📒 MySQL 설치 및 DB 구축과정 미리 실습하기
📕 DBMS/MySQL
1. DBMS
1) DBMS 개념
- 데이터베이스
- 데이터의 집합 (데이터 저장공간 자체)
- 여러 명의 사용자나 응용 프로그램이 공유하고 동시에 접근이 가능해야 함
- DBMS
- 데이터베이스를 관리, 운영하는 역할
2) 특징
- 데이터의 무결성
- 데이터베이스 안의 데이터에 오류가 있어서는 안됨
- 데이터의 독립성
- 데이터베이스의 크기를 변경하거나 데이터 파일의 저장소를 변경하더라도, 기존에 작성된 응용 프로그램은 영향 받지X
- 서로 의존적 관계가 아닌 독립적인 관계
- 보안
- 데이터베이스 안의 데이터에 아무나 접근하는 것이 아니라 데이터를 소유한 사람이나 데이터에 접근이 허가된 사람만 접근 가능
- 사용자의 계정에 따라서 다른 권한을 가짐
- 데이터 중복의 최소화
- 동일한 데이터가 여러 개 중복되어 저장되는 것 방지
- 응용 프로그램 제작 및 수정이 쉬워짐
- 각각의 파일 포맷에 맞춰 개발하지 않아도 됨
- 통일된 방식으로 응용 프로그램 작성 가능, 유지보수 쉬움
- 데이터의 안전성 향상
- DBMS가 제공하는 백업, 복원 기능을 이용
- 데이터가 깨지는 문제 발생할 경우, 원상 복원 및 복구하는 방법 명확해짐
3) DBMS 분류
- 계층형 DBMS
- 각 계층은 트리 형태를 가지며 1:N 관계를 가짐
- 처음 구축한 이후에는 구조를 변경하기 어려움
- 주어진 상태에서 검색은 빠르지만, 접근의 유연성이 부족해서 검색이 어려움
- 망형 DBMS
- 1:1, 1:N, N:M(다대다) 관계가 지원
- 효과적이고 빠른 데이터 추출 가능
- 계층형처럼 복잡한 내부 포인터 사용하여 구조 파악하기 어려움
- 관계형 DBMS
- 데이터베이스는 테이블이라는 최소 단위로 구성
- 테이블(=릴레이션, 엔티티)은 하나 이상의 열로 구성
- 여러개의 테이블로 나누어서 저장하여 불필요한 공간의 낭비를 줄이고 데이터 저장의 효율성 보장
- 테이블의 관계를 기본 키, 외래 키를 사용하여 맺어주어 부모-자식의 관계로 묶어줌
- 장점
- 쉽게 변화에 순응할 수 있는 구조
- 유지보수가 편리함
- 대용량 데이터의 관리와 데이터 무결성 보장을 잘 해줌
- 단점
- 시스템 자원을 많이 차지하여 시스템이 느려짐
2. MySQL
1) SQL 개념
- SQL 특징
- DBMS 제작 회사와 독립적임
- 다른 시스템으로 이식성이 좋음
- 표준이 계속 발전함
- 대화식 언어
- 분산형 클라이언트/서버 구조
2) MySQL 개념
- Oracle사에서 제작한 DBMS 소프트웨어로 오픈소스로 제공됨
📕 MySQL 설치
1. MySQL 설치 전 준비사항
2. MySQL 설치
3. 샘플 데이터베이스 설치
4. 설치 후에 확인할 사항
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📕 MySQL 전체 운영 실습
1. 요구사항 분석과 시스템 설계, 모델링
1) 정보시스템 구축 절차
- 분석 ➡️ 설계 ➡️ 구현 ➡️ 테스트 ➡️ 유지보수
- 1️⃣ 분석 : 사용자의 인터뷰와 업무 조사를 수행하여 무엇을 할 것인지 결정 (요구사항 분석/시스템 분석)
- 2️⃣ 설계 : 구축하고자 하는 시스템을 어떻게 할지 결정 (시스템 설계/프로그램 설계)
- 3️⃣ 구현 : 프로그래머가 설계서대로 프로그램 작성
- 4️⃣ 테스트
- 5️⃣ 유지보수
2) 데이터베이스 모델링
- 현실세계에서 사용되는 데이터를 MySQL에 어떻게 저장할지 결정하는 과정
- 테이블 형식에 맞춰 정보 저장
📖 참고 📖 용어 정리
- 데이터
- 하나하나의 단편적인 정보
- 정보는 있으나 아직 체계화 되지 못한 상태
- 테이블
- 데이터 입력하기 위해, 표 형태로 표현하는 것
- 데이터베이스 (DB)
- 테이블이 저장되는 저장소
- 각 데이터베이스는 서로 다른 고유한 이름을 가지고 있어야 함
- DBMS (DataBase Management System)
- 데이터베이스를 관리하는 시스템 또는 소프트웨어
- 열 (=컬럼, 필드)
- 각 테이블은 열로 구성
- 열 이름
- 각 열을 구분하기 위한 이름
- 열 이름은 각 테이블 내에서는 중복되지 않고, 고유해야 함
- 데이터 형식
- 열의 데이터 형식
- 테이블을 생성할 때 열 이름과 함께 지정해야 함
- 행 (=로우, 레코드)
- 실질적인 데이터
- 기본 키
- 기본 키(주키)는 각 행을 구분하는 유일한 열
- 중복되거나 비어있으면 X
- 각 테이블에는 기본 키 하나만 지정되어 있어야 함
- 외래 키 필드
- 두 테이블의 관계를 맺어주는 키
- SQL
- 구조화된 질의 언어
2. MySQL을 이용한 데이터베이스 구축 절차
1) 데이터베이스 구축 절차
- 1️⃣ DBMS 설치
- 2️⃣ 데이터베이스 생성 ➡️ 테이블 생성 ➡️ 데이터 입력 ➡️ 데이터 조회/활용
- 3️⃣ 테이블 외의 데이터베이스 개체의 활용 ➡️ 응용 프로그램에서 구축된 데이터 활용 (웹 서비스/애플리케이션)
- 4️⃣ 데이터 백업 및 관리
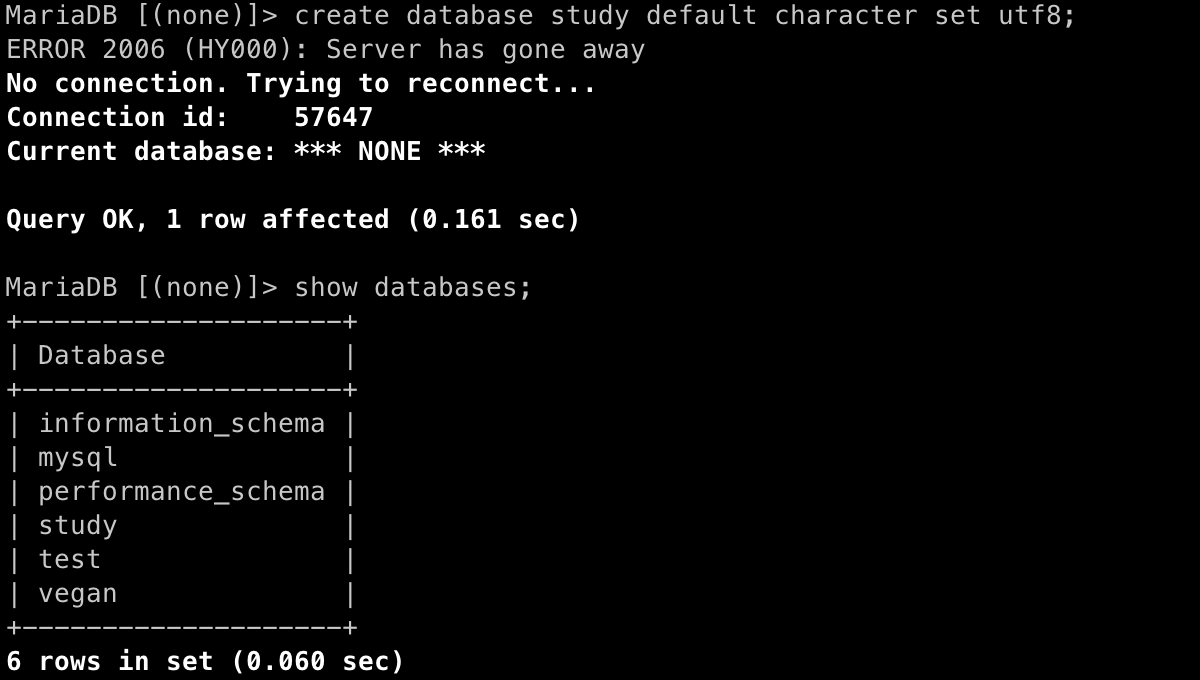
2) 데이터베이스 생성 (CREATE DATABASE)
- 📋 코드 📋
CREATE DATABASE study default CHARACTER SET UTF8;
# CREATE DATABASE study : study라는 데이터베이스 생성
# default CHARACTER SET UTF8 : 한글을 사용할 수 있는 UTF8로 문자열 저장- 📋 실행 📋
3) 데이터베이스 사용자 추가 (GRANT PRIVILEGES)
- 📋 코드 📋
GRANT ALL PRIVILEGES ON study.* TO study_user@localhost IDENTIFIED BY 'study';
EXIT;
mysql -u study_user -p
USE study;
# GRANT : 사용자에게 데이터베이스 사용 권한 적용
# ALL PRIVILEGES : 데이터베이스에 대한 모든 권한 (디비 삭제도 가능)
# ON study.* : 권한 대상은 study이며, study.*은 study의 모든 테이블을 의미
# TO study_user@localhost : study_user은 사용 권한을 받는 사용자 (없는 유저라면 새롭게 생성)
# IDENTIFIED BY 'study' : 사용자의 비밀번호를 study로 설정4) 테이블 생성 (CREATE TABLE)
- 📋 코드 📋
CREATE TABLE professor
(
_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(32) NOT NULL,
belong VARCHAR(12) DEFAULT 'FOO',
phone VARCHAR(12)
) ENGINE=INNODB;
DESCRIBE professor;
# _id : 이름의 칼럼 추가
# INT : 데이터 타입 설정
# PRIMARY KEY : 기본키로 설정 (하단에 PRIMARY_KEY(_id)로 설정 가능)
# AUTO_INCREMENT : 자동 인덱스 추가
# NOT NULL : 입력할 때 항상 값을 넣어줘야 함
# DEFAULT : 아무런 값을 입력하지 않을 때 자동으로 입력되는 값
# ENGINE=INNODB : mysql의 데이터 저장 구조를 선택
# DESC professor : 테이블 구조 확인 - 📋 실행 📋

5) 데이터 추가 (INSERT)
- 📋 코드 📋
INSERT INTO professor
(name, belong, phone)
VALUES('유재석', 'IDE','01112345678');
INSERT INTO professor
(name, belong, phone)
VALUES('황영조', 'MSE', '01121342443');
INSERT INTO professor
(name, belong, phone)
VALUES('케이멀', 'ESE', '01123424343');
INSERT INTO professor
(_id, name, belong, phone)
VALUES(256, '호날두', 'IME', '01134343222');
INSERT INTO professor
(name, belong, phone)
VALUES( '리오넬', 'IDE', '01123432432');
SELECT _id, belong, phone FROM professor;
SELECT * FROM professor;
# INSERT INTO professor : professor에 레코드 삽입
# (name, belong, phone) : professor가 가지는 컬럼 명시
# VALUES('유재석', 'IDE', '01112345678') : name, belong, phone 순서로 설정- 📋 실행 📋

6) 데이터 선택 (SELECT)
- 📋 코드 📋
SELECT * FROM student;
SELECT * FROM student ORDER BY _id;
# ORDER BY : 데이터를 특정 컬럼을 기준으로 정렬- 📋 실행 📋

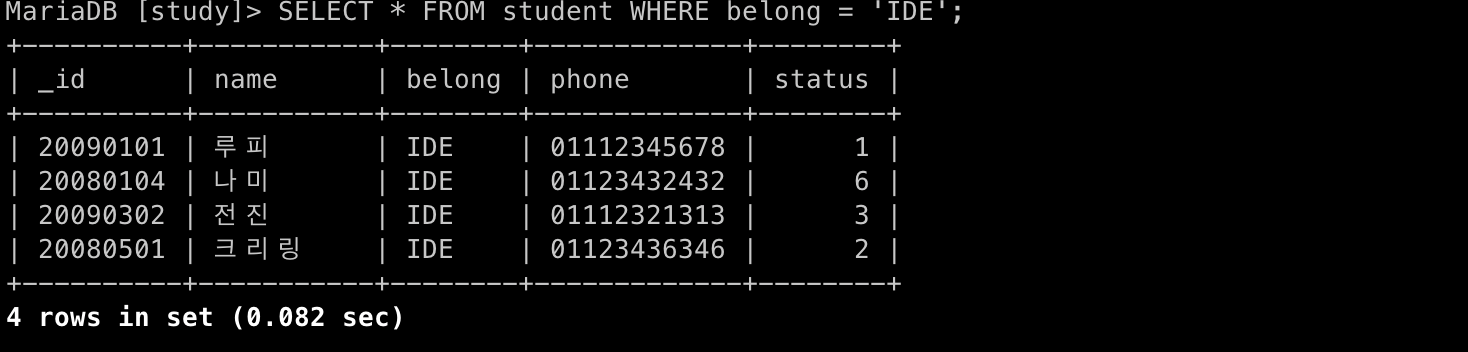
7) 데이터 조건 선택 (WHERE)
- 📋 코드 📋
SELECT * FROM student WHERE belong = 'IDE';
SELECT * FROM student WHERE _id LIKE '2009%';
SELECT * FROM student WHERE _id NOT LIKE '2009%';
SELECT * FROM student WHERE NOT belong = 'IDE';
SELECT * FROM student WHERE belong <> 'IDE';
# WHERE belong = 'IDE' : belong 조건이 IDE와 일치하는 것 찾음
# WHERE _id LIKE '2009%' : 2009로 시작하는 모든 값 찾음
# <>와 !=는 동일한 기능- 📋 실행 📋

8) 테이블 삭제 (DROP TABLE)
- 📋 코드 📋
DROP TABLE study;3. 테이블 외의 데이터베이스 개체의 활용
1) 인덱스
- 개념
- 책의 찾아보기(색인) 같은 기능
- 테이블의 열 단위에 생성
- 열을 기본 키로 설정하면 자동으로 인덱스가 설정됨
- Non-Unique Key Lookup
- 📋 코드 📋
CREATE INDEX name_idx ON student(name); # 인덱스 생성
CREATE TABLE student (
name VARCHAR(20) NOT NULL,
INDEX name_idx(name)
); # 테이블 생성시 인덱스 생성
SHOW INDEX FROM INDEX; # 인덱스 조회
ALTER TABLE student DROP INDEX name_idx; # 인덱스 삭제 - 📋 실행 📋

2) 뷰
- 개념
- 진짜 테이블에 링크된 가상의 테이블
- 사용자 입장에서는 테이블과 동일하게 보이지만, 실제 행 데이터를 가지고 있지 않음
- 특정 사용자에게 테이블 전체가 아닌 필요한 필드만 보여줄 수 있음
- 한번 정의된 뷰는 변경이 불가능함
- 📋 코드 📋
CREATE VIEW view_student AS SELECT name, phone FROM student; # 뷰 생성
SELECT * FROM student; # 뷰 조회
DROP VIEW view_student; # 뷰 삭제- 📋 실행 📋

3) 스토어드 프로시저
-
개념
- MySQL에서 제공해주는 프로그래밍 기능
- SQL문을 하나로 묶어서 편리하게 사용하는 기능
- 여러 SQL문을 하나씩 수행하기 보다 스토어드 프로시저로 만들어 놓은 후에 호출하는 방식 사용
-
함수와 차이점
- 함수 (function) : 클라이언트에서 처리, 리턴값 필수, 리턴값 하나만 반환 가능
- 프로시저 (precedure) : 서버로 보내서 처리, 리턴값 선택, 리턴값 여러개 반환 가능
-
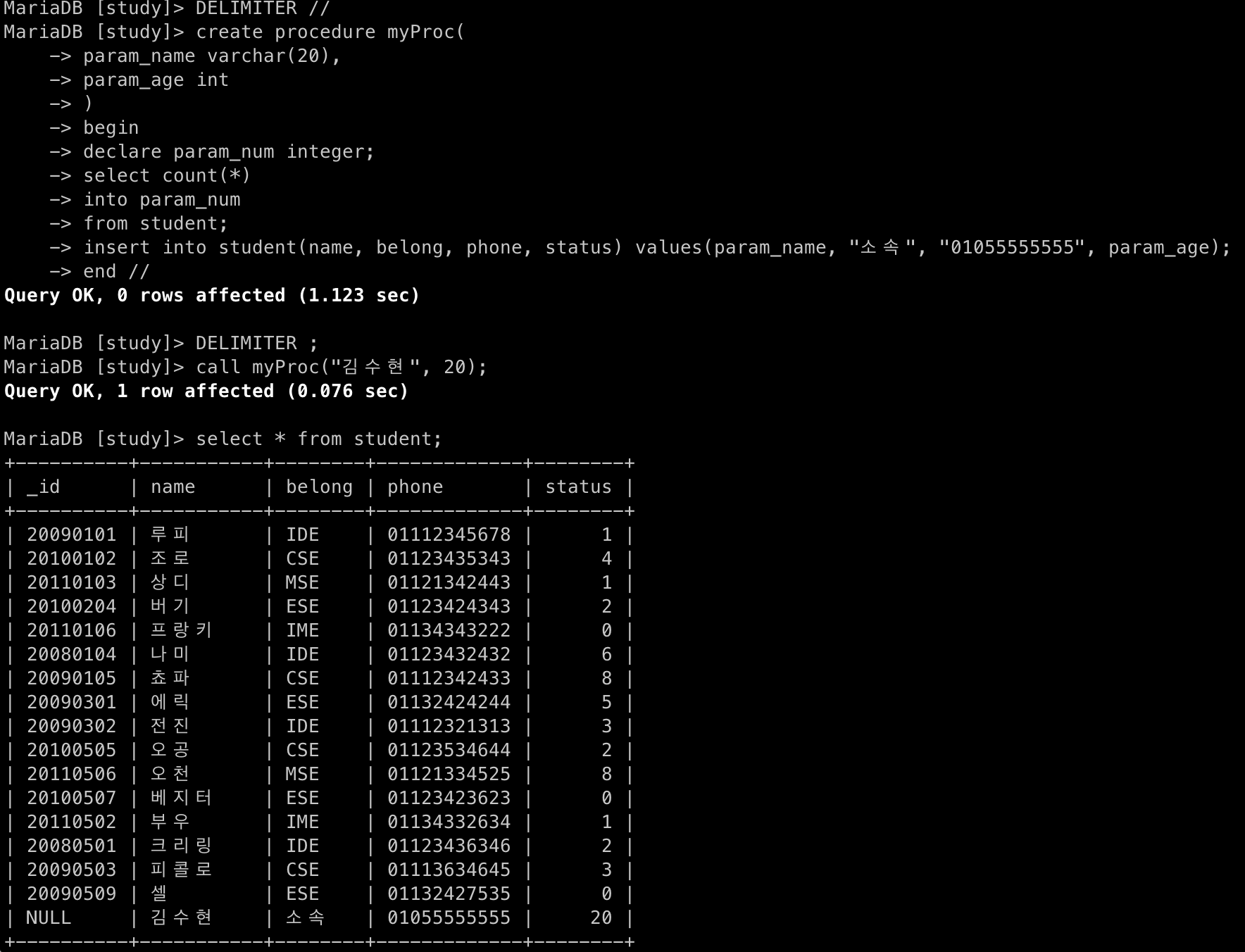
📋 코드 📋
DELIMITER //
CREATE PROCEDURE myProc(
param_name VARCHAR(20),
param_age INT
)
BEGIN
# 변수 선언
DECLARE param_num INTEGER;
SELECT COUNT(*) INTO param_num FROM student;
INSERT INTO student(name, belong, phone, status) VALUES(param_name, "소속", "01055555555", param_age);
END //
DELIMITER ;
# 프로시저 실행
CALL myProc("김수현", 20);
# DELIMITER : 구분자를 의미 (기존 세미콜론 대신하고, 원래대로 돌려놓기)
# -> CREATE PROCEDURE~END를 하나의 단락으로 묶어주는 효과 (프로시저 작성이 완료되지 않았음에도 실행되는 것 방지)- 📋 실행 📋
4) 트리거
- 개념
- 테이블에 부착되어서 INSERT/UPDATE/DELETE 작업이 발생되면 실행되는 코드
- 테이블에 대한 이벤트에 반응해 자동으로 실해오디는 작업
- 📋 코드 📋
# 삭제 데이터 보관할 테이블 생성
CREATE TABLE deleteTBL (
memberId CHAR(8),
memberName CHAR(5),
memberPhone CHAR(20),
deleteDate DATE
);
# 트리거 생성
DELIMITER //
CREATE TRIGGER trg_delete
AFTER DELETE
ON student
FOR EACH ROW
BEGIN
-- OLD 테이블의 내용을 백업 테이블에 삽입
INSERT INTO deleteTBL VALUES(OLD._id, OLD.name, OLD.phone, CURDATE());
END //
DELIMITER ;
# AFTER DELETE : 삭제 후에 작동하게 지정
# ON student : 트리거 부착할 테이블
# FOR EACH ROW : 각 행마다 적용시킴- 📋 실행 📋


📖 참고 📖
- 데이터베이스 튜닝
- 데이터베이스 성능을 향상시키거나 응답하는 시간을 단축시키는 것
- 쿼리에 대한 응답을 줄이기 위해서 가장 집중적으로 봄
- 전체 테이블 검색
- 인덱스가 없을 경우 처음부터 끝까지 테이블 전체 검색
- Full Table Scan
4. 데이터베이스 백업 및 관리
1) 백업
현재의 데이터베이스를 다른 매체에 보관하는 작업
2) 복원
데이터베이스에 문제가 발생했을 때 다른 매체에 백업된 데이터를 이용해서 원상태로 돌려놓는 작업
📒 MySQL 기본
📕 데이터베이스 모델링
1. 소프트웨어 개발 모델
1) 폭포수 모델
- 과정
- 1️⃣ : 프로젝트 계획
- 2️⃣ : 업무 분석
- 3️⃣ : 시스템 설계
- 4️⃣ : 프로그램 구현
- 5️⃣ : 테스트
- 6️⃣ : 유지보수
- 장점
- 각 단계가 명확히 구분되어서 프로젝트의 진행 단계가 명확해짐
- 단점
- 문제가 발생했을 경우에도 앞 단계로 거슬러 올라가기 어려움
2. 데이터베이스 모델링
- 개념
- 현 세계에서 사용되는 작업을 DBMS의 데이터베이스 개체로 옮기기 위한 과정
- 현실에서 쓰이는 것을 테이블로 변경하기 위한 과정
- 종류
- 개념적 모델링 (업무 분석 단계)
- 논리적 모델링 (업무 분석 후반 ~ 시스템 설계 전반)
- 물리적 모델링 (시스템 설계 후반)
- 🗒️ 예시
- 공간 낭비되는 L자형 테이블 분리
- 테이블의 중복되는 정보 제거
- 각 행을 구분하는 유일한 값으로 기본키 설정
- 두 테이블의 업무적인 연관성으로 관계 설정
- 관계가 맺어지면, 제약 조건 관계가 자동 설정됨
📕 MySQL 유틸리티 사용법
1. MySQL Workbench
- 기능
- 데이터베이스 연결 기능
- 인스턴스 관리
- 위저드를 이용한 MySQL의 동작
- 통합된 기능의 SQL 편집기
- 데이터베이스 모델링 기능
- 포워드/리버스 엔지니어링 기능
- 데이터베이스 인스턴스 시작/종료
- 데이터베이스 내보내기/가져오기
- 데이터베이스 계정 관리
2. 외부 MySQL 서버 관리
- 기존 Windows 설치 구조
- MySQL 서버 ➡️ MySQL Workbench(클라이언트) ➡️ 방화벽(3306) ➡️ IP 주소 ➡️ 외부 네트워크
- 변경된 Linux/Windows 설치 구조
- MySQL 서버 ➡️ 방화벽(3306) ➡️ IP 주소 ➡️ 외부 네트워크 ➡️ IP 주소 ➡️ MySQL Workbench(클라이언트)
3. 사용자 관리
- 다양한 사용자에게 역할에 맞는 다양한 권한 부여
- 역할 : 권한의 집합
📕 SQL 기본
1. SQL 분류
1) DML (Data Manipulation Language)
- 데이터 조작 (선택, 삽입, 수정, 삭제)
- 테이블의 행 사용
- DML을 사용하기 위해서는 그 전에 테이블 정의 필요
- 트랜잭션 발생하는 SQL
- 종류
- SELECT
- INSERT
- UPDATE
- DELETE
2) DDL (Data Definition Language)
- 데이터베이스, 테이블, 뷰, 인덱스 등 데이터베이스 개체를 생성/삭제/변경하는 역할
- 트랜잭션을 발생하지 않음
- 되돌림(ROLLBACK), 완전 적용(COMMIT) 시킬 수 없음
- 실행 즉시 MySQL에 적용됨
- 종류
- CREATE
- DROP
- ALTER
3) DCL (Data Control Language)
- 사용자에게 어떤 권한을 부여하거나 빼앗을 때 사용
- 종류
- GRANT
- REVOKE
- DENY
2. CREATE문
- 📋 코드 📋
-- 회원 테이블 생성
CREATE TABLE usertbl (
userID char(8) not null primary key, -- 사용자 아이디(PK)
name varchar(10) not null, -- 이름
birthYear int not null, -- 출생년도
addr char(2) not null, -- 지역경기, 서울, 경남 식으로 2글자만 입력
mobile1 char(3), -- 휴대폰의 국번 (011, 016, 017, 018, 019, 010 등)
mobile2 char(8), -- 휴대폰의 나머지 전화번호 (하이픈 제외)
height smallint, -- 키
mDate date -- 회원 가입일
);
-- 회원 구매 테이블 생성
CREATE TABLE buytbl (
num int auto_increment not null primary key,
userID char(8) not null,
prodName char(8) not null,
groupName char(4),
price int not null,
amount smallint not null,
FOREIGN KEY(userID) REFERENCES usertbl(userID)
);- 📋 실행 📋

3. SELECT문
- 데이터베이스 내의 테이블에서 원하는 정보를 추출
1) SELECT 구문 형식
SELECT select_expr
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}]2) SELECT 구문 상세
SELECT
[ALL | DISTINCT | DISTINCTROW]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT][SQL_BIG_RESULT][SQL_BUFFER_RESULT]
[SQL_NO_CACHE][SQL_CALC_FOUND_ROWS]
select_expr [, select expr ...]
[FROM table_references]
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec) ...]
[ORDER BY {col_name | expr | position} [ASC|DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[INTO OUTFILE 'file_name'
| CHARACTER SET charset_name] export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR {UPDATE | SHARE} [OF tbl_name [, tbl_name] ...] [NOWAIT|SKIP LOCKED] | LOCK IN SHARE MODE]]3) WHERE절
- 기본적인 WHERE절
SELECT 필드 이름 FROM 테이블 이름 WHERE 조건식;- 연산자의 사용
- 조건 연산자 (=, <, <=, >, >=, != 등)
- 관계 연산자 (AND, OR, NOT)
SELECT userID, Name FROM usertbl WHERE birthYear >= 1970 AND height >= 182;- BETWEEN, IN(), LIKE
- BETWEEN : 연속적인 값 검색
- IN : 이산적인 값 검색
- LIKE : 문자열 내용 검색 (% 무엇이든 허용, _ 한글자 매치)
-- BETWEEN ... AND
SELECT name, height FROM usertbl WHERE height BETWEEN 180 AND 183;
-- IN()
SELECT name, addr FROM usertbl WHERE addr IN ('경남', '전남', '경북');
-- LIKE
SELECT name, height FROM uertbl WHERE name LIKE '김%';- ANY/ALL/SOME, 서브쿼리
- ANY : 서브쿼리의 여러 개의 결과 중 한가지만 만족해도 됨
- =ANY는 IN과 동일
- ALL
- SOME : ANY와 동일
- ANY : 서브쿼리의 여러 개의 결과 중 한가지만 만족해도 됨
SELECT name, height
FROM usertbl
WHERE height > (SELECT height FROM usertbl WHERE name = '김경호');
-- 하위 쿼리가 2 이상의 값을 반환하여 오류 발생
select name, height
from usertbl
where height >= (
select height
from usertbl
where addr='경남'
);
-- ANY (하위 조건 - 키가 170보다 크거나 같은 사람)
select name, height
from usertbl
where height >= ANY (
select height
from usertbl
where addr='경남'
);
-- ALL (상위 조건 - 키가 173보다 크거나 같은 사람)
select name, height
from usertbl
where height >= ALL (
select height
from usertbl
where addr='경남'
);
4) ORDER BY
- 원하는 순서대로 정렬하여 출력
- 기본적으로 오름차순(ASC) 출력, 내림차순(DESC) 정렬시 뒤에 작성
SELECT name, mDate FROM usertbl ORDER BY mDate DESC;5) DISTINCT
- 중복된 것을 하나만 남김
SELECT DISTINCT addr FROM usertbl;6) LIMIT
- 출력 개수 제한
SELECT emp_no, hire_date FROM employees
ORDER BY hire_date ASC
LIMIT 5;7) GROUP BY절
- 형식
SELECT 컬럼명
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name|expr|position}]
[HAVING where_condition]
[ORDER BY {col_name|expr|position}]- 집계 함수
- AVG() : 평균
- MIN() : 최소값
- MAX() : 최대값
- COUNT() : 행의 개수 (중복 제외 COUNT(DISTINCT))
- STDEV() : 표준편차
- VAR_SAMP() : 분산
8) HAVING절
- 집계 함수는 WHERE절에 사용할 수 없음
- WHERE절 처럼 조건을 제한하고, GROUP BY절 다음에 사용
- 📋 코드 📋
SELECT userID AS '사용자', SUM(price * amount) AS '총구매액'
FROM buytbl
GROUP BY userID
HAVING SUM(price*amount) > 1000;- 📋 실행 📋

9) ROLLUP
- 분류별로 합계 및 총합 구하기
- GROUP BY절과 함께 사용
- 📋 코드 📋
SELECT num, groupName, SUM(price * amount) AS '비용'
FROM buytbl
GROUP BY groupName, num
WITH ROLLUP;- 📋 실행 📋

4. INSERT문
- INSERT 구문 형식
- 테이블명 다음에 나오는 열은 생략 가능 (단, 테이블에 정의된 열 순서 및 개수 동일해야 함)
- 입력할 열의 목록 나열
- 입력하지 않으면 NULL 삽입
INSERT [INTO] 테이블[(열1, 열2, ...)] VALUES(값1, 값2, ...)- IGNORE
- 입력시 데이터가 중복되어 입력되지 않는 오류 무시하고 넘어감
INSERT IGNORE INTO memberTBL VALUES ('BBK', '비비코', '미국');- ON DUPLICATE KEY UPDATE
- PK가 중복되지 않으면 INSERT
- PK가 중복되면 UPDATE문 수행
INSERT INTO memberTBL VALUES ('BBK', '비비코', '미국')
ON DUPLICATE KEY UPDATE name='비비코', addr='미국';- AUTO_INCREMENT
- 자동으로 1부터 증가하는 값 입력 (데이터 형은 숫자 형식만 사용 가능)
- 지정시 PRIMARY KEY 또는 UNIQUE 지정 필요
- INSERT에서 해당 열 입력하지X, NULL값 지정하면 자동으로 값 입력됨
CREATE TABLE testTBL2 (
id int AUTO_INCREMENT PRIMARY KEY,
userName char(3),
age int);
INSERT INTO testTBL2 VALUES (NULL, '지민', 22);
-- 마지막에 입력된 값 확인
SELECT LAST_INSERT_ID();
-- AUTO_INCREMENT 입력값 변경
ALTER TABLE testTBL2 AUTO_INCREMENT=100;
-- AUTO_INCREMENT 증가값 변경 (서버 변수 변경)
SET @@auto_increment_increment=3;- 대량의 샘플 데이터 생성
INSERT INTO 테이블 이름(열 이름1, 열 이름2, ...)
SELECT문;
-- employees 데이터 복사
CREATE TABLE testTBL4 (id int, Fname varchar(50), Lname varchar(50));
INSERT INTO testTBL4
SELECT emp_no, first_name, last_name
FROM employees.employees;5. UPDATE문
- UPDATE 구문 형식
- WHERE절 생략시 테이블의 전체 행 변경됨
UPDATE 테이블 이름
SET 열1 = 값1, 열2 = 값2, ...
WHERE 조건;6. DELETE문
- DELETE 구문 형식
- WHERE절이 생략되면 전체 데이터 삭제
DELETE FROM 테이블 이름 WHERE 조건;- 테이블 삭제
- DELETE
- 트랜잭션 로그를 기록하는 작업으로 삭제 오래 걸림
- DROP
- 테이블 자체 삭제 (구조도 삭제)
- 트랜잭션 발생X
- TRUNCATE
- DELETE와 기능 동일하지만, 트랜잭션 로그를 기록하지 않아 속도 빠름
- 테이블 구조는 남겨놓고 싶을 경우
- DELETE
DELETE FROM 테이블명;
DROP TABLE 테이블명;
TRUNCATE TABLE 테이블명;7. WITH절과 CTE
1) WITH절
- CTE(Common Table Extension)를 표현하기 위한 구문
- CTE
- 기존의 뷰, 파생 테이블, 임시 테이블 등으로 사용되던 것을 대신함
- 비재귀적/재귀적 CTE로 분류
2) 비재귀적 CTE
- 복잡한 쿼리 문장을 단순화 시키는데 적합함
📖 참고 📖
- USE
- 사용할 데이터베이스 지정
USE 데이터베이스_이름;
- SHOW
- 현재 서버에 존재하는 데이터베이스/테이블 정보 조회
SHOW DATABASES; SHOW TABLE;
- DESCRIBE (DESC)
- 테이블 정보 확인
DESCRIBE 테이블명; DESC 테이블명;
- 테이블 복사
- PK, FK 등 제약조건은 복사되지 않음
CREATE TABLE buytbl2 (SELECT * FROM buytbl);
- 트랜잭션
- 테이블의 데이터를 변경(입력/수정/삭제) 할 때 실제 테이블에 완전히 적용X
- 임시로 적용시키는 것
- 실수가 발생할 경우 취소 가능
📕 SQL 고급
1. MySQL의 데이터 형식
2. 조인
3. SQL 프로그래밍
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📒 MySQL 고급
📕 테이블과 뷰
1. 테이블
2. 뷰
3. 테이블스페이스
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📕 인덱스
1. 인덱스의 개념
2. 인덱스의 종류와 자동 생성
3. 인덱스의 내부 작동
4. 인덱스 생성/변경/삭제
5. 인덱스의 성능 비교
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📕 스토어드 프로그램
1. 스토어드 프로시저
2. 스토어드 함수
3. 커서
4. 트리거
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📕 전체 텍스트 검색과 파티션
1. 전체 텍스트 검색
2. 파티션
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📒 MySQL 응용 프로그래밍 및 공간 데이터
📕 PHP 기본 프로그래밍
1. 웹 사이트 개발 환경 구축
2. 스크립트 언어 개요와 HTML 문법
3. PHP 기본 문법
4. HTML과 PHP 관계
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📕 PHP와 MySQL의 연동
1. PHP와 MySQL의 기본 연동
2. 회원 관리 시스템
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📕 MySQL과 공간 데이터
1. 지리정보시스템의 개념
2. MySQL에서 공간 데이터의 저장
3. MySQL에서 진행하는 GIS 응용 프로젝트
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋
📕 파이썬과 MySQL 응용 프로그래밍
1. 파이썬 개발 환경 구축
2. 파이썬 문법
3. 파이썬과 MySQL 연동
4. 공간 데이터 조회 응용 프로그램
📖 참고 📖
- 🗒️ 예시
1️⃣2️⃣3️⃣4️⃣5️⃣6️⃣7️⃣
⬆️⬇️➡️
- 📋 코드 📋
- 📋 실행 📋

Notion으로 이동 (https://24tngus.notion.site/3a6883f0f47041fe8045ef330a147da3?v=973a0b5ec78a4462bac8010e3b4cd5c0&pvs=4)