
배열(Array)이란 동일한 타입의 원소들을 효율적으로 관리할 수 있는 기본 자료형입니다.
사용하는 이유
ex) 학생 1000명 성적 관리
// 1) 배열을 사용하지 않았을 때 (비효율적)
const score1 = 72;
const score2 = 96;
// ...
const score1000 = 80;
// 2) 배열을 사용하면, 하나의 변수와 인덱스로 관리
const score = [72, 96, ..., 80];1차원 배열 선언 방법
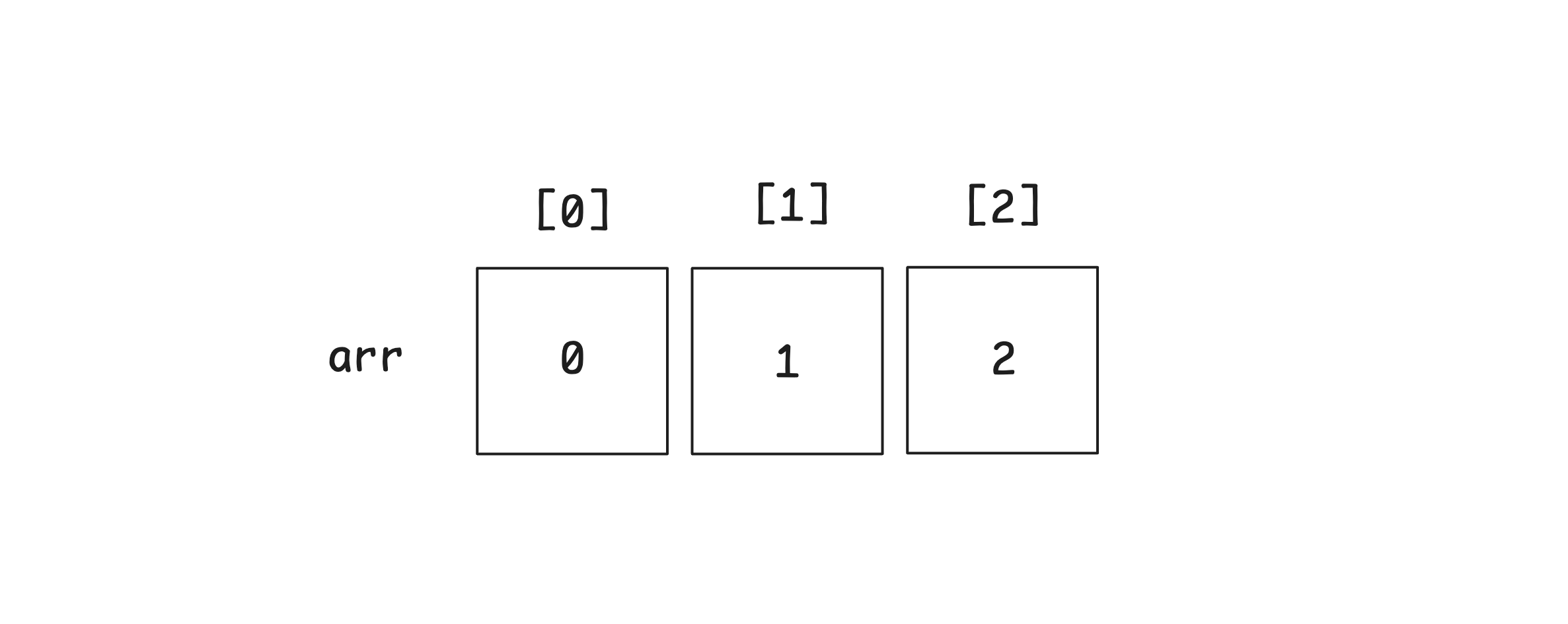
// 1) 리터럴
const arr = [0, 1, 2];
// 2) 배열 생성자 + 스프레드
const arr = [...new Array(3)].map((_, idx) => idx);
// 3) 배열 생성자 + fill
const arr = new Array(3).fill(0).map((_, idx) => idx + 1);🤧 배열 생성자에 스프레드 오퍼레이터를 씌우지 않고, map을 돌리면 값이 들어가지 않습니다.

2차원 배열 선언 방법
2차원 배열은 1차원 배열을 확장한 것입니다.
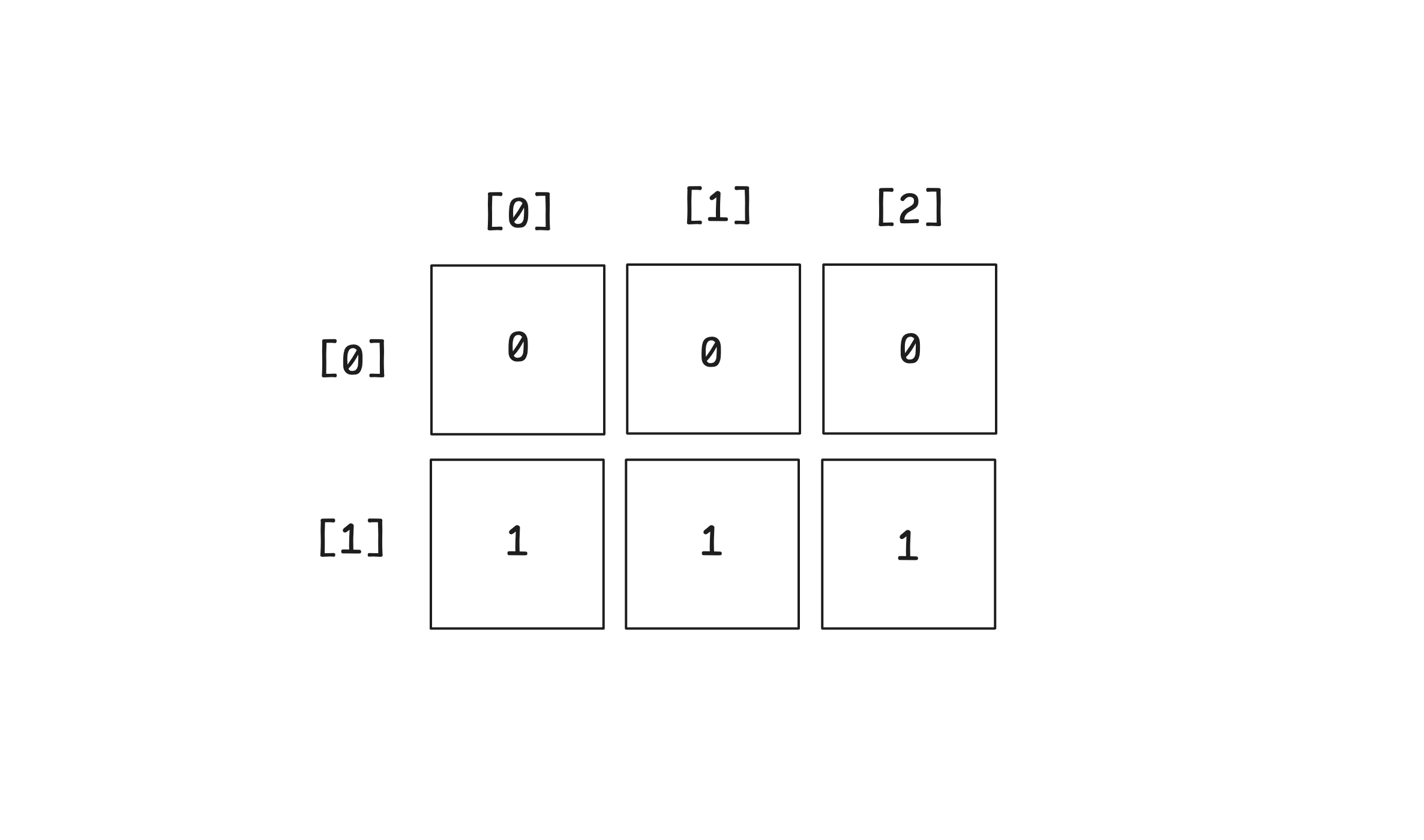
// 1) 리터럴
const arr = [[0, 0, 0], [1, 1, 1]];
// 2) 배열 생성자
const arr = [...new Array(3)].map((_, idx) => new Array(2).fill(idx))배열 연산의 시간 복잡도
크기가 N인 배열에 관한 연산의 시간 복잡도는 어떻게 될까요?
데이터 조회 : O(1)
배열은 임의 접근으로 모든 인덱스의 데이터에 한 번에 접근할 수 있습니다.
맨 뒤에 삽입할 경우 : O(1)
arr[N]에 임의 접근한 후 값을 넣어주기만 하면 됩니다. 기존에 있던 데이터들의 위치는 변하지 않습니다.
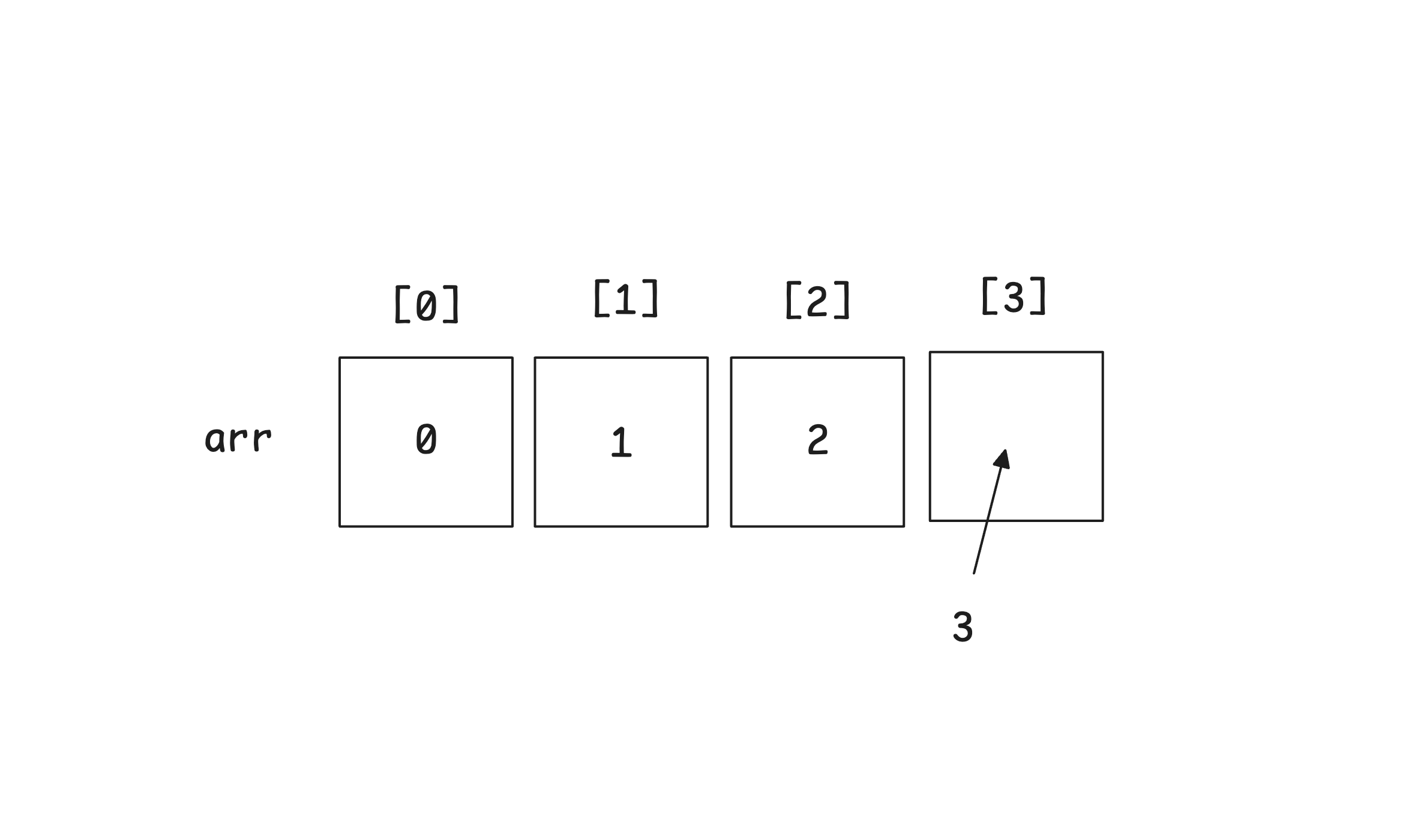
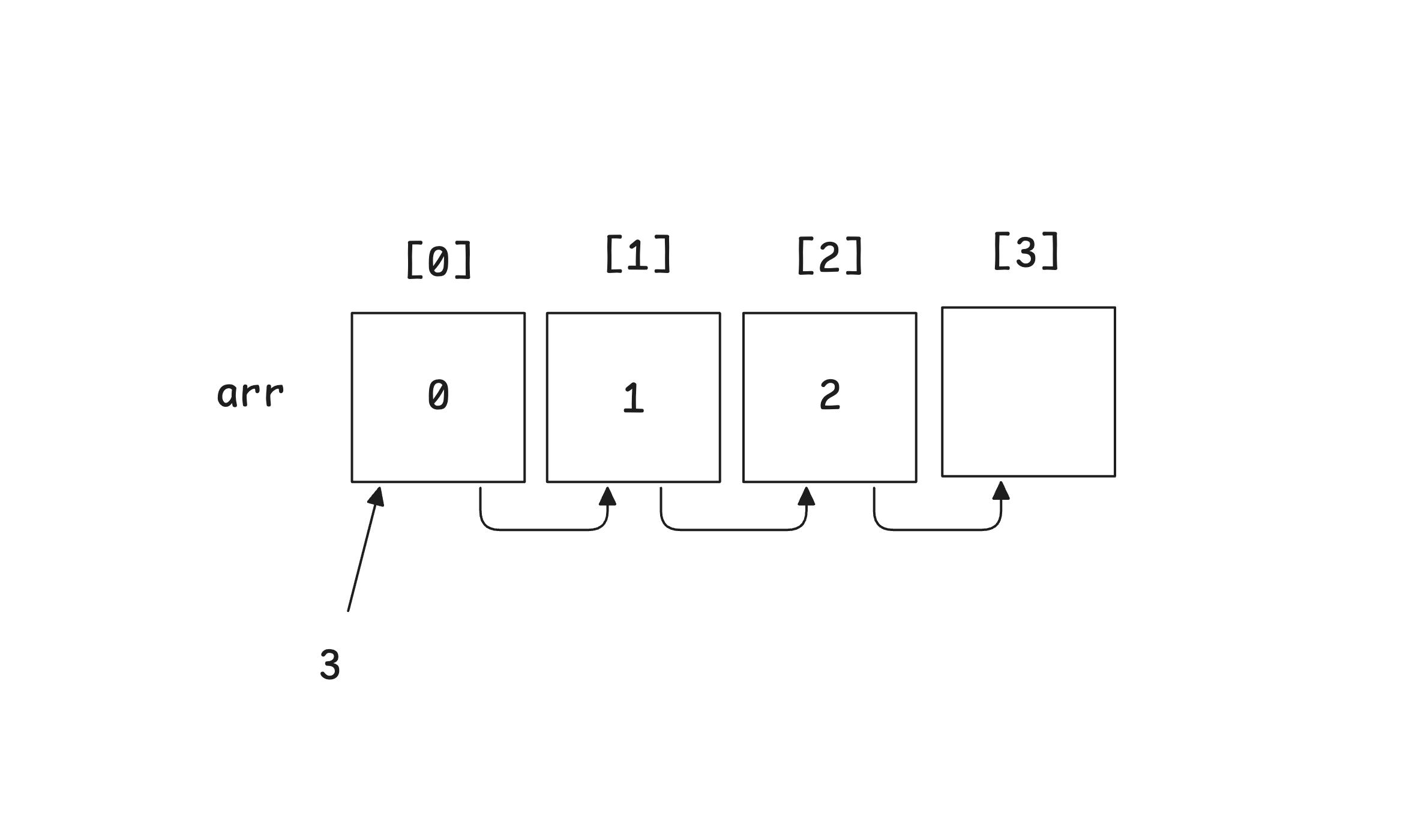
맨 앞 또는 중간에 삽입할 경우 : O(N)
삽입할 위치보다 뒤에 있는 데이터들을 한 칸씩 뒤로 밀고 나서 값을 삽입합니다. 기존의 데이터 개수만큼 연산이 필요합니다. 최악의 경우는 맨 앞에 삽입하는 경우로, 기존의 모든 데이터를 한 칸씩 뒤로 밀어주는 N번의 연산이 필요합니다.
→ 배열을 사용했을 때 효율적인 경우
데이터 조회를 자주 할 때
→ 배열을 사용하기 어려운 경우
배열로 표현할 데이터가 많은 경우, 메모리 한계로 인해 런타임 오류가 날 수 있습니다. (1차원은 1000만, 2차원은 3000 * 3000가 최대)
중간에 데이터 삽입이 많은 경우
자주 사용하는 배열 함수
- 배열 추가
- push(value): 배열의 끝에
value를 추가 - unshift(value): 배열의 앞에
value를 추가 - splice(index, 0, value1, value2, ...):
index에서 0개의 원소를 삭제한 후,value1, value2, ...를 넣음
- push(value): 배열의 끝에
- 배열 삭제
- pop(): 배열의 끝에서 원소를 삭제, 삭제된 값 return
- shift(): 배열의 앞에서 원소를 삭제, 삭제된 값 return
- splice(index, num, value1, value2):
index에서num개의 원소를 삭제한 후,value1, value2, ...를 넣음
- 고차 함수
- map(): 배열의 원소들을 함수의 return 값으로 변경함
- filter(): 배열의 원소 중 조건에 맞는 원소들만 걸러냄
- sort(): 배열을 정렬함
- every(): 배열 내의 모든 원소가 조건을 만족하는지를 return
- some(): 배열 내의 원소 중 조건을 만족하는 원소가 1개라도 있는지를 return
- find(): 조건을 만족하는 첫번째 원소, 만족하는 원소가 없는 경우 undefined return
- findIndex(): 조건을 만족하는 첫번째 원소의 인덱스, 만족하는 원소가 없는 경우 -1 return
- reduce(callback[, initialValue]): 배열의 각 요소를 순회하며 callback 함수의 실행 값을 누적하여 반환
const arr = [1, 2, 3, 4, 5];
arr.map(e => e * 2) // [2, 4, 6, 8, 10]
arr.filter(e => e > 2); // [3, 4, 5]
arr.sort((a, b) => a - b); // [1, 2, 3, 4, 5]
arr.every(e => e > 1); // false
arr.some(e => e > 1); // true
arr.find(e => e > 3); // 4
arr.findIndex(e => e > 3); // 3
arr.reduce((acc, cur, idx, arr) => acc + cur, 0) // 15더 자세한 배열 관련 함수 정리가 필요하다면 참고

글 잘 쓰고 싶어요