Unlearn What You Want to Forget: Efficient Unlearning for LLMs(Chen&Yang, 2023, ACL)
Unlearning Literature Review
- Unlearn What You Want to Forget: Efficient Unlearning for LLMs, Chen&Yang, 2023
📖 Title: Unlearn What You Want to Forget: Efficient Unlearning for LLMs
🗓 Year: 2023
🏛 Publish: ACL
👤 Author: Chen & Yang
🔗 Link: https://arxiv.org/abs/2310.20150
📝 Summary:
-
본 논문은 Language model에 대한 Target data influence removal 목적의 unlearning 문제를 다루고 있습니다.
-
본 논문에서 제안하는 EUL의 핵심 목표는 다음과 같이 요약될 수 있습니다.
- LLM의 multi-task nature, 그리고 LLM은 거대한 크기의 데이터에 대해 학습되므로 task마다, forgetting target마다 unlearning을 수행하는 것은 inefficient
- 따라서 매번 달라지는 task와 forgetting target에 대해 새로 unlearn할 필요 없이, Original LLM은 유지한 채로 작은 크기의 “unlearning layer”를 plugging하는 것만으로 다양한 task와 target에 대한 forget model로 switch할 수 있다.
- 이러한 “unlearning layer”는 각 task와 target에 대해, 제안된 objective를 최적화 하는 방식으로 학습하여 구할 수 있다. (이 때, LLM은 freeze)
- Multiple target에 대한 “unlearning layer”를 구하고 싶은 경우, 개별 target에 대한 “unlearning layer”를 proposed method에 따라 fusion하여 구할 수 있다.
-
본 논문에서 제안하는 EUL의 scheme은 다음과 같습니다.
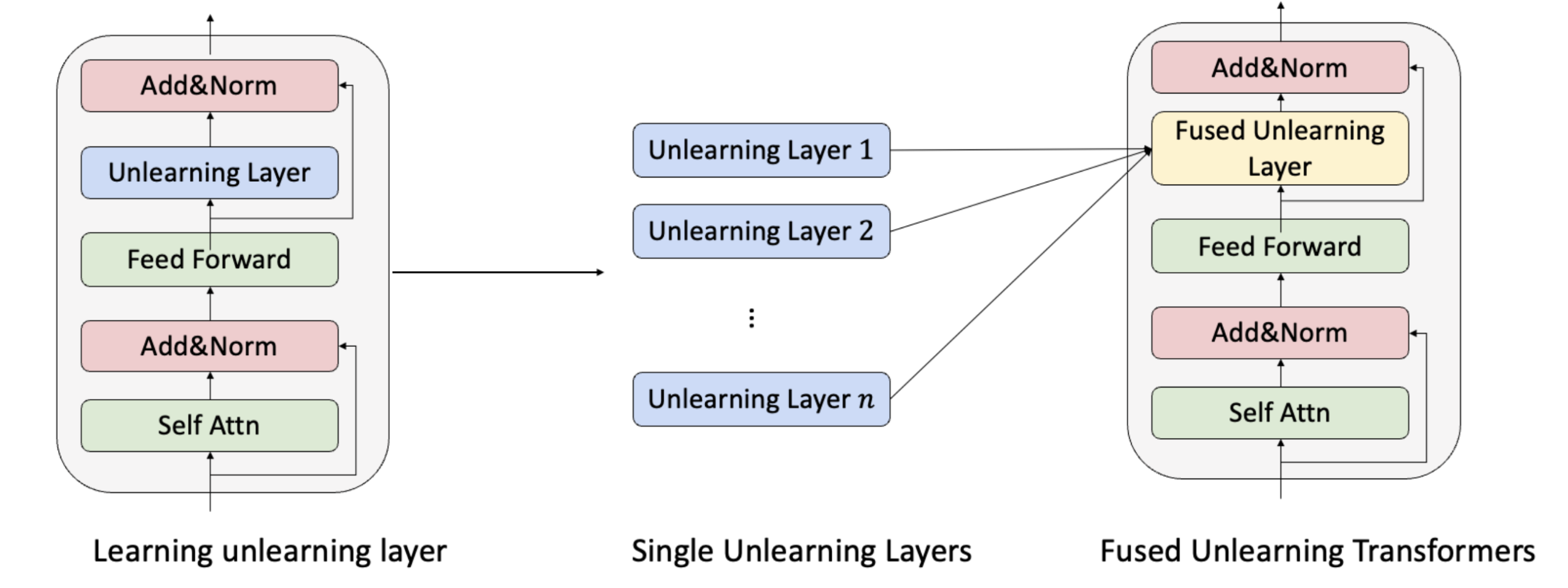
- Unlearning layer는 FF network 뒤에 plug되며, 논문 상에서는 adapter라고만 표현되어 있어서 정확한 아키텍처는 코드를 살펴봐야 할 것 같습니다.
- 추가로, LLM에 존재하는 모든 transformer layer에 삽입되는 것인지도 따로 나와있지 않아서 코드를 살펴보겠습니다.
-
다음은 unlearning layer를 학습하는 objective에 대한 내용입니다.
이 때 각 loss는 다음과 같습니다. (F(.)는 orignial model, F(f(.))는 updated model)
-
KL Loss
- KL Loss는 Original 모델에 대한 output 분포와 Unlearned Model(plugged model)에 대한 output 분포의 KL-Divergence가, retain set의 경우 작도록(가깝도록) forget set의 경우 크도록(멀도록) teacher-student manner로 학습합니다.
-
Task loss
- retain set에 대해 정의된 task에 대한 성능 유지에 대한 loss 입니다.
-
LM loss
- 은 F(.)를 pretraining 할 때 사용하였던 loss입니다. 이를테면 masked language model의 경우
- forgetting target에 대한 task 성능을 낮추는 것 뿐만 아니라, target이 그 어떠한 답변 generation중에도 포함되지 않도록 유도하기 위한 loss로 이해하였습니다.
-
-
다음은 fusion mechanism 입니다.
-
Fusion mechanism의 목적은 서로 다른 unlearning layer 를 위와 같은 방법으로 구하였을 때, 이를 단일한 unlearning layer 으로 merge하기 위함입니다.
-
위의 식은 linear regression problem이므로 다음과 같은 closed-form solution을 가집니다.
-
위와 같이 구한 을 plugging함으로써 mutlple task 또는 target에 대한 unlearned model을 구해낼 수 있습니다.
-
-
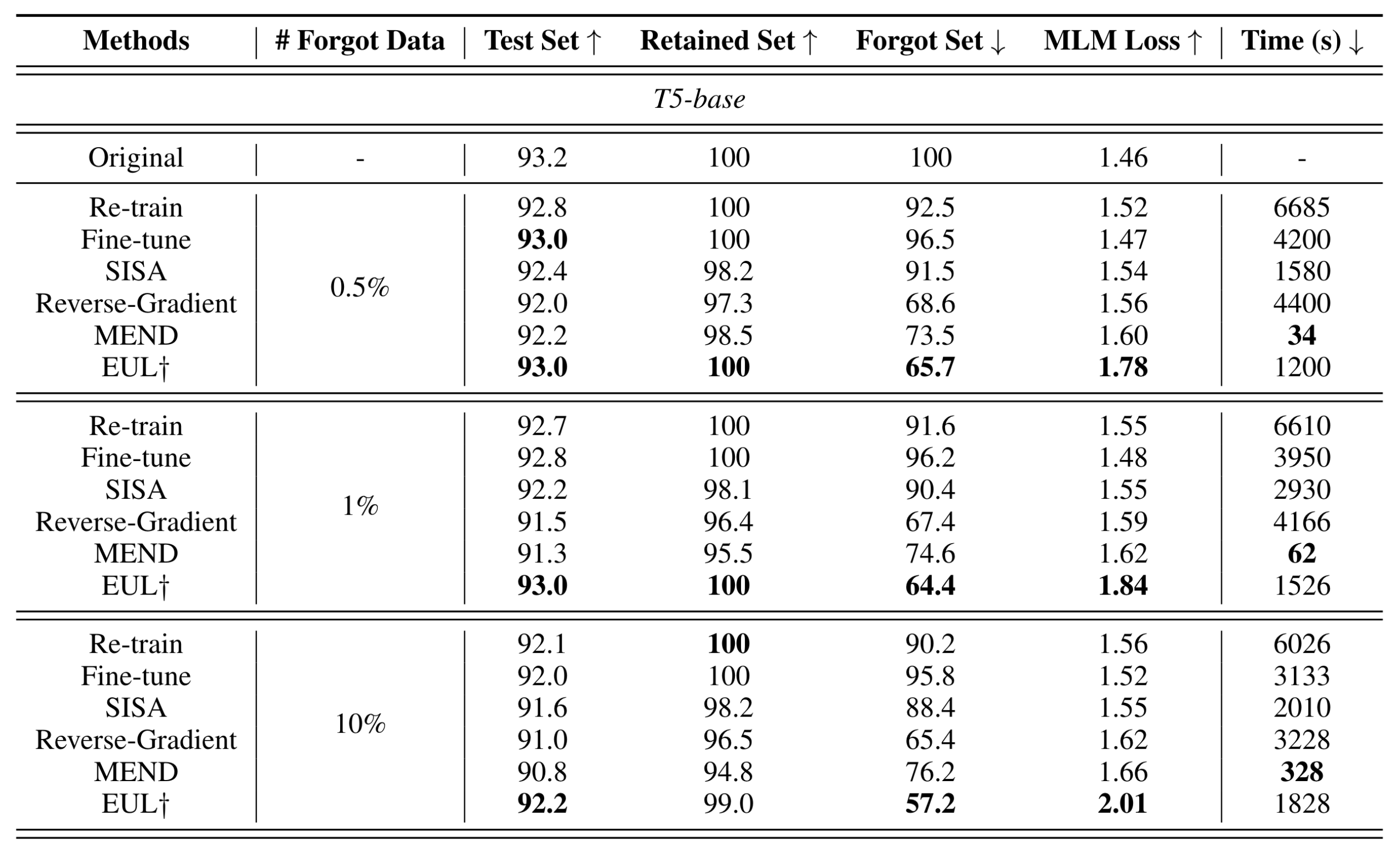
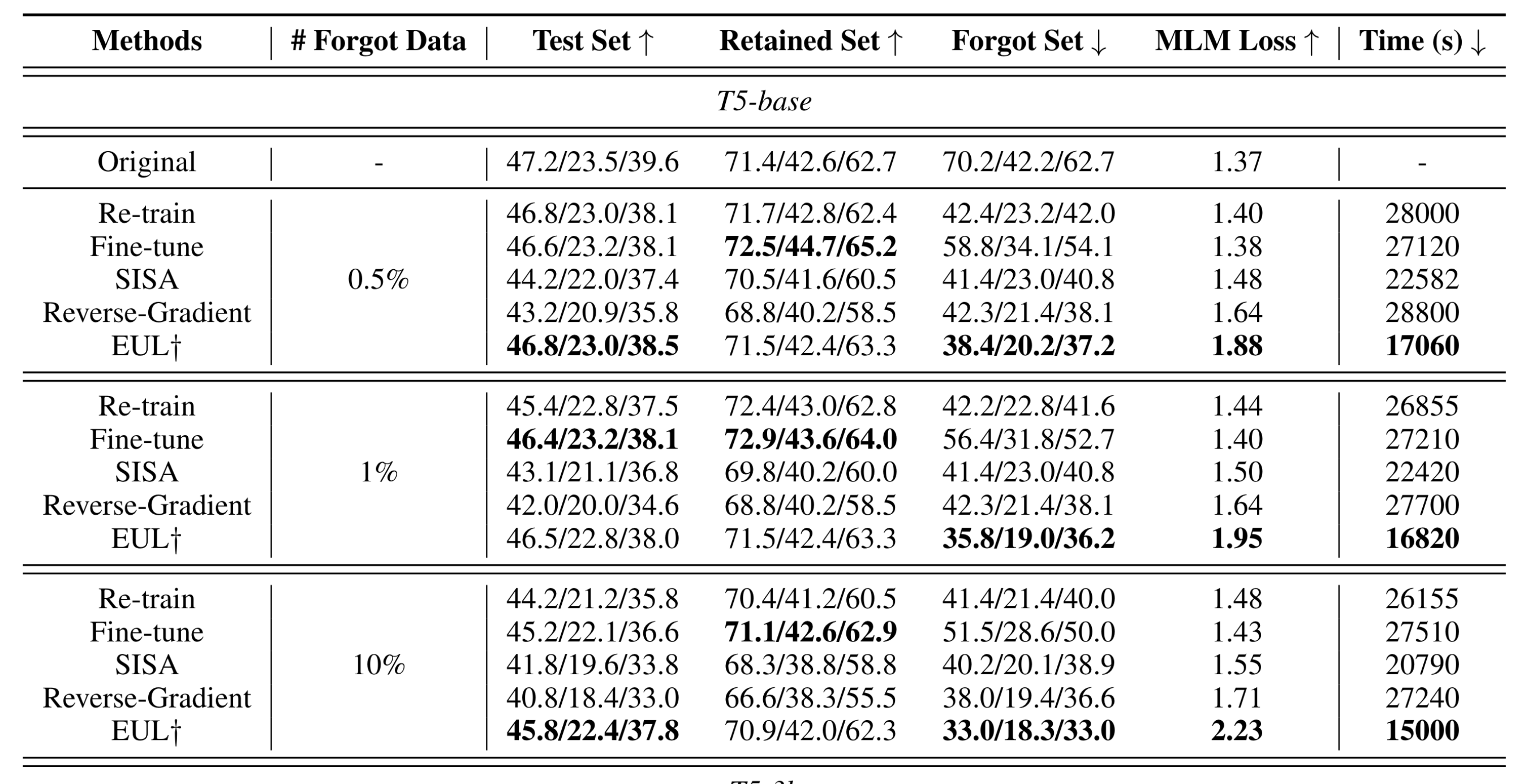
다음은 실험입니다. 실험은 T5(base, 3B) 모델에 대해 IMDB를 이용한 Sentiment classification, SAMSum을 이용한 summary generation 두 가지의 task에 대해 수행되었습니다.
-
Baseline은 Retrain, FT, SISA, Reverse-Gradient(GA)를 두고 Forget set acc, Retain set acc, Test acc, MLM Loss, RTE로 평가하여 비교하였습니다.
-
MLM loss는 forget data, 또는 관련된 entity와 action을 mask 토큰으로 처리 후, “Predict the masked word”라는 템플릿을 적용하여, 모델로부터 forget data를 얼마나 잘 추출해낼 수 있는지를 평가하는 지표입니다. 마스킹할 대상은 AllenNLP라는 pretrained NER 모델을 통해 추출하였습니다.
-
실험 결과는 다음과 같습니다.
-
IMDB / T5-base
-
SAMSum / T5-base
-

퍼가요 ~