentsDirectory() -> URL {
let paths = FileManager.default.urls(for: .documentDirectory, in: .userDomainMask)
return paths[0]
}getDocumentsDirectory().appendingPathComponent("recording.wav")를 사용하여 디바이스 내에 녹음된 음성이 저장될 경로를 지정한다.- File Manager는 iOS 애플리케이션마다 가지고 있는 공간을 관리하는 매니저이다.
settings에서 오디오와 관련된 설정값을 부여한다.- AVAudioRecorder의
record()메소드를 사용해서 녹음을 시작한다.
녹음 멈추기
func finishRecording(success: Bool) {
audioRecorder.stop()
if success {
playButton.isEnabled = true
transcribeButton.isEnabled = true
pronunciationButton.isEnabled = true
print("finishRecording - success")
} else {
playButton.isEnabled = false
transcribeButton.isEnabled = false
pronunciationButton.isEnabled = false
print("finishRecording - fail")
}
}녹음을 멈춰야 할 때는 AVAudioRecorder의 stop() 메소드를 사용한다. 그리고 재생, 텍스트 변환, 발음 평가 버튼을 활성화시킨다.
func audioRecorderDidFinishRecording(_ recorder: AVAudioRecorder, successfully flag: Bool) {
if !flag {
finishRecording(success: false)
}
}실제 사용자가 애플리케이션을 사용할 때는 전화가 오는 등 녹음이 중단되는 다양한 상황이 있을 수 있다. AVAudioRecorder의 delegate에 있는 audioRecorderDidFinishRecording 메소드에서 이런 상황에서 수행할 작업을 선언할 수 있다.
음성 재생하기
음성 녹음이 정상적으로 이뤄졌는지 확인하기 위해서는 음성을 재생하는 기능도 필요하다.
var audioPlayer: AVAudioPlayer?iOS에서 오디오를 재생하기 위해서는 AVAudioPlayer를 사용해야 한다. 따라서 View Controller에서 AVAudioPlayer 변수를 선언해준다.
@IBAction func playButtonTapped() {
audioPlayer = try? AVAudioPlayer(contentsOf: audioRecorder.url)
audioPlayer?.delegate = self
audioPlayer?.play()
}재생하기 버튼을 누르면 AVAudioPlayer를 사용해서 음성이 재생되도록 한다. 이때 음성 파일의 경로는 audioRecorder 의 url에 접근해서 알아올 수 있다.
🗣 Speech Recognition 구현하기
이제 녹음된 음성을 사용해서 Speech Recognition을 구현해보자.
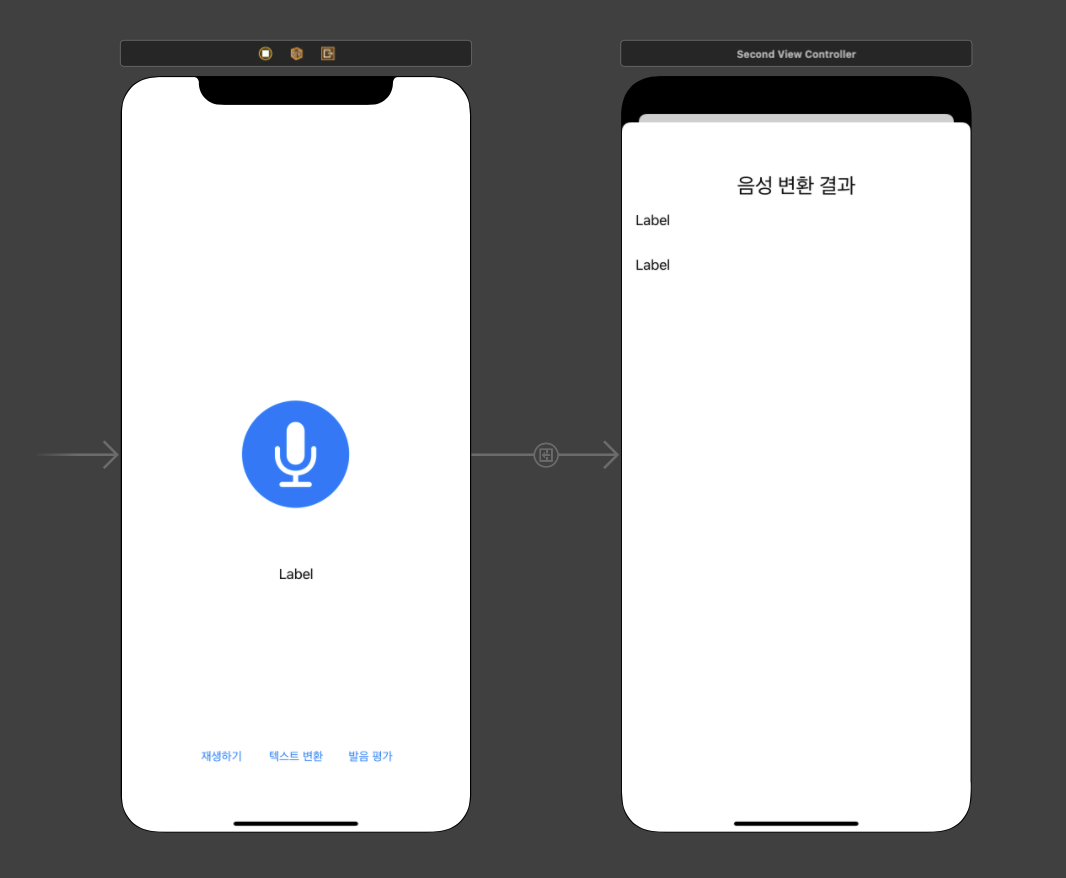
음성 녹음을 완료한 후 발음 평가 버튼을 누르면 새 화면에서 텍스트로 변환된 결과를 보여주고자 한다.
앞에서 언급했듯 Speech Recognition을 위해서 Apple의 Speech 프레임워크를 사용한다.
Speech 프레임워크는 실시간으로 사용자의 발화 내용을 인식할 수도 있고, 오디오 파일의 내용을 인식할 수도 있다.
우리는 오디오 파일을 사용해서 Speech Recognition을 진행할 것이기 때문에 SecondViewController에게 음성 파일의 경로를 알려주어야 한다.
// SecondViewController.swift
var audioUrl: URL?// ViewController.swift
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
guard let secondViewController = segue.destination as? SecondViewController else {
return
}
secondViewController.audioUrl = audioRecorder.url
}ViewController.swift에서 prepare 메소드를 사용하여 SecondViewController 의 audioUrl에 음성 파일 경로를 저장한다.
Speech Recognizer 사용하기
파일 경로까지 얻었으니 본격적으로 Speech Recognition을 구현해보자.
AVFoundation처럼 SecondViewController에서도 Speech 프레임워크를 import 해주어야 한다.
import Speech그리고 Speech Recognition 작업을 초기화하기 위해서 먼저 SFSpeechRecognizer 객체를 생성한다.
let speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: "en-US"))SFSpeechRecognizer는 speech recognizer 과정을 관리하는 핵심 오브젝트이다. 이 오브젝트는 음성 인식 권한 요청, 음성 인식 중 사용 언어 설정, 음성 인식 작업 초기화를 할 때 사용한다.
객체를 생성할 때 locale 이 없으면 사용자의 기본 언어로 speech recognition이 이루어진다. 우리 프로젝트에서는 영어를 인식해야 하기 때문에 지역을 명시적으로 선택해준다.
녹음과 마찬가지로 speech recognition도 권한 요청을 반드시 해주어야 한다.
override func viewDidLoad() {
super.viewDidLoad()
SFSpeechRecognizer.requestAuthorization { (status) in
switch status {
case .notDetermined: print("Not determined")
case .restricted: print("Restricted")
case .denied: print("Denied")
case .authorized: print("We can recognize speech now.")
@unknown default: print("Unknown case")
}
}
}SFSpeechRecognizer에 있는 requestAuthorization 메소드를 호출하여 음성 인식 권한 요청 팝업을 띄워준다.
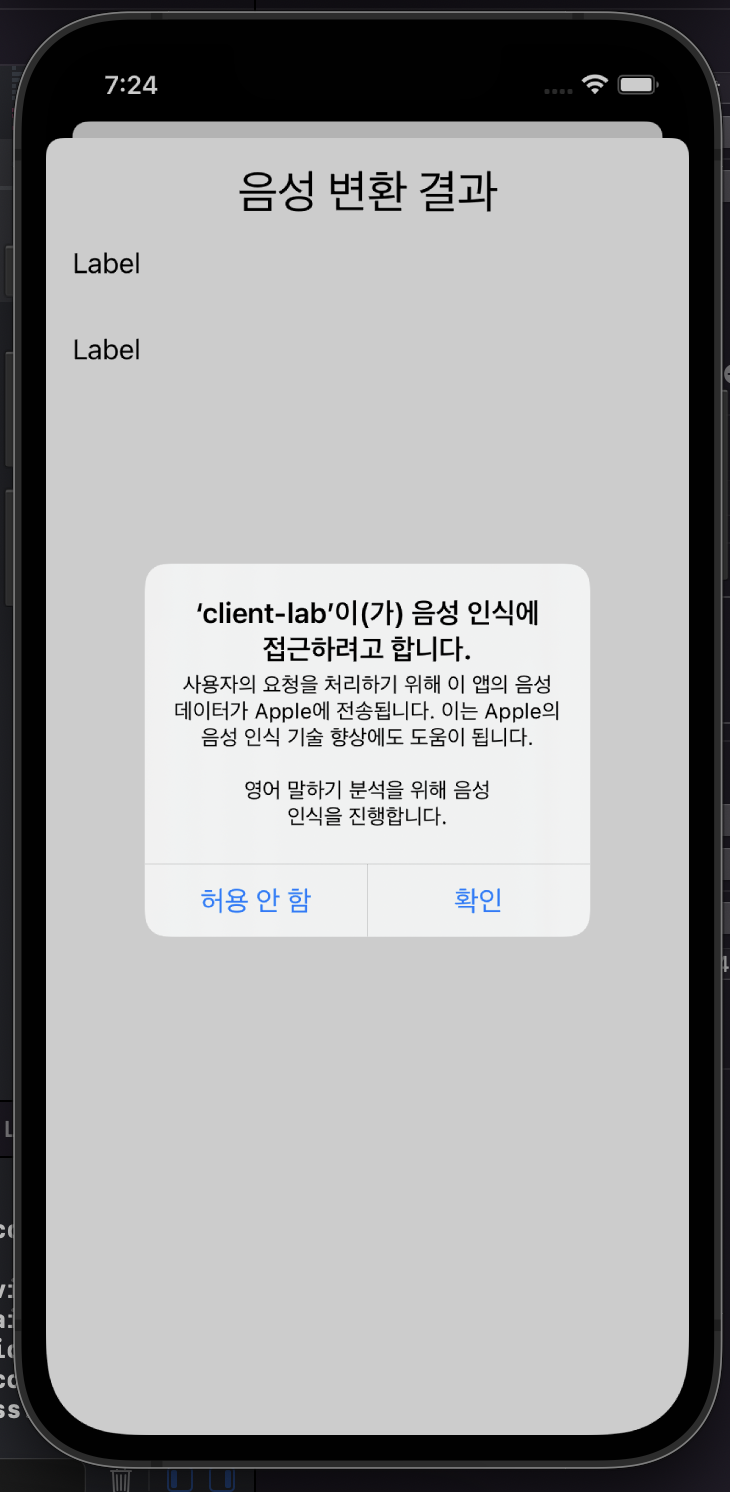
권한 허용까지 받으면 이제 음성 인식을 사용할 수 있다. 음성 인식을 진행하고 결과를 보여주기 위한 transcribeAudio() 메소드를 만들어준다.
func transcribeAudio() {
guard let audioUrl = audioUrl else {
print("Can't find audio url")
return
}
if speechRecognizer!.isAvailable {
let request = SFSpeechURLRecognitionRequest(url: audioUrl)
speechRecognizer?.supportsOnDeviceRecognition = true
speechRecognizer?.recognitionTask(
with: request,
resultHandler: { (result, error) in
if let error = error {
print(error.localizedDescription)
} else if let result = result {
print(result.bestTranscription.formattedString)
if result.isFinal {
self.resultLabel.text = result.bestTranscription.formattedString
if let metaData = result.speechRecognitionMetadata {
self.speakingRateLabel.text = "WPM: \(metaData.speakingRate)"
}
}
}
})
}
}-
speech recognizer 객체를 사용할 때는
isAvailable프로퍼티를 사용해서 서비스를 사용할 수 있는지 먼저 확인해야 한다. -
available 하면 recognition 요청 객체를 생성한다.
- 이 객체의 종류는 이미 존재하는 오디오 파일을 사용할 것인지, 실시간으로 오디오를 받아올 것인지에 따라 다르다.
- 이미 있는 파일에 대해 요청할 것이라면
SFSpeechURLRecognitionRequest를 사용, 실시간으로 오디오를 받아오는 애플리케이션이라면SFSpeechAudioBufferRecognitionRequest를 사용한다. 우리 프로젝트는 전자의 경우에 해당한다.
-
recognitionTask(with:resultHandler:)메소드를 사용해서 recognition을 시작한다.-
resultHandler에 있는 블록은 음성 인식 결과가 나오거나 에러가 발생할 때 실행된다. -
result파라미터는 음성 인식 과정의 결과들을 포함하는 객체이다. (SFSpeechRecognitionResult)- 이 객체는 speech recognition 작업이 시작되면 Speech 프레임워크가 생성해서 resultHandler로 넘겨준다.
- result는 현재 발언에 대한 하나 이상의 변환 결과를 가지고, 각 결과들은 정확도를 가지고 있다.
bestTranscription프로퍼티를 사용해서 가장 정확도가 높은 결과를 얻어온다.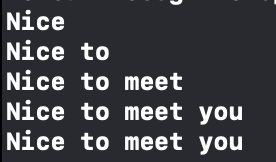
- result는 위 사진처럼 부분 결과도 포함하고 있다. 최종 변환 결과만을 얻기 위해서는
isFinal프로퍼티를 사용할 수 있다. - result는 average pause duration, speaking rate 등 다양한 발화 분석 정보를 가진 speechRecognitionMetadata 클래스를 포함하고 있다. 이 메타데이터를 활용해서 WPM을 쉽게 구할 수 있다.
-
💯 발음평가 API 사용하기
이번에는 저장된 음성 데이터를 서버와의 통신에 활용해보자.
ETRI에서 인공지능을 활용한 영어 발음평가 API를 무료로 제공하고 있다.
이 API를 사용하기 위해 16kHz로 녹음된 음성 데이터를 base64 문자열로 변환한 다음 body에 넣어서 HTTP request를 보낸다.
음성 데이터는 base64EncodedString() 메소드를 사용하면 간단하게 base64 문자열로 변환할 수 있다.
func postPronunciation() {
let url = "http://aiopen.etri.re.kr:8000/WiseASR/Pronunciation"
let key = ""
let audioData = try? Data(contentsOf: (audioRecorder?.url)!)
let encodedString = audioData?.base64EncodedString()
guard let encodedString = encodedString else {
print("오디오 인코딩 실패")
return
}
let parameters: Parameters = [
"access_key": key,
"argument": [
"language_code": "english",
"audio": encodedString
]
]
AF.request(url, method: .post, parameters: parameters, encoding: JSONEncoding.default, headers: ["Content-Type": "application/json; charset=UTF-8"])
.validate()
.responseDecodable(of: Pronunciation.self) { response in
switch response.result {
case .success(let response):
print(response)
case .failure(let error):
print(error.localizedDescription)
}
}
}정상적으로 요청을 보냈다면 텍스트로 변환된 문장과 발음 점수 데이터를 응답으로 받을 수 있다.
// PronunciationModel.swift
struct Pronunciation: Codable {
var requestId: String?
var result: Int?
var returnType: String?
var returnObject: PronuncationScore?
var reason: String?
enum CodingKeys: String, CodingKey {
case requestId = "request_id"
case result
case returnType = "return_type"
case returnObject = "return_object"
}
}
struct PronuncationScore: Codable {
var recognized: String
var score: Double
}HTTP response를 받기 위한 데이터 모델은 위와 같다.
💭 구현 결과 및 느낀 점
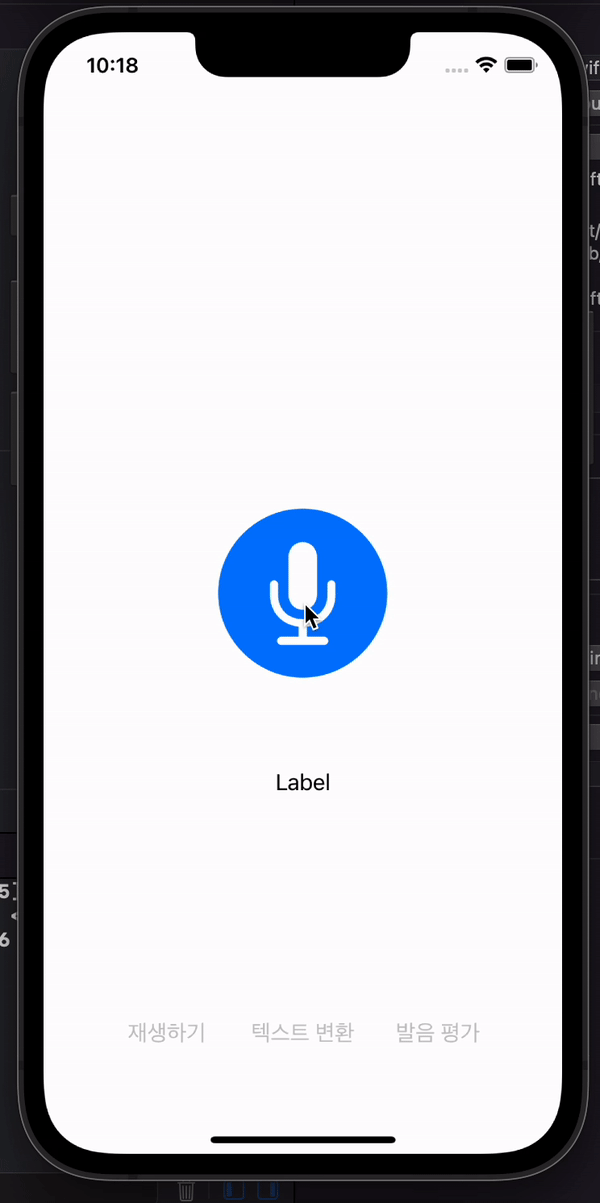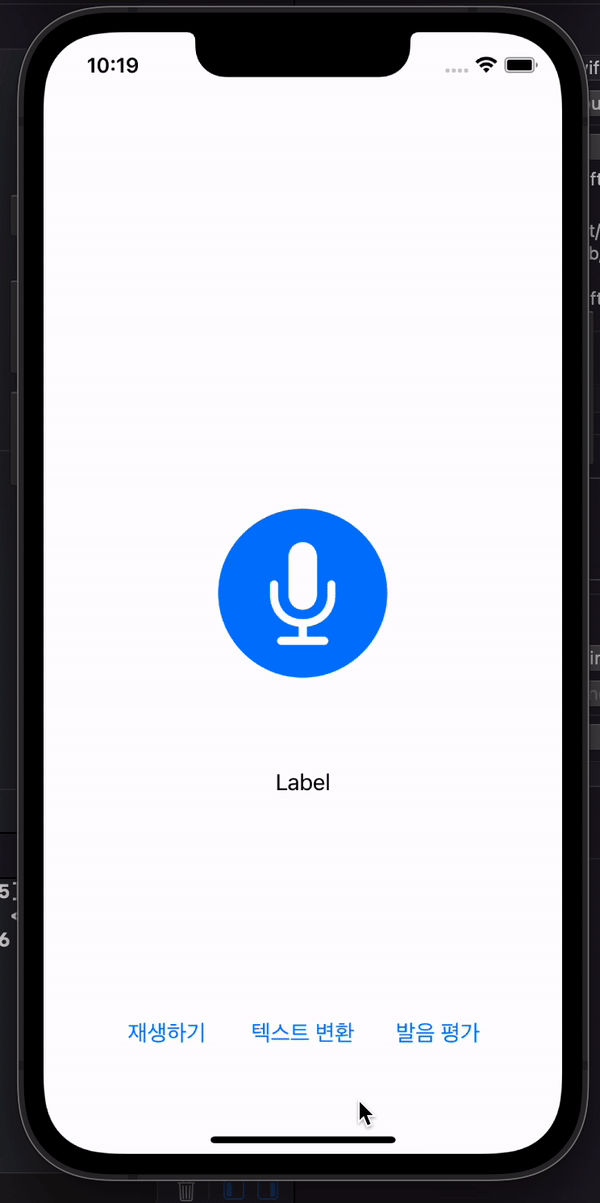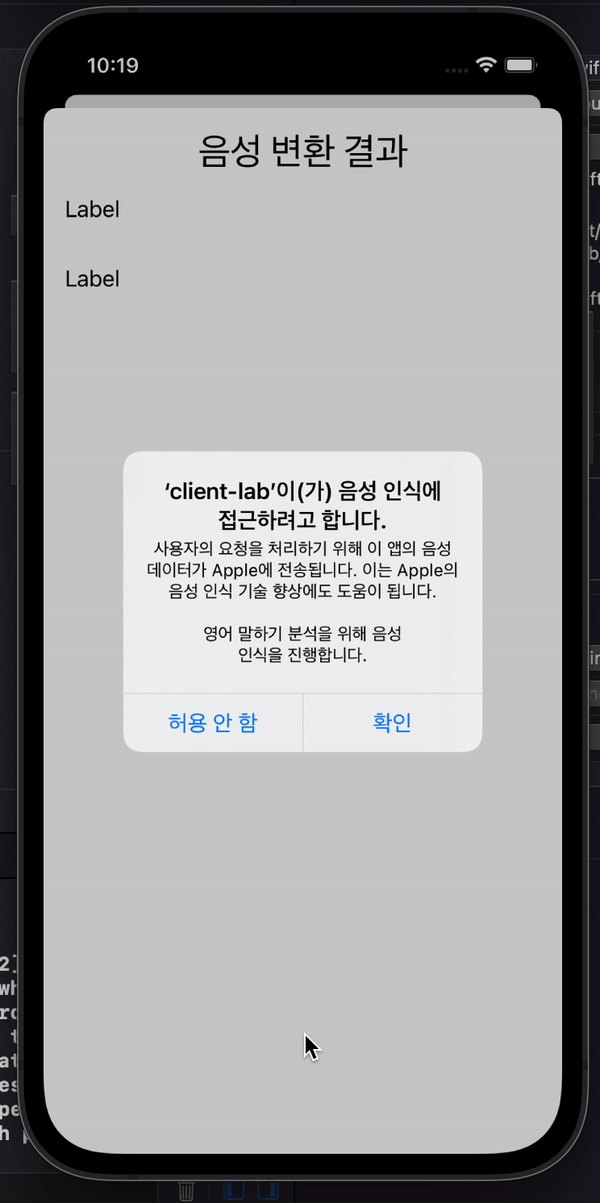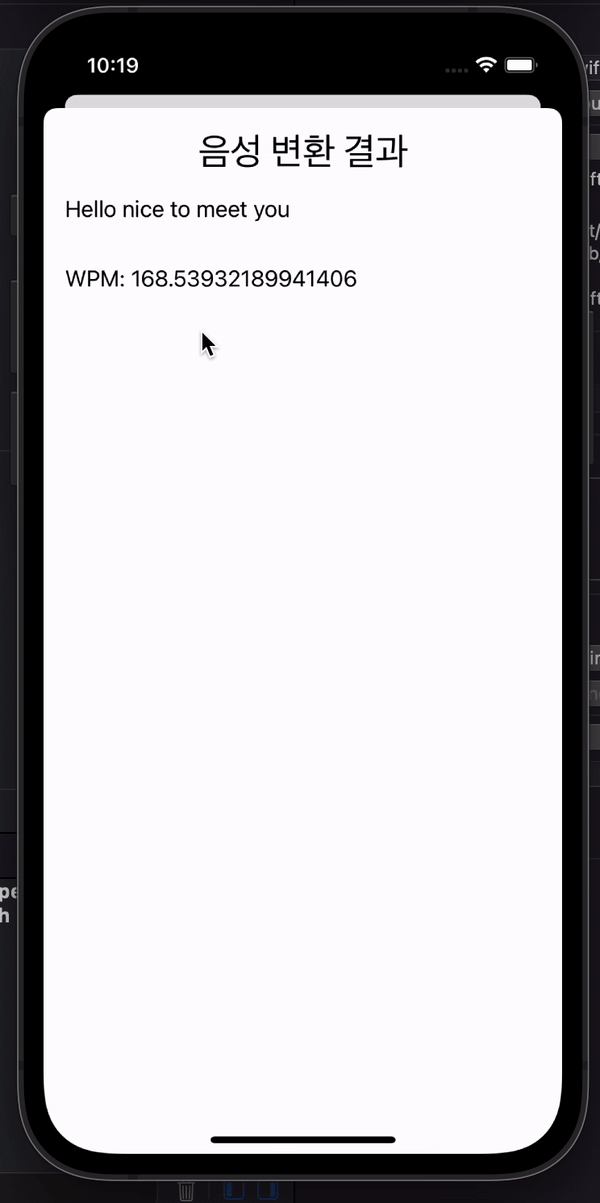
영상이 아니라 재생 기능은 생략했다. 🥲
이렇게 음성 데이터를 만지는 프로젝트는 처음인데, 공식 문서를 열심히 읽고 차근차근 따라가니 나름 원하는 대로 결과가 잘 나온 것 같다.
서버 구축까지 완료되면 서버와 음성 데이터를 주고 받는 것도 테스트 해보고 여러 음성 파일들을 목록으로 보여주는 것까지 부지런히 구현해봐야겠다.
졸프…. 파이팅!!!!🔥🔥
전체 코드는 GitHub에서 확인할 수 있다.

잘 읽었어요~