Sequential Model
이번 강에서는 Sequential Model 중 Transformer에 대하여 학습을 진행했다. Transformer는 예전부터 정말 제대로 이해하고 싶었던 구조라 이번 기회를 통해서 제대로 이해하기 위해 많은 노력을 했다.
00. 학습 내용
- Transformer에 대하여 학습
01. Transformer
- 우선 Transformer를 다루기 전에, 왜 attention 메커니즘이 중요한지에 대하여 알아볼 것이다.
- 보통 seq2seq 모델은 input을 encoder를 이용해 context vector를 생성하고 생성된 context 벡터를 decoder에 보내서 각각 출력할 아이템이 하나씩 선택되는 방식으로 학습이 이루어진다.
- 그런데 연구를 통해 이러한 하나의 고정된 context 벡터가 긴 문장들을 처리하기는 어렵다는 것을 알아냈다.
- 그래서 모델이 디코딩 과정에서 가장 관련된 입력 파트에 집중할 수 있도록 도와주는 방법이 바로 Attention 메커니즘이고, Trainsformer는 이러한 Attention 메커니즘만을 활용하여 만든 모델이다.
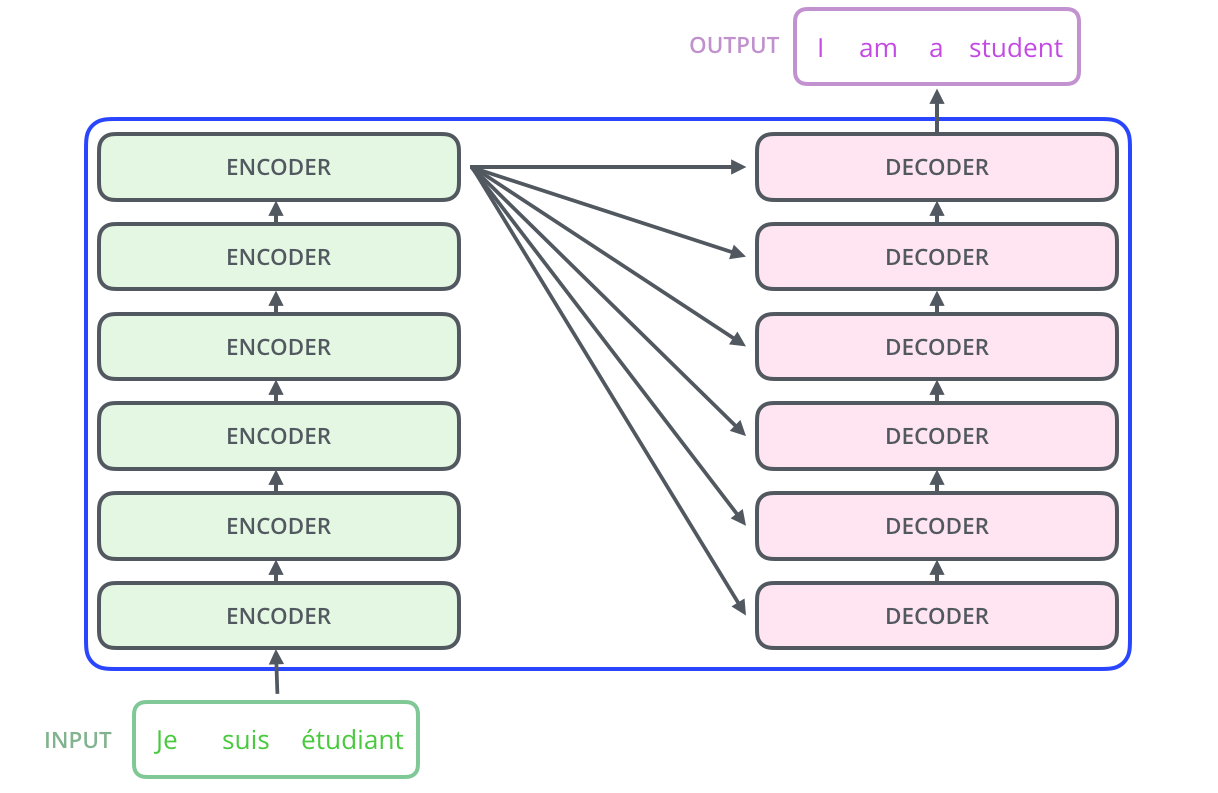
- Transformer는 위처럼 input data를 인코딩 해주는 Encoder를 쌓아서 만든 Encoders와 인코딩된 데이터를 디코딩 해주는 Decoder를 쌓아서 만든 Decoders로 이루어진다.(물론 Decoders에도 현재 데이터 이전의 번역된 문장이 input으로 들어감, SOS-단어들-EOS)
- input data로는 당연히 단어에 대한 Embedding 벡터가 들어가고, 이 Embedding 벡터는 Word2Vec 등을 이용해 생성할 수 있을 것이다. 또한 제일 밑단의 인코더를 제외하고는 각각 인코더의 인풋으로 이전 인코더의 아웃풋 벡터가 들어갈 것이다.
- 따라서 Transformer 모델을 만들기 전에 가장 먼저 해야할 것은 단어들의 Embedding 벡터를 만드는 것이다.
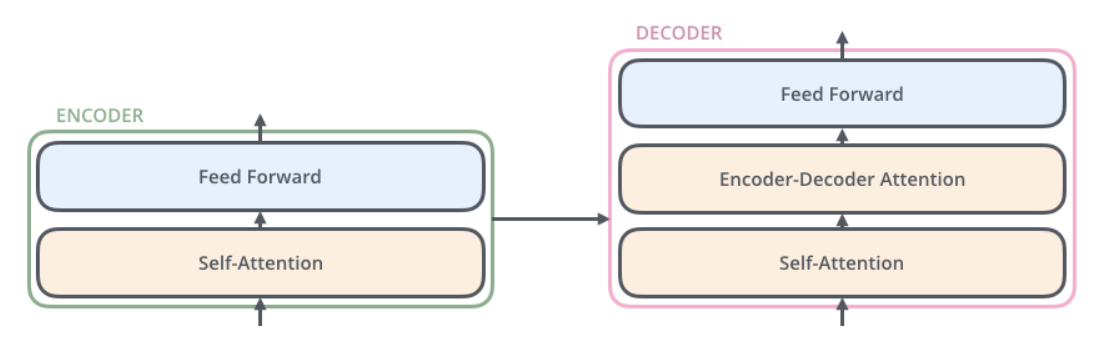
- Transformer의 Encoder는 Self-Attention Layer, feed-forward Layer로 이루어져 있다.
- Transformer의 Decoder는 Self-Attention Layer, Encoder-Decoder Attention Layer, feed-forward Layer로 이루어져 있다.
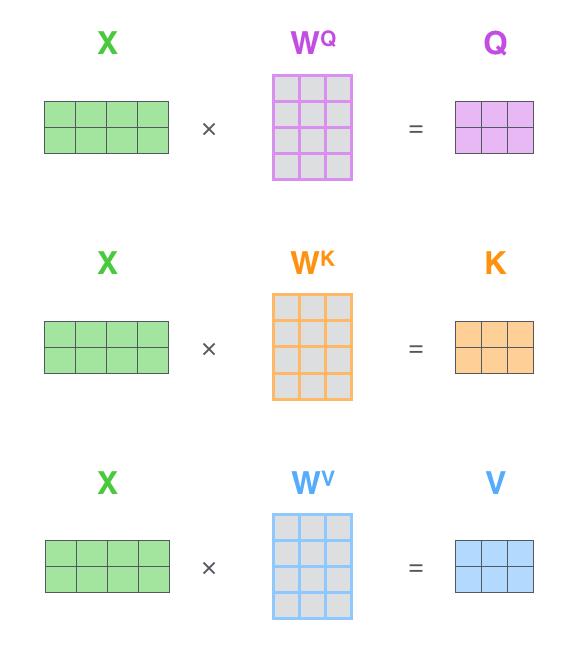
- 어떠한 하나의 문장을 읽을 때 사람은 하나의 단어가 어느 단어에 영향을 받는지를 바로 이해할 수 있다. 그러나 모델은 사람처럼 할 수 없다. 따라서 사람 처럼 문장을 이해하기 위해서 Transformer는 Self-Attention Layer를 사용한다.
- 우선 첫번째로 위 그림처럼 각각의 Linear Layer인 , , 에 각 단어의 임베딩을 넣어서 각 단어에 맞는 Query, Key, Value 값을 생성한다. (각 행렬의 사이즈는 대게 임베딩 보다 더 작게 설정함)
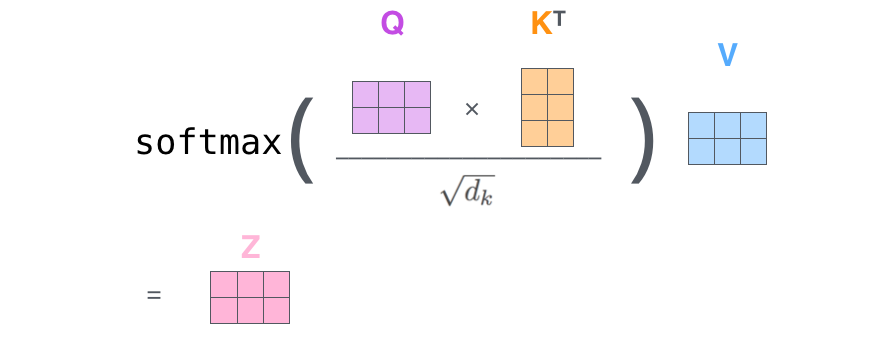
- 두번째는 Query, Key의 행렬 곱을 통해서 Score 값을 얻는 것이다. Score 값은 현재 위치의 단어를 인코딩 할 때 다른 다언들에 대해서 얼마나 집중을 해야 할지를 결정해주는 역할을 한다.
- 세번째는 Score 값을 Key 사이즈 값의 제곱근으로 나누어주는 것이다. 값의 정규화를 통해서 조금더 안정적이 gradient를 얻기 위한 과정이다.
- 네번째는 세번째에서 구해진 값을 softmax 함수에 넣는 것이다. softmax 함수를 통해서 나온 점수는 현재 위치의 단어를 인코딩에 하는데 있어서 각 단어들의 표현을 얼마나 사용할지를 결정해준다. 당연히 현재 위치의 단어가 가장 높은 값을 가지겠지만, 가끔은 다른 단어에 대한 정보가 들어가는 것이 인코딩에 도움이 될 수 있다.
- 다섯번째는 네번째에 얻어진 값과 Value 값을 곱하는 것이다. 이 식의 의미는 softmax 함수를 통해서 얻어진 값에는 분명 0에 수렴하는 값이 존재하기 때문에, 이 식을 통해서 우리는 집중하고 싶은 단어만을 남길 수 있다.
- 이제 이 결과로 나온 값을 우리는 feed-forward 신경망으로 보내게 된다.
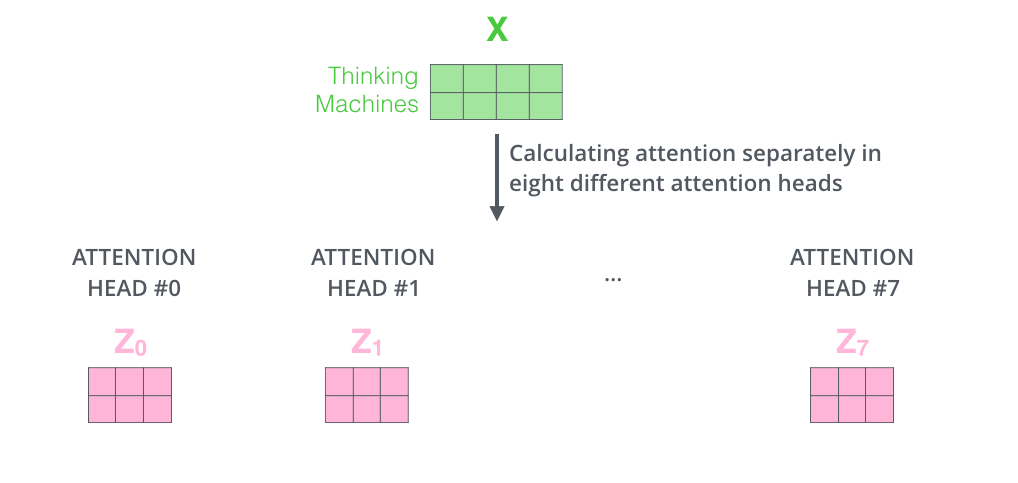
- 그런데 Transformer는 위의 Self-Attention Layer에 위 그림과 같이 여러 개의 Self-Attention Layer를 가지는 “multi-headed” attention이라는 메커니즘을 사용한다.
- 본 메커니즘 덕분에 Transformer는 모델이 다른 위치에 집중하는 능력을 확장시켰고, 또한 Attention Layer가 여러개 존재한다는 것은 여러 개의 Query/Key/Value weight가 존재하는 것이고 이는 모델이 여러 개의 representation 공간을 가지게 해줘 표현력이 더 좋아졌다고 할 수 있다.
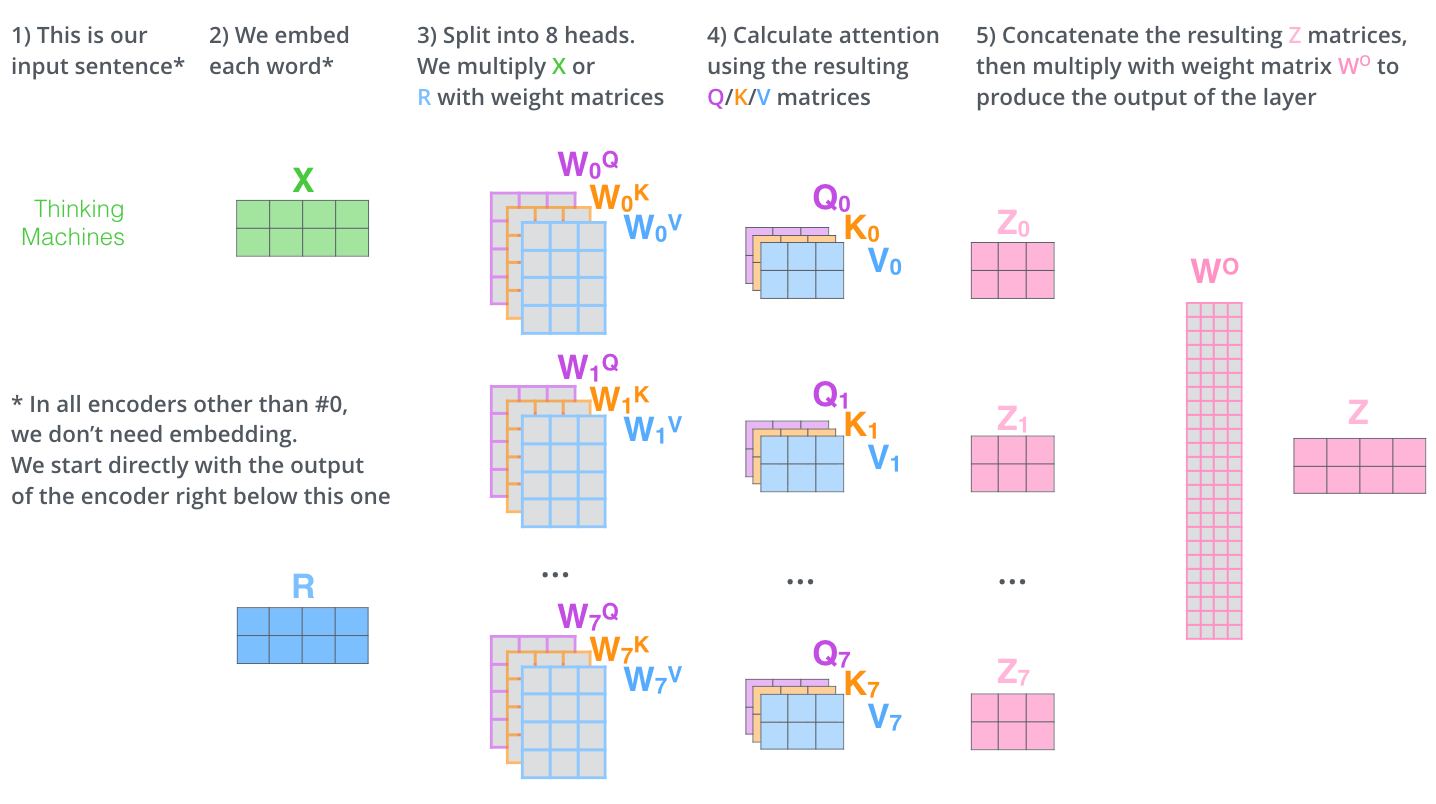
- 위 그림 처럼 multi-headed attention Layer를 거쳐서 나온 값 z를 일렬로 붙여서 최종적으로 feed-forward 신경망을 거쳐 우리가 원하는 크기의 인코딩 값을 얻게 된다.
- 이러한 연산을 하는 Encoder를 여러개 쌓게 되면 Transformer의 Encoders가 된다.
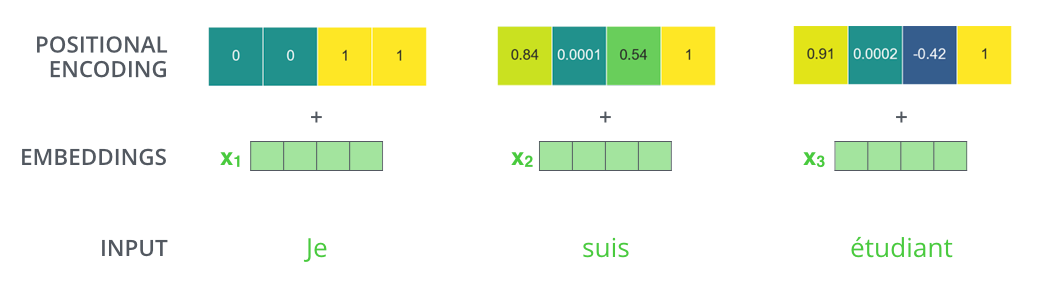
- 그런데 현재까지 Transformer의 아쉬운 점은 입력 문장에 대한 순서 정보를 고려하지 못한다는 것이다.
- 입력 문장에 대한 순서 정보를 고려하기 위해서 Transformer는 Positional Encoding을 사용한다.
- sin과 cos함수로 생성한 Positional Encoding 값을 인풋 임베딩에 더해줌으로써 Transformer는 입력 문장에 대한 순서 정보를 고려할 수 있게 된다. 또한 Positional Encoding은 입력 문장의 길이에 대한 scalability가 커진다는 장점도 가져다준다.
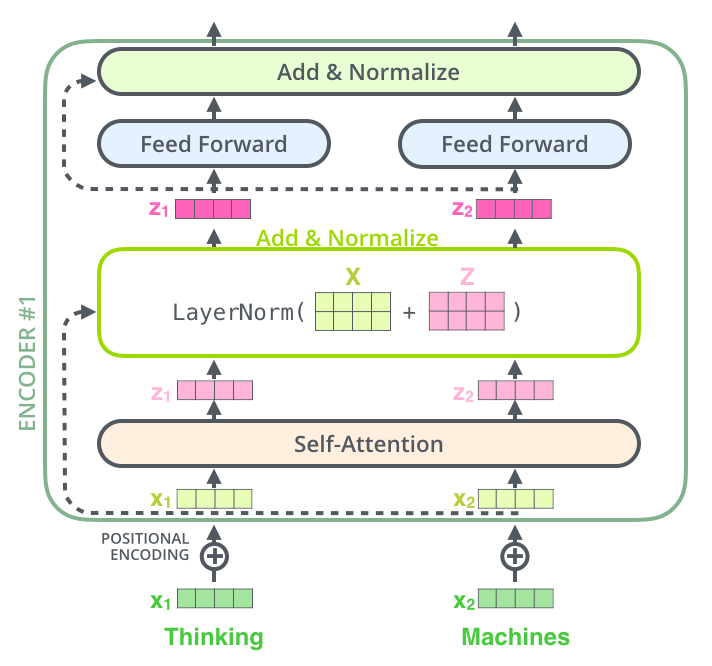
- 추가로 Encoder는 feed-forward 신경망을 거치기 전에 인풋과 Z 값을 서로 더하는 residual connection과 layer-normalization 을 거친다. (정규화와 모델을 조금더 깊게 쌓기 위해서)
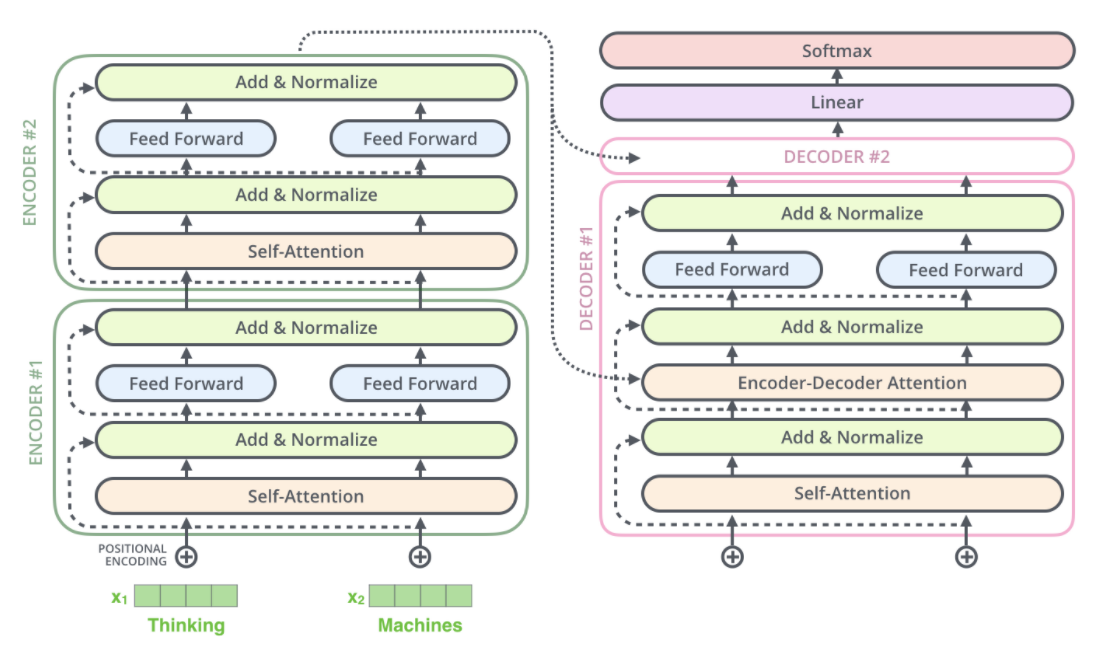
- 그렇다면 최종적으로 만들어진 Transformer의 Encoders의 구조는 그림의 왼쪽과 같을 것이다.
- 이제 Transformer의 Decoder와 마지막 Liner Layer와 Softmax Layer를 설명하도록 하겠다.
- Decoder가 Encoder와 조금 다른 점은 encoder-decoder attention layer와 self-attention layer에서 현재 위치의 미래 위치에 대한 정보는 Mask 처리하여 학습을 한다는 것이다.
- encoder-decoder attention layer는 self-attention layer와 동일한 연산이 일어나지만, Query 행렬은 이전 디코더의 아웃풋 값을 사용하고 Key와 Value 행렬들은 인코더의 출력값을 사용한다. 이 layer 덕분에 모델은 입력 시퀀스에 대하여 적절한 위치에 집중할 수 있도록 도와준다.
- self-attention layer에서 현재 위치의 미래 위치에 대한 정보는 Mask 처리는 대게 미래 위치에 대한 값을 -INF 값으로 치환하여 0으로 만들게 된다.(왜? 소프트맥스 함수를 거치니깐)
- 마지막 Liner Layer와 Softmax Layer는 단순하게 설명하면 그냥 해당하는 단어를 맞추는 Multi label classification을 해준다. 그런데 본 모델의 경우에는 아웃풋으로 EOS 토큰을 만나면 예측을 멈추게 된다.
- 그런데 이제 Transformer의 경우 각 스텝마다 번역할 단어가 나오게 될텐데, 이제 이 단어를 선택하는 방법에 따라서 크게 greedy decoding과 beam search로 나뉘어 지게 된다.
- greedy decoding은 그냥 단순하게 각 스텝마다 가장 확률 값이 높은 단어를 선택하는 것이다.
- beam search는 각 스텝마다 고려하는 단어의 수와 미래 출력 개수를 결정하여, 현재 스텝을 기준으로 여러 단어를 결정하여 가장 로스 값이 낮은 단어를 선택하는 방식이다.
참고자료

Machine Learning Engineer at Konan Technology