Level2 P-Stage DKT 대회 회고
이번에도 4주 간의 DKT 대회가 끝나서 대회 정리와 회고를 위해 글을 작성하려고 한다.
1. 프로젝트 소개
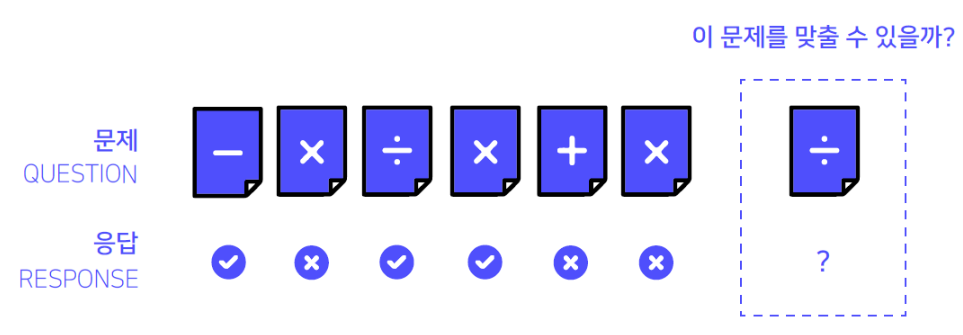
이번 대회는 위 그림과 같이 유저의 문제 풀이 Sequence를 이용하여 유저가 마지막에 푼 문제를 틀릴지 맞출지를 예측하는 것이었다.
주어진 데이터는 위 그림과 같이 유저의 문제 풀이 Sequence가 시간 순서로 주어졌고, 주어진 유저는 총 7,442명이며, 유저 마다 푼 문항의 수는 최소 9 ~ 1,860 문항이었다. 그리고 하나의 문항에 대해서 해당 문항이 속한 시험지, 지식 태그, 문제를 푼 시간, 정답 여부 등의 정보가 주어졌다.
따라서 이번 대회의 목표는 해당 유저의 문제 풀이 Sequence를 이용해 지식 상태를 잘 표현할 수 있는 모델 Model Architecture를 설계하는 것이라고 할 수 있었다.
2. 프로젝트 수행 절차
이번 대회에서 나는 철저히 모델 중심적인 사고를 가지고 프로젝트를 진행해 나갔다.
- 모델을 활용한 데이터의 패턴 분석
- 전체 데이터의 수가 200만개 이상이기 때문에, 단순한 EDA를 통해서는 데이터의 패턴을 효과적으로 파악할 수 없다고 생각하여, 모델의 특성에 기반하여 데이터의 패턴을 분석했다.
- GMF
- 유저 임베딩을 사용하면 모델이 과적합이 발생한다는 것을 확인
- 문항에 대한 변수를 추가할 수록 모델의 성능이 향상된다는 것을 확인
- 즉, 유저보다는 최대한 문항 정보를 활용하는 것이 더 중요함
- LightGCN
- 유저-문항을 그래프 형태로 표현하여, 유저-유저 연관성을 기반으로 데이터를 표현할 시에 성능이 좋지 않다는 것을 확인
- 즉, 유저-유저의 연관성을 바탕으로 본 데이터를 표현하는 것은 매우 어려움
- Item2Vec
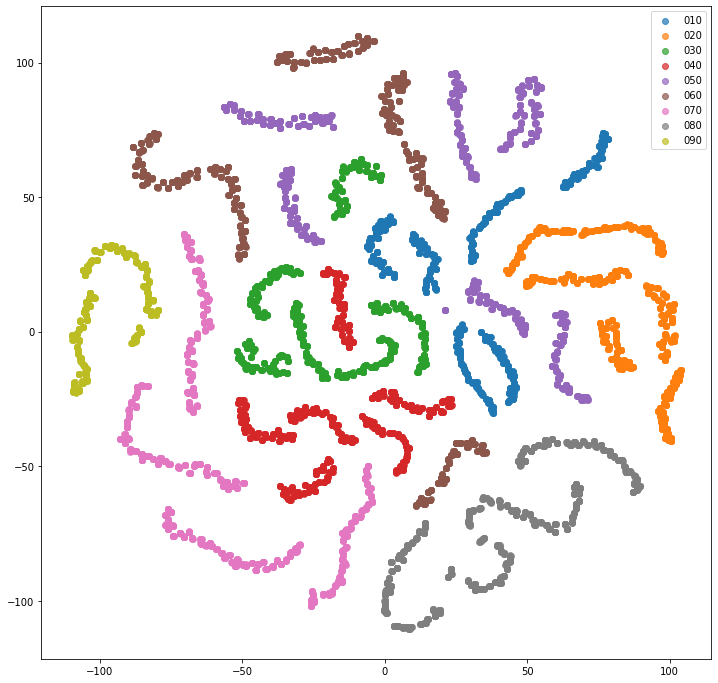
- 유저의 문제 풀이 내역을 기반으로 문항을 임베딩 했을 때 특정 군집을 이룸
- 즉, 유저의 문제 풀이 내역에는 특정한 패턴이 존재한다는 것을 알 수 있음
- BERT(0.78) vs Transformer(0.83)
- 문제 풀이 내역을 양방향으로 학습하는 BERT보다 단반향으로 학습을 하는 Transformer의 성능이 더 좋음
- Trasformer을 가지고 단순히 문항 만을 이용하여 다음에 등장할 문항을 예측 하더라도 높은 ACC를 보임
- 즉, 유저의 문제 풀이 순서는 매우 중요한 패턴이 내재되어 있다는 것을 알 수 있음
- 본 분석을 통해서, 유저를 임베딩 하는 것보다 최대한 문항 정보를 활용하여 parameterized function을 만드는 것이 중요하다는 것, 시간적 순서를 효과적으로 표현할 수 있는 Model Architecture 설계가 중요하다는 insight를 얻음
- 데이터의 패턴을 효과적으로 표현할 수 있는 Model Architecture 설계
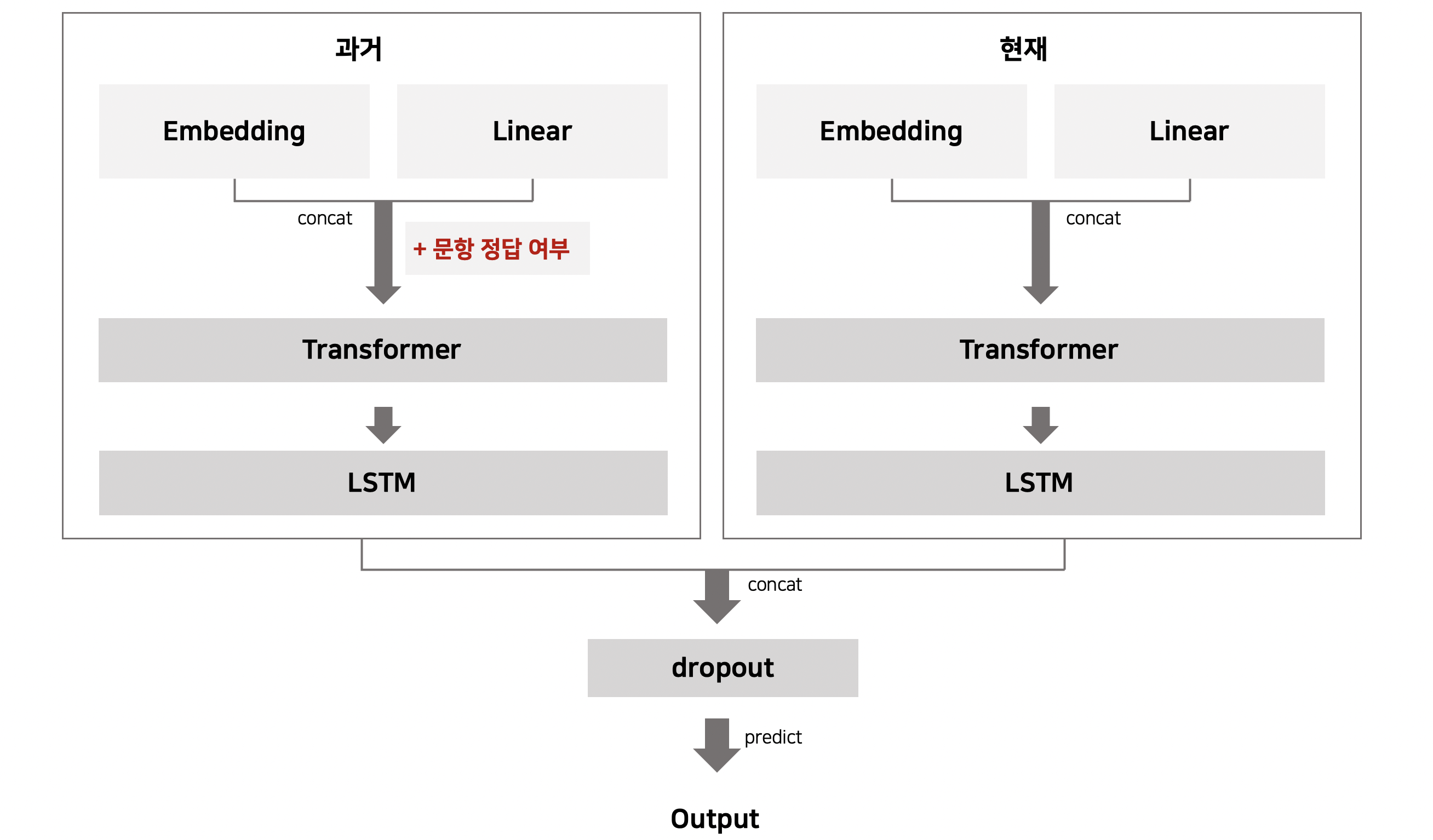
- 과거 풀이 정보의 경우 정답 여부를 알 수 있지만, 현재 풀이 정보의 경우 정답 여부를 모르기 때문에, 이에 표현될 수 있는 정보가 다를 수 있다고 생각하여 과거와 현재 풀이 정보의 연관성을 표현할 수 있는 Model Architecture를 설계함
- 범주형 변수의 경우 Embedding Layer로, 수치형 변수의 경우 Linear Layer를 이용해 Embedding하고, 두 변수를 concat해 문항에 대한 Embedding을 구함
- 시간적 순서를 효과적으로 표현하기 위하여 Transformer와 LSTM을 활용함
- 과거 풀이 정보와 현재 풀이 정보를 서로 다른 Embedding을 활용해 학습시킴으로써 non-convex 한 목적 함수를 조금 더 convex하게 만듦
- 모델의 일반화 성능을 높이기 위한 학습 방법
- Representation Learning
- 데이터의 표현을 효과적으로 학습할 수 있는 Model Architecture를 설계하여 최소한의 변수로 최대의 성능을 이끌어냄
- 범주형 - 문항, 시험지, 태그, 시험지 대분류, 시간, 요일
- 숫자형 - 정답률의 평균 / 표준편차, 풀이 시간의 평균 / 표준 편차
- Loss
- 단순히 마지막 문제에 대해서만 Loss를 계산하면, 모델은 한번 학습시에 유저의 개수 만큼의 데이터 밖에 활용할 수 없음
- 이에 전체 Time-step에 대하여 Loss를 계산하여 유저 데이터 부족 문제를 해결함
- Padding
- Max-len과 mean-len의 차이가 크기 때문에, Max-len으로 동일하게 Padding을 하게 되면 의미 없는 학습과 모델 학습 시간이 매우 늘어난다는 단점을 가짐
- 이를 해결하고자 배치 마다 서로 다른 크기의 padding을 두어 모델을 학습 시킴
- Representation Learning
3. 프로젝트 수행 결과 - private 3위
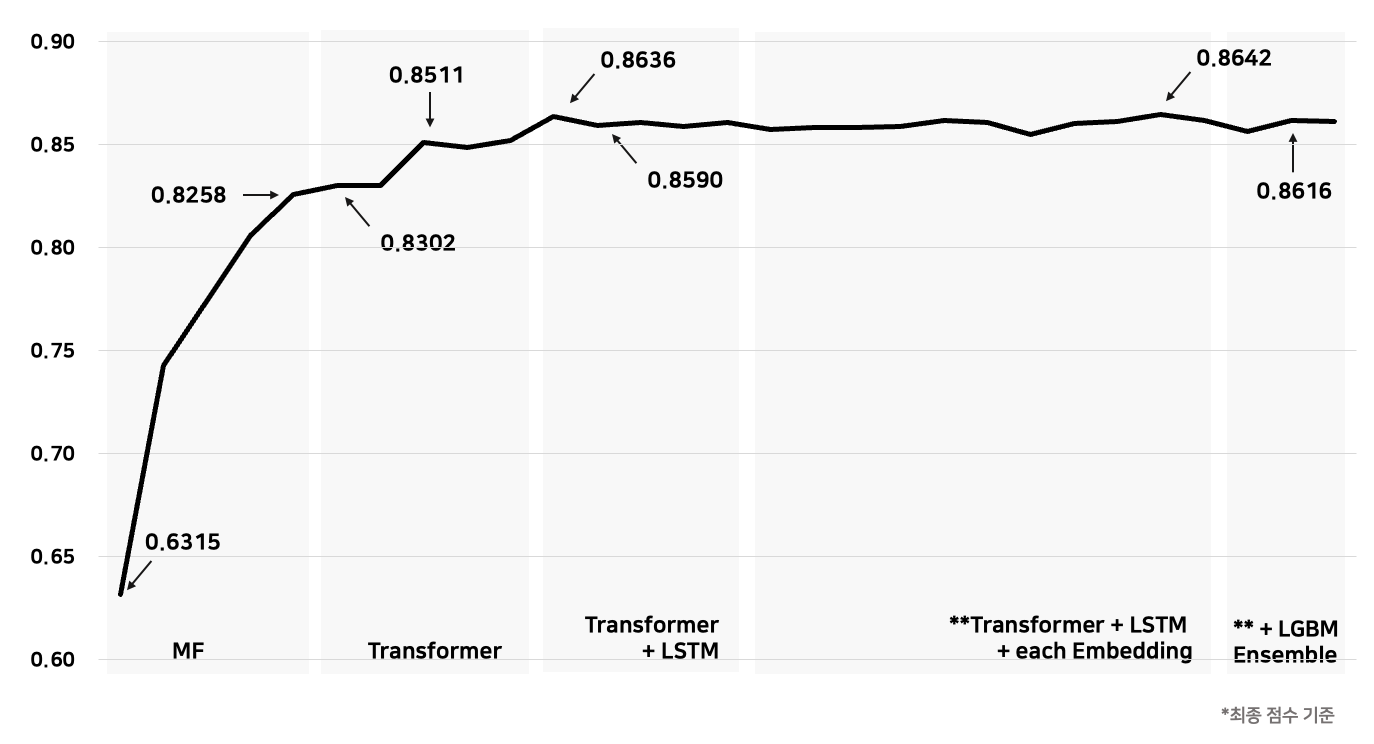
- 유저와 문항 정보를 함께 사용한 GMF 모델을 통해서 0.7429의 성능을 얻음
- 문항에 대한 정보만을 활용한 GMF 모델을 통해서 0.8258의 성능을 얻음
- 시간적 순서를 고려한 Transformer을 통해서 0.8302의 성능을 얻음
- Transformer와 LSTM을 함께 사용하여 0.8511의 성능을 얻음
- 과거 정보와 현재 정보를 같이 Modellig 하여 0.8590의 성능을 얻음
- 과거 정보에 정답에 대한 Embedding을 추가하여 0.8636의 성능을 얻음
- 과거 정보와 현재 정보를 서로 다른 Embedding을 활용해 학습하여 0.8642의 성능을 얻음
4. 새롭게 배운 내용
데이터를 제대로 표현할 수 있는 Model Architecture를 설계한다면, feature engineering과 ensemble 없이도 충분히 높은 성능을 낼 수 있다는 것을 배웠다. (그래도 feature engineering과 ensemble은 모델의 성능을 높이기 위한 좋은 방법임)

Machine Learning Engineer at Konan Technology