
📌 문자열 자료형
📝 문자열
큰 따옴표(" ")
작은 따옴표(' ')
📝 문자열 연산
파이썬은 문자열을 더하거나 곱할 수 있음
>>> head = "Python"
>>> tail = " is fun!"
>>> head + tail # +를 이용해 문자열 합치기
'Python is fun!'>>> a = "python"
>>> a * 2 # *는 문자열의 반복을 의미
'pythonpython'📝 문자열 길이
len 함수 사용
>>> a = "Life is too short"
>>> len(a)
17📝 문자열 인덱싱(indexing)
'가리킨다'는 의미
✔ 인덱싱을 할 땐 파이썬은 0부터 숫자를 센다는 것에 유의
💡 a [번호]
▫ 문자열 안의 특정 값을 뽑아냄
▫ a 앞에 마이너스가 붙은 경우 문자열 뒤부터 셈
▫ 단, 뒤에서 셀 땐 -0이 아닌 -1부터 셈
>>> a = "Life is too short, You need Python"
>>> a[0]
'L'
>>> a[12]
's'
>>> a[-1]
'n'
>>> a[-0]
'L' # 0이나 -0은 값이 같기 때문에 a[0]과 a[-0]도 똑같은 값 출력📝 문자열 슬라이싱(slicing)
'잘라낸다'는 의미
💡 a [시작 번호 : 끝 번호]
▫ 시작 번호부터 끝 번호까지의 문자를 뽑아냄
▫ 끝 번호에 해당하는 문자는 출력하지 않음

>>> s = "Life is too short, you need python"
>>> s
'Life is too short, you need python'
>>> s[3]
'e'
>>> s[9]
'o'
>>> s[10]
'o'
>>> s[3:10]
'e is to'
>>> s[:10]
'Life is to'
>>> s[0:10]
'Life is to'
>>> s[3:]
'e is too short, you need python'
>>> s[3:34]
'e is too short, you need python'Life만 출력
>>> a = "Life is too short, You need Python"
>>> a[0:3]
'Lif' # 끝 번호에 해당하는 e는 출력되지 않음
>>> a[0:4]
'Life' # 따라서, [시작 번호 : 끝 + 1 번호] 로 입력📝 문자열 포매팅(formatting)
문자열 안에 어떤 값을 삽입하는 방법
① 숫자 바로 대입
문자열 포맷 코드 %d
>>> "I eat %d apples." % 3
'I eat 3 apples.'② 문자열 바로 대입
문자열 포맷 코드 %s
>>> "I eat %s apples." % "five"
'I eat five apples.'💡 문자열 대입 시에는 반드시 "큰 따옴표"나 '작은 따옴표' 써주기
③ 숫자 값을 나타내는 변수로 대입
>>> number = 3
>>> "I eat %d apples." % number
'I eat 3 apples.'④ 2개 이상의 값 넣기
% 다음 괄호() 안에 쉼표(,)로 구분하여 각각 값 넣어주기
>>> number = 10
>>> day = "three"
>>> "I ate %d apples. so I was sick for %s days." % (number, day)
'I ate 10 apples. so I was sick for three days.'🔎 문자열 포맷 코드의 종류
| 코드 | 설명 |
|---|---|
| %s | 문자열(String) |
| %c | 문자 1개(character) |
| %d | 정수(Integer) |
| %f | 부동소수(floating-point) |
| %o | 8진수 |
| %x | 16진수 |
| %% | Literal % (문자 % 자체) |
📝 %s 포맷 코드
어떤 형태의 값이든 변환해서 넣을 수 있음
정수 3은 %d, 실수 3.234는 %f를 쓰지만 %s는 정수든 실수든 문자열로 바꾸어 대입하기 때문에 비교적 다양하게 쓰여짐
>>> "I have %s apples" % 3
'I have 3 apples'
>>> "rate is %s" % 3.234
'rate is 3.234'>>> import math
>>> 'The value of pi is approximately %.3f.' % math.pi
'The value of pi is approximately 3.142.'
>>> f'The value of pi is approximately {math.pi:.3f}.'
'The value of pi is approximately 3.142.'
>>> 'The value of pi is approximately {:.3f}'.format(math.pi)
'The value of pi is approximately 3.142'📝 포맷 코드와 숫자 함께 사용
① 정렬과 공백
%s를 숫자와 함께 사용하면 공백과 정렬 표현 가능
>>> "%d" % 1234
'1234'
>>> "%10d" % 1234 # 전체 길이가 10인 공간에서 대입되는 값을 오른쪽으로 정렬하고
그 앞의 나머지는 공백으로 남겨 두라는 의미
' 1234'>>> "%d" % 1234
'1234'
>>> "%-10d" % 1234 # 1234를 왼쪽으로 정렬하고 나머지는 공백
'1234 '② 숫자 표현
%f를 숫자와 함께 사용하면 소수점 뒤에 나올 숫자의 개수 및 자리 조절 가능
💡 소수점 포인트 앞의 숫자는 문자열의 전체 길이를 의미
%0.4f에서 사용한 숫자 0은 길이에 상관하지 않겠다는 의미
→ 숫자 0은 생략해서 %.4f 등으로 많이 씀
>>> "%f" % 1234.5678
'1234.567800' # 기본 소수점 이하 여섯 자리 출력
>>> "%.3f" % 1234.5678
'1234.568' # 소수점 셋째 자리까지 출력(넷째 자리에서 반올림 처리)
>>> "%10.3f" % 1234.5678
' 1234.568'📝 format 함수를 사용한 포매팅
① 숫자 바로 대입
>>> "I eat {0} apples".format(3)
'I eat 3 apples'
>>> "I eat {} apples".format(3)
'I eat 3 apples'② 문자열 바로 대입
>>> "I eat {0} apples".format("five")
'I eat five apples'③ 숫자 값을 가진 변수로 대입
>>> number = 3
>>> "I eat {0} apples".format(number)
'I eat 3 apples'④ 2개 이상의 값 넣기
>>> number = 10
>>> day = "three"
>>> "I ate {0} apples. so I was sick for {1} days.".format(number, day)
'I ate 10 apples. so I was sick for three days.'⑤ 이름으로 넣기
>>> "I ate {number} apples. so I was sick for {day} days.".format(number=10, day=3)
'I ate 10 apples. so I was sick for 3 days.'⑥ 인덱스와 이름을 혼용해서 넣기
>>> "I ate {0} apples. so I was sick for {day} days.".format(10, day=3)
'I ate 10 apples. so I was sick for 3 days.'⑦ 왼쪽 정렬, 오른쪽 정렬, 가운데 정렬
>>> "{0:<10}python".format("hi!") # 0은 인덱스(format 함수의 첫번째 매개변수의 값), <는 왼쪽 정렬, 10은 자릿수를 의미
'hi! python'
>>> "{0:>10}python".format("hi!")
' hi!python'
>>> "{0:^10}python".format("hi!")
' hi! python'⑧ 공백 채우기
>> "{0:=^10}".format("hi") # 가운데 정렬(^)에 =로 공백 채우기
'====hi===='
>>> "{0:!<10}".format("hi") # 왼쪽 정렬(<)에 !로 공백 채우기
'hi!!!!!!!!'
>>> "{0:!<10}python".format("hi")
'hi!!!!!!!!python'⑨ 소수점 표현
>>> y = 3.42134234
>>> "{0:0.4f}".format(y) # 소수점 네 자리까지만 출력
'3.4213'
>>> "{0:10.4f}".format(y) # 자릿수 10으로 맞춰주고 소수점 네 자리까지 출력
' 3.4213'⑩ { 또는 } 문자 표현하기
>>> "{{ and }}".format() # {}를 포매팅 문자가 아닌 문자 그대로 사용하고 싶은 경우
{{}}처럼 중괄호 문자를 연속으로 2개 사용
'{ and }' 📝 f 문자열 포매팅
문자열 앞에 f 접두사를 붙이면 f 문자열 포매팅 기능 사용 가능
파이썬 3.6 버전부터 f 문자열 포매팅 기능 제공
>>> name = '홍길동'
>>> age = 30
>>> f'나의 이름은 {name}입니다. 나이는 {age}입니다.' # name, age 등의 변숫값
생성 후 그 값 참조 가능
'나의 이름은 홍길동입니다. 나이는 30입니다.'① f 문자열 포매팅은 표현식을 지원
📢 여기서 잠깐! 표현식이란?
중괄호 안의 변수를 계산식과 함께 사용하는 것
>>> age = 30
>>> f'나는 내년이면 {age + 1}살이 된다.'
'나는 내년이면 31살이 된다.'② 딕셔너리에서 사용
>>> d = {'name':'홍길동', 'age':30} # 딕셔너리는 Key와 Value로 이뤄진 한 쌍
>>> f'나의 이름은 {d["name"]}입니다. 나이는 {d["age"]}입니다.'
'나의 이름은 홍길동입니다. 나이는 30입니다.'③ 정렬
>>> f'{"hi":<10}' # 왼쪽 정렬
'hi '
>>> f'{"hi":>10}' # 오른쪽 정렬
' hi'
>>> f'{"hi":^10}' # 가운데 정렬
' hi '④ {} 문자 그대로 표시
>>> f'{{ and }}' # {}를 2개 동시 사용
'{ and }'⑤ 공백 채우기
>>> f'{"hi":=^10}' # 가운데 정렬하고 '=' 문자로 공백 채우기
'====hi===='
>>> f'{"hi":!<10}' # 왼쪽 정렬하고 '!' 문자로 공백 채우기
'hi!!!!!!!!'⑥ 소수점 표현
>>> y = 3.42134234
>>> f'{y:0.4f}' # 소수점 4자리까지만 표현
'3.4213'
>>> f'{y:10.4f}' # 소수점 4자리까지 표현하고 총 자리수를 10으로 맞춤
' 3.4213'
📖 문자열 관련 함수
문자열 자료형이 가진 내장 함수
💡 내장 함수 사용 시, 문자열 변수 이름 뒤에 '.'을 붙인 후 함수 적어주기
▪ ex. name.count, name.find 등
① count
문자 갯수 세기
>>> a = "hobby"
>>> a.count('b') # 문자 b의 개수 리턴
2② join
문자열 삽입
>>> ",".join('abcd') # abcd라는 문자 사이에 ',' 삽입
'a,b,c,d'
>>> ",".join(['a', 'b', 'c', 'd']) # 리스트나 튜플의 입력에서도 사용 가능
예시에 쓰인 것은 리스트
'a,b,c,d'③ find
위치 알려주기 #1
찾는 문자열이 처음 나온 위치 반환
없으면 -1 반환
>>> a = "Python is the best choice"
>>> a.find('b')
14 # 문자열 중 문자 b가 처음으로 나온 위치 반환
# 파이썬은 0부터 숫자를 세므로 답은 15가 아니고 14임을 꼭 기억
>>> a.find('k')
-1 # 찾는 문자 또는 문자열이 존재하지 않는 경우 -1 반환④ index
위치 알려주기 #2
find와 마찬가지로 찾는 문자열이 처음 나온 위치 반환
단, 찾는 문자열이 없으면 에러 발생
>>> a = "Life is too short"
>>> a.index('t')
8 # t가 처음으로 나온 위치 반환
>>> a.index('k')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found # find와 달리, 찾는 문자열이 없으면 오류 발생⑤ upper
소문자를 대문자로 바꾸기
>>> a = "hi"
>>> a.upper()
'HI'⑥ lower
대문자를 소문자로 바꾸기
>>> a = "HI"
>>> a.lower()
'hi'⑦ lstrip, rstrip, strip
왼쪽, 오른쪽, 양쪽 공백 지우기
>>> a = " hi "
>>> a.lstrip() # lstrip에서 l은 left
문자열 중 가장 왼쪽에 있는 한 칸 이상의 연속된 공백들을 모두 지움
'hi '
>>> a= " hi "
>>> a.rstrip() # rstrip에서 r은 right
문자열 중 가장 오른쪽에 있는 한 칸 이상의 연속된 공백을 모두 지움
' hi'
>>> a = " hi "
>>> a.strip() # 문자열 양쪽에 있는 한 칸 이상의 연속된 공백을 모두 지움
'hi'⑧ replace
문자열 바꾸기
replace(바뀔 문자열, 바꿀 문자열)
문자열 안의 특정 값을 다른 값으로 치환
>>> a = "Life is too short"
>>> a.replace("Life", "Your leg")
'Your leg is too short'⑨ split
문자열 나누기
공백 또는 특정 문자열을 구분자로 해서 문자열 분리
분리된 문자열은 리스트로 반환됨
>>> a = "Life is too short"
>>> a.split() # 괄호 안에 아무 것도 넣지 않으면 공백을 기준으로 문자열 나눔
['Life', 'is', 'too', 'short'] # 리스트
>>> b = "a:b:c:d"
>>> b.split(':') # 특정 값이 있을 경우 괄호 안의 값을 구분자로 지정해 문자열 나눔
['a', 'b', 'c', 'd'] # 리스트⑩ print
사람이 읽을 수 있는 형태로 문자열 출력
>>> print("The Latin 'Oryctolagus cuniculus' means 'domestic rabbit'.")
The Latin 'Oryctolagus cuniculus' means 'domestic rabbit'.
>>> print('one\ttwo\nthree\tfour') # 문자열 앞뒤 따움표를 제거
one two # 탈출 문자열을 읽기 편한 형태로 변환해서 출력
three four
>>> members = '''one
... two
... three'''
>>> members
'one\ntwo\nthree'
>>> print(members)
one
two
three
>>> print(1, 2, 3) # 쉼표로 구분된 값 리스트를 전달하면
1 2 3 # 값 사이에 공백 하나를 넣고 마지막 값 뒤에는
>>> print() # 새 줄을 넣어 출력 (인자가 없으면 다음 줄로)
>>> print(1, 'two', 'three', 4.0)
1 two three 4.0
>>> radius = 5
>>> print("The diameter of the circle is", radius * 2, "cm.")
The diameter of the circle is 10 cm.
# print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
>>> print('a', 'b', 'c')
a b c
>>> print('a', 'b', 'c', sep='|')
a|b|c
>>> print('a', 'b', 'c', sep='|', end='...') # seperate(분리하다), end(끝)
a|b|c...>>>
①① input
키보드에서 입력받은 한 줄의 텍스트를 읽어들임
>>> name = input("이름을 입력하세요. :")
이름을 입력하세요. : 홍길동
>>> print(f"안녕. {name}")
안녕. 홍길동
>>> species = input() >>> species = input("Please enter a species: ")
Home sapiens Please enter a species: Python curtus
>>> species >>> species
'Home sapiens' 'Python curtus'
>>> population = input()
6973738433
>>> population
'6973738433'
>>> type(population) # type() → 변수의 데이터 타입을 확인할 때 사용
<class 'str'>
>>> population = int(population) # int() → 정수 형식의 문자열 데이터를
정수형 데이터로 변환
>>> population
6973738433
>>> type(population)
<class 'int'>
📌 리스트 자료형
📝 리스트(list)
자료형의 집합을 표현할 수 있는 자료형
💡 리스트명 = [요소1, 요소2, 요소3, ...]
대괄호([ ])로 감싸고 각 요소값은 쉼표(,)로 구분
📝 리스트의 생김새
리스트 안에는 어떠한 자료형도 포함 가능
>>> a = ['a', 1, 2.3, True]
>>> a
['a', 1, 2.3, True]
>>> a = ['a', 1, 2.3, True, [1, 2, 'a']]
>>> a
['a', 1, 2.3, True, [1, 2, 'a']]📝 리스트의 인덱싱
문자열에서처럼 인덱싱 가능
>>> a = [1, 2, 3]
>>> a
[1, 2, 3]
>>> a[0]
1
>>> a[0] + a[2]
4
>>> a[-1] # 리스트 a의 마지막 요솟값
3
>>> a = [1, 2, 3, ['a', 'b', 'c']]
>>> a[0]
1
>>> a[-1]
['a', 'b', 'c']
>>> a[3]
['a', 'b', 'c']
>>> a[-1][0] # a[-1]이 가리키는 ['a', 'b', 'c'] 리스트 중 0번째 요소를 추출
'a'📝 리스트의 슬라이싱
문자열에서처럼 슬라이싱 기법을 적용 가능
💡 [시작 인덱스 : 끝 인덱스]
끝이 2인 경우라면, 0번부터 1번까지만 출력하고 2번은 출력 X
>>> a = [1, 2, 3, 4, 5]
>>> a[0:2]
[1, 2]
>>> a = [1, 2, 3, 4, 5]
>>> b = a[:2] # a[2]인 3 포함 X
>>> c = a[2:] # a[2]인 3부터 끝까지 출력
>>> b
[1, 2]
>>> c
[3, 4, 5]📝 리스트 결합(+)
리스트 사이에서 +는 2개의 리스트를 합치는 기능
문자열에서 "abc" + "def" = "abcdef"가 되는 것과 같은 의미
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a + b
[1, 2, 3, 4, 5, 6]📝 리스트 반복(*)
"abc" * 3 이라고 한다면 결과값은 "abcabcabc"
리스트를 반복해서 출력해 새로운 리스트를 생성
>>> a = [1, 2, 3]
>>> a * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]📝 리스트 길이 구하기
len 함수 사용
문자열, 리스트 외에 튜플과 딕셔너리에도 쓰이는 함수
>>> a = [1, 2, 3]
>>> len(a)
3📢 <번외> 초보자들이 많이 하는 실수?
문자와 숫자를 더하는 행위 → 에러가 발생하므로 str 함수 사용
str은 정수나 실수를 문자열로 바꿔주는 파이썬의 내장 함수>> "a" + 123 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can only concatenate str (not "int") to str >> 123 + "a" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'int' and 'str' >> str(123) + "a" '123a'
리스트는 값의 수정·삭제가 가능
>>> a = [1, 2, 3]
>>> a[2] = 4
>>> a
[1, 2, 4]📝 del
리스트 요소 삭제
del a[x]는 x번째 요솟값 삭제
💡 del 함수는 파이썬이 자체적으로 가지고 있는 삭제 함수
>>> a = ['a', 'b', 'c']
>>> del a[2]
>>> a
['a', 'b']
💡 객체란 파이썬에서 사용되는 모든 자료형을 의미
📝 슬라이싱 기법
리스트의 요소 여러 개를 한꺼번에 삭제 가능
>>> a = [1, 2, 3, 4, 5]
>>> del a[2:] # a[2:]에 해당하는 리스트의 요소들 삭제
>>> a
[1, 2]📖 리스트 관련 함수
① append
리스트에 요소 추가
'덧붙이다, 첨부하다'
append(x)는 리스트의 맨 마지막에 x를 추가하는 함수
>>> a = [1, 2, 3]
>>> a.append([4, 5])
>>> a
[1, 2, 3, [4, 5]]② sort
리스트의 요소를 오름차순으로 정렬
숫자 뿐만 아니라 알파벳 같은 문자도 정렬 가능
>>> a = [1, 4, 3, 2]
>>> a.sort()
>>> a
[1, 2, 3, 4]>>> a = ['a', 'c', 'b']
>>> a.sort()
>>> a
['a', 'b', 'c']③ reverse
리스트 뒤집기
리스트를 역순으로 뒤집어줌
현재의 리스트를 거꾸로 뒤집음
>>> a = ['a', 'c', 'b']
>>> a.reverse()
>>> a
['b', 'c', 'a']④ index
인덱스 반환
index(x)는 리스트에 x 값이 있으면 x의 인덱스 값(위칫값)을 리턴
존재하지 않는 것을 입력하면 에러 발생
리스트에서 find 함수는 존재 X
>>> a = [1, 2, 3]
>>> a.index(3) # 숫자 3의 위치는 a[2]이므로 2를 리턴
2
>>> a.index(1) # 숫자 1의 위치는 a[0]이므로 0을 리턴
0 ⑤ insert
리스트에 요소 삽입
💡 insert(a, b)
리스트의 a번째 위치에 b를 삽입
>>> a = [1, 2, 3]
>>> a.insert(0, 4) # 0번째 자리, 즉 첫 번째 요소인 a[0] 위치에 값 4를 삽입
>>> a
[4, 1, 2, 3]
>>> a.insert(3, 5) # 리스트 a의 a[3], 즉 네 번째 요소 위치에 값 5를 삽입
>>> a
[4, 1, 2, 5, 3]⑥ remove
리스트의 요소 제거
remove(x)는 리스트에 첫 번째로 나오는 x를 삭제
a가 3이라는 값을 2개 가지고 있을 때 remove를 썼다면 첫 번째 3만 삭제됨
>>> a = ['a', 'b', 'c']
>>> a.remove('c')
>>> a
['a', 'b']⑦ pop
리스트 요소 추출
pop()은 리스트의 맨 마지막 요소를 리턴하고 그 요소 삭제
>>> a = ['a', 'b', 'c']
>>> a.pop()
'c'
>>> a
['a', 'b']
>>> a = [1, 2, 3]
>>> a.pop(1) # a.pop(1)은 a[1]의 값을 꺼내어 리턴
2
>>> a
[1, 3]⑧ count
리스트에 포함된 요소 x의 개수 세기
>>> a = [1, 2, 3, 1]
>>> a.count(1)
2⑨ extend
리스트 확장
extend(x)에서 x에는 리스트만 올 수 있으며 기존에 존재했던 리스트에
x 리스트를 더하게 됨
>>> a = [1, 2, 3]
>>> a.extend([4, 5])
>>> a
[1, 2, 3, 4, 5]
>>> a = [1, 2, 3]
>>> a = a + [4, 5] # a += [4, 5]와 동일한 표현식
>>> a
[1, 2, 3, 4, 5]📝 리스트 타입의 변수는 주소를 공유
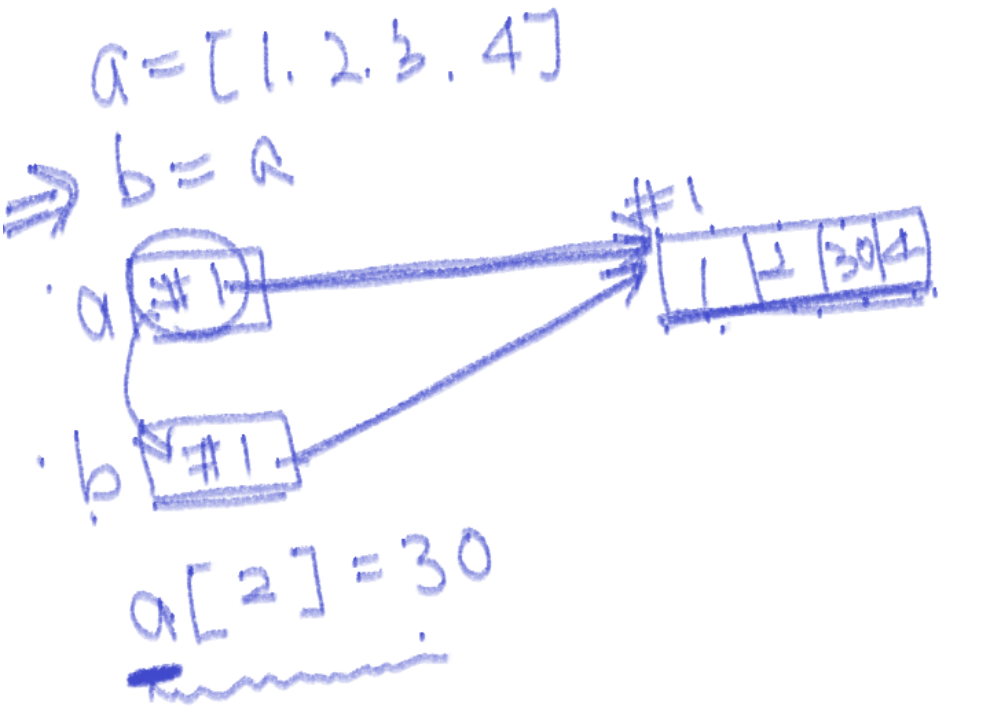
>>> a = [ 1, 2, 3, 4 ]
>>> b = a
>>> a
[1, 2, 3, 4]
>>> b
[1, 2, 3, 4]
>>> a[2] = 30
>>> a
[1, 2, 30, 4]
>>> b
[1, 2, 30, 4]📝 슬라이싱 기법을 통해 값 복사
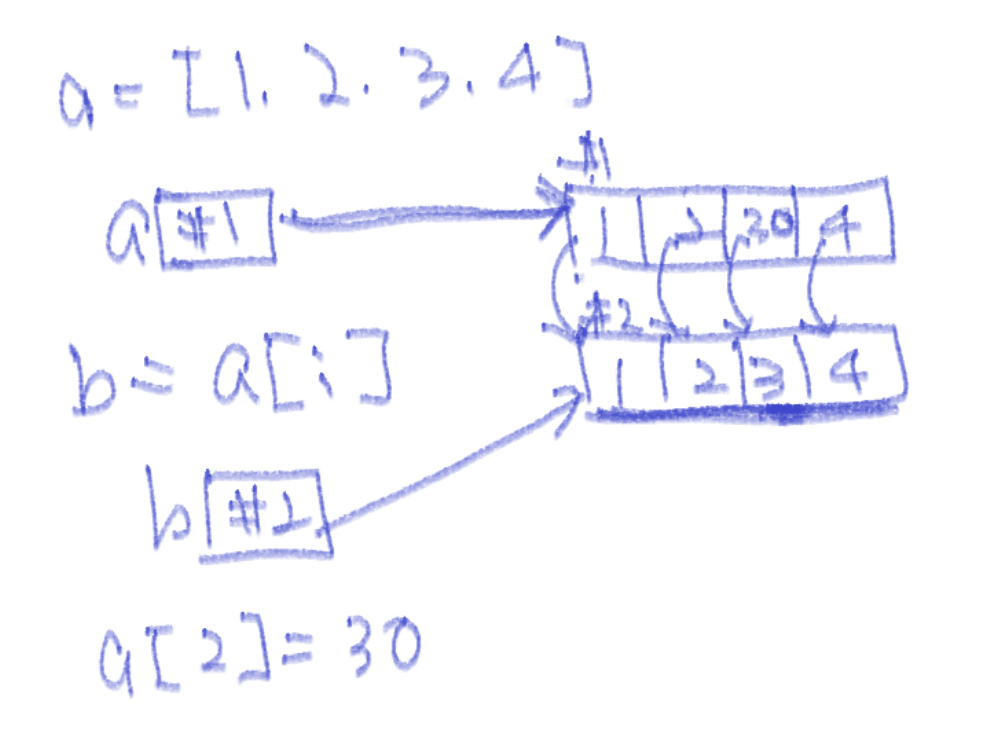
>>> a = [ 1, 2, 3, 4 ]
# a 리스트의 처음부터 끝까지 데이터를 가져와서 새로운 리스트 반환
>>> b = a[:]
>>> a
[1, 2, 3, 4]
>>> b
[1, 2, 3, 4]
>>> a[2] = 30
>>> a
[1, 2, 30, 4]
>>> b
[1, 2, 3, 4]📌 튜플 자료형
문자열 " "
리스트 [ , ]
튜플 ( , )
📝 튜플(tuple)
몇 가지 점을 제외하고 리스트와 비슷
💡 튜플과 리스트의 가장 큰 차이점
리스트는 요솟값의 생성, 삭제, 수정 등의 변경이 가능
✔ 튜플은 요솟값의 변경이 불가능
📝 튜플의 형태
단 1개의 요소값을 가질 경우 요소 뒤에 반드시 쉼표(,)를 붙여야 함
소괄호(()) 생략 가능
>>> a = (1) # 계산의 우선 순위를 지정할 때 사용하는 괄호
>>> a
1
>>> type(a)
<class 'int'>>>> a = (1, ) # 요소 하나를 가지는 튜플 타입을 의미하는 괄호
>>> a
(1,)
>>> type(a)
<class 'tuple'>📝 튜플의 요솟값을 삭제하려는 경우
리스트처럼 del 함수로 지우려고 하면 에러 발생
📝 튜플의 요솟값을 변경하려는 경우
요솟값의 변경도 에러 발생
📝 인덱싱
문자열, 리스트처럼 인덱싱 가능
>>> t1 = (1, 2, 'a', 'b')
>>> t1[0]
1
>>> t1[3]
'b'📝 슬라이싱
문자열, 리스트처럼 슬라이싱 가능
새 튜플 반환
>>> t1 = (1, 2, 'a', 'b')
>>> t1[1:] # 1부터 마지막 요소까지 슬라이싱
(2, 'a', 'b')📝 튜플 더하기
+ 사용
>>> t1 = (1, 2, 'a', 'b')
>>> t2 = (3, 4)
>>> t3 = t1 + t2 # 기존의 t1, t2의 요솟값은 변경되지 않고 새로운 튜플인 t3 생성
>>> t3
(1, 2, 'a', 'b', 3, 4)📝 튜플 곱하기
* 사용
>>> t2 = (3, 4)
>>> t3 = t2 * 3 # t2를 3번 반복
>>> t3
(3, 4, 3, 4, 3, 4)📝 튜플 길이
len
>>> t1 = (1, 2, 'a', 'b')
>>> len(t1)
4💡 튜플은 요솟값 변경 불가능
따라서 sort, insert, remove, pop과 같은 내장 함수가 없음
📌 딕셔너리 자료형
📝 딕셔너리(Dictinary)
연관 배열(associative array) 또는 해시(hash) 라고도 부름
💡 {"키1":"값1", "키2":"값2", "키3":"값3"...}
키
문자열, 숫자로 구성
값
모든 자료형 가능
Key는 딕셔너리 내의 데이터를 식별하는 용도
값들을 구분하므로 중복되지 않는 유일(unique)한 값을 가져야 함
→ 하나를 제외한 나머지 값들이 모두 무시되기 때문
📝 딕셔너리 쌍 추가
딕셔너리는 인덱스가 없어 순서 중요 X
>>> a = {1: 'a'}
>>> a[2] = 'b'
>>> a
{1: 'a', 2: 'b'}📝 딕셔너리 요소 삭제
del a[key]
지정한 Key에 해당하는 {key : value} 쌍이 삭제
>>> del a[1]
>>> a
{2: 'b', 'name': 'pey', 3: [1, 2, 3]}📝 딕셔너리 사용법
💡 리스트는 key로 쓸 수 없지만 튜플은 key로 쓸 수 있음
리스트는 값이 가변적이기 때문에 key로 사용 불가능
튜플은 값의 변경이 불가능하기에 사용 가능
📝 key를 사용해 value 얻기
key의 value를 얻기 위해서는 '딕셔너리 변수 이름[Key]' 사용
>>> grade = {'pey': 10, 'julliet': 99}
>>> grade['pey']
10
>>> grade['julliet']
99📖 딕셔너리 관련 함수
① keys
key 리스트 만들기
딕셔너리 형태의 key만 모아 객체 리턴
>>> a = {'name': 'pey', 'phone': '010-9999-1234', 'birth': '1118'}
>>> a.keys() # a.keys()는 딕셔너리 a의 Key만을 모아 dict_keys 객체를 리턴
dict_keys(['name', 'phone', 'birth'])② values
value 리스트 만들기
>>> a = {'name': 'pey', 'phone': '010-9999-1234', 'birth': '1118'}
>>> a.values() # values 함수를 호출하면 dict_values 객체를 리턴
dict_values(['pey', '010-9999-1234', '1118'])③ items
key, value 쌍 얻기
items 함수는 key와 value 쌍을 튜플로 묶은 값을 dict_items 객체로 리턴
>>> a = {'name': 'pey', 'phone': '010-9999-1234', 'birth': '1118'}
>>> a.items()
dict_items([('name', 'pey'), ('phone', '010-9999-1234'), ('birth', '1118')])
>>> person = {"name":"hong", "age":23, "phone":"010-0000-0000"}
>>> person["name"]
'hong'
>>> for key in person.keys():
... print(f"{key}\t:{person[key]}")
...
name :hong
age :23
phone :010-0000-0000
>>> for key, value in person.items():
... print(f"{key}\t:{value}")
...
name :hong
age :23
phone :010-0000-0000④ clear
key와 value 값 삭제
>>> a.clear()
>>> a
{}빈 리스트 []
빈 튜플 ()
빈 딕셔너리 {}
⑤ get
key로 value 얻기
get(x) 함수는 x라는 Key에 대응되는 Value 리턴
>>> a = {'name': 'pey', 'phone': '010-9999-1234', 'birth': '1118'}
>>> a.get('name') # a.get('name')와 a['name']는 동일한 결괏값을 가짐
# 단, 전자는 None을 리턴하고 후자는 에러를 발생시킴
'pey'
>>> a.get('phone')
'010-9999-1234'딕셔너리 안에 찾으려는 키가 없을 경우 디폴트 값을 대신 가져오게 할 수 있음
💡 get(x, '디폴트 값')
>> a.get('nokey', 'foo') 'foo'
⑥ in
찾고싶은 key가 딕셔너리 안에 있는지 조사
>>> a = {'name':'pey', 'phone':'010-9999-1234', 'birth': '1118'}
>>> 'name' in a
True
>>> 'email' in a
False📌 집합 자료형
📝 집합(set)
집합에 관련된 것을 쉽게 처리하기 위해 만든 자료형
📝 집합 자료형 만들기
set 키워드 사용
>>> s1 = set([1, 2, 3])
>>> s1
{1, 2, 3}
>>> s2 = set("Hello")
>>> s2
{'e', 'H', 'l', 'o'}📝 집합의 특징
중복 허용 X
순서 X
→ 인덱싱 불가 (딕셔너리도 순서가 없기에 이와 마찬가지)
📝 set 자료형에 저장된 값을 인덱싱으로 접근하는 방법
리스트나 튜플로 변환한 후 시도
>>> s1 = set([1, 2, 3])
>>> l1 = list(s1)
>>> l1
[1, 2, 3]
>>> l1[0]
1
>>> t1 = tuple(s1)
>>> t1
(1, 2, 3)
>>> t1[0]
1📝 교집합, 합집합, 차집합 구하기
set이 유용하게 사용됨
>>> s1 = set([1, 2, 3, 4, 5, 6])
>>> s2 = set([4, 5, 6, 7, 8, 9])💁♀️ 교집합
intersection
& 사용
>>> s1 & s2
{4, 5, 6}
>>> s1.intersection(s2) # s2.intersection(s1)을 사용해도 결과는 동일
{4, 5, 6}💁♀️ 합집합
union
| 사용
>>> s1 | s2
{1, 2, 3, 4, 5, 6, 7, 8, 9}
>>> s1.union(s2) # s2.union(s1)을 사용해도 결과는 동일
{1, 2, 3, 4, 5, 6, 7, 8, 9}💁♀️ 차집합
difference
-사용
>>> s1 - s2
{1, 2, 3}
>>> s2 - s1
{8, 9, 7}
>>> s1.difference(s2)
{1, 2, 3}
>>> s2.difference(s1)
{8, 9, 7}📖 집합 자료형 관련 함수
① add
값 1개 추가
>>> s1 = set([1, 2, 3])
>>> s1.add(4)
>>> s1
{1, 2, 3, 4}② update
값 여러 개 추가
>>> s1 = set([1, 2, 3])
>>> s1.update([4, 5, 6])
>>> s1
{1, 2, 3, 4, 5, 6}③ remove
특정 값 제거
>>> s1 = set([1, 2, 3])
>>> s1.remove(2)
>>> s1
{1, 3}📌 불 자료형
📝 불(bool)
True나 False, 단 2개의 값을 가짐
not, and, or 연산이 가능
true, false와 같이 작성하면 안되고 첫 글자를 항상 대문자로 작성
📝 불 자료형 사용법
논리 연산
조건문
>>> 1 == 1 # 불 자료형은 조건문의 리턴값으로도 활용됨
True
>>> 2 > 1
True
>>> 2 < 1
False📝 자료형의 참과 거짓
데이터 타입의 값이 논리 연산에서 False로 취급되는 경우
빈 문자, 빈 딕셔너리·튜플·리스트, None, 숫자 0
| 값 | 참 또는 거짓 |
|---|---|
| "python" | 참 |
| "" | 거짓 |
| (1, 2, 3) | 참 |
| () | 거짓 |
| {'a': 1} | 참 |
| {} | 거짓 |
| 1 | 참 |
| 0 | 거짓 |
| None | 거짓 |
📝 불 연산
bool 함수 사용
데이터가 있으면 참, 없거나 숫자 0이면 거짓
>>> bool('python')
True
>>> bool('')
False📝 연산자 우선 순위
산술 연산자 > 비교 연산자 > 불 연산자
>>> x = 3
>>> (1 < x) and (x <= 5) >>> 3 < 5 != True
True True
>>> 1 < x <= 5 >>> 3 < 5 != False
True True
>>> (3 < 5) and (5 != True) # int(True)
True
>>> (3 < 5) and (5 != False) # int(False)
True📝 논리 연산 (논리합, 논리곱)
True or True → True → 하나라도 True면 True를 반환
True or False → True 둘 모두 False인 경우, False를 반환
False or True → True
False or False → False
True and True → True → 하나라도 False이면 False를 반환
True and False → False 둘 모두 True인 경우, True를 반환
False and True → False
False and False → False📝 문자열 비교
ASCII 코드를 기준으로 비교
공백(32) < A(65) < z(122)
사전 순 비교(dictionary ordering, lexicographical ordering)
→ 문자열 내 서로 대응하는 문자들을 왼쪽부터 오른쪽으로 비교
in 연산자
→ 어떤 문자열이 다른 문자열 내에 들어 있는지 확인
>>> ' ' < 'A'
True
>>> 'A' < 'z'
True
>>> 'abc' < 'abcd'
True
>>> 'Jan' in '01 Jan 2020' # 대소문자 구분
True
>>> '' in 'abc' # 빈 문자열은 모든 문자열의 부분 문자열
True
>>> '' in ''
True📌 자료형의 값을 저장하는 공간, 변수
📝 변수
객체를 가리키는 것
객체란 자료형의 데이터(값)와 같은 것
a = [1, 2, 3] # [1, 2, 3] 값을 가지는 리스트(객체)가 자동으로 메모리에 생성
# 변수 a는 [1, 2, 3] 리스트가 저장된 메모리의 주소를 가리키게 됨💡 메모리란 컴퓨터가 프로그램에서 사용하는 데이터를 기억하는 공간
📝 id
변수가 가리키는 객체 데이터가 저장된 주소를 리턴하는 내장 함수
>>> a = [1, 2, 3]
>>> id(a)
4303029896 # 변수 a가 가리키는 메모리의 주소📝 리스트 복사
b 변수를 생성할 때 a 변수의 값을 가져오면서 a와는 다른 주소를 가리키도록 만드는 방법
>>> a[1] = 4
>>> a
[1, 4, 3]
>>> b
[1, 4, 3]① : 이용
리스트 전체를 가리키는 : 기호를 사용해 복사
>>> a = [1, 2, 3]
>>> b = a[:]
>>> a[1] = 4
>>> a
[1, 4, 3]
>>> b
[1, 2, 3]② copy 모듈 이용
값 복사 가능
>>> from copy import copy
>>> a = [1, 2, 3]
>>> b = copy(a) # b = copy(a)는 b = a[:]와 동일
>>> b is a
False # 두 변수의 값은 같지만 가리키는 객체는 서로 다름📝 변수 만드는 법
>>> a, b = ('python', 'life') # 튜플로 값 대입
>>> (a, b) = 'python', 'life' # 튜플의 괄호 생략 가능
>>> [a, b] = ['python', 'life'] # 리스트로 값 대입
>>> a = b = 'python' # 여러 개의 변수에 같은 값 대입 가능📝 변수의 값을 바꾸기(치환)
a, b = b, a(b의 값을 a에, a의 값을 b에 삽입)
>>> a = 3
>>> b = 5
>>> a, b = b, a
>>> a
5
>>> b
3📌 if문
📝 조건문(분기문, 제어문)
참일 때 실행되는 블록, 거짓일 때 실행되는 블록이 다름
📝 if문
들여쓰기 주의
조건문 다음에 콜론(:)을 붙여야 조건절이 끝났다는 것을 의미
if 조건문:
수행할 문장1
수행할 문장2
else:
수행할 문장1
수행할 문장2📝 비교 연산자
<, >, ==, !=, <=, >=
① and, or, not
and
모두 참이어야만 참
or
둘 중 하나만 참이어도 참
not
참을 거짓으로, 거짓을 참으로 바꿔줌
② in, not in
연속된 데이터에 찾으려는 값이 있는지 검색하려면 in
찾으려는 값이 없는지 검색하려면 not in
📝 조건문에서 구문을 실행하지 않고 통과
pass 사용
📝 elif(else if)
if와 else 만으로 조건 판단이 어려울 때 보다 다양한 조건 판단
if 조건문:
수행할_문장1
수행할_문장2
elif 조건문:
수행할_문장1
수행할_문장2
elif 조건문:
수행할_문장1
수행할_문장2
else:
수행할_문장1
수행할_문장2📝 조건부 표현식(conditional expression)
if score >= 60:
message = "success"
else:
message = "failure"위의 코드를 조건부 표현식을 사용해 아래와 같이 간단히 표현 가능
message = "success" if score >= 60 else "failure"📝 단락 평가(short-circuit evaluation)
and나 or를 포함하는 표현식을 평가할 때 왼쪽부터 오른쪽으로 평가
평가를 멈출만한 충분한 정보를 얻으면 아직 평가하지 않은 피연산자가 있어도 평가를 멈춤
>>> 1 / 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> (2 < 3) or (1 / 0)
True📝 구문 오류(syntax error)
유효하지 않은 파이썬 코드를 입력했을 때 발생
>>> 3 +
File "<stdin>", line 1
3 +
^
SyntaxError: invalid syntax📝 의미 오류(semantic error)
파이썬이 할 수 없는 (Ex. 수를 0으로 나눈다거나 존재하지 않는 변수를 사용) 명령을 내렸을 때 발생
>>> 3 + moogah
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'moogah' is not defined📌 실습 #1
연령별 BMI 지수에 따른 위험도를 출력하는 프로그램을 작성하시오.

age = int(input("나이를 입력하세요 : "))
bmi = int(input("BMI 지수를 입력하세요 : "))
if age < 45 and bmi < 22:
print("위험도: 낮음")
elif age < 45 and bmi >= 22:
print("위험도: 중간")
elif age >= 45 and bmi < 22:
print("위험도: 중간")
elif age >= 45 and bmi >= 22:
print("위험도: 높음")
age = int(input("나이를 입력하세요 : "))
bmi = int(input("BMI 지수를 입력하세요 : "))
young = age < 45
old = not young
slim = bmi < 22
fat = not slim
if young and slim:
print("위험도: 낮음")
elif young and fat:
print("위험도: 중간")
elif old and slim:
print("위험도: 중간")
elif old and fat:
print("위험도: 높음")