
📌 사용자 입출력
input
input 은 사용자가 키보드로 입력한 모든 것을 문자열로 저장
>>> a = input()
Life is too short, you need python
>>> a
'Life is too short, you need python'print는 데이터를 출력시켜줌
>>> a = 123
>>> print(a)
123
>>> a = "Python"
>>> print(a)
Python
>>> a = [1, 2, 3]
>>> print(a)
[1, 2, 3]한 줄에 결괏값을 계속 이어서 출력
매개변수 end 를 사용해 끝 문자를 지정
end 매개변수의 초깃값은 줄바꿈 \n 문자
>>> for i in range(10):
... print(i, end=' ')
...
0 1 2 3 4 5 6 7 8 9 >>>📌 파일 읽고 쓰기
파일 생성
💡 형태
파일 객체 = open(파일 이름, 파일 열기 모드)
# newfile.py
f = open("C:/doit/새파일.txt", 'w')
f.close()파일 열기 모드
r 읽기 모드
파일을 읽기만 할 때 사용
w 쓰기 모드
파일에 내용을 쓸 때 사용
a 추가 모드
파일의 마지막에 새로운 내용을 추가할 때 사용
💡 f.close
파일을 열고나서 닫을 때 쓰는 f.close()는 생략해도 되지만 파일을 제대로 닫지 않고 또 사용할 경우 에러가 발생할 수 있으므로 써주는 것이 좋음
파일을 읽는 방법들
① readline
보통 맨 앞에서부터 시작해서 행 단위로 파일을 읽어들임
② readlines()
파일 내용을 행 단위로 읽어서 리스트로 반환
f = open(r'new_file.txt', 'r', encoding='utf-8')
# for i in range(1, 10):
# f.write(f'{i}번째 라인입니다.\n')
# 파일 내용을 줄 단위로 저장하고 있는 리스트를 반환
lines = f.readlines()
print(lines)
for line in lines:
print(line, end="")
f.close()strip
읽어들인 파일 데이터 함수의 개행 문자 \n 제거
f = open(r'new_file.txt', 'r', encoding='utf-8')
# for i in range(1, 10):
# f.write(f'{i}번째 라인입니다.\n')
# 파일 내용을 줄 단위로 저장하고 있는 리스트를 반환
lines = f.readlines()
print(lines)
for line in lines:
# print(line, end="") # print 함수를 실행할 때 개행문자를 제거
line = line.strip() # 파일 데이터에서 개행문자를 제거
print(line)
f.close()
③ read
파일 내용 전체를 문자열로 리턴
f = open(r'new_file.txt', 'r', encoding='utf-8')
# 파일 내용 전체를 문자열로 반환
lines = f.read()
print(lines)
f.close()파일 객체를 이용해 파일을 읽어들이는 방법
f = open(r'new_file.txt', 'r', encoding='utf-8')
# 방법1. readlines() 함수를 이용
# lines = f.readlines()
# for line in lines:
# print(line, end="")
# 방법2. 파일 객체를 이용하는 방법
for line in f:
print(line, end="")
f.close()④ 파일 객체를 for 문과 함께 사용
파일 객체(f)는 기본적으로 위와 같이 for 문과 함께 사용하여 파일을 줄 단위로 읽어 들임
Ex. for line in f:
파일에 새 내용 추가
이미 존재하는 파일을 열면(w) 그 파일의 내용이 모두 사라지게 됨
이런 경우에 추가 모드(a) 사용
f = open('new_file.txt",'a')⑤ with 문과 함께 사용
with 블록을 벗어나는 순간, 열려있던 파일 객체 f를 close
💡 with ... open
close() 함수를 이용하지 않고 자동으로 파일 객체 반환
# f = open(r'new_file.txt', 'r', encoding='utf-8')
# for line in f:
# print(line, end="")
# f.close()
with open(r'new_file.txt', 'r', encoding='utf-8') as f:
for line in f:
print(line, end="")
# 자동으로 파일 객체 반환📌 실습 #1
성적 데이터 파일을 읽어서 이름, 과목 별 점수, 합계, 평균 정보 출력
코드 짜는 것이 힘들다면 우선 프로그램의 로직만이라도 주석으로 짜보고 그 주석에 맞는 로직을 구현하는 것이 더 쉬움
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
print('====== ==== ==== ==== ==== ====')
print('이 름 국어 영어 수학 합계 평균')
print('====== ==== ==== ==== ==== ====')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
with open('score_data.txt', 'r', encoding='utf-8') as file:
print_title()
for line in file:
line = line.strip()
datas = line.split()
name = datas[0]
scores = datas[1:]
sum = calurate_sum(scores)
average = calurate_average(scores)
print_data(name, scores, sum, average)
결과
====== ==== ==== ==== ==== ====
이 름 국어 영어 수학 합계 평균
====== ==== ==== ==== ==== ====
홍길동 100 90 80 270 90
신길동 90 70 60 220 73
고길동 60 100 20 180 60
====== ==== ==== ==== ==== ====
리팩토링(refactoring)
제일 많이 쓰는 방식은 코드가 길어졌을 때 별도의 함수를 만들어 호출하는 방식으로 변경하는 방식
📌 프로그램 입출력
대부분의 명령 프롬프트에서 사용하는 명령어는 다음과 같이 인수를 전달하여 프로그램을 실행하는 방식을 따름
명령어 [인수1 인수2 ...]
📖 sys 모듈
모듈을 사용해 프로그램에 인수 전달
모듈을 사용하려면 다음 예의 import sys처럼 import 명령어 사용
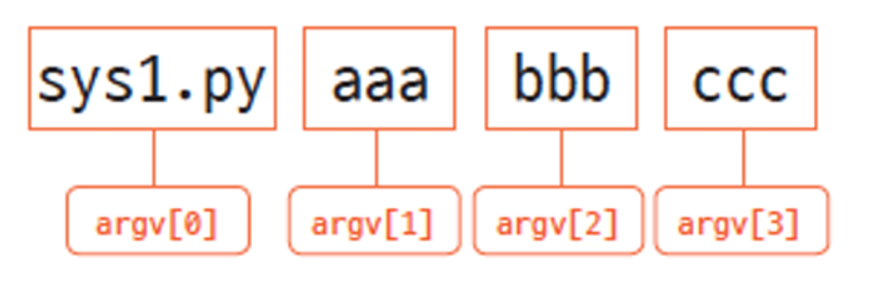
💡 sys.argv
sys는 파이썬 인터프리터와 관련된 정보와 기능을 제공하는 모듈 혹은 라이브러리이고argv는argument(인수)를 의미
Ex. 로컬과 개발 등의 환경이 서로 달라서 인자값을 줘야하는 경우처럼 파일을 다른 목적으로 처리를 해야 할 때 인자값을 줘야 할 텐데 이럴 때 파이썬에서는 sys.argv에 값을 담아 처리 가능
# sys.argv
import sys
print(sys.argv)
dan = 2
for i in range(1, 10):
print(f"{dan} x {i} = {dan * i}")
결과
PS C:\python> python test.py first second third
['test.py', 'first', 'second', 'third']
2 x 1 = 2
2 x 2 = 4
2 x 3 = 6
2 x 4 = 8
2 x 5 = 10
2 x 6 = 12
2 x 7 = 14
2 x 8 = 16
2 x 9 = 18
import sys
print(sys.argv)
dan = int(sys.argv[1])
for i in range(1, 10):
print(f"{dan} x {i} = {dan * i}")
결과
PS C:\python> python test.py 4
4 x 1 = 4
4 x 2 = 8
4 x 3 = 12
4 x 4 = 16
4 x 5 = 20
4 x 6 = 24
4 x 7 = 28
4 x 8 = 32
4 x 9 = 36
📌 실습 #2
프로그램 실행 시 전달받은 문장에 포함된 글자(문자)의 사용 횟수를 계산해 출력
Ex.
python test.py "This is sample program" 입력 ⇒ This is sample program T => 1 h => 1 i => 2 s => 3 :
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
# 글자(키)와 글자의 사용 횟수(값)를 가지는 딕셔너리
char_count = dict()
# 입력받은 문장에서 한 글자씩을 추출해서 딕셔너리에 추가
for char in sentence:
# 딕셔너리에 해당 글자가 존재하는 경우, 사용 횟수를 증가
if char in char_count:
char_count[char] = char_count[char] + 1
# 딕셔너리에 해당 글자가 존재하지 않는 경우, 사용 횟수로 1을 설정해서 추가
else:
char_count[char] = 1
# 딕셔너리를 순회하면서 출력
for char in char_count:
print(f"{char} => {char_count[char]}")
결과
S C:\python> python test.py "This is sample program"
입력 => This is sample program
T => 1
h => 1
i => 2
s => 3
=> 3
a => 2
m => 2
p => 2
l => 1
e => 1
r => 2
o => 1
g => 1📌 실습 #3
위의 프로그램을 (대소문자를 구분하지 않은) 알파벳과 그 횟수로 제한하고 알파벳 순으로 정렬해서 출력하도록 수정해보세요. (공백, 특수문자는 카운팅 대상에서 제외)
Ex.
PS C:\python> python test.py "T & t is sampe char." 입력 => T & t is sampe char. a => 2 c => 1 : i => 1 s => 1 t => 2
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
# 알파벳을 소문자로 변경
char = char.lower()
# 알파벳이 아닌 경우 다음 글자를 처리
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
# 알파벳(키)을 기준으로 정렬한 결과를 알파벳(키) => 횟수(값) 형식으로 출력
for key in sorted(char_count.keys()):
print(f"{key} => {char_count[key]}")
결과
PS C:\python> python test.py "T & t is same alphabet."
입력 => T & t is same alphabet.
a => 3
b => 1
e => 2
h => 1
i => 1
l => 1
m => 1
p => 1
s => 2
t => 3📌 실습 #4
위의 프로그램을 가장 많이 나온 알파벳 순으로 출력하도록 수정
PS C:\python> python test.py "T & t is same alphabet." 입력 => T & t is same alphabet. 3 => [ 'a', 't' ] 2 => [ 'e', 's' ] 1 => [ 'b', 'h', 'i', 'l', 'm' ]
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
char = char.lower()
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
# 횟수(숫자)를 키로 가지고, 문자 리스트를 값으로 가지는 딕셔너리를 정의
# { 3: ['a', 'b', 'c'], 2: ['x', 'y'] }
count_char = {}
for char in sorted(char_count.keys()):
count = char_count[char]
if count in count_char: count_char[count].append(char)
else: count_char[count] = [char]
# 횟수(키) 내림차순으로 정렬해서 출력
for key in sorted(count_char.keys(), reverse=True):
print(f"{key} => {count_char[key]}")📌 프로그램 통합
c:\python\hangman.py
import re
import random
# words = input('여러 단어로 구성된 문장을 입력하세요. ')
words = "Visit BBC for trusted reporting on the latest world and US news, sports, business, climate, innovation, culture and much more."
print(f"입력 : {words}")
# 문장부호를 제거 ! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ` { | } ~ \
words = re.sub(r'[!"#$%&\'()*+,-./:;<=>?@\[\]^_\`{|}~\\\\]', '', words)
# 공백문자를 기준으로 단어를 분리
words = words.split()
# 임의의 단어를 추출
rand_word = list(words[random.randrange(len(words))])
# 화면에 출력할 내용
disp_word = list('_' * len(rand_word))
print(f'힌트 >>> {''.join(disp_word)}')
try_count = 0
while True:
try_count += 1
alpha = input(f'{try_count} 시도 >>> 영어 단어를 구성하는 알파벳을 입력하세요. ')
for i, a in enumerate(rand_word):
if alpha == a:
disp_word[i] = alpha
print(f'힌트 >>> {''.join(disp_word)}')
if disp_word.count('_') == 0:
print(f'정답 "{''.join(rand_word)}"를 {try_count}번 만에 맞췄습니다.')
break
elif try_count >= 10:
print(f'10번에 기회가 모두 끝났습니다. 정답은 "{''.join(rand_word)}" 입니다.')
breakc:\python\score.py
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
# print('====== ==== ==== ==== ==== ====')
# print('이 름 국어 영어 수학 합계 평균')
# print('====== ==== ==== ==== ==== ====')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
print('이 름 국어 영어 수학 합계 평균')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_tail():
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
with open('score_data.txt', 'r', encoding='utf-8') as file:
print_title()
for line in file:
line = line.strip()
datas = line.split()
name = datas[0]
scores = datas[1:]
sum = calurate_sum(scores)
average = calurate_average(scores)
print_data(name, scores, sum, average)
print_tail()c:\python\counter.py
import sys
sentence = sys.argv[1]
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
char = char.lower()
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
# 회수(숫자)를 키로 가지고, 문자 리스트를 값으로 가지는 딕셔너리를 정의
# { 3: ['a', 'b', 'c'], 2: ['x', 'y'] }
count_char = {}
for char in sorted(char_count.keys()):
count = char_count[char]
if count in count_char: count_char[count].append(char)
else: count_char[count] = [char]
# 회수(키) 내림차순으로 정렬해서 출력
for key in sorted(count_char.keys(), reverse=True):
print(f"{key} => {count_char[key]}")c:\python\main.py
================= 1. 행맨 2. 점수계산 3. 알파벳 카운터 Q. 종료 ================= 실행할 프로그램의 번호를 입력하세요. : 1
① 메뉴를 출력하고 메뉴 번호를 입력 받아 동작하는 것을 확인
def show_menu():
print("""
=================
1. 행맨
2. 점수계산
3. 알파벳 카운터
Q. 종료
=================
""")
while True:
show_menu()
menu = input("실행할 프로그램의 번호를 입력하세요. : ")
if menu == 'Q':
print("프로그램을 종료합니다.")
break
menu = int(menu)
if menu == 1:
print("행맨 실행")
elif menu == 2:
print("점수 계산 실행")
elif menu == 3:
print("알파벳 카운트 실행")
else:
print("잘못된 입력입니다. 다시 시도해 주세요.")② 행맨 소스 코드 모듈화
import re
import random
def main(): → main() 함수를 호출해야 실행되도록 수정
#words = input('여러 단어로 구성된 문장을 입력하세요. ')
words = "Visit BBC for trusted reporting on the latest world and US news, sports, business, climate, innovation, culture and much more."
print(f"입력 : {words}")
# 문장부호를 제거 ! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ` { | } ~ \
words = re.sub(r'[!"#$%&\'()*+,-./:;<=>?@\[\]^_\`{|}~\\\\]', '', words)
# 공백문자를 기준으로 단어를 분리
words = words.split()
# 임의의 단어를 추출
rand_word = list(words[random.randrange(len(words))])
# 화면에 출력할 내용
disp_word = list('_' * len(rand_word))
print(f'힌트 >>> {''.join(disp_word)}')
try_count = 0
while True:
try_count += 1
alpha = input(f'{try_count} 시도 >>> 영어 단어를 구성하는 알파벳을 입력하세요. ')
for i, a in enumerate(rand_word):
if alpha == a:
disp_word[i] = alpha
print(f'힌트 >>> {''.join(disp_word)}')
if disp_word.count('_') == 0:
print(f'정답 "{''.join(rand_word)}"를 {try_count}번 만에 맞췄습니다.')
break
elif try_count >= 10:
print(f'10번에 기회가 모두 끝났습니다. 정답은 "{''.join(rand_word)}" 입니다.')
break
if __name__ == '__main__': # 모듈 import 시에는 실행되지 않도록 제한
main() # 모듈을 직접 실행했을 때만 실행
③ main 모듈에서 행맨 모듈을 추가하고 메뉴 선택 시 모듈의 실행 함수 호출
import hangman
→ 행맨 모듈을 (사용하기 위해) 추가
def show_menu():
print("""
=================
1. 행맨
2. 점수계산
3. 알파벳 카운터
Q. 종료
=================
""")
while True:
show_menu()
menu = input("실행할 프로그램의 번호를 입력하세요. : ")
if menu == 'Q':
print("프로그램을 종료합니다.")
break
menu = int(menu)
if menu == 1:
print("행맨 실행")
hangman.main() # 행맨 모듈의 실행 함수를 호출
elif menu == 2:
print("점수 계산 실행")
elif menu == 3:
print("알파벳 카운트 실행")
else:
print("잘못된 입력입니다. 다시 시도해 주세요.")④ 점수 계산 코드 모듈화
def calurate_sum(scores):
sum = 0
for score in scores:
sum += int(score)
return sum
def calurate_average(scores):
return int(calurate_sum(scores) / len(scores))
def print_title():
# print('====== ==== ==== ==== ==== ====')
# print('이 름 국어 영어 수학 합계 평균')
# print('====== ==== ==== ==== ==== ====')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
print('이 름 국어 영어 수학 합계 평균')
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_tail():
print(f'{"="*6} {"="*4} {"="*4} {"="*4} {"="*4} {"="*4}')
def print_data(name, scores, sum, average):
print(f"{name:3}", end=" ")
for score in scores:
print(f"{int(score):4}", end=" ")
print(f"{sum:4}", end=" ")
print(f"{average:4}")
def main():
with open('score_data.txt', 'r', encoding='utf-8') as file:
print_title()
for line in file:
line = line.strip()
datas = line.split()
name = datas[0]
scores = datas[1:]
sum = calurate_sum(scores)
average = calurate_average(scores)
print_data(name, scores, sum, average)
print_tail()
if __name__ == '__main__':
main()⑤ 알파벳 카운트 코드 모듈화
import sys
def main():
# sentence = sys.argv[1]
sentence = input("문장을 입력하세요. ")
print(f"입력 => {sentence}")
char_count = dict()
for char in sentence:
char = char.lower()
if char < 'a' or char > 'z':
continue
if char in char_count: char_count[char] = char_count[char] + 1
else: char_count[char] = 1
count_char = {}
for char in sorted(char_count.keys()):
count = char_count[char]
if count in count_char: count_char[count].append(char)
else: count_char[count] = [char]
for key in sorted(count_char.keys(), reverse=True):
print(f"{key} => {count_char[key]}")
if __name__ == '__main__':
main()⑥ main 모듈에 점수 계산 모듈과 알파벳 카운트 모듈 추가
import hangman
import score
import counter
def show_menu():
print("""
=================
1. 행맨
2. 점수계산
3. 알파벳 카운터
Q. 종료
=================
""")
while True:
show_menu()
menu = input("실행할 프로그램의 번호를 입력하세요. : ")
if menu == 'Q':
print("프로그램을 종료합니다.")
break
menu = int(menu)
if menu == 1:
print("행맨 실행 ...")
hangman.main()
elif menu == 2:
print("점수 계산 실행 ...")
score.main()
elif menu == 3:
print("알파벳 카운트 실행 ...")
counter.main()
else:
print("잘못된 입력입니다. 다시 시도해 주세요.")📌 클래스
클래스
데이터 + 데이터를 다루는 함수
형태
💡 class 클래스 이름:
클래스(class)
똑같은 무언가를 계속 만들어 낼 수 있는 설계 도면(붕어빵 틀)
객체(object)
클래스로 만든 피조물(붕어빵)
붕어빵 틀 = 클래스
붕어빵 = 객체
클래스로 만든 객체의 특징
객체마다 고유한 성격을 가짐
→ 동일한 클래스로 만든 객체들은 서로 전혀 영향을 주지 않음
객체는 클래스로 만들고 1개의 클래스는 무수히 많은 객체를 만들어 낼 수 있음
>>> class Cookie: # 아무런 기능이 없는 클래스
... pass
...
...
...
>>> a = Cookie() # Cookie()의 결괏값을 리턴받은 a와 b가 객체
>>> b = Cookie()클래스 안에 구현된 함수는 메서드(method) 라고 부름
💡 <형태>
def 함수 이름(매개변수): 수행할 문장 ...
객체를 이용해 클래스의 메서드를 호출
도트(.) 연산자 사용
Ex. a.setdata(4, 2)
self
해당 클래스를 통해 생성된 인스턴스를 지칭
self에는 해당 메서드를 호출한 객체 a가 자동으로 전달
파이썬 메서드의 첫 번째 매개변수 이름은 관례적으로 self 사용
객체를 호출할 때 호출한 객체 자신이 전달되기 때문에 self 라는 이름을 사용하지만 다른 이름을 써도 상관은 없음
생성자(constructor)
객체가 생성될 때 자동으로 호출되는 메서드
메서드명으로 __init__ 를 사용하면 이 메서드는 생성자가 됨
__init__ 메서드도 다른 메서드와 마찬가지로 첫 번째 매개변수 self 에 생성되는 객체가 자동으로 전달됨
📌 계산기
class Calculator: # class : 클래스를 정의할 때 사용하는 키워드
# Calculator: 클래스 이름
def __init__(self): # 생성자 : 해당 클래스의 인스턴스가 생성될 때
먼저 호출, 실행되는 메서드(클래스 내에 정의된 함수)
self.result = 0 # 해당 클래스 내의 변수를 초기화 로직이 추가
# self : 해당 클래스를 이용해서 생성된 인스턴스를 의미
def add(self, num):
self.result += num
return self.result
def sub(self, num):
self.result -= num
return self.result
cal1 = Calculator() # Calculator 클래스의 인스턴스를 생성해 cal1 변수에 할당
cal2 = Calculator()
print(cal1.add(3))
print(cal2.add(30))
print(cal1.add(4))
print(cal2.add(40))
print(cal1.sub(10))
print(cal2.sub(10))① 사칙 연산 기능 추가
class Calculator:
def setdata(self, first, second):
self.first = first
self.second = second
def add(self):
return self.first + self.second
def sub(self):
return self.first - self.second
def mul(self):
return self.first * self.second
def div(self):
return self.first / self.second
cal1 = Calculator()
result = cal1.add() # 인스턴스 변수가 정의되지 않은 상태에서
# 값을 사용하려고 한다면 오류 발생
# → 생성자가 필요한 이유
cal1.setdata(10, 20)
result = cal1.add()
print(result) # 30
result = cal1.sub()
print(result) # -10
result = cal1.mul()
print(result) # 200
result = cal1.div()
print(result) # 0.5② 생성자 추가
class Calculator:
def __init__(self): # 변수 초기화 작업
self.first = 0
self.second = 0
def setdata(self, first, second):
self.first = first
self.second = second
def add(self):
return self.first + self.second
def sub(self):
return self.first - self.second
def mul(self):
return self.first * self.second
def div(self):
return self.first / self.second
cal1 = Calculator() # 인스턴스가 생성될 때
# 클래스에서 정의한 생성자가 제일 먼저 호출, 실행
result = cal1.add() # 오류가 발생하지 않음
cal1.setdata(10, 20)
result = cal1.add()
print(result) # 30
result = cal1.sub()
print(result) # -10
result = cal1.mul()
print(result) # 200
result = cal1.div()
print(result) # 0.5③ 클래스를 정의할 때 변수와 메서드를 묶는 이유
class Calculator:
def __init__(self): # 변수 초기화 작업
self.first = 0
self.second = 0
def setdata(self, first, second):
self.first = first
self.second = second
def add(self):
return self.first + self.second
def sub(self):
return self.first - self.second
def mul(self):
return self.first * self.second
def div(self):
return self.first / self.second
cal1 = Calculator()
cal1.setdata(100, 0)
result = cal1.div() # ZeroDivisionError 오류가 발생
print(result)④ div 메서드 수정
class Calculator:
def __init__(self): # 변수 초기화 작업
self.first = 0
self.second = 0
def setdata(self, first, second):
self.first = first
self.second = second
def add(self):
return self.first + self.second
def sub(self):
return self.first - self.second
def mul(self):
return self.first * self.second
def div(self):
if self.second == 0: # 나누는 수(제수)가 0인 경우 0을 반환하도록 수정
return 0
return self.first / self.second
cal1 = Calculator()
cal1.setdata(100, 0)
result = cal1.div() # ZeroDivisionError 오류가 발생하지 않고 0을 반환
print(result) 📌 시계
import time
class Clock:
def __init__(self) -> None:
self.hour = 0
self.miniute = 0
self.second = 0
def print(self):
print(f"{self.hour}:{self.miniute}:{self.second}")
def add_one_hour(self):
self.hour += 1
if self.hour >= 24:
self.hour = 0
def add_one_minute(self):
self.miniute += 1
if self.miniute >= 60:
self.miniute = 0
self.add_one_hour()
def add_one_second(self):
self.second += 1
if self.second >= 60:
self.second = 0
self.add_one_minute()
c = Clock()
while True:
c.add_one_second()
c.print()
# time.sleep(1)📌 모듈
모듈(module)
함수나 변수 또는 클래스를 모아 놓은 코드를 파일 단위로 관리
→ 이 파일을 모듈이라 칭함
파이썬 확장자.py로 만든 파이썬 파일은 모두 모듈
코드의 중복을 줄이고 파일의 재활용성을 높여줌
📢 여기서 잠깐! 파이썬 코드를 작성해 특정 디렉토리에 .py 확장자로 파일을 저장해 본 경험이 있을 것이다. 이 파일을 바로 '모듈'이라고 한다.
모듈의 사용법
💡 import 모듈 이름
또는
💡 from 모듈 이름 import 모듈 함수
→ 모듈 이름 없이 함수 이름만 쓰고 싶은 경우 사용
→ 사용하고 싶은 모듈 함수가 여러 개라면 쉼표(,)로 구분하여 적어줌
→ 모든 모듈 함수를 사용하고 싶다면*기호 사용
>>> import mod1
>>> print(mod1.add(3, 4))
7
>>> from mod1 import add
>>> add(3, 4)
7💡 import
현재 디렉터리에 있는 파일이나 파이썬 라이브러리가 저장된 디렉터리에 있는 모듈만 불러올 수 있음에 유의
📢 여기서 잠깐! 파이썬 라이브러리란?
파이썬을 설치할 때 자동으로 설치되는 파이썬 모듈을 의미
if __name__ == "__main__": 의 의미
# mod.py
def add(a,b):
return a+b
print(add(1,2))여기서 mod 파일을 실행시킬 경우, print 함수로 인해 결괏값인 3도 같이 출력
→ 다른 파일에서 mod 파일을 import 하여 사용할 경우, 이 결괏값이 필요가 없어지는데 이럴 때 쓰는 게 if __name__ == "__main__"
# mod.py
def add(a,b):
return a+b
if __name__ == '__main__':
print(add(1,2))if 문을 사용하면 C:\doit>python mod1.py 처럼 이 파일을 직접 실행했을 때, __name__ == "__main__" 의 값이 참이 되기 때문에 결괏값이 출력됨
하지만 우리가 다른 파일에서 mod를 부르면 __name__ == "__main__" 의 값이 거짓이 되기 때문에 print 값은 출력되지 않음
→ mod 파일 안에서 코드를 실행하면 __name__ 변수에 __main__ 값이 저장
→ 다른 파일에서 mod를 부르면 __name__ 변수에는 mod (모듈 이름 값) 이 저장
💡
__name__
파이썬이 내부적으로 사용하는 특별한 변수
밑줄을 긋는 이유는 해당하는 모듈을 독립적으로 실행했을 때
실행되는 코드들을 넣어주기 위한 것
클래스나 변수 등을 포함한 모듈
모듈은 함수 뿐만 아니라 클래스나 변수도 포함 가능
# mod2.py
PI = 3.141592
class Math:
def solv(self, r):
return PI * (r ** 2)
def add(a, b):
return a+b
C:\Users\pahkey> cd C:\doit
C:\doit> python
>>> import mod2
>>> print(mod2.PI) # mod2.py 파일에 있는 PI 변수의 값 사용
3.141592
>>> a = mod2.Math() # mod2.py 파일에 있는 Math 클래스 사용
>>> print(a.solv(2))
12.566368
>>> print(mod2.add(mod2.PI, 4.4)) # mod2.py 파일에 있는 add 함수 사용
7.541592다른 파일에서 모듈 불러오기
import 하려는 파일과 현재 파일이 같은 디렉토리 안에 있어야 구문이 정상적으로 실행
# modtest.py
import mod2
result = mod2.add(3, 4)
print(result)sys.path.append
sys 모듈은 파이썬을 설치할 때 함께 설치되는 라이브러리 모듈
sys.path 는 파이썬 라이브러리가 설치되어 있는 디렉터리 목록을 보여줌
💡 모듈이 있는 위치를 append(추가)시켜주는 역할
이 디렉터리 안에 저장된 파이썬 모듈은 모듈이 저장된 디렉터리로 이동할 필요 없이 바로 불러 사용 가능
C:\doit>python
>>> import sys
>>> sys.path.append("C:/doit/mymod")
>>> sys.path
['', 'C:\\Windows\\SYSTEM32\\python311.zip', 'c:\\Python311\\DLLs',
'c:\\Python311\\lib', 'c:\\Python311', 'c:\\Python311\\lib\\site-packages',
'C:/doit/mymod']
>>>PYTHONPATH 환경변수 사용
set 명령어를 사용해 디렉토리 설정
이후, 디렉토리 이동이나 별도의 추가 작업 없이 모듈 불러오기 가능
C:\doit>set PYTHONPATH=C:\doit\mymod
C:\doit>python
>>> import mod2
>>> print(mod2.add(3, 4))
7