문서 목적
해당 문서는 EMR에서 resource manager capacity scheduler 부분에서 queue 부분이 막혀서, 이 부분을 해결하기 위해 공부한 내용을 정리하고자 작성된 문서이다. 해당 내용은 하둡 완벽 가이드책을 기반으로 정리한 내용이다.
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=103031150
YARN(Yet Anoter Resource Negotiator)
하둡 클러스터 자원 관리 시스템으로, 맵리듀스의 성능을 높이기 위해 하둡2에서 처음 도입되었으나, 맵리듀스뿐만 아니라 다른 분산 컴퓨팅 도구도 지원한다.
클러스터의 자원을 요청하고 사용하기 위한 API를 제공하지만, 사용자 코드에서 직접 해당 API를 사용할 수 없다. YARN이 내장된 분산 컴퓨팅 프레임워크에서 고수준 API를 작성해야 하며, 사용자는 자원 관리의 자세한 내용은 알 수 없다.
애플리케이션은 YARN과 HDFS/HBase 위에서 YARN 애플리케이션을 실행한다.
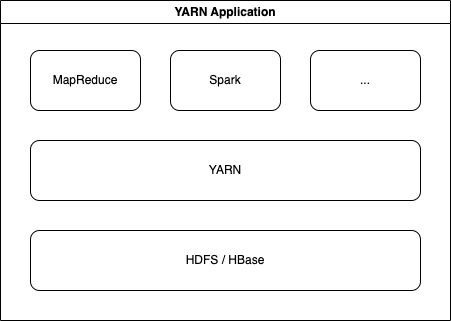
YARN Application 수행
YARN 구성
- Resource Manager
클러스터에 유일하게 실행되며, 클러스터 전체 자원의 사용량을 관리 - Node Manager
모든 머신에서 실행되며, 컨테이너를 구동하고 모니터링
YARN 자체는 애플리케이션이 서로 통신하는 기능을 제공하지 않고, 하둡의 RPC와 같은 원격 호출 방식을 이용하여 상태 변경을 전달하고 클라이언트로부터 결과를 받는데, 애플리케이션마다 다르다.
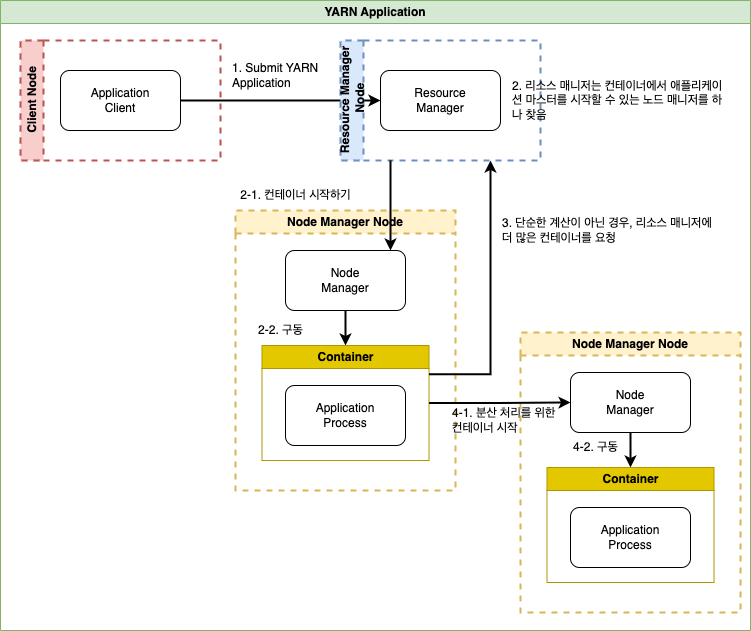
YARN 스캐줄링
Scheduler Option
- FIFO
- 애플리케이션을 큐에 하나씩 넣고 제출된 순서에 따라 순차적으로 실행
- 대형 애플리케이션이 수행될 때 클러스터의 모든 자원을 점유해버릴 수 있기 때문에 클러스터 환경에서는 적합하지 않음.
- Capacity
- 트리 형태의 큐를 선언하고, 큐별로 사용 가능한 용량을 할당하여 YARN 자원을 관리 하는 것으로, 각 큐는 서로 분리되어 있으며 단일 큐 내부에서는 FIFO 방식으로 스케쥴링이 된다.
- Fair
- 모든 잡의 자원을 동적으로 분배하기 때문에 미리 자원의 가용량을 예약할 필요가 없음.
- 대형 애플리케이션이 시작되면 클러스터의 모든 자원을 사용하다가, 다른 애플리케이션이 추가로 시작되면 클러스터 자원의 절반을 이 애플리케이션에 할당하여 각 애플리케이션은 클러스터의 자원을 공평하게 사용할 수 있게 된다.
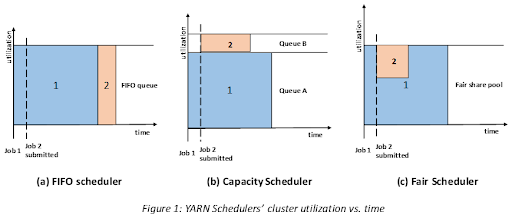
https://tutorials.freshersnow.com/hadoop-tutorial/hadoop-schedulers/
Capacity Scheduler
Capactity Scheduler 적용 방법
conf/yarn-site.xml에서 아래와 같이 설정 필요<property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property>
Capacity Scheduler를 사용하면 조직 체계에 맞게 하둡 클러스터를 공유할 수 있다. 각 큐마다 전체 클러스터의 지정된 가용량을 미리 할당 받고, 분리된 전용 큐에서 가용량의 지정된 부분을 사용하도록 설정할 수 있다.
하나의 단일 애플리케이션은 큐의 가용량을 넘는 자원을 사용할 수 없으나, 큐 탄력성(queue elasticty)를 이용하여 다수의 애플리케이션이 존재하고 현재 가용할 수 있는 자원이 클러스터에 남아 있다면 스케줄러는 여분의 자원 할당할 수 있다.
capacity-scheduler.xml을 이용하여 capacity scheduler의 설정을 진행하는데, property별 의미는 아래와 같다.
- https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
참고 사항
- leaf끼리의 min capacity의 합은 100이 되어야 함
Capacity Scheduler Example
아래 내용을 기반으로 capacity-scheduler.xml 작성 예시
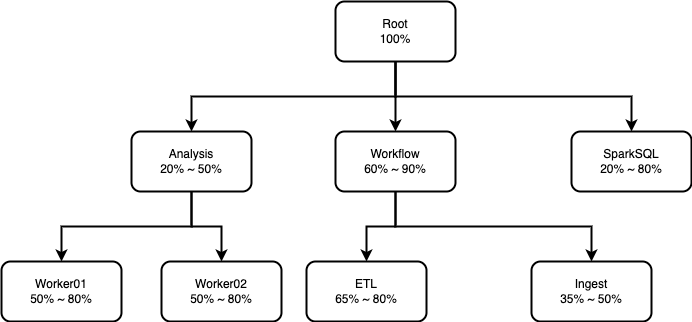
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>analysis,workflow,sparksql</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.analysis.queues</name>
<value>worker01,worker02</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.workflow.queues</name>
<value>etl,ingest</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.analysis.capacity</name>
<value>20</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.analysis.maximum-capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.workflow.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.workflow.maximum-capacity</name>
<value>90</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.sparksql.capacity</name>
<value>20</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.sparksql.maximum-capacity</name>
<value>80</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.analysis.worker01.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.analysis.worker01.maximum-capacity</name>
<value>80</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.analysis.worker02.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.analysis.worker02.maximum-capacity</name>
<value>80</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.workflow.etl.capacity</name>
<value>65</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.workflow.etl.maximum-capacity</name>
<value>80</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.workflow.ingest.capacity</name>
<value>35</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.workflow.ingest.maximum-capacity</name>
<value>50</value>
</property>
</configuration>적용된 큐 확인
mapred queue -listFair Scheduler
페어 스케줄러는 실행 중인 모든 애플리케이션에서 동일하게 자원을 할당한다.
활성화 방법으로는 conf/yarn-site.xml에서 아래와 같이 설정 필요
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>