📍 검색
- 저장되어 있는 자료 중에서 원하는 항목을 찾는 작업
- 목적하는 탐색 키를 가진 항목을 찾는 것
탐색키 : 자료를 구별하여 인식할 수 있는 키 - 검색의 종류
순차 검색
이진 검색
해쉬
순차 검색
- 일렬로 되어있는 자료를 순서대로 검색하는 방법
가장 간단하고 직관적인 검색 방법
배열이나 연결 리스트 등 순차구조로 구현된 자료구조에서 원하는 항목을 찾을 때 유용함
알고리즘이 단순하여 구현이 쉽지만, 검색 대상의 수가 많은 경우에는 수행시간이 급격히 증가하여 비효율적임 - 2가지 경우
정렬되어 있지 않은 경우
정렬되어 있는 경우
정렬되어 있지 않은 경우
- 검색과정
- 첫번째 원소부터 순서대로 검색 대상과 키 값이 같은 원소가 있는지 찾는다
- 키 값이 동일한 원소를 찾으면 그 원소의 인덱스를 반환
- 자료구조의 마지막에 이를 때까지 검색 대상을 찾지 못하면 검색 실패
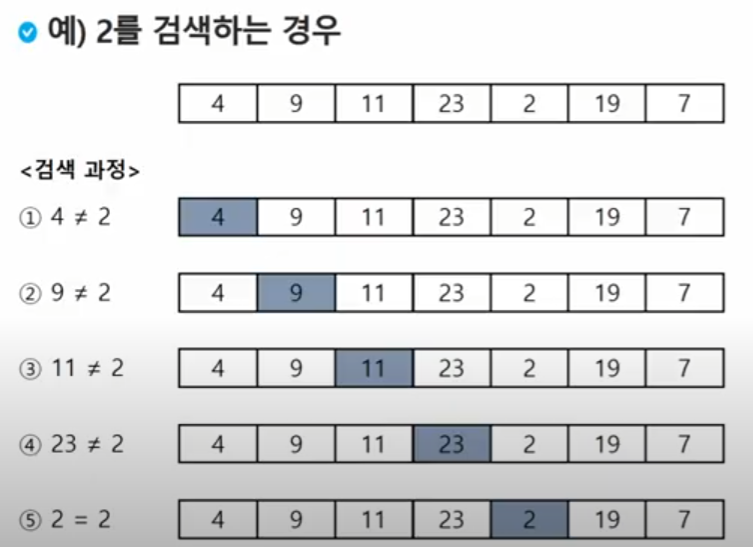
- 찾고자 하는 원소의 순서에 따라 비교회수가 결정됨
첫 번째 원소를 찾을 때는 1번 비교, 두 번째 원소를 찾을 때는 2번 비교
정렬되지 않은 자료에서 순차 검색의 평균 비교 횟수
=(1/n) * (1+2+3+... +n) = (n+1)/2
시간 복잡도 : O(n)
def sequentialSearch(a, n, key): # a가 검색대상, n이 검색할 인덱스, key는 찾는 키 값
i <- 0
**while i < n and a[i]!=key:** # i가 존재하는 범위안에 있고 (선조건)
i <- i + 1
if i < n: return i # 두번째 조건때문에 종단된 경우라면 리턴
else : return -1 - for문으로 돌리는 것과 위와 동일한 검색이다. 뭘 쓰든 상관 없다.
정렬되어 있는 경우
- 검색 과정
- 자료를 순차적으로 검색하면서 키 값을 비교하여,
원소의 키 값이 검색 대상의 키 값보다 크면 원소가 없다 > 검색종료

더 큰 요소가 나오면 검색 종료
- 찾고자 하는 원소의 순서에 따라 비교회수가 결정됨
검색 실패를 반환하는 경우 평균 비교 회수가 반으로 줄어든다
시간복잡도 : O(n)
def sequentialSearch2(a, n, key):
i <- 0
while i < n and a[o] < key:
i <- i + 1
if i < n and a[i] == key: # 검색 성공한 경우
return i
else?
return -1이진 검색
- 자료의 가운데에 있는 항목의 키 값과 비교하여 다음 검색의 위치를 결정하고 검색을 계속 진행하는 방법
목적 키를 찾을 때까지 이진 검색을 순환적으로 반복 수행함으로써 검색 범위를 반으로 줄여가며 빠르게 검색 - 이진 검색을 위해 자료가 정렬된 상태여야 한다 (시간순 정렬)
- 검색 과정
- 중앙에 있는 원소를 고른다
- 중앙 원소와 목표값 비교
- 목표값이 작으면 왼쪽 반, 크다면 오른쪽 반에 대해서 검색 수행
- 위 과정 반복

더이상 찾을만한 구간이 남아있지 않으면 검색 실패!
- 검색 범위의 시작점과 종료점을 이용해 검색을 반복 수행
- 자료에 삽입이나 삭제가 발생했을 때 배열의 상태를 항상 정렬 상태로 유지하는 추가 작업이 필요하다
def binarySearch(a, N, key)
start = 0
end = N -1
while start <= end : # 검색 구간이 남아있으면
middle = (start + end)//2 # 중간 위치 검색
if a[middle] == key: # 검색 성공
return true
elif a[middle] > key:
end = middle - 1
else:
start = middle + 1
return false # 검색 실패- 재귀함수 이용
재귀함수를 이용하여 이진 검색을 구현할 수도 있다
그러나 재귀보다는 반복구조가 더 빠르다
인덱스
인덱스라는 용어는 Database에서 유래했으며, 테이블에 대한 동작 속도를 높여주는 자료 구조
Database 분야가 아닌 곳에서는 Look up table 등의 용어 사용
필요한 디스크 공간은 보통 테이블을 저장하는데 필요한 디스크 공간보다 작다 보통 인덱스는 키-필드만 가지고 있고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문
- 배열을 사용한 인덱스
대량의 데이터를 매번 정렬하면, 프로그램 반응은 느려질 수밖에 없다
성능 저하 문제 해결 위해 배열 인덱스 사용 가능
원본 데이터에 데이터 삽입될 경우 상대적으로 크기가 작은 인덱스 배열을 정렬하기 때문에 속도가 빠르다
선택 정렬
- 주어진 자료들 중 가장 작은 값의 원소부터 차례대로 선택하여 위치를 교환하는 방식
- 정렬 과정
- 주어진 리스트 중에서 최소값을 찾는다 (오른차순)
- 그 값을 리스트의 맨 앞에 위치한 값과 교환한다
- 맨 처음 위치를 제외한 나머지 리스트를 대상으로 위의 과정을 반복한다
- 시간 복잡도 : O(n의 제곱)
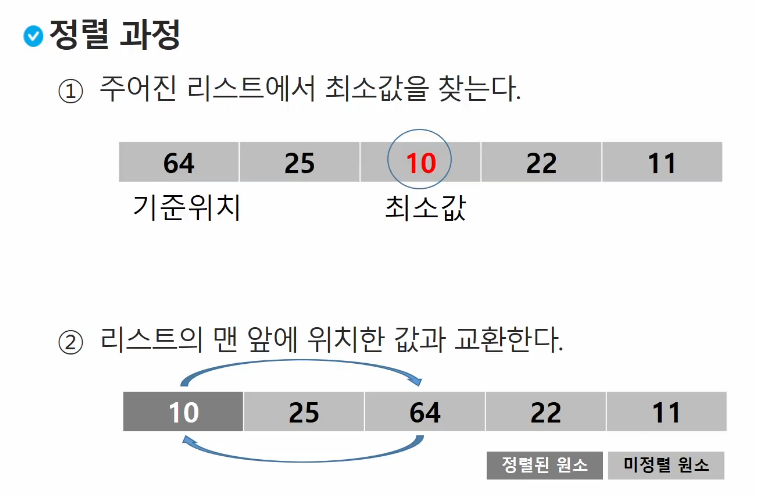 미정렬 원소가 하나 남은 상황에서는 마지막 원소가 가장 큰 값을 갖고 종료하고 선택 정렬이 완료된다
미정렬 원소가 하나 남은 상황에서는 마지막 원소가 가장 큰 값을 갖고 종료하고 선택 정렬이 완료된다
def selectionSort(a, N):
for i in range(N - 1):
minIdx = i
for j in range(i + 1, N):
if a[minIdx] > a[j]:
minIdx = j
a[i], a[minIdx] = a[minIdx]. a[i] # 두 개가 다를 때만 교환하라는 조건 필요없음*if i != minIdx
셀렉션 알고리즘
- 저장되어 있는 자료로부터 k번째로 큰 혹은 작은 원소를 찾는 방법
최소값, 최대값 혹은 중간값을 찾는 알고리즘 - 선택과정
아래와 같은 과정을 통해 이루어진다
정렬 알고리즘 이용
원하는 순서에 있는 원소 가져오기
일반적인 셀렉션 알고리즘

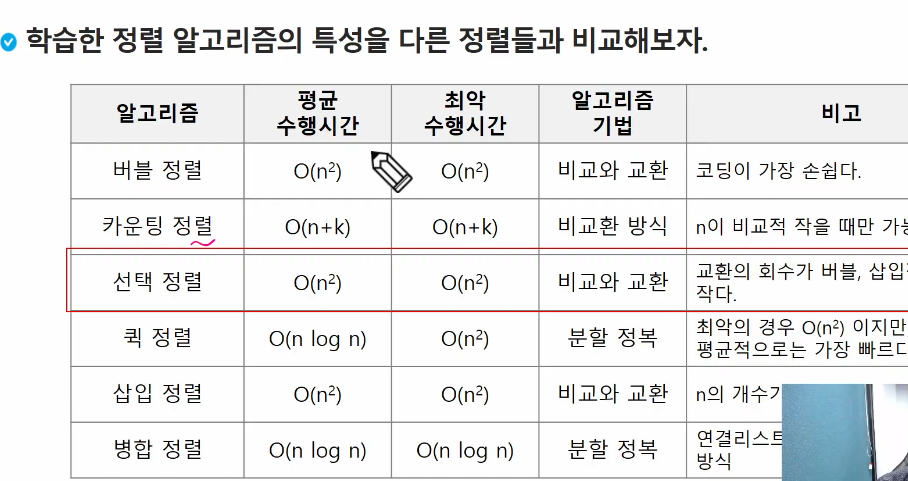
정렬 알고리즘 비교