apollo clinet cache란?
apollo client cache란 말 그대로 apollo를 사용하는 client에서 컨트롤할 수 있는 캐시를 가리킨다. apollo clinet에서 캐시를 사용하기 위해서는 아래와 같이 초기화하는 과정이 필요하다.
import { InMemoryCache, ApolloClient } from '@apollo/client';
const client = new ApolloClient({
// ...other arguments...
cache: new InMemoryCache(options)
});
출처: https://www.apollographql.com/docs/react/caching/cache-configuration/캐시를 사용했을 때 장점은 빠른 응답속도이다. 이전에 api를 요청했을 때 데이터를 메모리에 캐싱해두고, 다음에 같은 요청이 들어왔을 때 서버에 요청하는 대신 메모리에 있는 값을 가져와 반환하는 형태인 것이다. apollo client cache는 이러한 작업을 자동화하고, cache를 읽고 쓰고, 변형하는 각종 도구를 제공한다.
작동방식
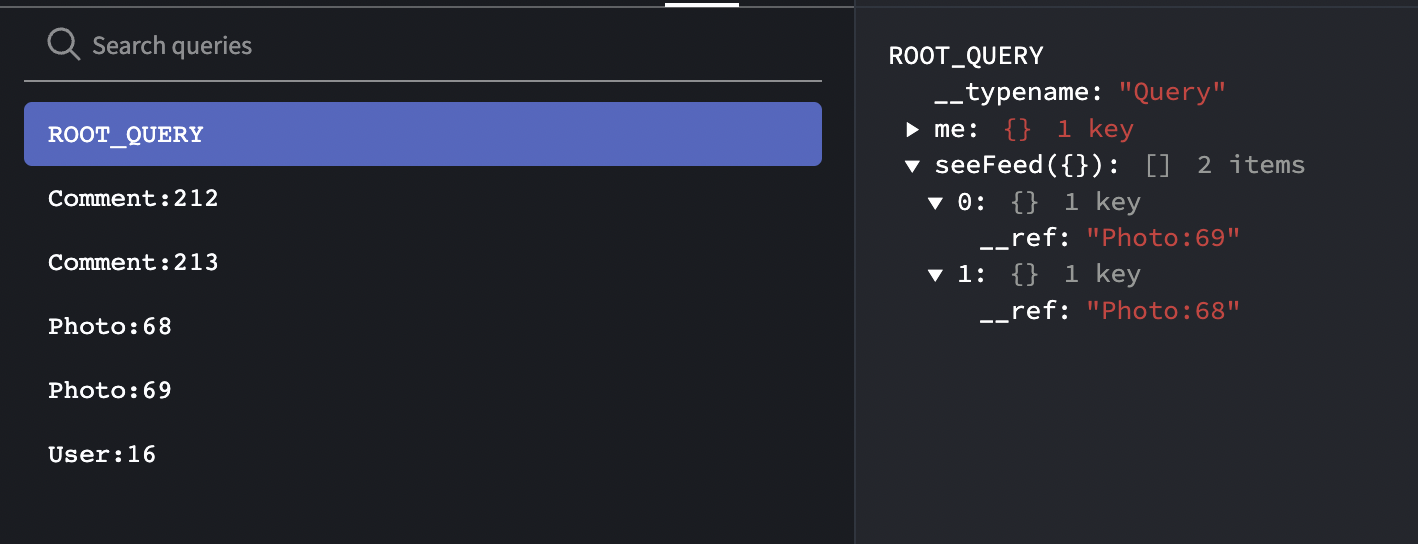
apollo는 쿼리를 호출하면 ROOT_QUERY를 key로 갖는 캐시를 기본적으로 생성한다. ROOT_QUERY는 object를 value로 갖는데, 각 데이터는 api의 이름과 호출에 사용된 variables 조합을 key로, 서버의 응답을 value로 갖는다. 즉, 같은 쿼리를 호출해도 그 변수가 다르다면 서로 다른 위치에 캐시가 저장되는 것이다.
"ROOT_QUERY":{
seeProfile({"username":"somebody"}):{
__ref: "User:1"
}
},
"User:1":{
username:"somebody",
age:17
}예시로 작성한 캐시 구조를 보면 seeProfile이라는 쿼리의 응답값이 reference 형태인 것을 볼 수 있을 것이다. 이처럼 아폴로 캐시는 ROOT_QUERY 하위에 모든 데이터를 입력하지 않고, 별도의 Fragment를 구성한뒤, 해당 데이터를 ROOT_QUERY가 참조하는 형태로 캐시가 구성되어 있다. 여기서 Fragment는 데이터타입과 id의 조합으로 네이밍된다.
실제 apollo client cache의 구조 (Apollo Client Devtools)
프론트에서 캐시를 다룰 때의 마음가짐
실제 react 프로젝트에서는 cache를 어떻게 사용할 수 있을까? react에서 apollo cache는 마치 state처럼 동작한다. useState를 사용해 api의 응답값을 state에 저장하지 않아도, 캐시를 수정하는 것만으로 해당 cache를 참조하고 있는 컴포넌트는 자동으로 리렌더링된다. 게다가 cache는 모든 컴포넌트에서 접근이 가능하기 때문에 cache를 잘만 컨트롤하면 별도의 상태관리 도구를 사용하지 않고도 간편하게 클라이언트 상태를 관리할 수 있게 된다. (reactiveVar까지 사용하면 정말 별도의 상태관리 도구를 사용할 필요가 없어진다.) 여기서 한발 나아가 캐시 자체를 가까운 데이터베이스라고 여기는 마음가짐까지 가진다면 코드를 한결 간결하게 작성할 수 있다.
실제 캐시 사용 예시
간단한 예시를 들자면 다음과 같다. 서비스를 구축하다보면 서비스 전반에 걸쳐 현재 로그인중인 사용자의 정보가 필요할 때가 종종 발생한다. 이때 일반적인 경우라면 context api나 redux, recoil 등 상태관리 도구를 사용해 전역으로 사용자 데이터를 관리해야 할 것이다. 하지만 apollo client cache를 사용하면 그냥 사용자 정보가 필요한 시점에 쿼리를 날리기만 하면 된다. porp drilling이 불가피한 상황에서도 필요한 모든 데이터를 보내는 대신에 쿼리를 호출할 최소한의 id만 prop으로 보낸다면 해당 컴포넌트에서 다시 쿼리를 호출해 캐시에 저장된 데이터를 가져올 수 있다. 게시글을 등록하거나, 좋아요를 누르거나, 댓글을 삭제하는 경우에도 mutation을 실행한 뒤에 response가 성공적이라면 캐시를 직접 수정하여 화면에 반영할 수도 있다. 이러한 일련의 과정이 state 없이 오직 cache만으로 가능하다.
