
📌 문서 색인
PUT <index_name>/_doc/<_id>
{
<document>
}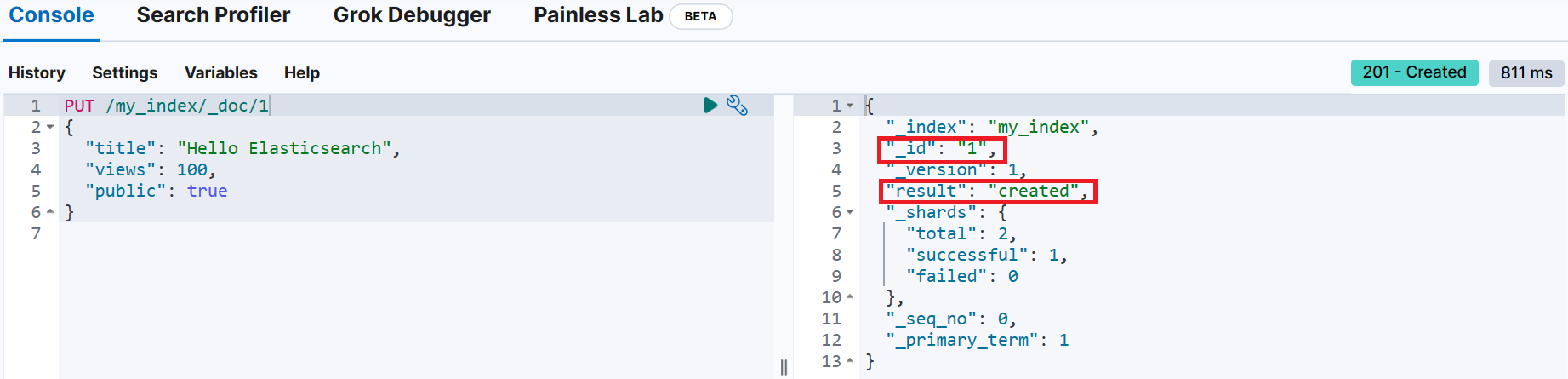
PUT /my_index/_doc/1
{
"title": "Hello Elasticsearch",
"views": 100,
"public": true
}📌 _id를 지정하지 않고 색인
POST <index_name>/_doc
{
<document>
}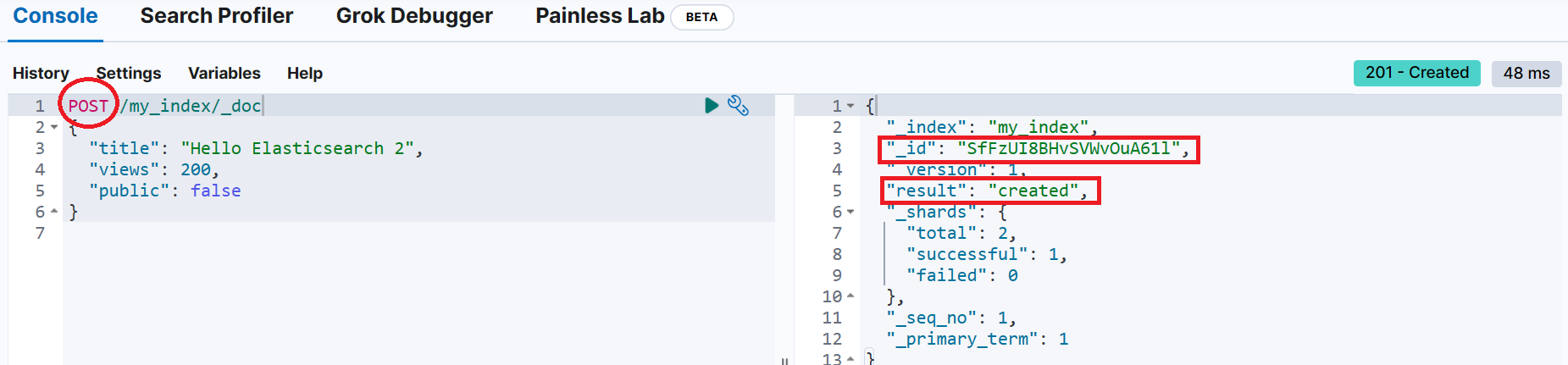
POST /my_index/_doc
{
"title": "Hello Elasticsearch 2",
"views": 200,
"public": false
}📌 문서 조회
GET <index_name>/_doc/<_id>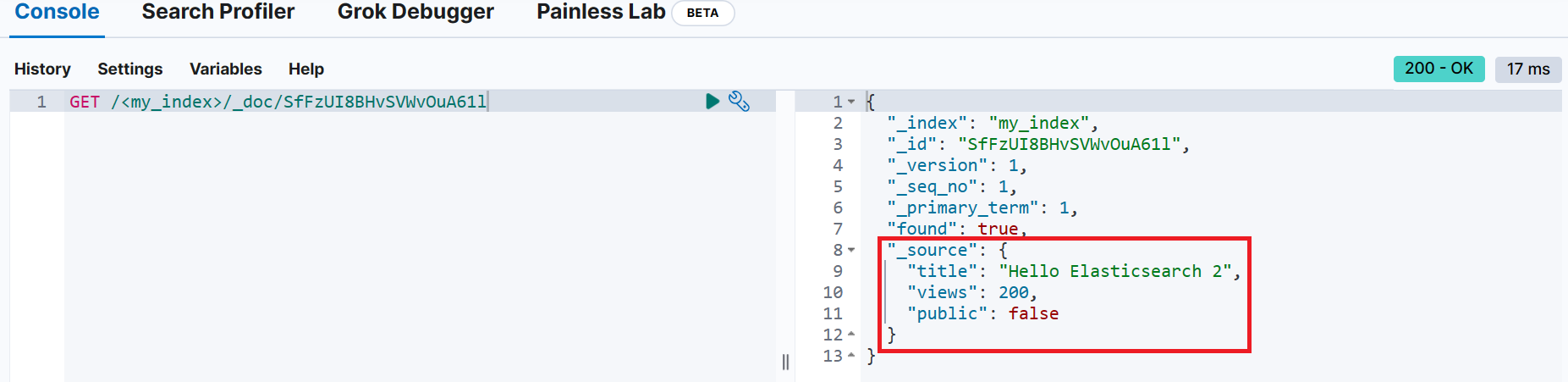
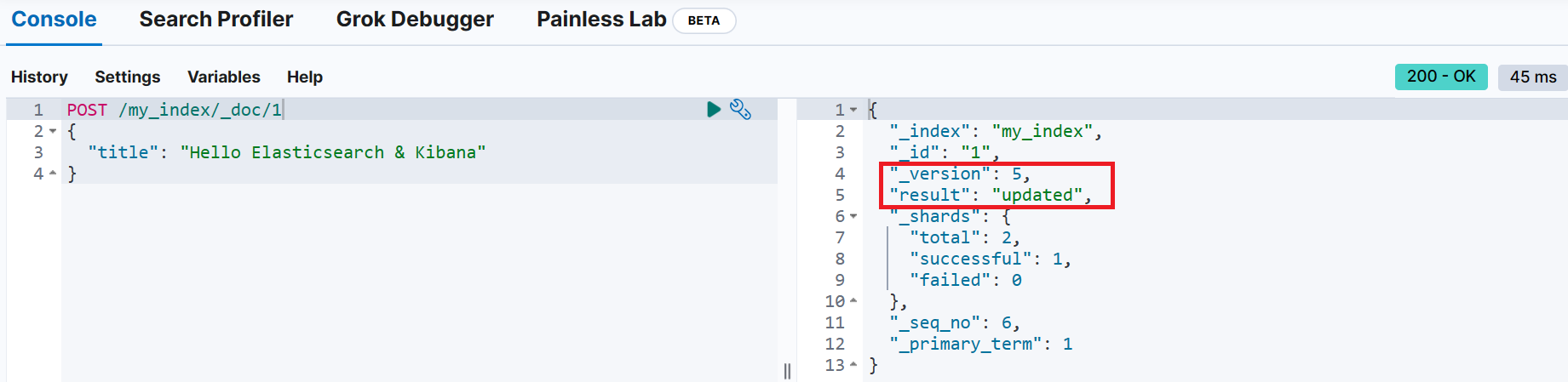
📌 문서 업데이트
POST <index-name>/_doc/<_id>
{
<변경할 내용>
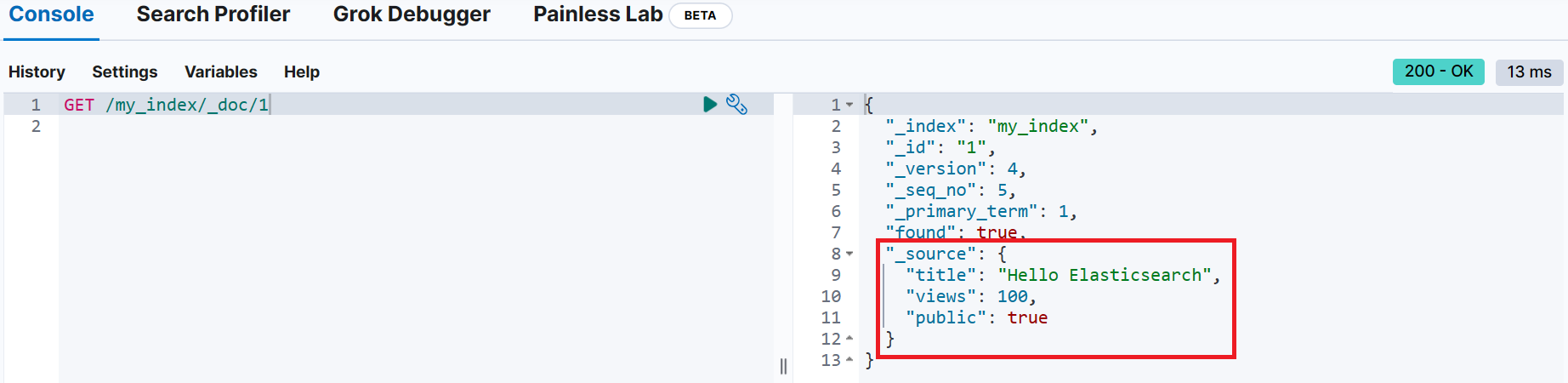
}업데이트 전 _id가 1인 문서 조회
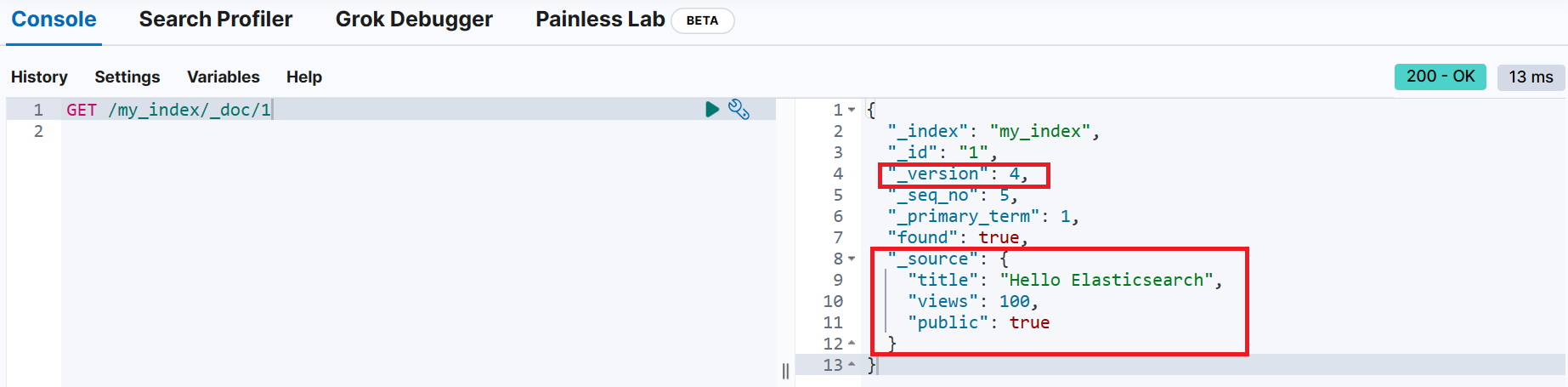
업데이트 성공 시 _version이 증가한 것을 확인
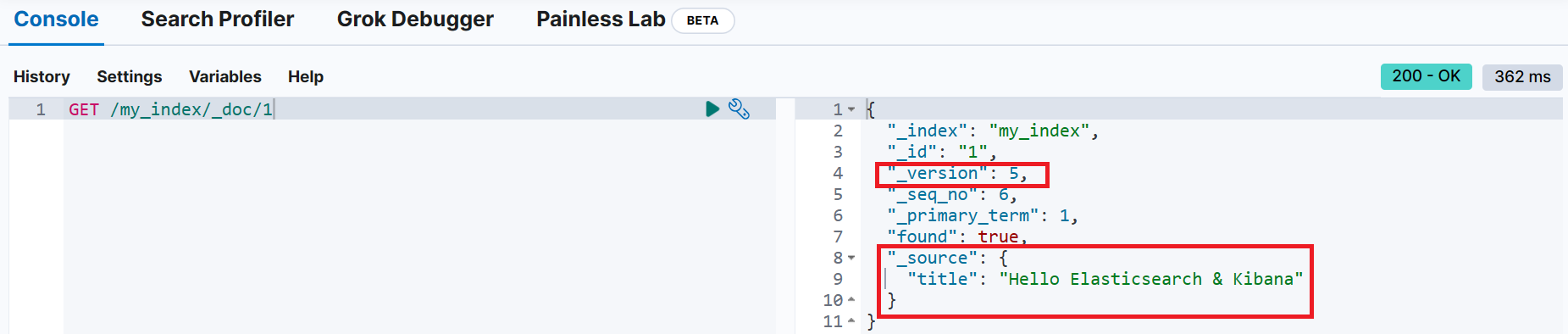
_id가 1인 문서를 조회해 보면 문서의 내용이 모두 바뀐 것을 확인 (views, public 항목이 사라지고, title 항목만 존재)
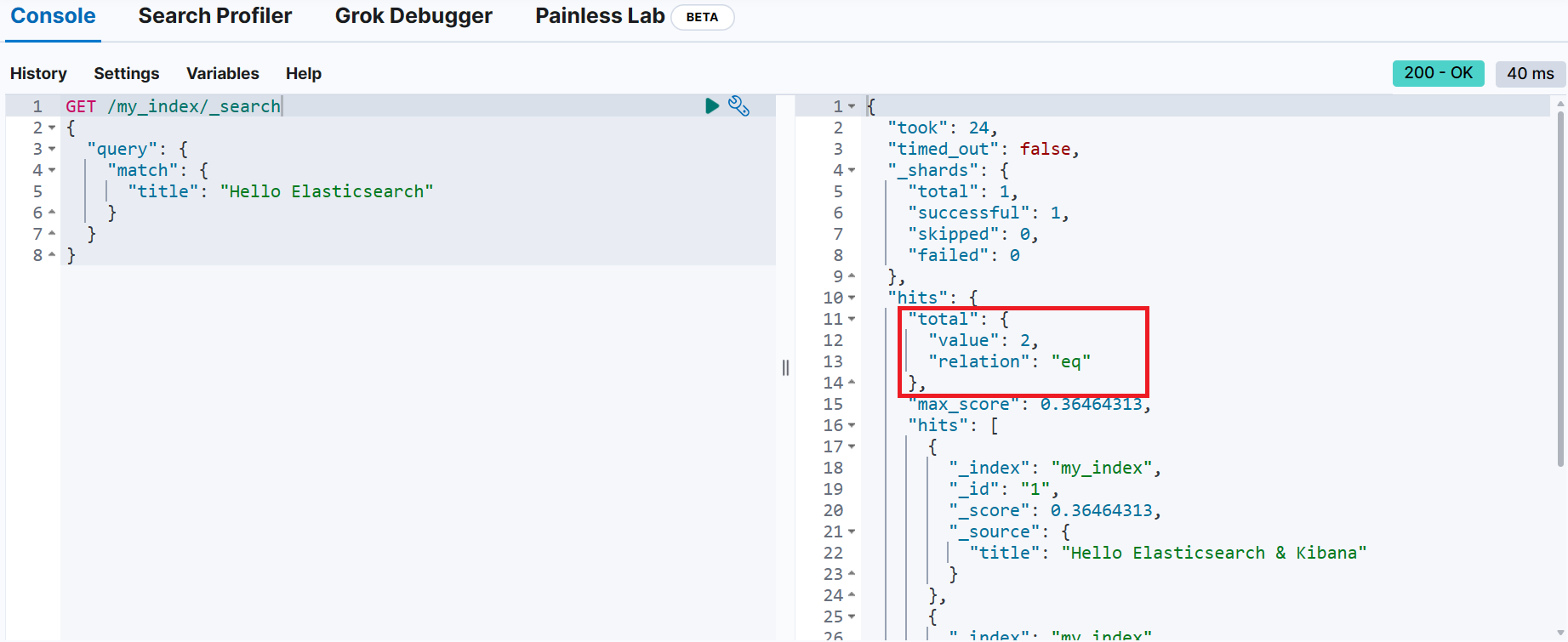
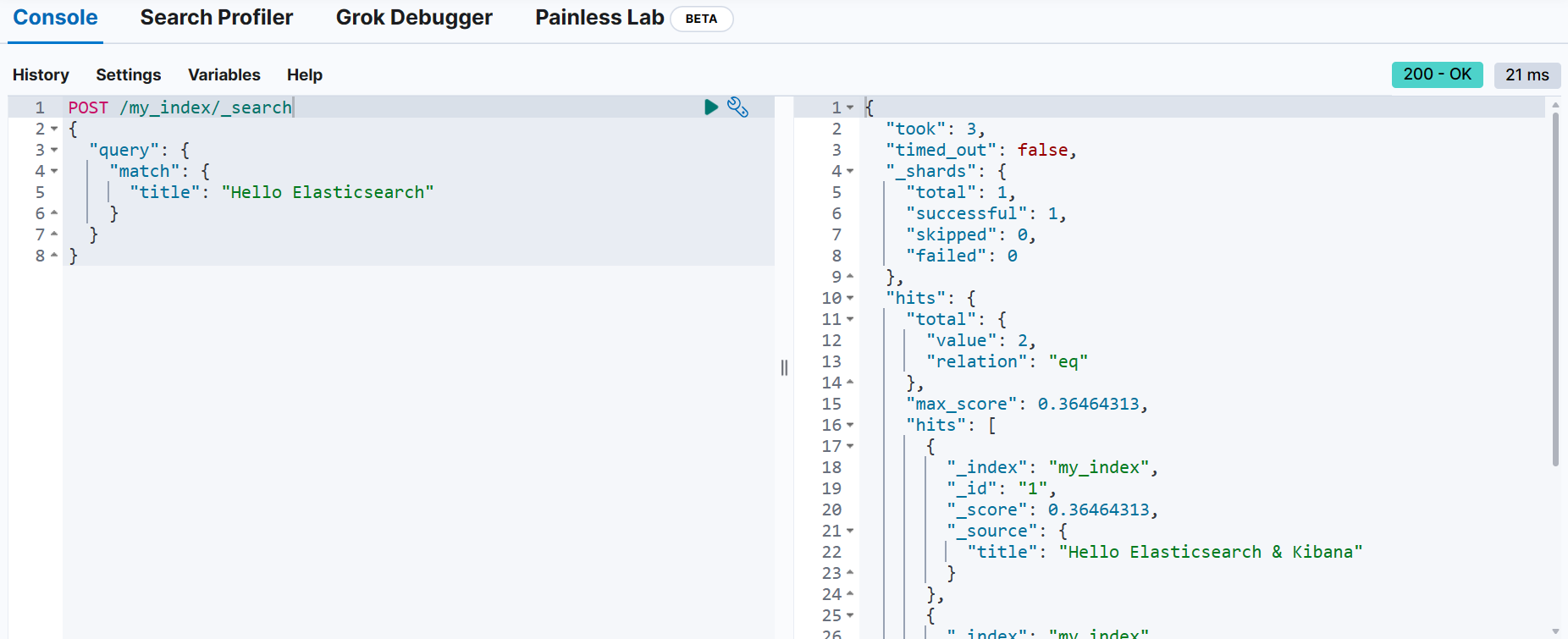
📌 문서 검색
GET/POST <index-name>/_search
{
"query": {
...
}
}
📌 문서 삭제
DELETE <index_name>/_id/<_id>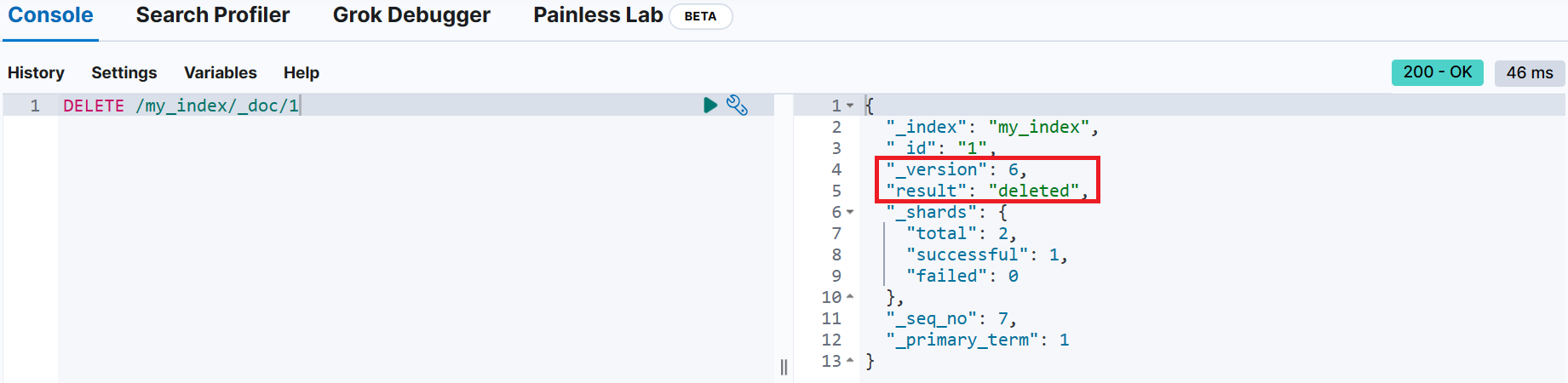

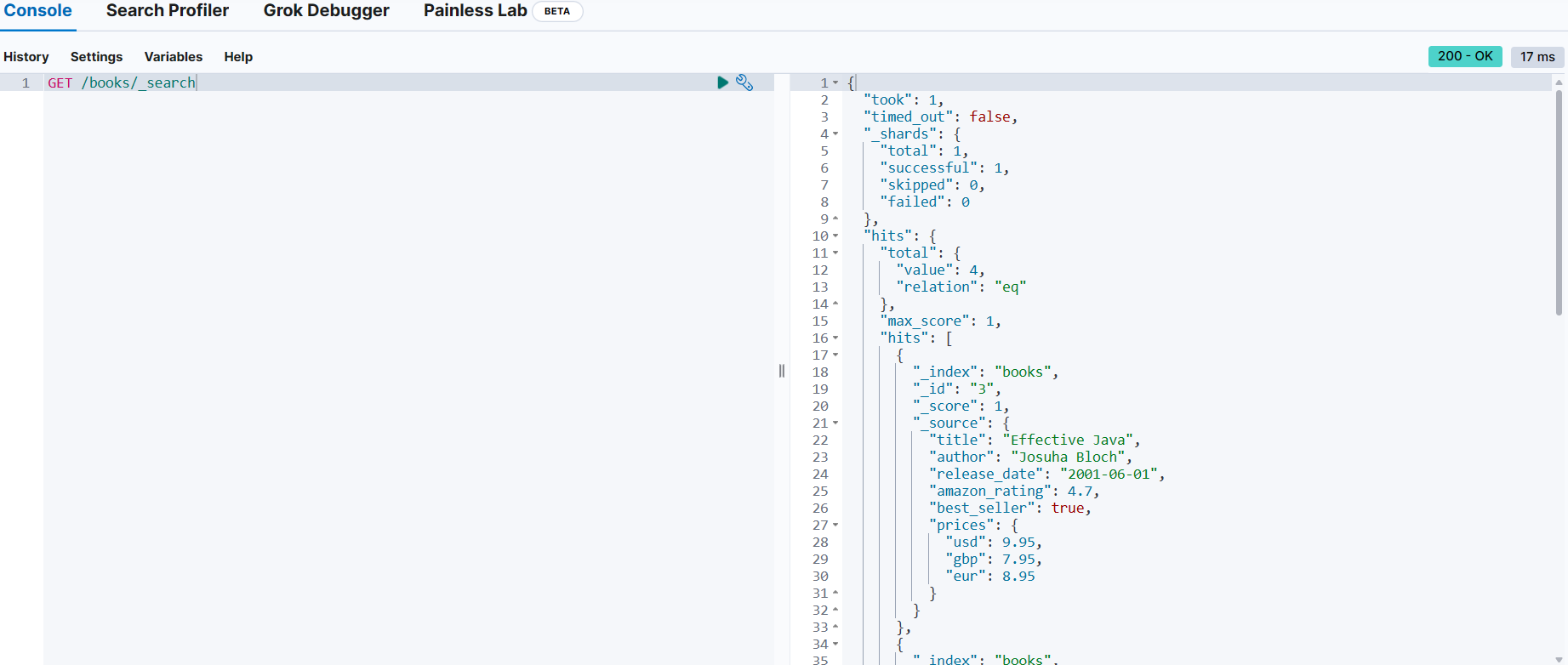
📌 _count : 해당 인덱스에 속하는 문서의 수

📌 복합 쿼리
bool 쿼리
must 절
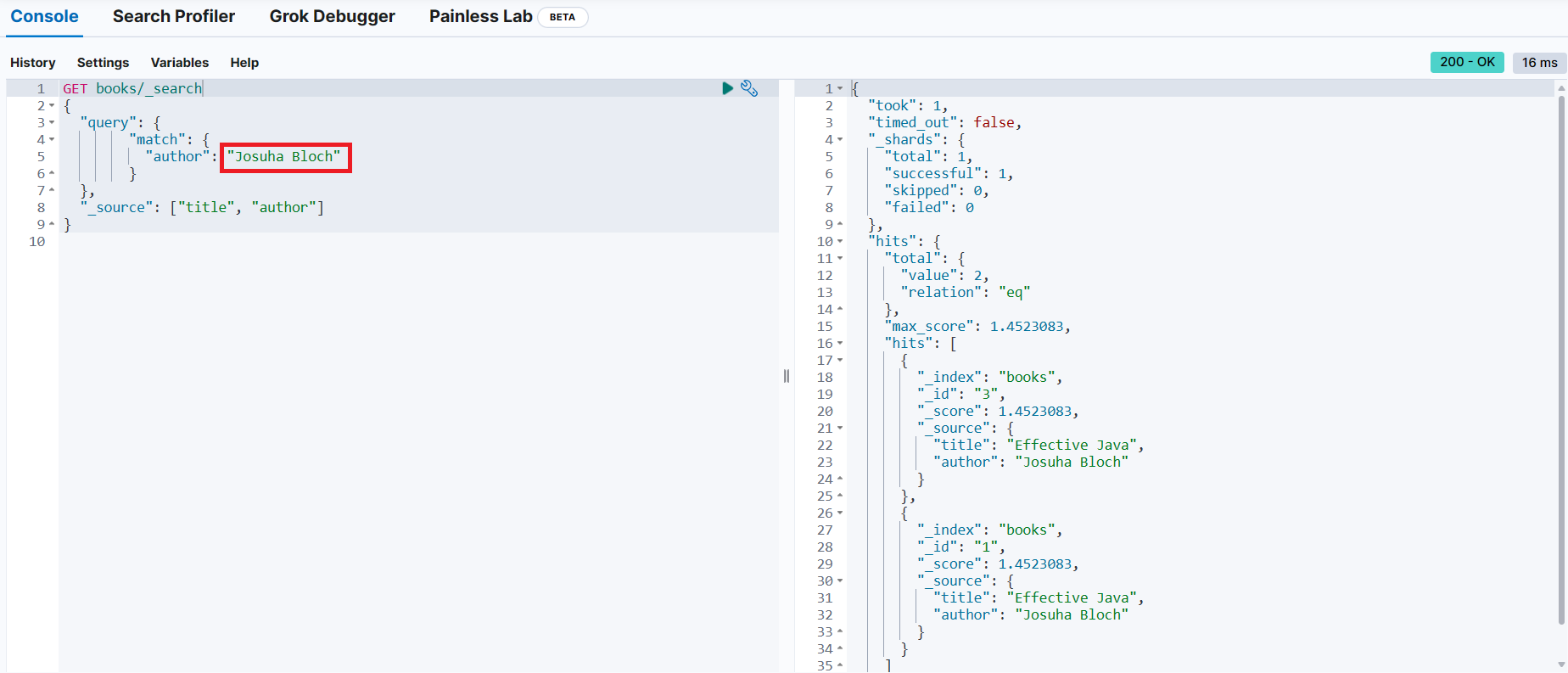
books 인덱스에서 저자가 Joshua Bloch인 도서(문서) 검색
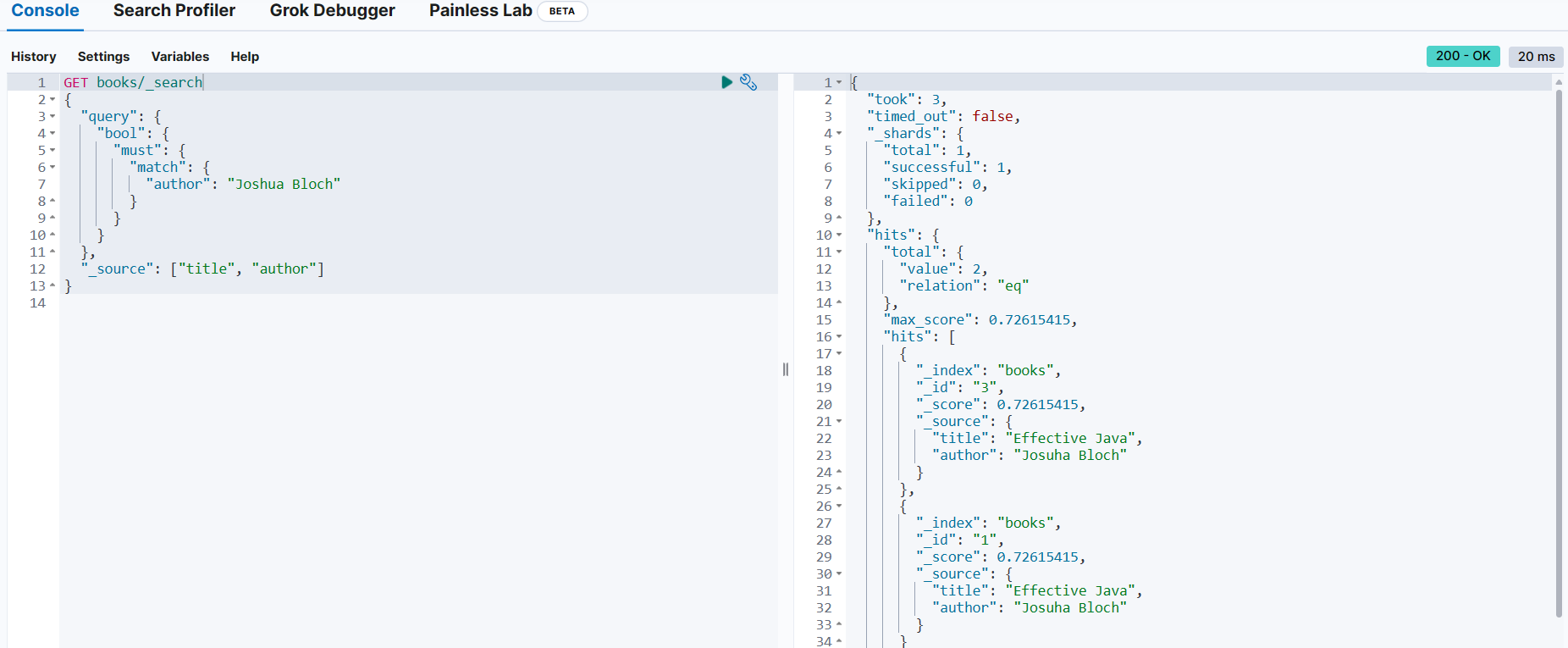
GET books/_search
{
"query": {
# 부울 쿼리
"bool": {
# must 절 → 문서가 기준과 일치해야 함
"must": {
# match 쿼리 → Joshua Bloch가 쓴 책과 일치하는 쿼리
"match": {
"author": "Joshua Bloch"
}
}
}
},
"_source": ["title", "author"]
}동일한 기능을 match 쿼리로 변경
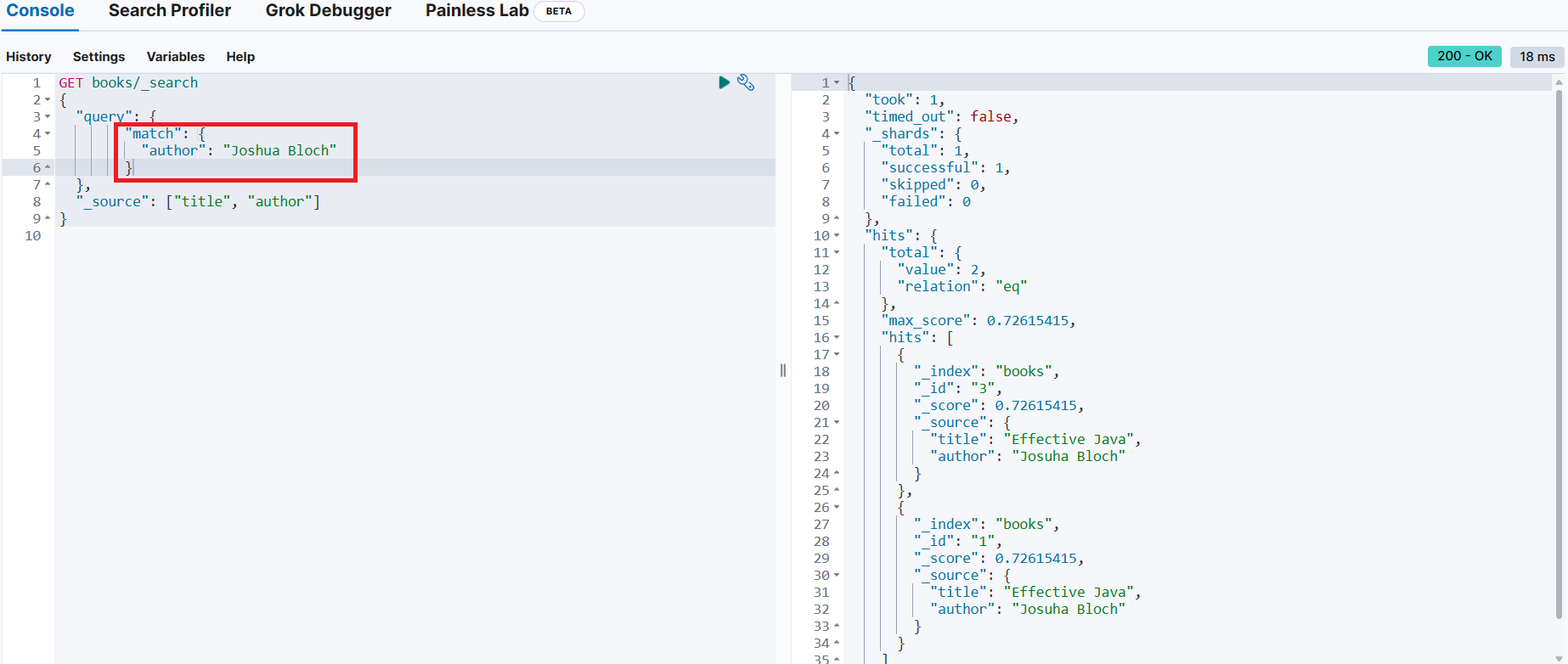
검색어(저자 이름)의 순서가 달라도 검색이 가능
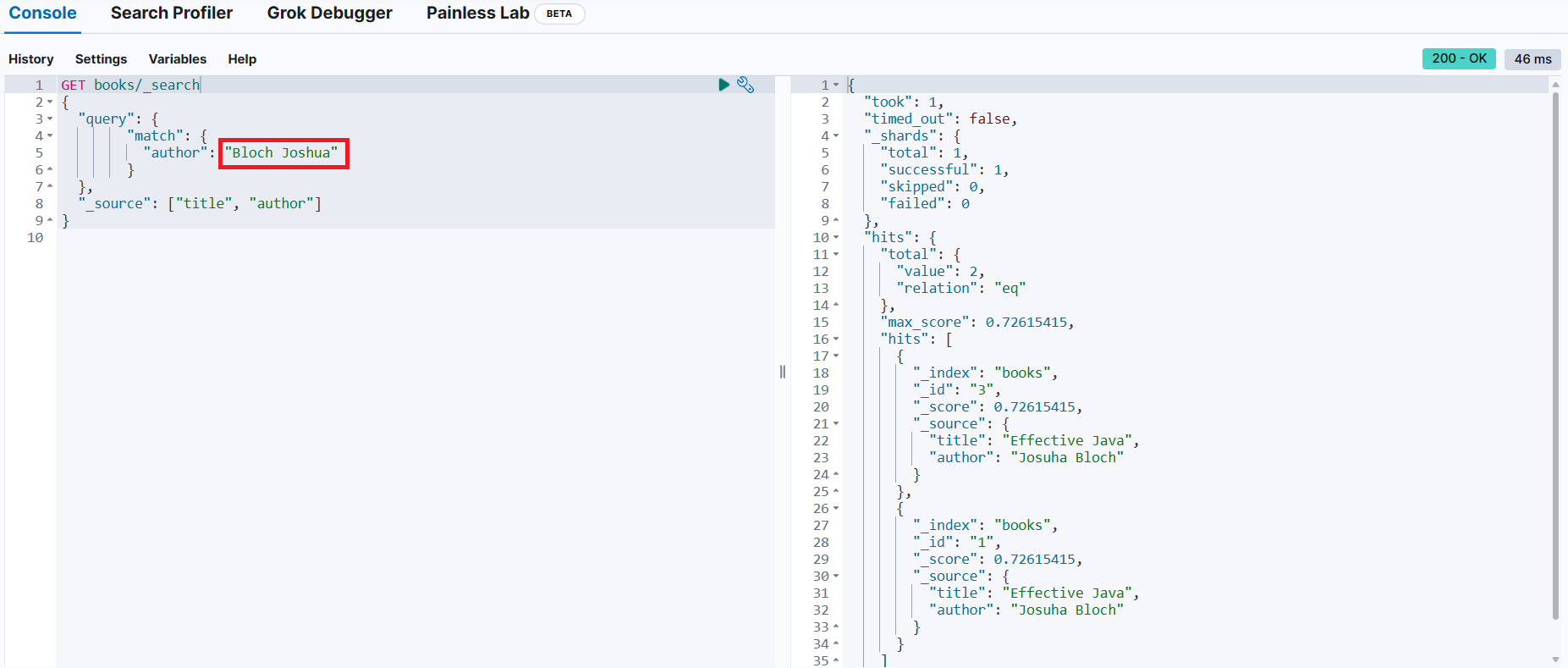
match_phase 쿼리로 변경
→ 단어의 순서가 다른 경우 검색되지 않는 것을 확인
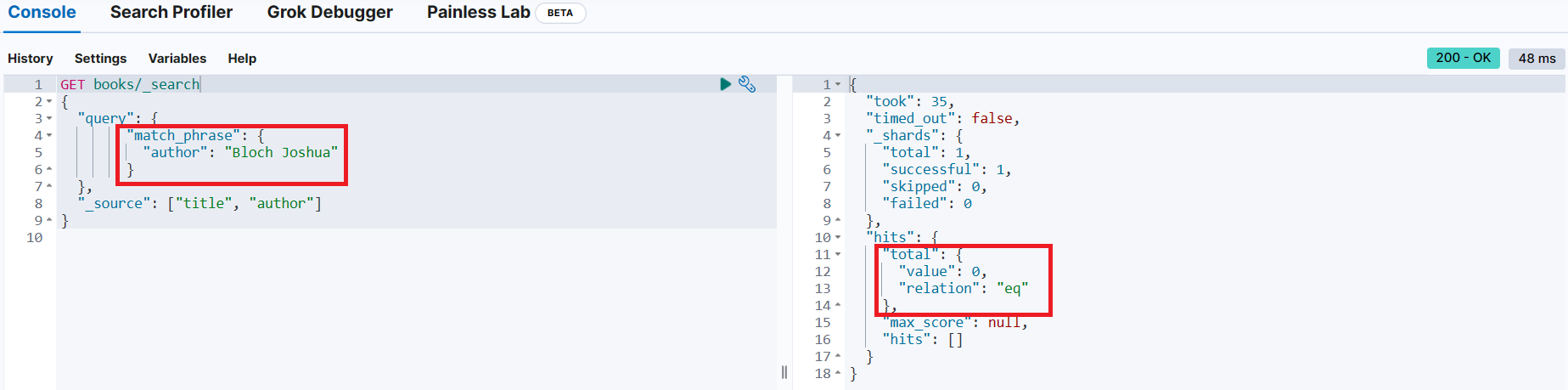
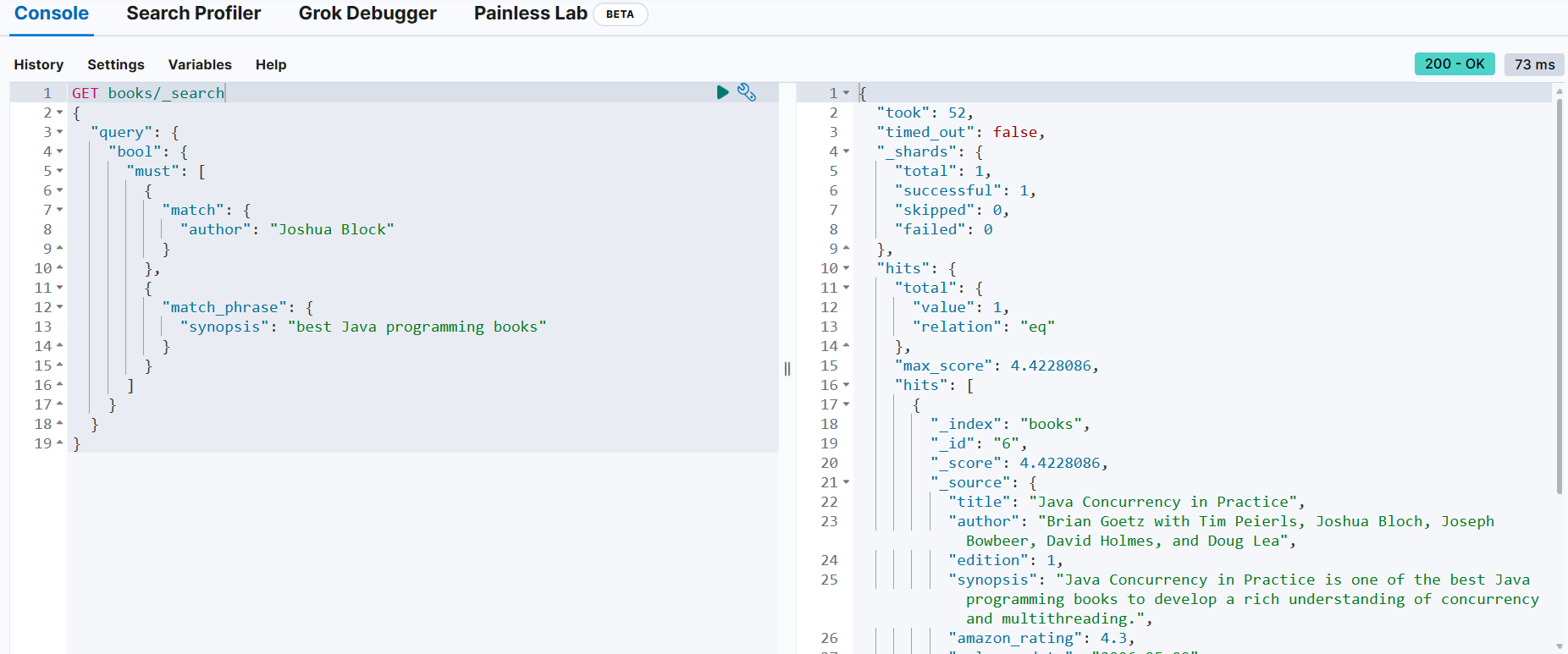
저자가 "Joshua Bloch"이고, synopsis에 "best Java programming books" 내용을 포함하고 있는 문서 조회
{
"took": 52,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 4.4228086,
"hits": [
{
"_index": "books",
"_id": "6",
"_score": 4.4228086,
"_source": {
"title": "Java Concurrency in Practice",
"author": "Brian Goetz with Tim Peierls, Joshua Bloch, Joseph Bowbeer, David Holmes, and Doug Lea",
"edition": 1,
"synopsis": "Java Concurrency in Practice is one of the best Java programming books to develop a rich understanding of concurrency and multithreading.",
"amazon_rating": 4.3,
"release_date": "2006-05-09",
"tags": [
"Computer Science Books",
"Programming Languages",
"Java Programming"
]
}
}
]
}
}
GET books/_search
{
"query": {
"bool": {
"must": [ → 반드시 만족해야 하는 조건이 여러 개이므로 배열로 나열
{
"match": {
"author": "Joshua Block"
}
},
{
"match_phrase": {
"synopsis": "best Java programming books"
}
}
]
}
}
}must_not 절
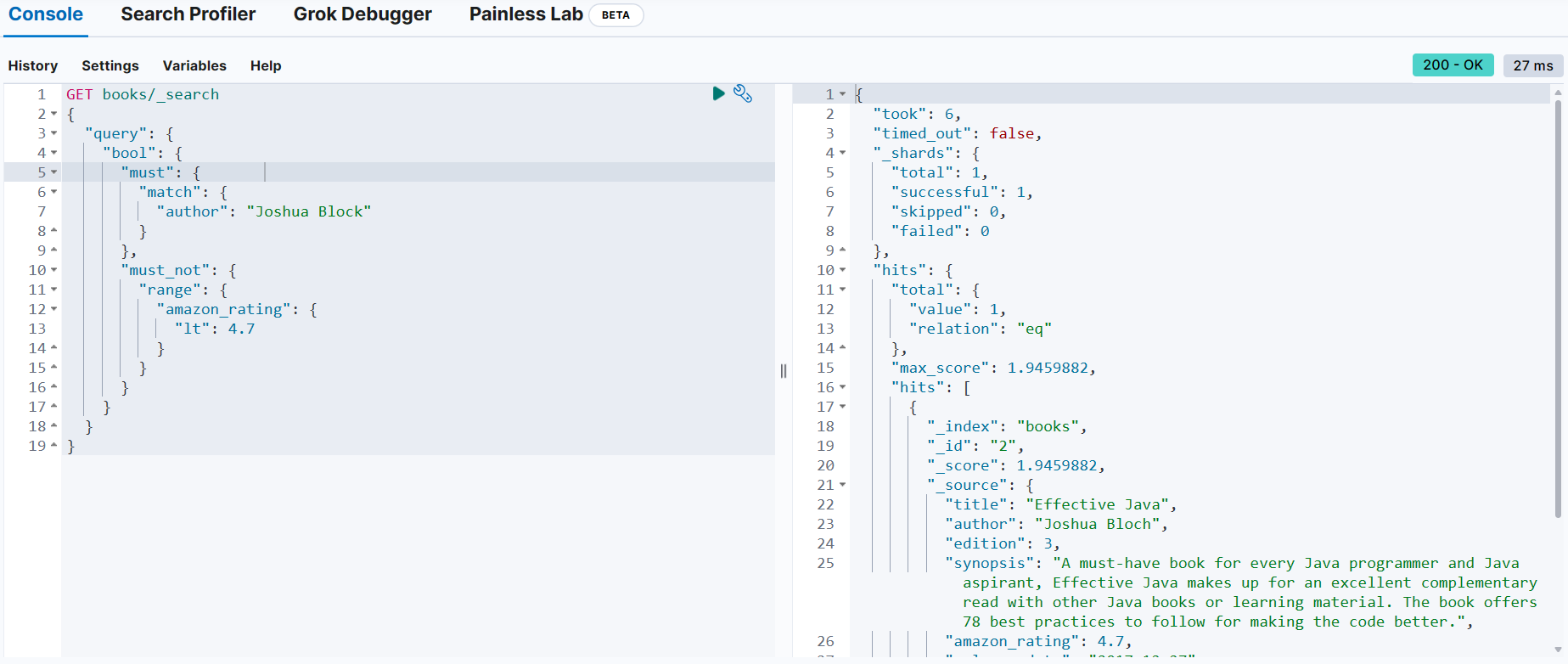
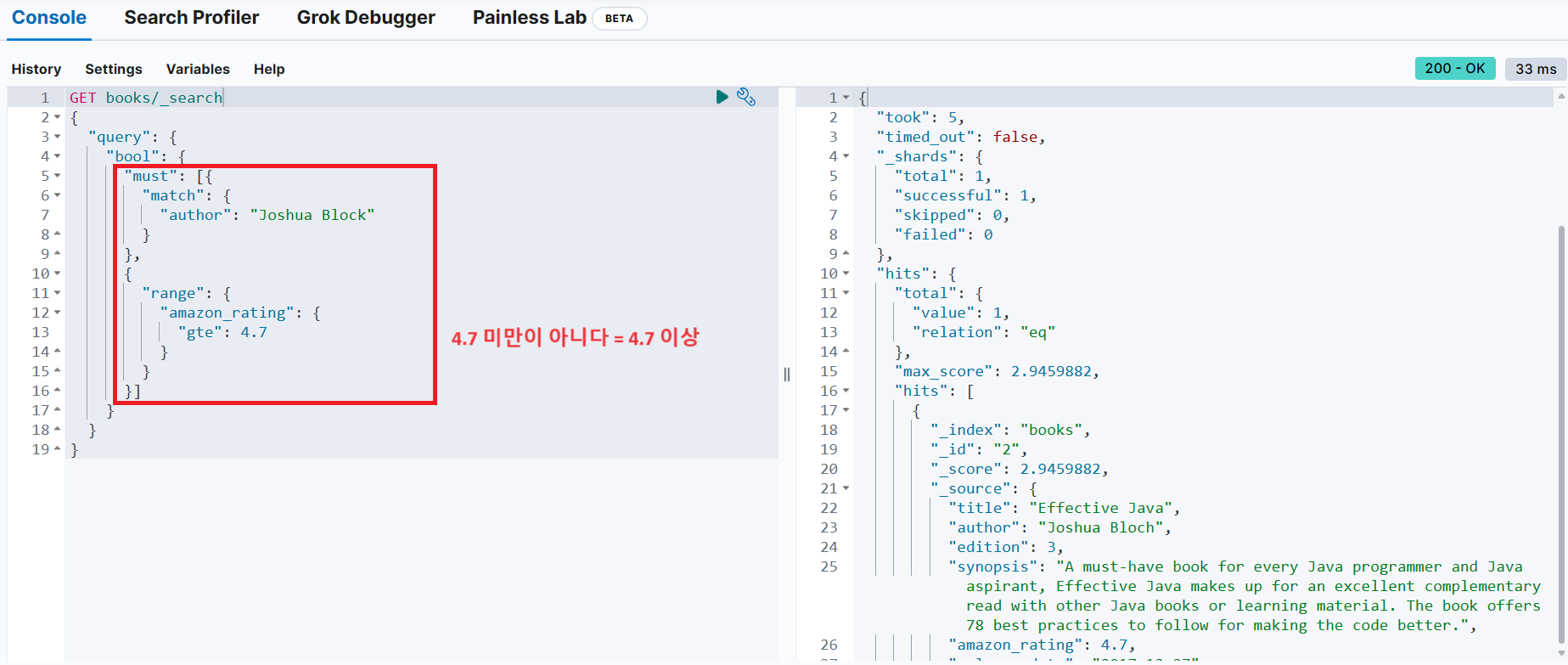
Joshua Block 책 중에서 아마존 평점이 4.7 미만이 아닌 책을 검색
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.9459882,
"hits": [
{
"_index": "books",
"_id": "2",
"_score": 1.9459882,
"_source": {
"title": "Effective Java",
"author": "Joshua Bloch",
"edition": 3,
"synopsis": "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"amazon_rating": 4.7,
"release_date": "2017-12-27",
"tags": [
"Object Oriented Software Design"
]
}
}
]
}
}
GET books/_search
{
"query": {
"bool": {
"must": { → 반드시 만족해야하는 조건이 하나이므로 대괄호를 생략
"match": {
"author": "Joshua Block"
}
},
"must_not": { → 반드시 만족해야하는 조건이 하나이므로 대괄호를 생략
"range": {
"amazon_rating": {
"lt": 4.7
}
}
}
}
}
}
should 절
검색어가 should 쿼리와 일치하면 관련성 점수가 올라감
should 절 포함하지 않고 검색했을 때
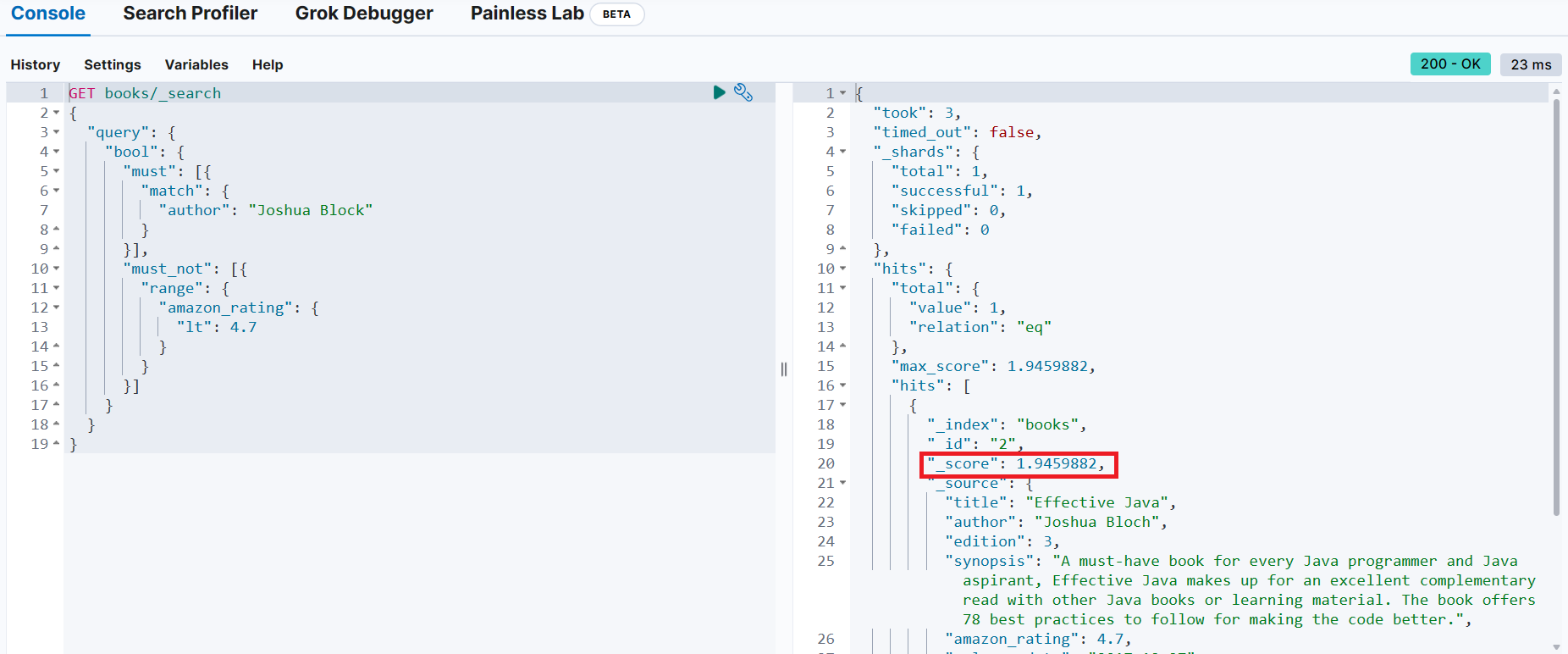
should 절을 포함해서 검색했을 때
→ _score가 증가
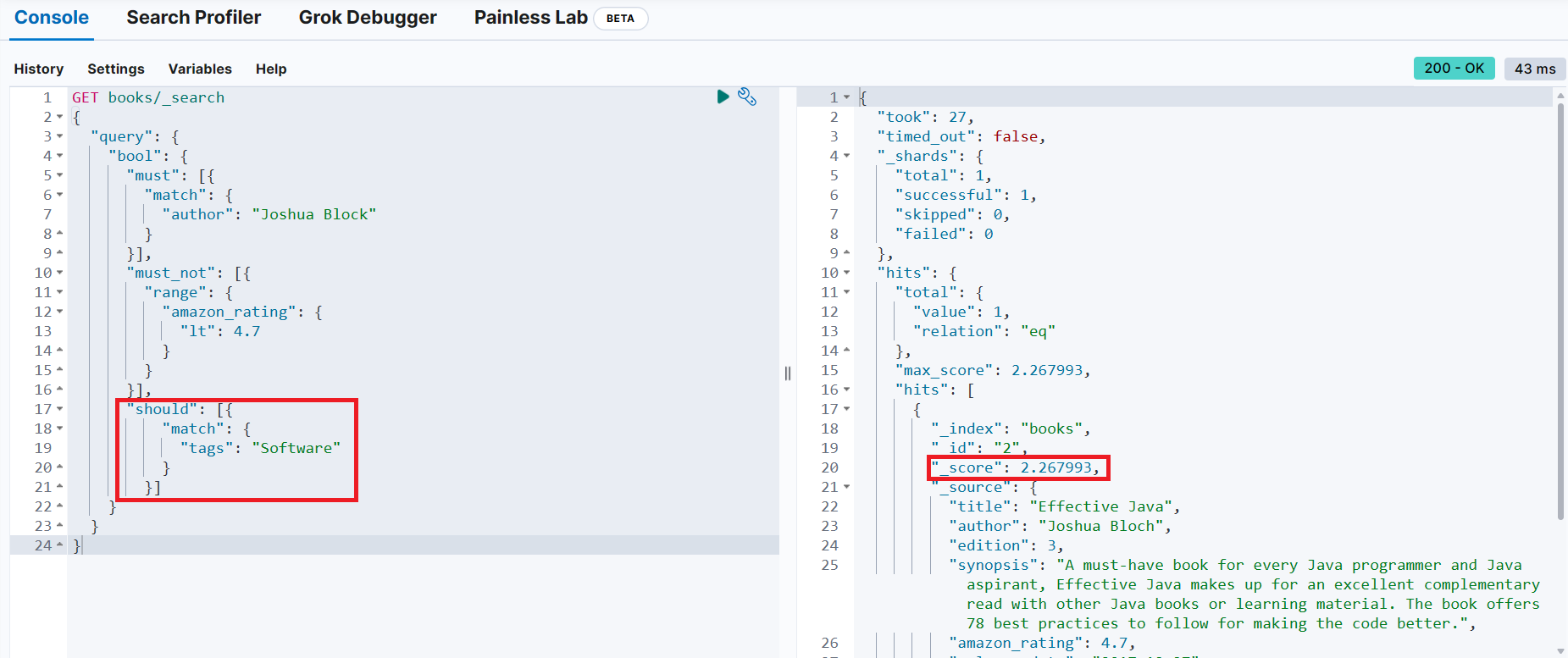
should 절에 일치하지 않는 조건 추가
→ 검색 결과는 변함이 없는데, _score가 감소(should 절이 없는 것과 동일)
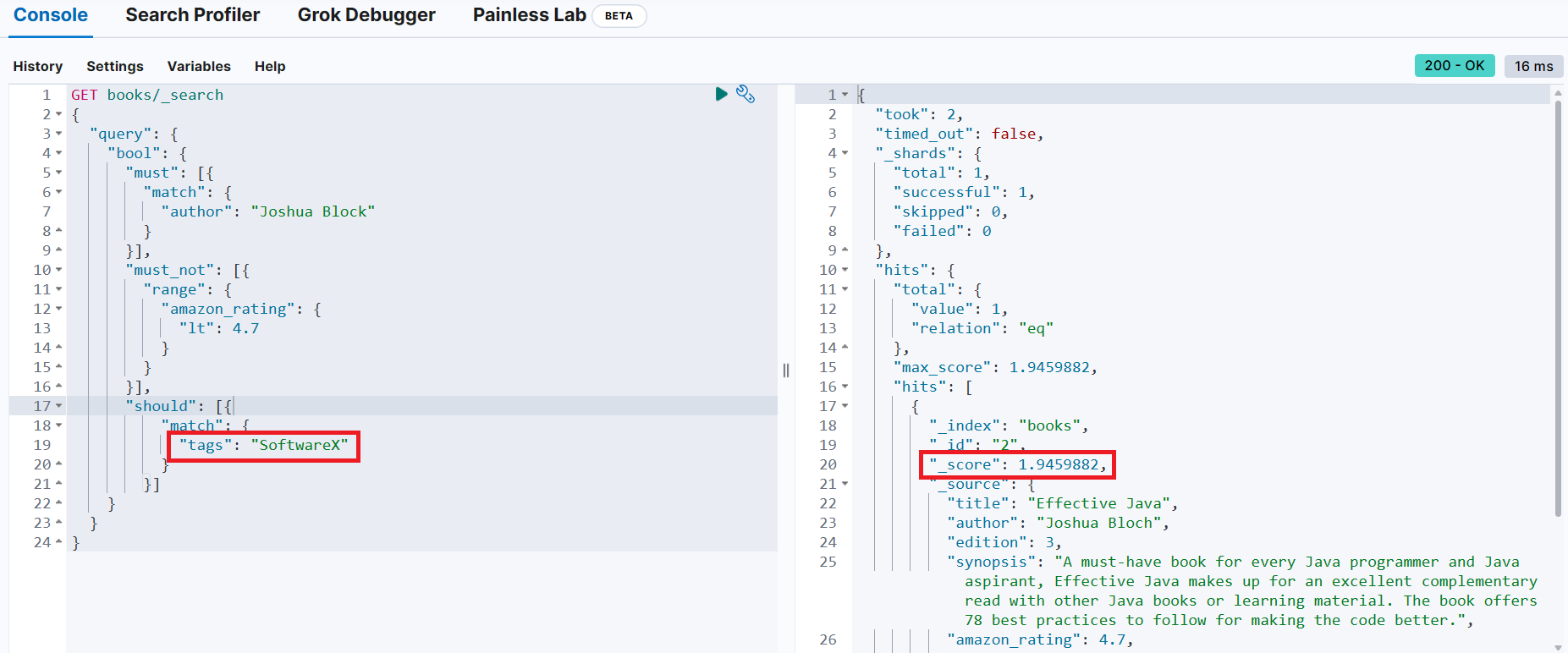
📢 should 절의 조건은 검색 결과에 영향을 미치지 않으나, 일치하는 경우 검색 결과의 유사도 점수가 증가하는 것을 확인 가능
filter 절
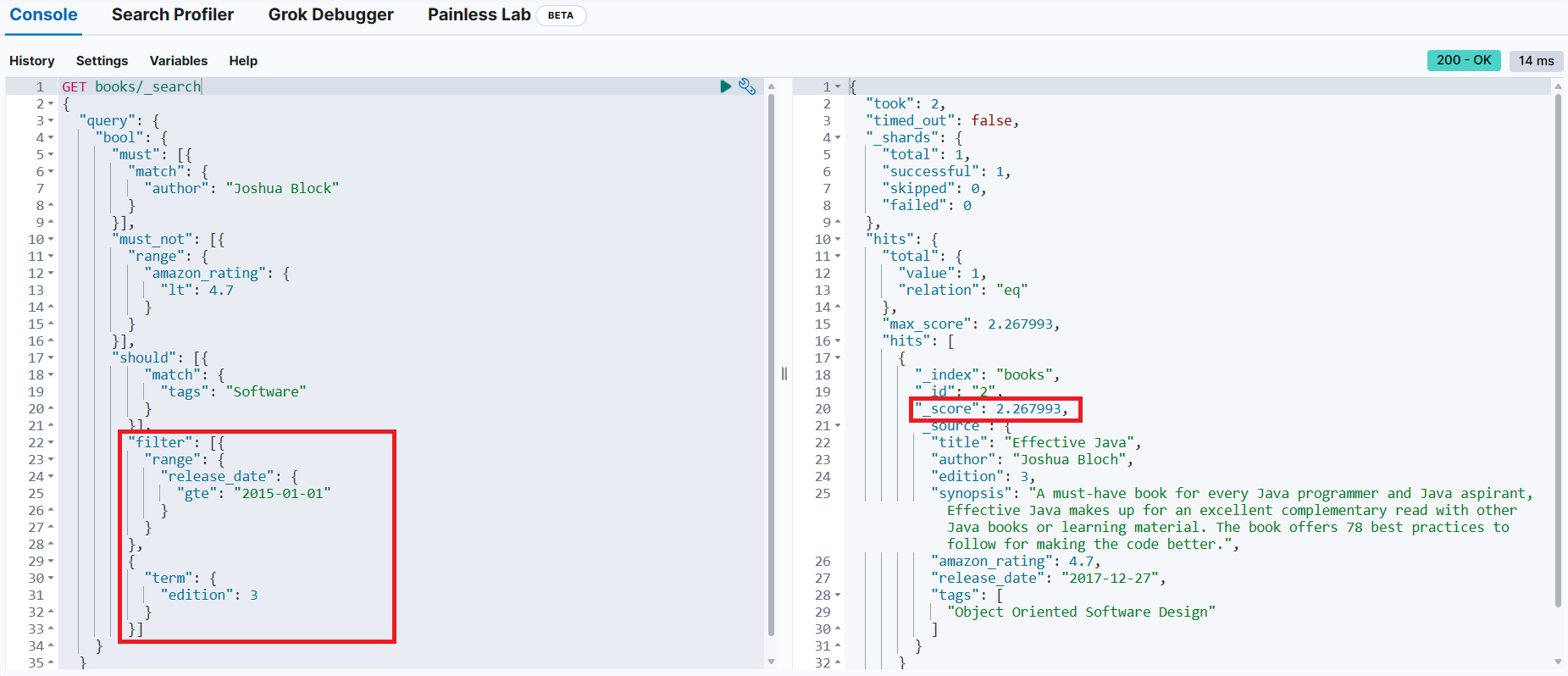
Joshua Block 책 중에서 아마존 평점이 4.7 미만이 아닌 책 중 태그에 Software가 포함된 책을 검색하는데, 검색 결과에서 2015년 이전에 출판된 책은 필터링(2015년 이전에 출판된 책은 결과에서 제외)
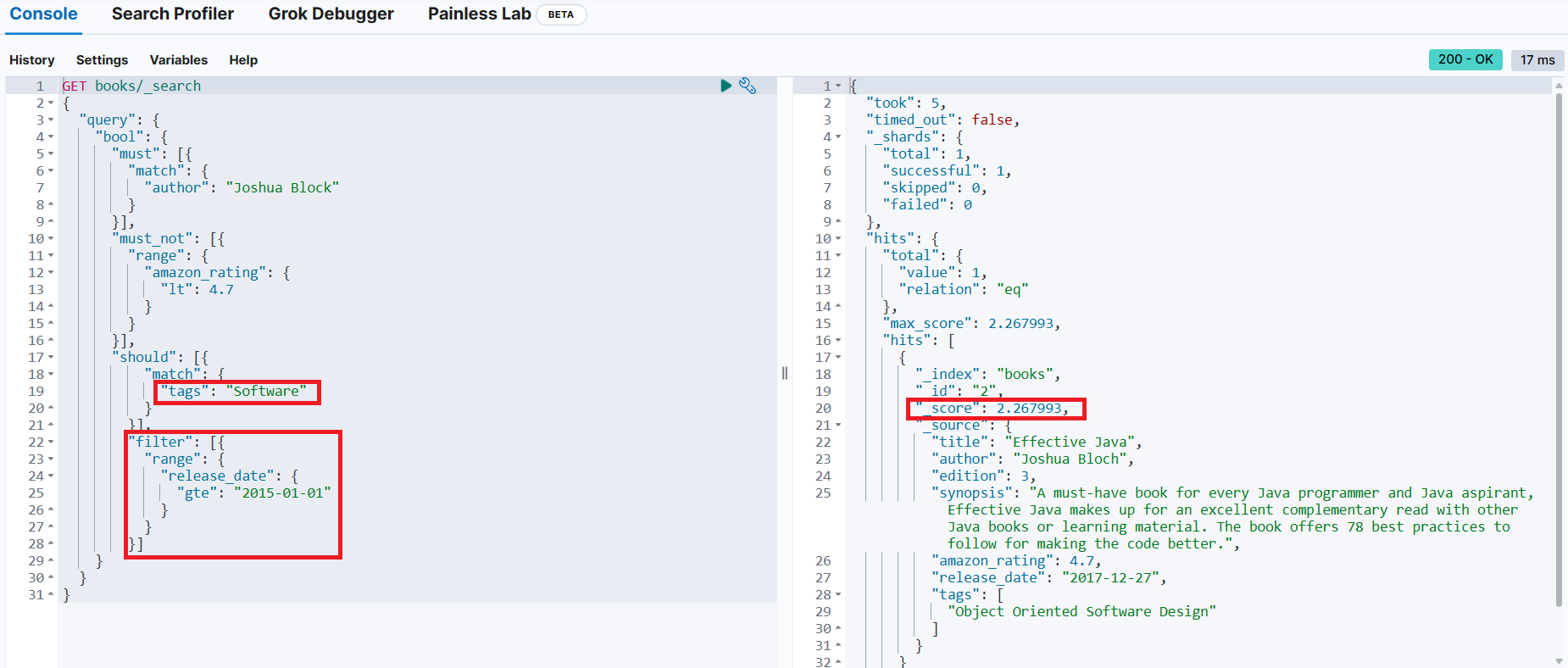
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.267993,
"hits": [
{
"_index": "books",
"_id": "2",
"_score": 2.267993,
"_source": {
"title": "Effective Java",
"author": "Joshua Bloch",
"edition": 3,
"synopsis": "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"amazon_rating": 4.7,
"release_date": "2017-12-27",
"tags": [
"Object Oriented Software Design"
]
}
}
]
}
}filter 절을 추가하지 않고 검색
검색 결과가 동일하고 _score도 동일
→ 연관성 점수에 영향을 미치지 않음
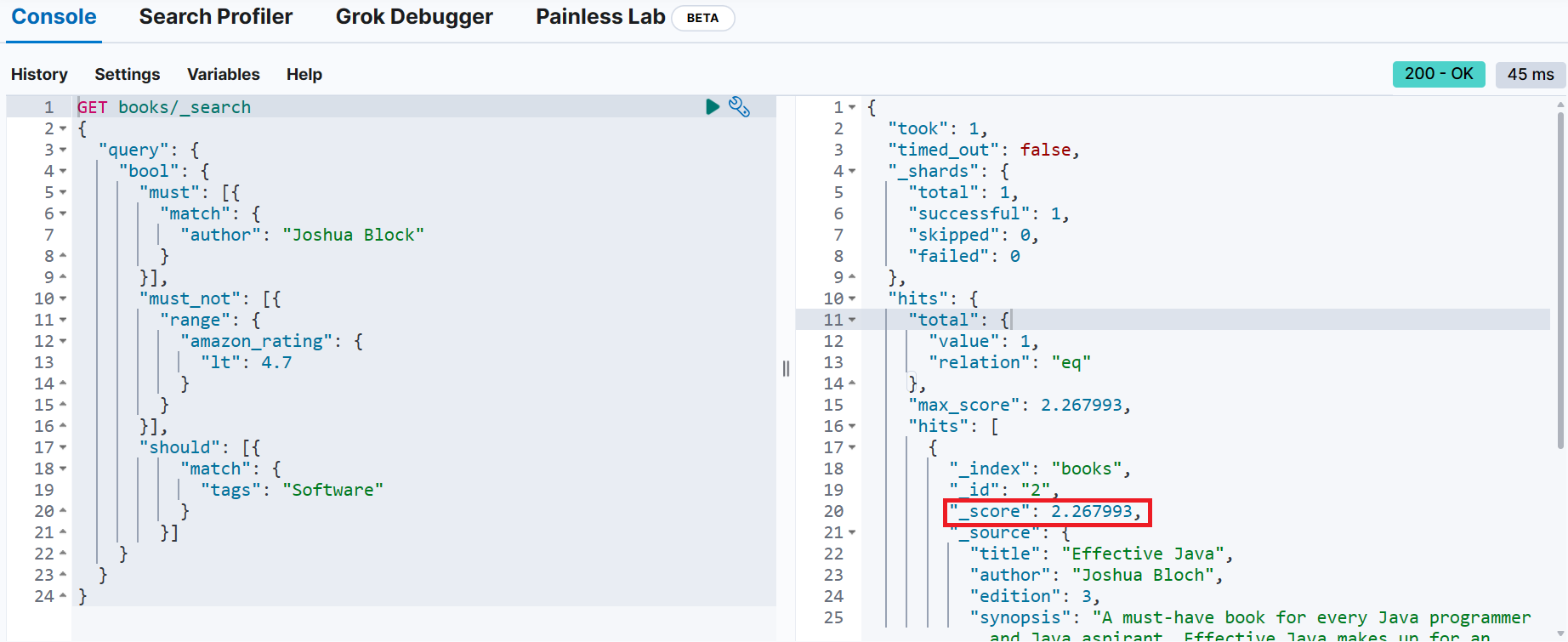
filter 조건을 만족하지 않으면 검색 대상이 될 수 없음
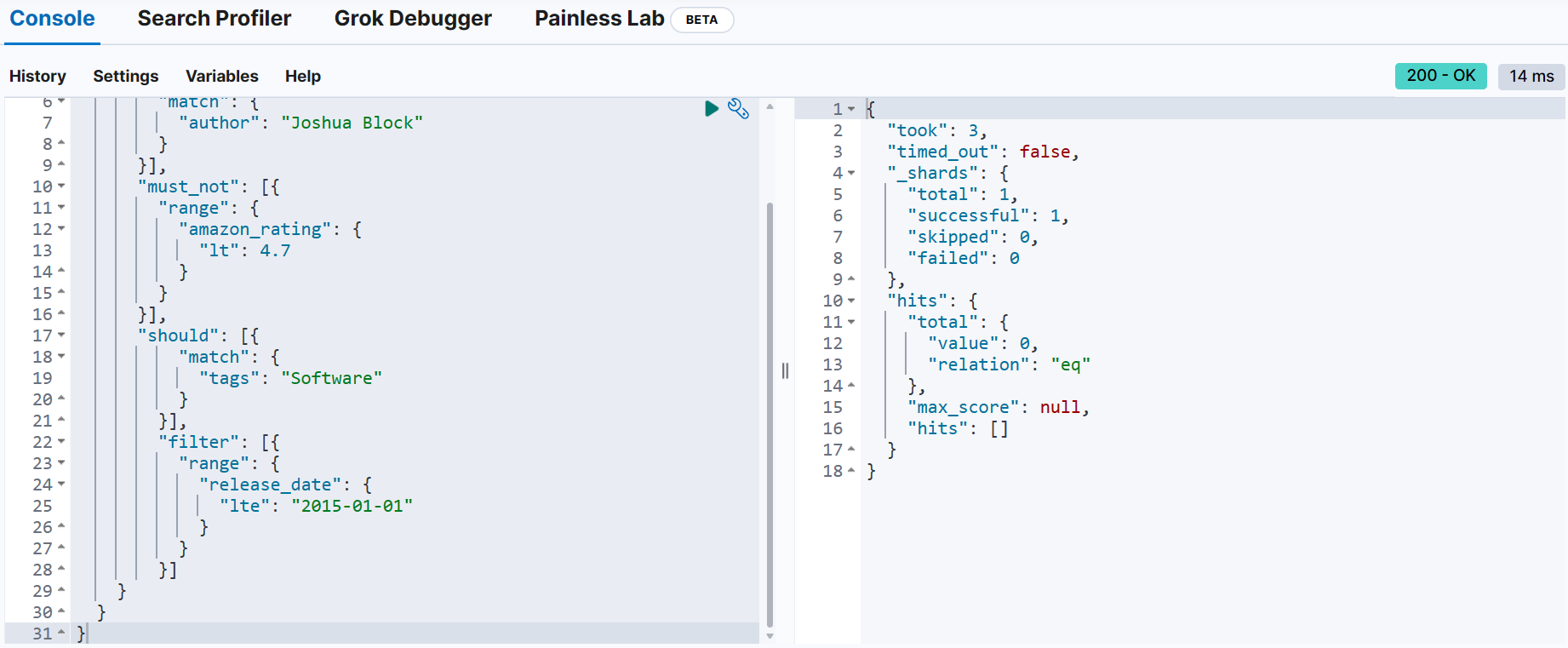
Joshua Block 책 중에서 아마존 평점이 4.7 미만이 아닌 책 중 태그에 Software가 포함된 책을 검색하는데, 검색 결과에서 2015년 이전에 출판되고 3판인 책을 검색
📌 집계 (aggregations)
✔ 집계 유형
-
메트릭 집계 - 합계, 최소, 최대, 평균
→ 문서 데이터 집합 전체에 걸쳐 집계된 값 -
버킷 집계 - 날짜, 연령 그룹 등과 같은 간격으로 분리된 버킷으로 데이터를 수집하는 집계
→ 히스토그램, 원형 차트, 기타 시각화 구축에 사용 -
파이프라인 집계 - 다른 집계의 출력에 대해 작동하는 집계
✔ 검색과 마찬가지로 _search 엔드포인트를 사용
✔ query 개체 대신 aggs 개체를 사용
📌 10개국의 코로나 관련 데이터 색인화
https://github.com/madhusudhankonda/elasticsearch-in-action/blob/main/datasets/covid-26march2021.txt
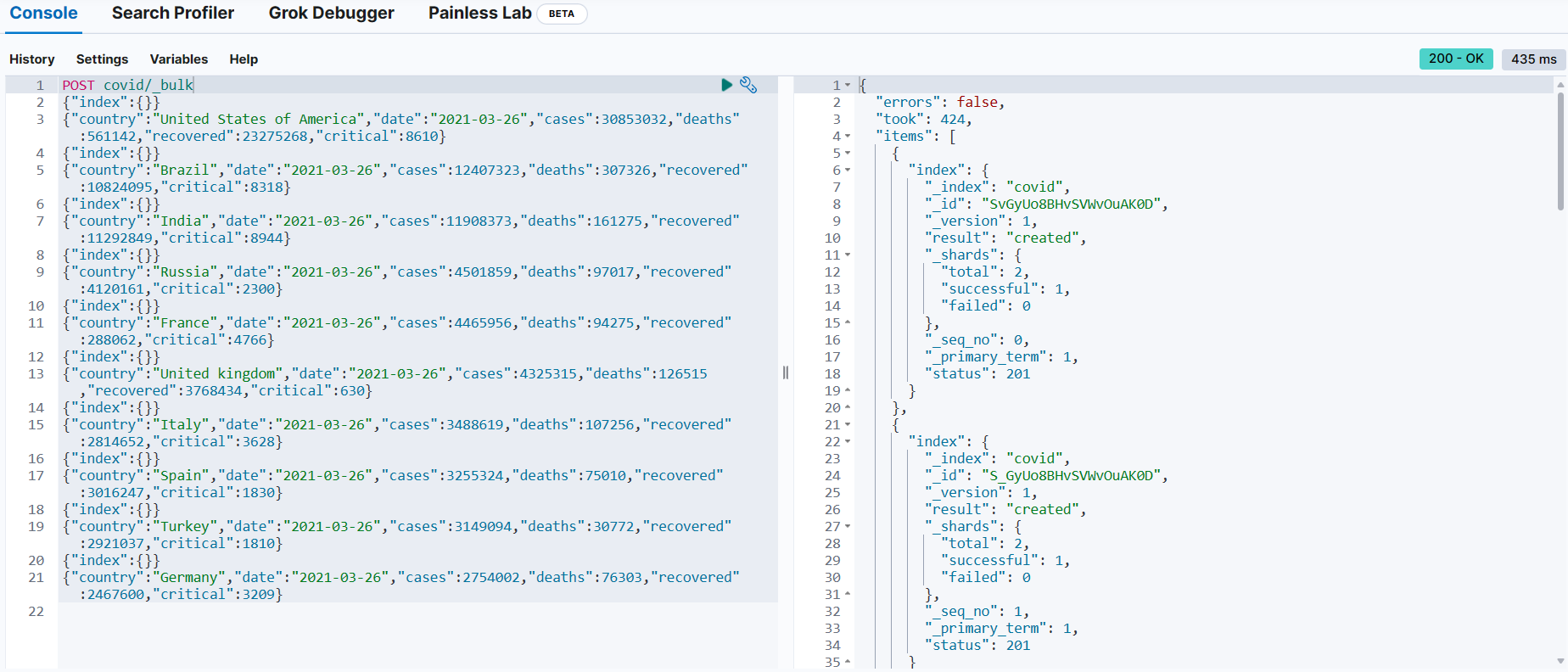
POST covid/_bulk → _bulk API
{"index":{}} → 실행하려고 하는 작업(인덱싱) → 메타 데이터(_index, _id)를 생략
{"country":"United States of America", ... ,"recovered":23275268,"critical":8610} ~~~~~~ ~~~
| |
_bulk API에서 지정했으므로 생략 --+ |
임의의 ID를 자동으로 생성 --+📌 covid 인덱스에 문서 개수 조회

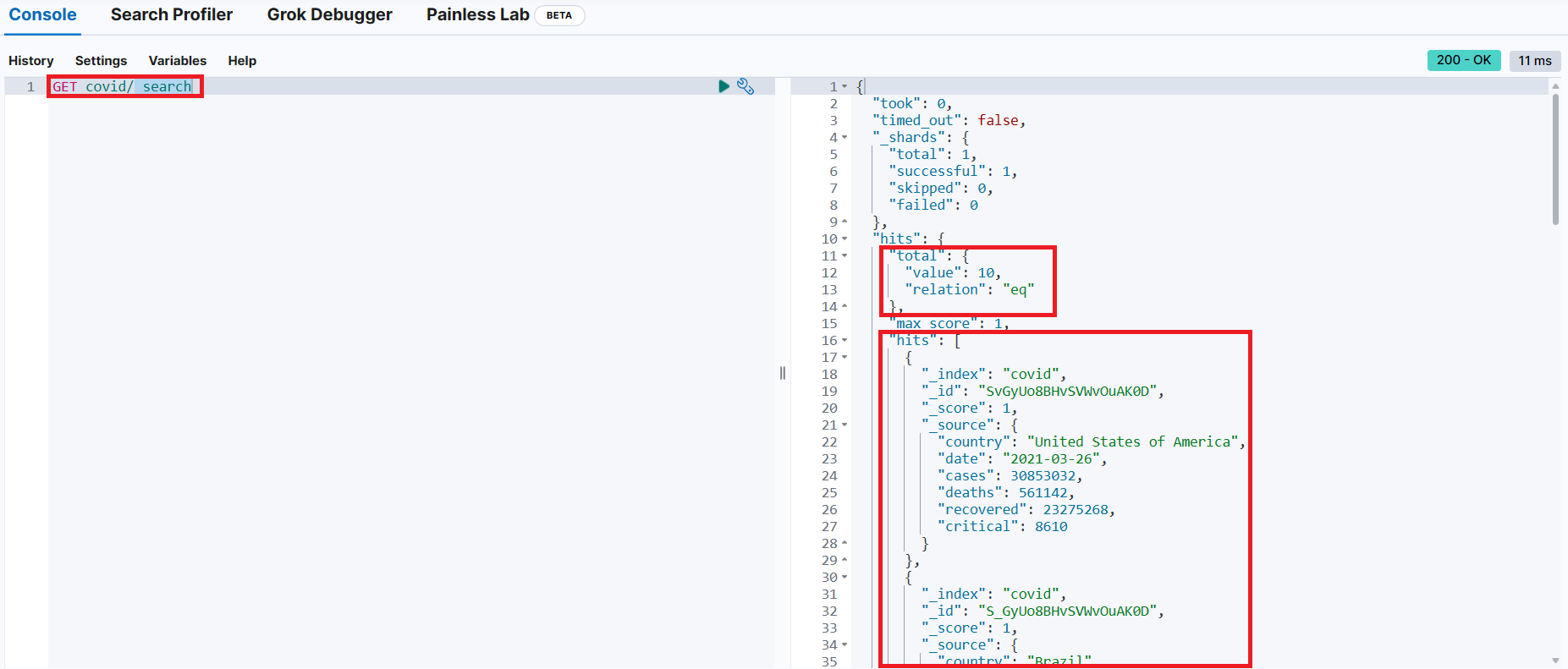
📌 covid 인덱스에 모든 문서 조회
📌 메트릭(metric) 집계
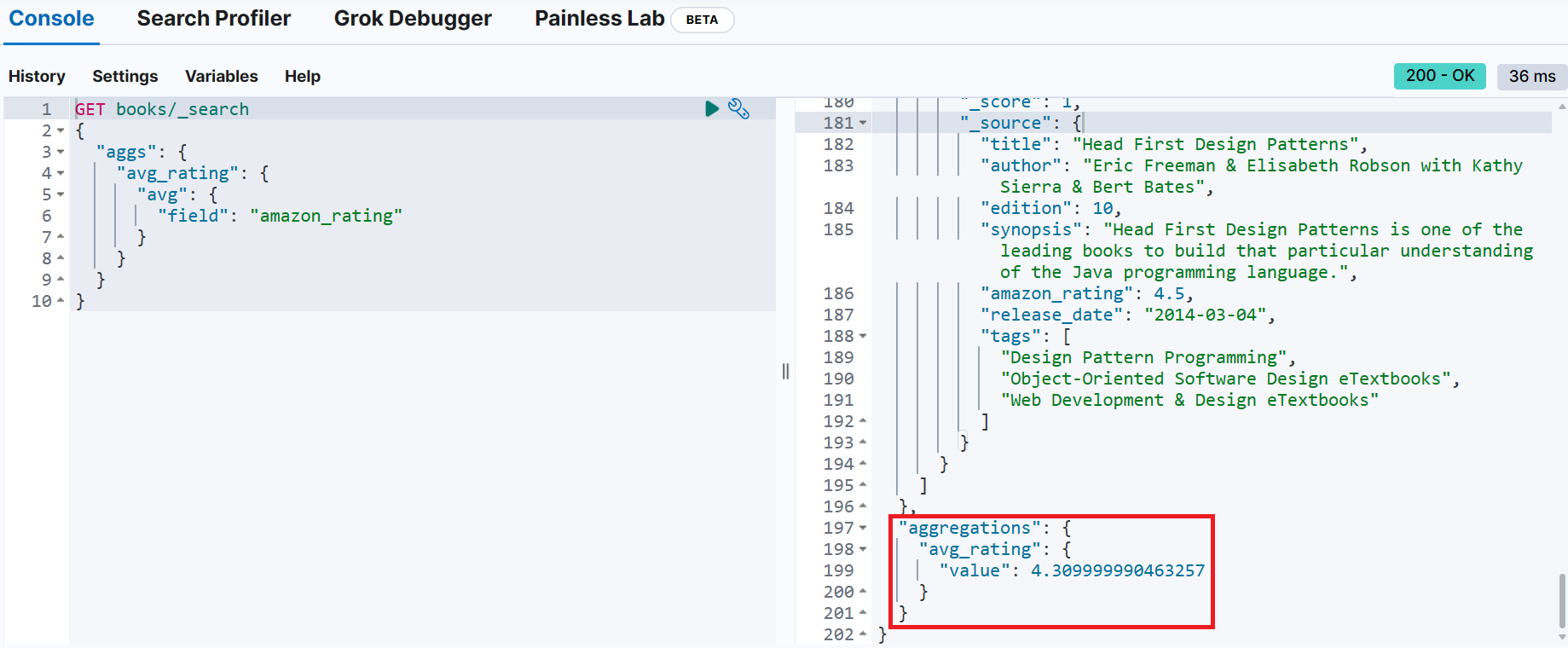
GET books/_search → 조회와 동일한 엔드포인트 사용(_search API 이용)
{
"aggs": { → 집계 의미
"avg_rating": { → 집계 결과를 나타내는 사용자 정의 이름
"avg": { → 집계 유형 (avg = 평균)
"field": "amazon_rating" → 집계 대상
}
}
}
}📌 covid 인덱스에서 전체 중증환자 수를 집계해 critial_patients로 출력
문서 구조
{
"country": "United States of America",
"date": "2021-03-26",
"cases": 30853032, → 확진자
"deaths": 561142, → 사망자
"recovered": 23275268, → 완치자
"critical": 8610 → 중증환자
}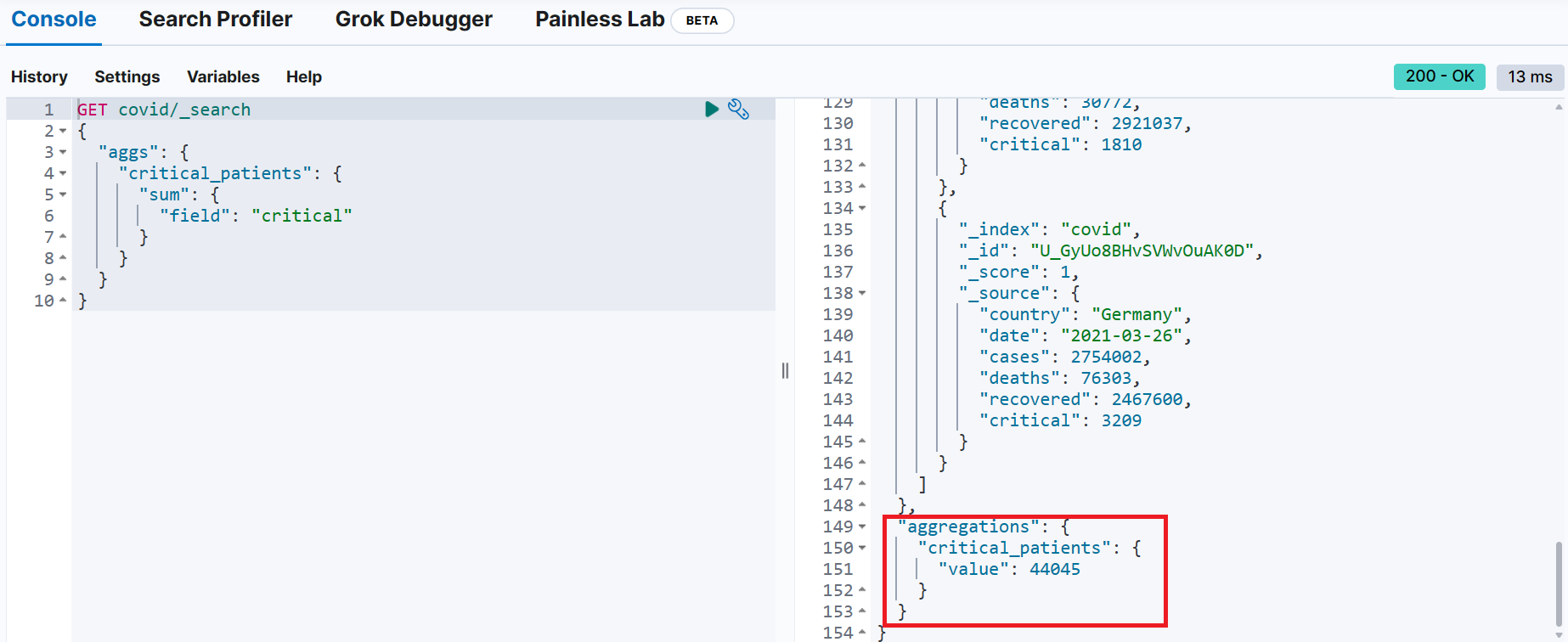
GET covid/_search
{
"aggs": {
"critial_patients": {
"sum": {
"field": "critical"
}
}
}
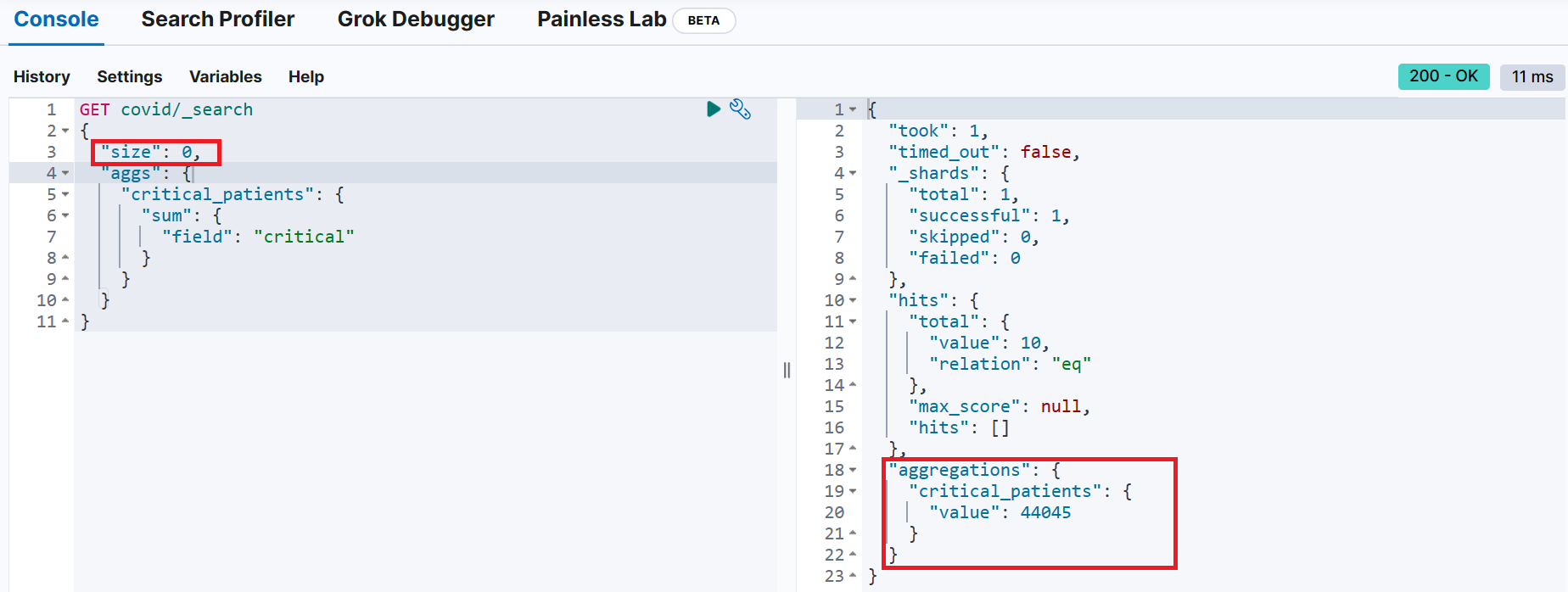
}원본 소스 문서가 집계 결과에 포함되지 않도록 설정
covid 인덱스에서 전체 사망자수 중 가장 큰 값, 가장 작은 값, 평균 값
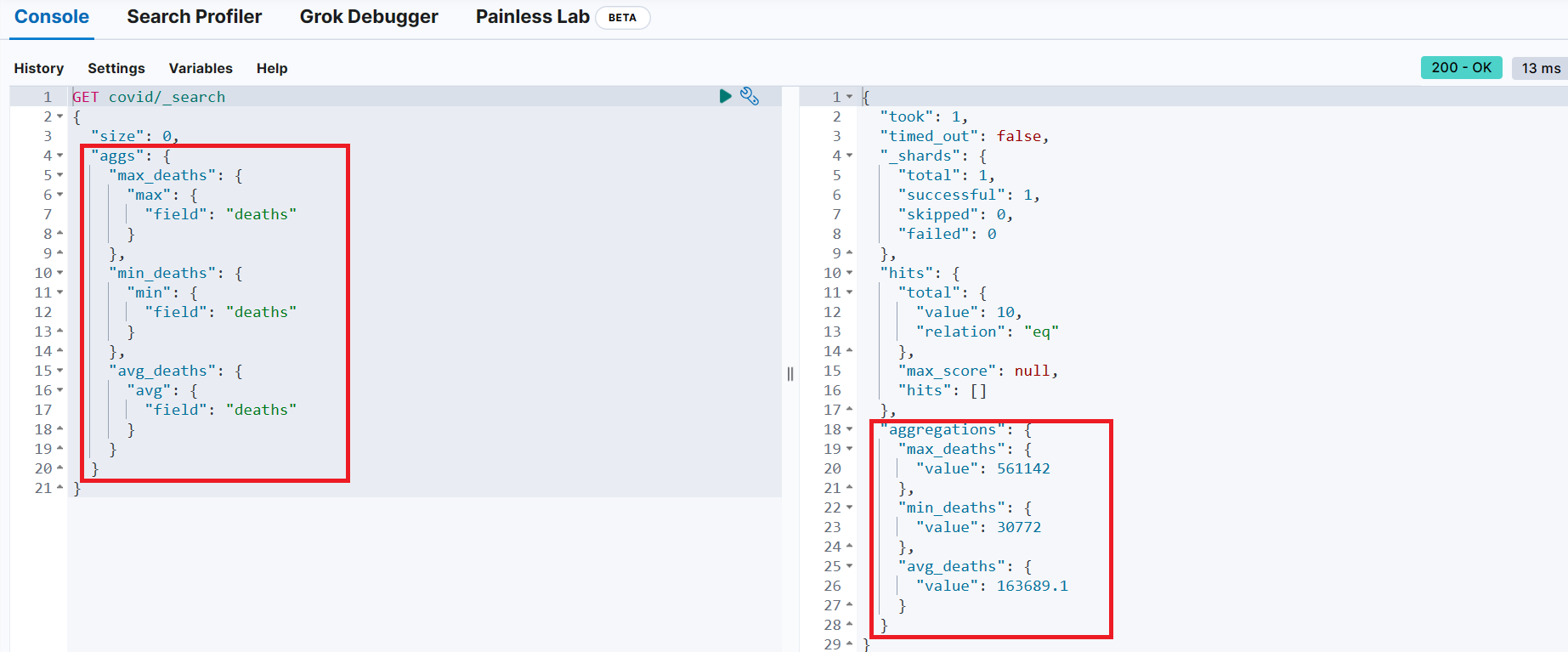
GET covid/_search
{
"size": 0,
"aggs": {
"max_deaths": {
"max": {
"field": "deaths"
}
},
"min_deaths": {
"min": {
"field": "deaths"
}
},
"avg_deaths": {
"avg": {
"field": "deaths"
}
}
}
}stats 항목을 이용해 개수, 최소값, 최대값, 평균, 합계 조회
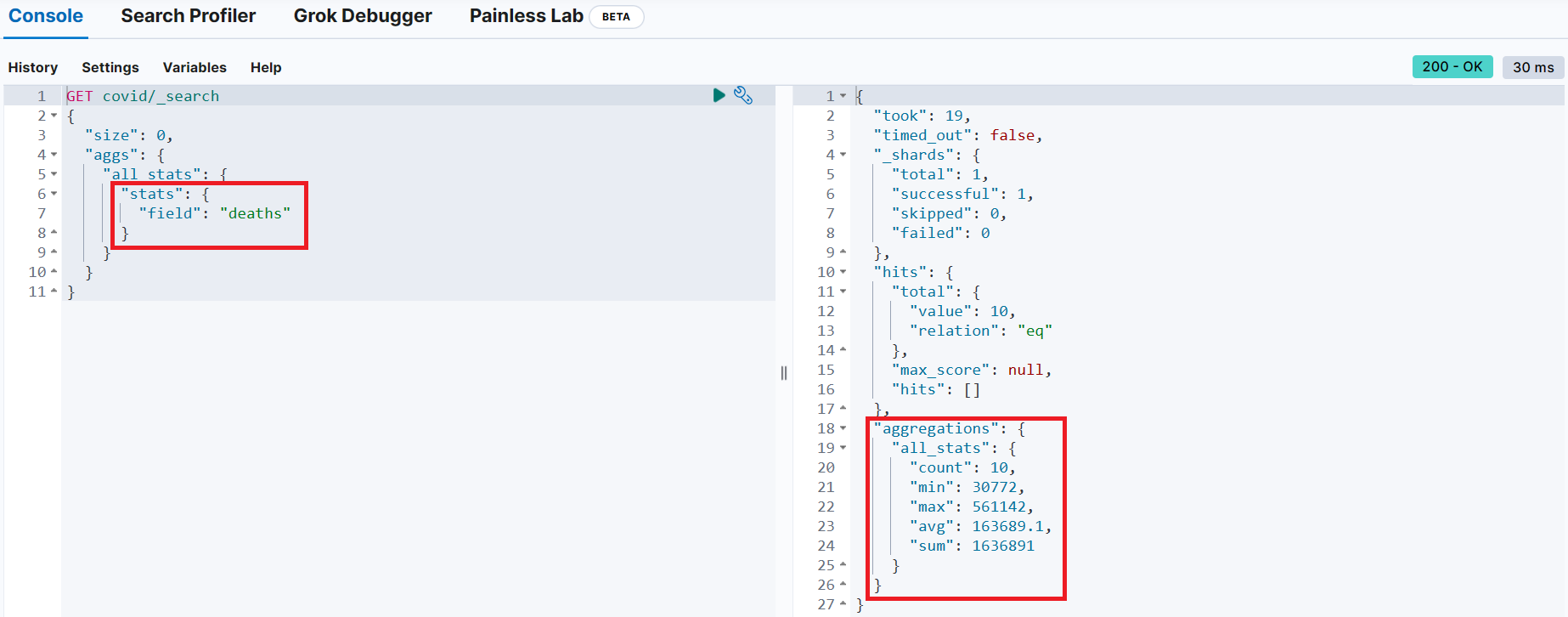
GET covid/_search
{
"size": 0,
"aggs": {
"all_stats": { → 결과를 출력할 때 사용하는 사용자 정의 이름
"stats": { → 개수, 최소값, 최대값, 평균, 합계를 계산
"field": "deaths" → 계산 대상 데이터
}
}
}
}extended_stats - 분산, 표준 편차와 같은 더 많은 정보 제공
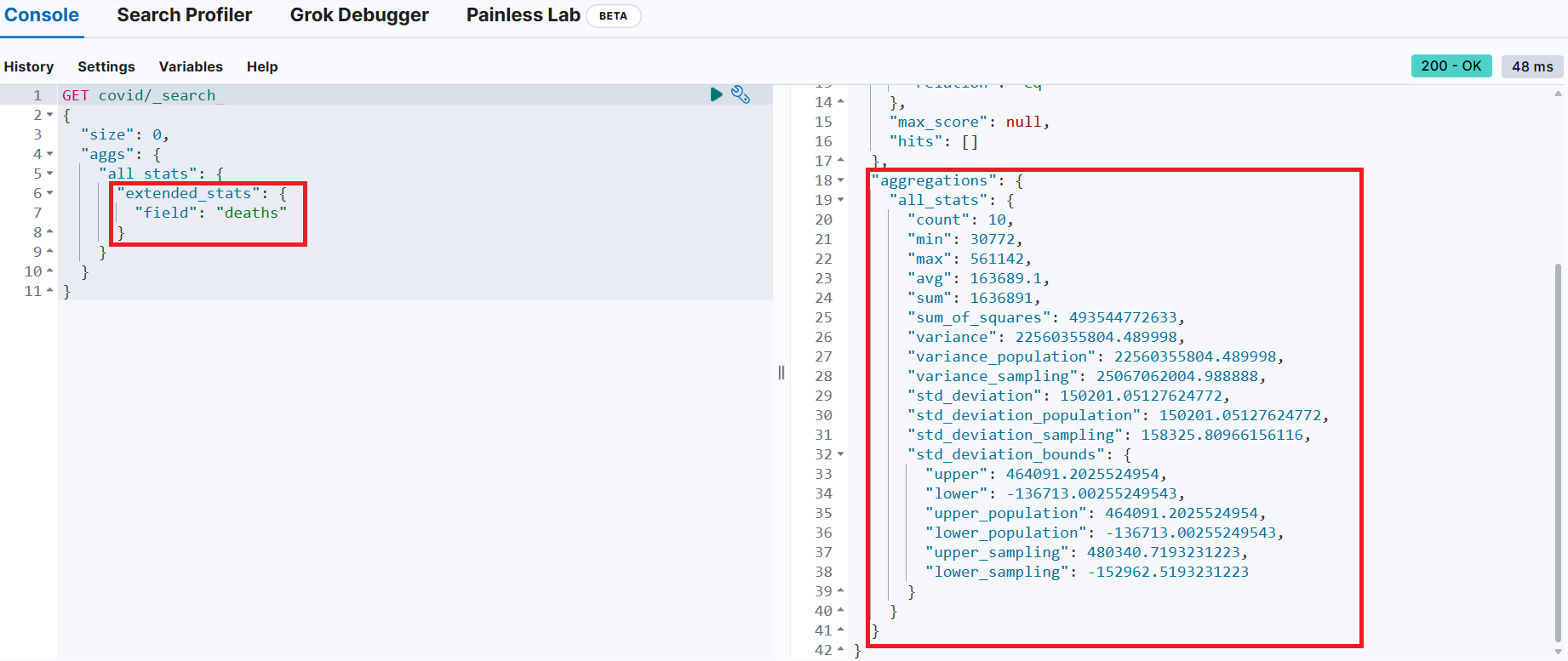
📌 버킷(bucket) 집계
버킷팅
→ 데이터를 다양한 그룹이나 버킷으로 분리
히스토그램 버킷 (histogram buckets)
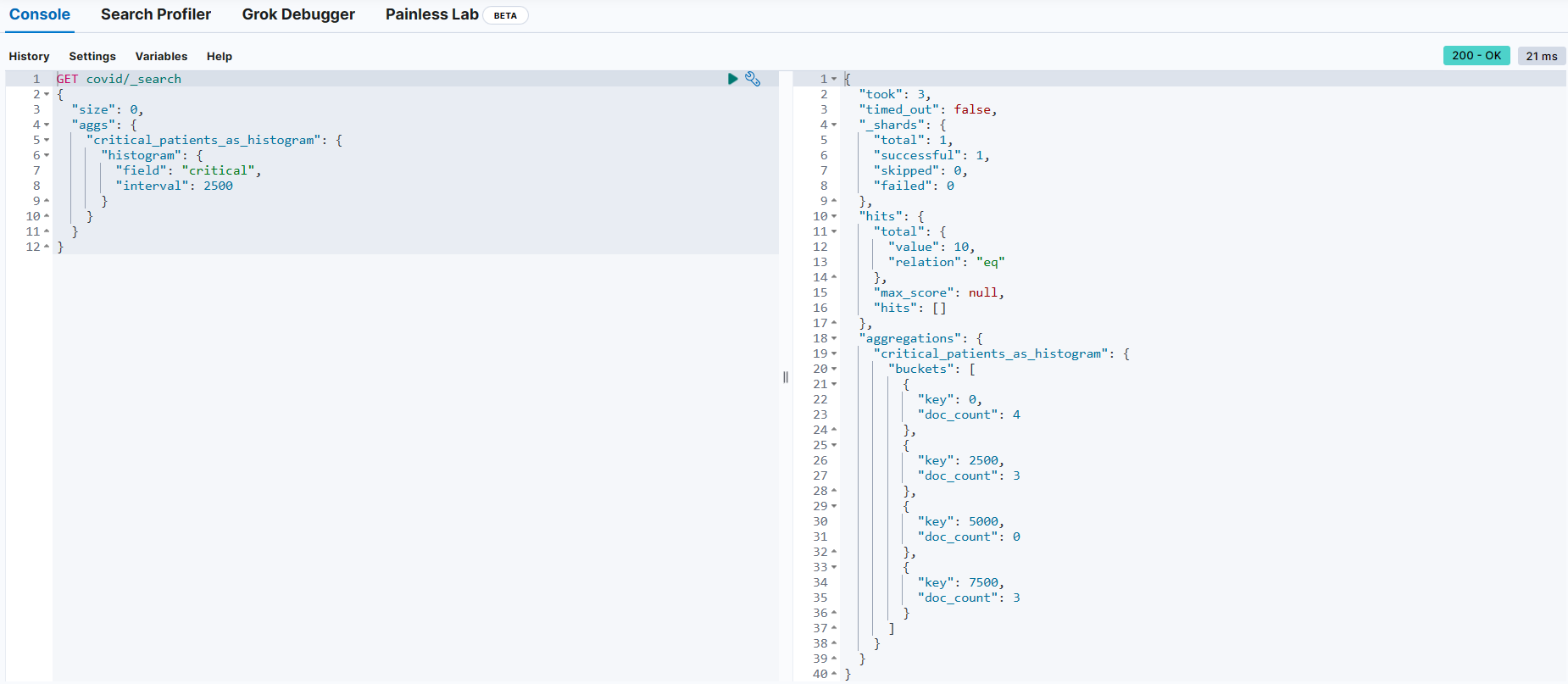
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"critical_patients_as_histogram": {
"buckets": [
{
"key": 0,
"doc_count": 4
},
{
"key": 2500,
"doc_count": 3
},
{
"key": 5000,
"doc_count": 0
},
{
"key": 7500,
"doc_count": 3
}
]
}
}
}GET covid/_search
{
"size": 0,
"aggs": {
"critical_patients_as_histogram": {
"histogram": {
"field": "critical",
"interval": 2500 → 일정한 간격으로 범위를 구분
}
}
}
}범위 버킷 (range buckets)
정의된 범위를 기반으로 버킷 세트 정의
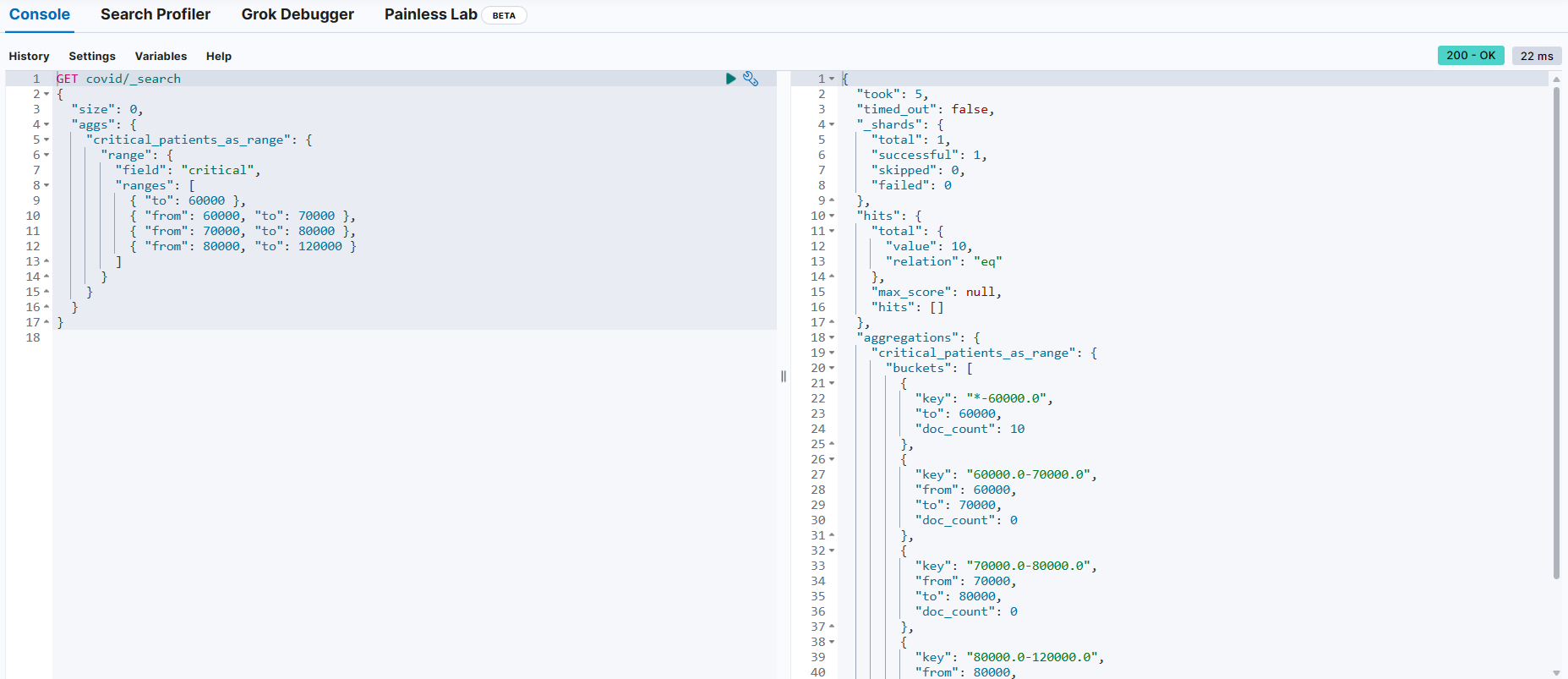
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"critical_patients_as_range": {
"buckets": [
{
"key": "*-60000.0",
"to": 60000,
"doc_count": 10
},
{
"key": "60000.0-70000.0",
"from": 60000,
"to": 70000,
"doc_count": 0
},
{
"key": "70000.0-80000.0",
"from": 70000,
"to": 80000,
"doc_count": 0
},
{
"key": "80000.0-120000.0",
"from": 80000,
"to": 120000,
"doc_count": 0
}
]
}
}
}
GET covid/_search
{
"size": 0,
"aggs": {
"critical_patients_as_range": {
"range": {
"field": "critical",
"ranges": [ → 범위 정의
{ "to": 60000 },
{ "from": 60000, "to": 70000 },
{ "from": 70000, "to": 80000 },
{ "from": 80000, "to": 120000 }
]
}
}
}
}📌 (교재) 처음 배우는 네트워크 보안 205p
ELK를 통한 보안 관제
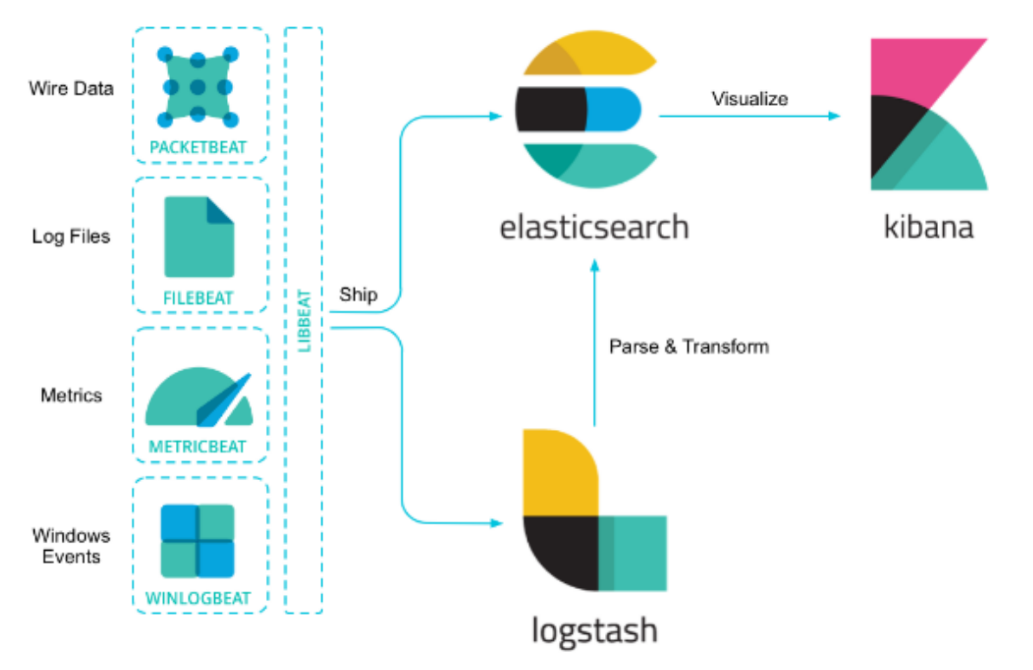
데이터
서비스 환경 전체에 분산되어 있을 뿐 아니라 정보의 특성이나 구조, 수집 방법 등이 다양 → 데이터가 생성되면 검색, 상관관계 및 분석을 위해 중앙집중식 로깅 플랫폼이 필요
✔ 네트워크 종단에 있는 기기
→ 수집해야 할 중요한 메트릭 존재
✔ 프로트엔드, 백엔드, 데이터 베이스 서버 그룹
→ 심각한 오류나 경고 로그 생성
✔ 고객이 실행하는 애플리케이션
→ 심각한 계측 데이터와 추적 데이터 생성
로그 vs 메트릭
로그 → 시스템 또는 애플리케이션이 생성한 특정 이벤트에 대한 정보
메트릭 → 특정 시점에서 시스템 또는 애플리케이션의 상태를 측정한 것
비츠(beats) 에이전트 - 데이터를 수집해 중앙 수신지로 전송
파일비트(Filebeat)
다양한 위치에서 다음과 같은 유형의 시스템과 애플리케이션의 로그 수집
💡 다음과 같은 유형의 시스템
1. 디스크에 있는 파일
2. HTTP API 엔드포인트
3. 카프카, 애저 이벤트 수집기, GCP Pub/Sub 같은 메시지 스트림
4. Syslog 리스너
매트릭비트(metricbeat)
지원되는 다양한 시스템과 프로토콜에서 시스템과 애플리케이션, 플랫폼의 매트릭 수집
오딧비티(auditbeat)
리눅스 감사 시스템(Linux Auditing System = auditd) 프레임워크에서 규정한 운영체제 감사 데이터 수집
하트비트(heartbeat)
ICMP, TCP, HTTP 프로토콜을 통해 애플리케이션과 서비스 가동 시간, 가용성 정보를 수집하고 모니터링
패킷비트(packetbeat)
분석 대상 호스트에서 실시간으로 네트워크 패킷 정보를 수집하고 복호화
윈로그비트(winlogbeat)
윈도우 시스템에서 발생하는 이벤트 로그 수집
펑션비트(functionbeat)
AWS Lambda 또는 Google Cloud Functions와 같은 서버리스 플랫폼에서 기능(function)으로 배포해 CloudWatch Logs, GCP Pub/Sub, AWS Kinesis 같은 클라우드 용 로그 소스에서 데이터를 수집할 수 있는 특별한 비트
📌 정적 웹 페이지를 제공하는 웹 서버 구성
엔진엑스 설치 및 실행
https://nginx.org/en/download.html
https://nginx.org/download/nginx-1.25.5.zip
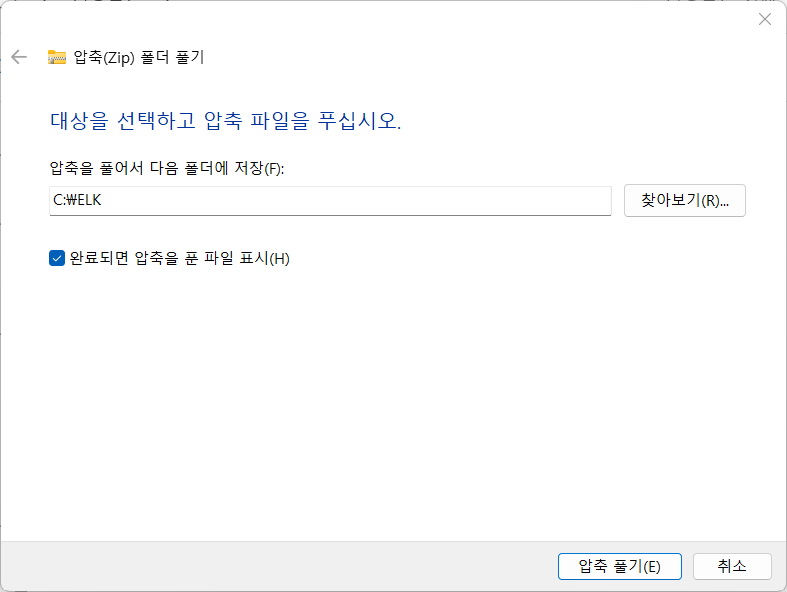
내려받은 압축파일을 C:\ELK 디렉터리에 압축해제
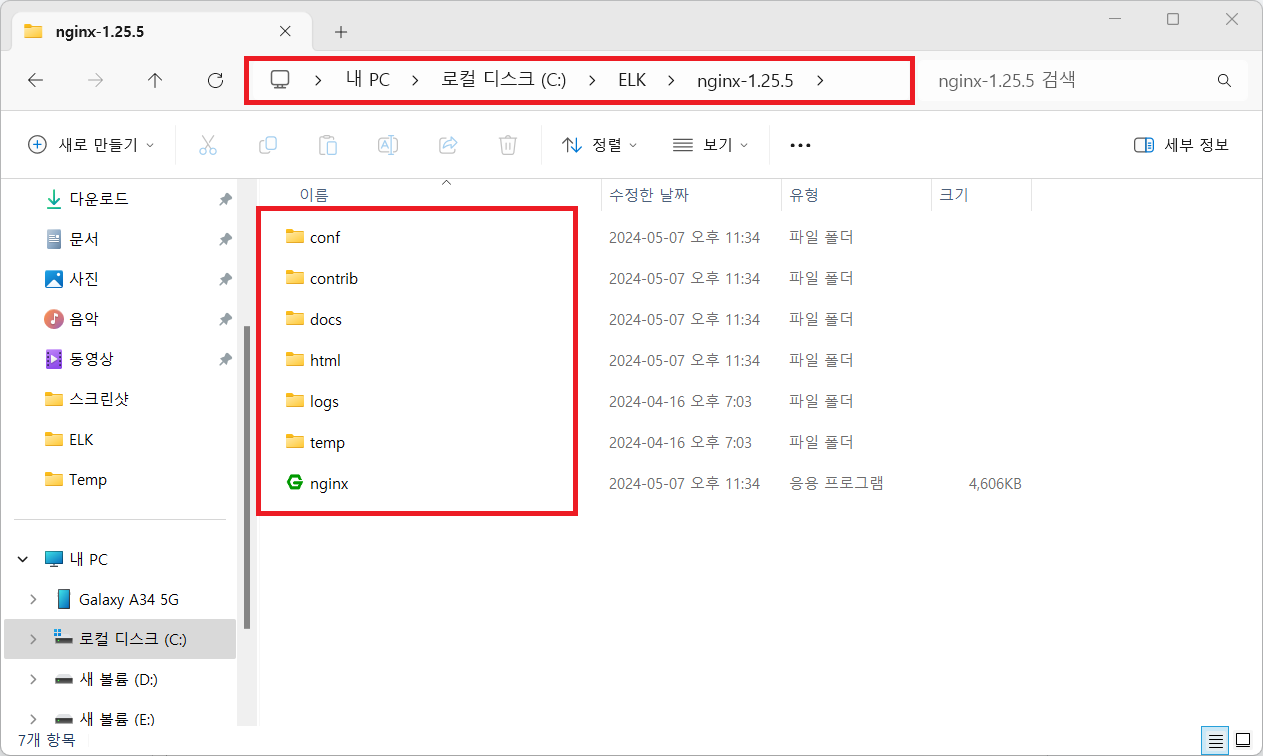
(관리자 모드) 명령 프롬프트에서 nginx 실행
C:\Windows\System32> cd c:\ELK\nginx-1.25.5
C:\ELK\nginx-1.25.5> nginx.exe
~~~~~~~~~~~~~~~~~~~
압축해제한 폴더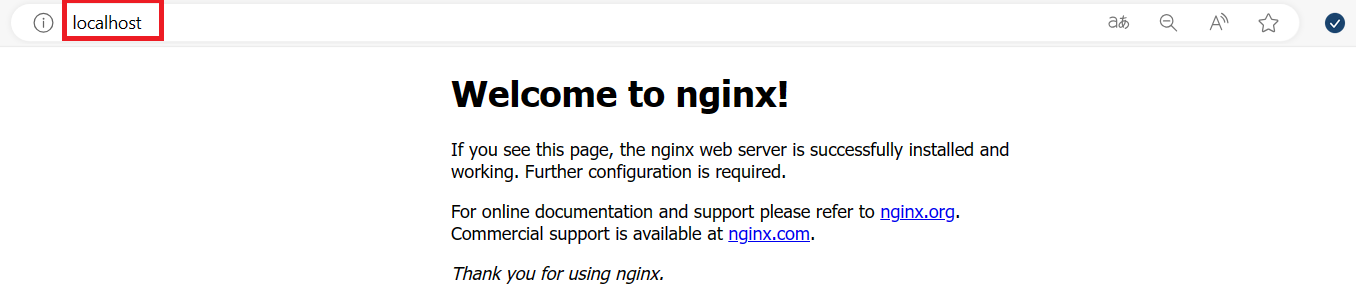
80 포트가 사용 중인 경우, 서비스 포트를 변경해서 실행
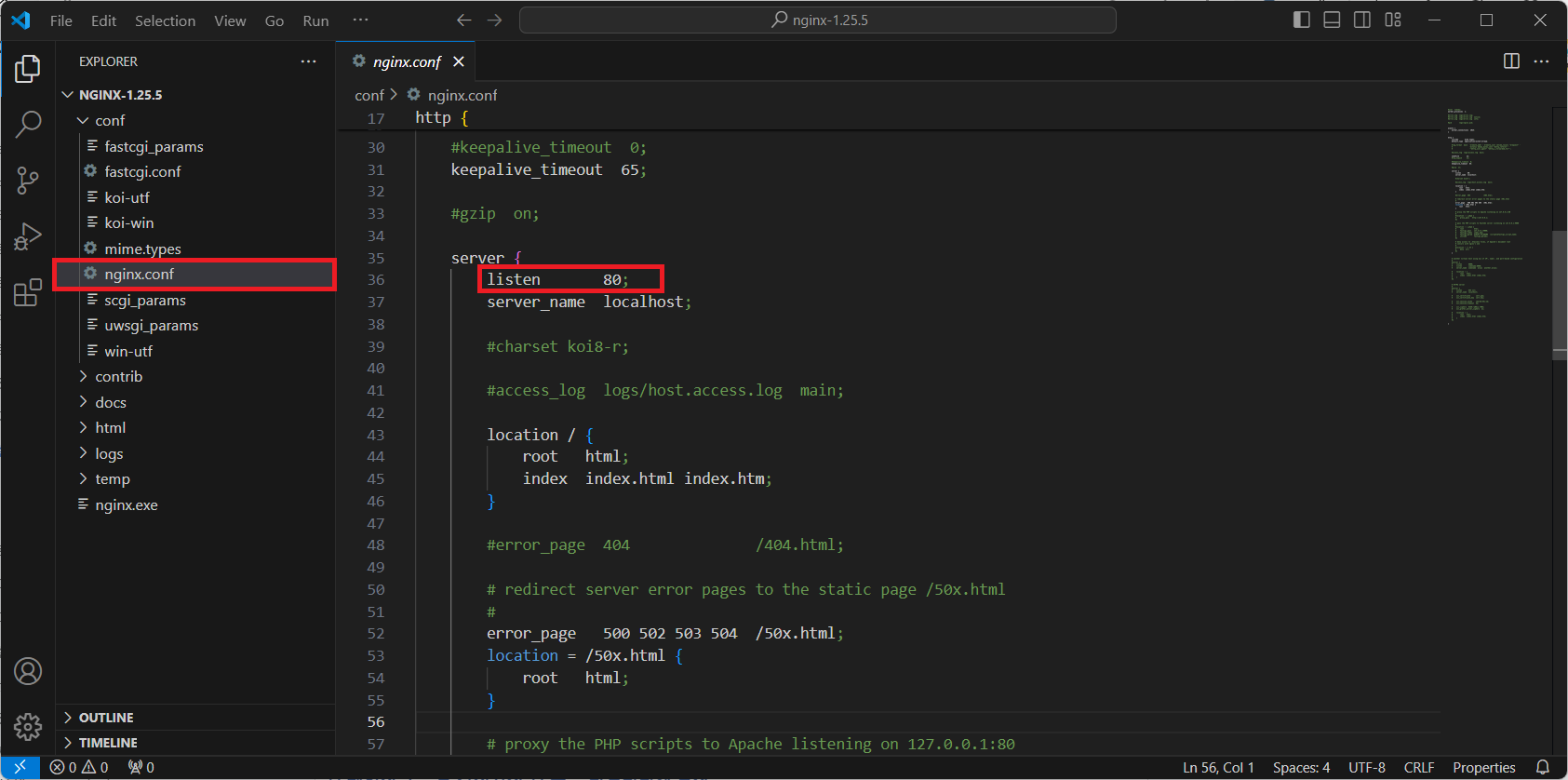
웹 페이지 소스를 가져와서 웹 루트 디렉터리에 복사
https://github.com/PacktPublishing/Getting-Started-with-Elastic-Stack-8.0
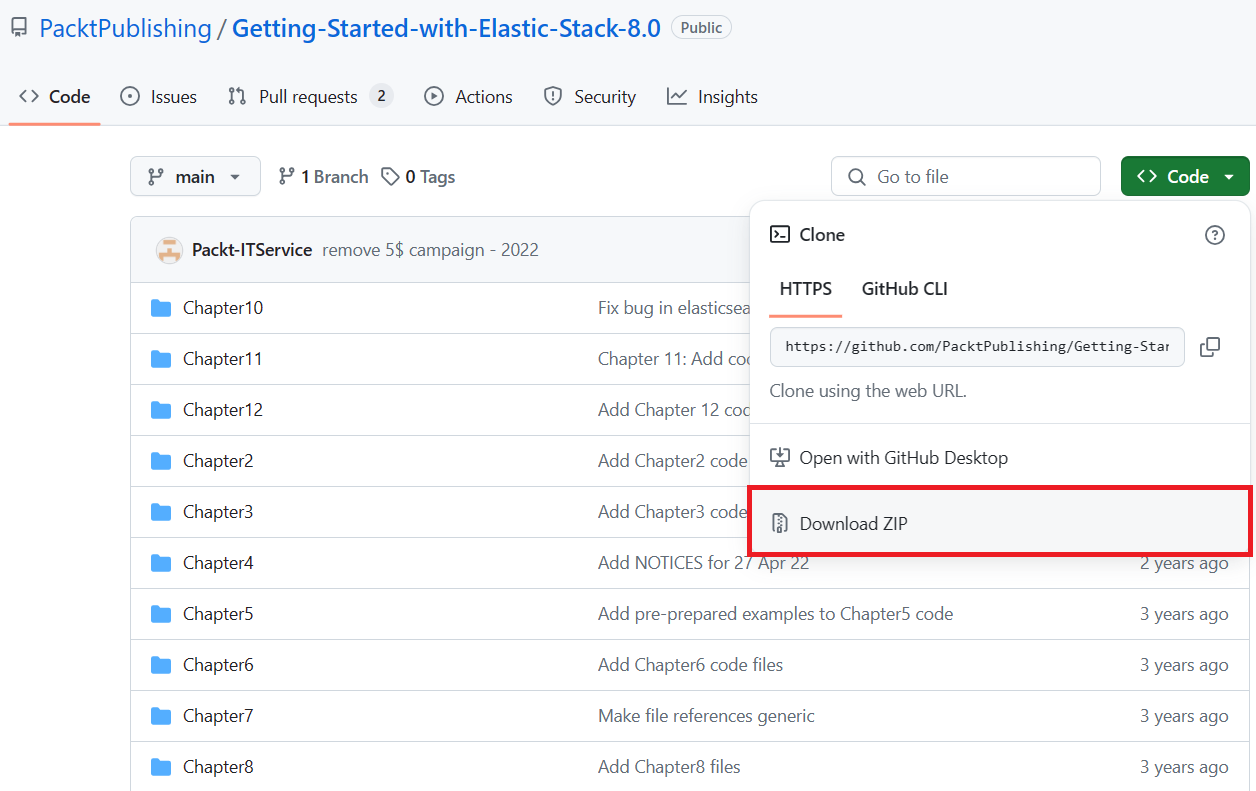
내려받은 파일을 C:\ELK 폴더로 압축해제
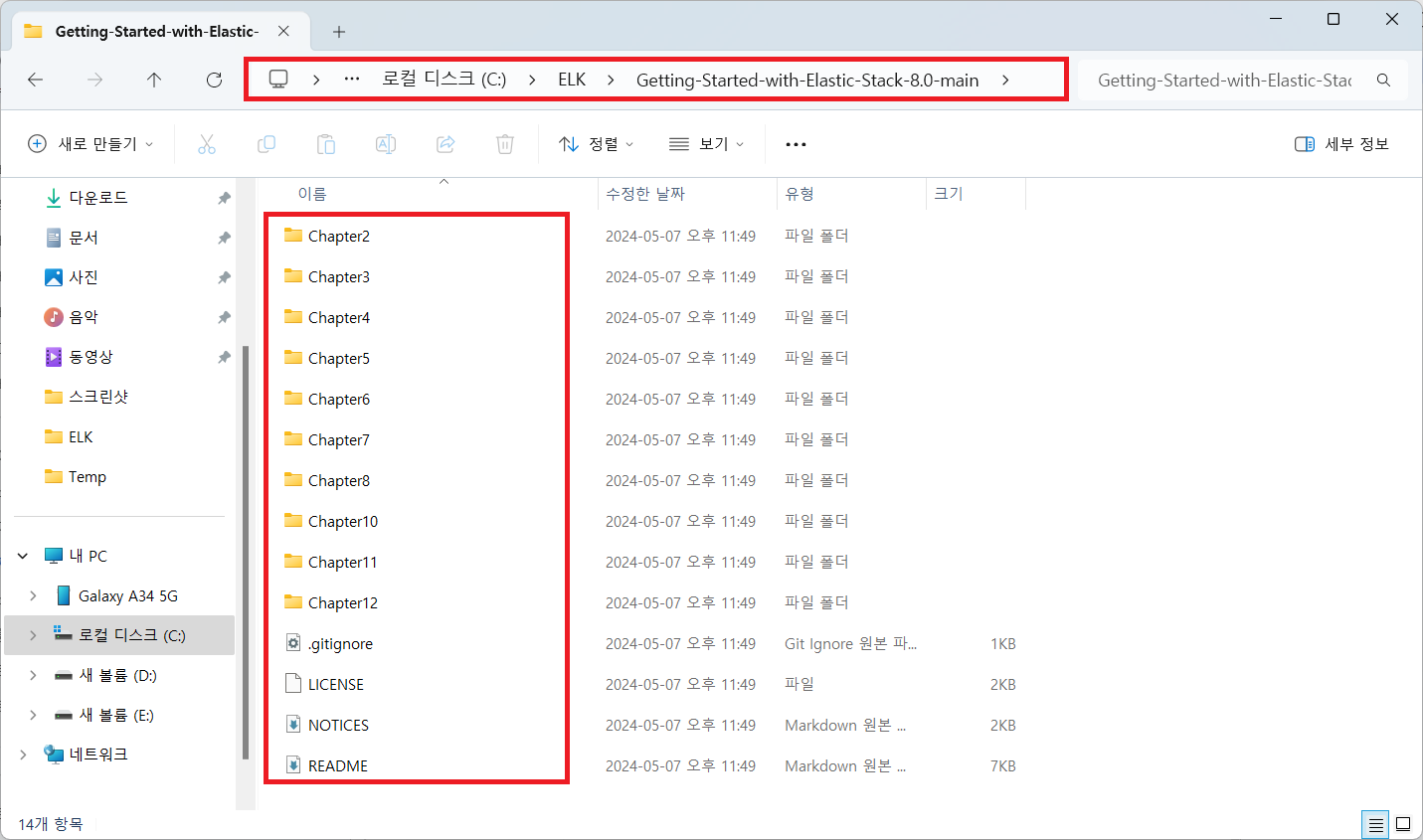
웹 페이지 소스를 웹 루트 디렉터리로 복사
c:\ELK> xcopy /s /e /y c:\ELK\Getting-Started-with-Elastic-Stack-8.0-main\Chapter6\html-webpage\* c:\ELK\nginx-1.25.5\html\
C:\ELK\Getting-Started-with-Elastic-Stack-8.0-main\Chapter6\html-webpage\404.html
C:\ELK\Getting-Started-with-Elastic-Stack-8.0-main\Chapter6\html-webpage\index.html
C:\ELK\Getting-Started-with-Elastic-Stack-8.0-main\Chapter6\html-webpage\css\style.css
C:\ELK\Getting-Started-with-Elastic-Stack-8.0-main\Chapter6\html-webpage\js\scripts.js
4개 파일이 복사되었습니다.
c:\ELK> xcopy /?
파일과 디렉터리 트리를 복사합니다.
/S 비어 있지 않은 디렉터리와 하위 디렉터리를 복사합니다.
/E 비어 있는 경우를 포함하여 디렉터리와 하위 디렉터리를 복사합니다.
/S /E 스위치와 같으며 /T를 수정하는 데 사용될 수 있습니다.
/Y 기존 대상 파일을 덮어쓸지 여부를 묻지 않습니다.
# 웹 루트 디렉터리에 파일이 복사되었는지 확인
c:\ELK> tree c:\ELK\nginx-1.25.5\html /A /F
폴더 PATH의 목록입니다.
볼륨 일련 번호는 9027-83B9입니다.
C:\ELK\NGINX-1.25.5\HTML
| 404.html
| 50x.html
| index.html
|
+---css
| style.css
|
\---js
scripts.js웹 브라우저를 통해 확인
엔진엑스 로그 생성 확인
웹 브라우저로 http://localhost 와 http://localhost/x 로 접속을 몇 차례 시도 후 아래 명령어로 확인
c:\ELK> dir c:\ELK\nginx-1.25.5\logs
C 드라이브의 볼륨에는 이름이 없습니다.
볼륨 일련 번호: 9027-83B9
c:\ELK\nginx-1.25.5\logs 디렉터리
2024-05-07 오후 11:38 <DIR> .
2024-05-07 오후 11:34 <DIR> ..
2024-05-07 오후 11:38 0 access.log
2024-05-07 오후 11:38 0 error.log
2024-05-07 오후 11:38 6 nginx.pid
3개 파일 6 바이트
2개 디렉터리 21,650,751,488 바이트 남음
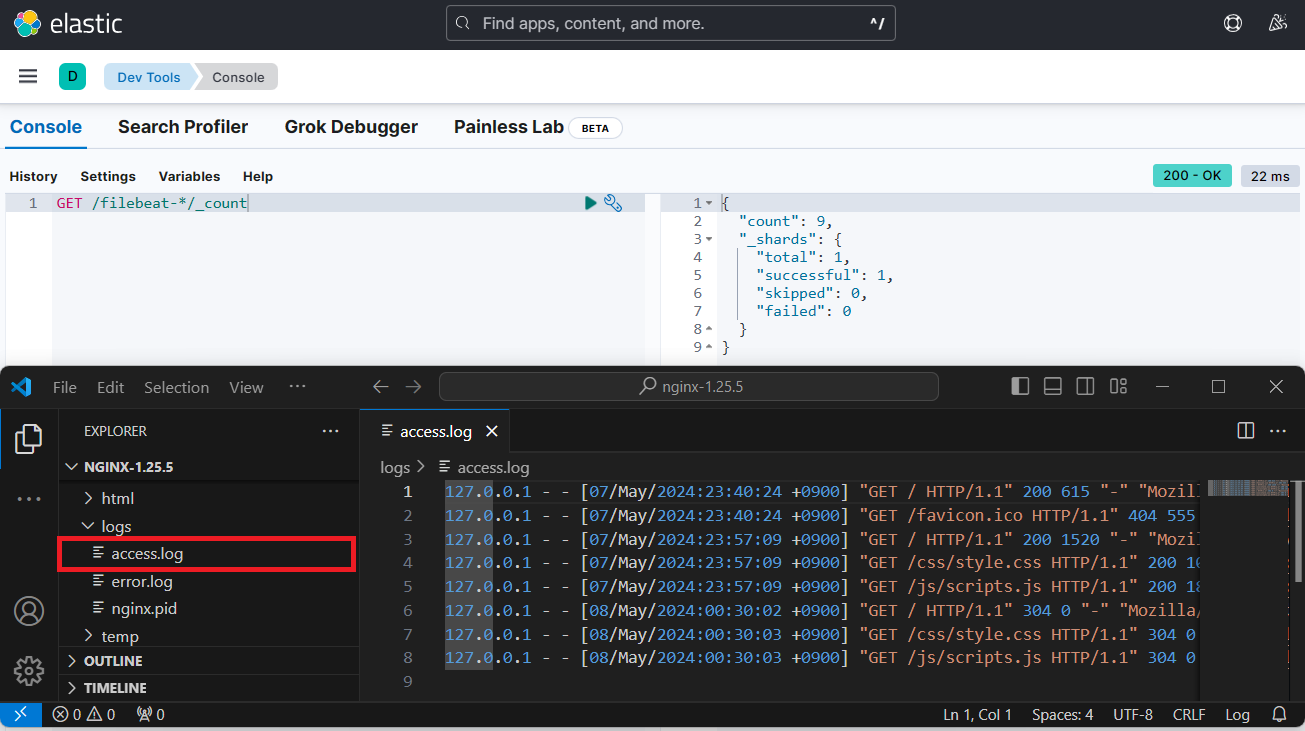
c:\ELK> type c:\ELK\nginx-1.25.5\logs\access.log
127.0.0.1 - - [07/May/2024:23:40:24 +0900] "GET / HTTP/1.1" 200 615 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
127.0.0.1 - - [07/May/2024:23:40:24 +0900] "GET /favicon.ico HTTP/1.1" 404 555 "http://localhost/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
127.0.0.1 - - [07/May/2024:23:57:09 +0900] "GET / HTTP/1.1" 200 1520 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
127.0.0.1 - - [07/May/2024:23:57:09 +0900] "GET /css/style.css HTTP/1.1" 200 1010 "http://localhost/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
127.0.0.1 - - [07/May/2024:23:57:09 +0900] "GET /js/scripts.js HTTP/1.1" 200 1823 "http://localhost/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
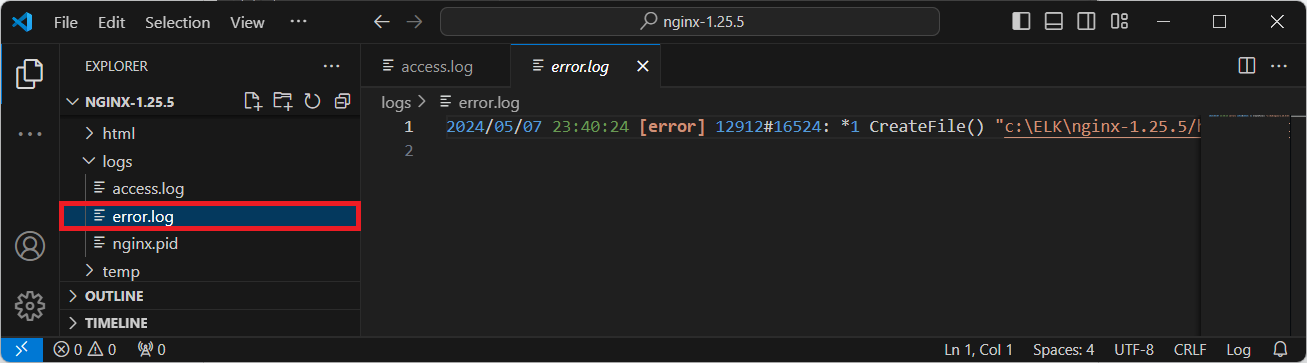
c:\ELK> type c:\ELK\nginx-1.25.5\logs\error.log
2024/05/07 23:40:24 [error] 12912#16524: *1 CreateFile() "c:\ELK\nginx-1.25.5/html/favicon.ico" failed (2: The system cannot find the file specified), client: 127.0.0.1, server: localhost, request: "GET /favicon.ico HTTP/1.1", host: "localhost", referrer: "http://localhost/"📌 파일비트를 이용한 로그 수집
파일비트 에이전트 설치
https://www.elastic.co/kr/downloads/beats/filebeat
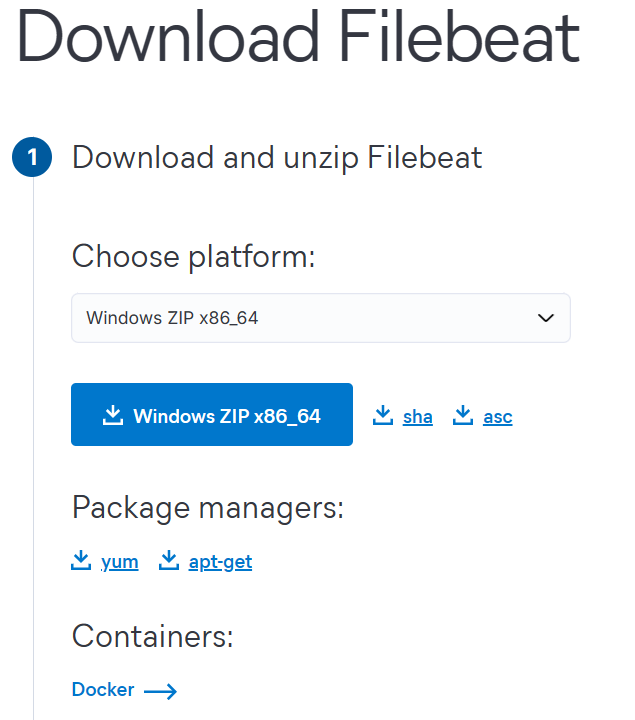
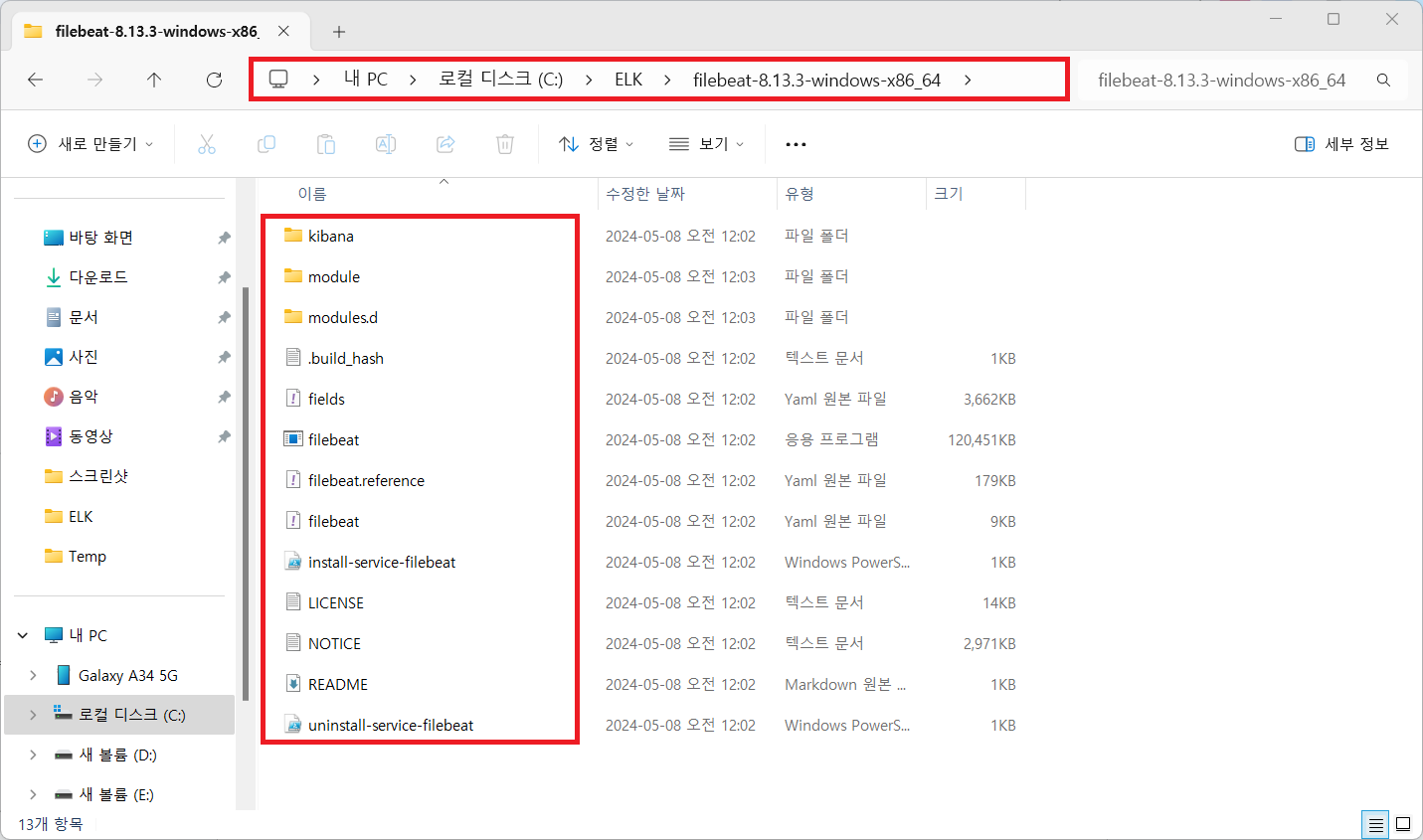
다운로드 받은 filebeat 패키지를 C:\ELK 아래에 압축해제
파일비트 설정
https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-options.html
C:\ELK\filebeat-8.13.3-windows-x86_64\filebeat.yml
###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
# ============================== Filebeat inputs ===============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input-specific configurations.
# filestream is an input for collecting log messages from files.
- type: filestream
# Unique ID among all inputs, an ID is required.
id: my-filestream-id
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
- C:\ELK\nginx-1.25.5\logs\*.log
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
# Line filtering happens after the parsers pipeline. If you would like to filter lines
# before parsers, use include_message parser.
#exclude_lines: ['^DBG']
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
# Line filtering happens after the parsers pipeline. If you would like to filter lines
# before parsers, use include_message parser.
#include_lines: ['^ERR', '^WARN']
# Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#prospector.scanner.exclude_files: ['.gz$']
# Optional additional fields. These fields can be freely picked
# to add additional information to the crawled log files for filtering
#fields:
# level: debug
# review: 1
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
# ================================== General ===================================
# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name:
# The tags of the shipper are included in their field with each
# transaction published.
#tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging
# ================================= Dashboards =================================
# These settings control loading the sample dashboards to the Kibana index. Loading
# the dashboards is disabled by default and can be enabled either by setting the
# options here or by using the `setup` command.
#setup.dashboards.enabled: false
# The URL from where to download the dashboard archive. By default, this URL
# has a value that is computed based on the Beat name and version. For released
# versions, this URL points to the dashboard archive on the artifacts.elastic.co
# website.
#setup.dashboards.url:
# =================================== Kibana ===================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
host: "localhost:5601"
# Kibana Space ID
# ID of the Kibana Space into which the dashboards should be loaded. By default,
# the Default Space will be used.
#space.id:
# =============================== Elastic Cloud ================================
# These settings simplify using Filebeat with the Elastic Cloud (https://cloud.elastic.co/).
# The cloud.id setting overwrites the `output.elasticsearch.hosts` and
# `setup.kibana.host` options.
# You can find the `cloud.id` in the Elastic Cloud web UI.
#cloud.id:
# The cloud.auth setting overwrites the `output.elasticsearch.username` and
# `output.elasticsearch.password` settings. The format is `<user>:<pass>`.
#cloud.auth:
# ================================== Outputs ===================================
# Configure what output to use when sending the data collected by the beat.
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
# Performance preset - one of "balanced", "throughput", "scale",
# "latency", or "custom".
preset: balanced
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
# ------------------------------ Logstash Output -------------------------------
#output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
# ================================== Logging ===================================
# Sets log level. The default log level is info.
# Available log levels are: error, warning, info, debug
#logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors, use ["*"]. Examples of other selectors are "beat",
# "publisher", "service".
#logging.selectors: ["*"]
# ============================= X-Pack Monitoring ==============================
# Filebeat can export internal metrics to a central Elasticsearch monitoring
# cluster. This requires xpack monitoring to be enabled in Elasticsearch. The
# reporting is disabled by default.
# Set to true to enable the monitoring reporter.
#monitoring.enabled: false
# Sets the UUID of the Elasticsearch cluster under which monitoring data for this
# Filebeat instance will appear in the Stack Monitoring UI. If output.elasticsearch
# is enabled, the UUID is derived from the Elasticsearch cluster referenced by output.elasticsearch.
#monitoring.cluster_uuid:
# Uncomment to send the metrics to Elasticsearch. Most settings from the
# Elasticsearch outputs are accepted here as well.
# Note that the settings should point to your Elasticsearch *monitoring* cluster.
# Any setting that is not set is automatically inherited from the Elasticsearch
# output configuration, so if you have the Elasticsearch output configured such
# that it is pointing to your Elasticsearch monitoring cluster, you can simply
# uncomment the following line.
#monitoring.elasticsearch:
# ============================== Instrumentation ===============================
# Instrumentation support for the filebeat.
#instrumentation:
# Set to true to enable instrumentation of filebeat.
#enabled: false
# Environment in which filebeat is running on (eg: staging, production, etc.)
#environment: ""
# APM Server hosts to report instrumentation results to.
#hosts:
# - http://localhost:8200
# API Key for the APM Server(s).
# If api_key is set then secret_token will be ignored.
#api_key:
# Secret token for the APM Server(s).
#secret_token:
# ================================= Migration ==================================
# This allows to enable 6.7 migration aliases
#migration.6_to_7.enabled: truenginx 모듈을 활성화하고 수집할 로그 파일 구성
# filebeat가 설치된 디렉터리로 이동
C:\Windows\system32> cd c:\ELK\filebeat-8.13.3-windows-x86_64
# nginx 모듈 활성화
c:\ELK\filebeat-8.13.3-windows-x86_64> filebeat.exe modules enable nginx
Enabled nginx modules.d 디렉터리 아래에
nginx.yml.disabled 파일을 nginx.yml 파일로 리네임
c:\ELK\filebeat-8.13.3-windows-x86_64> dir .\modules.d
C 드라이브의 볼륨에는 이름이 없습니다.
볼륨 일련 번호: 9027-83B9
c:\ELK\filebeat-8.13.3-windows-x86_64\modules.d 디렉터리
2024-05-07 16:24 <DIR> .
2024-05-07 16:24 <DIR> ..
...(생략)...
2024-05-07 16:12 541 netflow.yml.disabled
2024-05-07 16:12 604 netscout.yml.disabled
2024-05-07 16:12 786 nginx.yml
2024-05-07 16:12 1,537 o365.yml.disabled
2024-05-07 16:12 342 okta.yml.disabled
...(생략)...
69개 파일 77,210 바이트
2개 디렉터리 134,162,231,296 바이트 남음
c:\ELK\filebeat-8.13.3-windows-x86_64>C:\ELK\filebeat-8.13.3-windows-x86_64\modules.d\nginx.yml
# Module: nginx
# Docs: https://www.elastic.co/guide/en/beats/filebeat/8.13/filebeat-module-nginx.html
- module: nginx
# Access logs
access:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:
# Error logs
error:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:
# Ingress-nginx controller logs. This is disabled by default. It could be used in Kubernetes environments to parse ingress-nginx logs
ingress_controller:
enabled: false
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:설정 프로세스 실행
c:\ELK\filebeat-8.13.3-windows-x86_64> filebeat.exe setup --dashboards --pipelines
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Loaded Ingest pipelines파일비트 실행 → 로그 수집 시작
c:\ELK\filebeat-8.13.3-windows-x86_64> filebeat.exe키바나에서 수집된 로그 확인
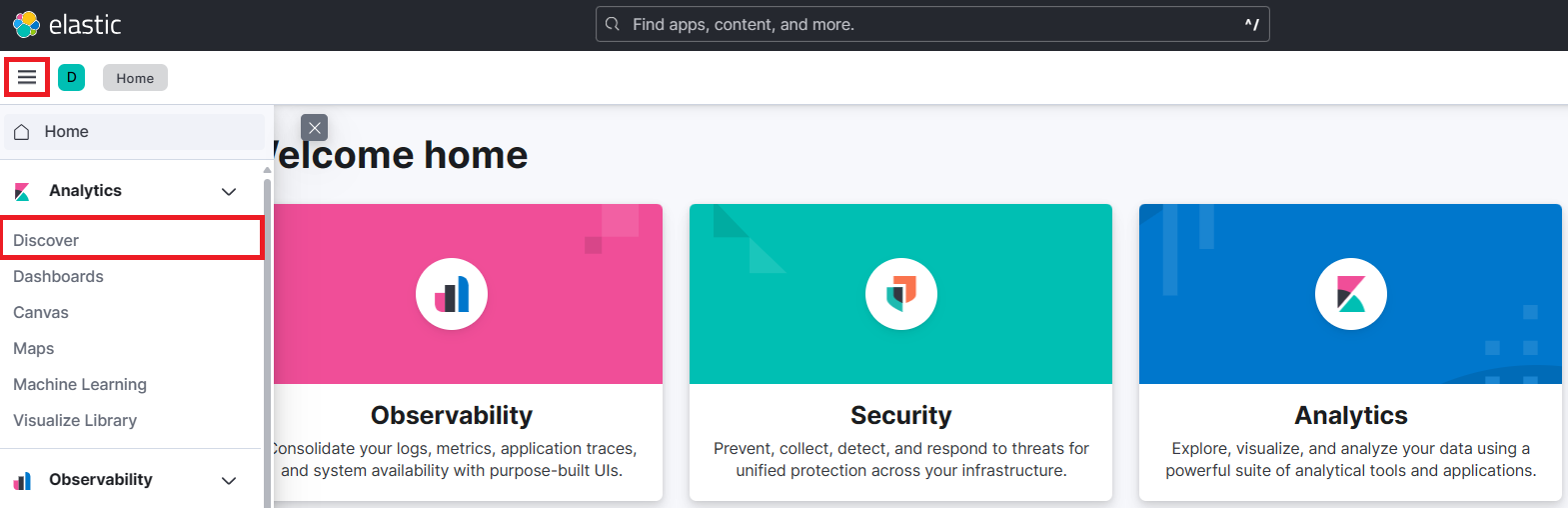
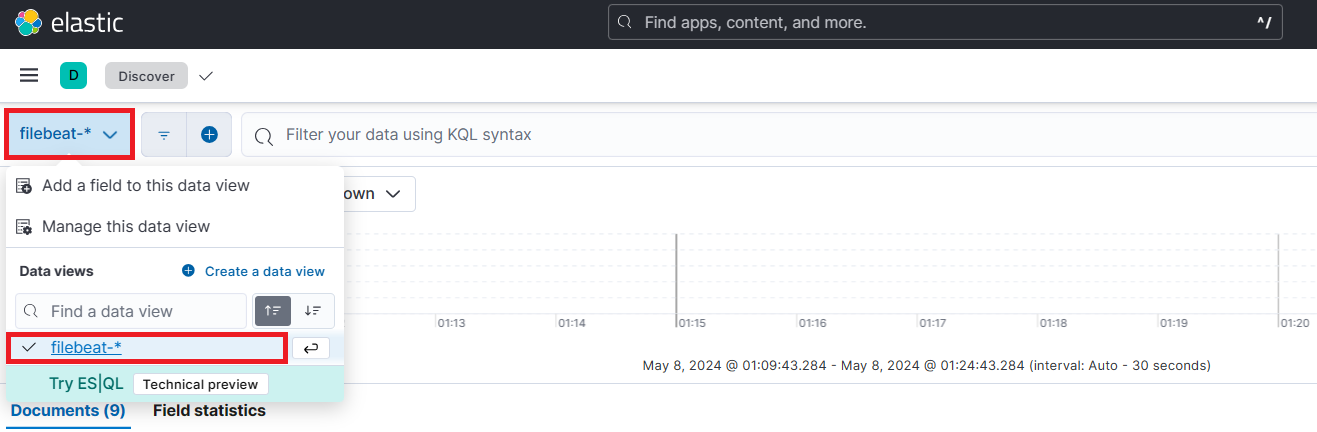
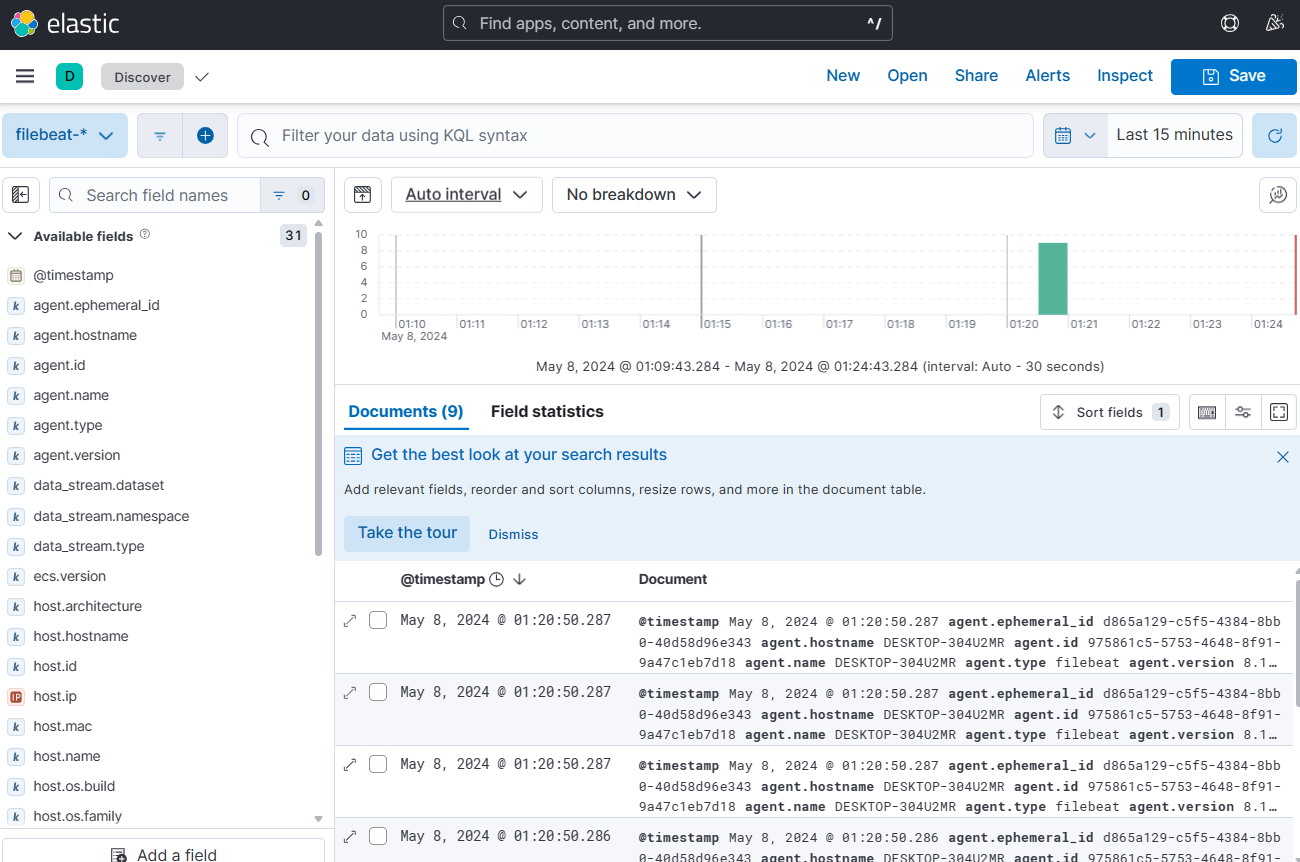
문서 구조
{
"_index": ".ds-filebeat-8.13.3-2024.05.07-000001",
"_id": "1JPbU48BKfOdZyoGwlOW",
"_score": 1,
"_source": {
"@timestamp": "2024-05-07T16:20:47.382Z",
"input": {
"type": "filestream"
},
"ecs": {
"version": "8.0.0"
},
"host": {
"name": "desktop-304u2mr",
"ip": [
"fe80::8c7b:30b:809d:589b",
"169.254.56.238",
"fe80::997e:be58:a0a9:3833",
"169.254.126.211",
"fe80::2e1a:c9e9:fc9b:66e8",
"169.254.14.168",
"fe80::dcae:33b4:a587:676a",
"192.168.174.1",
"fe80::59a0:4a3f:c37d:c925",
"192.168.37.1",
"fe80::1ae7:7df8:36e8:2beb",
"192.168.45.129"
],
"mac": [
"00-50-56-C0-00-01",
"00-50-56-C0-00-08",
"8C-B0-E9-1B-D5-55",
"D0-3C-1F-D3-6A-5D",
"D0-3C-1F-D3-6A-5E",
"D2-3C-1F-D3-6A-5D"
],
"hostname": "desktop-304u2mr",
"architecture": "x86_64",
"os": {
"name": "Windows 11 Pro",
"kernel": "10.0.22621.3447 (WinBuild.160101.0800)",
"build": "22621.3447",
"type": "windows",
"platform": "windows",
"version": "10.0",
"family": "windows"
},
"id": "b693f564-801c-4c5e-8d3e-36bfb9e3d2f1"
},
"agent": {
"type": "filebeat",
"version": "8.13.3",
"ephemeral_id": "d865a129-c5f5-4384-8bb0-40d58d96e343",
"id": "975861c5-5753-4648-8f91-9a47c1eb7d18",
"name": "DESKTOP-304U2MR"
},
"log": {
"offset": 0,
"file": {
"idxhi": "2031616",
"idxlo": "106503",
"vol": "2418508729",
"path": """C:\ELK\nginx-1.25.5\logs\error.log"""
}
},
"message": "2024/05/07 23:40:24 [error] 12912#16524: *1 CreateFile() \"c:\\ELK\\nginx-1.25.5/html/favicon.ico\" failed (2: The system cannot find the file specified), client: 127.0.0.1, server: localhost, request: \"GET /favicon.ico HTTP/1.1\", host: \"localhost\", referrer: \"http://localhost/\""
}
},