
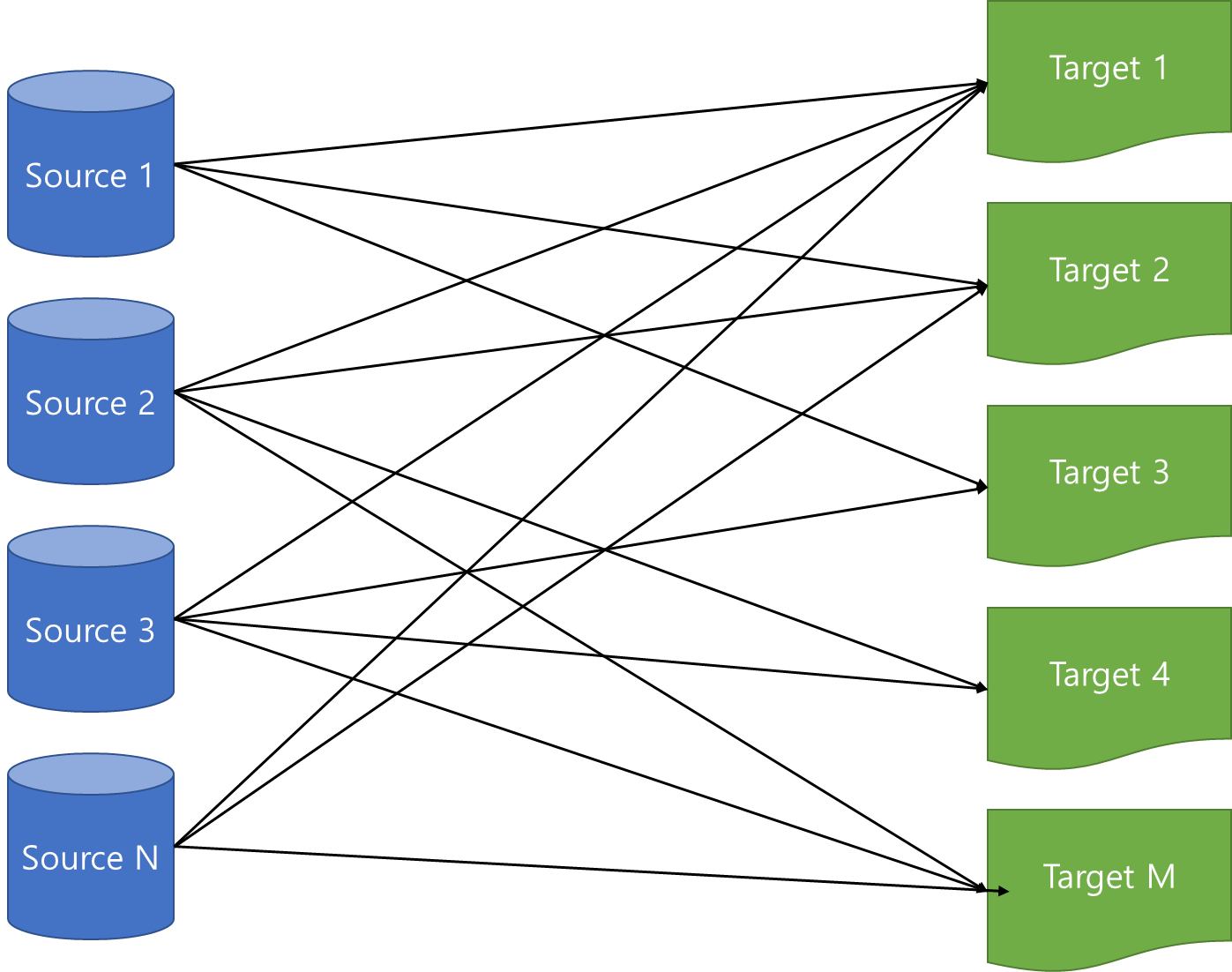
kafka가 있기 전까지는 단방향 통신을 통해 source application에서 target application으로 연동하는 코드를 작성하였고, 아키텍처가 복잡하지 않아 운영에 큰 문제가 없었다.
하지만 시간이 지남에 따라 source 및 target 애플리케이션 수가 증가하였고, 이로 인해 파이프라인 개수가 많아지면서 코드 및 버전관리에 한계가 생기게 되었다. 또한, target 애플리케이션의 장애가 source 애플리케이션에 그대로 전달되기도 하였다.
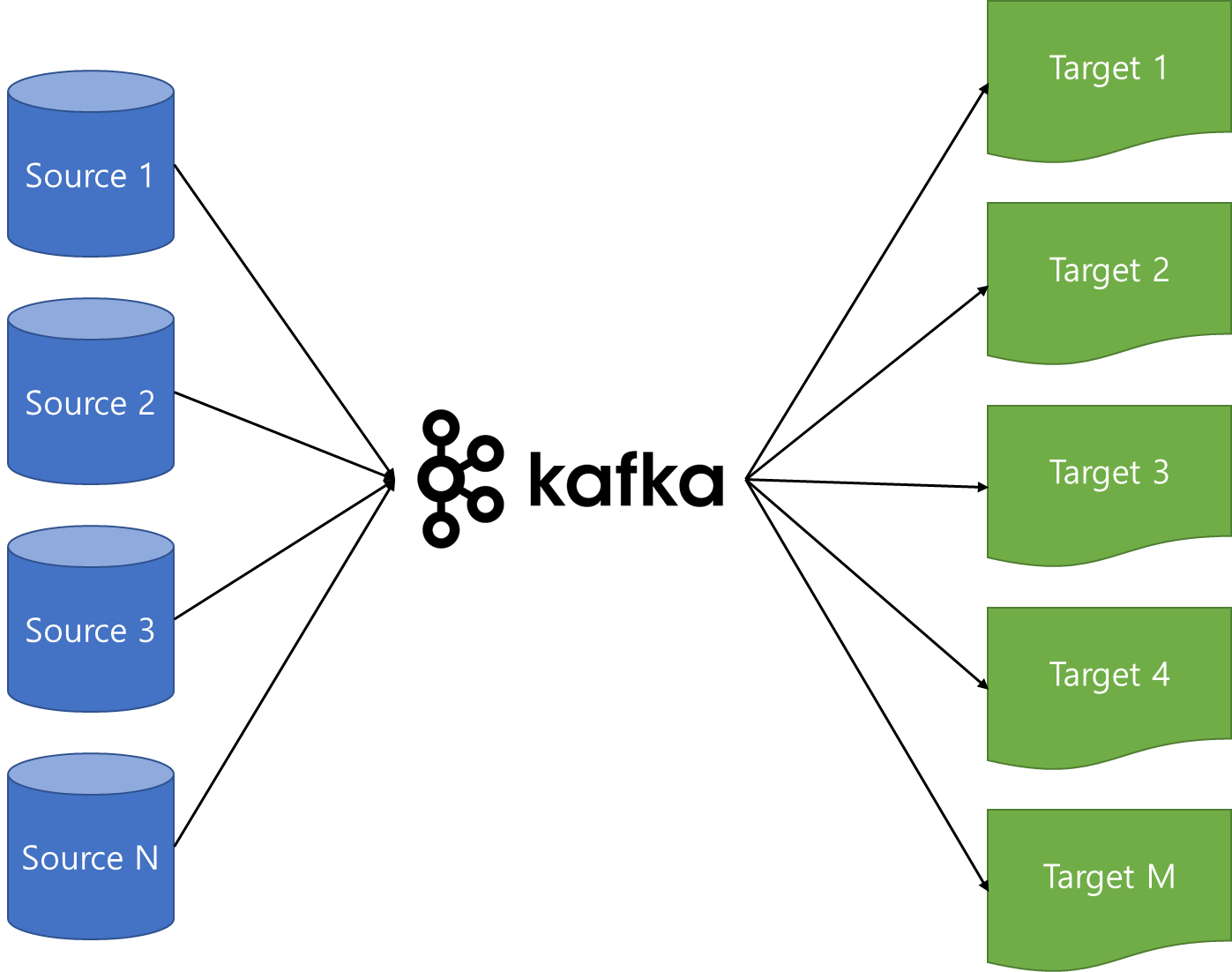
이를 해결하기 위해, 링크드인 데이터팀은 Apache Kafka라는 시스템을 만들었다.
카프카는 중앙집중화를 통해 여러 source의 데이터를 한 곳에서 실시간으로 관리할 수 있게 되었다.
즉, 기업의 대용량 데이터를 수집하고 이를 사용자들이 실시간 스트림으로 소비할 수 있게 만들어 주는 중추 신경으로 동작한다.
카프카를 중앙에 배치함으로, sourc 애플리케이션과 target 애플리케이션의 커플링을 완화하였다.(의존도를 낮춤)
카프카 내부에 데이터가 저장되는 파티션의 동작은 FIFO방식인 큐와 유사하며, 큐에 데이터를 보내는 것이 프로듀서, 가져오는 것이 컨슈머다.
카프카에 전달할 수 있는 데이터 포멧은 사실상 제한이 없으며, 카프카 클라이언트에서는 기본적으로 ByteArray, ByteBuffer, Long, Double, String 타입에 대해 serializer, deserializer 클래스가 제공된다.
만약 필요 시, 커스텀 클래스를 생성하여 사용하면 된다.
카프카는 최소 3대 이상의 서버에서 분산 운영하여 프로듀서를 통해 전송받은 데이터를 파일 시스템에 안전하게 기록한다. 카프카 클러스터 중 일부 서버에 장애가 발생하더라도 데이터를 지속적으로 복제하여 안전하게 운영 가능하다.
카프카는 현재 많은 기업에서 사용하고 있으며, 현재 오픈 소스로 제공되고 있다.
요약
- Before Kafka
- source 애플리케이션에서 target 애플리케이션으로 단방향 통신
- 시간이 지남에 따라 source, target 애플리케이션 증가
- 데이터 전송라인의 증가로 배포, 장애 대응 힘듦
- 데이터 전송 시 Protocal foramat의 파편화 심화
- After Kafka
- source와 target간의 커플링을 약하게 만듦
- 분산 및 복제 운영으로 서버 장애 시에도 안전하게 사용 가능
- 낮은 지연과 높은 처리량을 지님
- Producer와 Consumer로 구성
- Producer : kafka에 데이터를 보내는 아이
- Consumer : kafka에서 데이터를 가져가는 아이
