
서치라이트의 블로그 글을 정해진 형식의 HTML로 변환해주는 일명 '서치라이트 블로그 포매터'를 개발하였다ㅏ 👏👏👏
개발하게 된 계기
블로그 페이지를 개발한 후 총 7개의 블로그 글을 작성하였는데 모두 내가 쓴 것이다.
- 7개의 글을 작성하면서 반복적인 작업을 하는게 너무 비효율적이었음.. 프로그램의 필요성을 느낌. 인턴할 때는 바빠서 못 만들었음
- 블로그 글 작성을 전담하면서 나만의 노하우가 생겼는데, 서치라이트와 빠이빠이해버림
- 서치라이트 시절 알게 된
DOMParser를 써보고 싶었는데 블로그 포매터를 만들면서 써볼 수 있을 것 같았음
바닐라 JS를 쓴 이유
vite를 이용하여 생성한 Vanilla Javascript 프로젝트를 이용하여 만들었다.
리액트, Next.js가 아니라 왜 바닐라를 썼는가! 그 이유는
- 공부용 프로젝트니까 바닐라 복습 겸!
- 작은 프로젝트. 많은 페이지가 필요할 것 같지 않음 (많아도 2페이지..?)
배운 것
📁 JS에서 입력받은 파일 읽기
const reader = new FileReader();
reader.readAsText(file);
reader.onload = (ev: ProgressEvent<FileReader>) => {
const text = ev.target?.result as string; // 파일을 텍스트로 읽어옴
};File Input Element에 change 이벤트를 달고 File 객체를 받는 것은 많이 해봤을 것이다.
입력 받은 File 값을 FileReader 객체와 readAsText() 함수를 이용하면 파일의 내용을 텍스트 값으로 받아올 수 있다.
🐟 Domparser
const domparser = new DOMParser();
const doc = domparser.parseFromString(text, "text/html");
const $article = doc.querySelector("article");DOMParser 객체를 만들고 parseFromString을 이용하면 문자열을 Document로 변환하여 return 한다.
🐰 Code Rabbit AI
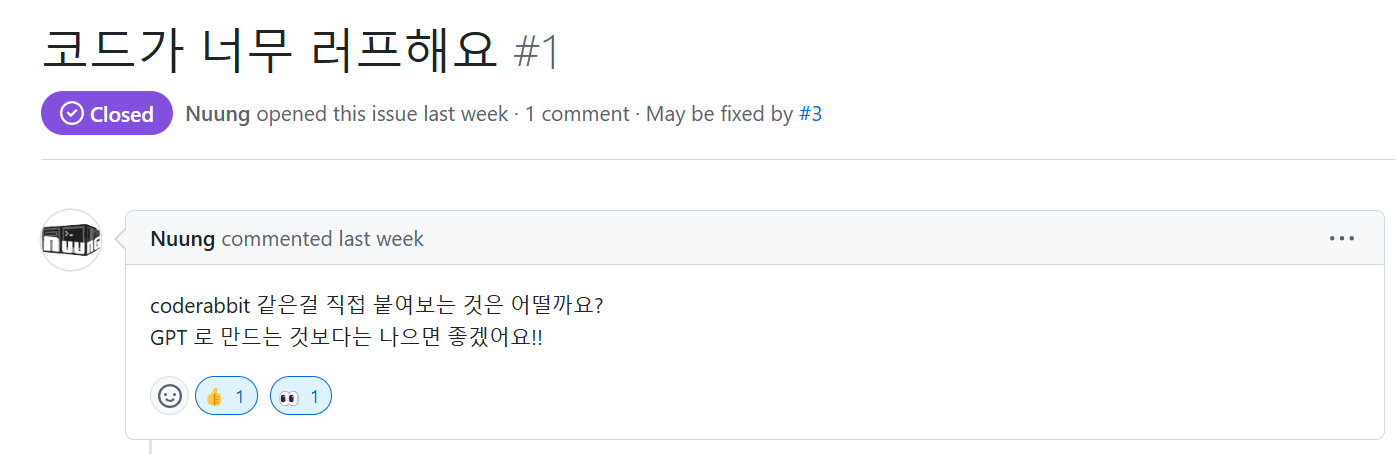
coderabbit을 붙여보라는 조언... 다음 PR 올릴 때 적용해보았는데 엄청 간단했다!
토끼가 해준 코드 리뷰를 반영한 커밋도 올렸다! 토.끼.조.아.
아직 부족한 부분
-
코드가 너무 못생겼다.. 그냥 필요한 작업들 하나하나 함수로 만들어서 순서대로 붙인 코드.. 실행만 되는 코드.. 로직 위주의 코드를 짜려니까 너무 어렵다!
그래서 coderabbit에게 full review를 요청했는데 이 녀석이 내 말을 무시한다. 도와줘 토깽아....ㅠㅠㅠㅠㅠㅠ
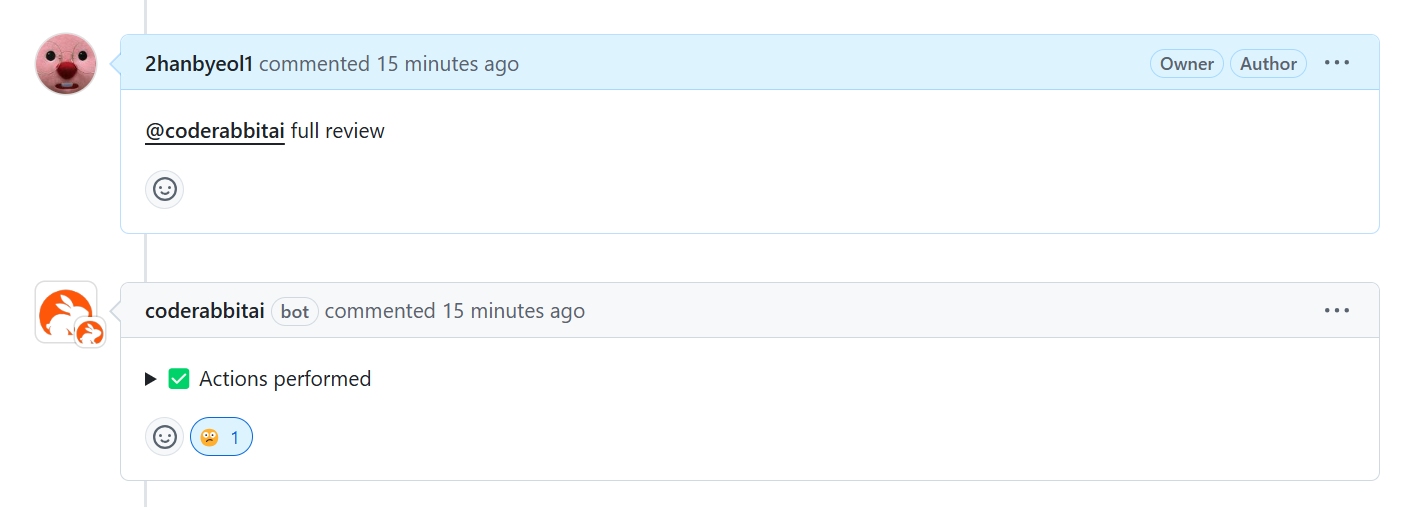
Action performed라고는 뜨는데 리뷰는 안 해줌.. -_- 왜지? -
이미지 관련 처리
이미지 관련해서 직접해줘야 할 작업이 아직 남아있어서 이 녀석을 어떻게 해결할지 고민이다...

감사해요 :) 아주 든든하게 잘 쓰고 있습니다! 🔥🔥🙏