
Topic
토픽은 카프카에서 데이터를 구분하기 위해 사용하는 단위로 데이터가 들어갈 수 있는 공간이라고 보면 된다. 토픽은 여러개 생성 가능하며, 약간 데이터베이스의 테이블 또는 파일 시스템의 폴더와 같은 느낌이라고 볼 수 있다.
토픽은 이름을 가질 수 있으며, 무슨 데이터를 담는지 명확하게 명시해야 유지보수에 도움이 된다.
토픽 이름의 경우 데이터의 얼굴이라고 보고 어떤 개발환경에서 사용되는 것인지 판단 가능해야 하고 어떤 애플리케이션에서 어떤 데이터 타입으로 사용되는지 유추할 수 있어야 한다.
토픽 이름 제약 조건
- 빈 문자열 토픽 이름은 지원하지 않는다.
- 토픽 이름은 마침표 하나 또는 파침표 둘로 생성될 수 없다.
- 토픽 이름의 길이는 249자 미만으로 생성되어야 한다.
- 토픽 이름은 영어 대소문자, 숫자, . , _ , - 조합으로 생성할 수 있으며, 이외의 문자열이 포함된 토픽 이름은 생성 불가하다.
__consumer_offsets,__transaction_state는 카프카 내부 로직 관리 목적으로 사용되므로 생성 불가능하다.- 이름에 마침표와 언더바가 동시에 들어갈 수 없다.
- 이미 생성된 토픽 이름의 마침표와 언더바를 바꾼 내역은 같다고 보아 생성 불가능하다.
(e.g.to.pic이름이 생성되어 있으면to_pic은 생성 불가)
토픽 작명 템플릿과 예시
제일 중요한 것은 토픽 이름에 대해 규칙을 사전에 정의하고 그 규칙을 따르는 것이다.
<환경>.<팀명>.<애플리케이션명>.<메시지타입>
prod.data-engineer.data-cdc.json<프로젝트명>.<서비스명>.<환경>.<이벤트명>
commerence.payment.prod.notification
토픽과 파티션
토픽은 1개 이상의 파티션을 소유하고 있으며, 0으로 시작된다. 하나의 파티션은 큐와 같이 파티션 끝에서 부터 차곡 차곡 쌓이며, 토픽에 컨슈머를 연결하면 오래된 순서로 데이터를 가져간다. 다른 메시지 플랫폼과 달리 데이터를 가져다고 레코드를 삭제하지 않는다. 파티션에는 프로듀서가 보낸 데이터들이 들어가 저장되는데 이것을 레코드라고 부른다.
파티션은 카프카의 병렬처리 핵심으로, 컨슈머들이 레코드를 병렬로 처리할 수 있도록 매칭된다. 컨슈머와 파티션을 늘림으로써 처리량을 증가 시킬 수 있다.
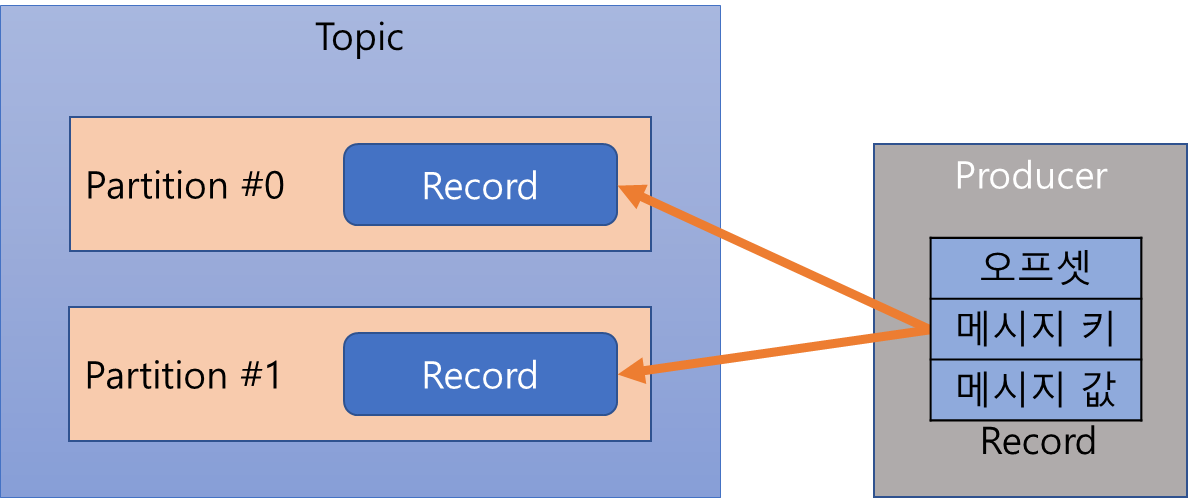
레코드
레코드는 타임스탬프, 메시지 키, 메시지 값, 오프셋, 헤더로 구성되어 있다. 브로커에 한번 적재된 레코드는 수정할 수 없고 로그 리텐션 기간 또는 용량에 따라서만 삭제된다.
타임스탬프의 경우 프로듀서에서 해당 레코드가 생성된 시점의 유닉스타임이 설정(이는 임의의 타임스탬프 값 또는 브로커에 적재된 시간 등으로 변경 가능)되며, 컨슈머는 레코드의 타임스탬프를 통해 레코드가 언제 생성되었는지 알 수 있다.
메시지 키는 메시지 값을 순서대로 처리하거나 값의 종류를 나타내기 위해 사용한다. 메시지 키를 사용하면 메시지 키의 해시값을 토대로 파티션을 지정하여, 동일한 메시지 키라면 동일 파티션에 들어가게 된다. 어느 파티션에 지정될지는 알 수 없고 파티션의 개수가 변경되면 키와 파티션 매칭이 달라지게 된다. 메시지 키를 선정하지 않으면 null로 설정되고 라운드로빈으로 파티션을 지정한다.
메시지 값에는 실질적으로 처리할 데이터가 들어있고, 키와 값은 직렬화되어 브로커로 전송된다. 따라서 컨슈머를 이용할 때 역직렬화를 수행해야 하며 반드시 동일한 형태로 처리해야 한다.
오프셋의 경우 0이상의 숫자로 이루어져 있으며, 사용자가 직접 지정할 수 없고 이전에 전송된 레코드의 오프셋 + 1 값으로 생성된다. 이 오프셋으로 컨슈머들이 파티션의 데이터를 어디까지 가져갔는지 명확히 지정할 수 있다.
헤더는 레코드의 추가적인 정보를 담는 메타데이터 저장소 용도로 사용되며 키/값 형태로 데이터를 추가하여 레코드의 속성을 저장 컨슈머에서 참조할 수 있다.
요약
- 토픽
- 카프카에서 데이터를 구분하기 위해 사용하는 단위로 데이터가 들어갈 수 있는 공간
- 토픽의 이름은 무슨 데이터를 담는지 명확하게 명시되어야 한다.
- 파티션
- 토픽은 1개 이상의 파티션이 있으며, 파티션은 저장소 안에 데이터를 저장하는 공간
- 파티션의 구조는 큐와 같이 FIFO이며, 레코드를 가지고 가더라도 삭제되지 않는다
- 컨슈머 개수를 늘림과 동시에 파티션 개수를 늘리면 처리량이 증가하는 효과를 얻을 수 있다.
- 레코드
- 타임스탬프, 메시지 키, 메시지 값, 오프셋, 헤더로 구성되어 있다.
- 타임스탬프 : 프로듀서에서 해당 레코드가 생성된 시점(설정에 따라 바뀔 수 있음)
- 메시지 키 : 메시지 값을 처리하거나 종류를 나타내기 위해 사용
메시지 키가 같으면 같은 partition 매칭이 된다.(partition 수를 변경하면 이 조건이 깨짐) - 메시지 값 : 실질적으로 처리할 데이터가 들어있으며 직렬화 되어 브로커로 전송
- 오프셋 : 0 이상의 숫자로 컨슈머들이 파티션의 데이터를 어디까지 가져갔는지 명확히 지정할 수 있다.
- 헤더 : 레코드의 추가적인 메타데이터 저장소 용도로 사용
- 타임스탬프, 메시지 키, 메시지 값, 오프셋, 헤더로 구성되어 있다.
