📌 가명처리 기술의 이해
1. 개인정보 데이터(자료형태) 이해
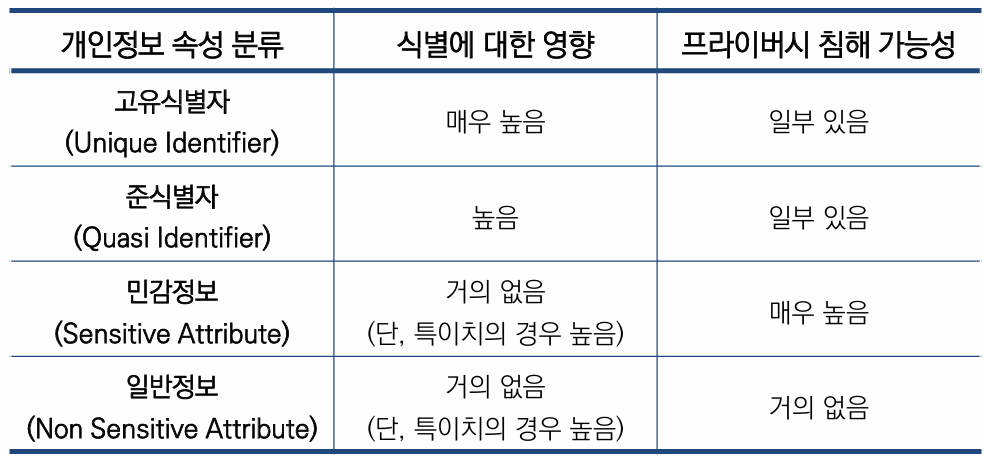
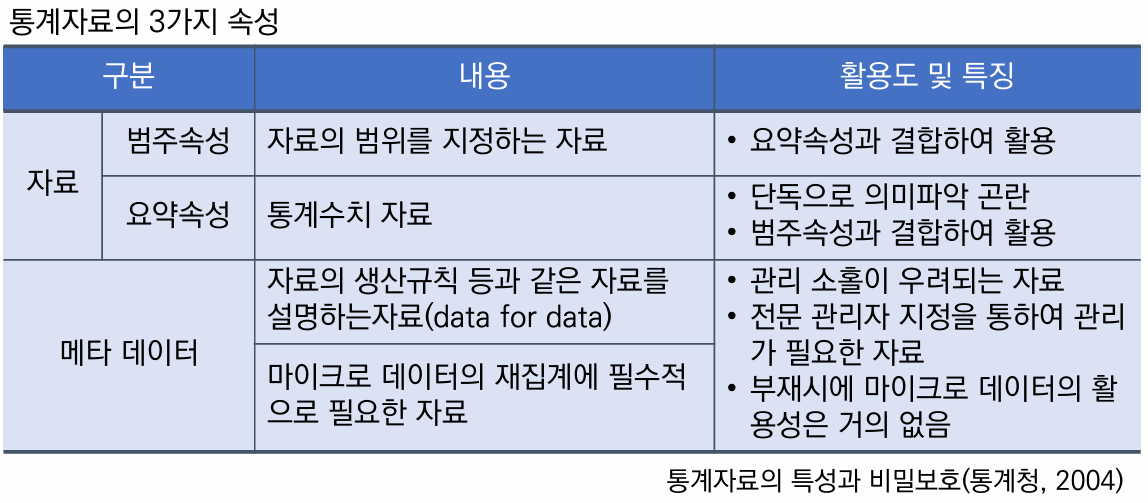
개인정보 속성 분류 목적
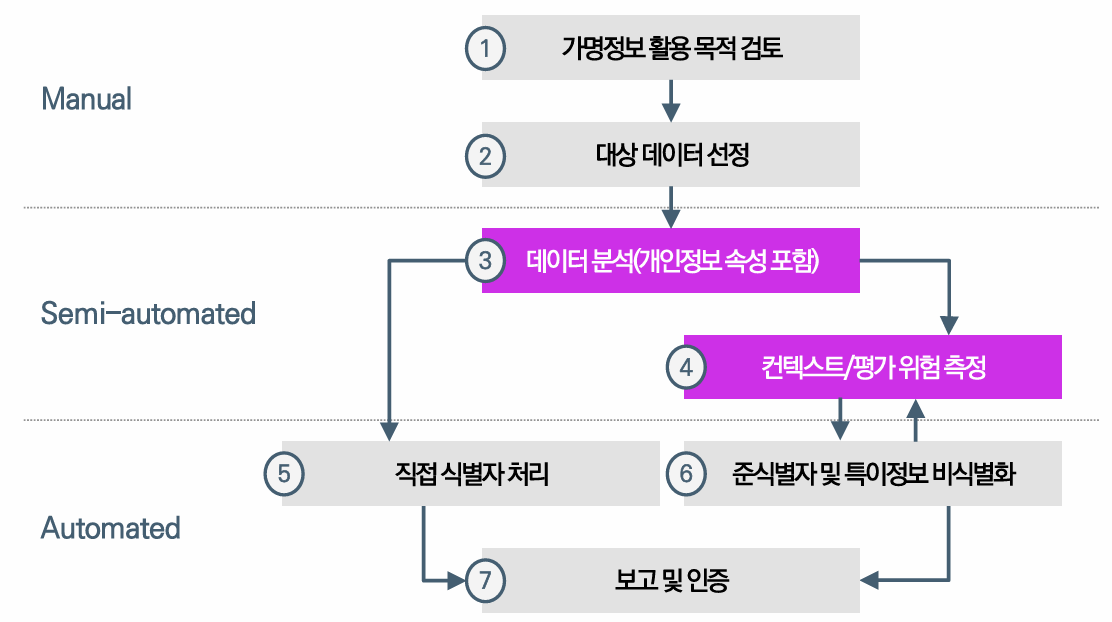
개인정보 속성 분류
개인정보 자료 일반적 자료 형태
자료 형태로 데이터 분석
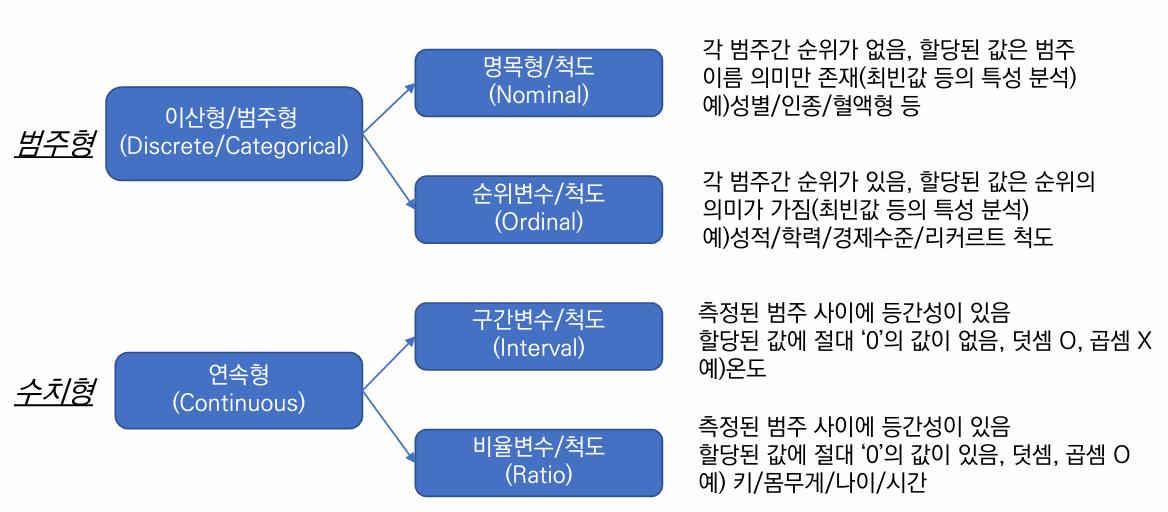
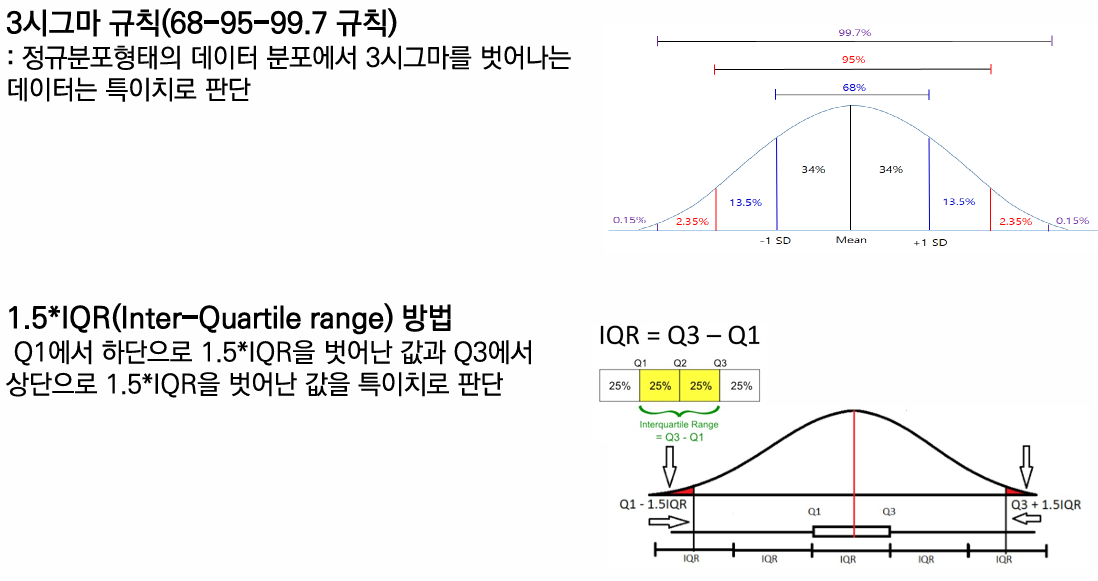
특이정보 관찰 방법

수치형 데이터 관찰 방법
범주형 데이터 관찰 방법
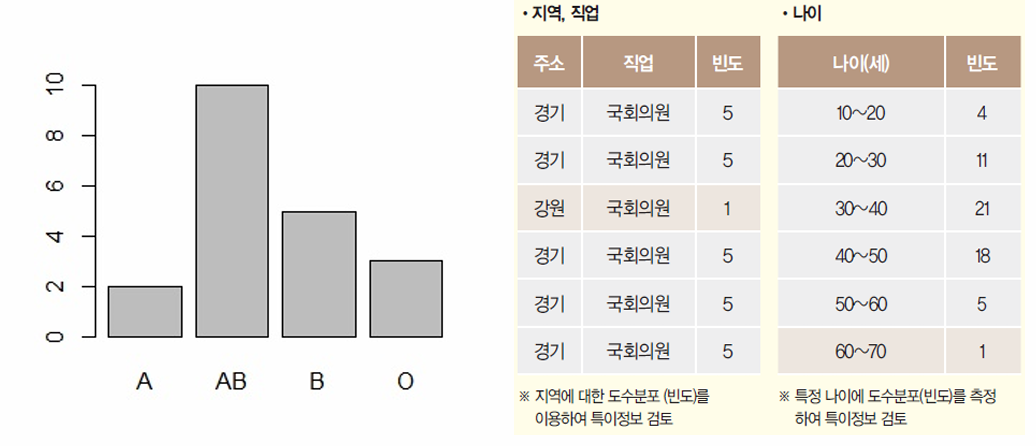
2. 가명처리 기술 이해
가명처리 기술 이슈
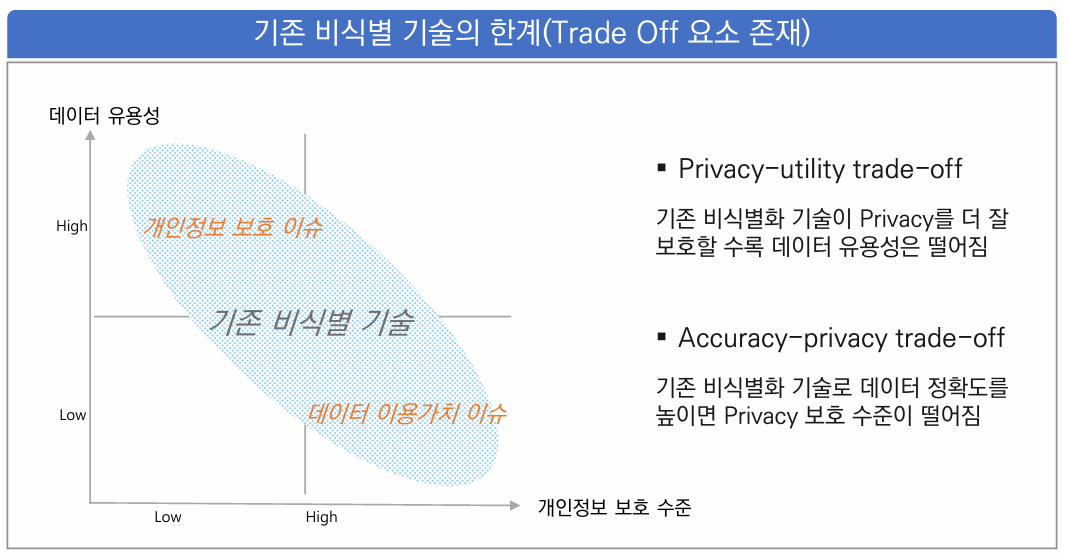
가명처리 기법 (ISO/IEC 20889 기준)

3. 가명처리 가이드라인의 기술분류
개요
아래 분류는 이해를 돕기 위해 ISO/IEC 20889, 그리고 EU ENISA에서 발간한 보고서 등 국내·외 자료들을 참고하여 작성했으며 표준 X
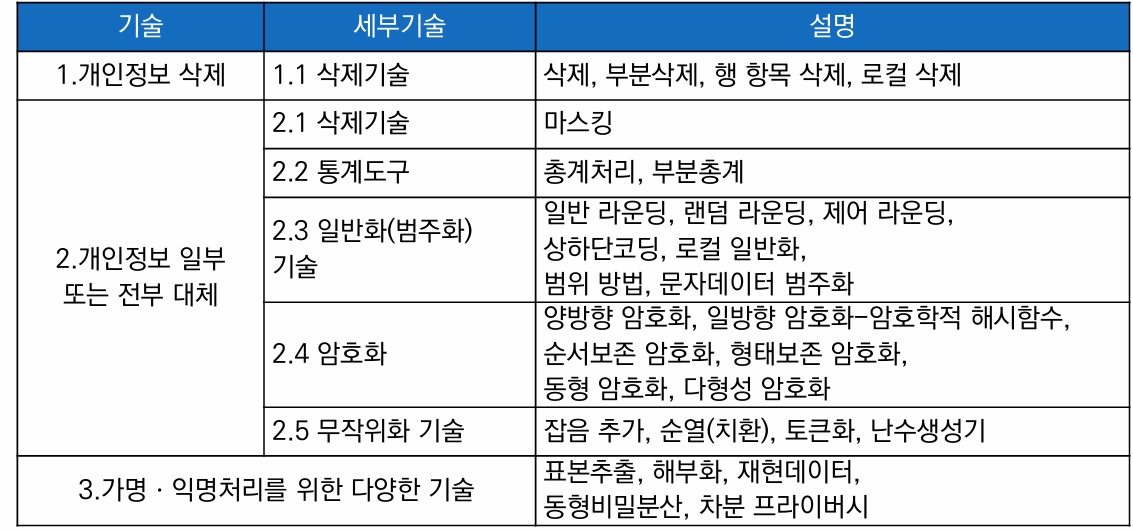
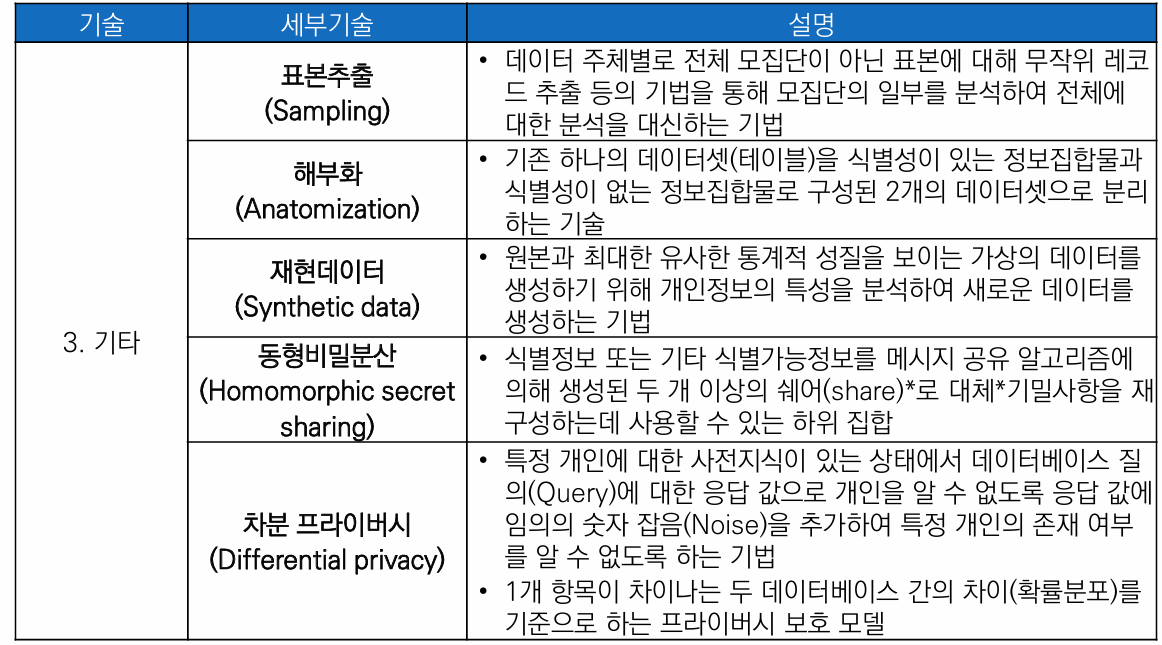
1. 개인정보 삭제
2. 개인정보 일부 또는 전부 대체
3. 기타 기술
4. 가명처리 기술 상세
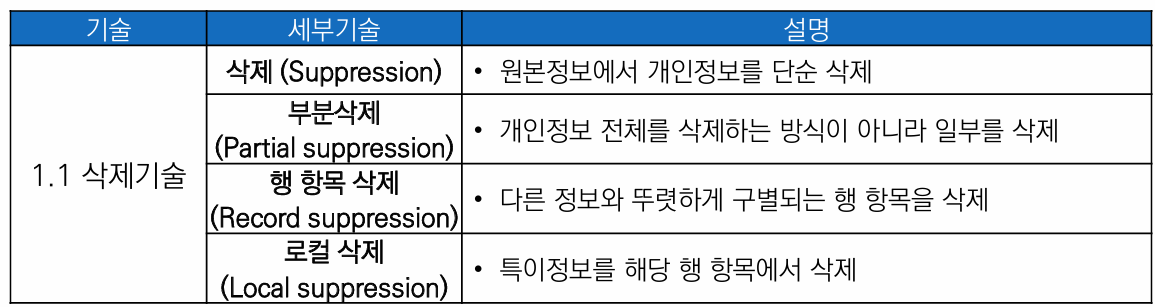
1-1. 삭제 기술 - 선택된 항목을 제거하는 기술
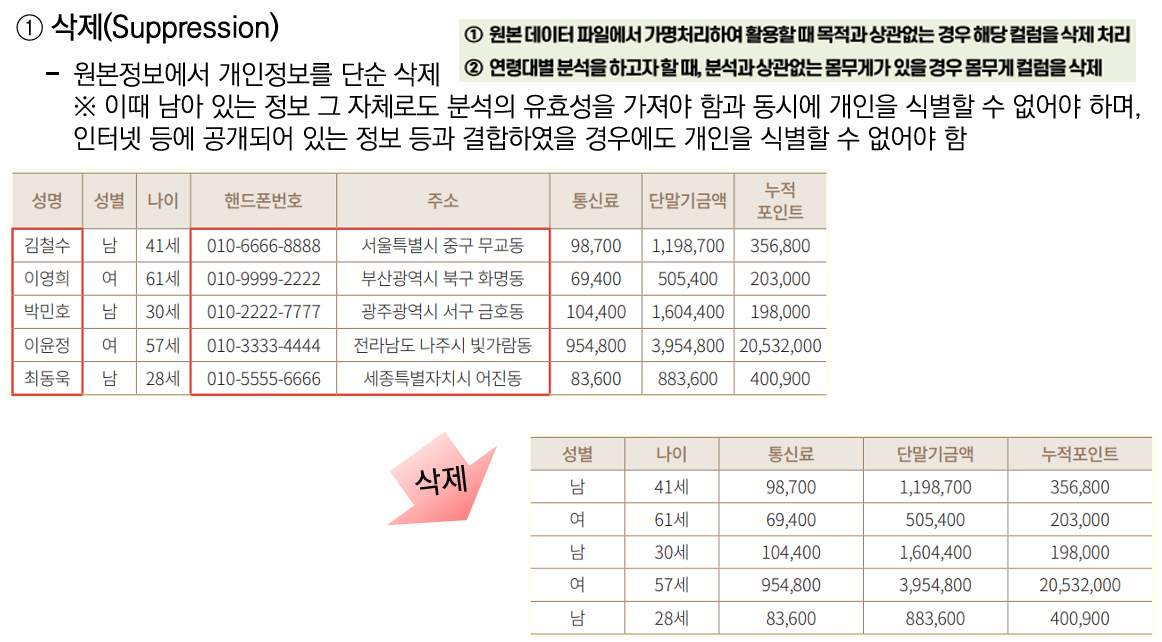
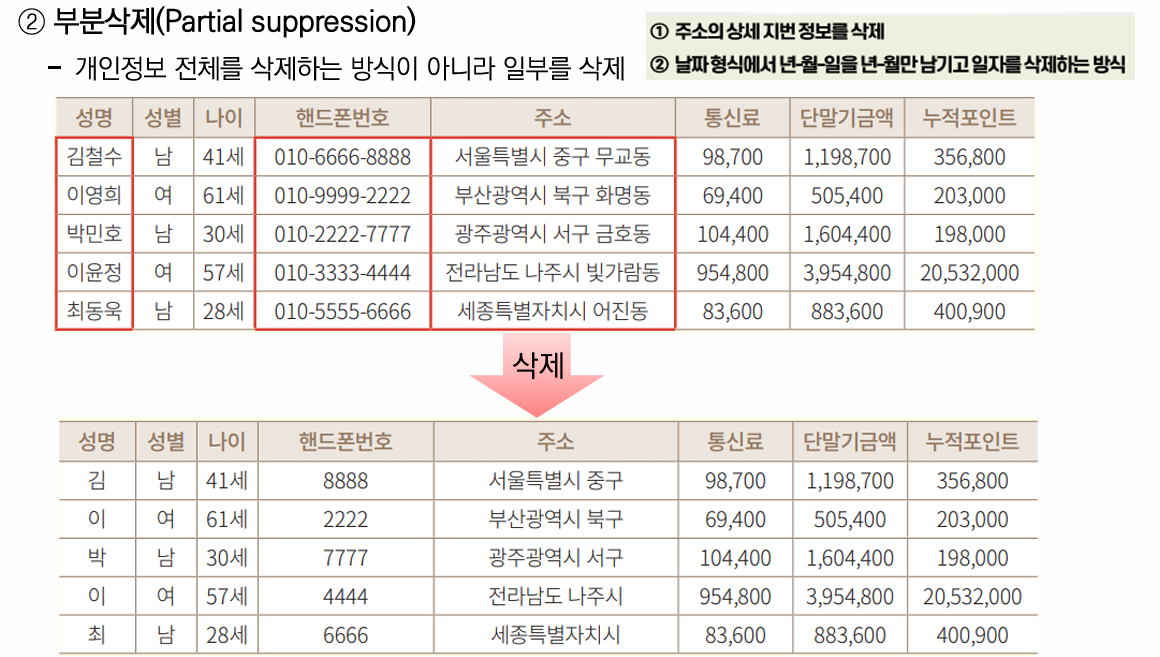
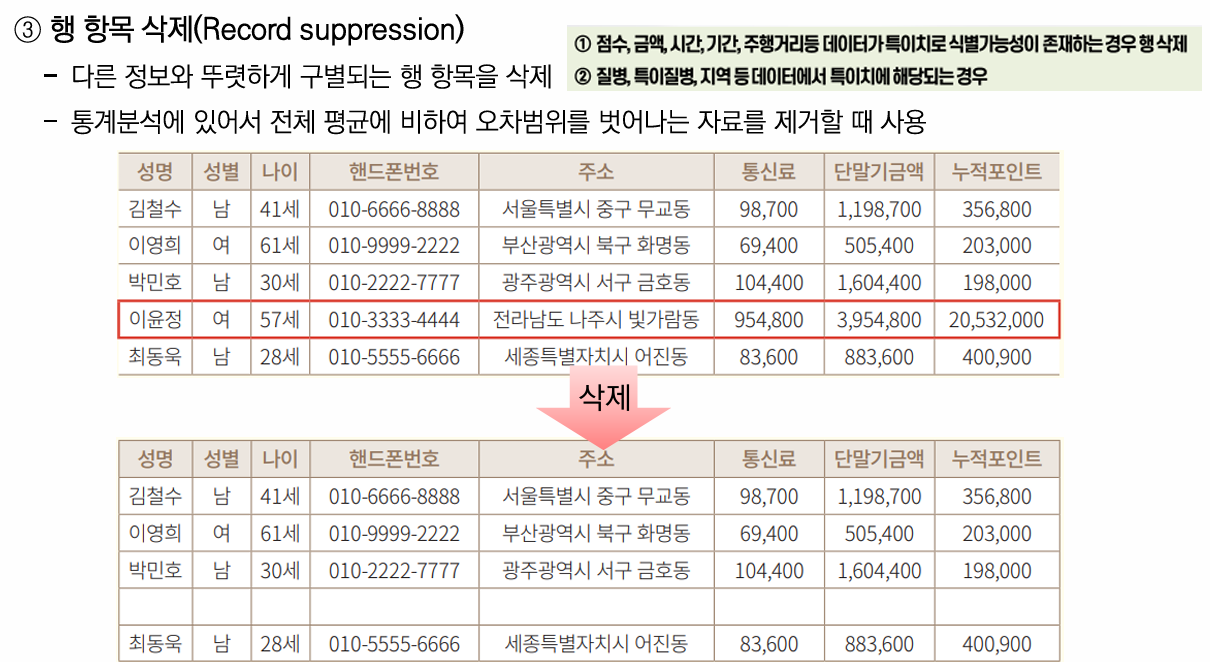
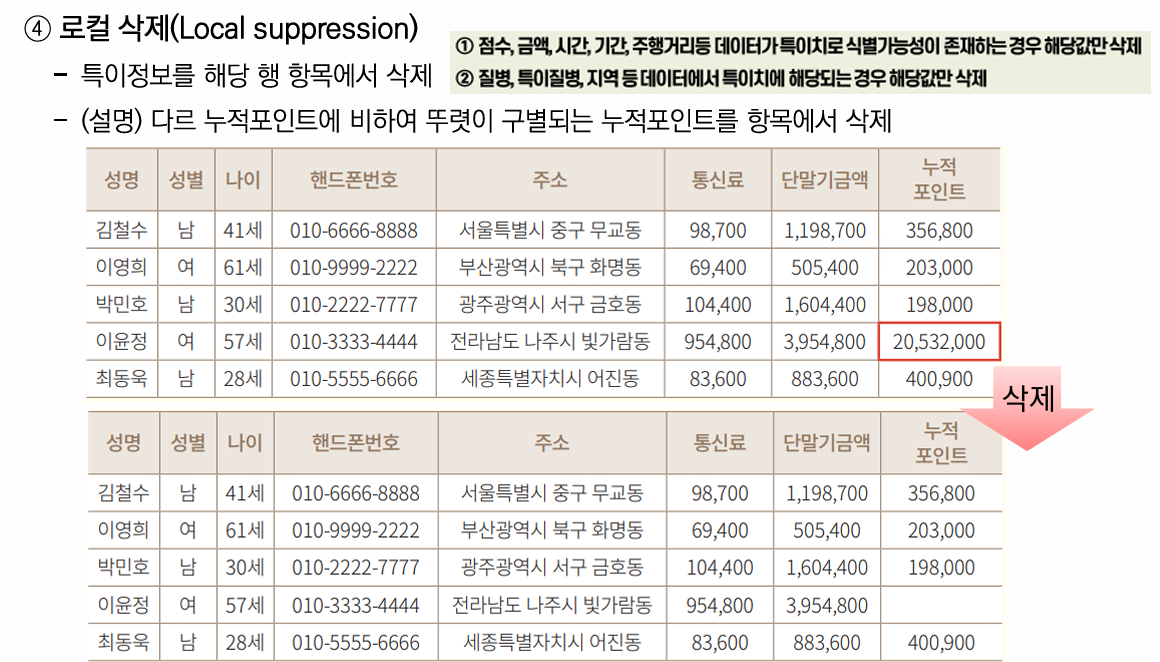
2-1. 삭제 기술 - 선택된 항목을 제거하는 기술
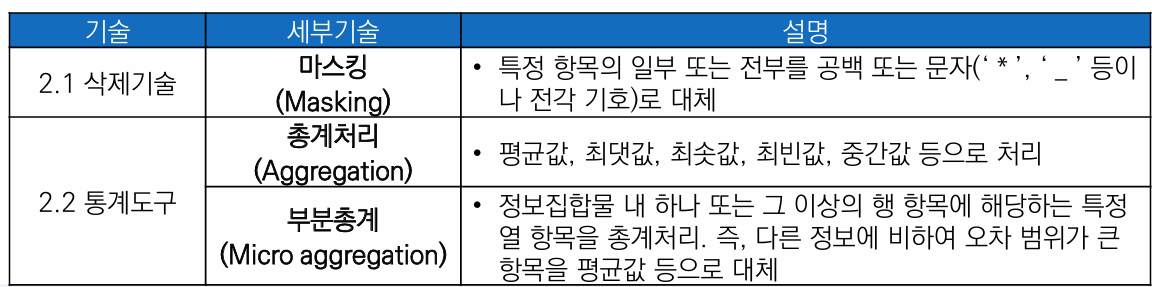
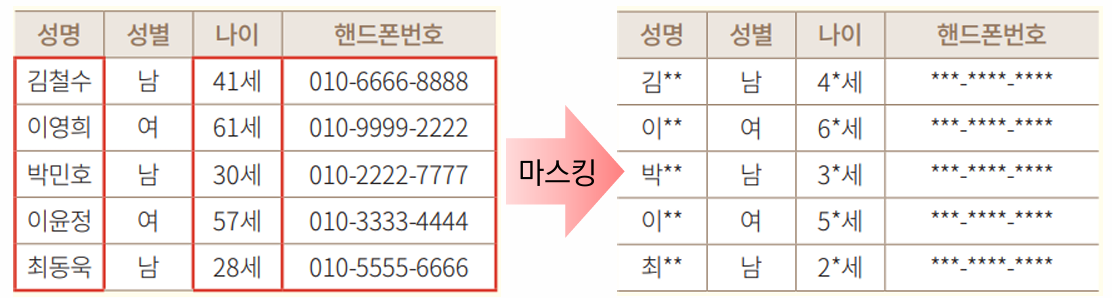
마스킹(Masking)
특정 항목의 일부 또는 전부를 공백 또는 문자(' *', '_' 등이나 전각 기호)로 대체
💡 분류는 개인정보 일부 또는 전부 대체로 분류되지만, 기술적으로 마스킹된 부분은 데이터로써의 가치가 없어져 일부 문건에서는 삭제로 분류되기도 함
2-2. 통계 도구 - 데이터의 전체 구조를 변경하는 통계적 성질을 가진 기법
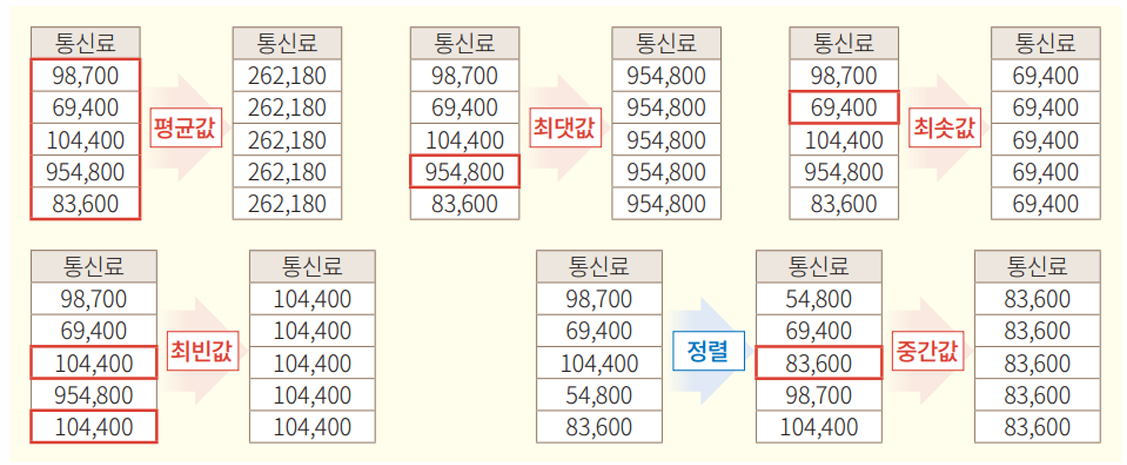
총계처리 (Aggregation)
평균값, 최댓값, 최솟값, 최빈값, 중간값 등으로 처리
💡 단, 데이터 전체가 유사한 특징을 가진 개인으로 구성되어 있을 경우 그 데이터의 대푯값이 특정 개인의 정보를 그대로 노출시킬 수도 있으므로 주의 필요
부분총계 (Micro Aggregation)
정보집합물 내 하나 또는 그 이상의 행 항목에 해당하는 특정 열 항목을 총계처리 즉, 다른 정보에 비하여 오차 범위가 큰 항목을 평균값 등으로 대체
동질 집합 내의 특정 항목을 총계처리 하거나 특정 조건에 너무 특이한 값이 있어 개인의 식별 가능성이 높지만 분석에 꼭 필요한 값인 경우 처리
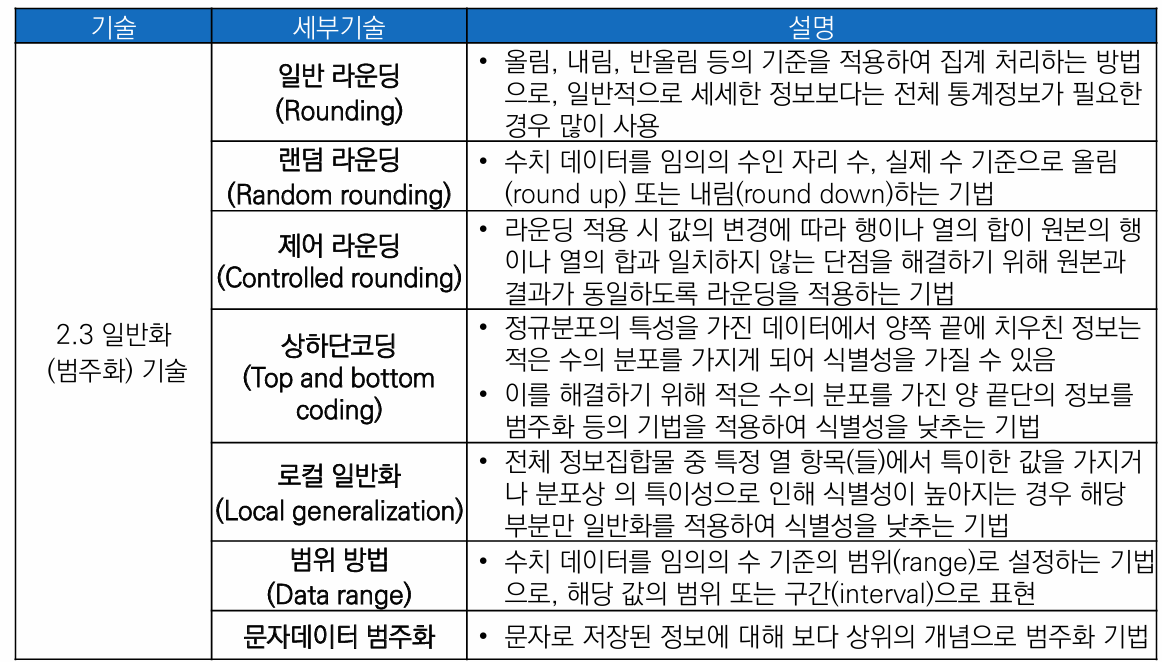
2-3. 일반화 기술 - 범주화로도 불리며 특정한 값을 상위의 속성으로 대체
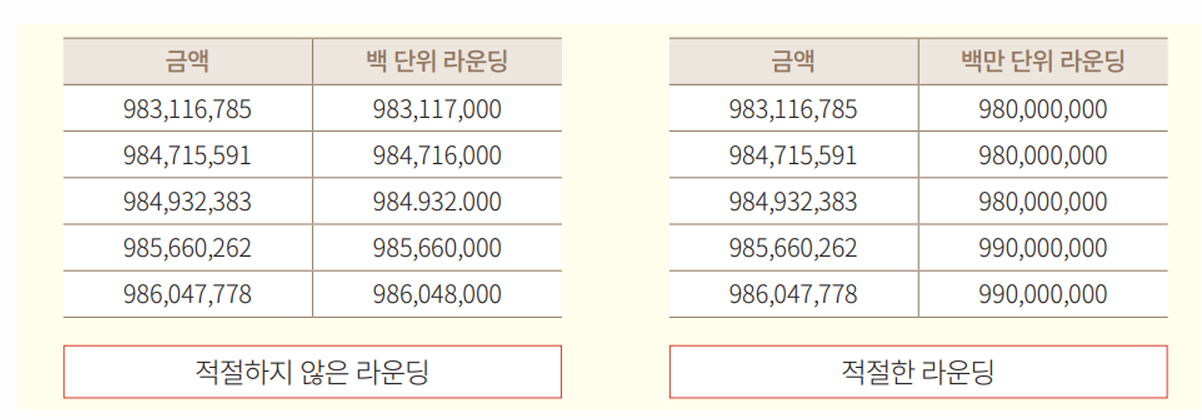
1-1. 일반 라운딩 (Rounding)
올림, 내림, 반올림 등의 기준을 적용하여 집계 처리하는 방법
💡 적절하지 않은 라운딩의 경우 라운딩 후에도 남은 값의 유일성이 남게 될 수 있으며, 적용하는 단위에 대한 판단이 중요

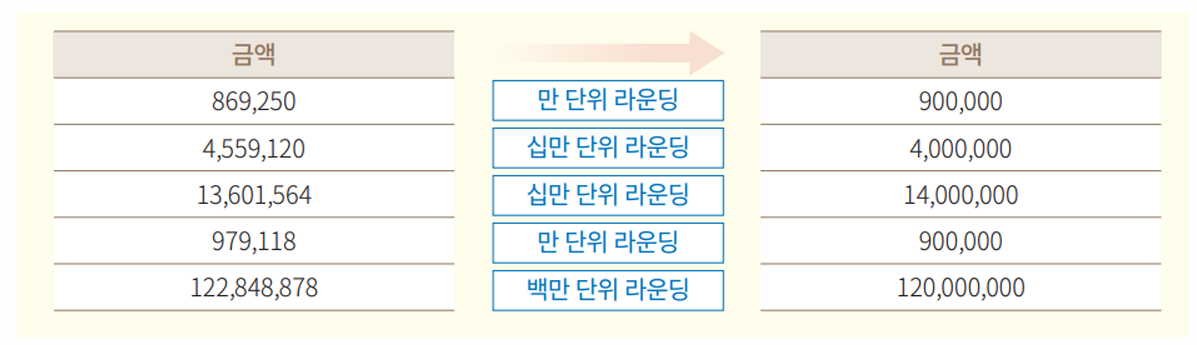
1-2. 랜덤 라운딩 (Random Rounding)
수치 데이터를 임의의 수인 자리 수, 실제 수 기준으로 올림(round up) 또는 내림(round down)하는 기법
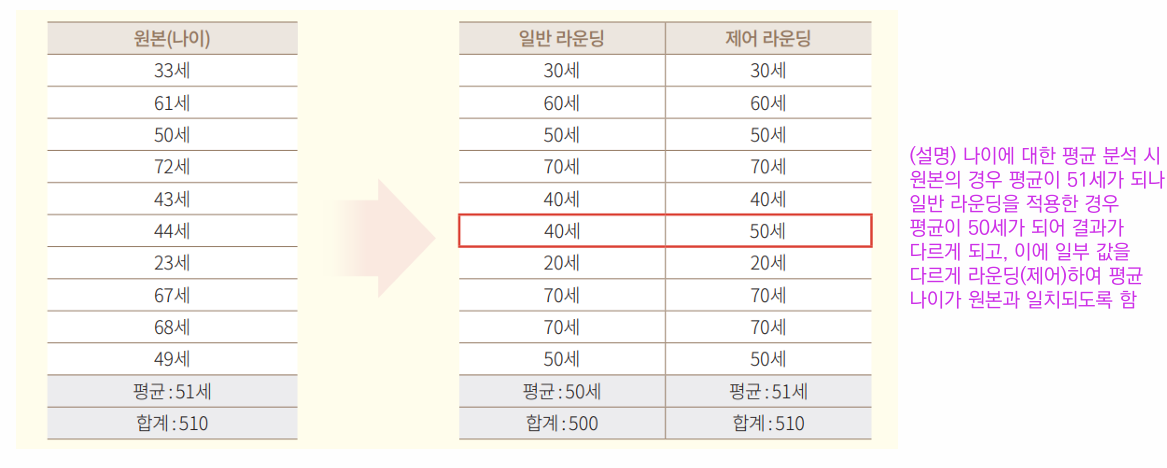
1-3. 제어 라운딩 (Controlled Rounding)
라운딩 적용 시 값의 변경에 따라 행이나 열의 합이 원본의 행이나 열의 합과 일치하지 않는 단점을 해결하기 위해 원본과 결과가 동일하도록 라운딩을 적용하는 기법
💡 컴퓨터 프로그램으로 구현하기 어렵고 복잡한 통계표에는 적용하기 어려우며, 해결할 수 있는 방법이 존재하지 않을 수 있어 아직 실무에서는 잘 사용하지 않음
2. 상하단코딩 (Topr and bottom coding)
정규분포의 특성을 가진 데이터에서 양쪽 끝에 치우친 정보는 적은 수의 분포를 가지게 되어 식별성을 가질 수 있으며, 이를 해결하기 위해 적은 수의 분포를 가진 양 끝단의 정보를 범주화 등의 기법을 적용하여 식별성을 낮추는 기법
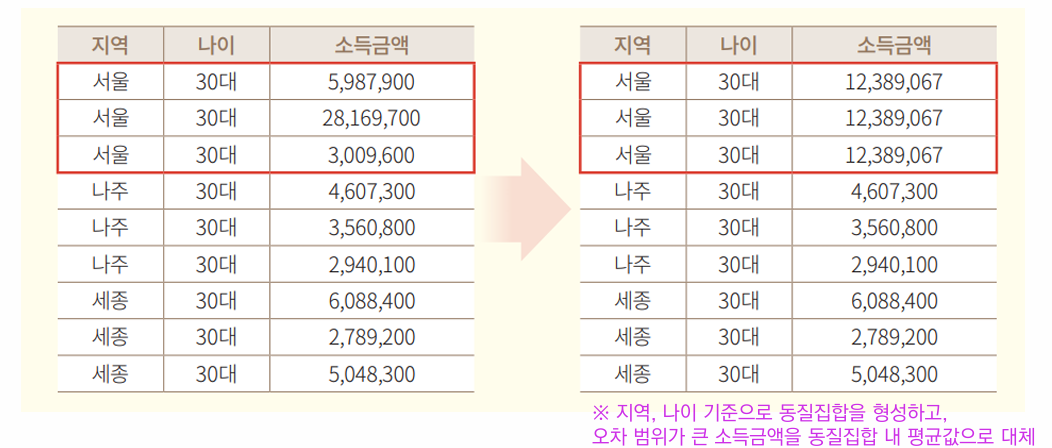
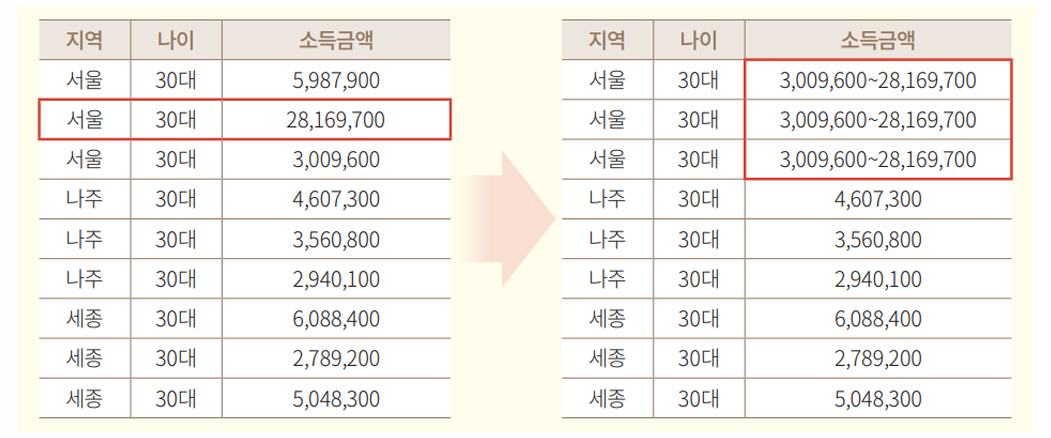
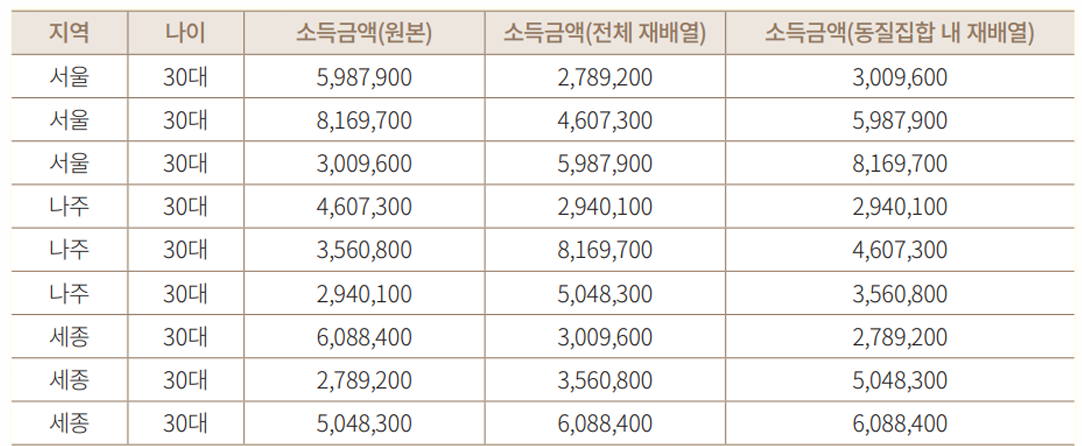
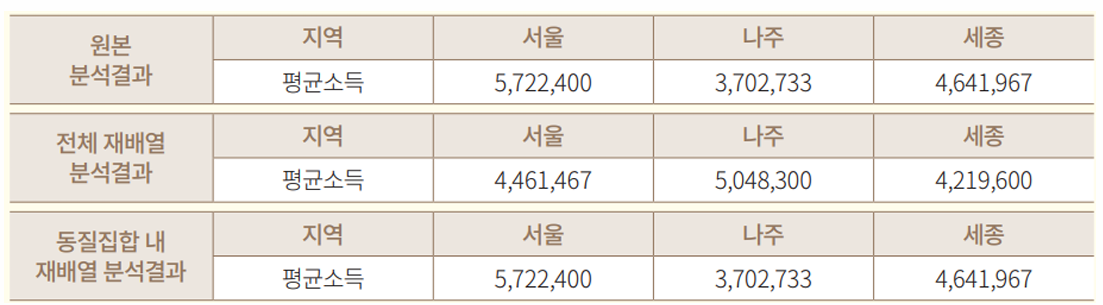
3. 로컬 일반화 (Local generalization)
전체 정보집합물 중 특정 열 항목(들)에서 특이한 값을 가지거나 분포상의 특이성으로 인해 식별성이 높아지는 경우 해당 부분만 일반화를 적용하여 식별성을 낮추는 기법
→ 서울 지역의 30대 중 분포 상 다른 금액에 비해 특이한 값을 동질집합 내 범주화
→ 특이한 로컬(28,169,700)에만 3,009,600 ~ 28,169,700으로 범주화 할 수 있음
4. 범위 방법 (Data range)
수치 데이터를 임의의 수 기준의 범위(range)로 설정하는 기법으로, 해당 값의 범위 또는 구간(interval)으로 표현

5. 문자 데이터 범주화 (Categorization of character data)
문자로 저장된 정보에 대해 상위의 개념으로 범주화하는 기법
2-4. 암호화 - 정보 가공 시 일정한 규칙의 알고리즘을 적용하여 대체
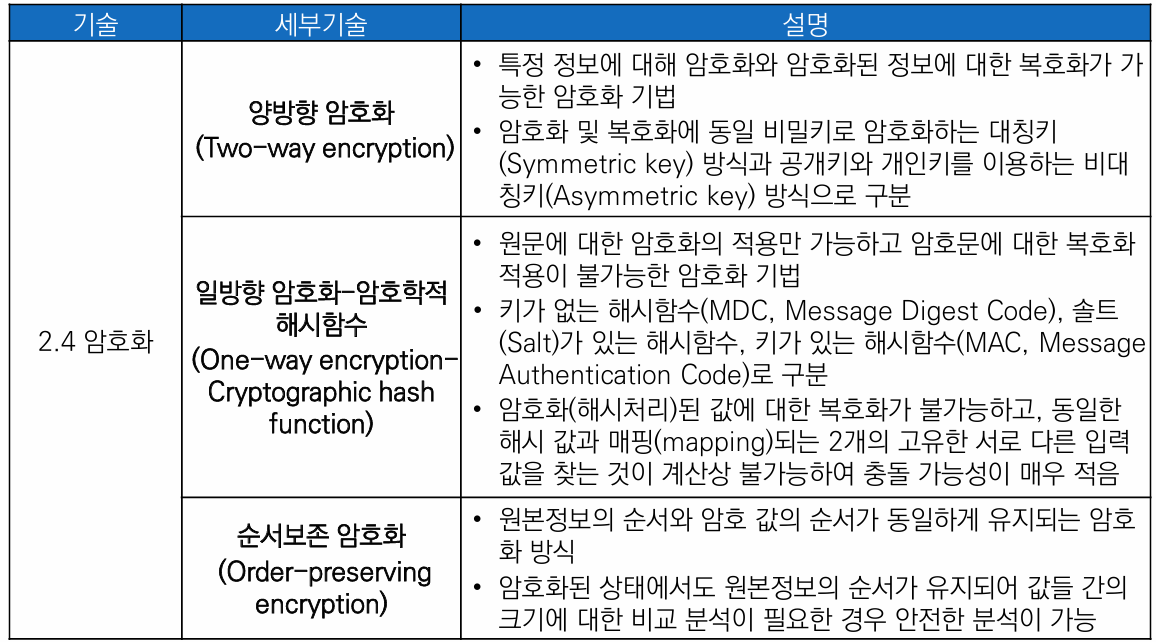
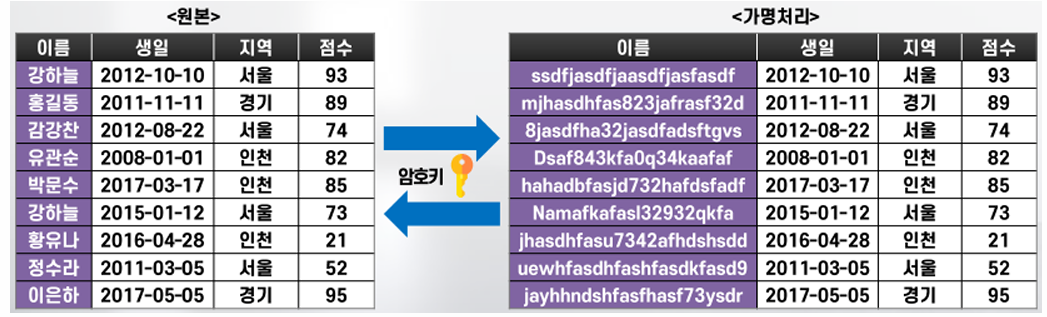
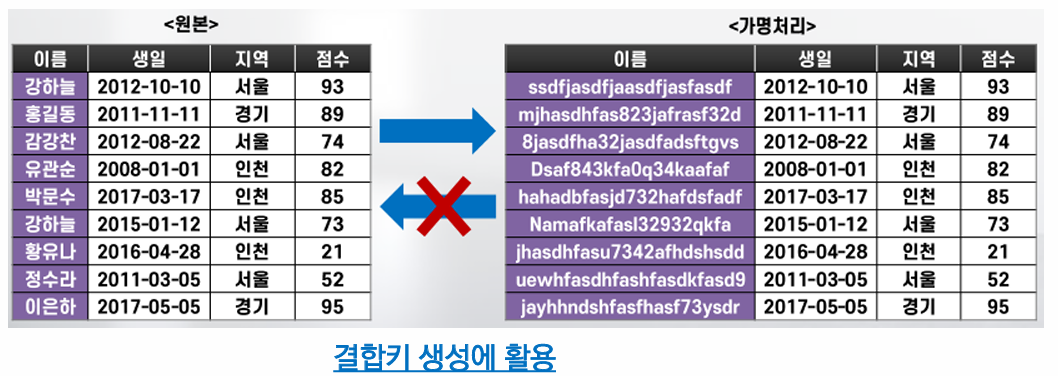
양방향 암호화 (Two-way encryption)
특정 정보에 대해 암호화와 암호화된 정보에 대한 복호화가 가능한 암호화 기법
암호화 및 복호화에 동일한 비밀키로 암호화하는 AES, ARIA 등 대칭키(Symmetric key) 방식과 공개키와 개인키를 이용하는 RSA 등 비대칭키(Asymmetric key) 방식으로 구분되며, 키(key) 관리에 주의 필요
일방향 암호화- 암호학적 해시함수(One-way encryption-Cryptographic hash function)
원문에 대한 암호화의 적용만 가능하고 암호문에 대한 복호화 적용이 불가능한 암호화 기법
키가 없는 해시함수(MDC, Message Digest Code), 키가 있는 해시함수(MAC, Message Authentication Code), 솔트(Salt)가 있는 해시함수로 구분
암호화(해시처리)된 값에 대한 복호화가 불가능하고, 동일한 해시 값과 매핑(mapping)되는 2개의 고유한 서로 다른 입력값을 찾는 것이 계산상 불가능하여 충돌 가능성이 매우 적음
순서보존 암호화(Order-preserving encryption)
원본정보의 순서와 암호값의 순서가 동일하게 유지되는 암호화 방식
암호화된 상태에서도 원본정보의 순서가 유지되어 값들 간의 크기에 대한 비교 분석이 필요한 경우 안전한 분석이 가능
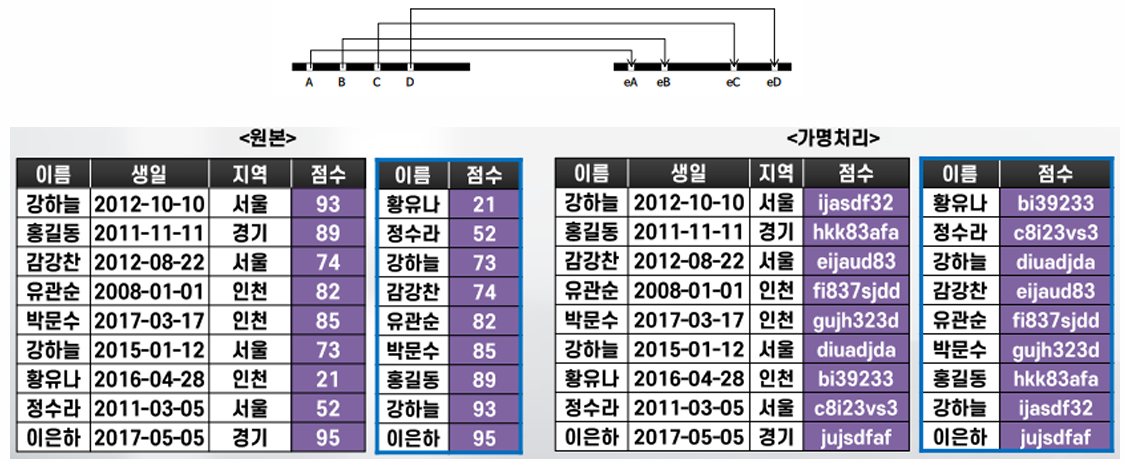
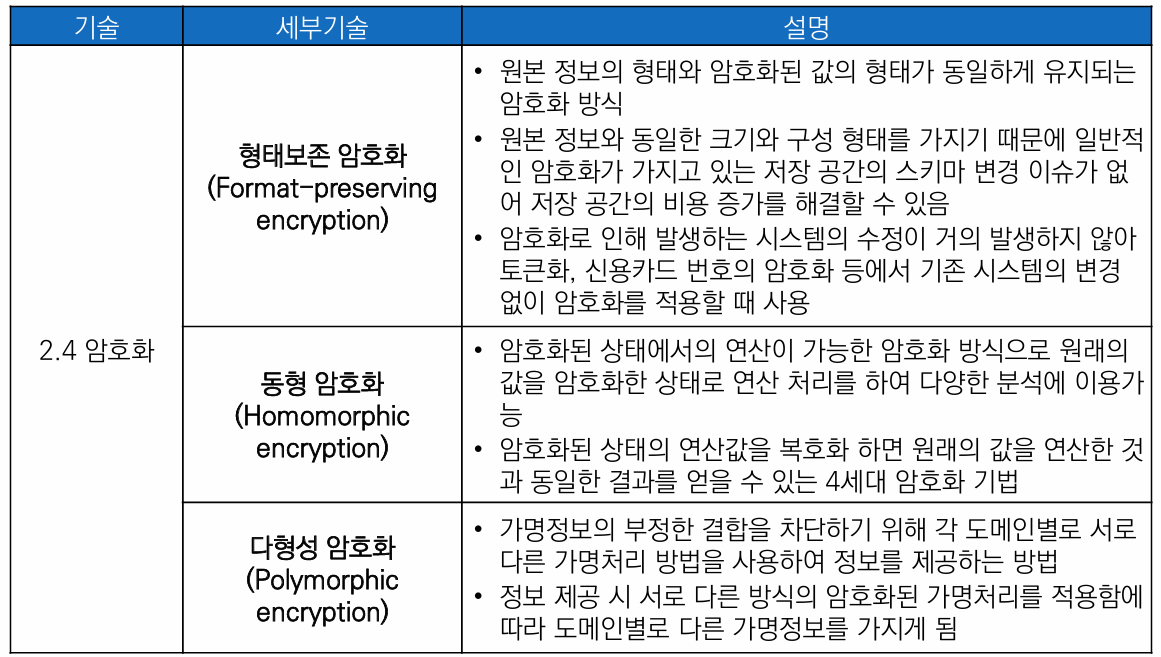
형태보존 암호화(Format-preserving encryption)
원본 정보의 형태와 암호화된 암호값의 형태가 동일하게 유지되는 암호화 방식
원본 정보와 동일한 크기와 구성 형태를 가지기 때문에 일반적인 암호화가 가지고 있는 저장 공간의 스키마 변경 이슈가 없어 저장 공간의 비용 증가를 해결할 수 있음
암호화로 인해 발생하는 시스템의 수정이 거의 발생하지 않아 토큰화, 신용카드 번호의 암호화 등에서 기존 시스템의 변경 없이 암호화를 적용할 때 사용
동형 암호화(Homomorphic encryption)
암호화된 상태에서의 연산이 가능한 암호화 방식
원래의 값을 암호화한 상태로 연산 처리를 하여 다양한 분석에 이용가능
암호화된 상태의 연산한 값을 복호화 하면 원래의 값을 연산한 것과 동일한 결과를 얻을 수 있는 4세대 암호화 기법
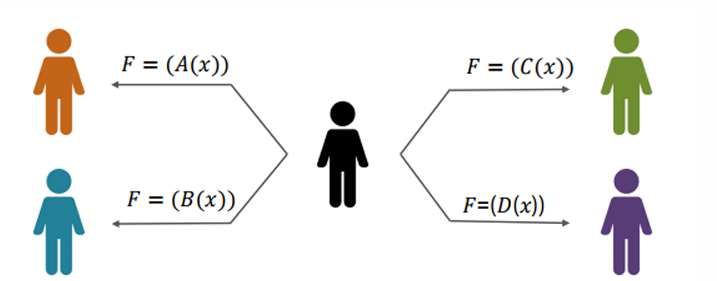
다형성 암호화(Polymorphic encryption)
가명정보의 부정한 결합을 차단하기 위해 각 도메인별로 서로 다른 가명처리 방법을 사용하여 정보를 제공하는 방법
정보 제공 시 서로 다른 방식의 암호화된 가명처리를 적용함에 따라 도메인별로 다른 가명정보를 가지게 됨
2-5. 무작위화기술 - 속성의 값을 원래의 값과 다르게 변경
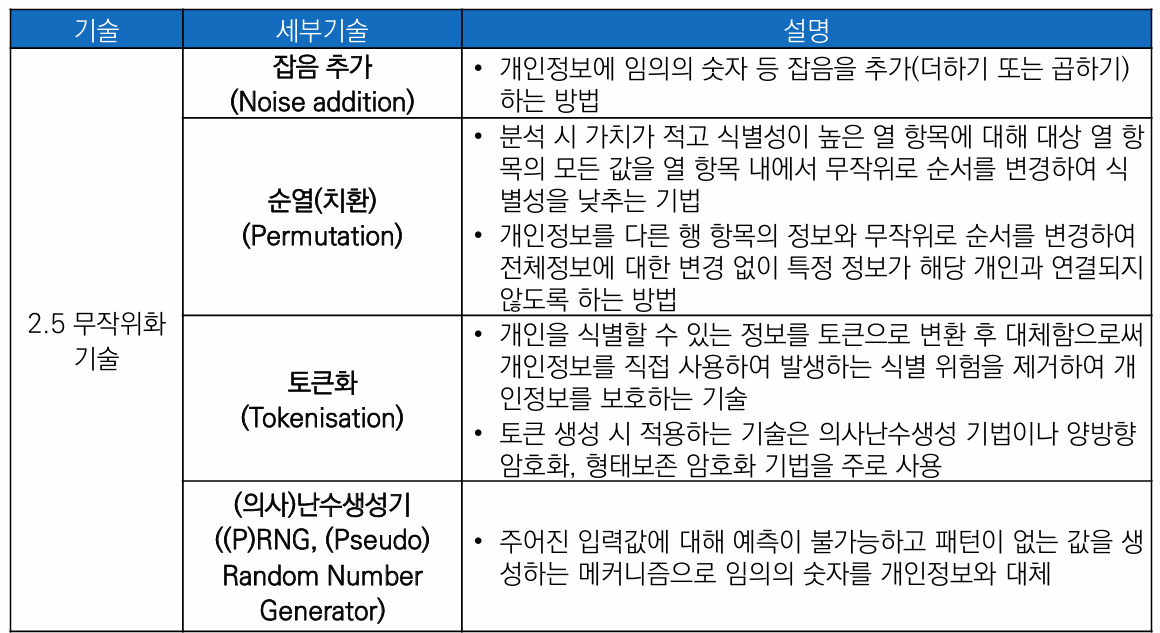
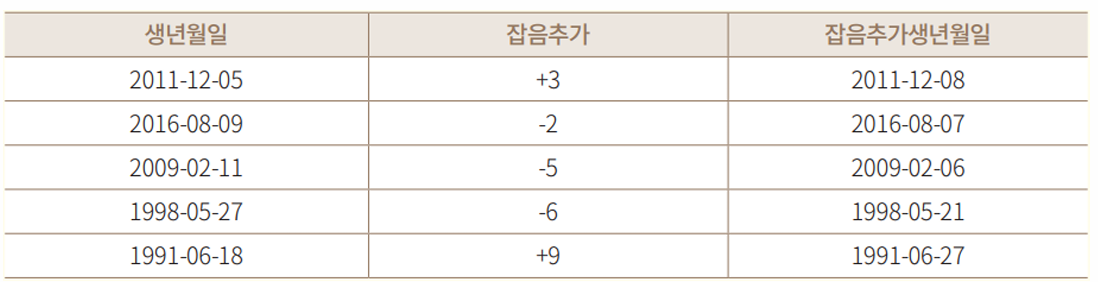
잡음 추가 (Noise addition)
개인정보에 임의의 숫자 등 잡음을 추가(더하기 또는 곱하기)하는 방법
지정된 평균과 분산의 범위 내에서 잡음이 추가되므로 원 자료의 유용성을 해치지 않으나, 잡음값은 데이터 값과는 무관하기 때문에 유효한 데이터로 활용하기 곤란하여 중요한 종적정보는 동일한 잡음을 사용해야
함
Ex. 입원 일자에 +3이라는 노이즈를 추가하는 경우 퇴원일자에도 +3이라는 노이즈를 부여해야 전체 입원 일수에 변화가 없음)
순열(치환) (Permutation)
기존 값은 유지하면서 개인이 식별되지 않도록 데이터를 재배열하는 방법
개인정보를 다른 행 항목의 정보와 무작위로 순서를 변경하여 전체정보에 대한 변경 없이 특정 정보가 해당 개인과 연결되지 않도록 하는 방법
💡 데이터의 훼손 정도가 매우 큰 기법으로 무작위로 순서를 변경하는 조건 선정에 주의 필요
토큰화 (Tokenisation)
개인을 식별할 수 있는 정보를 토큰으로 변환 후 대체함으로써 개인정보를 직접 사용하여 발생하는 개인에 대한 식별 위험을 제거하여 개인정보를 보호하는 기술
토큰 생성 시 적용하는 기술은 의사난수생성 기법이나 일방향 암호화, 순서보존 암호화 기법을 주로 사용
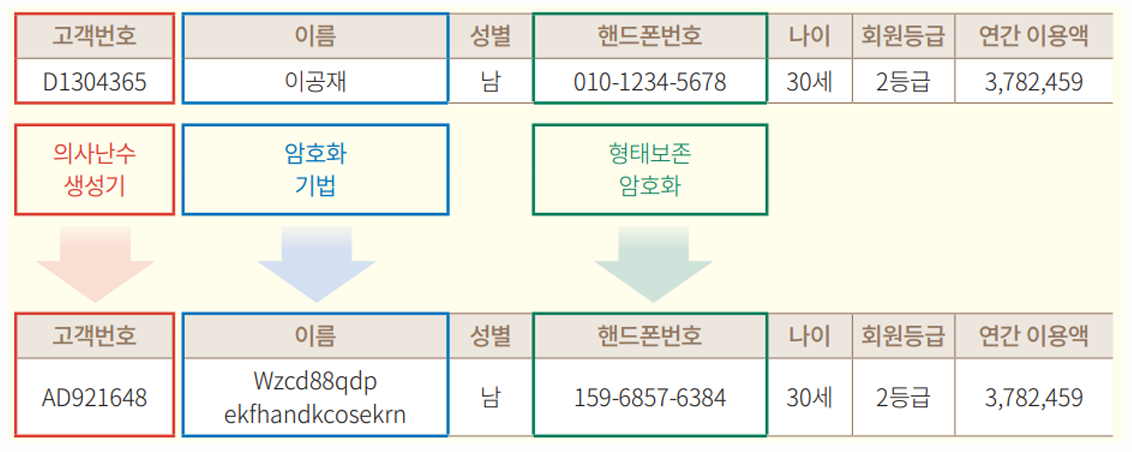
(의사)난수생성기 ((P)RNG, (Pseudo) Random Number Generator)
주어진 입력 값에 대해 예측이 불가능하고 패턴이 없는 값을 생성하는 메커니즘으로 임의의 숫자를 개인정보에 할당
💡 난수는 원칙적으로 규칙적인 배열순서가 없는 임의의 수를 의미하며 컴퓨터는 원천적으로 입력에 의한 처리 결과를 반환하는 것으로, 처리의 방법과 입력이 동일하면 항상 동일한 출력이 발생하기 때문에 완전한 난수의 생성은 불가능
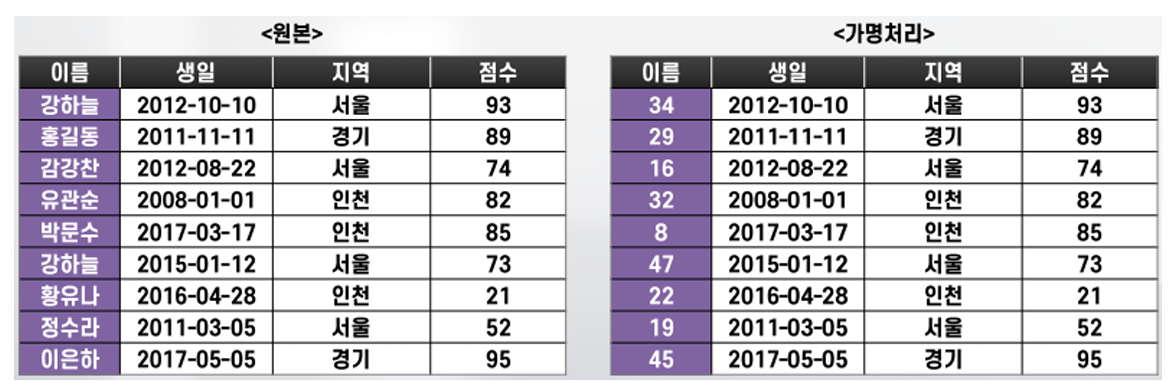
3. 가명·익명 처리를 위한 다양한 기술 (기타 기술)
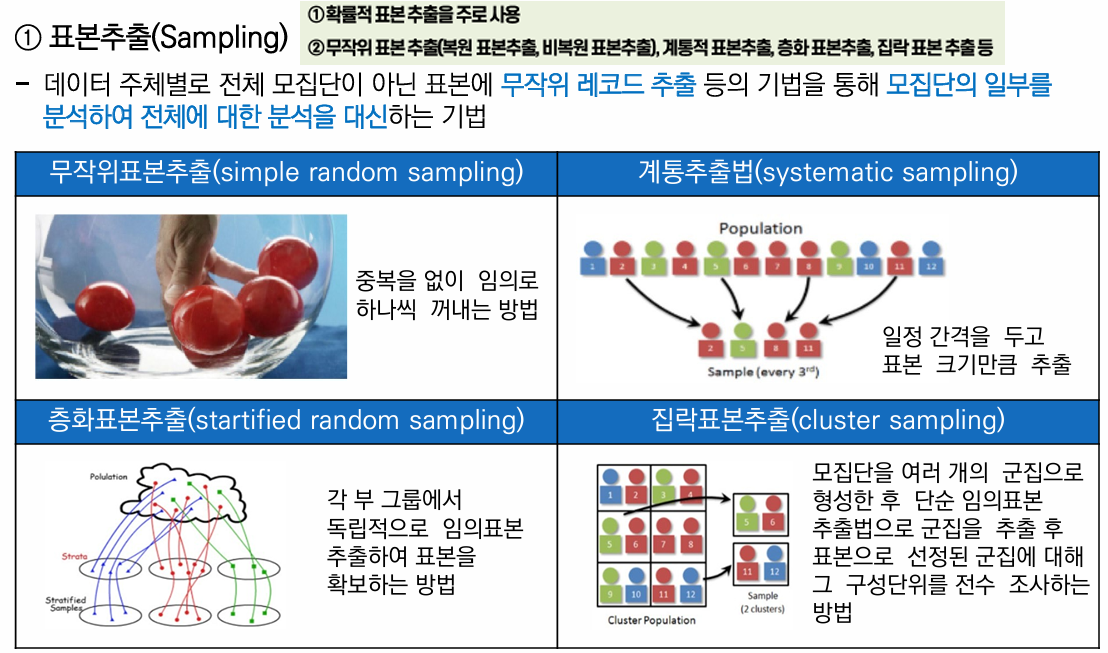
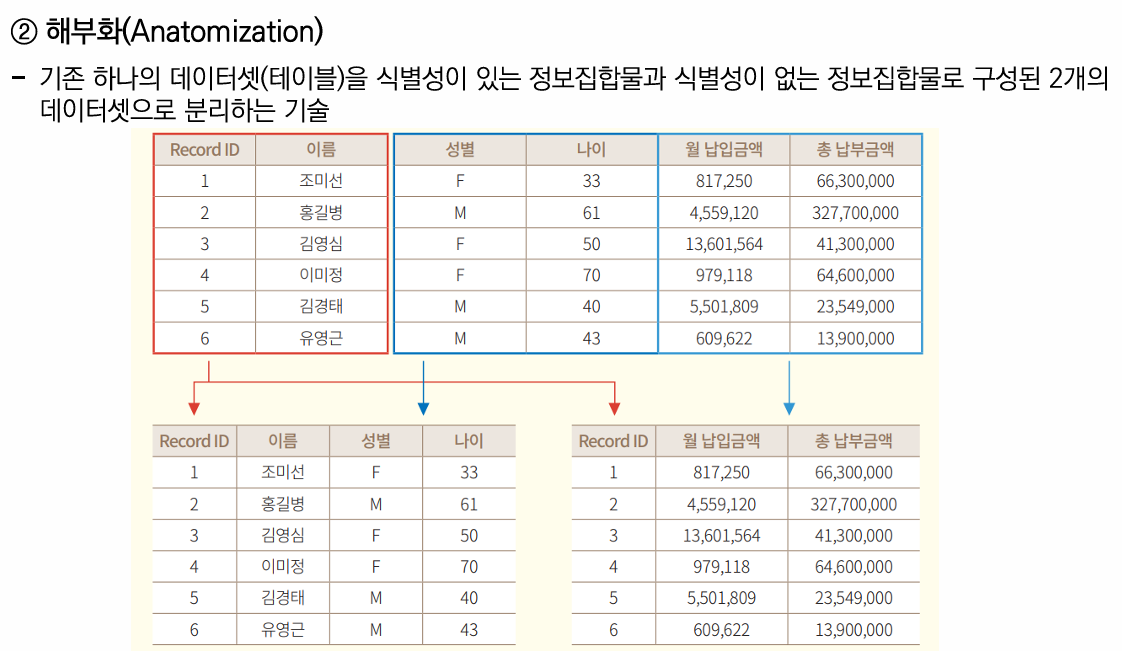
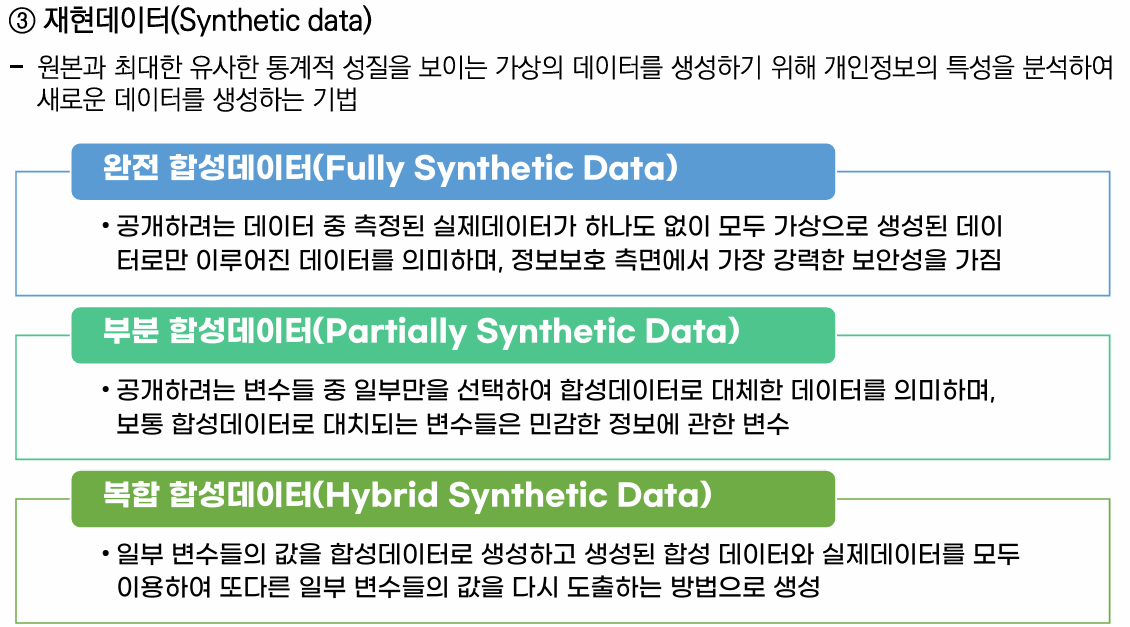
📌 가명처리 기법 실습
1. 엑셀을 이용한 가명처리
1. 통계처리

최대, 최소, 평균, 중앙값 구하기
최대값은 MAX 함수, 최소값은 MIN 함수, 평균은 AVERAGE 함수, 중앙값은 MEDIAN 함수로 구하며 이들 함수 이름 뒤에 IF, IFS를 붙인 MAXIFS, MINIFS, AVERAGEIF, AVERAGEIFS 함수는 조건을 만족하는 값을 구해줌

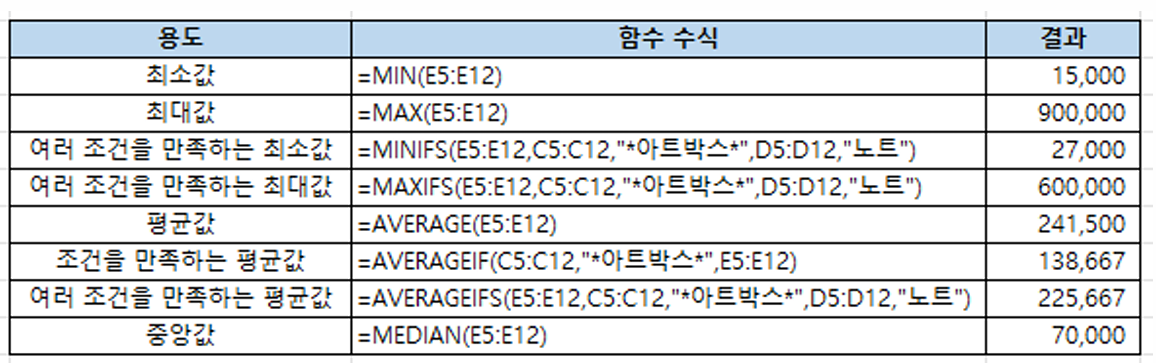
최빈값 구하기 (숫자만 가능)
엑셀의 MODE.SNGL 함수는 데이터 집합에서 최빈값(주어진 값 중에서 가장 자주 나오는 값)을 한 개만 구한다. 한 개만 구해준다고 하여 MODE 뒤에 Single을 줄인 SNGL이 붙어 있음
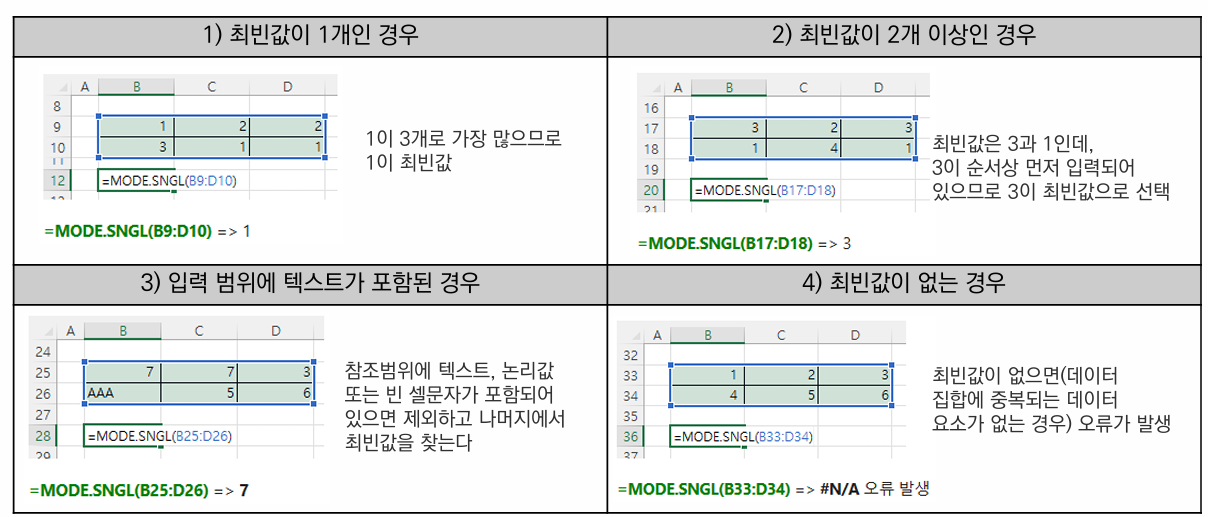
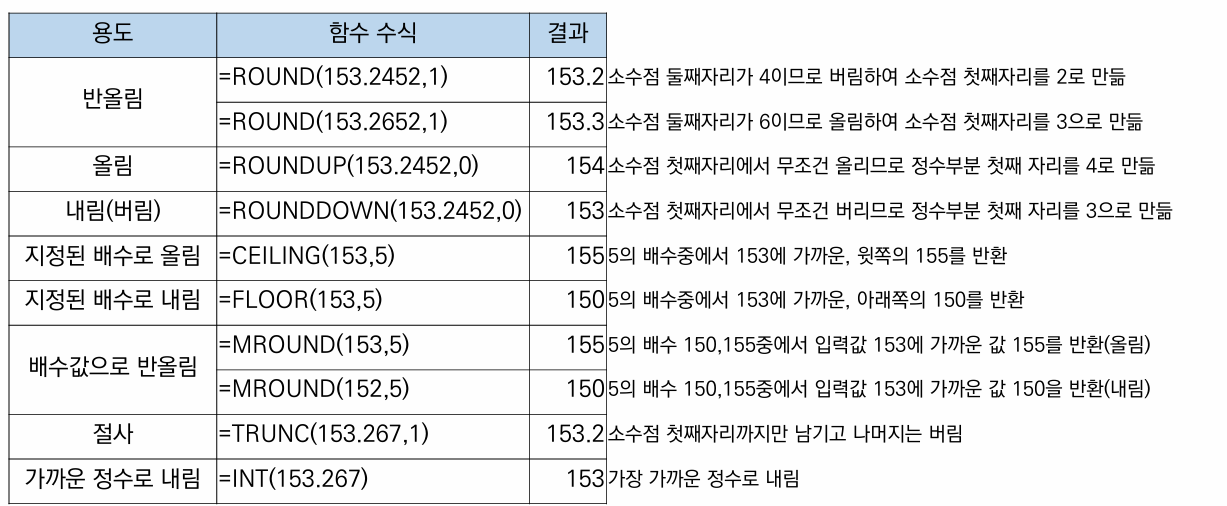
라운드 (반올림, 올림, 내림) 구하기
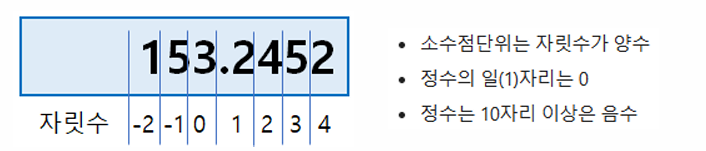
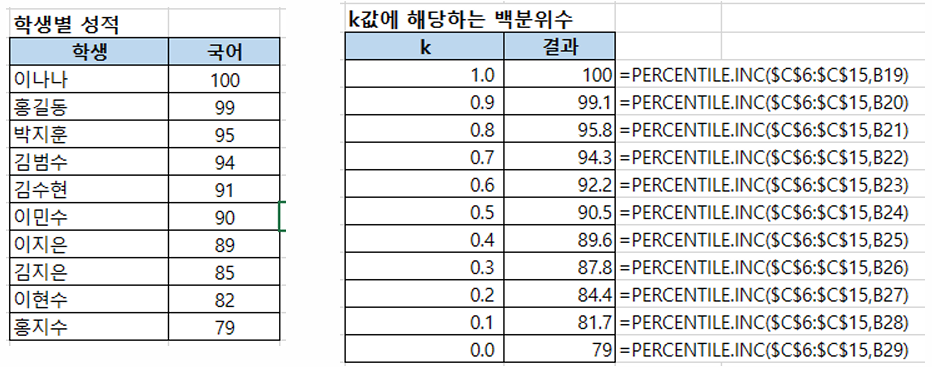
백분위수 값
PERCENTILE.EXC(array, k)
→ 데이터 범위에서 k값에 해당하는 백분위수(k값에서 O과 1은 제외된다)
PERCENTILE.INC(array, k)
→ 데이터 범위에서 k값에 해당하는 백분위수(k값에서 O과 1은 포함된다)
• array : 백분위를 구할 데이터 배열 또는 범위
• k: k 번째 백분위 수를 나타내는 숫자(k는 0에서 1 사이(0과 1 포함)의 값)
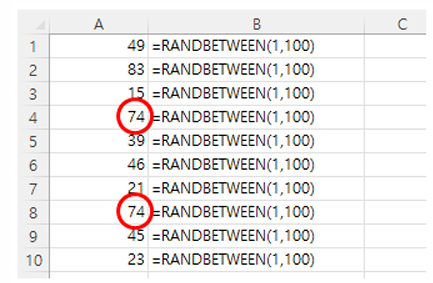
샘플링
RANDBETWEEN(bottom, top)
→ 숫자 사이의 정수·난수를 반환
INDEX(reference, row_num, [column_num], [area_num])
→ 참조영역에서 행과 열에 해당하는 값을 찾아줌
→ Ex. =INDEX(A2:O20, RANDBETWEEN(1,20), 1)
• reference : 값을 찾을 참조영역
• row_num : 값이 위치한 행번호
• column_num : (생략가능)값이 위치한 열번호
• area_num : (생략가능)값이 위치한 범위의 번호, 생략시 1이 기본값으로 사용
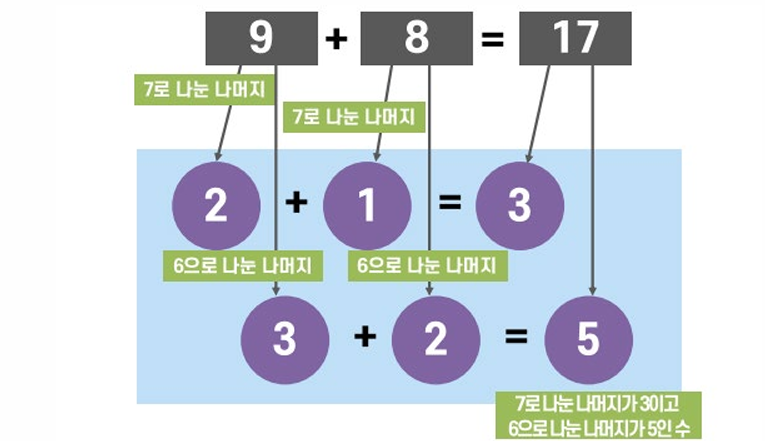
몫, 나머지 구하기
QUOTIENT(numerator, denominator)
→ 나눗셈의 몫을 반환
• numerator : 나눗셈에서 분자
• denominator: 나눗셈에서 분모

MOD(number, divisor)
→ 나눗셈의 나머지를 반환
• number : 나늣셈에서 분자
• divisor: 나눗셈에서 분모

2. 문자처리

3. 사용자 정의 (Macro 정의)

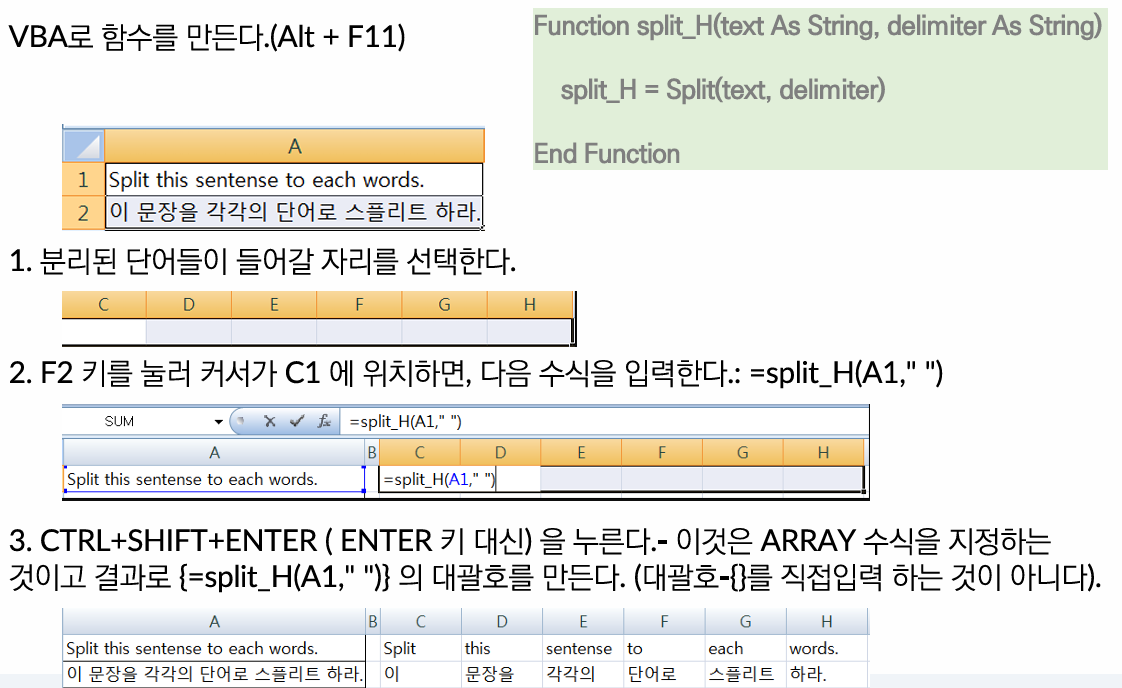
3-1. 구분자 분리
참고
https://developeryou.blogspot.com/2015/08/split.html
4. 기타
2. 시나리오 소개 및 가명처리 실습
① 시나리오 소개
분야
통신
형태
내부이용
시나리오 내용
(배경) A통신사의 B팀이 보유한 고객의 통신상품 이용현황(2018년 ~ 2022년)을 분석하여 A통신사의 C팀이 통신상품을 고도화하고자 함
(수행내용) C팀의 활용 목적에 맞게 가명처리하고 활용하고자 함
(제공자료) 데이터셋, 가명처리 관련 템플릿 양식
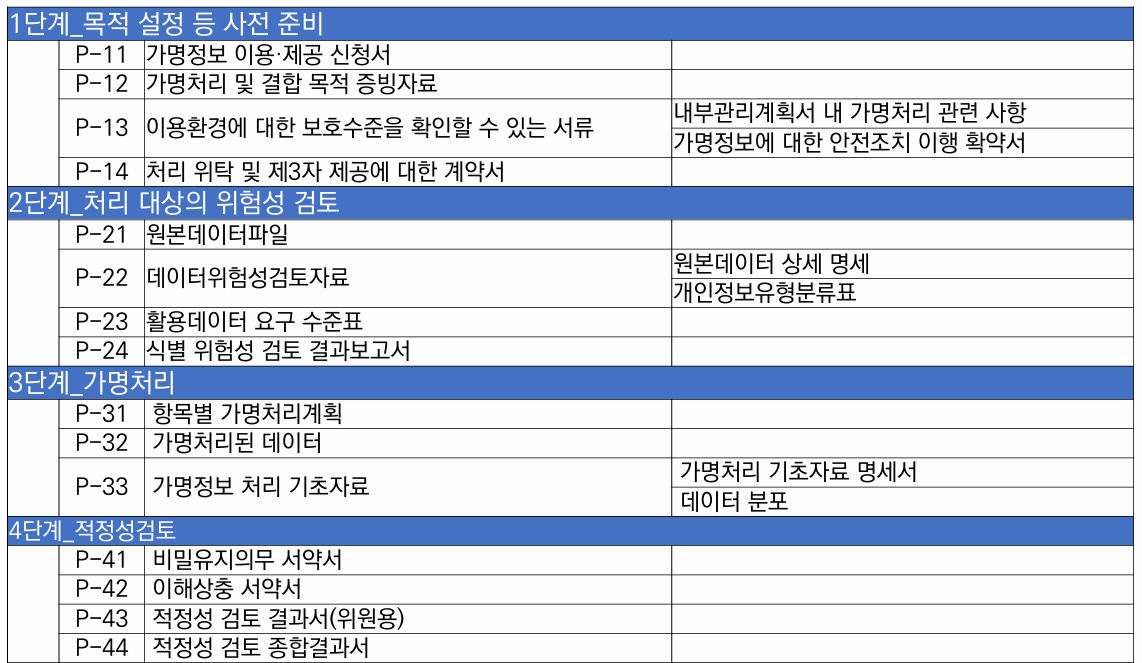
② 가명처리 관련 서류 (참고자료 제공)
③ 제공 데이터 소개
④ 적정성 검토 기준 실습
위험성 검토
원본 데이터를 대상으로 개인정보 유형, 속성, 특이정보 관찰
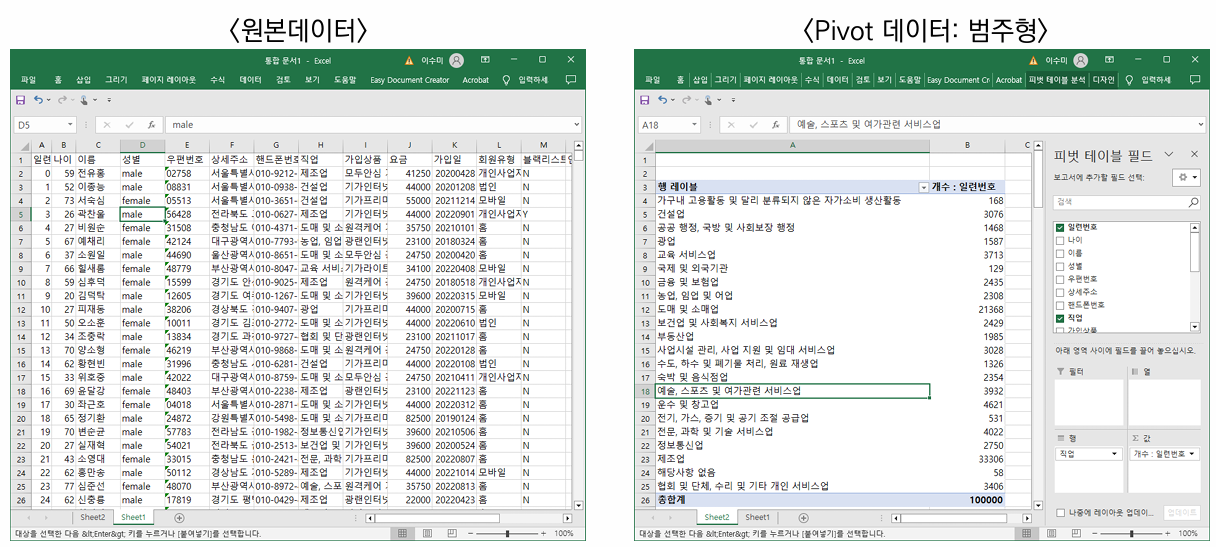
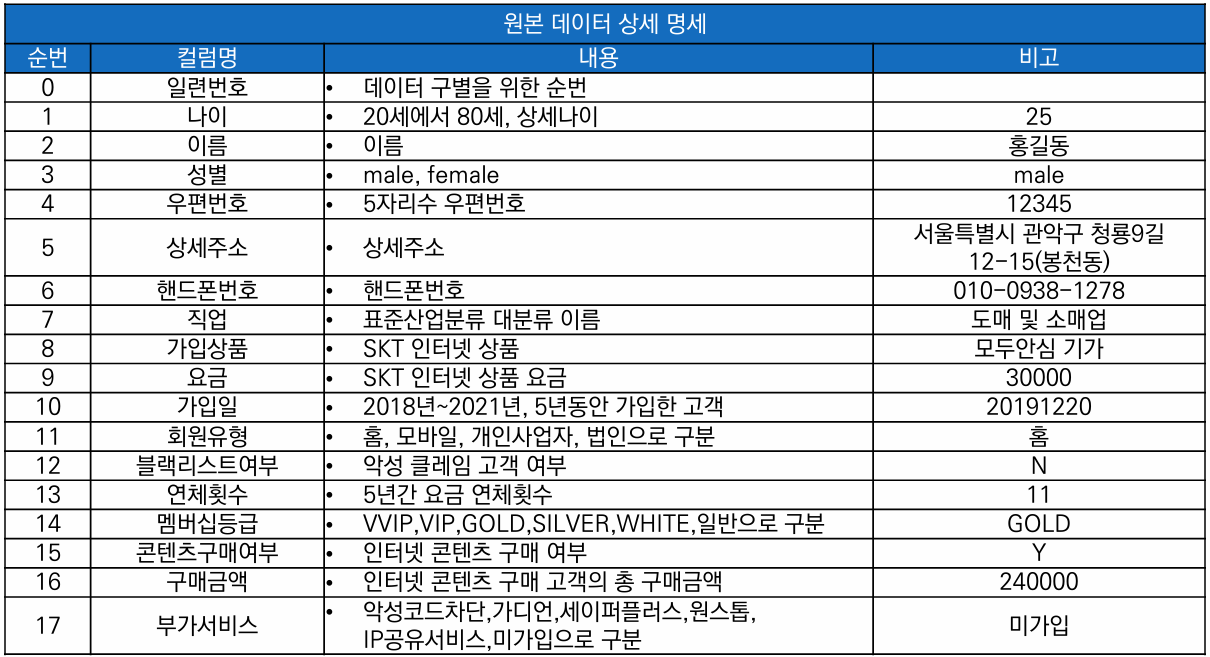
원본 데이터 상세 명세와 개인정보 유형 분류표 작성

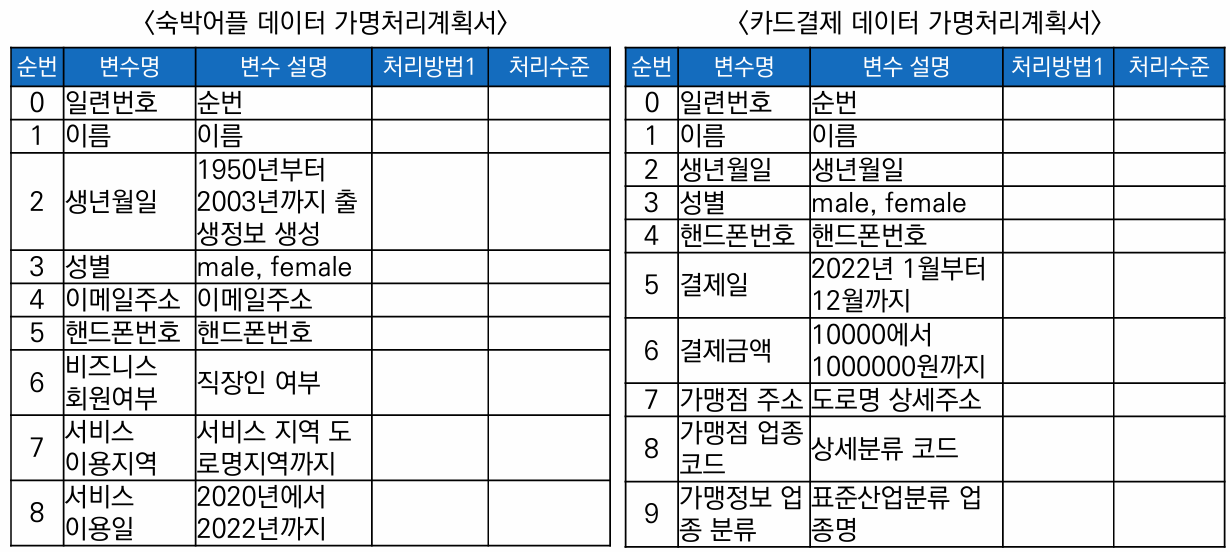
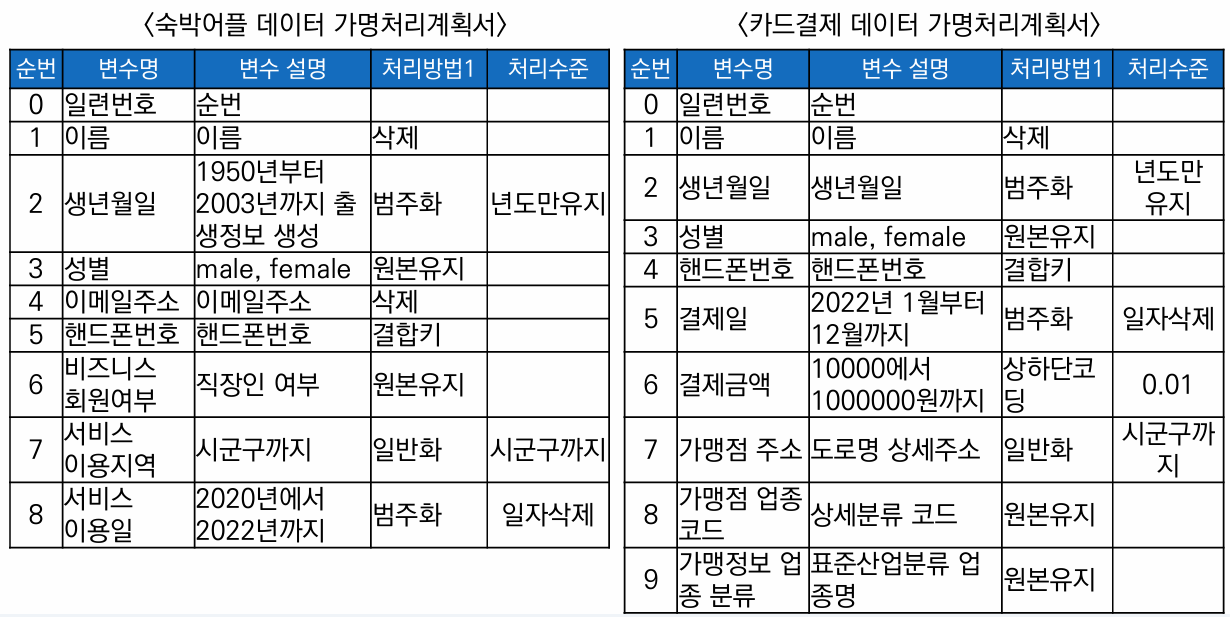
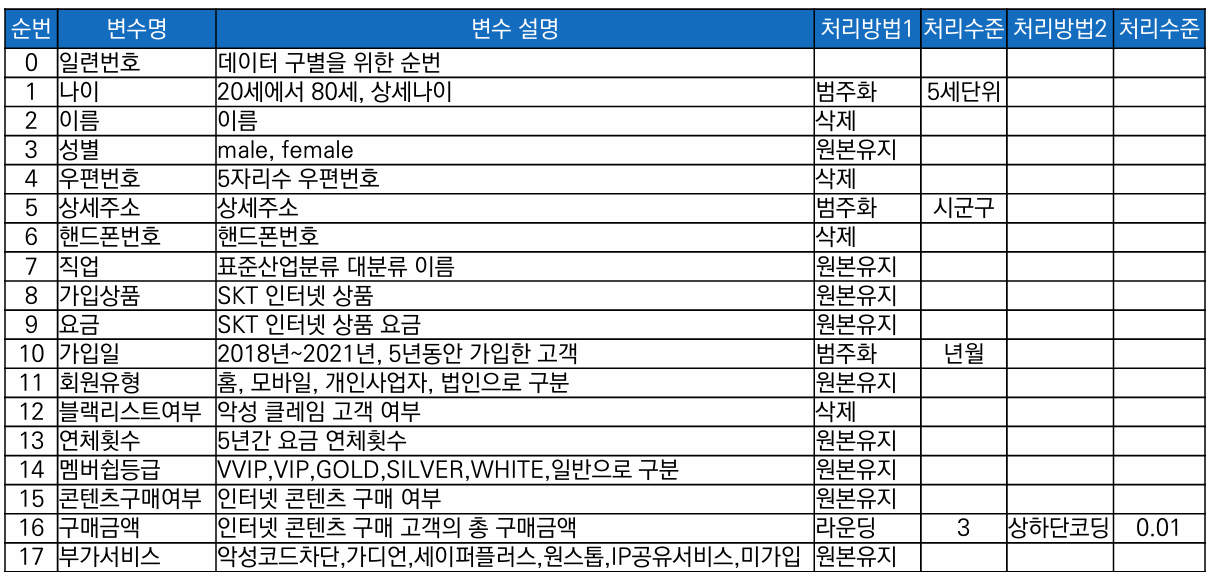
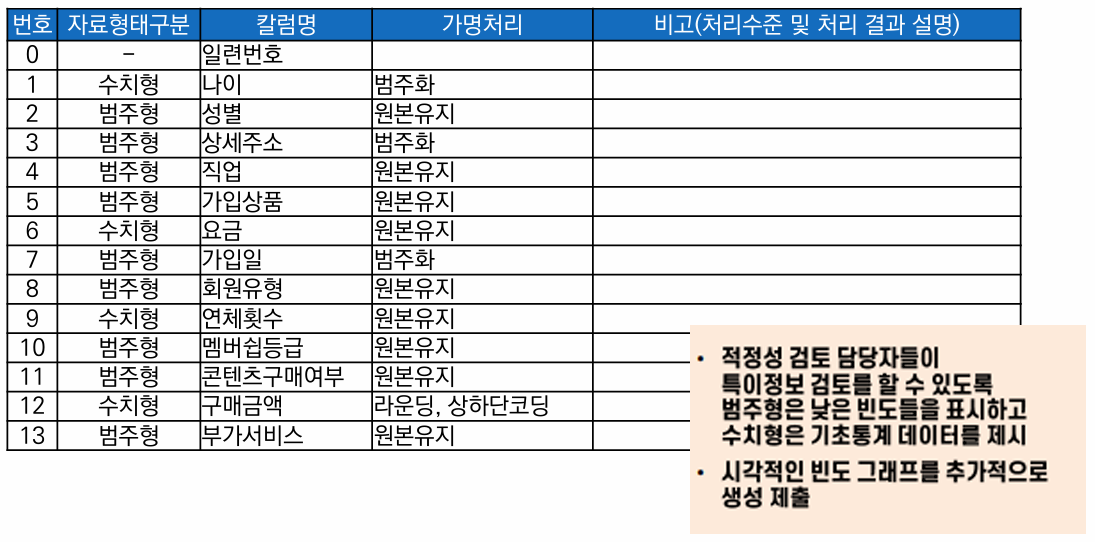
항목 별 가명처리 계획서
위험성 검토, 요구사항 수준 등을 검토하고 처리 목적에 적합한 가명처리 수준을 계획하고 처리
가명처리
적정성 검토에 필요한 가명정보 처리 기초자료 명세서 작성
3. 가명정보 결합 실습
시나리오 소개

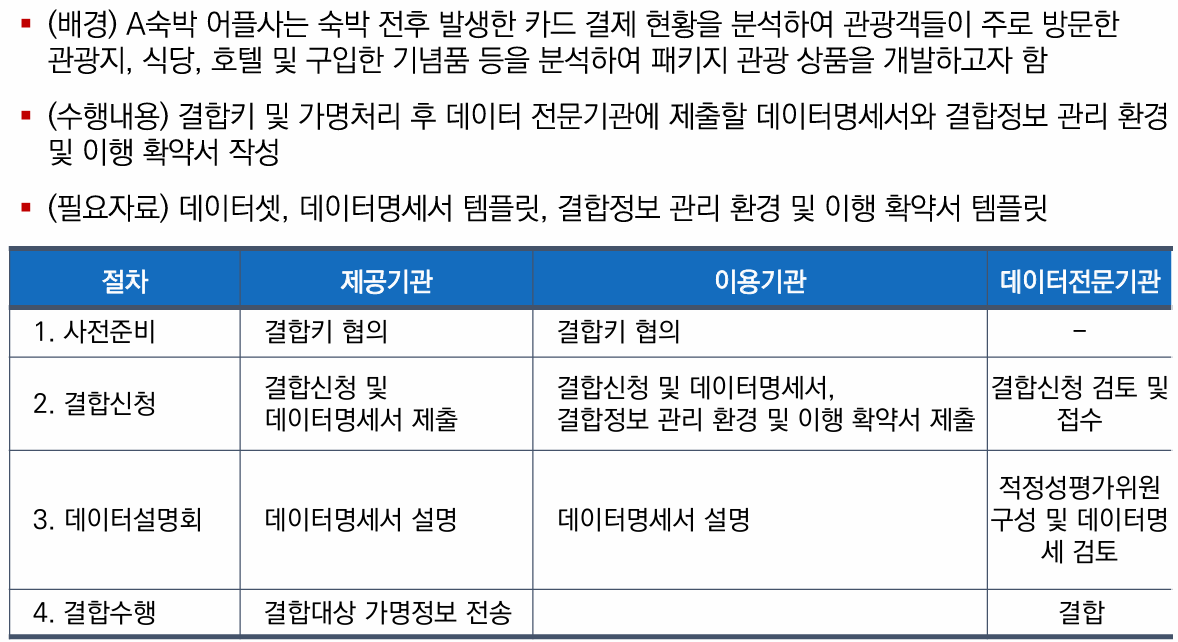
가명 처리 및 결합
아래와 같이 가명처리를 수행 및 결합하시오.