문서 목적
해당 문서는 Spark를 kubernetes에 올리는 내용을 정리하기 위해 작성된 문서이다.
Spark
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
link
- 빅데이터 처리를 위한 오픈소스 분산처리 플랫폼
- 인메모리 기반의 대용량 데이터 고속 처리 엔진
- 범용 분산 클러스터 컴퓨팅 프레임워크
- 자세한 내용 : https://wikidocs.net/26513
Spark 구조
- 작업을 관리하는 드라이버, 작업이 실행되는 노드를 관리하는 클러스터 매니저로 크게 2가지로 볼 수 있음
Spark architecture
- master - slave 구조로 실행
- driver : 작업 관장
- executor : 실제 작업이 동작
- driver는 spark-context 객체를 생성하여 클러스터 매니저와 통신하면서 클러스터의 자원 관리를 지원하고, 애플리케이션 라이프 사이클을 관리한다.
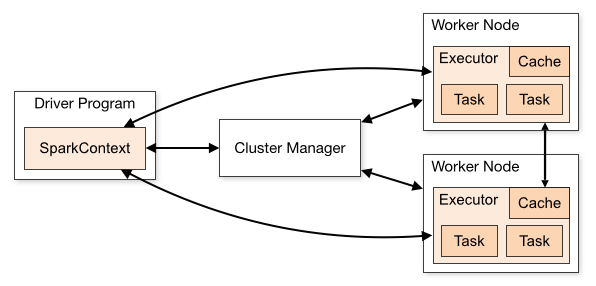
출처 : https://spark.apache.org/docs/latest/cluster-overview.html
Spark application
- spark의 실행 프로그램
- cluster manager가 스파크 어플리케이션 리소스를 효율적으로 배분
Driver
- spark application을 실행하는 프로세스
- main 실행 및 SparkContext 객체 생성
- Spark application의 라이플 사이클 관리
- 애플리케이션 전달 및 작업 처리 결과를 사용자에게 전달
Executor
- Task 실행을 담당하는 에이전트로 실제 작업을 진행하는 프로세스
- task단위로 작업을 실행하고 결과를 드라이버에 알려줌
- 동작 중 오류가 발생하면 다시 재작업을 진행
Task
- Executor에서 실행하는 실제 작업
- 캐쉬 공유로 작업 속도 증가 가능
Spark job
- Job, Stage, Task로 구성
- Job : Spark application으로 제출된 작업
- Stage : Job을 작업의 단위에 따라 나눈 것
- Task : executor에서 실행되는 실제 작업
Spark on Kubernetes
장단점
장점
- 컨테이너화
- 비용 절감
- 풍부한 생태계에 통합
단점
- 빌드 시간과 전문 지식이 필요하다.
- 최신 Spark 버전을 실행 해야 한다.
출처
- https://spot.io/blog/the-pros-and-cons-of-running-apache-spark-on-kubernetes/
- https://spot.io/blog/tutorial-running-pyspark-inside-docker-containers/
- https://spot.io/blog/setting-up-managing-monitoring-spark-on-kubernetes/
- https://www.datamechanics.co/apache-spark-on-kubernetes
- https://towardsdatascience.com/spark-on-kubernetes-the-easy-way-585e558abf59
- https://hub.docker.com/r/datamechanics/spark

열심히 정리하는 습관 기르기..