REST API 와 GraphQL
REST API
(Representational State Transfer API)
- 기계와 기계가 규격화된 방식으로 웹을 이용해서 통신할 수 있도록 돕는 통신 규칙
- 웹의 통신 규약인 http 프로토콜을 기반으로 요청과 응답을 정의하는 방식
- 컴퓨터의 기능을 실행시키는 명령 이라고 할 수 있다
document.write(’hello world’) - 내 컴퓨터가 아니라 남의 컴퓨터를 실행시킨다
즉, 다른 컴퓨터 또는 서버를 조작하고 그 결과를 가져오는 데 사용된다 - Amazon, Google, Facebook, LinkedIn 및 Twitter와 같은 다양한 웹 사이트는 사용자가 이러한 클라우드 서비스와 통신할 수 있도록 하는 REST 기반 API를 사용
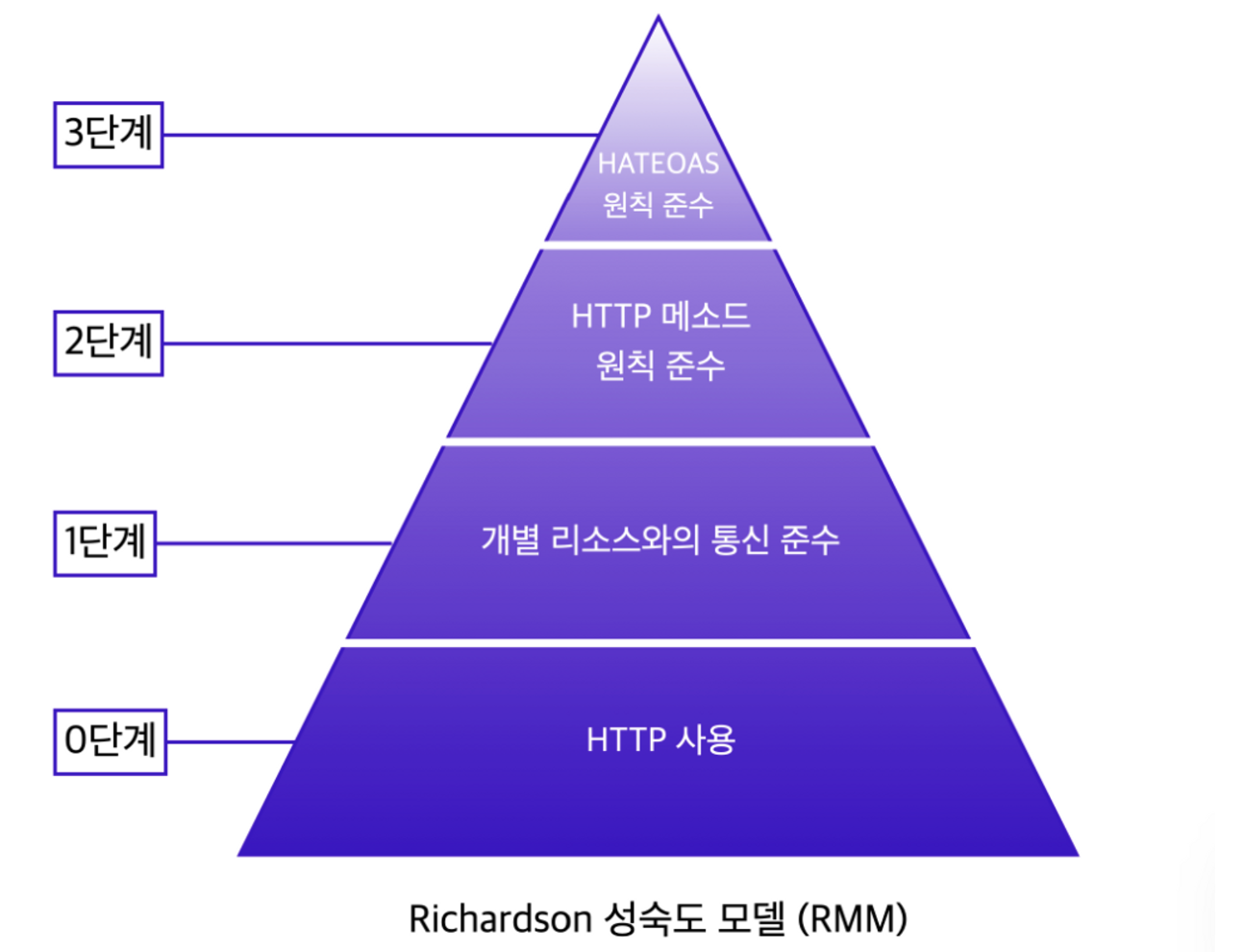
REST 성숙도 모델
Leonard Richardson은 API 등급을 매기기 위해 Richardson 성숙도 모델을 개발
- REST 준수 점수가 높은 API가 더 나은 성능을 보이는 것으로 간주한다
*사례: 주치의 예약 시스템
REST 성숙도 모델 - 0단계
- 단순히 HTTP 프로토콜 사용하기
- 해당 API는 REST API라고 할 수는 없고 REST API를 작성하기 위한 기본 단계라고 볼 수 있다

REST 성숙도 모델 - 1단계
- 개별 리소스와의 통신을 준수한다
즉, 웹에서 사용되는 모든 데이터나 자원을 HTTP URI로 표현한다 - 따라서 모든 자원은 개별 리소스에 맞는 적절한 엔드포인트를 사용하고, 요청에 대한 정보를 응답으로 전달해야 한다
📍 엔드포인트
리소스에 집중하면서 명사 형태의 단어로 작성
응답으로 리소스를 전달할 때,
사용한 리소스에 대한 정보와 리소스 사용에 대한 성공/실패 여부 반환이 필요하다

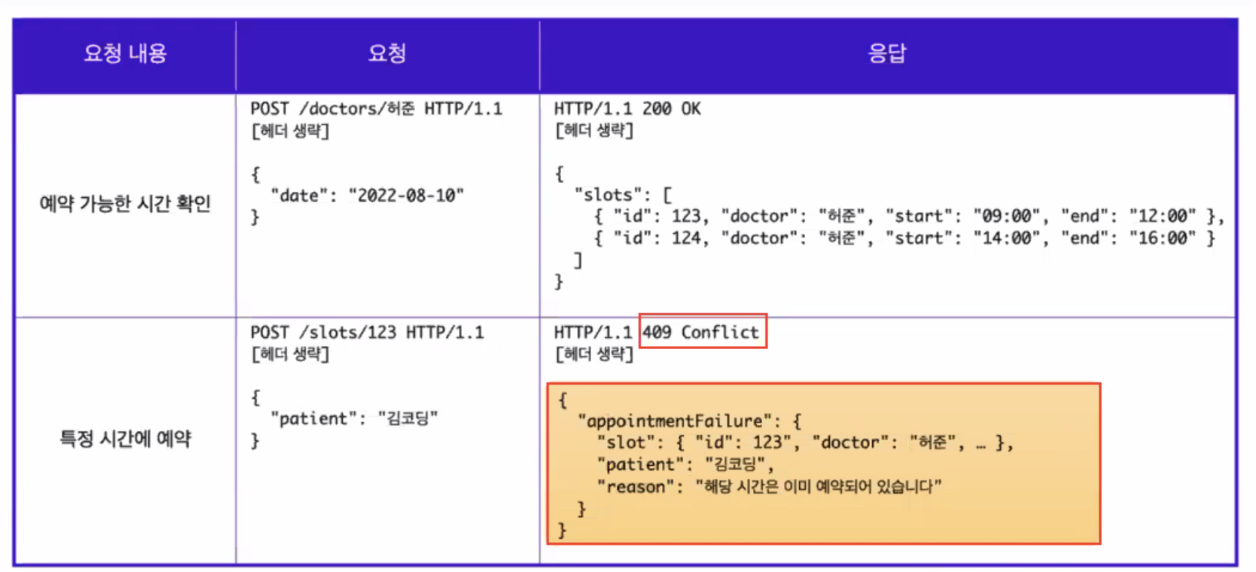
- 0단계에서는 요청의 엔드포인트로 모두 /appointment를 사용했지만 1단계에서는 요청하는 리소스에 따라 각기 다른 엔드포인트로 구분하여 사용한다
- 예약 요청시 /doctors/허준 이라는 엔드포인트 사용
- 특정 시간 요청시 /slots/123 으로 실제 변경되는 리소스를 엔드포인트로 사용
- 사용한 리소스에 대한 정보와 리소스 사용에 대한 성공/실패 여부 반환이 필요하다
- 실패시 실패한 이유도 반드시 작성!
REST 성숙도 모델 - 2단계
- CRUD에 맞게 적절한 HTTP 메서드를 사용하는 것에 중점
- 0 ~ 1단계에서는 모든 요청을 POST 메서드를 사용했다
- HTTP 메서드 사용할 때의 규칙
- GET 메서드의 경우 서버 데이터를 변화시키지 않는 요청에 사용
- POST 메서드는 요청마다 새로운 리소스를 생성, PUT 메서드는 요청마다 같은 리소스를 반환
- 매 요청마다 같은 리소스를 반환하는 특징을 멱등(idempotent)하다고 한다
- 멱등성을 가지는 메서드 PUT과 그렇지 않은 메서드 POST는 구분해서 사용한다
PUT 메서드는 클라이언트가 서버의 리소스를 갱신 또는 생성할 때 사용됩니다. 만약 클라이언트가 동일한 데이터로 PUT 요청을 여러 번 보내더라도 결과는 항상 동일한 리소스의 갱신이나 생성이 일어납니다. 따라서 PUT 메서드는 멱등합니다.
POST 메서드는 새로운 리소스를 생성할 때 사용되며, 여러 번 요청을 보내면 새로운 리소스가 중복 생성될 수 있습니다. 따라서 POST 메서드는 멱등하지 않습니다.
멱등한 작업은 동일한 요청을 반복해도 항상 동일한 결과를 보장하며, 이것은 웹 API의 안정성과 예측 가능한 동작을 보장하는 중요한 개념입니다.
- PUT 메서드와 PATCH 메서드도 구분해서 사용한다
- PUT은 교체
- PATCH는 수정의 용도
- REST 성숙도 모델 2단계까지 적용하면 대체적으로 잘 작성된 API이다

- 0,1단계에서는 모든 요청을 POST 메서드를 사용했다
- 예약 가능한 시간 확인 - 조회 (READ)
- GET 메서드로 요청
- GET은 body 가지지 않기 때문에 query parameter 사용해서 필요한 리소스를 전달한다
- 특정 시간에 예약(특정 예약 시간을 생성) - 생성(CREATE)
- POST 메서드를 사용해서 요청
- 응답은 새롭게 생성된 리소스를 보내주기 때문에 응답 코드는 201 Created로 명확히 작성
- 관련 리소스를 클라이언트가 Location 헤더에 작성된 URI를 통해 확인할 수 있도록 한다
- 예약 가능한 시간 확인 - 조회 (READ)
REST 성숙도 모델 - 3단계
- HATEOAS (Hypertext As The Engine Of Application State - 클라이언트가 서버의 응답을 통해 어떤 동작을 수행할 수 있는지를 자체적으로 파악할 수 있도록 해주는 개념)
- 하이퍼 미디어 컨트롤 적용
- 2단계와 동일하지만, 응답에 리소스의 URI를 포함한 링크 요소 삽입해서 작성
- 링크 요소는 응답 받은 다음 할 수 있는 다양한 액션을 위한 하이퍼미디어 컨트롤을 포함
- 응답 내에 새로운 링크를 넣어 새로운 기능에 접근할 수 있도록 하는 것이 핵심
- 링크를 통해 쉽고 효율적으로 리소스와 기능에 접근할 수 있다

- 링크를 통해 쉽고 효율적으로 리소스와 기능에 접근할 수 있다
GraphQL
(Graph + Query Language)
- Facebook에서 처음으로 개발, 오픈 소스로 제공된 쿼리 언어
- Query Language 중에서도
Server API 를 통해 정보를 주고받기 위해 사용하는 Query Language를 의미 - 2016년 처음으로 등장해 현재까지 인지도 및 만족 부분에서 높은 비율을 차지하고 있는 쿼리 언어
- 개발자들 사이에서 인식률이 굉장히 높은 언어
- 배우고 싶은 비율과 다시 사용하겠다는 비율이 굉장히 높은 언어
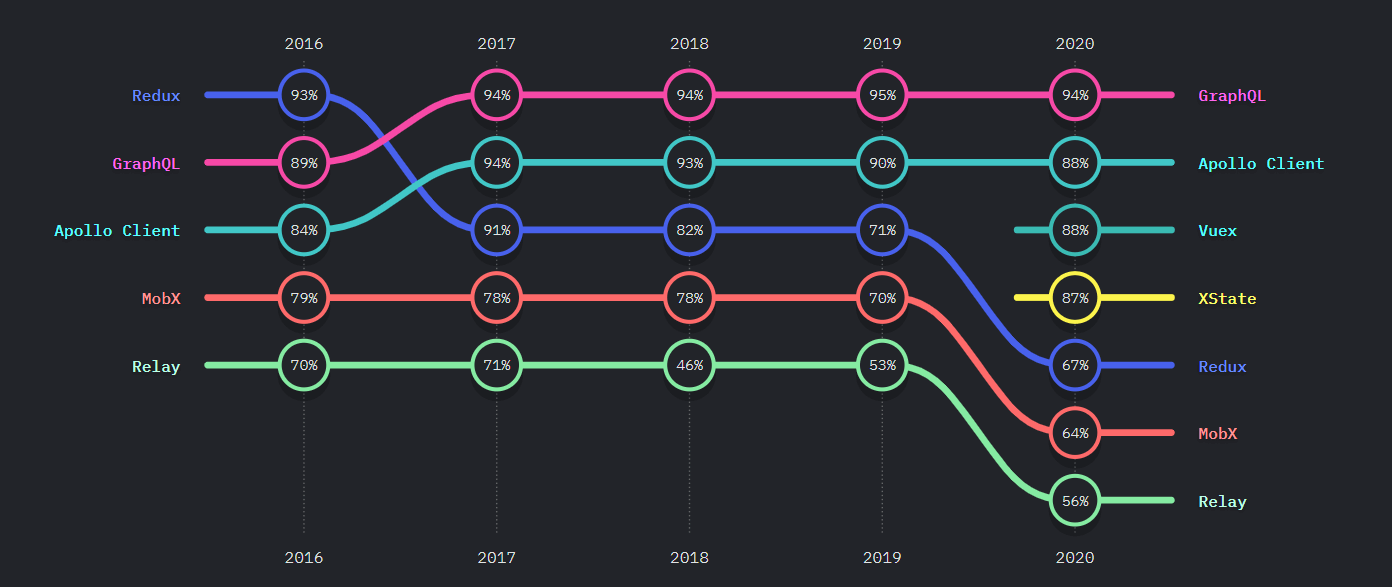
State of JavaScript 2022
* 왜 사용하는가? * GraphQL의 아이디어는 **그래프로 생각하기**에서부터 출발 * 그래프라는 자료구조는 인간의 뇌 구조 및 언어적인 설명과 비슷하기 때문에 실제 현실 세계의 많은 현상들을 모델링할 수 있는 강력한 도구 * 간선을 통해 특정한 순서에 따라 그래프를 재귀적으로 탐색할 수 있다
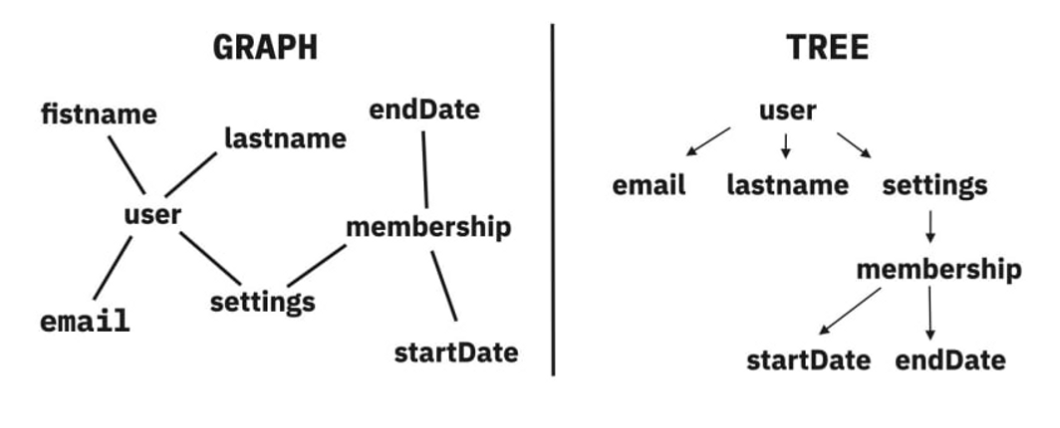
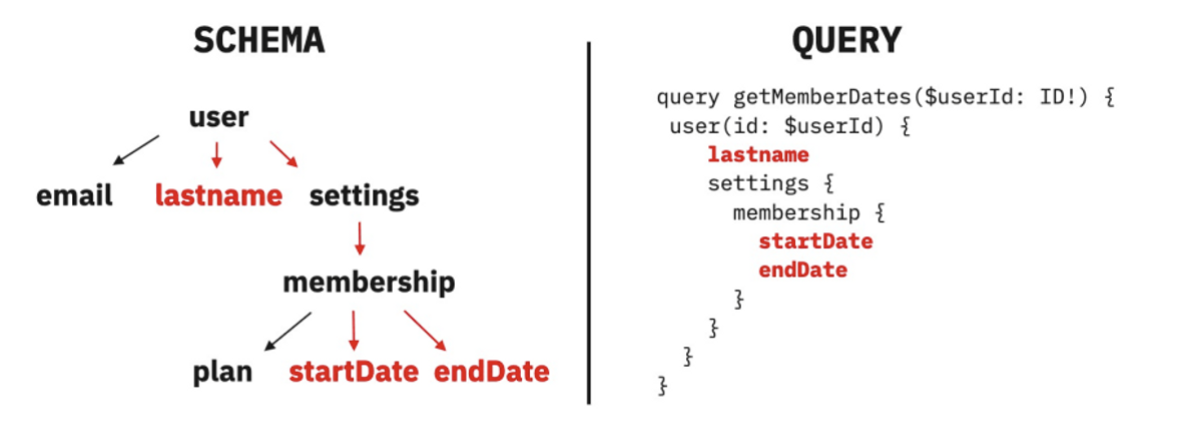
-
모든 데이터가 그래프 형태로 연결되어 있다고 전제
-
클라이언트 요청에 따라 유연하게 트리 구조의 JSON 데이터를 응답으로 전송한다
-
REST API 방식의 고정된 자원이 아닌 클라이언트 요청에 따라 유연하게 자원을 가져올 수 있다는 점에서 엄청난 이점
-
사용 예시
- 사례) 도서관의 도서 목록 시스템 구축
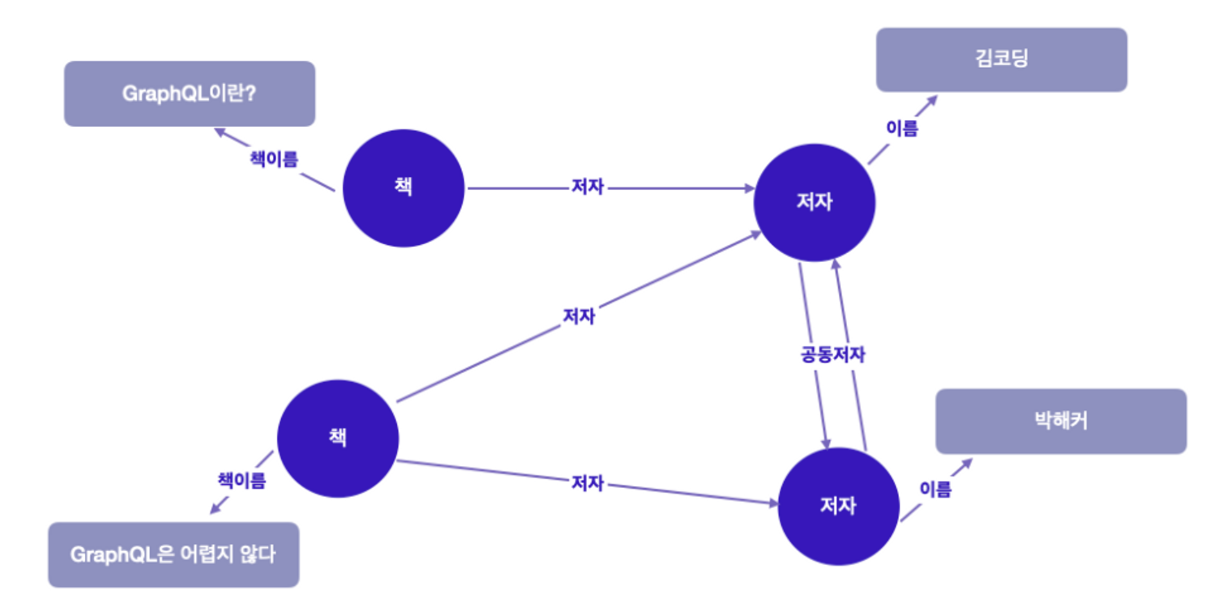
- 사례) 도서관의 도서 목록 시스템 구축
// 위 그래프에서 실행할 수 있는 쿼리
query {
책(ISBN이 "9780674430006") { //이 노드에서 시작 (조건)
책 이름
저자 {
이름
}
}
}
// 돌아오는 쿼리
{
책 : {
책 이름 : "GraphQL은 어렵지 않다",
저자 : [
{ 이름 : "김코딩"},
{ 이름 : "박해커"},
]
}
}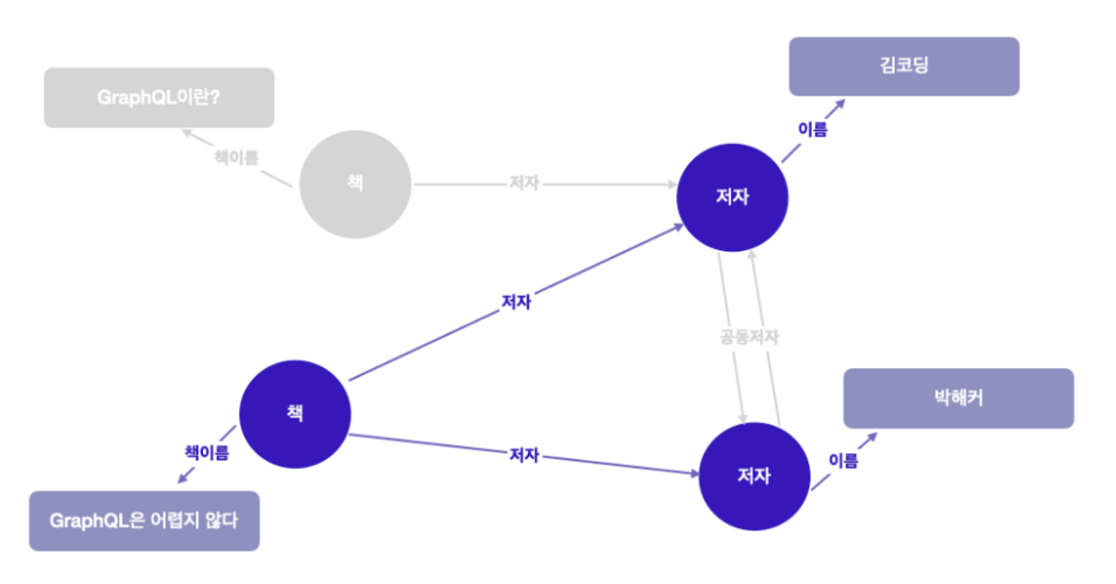
- 그래프 관점에서 봤을 경우
- ISBN 번호를 사용하여 선택한 “책" 노드에서 시작
- 중첩된 각 필드로 표시된 간선을 따라 그래프를 탐색하기 시작
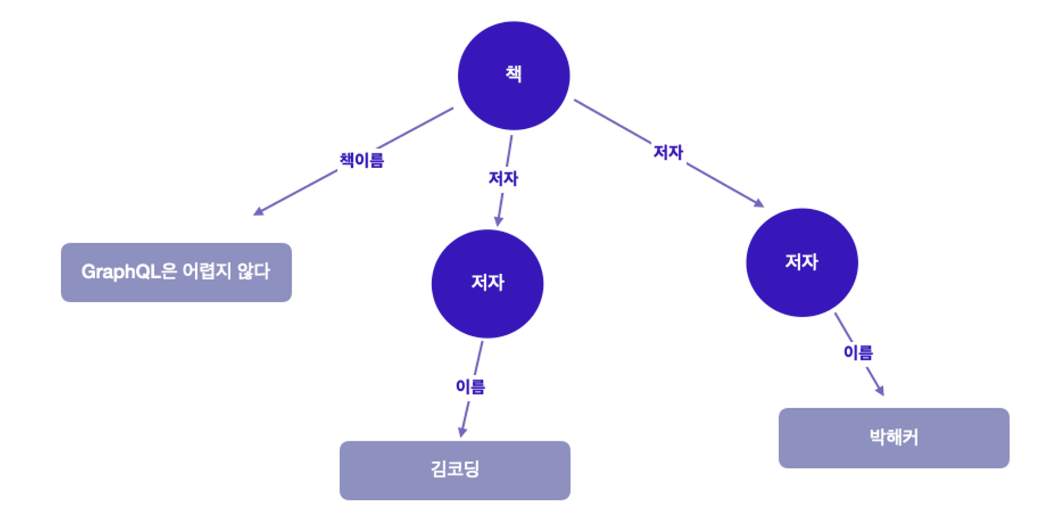
- 트리 구조로 봤을 경우
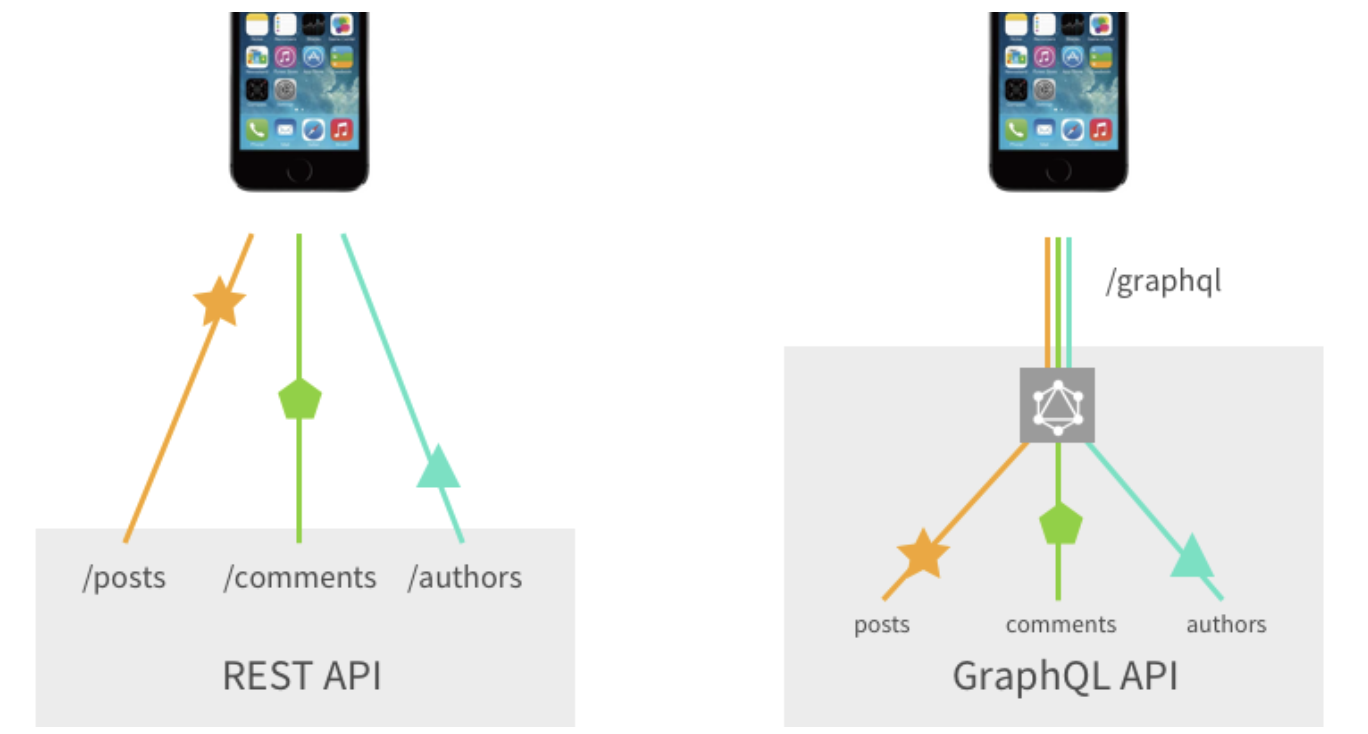
GraphQL VS REST API
- REST API의 한계
- 가상의 블로그 앱을 구현한다고 가정하면 아래 데이터가 필요하다
- 유저의 이름
- 유저의 포스팅 목록
- 유저의 팔로워 목록
- Overfetch: 필요 없는 데이터까지 제공
* 예제처럼 유저의 이름만 필요한 상황에서 REST API를 사용한다면,
응답 데이터에는 유저의 주소, 생일 등과 같이 실제로는 클라이언트에게 필요없는 정보가 포함되어 있을 수도 있다 - Underfetch: endpoint가 필요한 정보를 충분히 제공하지 못함
- 클라이언트는 필요한 정보를 모두 확보하기 위하여 추가적인 요청을 보내야만 한다
- 포스팅 목록 및 유저가 보유한 팔로워까지 필요할 때, 필요한 정보를 모두 가져오려면 REST API에서는 각각의 자원에 따라 엔드포인트를 구분하기 때문에 3가지 엔드포인트에 요청을 보내야한다
- 클라이언트 구조 변경 시 엔드포인트 변경 또는 데이터 수정이 필요함
- REST API에서는 자원의 크기와 형태를 서버에서 결정하기 때문에 클라이언트가 직접 데이터의 형태를 결정할 수 없다. 이로 인해 만약 클라이언트에서 필요한 데이터의 내용이 변할 경우 다른 엔드포인트를 통해 변경된 데이터를 가져오거나 수정을 해야한다
- 가상의 블로그 앱을 구현한다고 가정하면 아래 데이터가 필요하다
- REST API와 GraphQL의 차이점
- REST API는 Resource에 대한 형태 정의와 데이터 요청 방법이 연결되어 있지만,
GraphQL에서는 Resource에 대한 형태 정의와 데이터 요청이 완전히 분리되어 있다
- REST API는 Resource에 대한 형태 정의와 데이터 요청 방법이 연결되어 있지만,
- REST API는 Resource의 크기와 형태를 서버에서 결정하지만,
GraphQL에서는 Resource에 대한 정보만 정의하고, 필요한 크기와 형태는 클라이언트 단에서 요청 시 결정한다 - REST API는 URI가 Resource를 나타내고 Method가 작업의 유형을 나타내지만,
GraphQL에서는 GraphQL Schema가 Resource를 나타내고 Query, Mutation 타입이 작업의 유형을 나타낸다 - REST API는 여러 Resource에 접근하고자 할 때 여러 번의 요청이 필요하지만,
GraphQL에서는 한 번의 요청에서 여러 Resource에 접근할 수 있다 - REST API에서 각 요청은 해당 엔드포인트에 정의된 핸들링 함수를 호출하여 작업을 처리하지만, GraphQL에서는 요청 받은 각 필드에 대한 resolver를 호출하여 작업을 처리한다
-
GraphQL의 장점
- 하나의 endpoint 요청
/graphql이라는 하나의 endpoint 로 요청을 받고 그 요청에 따라 query , mutation을 resolver 함수로 전달해서 요청에 응답- 모든 클라이언트 요청은
POST메소드를 사용
- No! under & overfetching
- 여러 개의 endpoint 요청을 할 필요없이 하나의 endpoint에서 쿼리를 이용해 원하는 데이터를 정확하게 API에 요청하고 응답으로 받을 수 있다
- 강력한 playground
- graphql 서버를 실행하면 playground라는 GUI를 이용해 resolver 와 schema 를 한 눈에 보고 테스트 해 볼 수 있다 (POSTMAN 과 비슷)
- 클라이언트 구조 변경에도 지장이 없음
- 클라이언트 구조가 바뀌어도 필요한 데이터를 결정, 요청하고 응답받기 때문에 서버에 지장이 없다
클라이언트에서는 무슨 데이터가 필요한지에 대해서만 요구사항을 쿼리로 작성하면 됨
- 클라이언트 구조가 바뀌어도 필요한 데이터를 결정, 요청하고 응답받기 때문에 서버에 지장이 없다
- 즉, GraphQL은 여러 자원에 대한 데이터를 효율적으로 요청하고 응답받을 수 있는 기능을 제공하며, 클라이언트가 필요한 정보를 한 번에 요청할 수 있도록 도와줍니다. 이로써 과도한 네트워크 트래픽을 줄이고 성능을 개선할 수 있습니다.
- 하나의 endpoint 요청
-
GraphQL의 단점
- REST API에 친숙한 개발자의 경우 GraphQL를 학습하는 데 시간이 필요
- 캐싱이 REST보다 훨씬 복잡
- HTTP에선 각 메소드에 따라 캐싱이 구현되어 있지만
GraphQL에선POST메소드만을 이용해 요청을 보내기 때문에
각 메소드에 따른 캐싱을 지원받을 수 없다. 이를 보안하기 위해 Apollo 엔진의 캐싱과 영속 쿼리 등이 등장
- HTTP에선 각 메소드에 따라 캐싱이 구현되어 있지만
- 고정된 요청과 응답만 필요할 경우에는 Query 로 인해 요청의 크기가 RESTful API 의 경우보다 더 커진다
출처)
https://hevodata.com/learn/rest-vs-restful-apis/#4
https://urclass.codestates.com/
https://tsh.io/blog/javascript-trends/
https://tech.kakao.com/2019/08/01/graphql-basic/
