SHAP (SHapley Additive exPlanations)
SHAP란?
SHAP
- 머신러닝 모델의 예측을 설명하기 위한 framework
- 한 sample x에 대해 모델의 예측 결과 f(x)를 각 feature들의 기여도로 분해하여 설명하는 방법
- 이때 전체 예측값은 다음과 같이 표현됨
f(x) = base value + Σ (각 feature의 기여도) - SHAP는 additive feature attribution 방법 중 하나이며, 그중에서도 Shapley value를 기반으로 함
Shapley value
- cooperative game theory에서 나온 개념으로, 여러 요소(=player)가 함께 만든 결과를 각 요소의 기여도로 공정하게 분배하는 방법
- 각 요소가 결과에 기여한 정도를 계산할 때 모든 가능한 순서에서의 marginal contribution을 평균내어 결정함
(marginal contribution: 어떤 요소가 추가되었을 때 결과가 얼마나 바뀌는지)
왜 SHAP는 Shapley value를 사용하는가?
- SHAP는 feature attribution(각 feature의 기여도)을 계산하는 여러 방법 중에서 다음 3가지 성질을 동시에 만족하는 유일한 해가 Shapley value 기반이라는 것을 논문에서 보임
- local accuracy
- 모든 feature의 기여도를 더하면 실제 모델의 예측값과 같아야 함 (explanation이 실제 모델 output을 정확히 재현해야 함)
- missingness
- 어떤 feature가 모델에 사용되지 않으면 그 feature의 기여도는 0이어야 함
- consistency
- 어떤 feature가 모델에서 더 중요해졌다면 해당 feature의 기여도는 감소하지 않아야 함
SHAP에서 사용되는 주요 용어
-
base value/expected value
: 아무 feature도 모를 때의 모델의 평균적인 예측값
→ 보통 background data에 대한 평균 prediction
→ SHAP 설명은 이 값을 기준으로 시작됨 -
SHAP value
: 특정 sample에서 특정 feature가 prediction을 얼마나 증가(+)/감소(-)시켰는지를 나타내는 값
→ 모든 feature의 SHAP value를 더하면 최종 prediction이 됨 -
masking
: 특정 feature를 모르는 상태로 만들기 위한 과정
→ 실제로 feature를 제거할 수 없기 때문에, background data를 이용해 해당 feature를 가려(hidden) 대체함 -
background data
: feature를 모르는 상태를 정의하기 위해 사용하는 reference dataset
→ masking 시, 숨겨진 feature 값을 어떤 값으로 대체할지 결정하는 기준
→ 동시에 base value(=expected value)를 계산하는 데 사용됨- 즉, 아무것도 모르는 상태의 예측값을 정하고 feature를 하나씩 추가했을 때 얼마나 변하는지를 계산할 때 기준이 되는 데이터
- 기본적으로 train data의 일부 샘플을 사용함 (모델이 학습한 분포를 유지해야하기 때문)
정리
background data → base value 계산
background data + masking → feature 없는 상태 생성
→ 이걸 이용해서 marginal contribution 계산
→ 그 평균이 SHAP valueExplainer
SHAP는 하나의 알고리즘이 아니라 모델과 상황에 따라 다른 방식으로 Shapley value를 계산하는 여러 explainer들을 포함하는 framework임
model 타입
TreeExplainer
- tree 기반 모델(XGBoost, LightGBM, RandomForest 등)에 특화된 explainer
- Tree 구조를 활용하여 SHAP value를 빠르고 정확하게 계산함
- 대부분의 tabular + tree 모델에서 가장 많이 사용됨
LinearExplainer
- 선형 모델(Linear Regression, Logistic Regression 등)에 최적화된 explainer
- (독립 가정 시) SHAP value는 대략 coefficient × (feature - 평균) 형태로 계산됨
- feature 간 correlation을 고려하는 경우, 기여도가 여러 feature에 분산됨
KernelExplainer
- 어떤 모델에도 사용할 수 있는 model-agnostic explainer
- Shapley value를 weighted linear regression으로 근사하여 계산
- 모든 feature 조합을 직접 계산하는 대신 샘플링 기반으로 근사함
- 보통 다른 explainer를 사용할 수 없는 black-box 모델에 사용됨
PermutationExplainer
- feature를 하나씩 추가/제거하면서 prediction 변화를 측정하는 방식
- 여러 feature permutation을 통해 marginal contribution을 계산하고 평균내어 SHAP value를 근사함
- 일부 경우(local interaction이 낮을 때) 정확한 SHAP 값 계산 가능
- black-box 모델이지만 Kernel보다 효율적으로 계산하고 싶을 때 사용됨
PartitionExplainer
- feature를 독립적으로 보지 않고, 그룹 구조(계층 구조)를 고려하는 explainer
- correlated feature들을 하나의 그룹으로 묶어 처리
- 특징: correlation 구조 반영 가능
- feature 간 상관관계가 강할 때, 그룹 단위 해석이 필요할 때 사용됨
ExactExplainer
- 가능한 모든 feature 조합을 계산하여 SHAP value를 정확하게 계산함
- feature 수가 매우 적을 때 (≈10~15 이하) 사용함
SamplingExplainer
- Shapley value를 sampling 방식으로 근사하는 explainer
- 전체 feature 조합 대신 일부 조합만 샘플링하여 계산함
- KernelExplainer와 유사한 목적이지만, background data가 큰 경우 더 효율적일 수 있음
DeepExplainer
- 딥러닝 모델을 위한 explainer (Deep SHAP)
- DeepLIFT 기반으로 SHAP value를 근사함
- background data를 사용하여 기대값(E[f(x)])을 추정함
GradientExplainer
- gradient 기반 방식 (expected gradients)
- Integrated Gradients를 확장한 형태
- SHAP와 유사하지만 classical Shapley value와는 다르며, Aumann-Shapley value(연속형 확장)에 기반함
- 딥러닝 모델에서 gradient 기반 설명을 사용할 때 사용함
masker 타입
masker: feature를 모르는 상태를 어떻게 만들 것인지 정의하는 방법
Independent
- 각 feature를 서로 독립적이라고 가정하고 masking을 수행하는 방식
- 특정 feature를 숨길 때, 해당 feature 값을 background data에서 독립적으로 샘플링하여 대체함
- 즉, feature 간 상관관계를 고려하지 않음
- 특징
- 계산이 단순하고 빠름
- 모델이 실제로 사용하는 feature 영향만 직접적으로 반영
- correlated feature가 있을 경우 기여도가 왜곡될 수 있음
- 언제 사용
- feature 간 상관관계가 약할 때
- 모델이 어떻게 판단했는지를 그대로 보고 싶을 때
Partition
- feature들을 독립적으로 보지 않고, 계층적 구조(트리 구조)를 기반으로 그룹화하여 masking을 수행하는 방식
- correlated feature들을 하나의 그룹으로 묶어 함께 처리함
- 특징
- feature 간 상관관계를 반영 가능
- grouped Shapley value(Owen value) 기반
- Independent보다 더 현실적인 데이터 분포 반영
- 언제 사용
- feature 간 상관관계가 강할 때
- 그룹 단위 해석이 필요한 경우
Impute
- hidden feature를 단순히 제거하지 않고, 관측된 다른 feature들을 기반으로 추정(imputation)하여 대체하는 방식
- feature 간 조건부 분포(conditional distribution)를 반영함
- 특징
- 데이터의 상관관계를 가장 잘 반영함
- 실제 데이터 분포에 가까운 설명이 가능함
- 계산 비용이 상대적으로 큼
- 언제 사용
- feature 간 상관관계가 매우 중요한 경우
Text
- 텍스트 데이터를 위한 masker
- 단어 또는 토큰 단위로 feature를 masking하며, tokenizer를 기반으로 동작함
- 숨겨진 토큰은 mask token([MASK] 등)으로 대체됨
- 특징:
- NLP 모델(BERT 등)에 사용
- 토큰 단위로 SHAP value 계산 가능
- 언제 사용
- 텍스트 분류, 감성 분석 등 NLP 모델 설명
Image
- 이미지 데이터를 위한 masker
- 특정 영역(픽셀 또는 패치)을 blur, 평균값, inpainting 등으로 대체하여 masking 수행
- 특징
- 이미지 영역 단위로 feature 중요도 계산 가능
- 시각적으로 직관적인 설명 제공
- 언제 사용
- CNN, ViT 등 이미지 모델 설명
Fixed
- masking을 수행하지 않고, 특정 값을 고정하여 사용하는 방식
- 일부 feature를 항상 동일한 값으로 유지함
- 특징
- 특정 feature를 제거하지 않고 통제 변수처럼 다룰 때 사용
- 실험적 분석에 유용
- 언제 사용
- 특정 feature의 영향만 분리해서 보고 싶을 때
shap.Explainer
- SHAP에서 사용하는 통합 explainer 인터페이스
- 모델과 masker를 입력으로 받아, 상황에 맞는 SHAP 알고리즘을 자동으로 선택하여 SHAP value를 계산하는 객체
- 내부적으로 TreeExplainer, LinearExplainer, PermutationExplainer 등의 subclass 중 하나를 선택함
- 입력:
- model: 설명할 모델 또는 함수
- masker (또는 background data): feature를 숨기는 방식과 기준 데이터 정의
- 출력:
- shap.Explanation 객체 (SHAP value, base value, 입력 데이터 등을 포함)
shap.Explainer 주요 파라미터
model
- 설명할 대상 모델 또는 함수
- 입력 데이터를 받아 prediction을 반환하는 객체
- ex) sklearn, xgboost, lightgbm 모델
masker (또는 background data)
- feature를 숨기는 방식과 기준 데이터를 정의
- SHAP에서 feature를 모르는 상태를 어떻게 구성할지 결정
- background data를 입력하면 내부적으로 기본 masker(주로 Independent)가 생성됨
- ex
- tabular:
X_train,shap.maskers.Independent(X_train) - correlation 반영:
shap.maskers.Partition(X_train) - 조건부 분포 반영:
shap.maskers.Impute(X_train) - text: tokenizer 기반 masker
- image: blur / inpainting 기반 masker
- tabular:
algorithm
- 사용할 SHAP 알고리즘(= explainer 종류)을 지정
- 주요 옵션:
"auto"(기본값): model과 masker를 기반으로 적절한 explainer 자동 선택- ex) tree model → TreeExplainer, linear model → LinearExplainer
"tree": TreeExplainer 사용"linear": LinearExplainer 사용"permutation": PermutationExplainer 사용"partition": PartitionExplainer 사용"kernel": KernelExplainer 사용"deep": DeepExplainer 사용"exact": ExactExplainer 사용
link
- 모델 출력과 SHAP value를 연결하는 함수
- SHAP는 link 공간에서 additive 구조를 유지함
- 주요 옵션:
"identity": 그대로 사용 (회귀 문제)"logit": log-odds 변환 (분류 문제에서 확률 설명 시)
- 의미: SHAP value는 link 적용된 공간에서 합이 맞도록 계산됨
feature_names
- feature 이름을 지정
- 결과 해석 및 시각화(plot)에 사용됨
output_names
- 모델 출력 이름 지정 (예: 클래스 이름)
- multi-output 모델에서 사용
seed
- 랜덤 연산에 대한 seed 설정
- sampling 기반 explainer에서 결과 재현성 확보
linearize_link
- 비선형 link 함수 사용 시, additive 성질을 유지하도록 보정하는 옵션
- 일반적인 사용에서는 크게 신경 쓰지 않아도 됨
shap.Explainer output
.values: SHAP value.base_values: base value (expected value).data: 입력 feature 값
shap.Explainer 코드
- 패턴
explainer = shap.Explainer(
model, # 설명 대상
masker, # background or masker
algorithm=..., # explainer 선택
link=..., # 출력 공간
)- 사용 예시
import shap
# model: 이미 학습된 모델
# X_train: background data
explainer = shap.Explainer(
model,
X_train # → 자동으로 Independent masker 생성
)
# X_test: 설명 대상이 되는 데이터 (sample)
# test data를 넣는 경우(일반적): 모델이 새로운 데이터에서 어떻게 판단했는지 확인 가능
# train data를 넣는 경우: 모델의 학습 패턴 확인 가능
shap_values = explainer(X_test)- output 확인
print(shap_values.values.shape) # SHAP values
print(shap_values.base_values) # base value
print(shap_values.data.shape) # 입력 데이터Plot 종류
bar plot
- SHAP 값을 이용해 feature importance를 막대그래프로 표현하는 plot
- max_display 파라미터로 표시할 feature 수를 조절할 수 있음
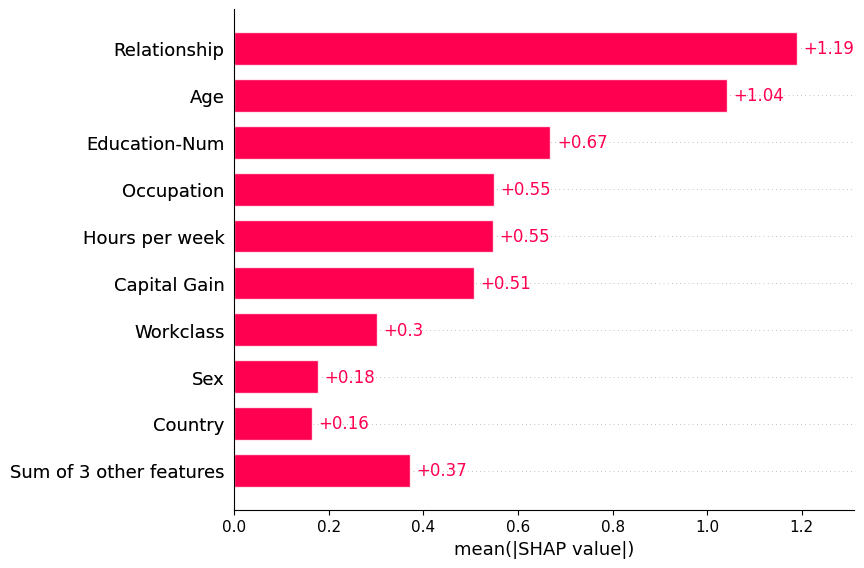
global bar plot
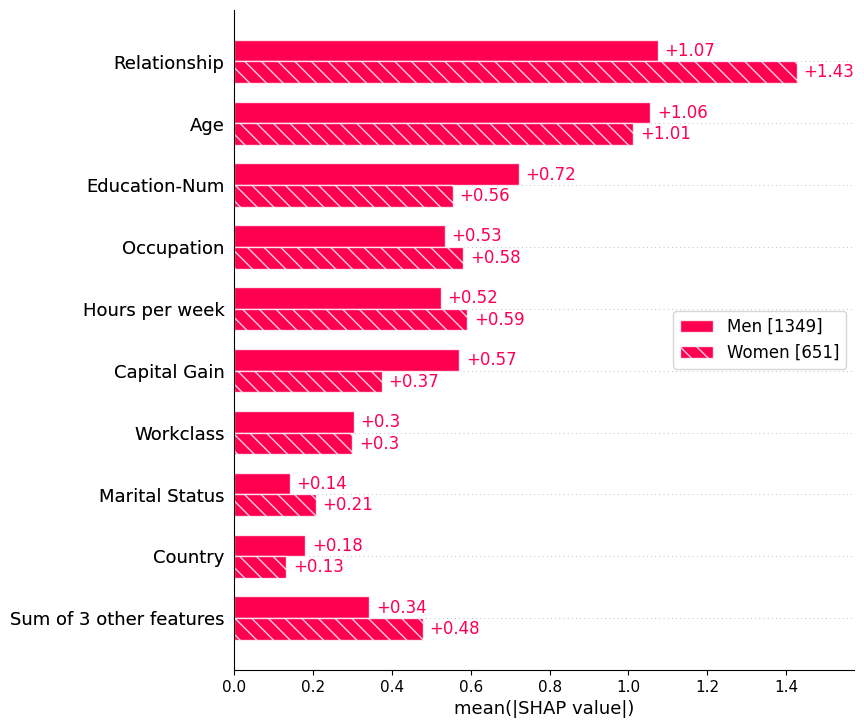
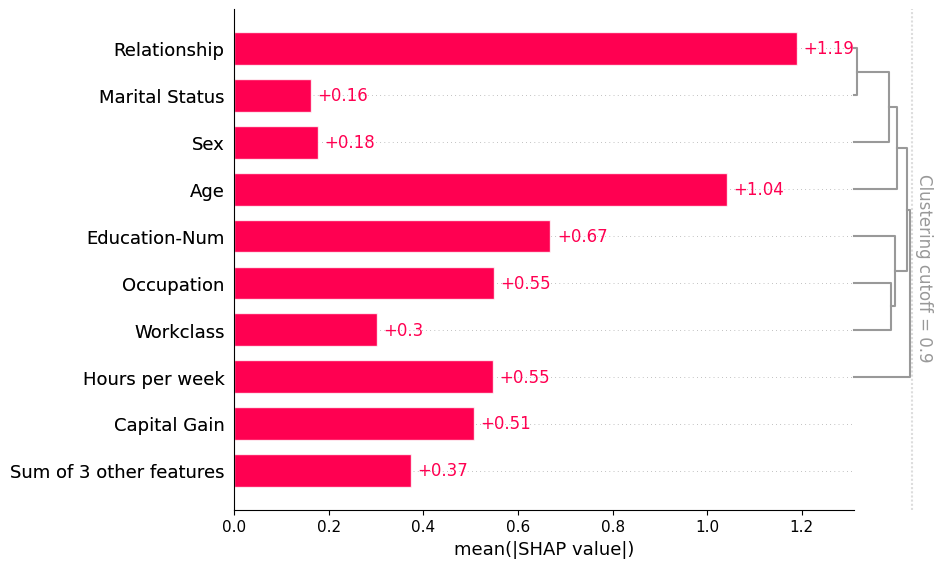
여러 sample을 입력하면 각 feature의 중요도를 mean(|SHAP value|)로 계산하여 global importance를 표시함
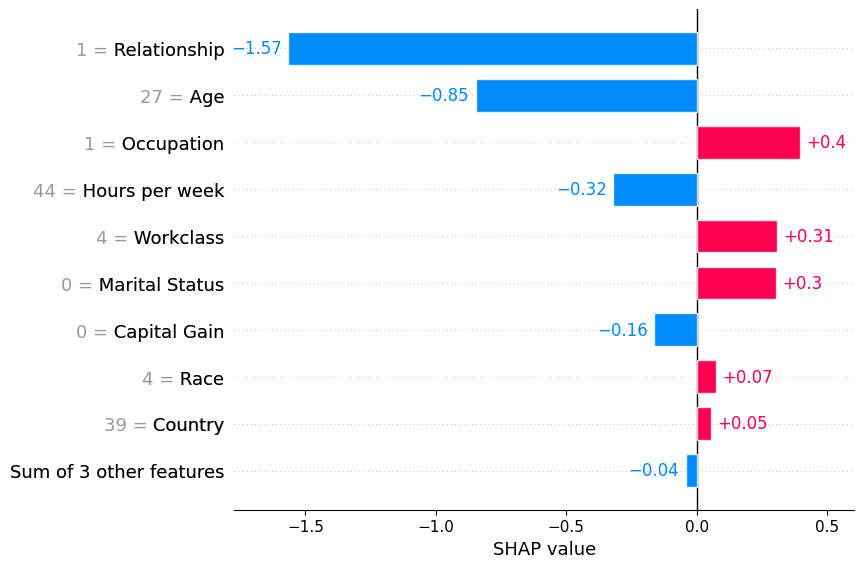
local bar plot
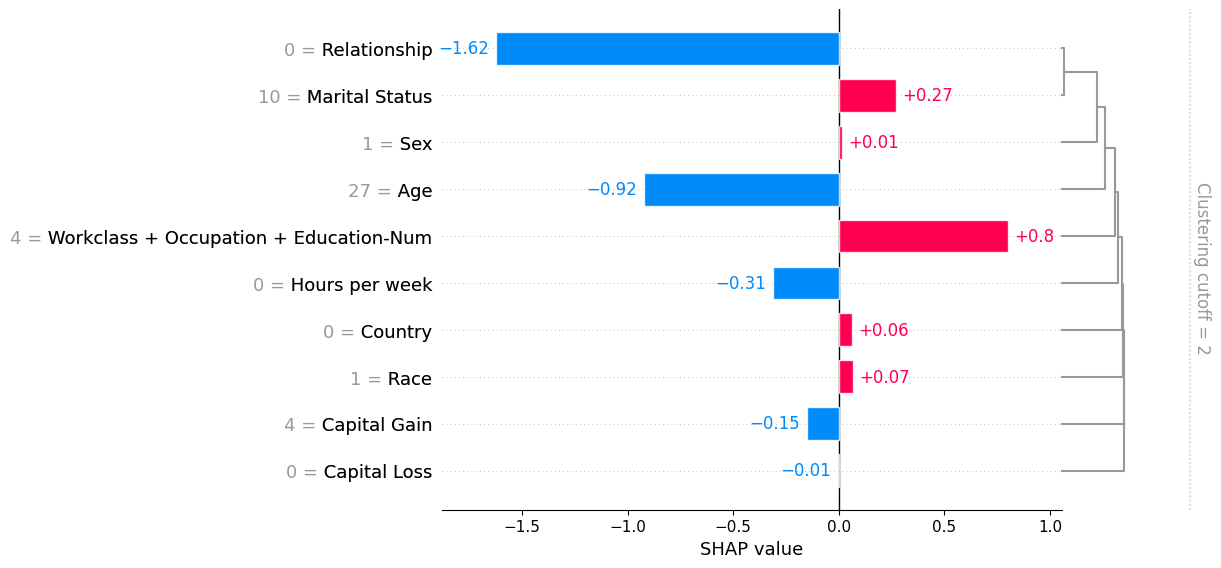
단일 sample을 입력하면 해당 sample의 SHAP value를 기반으로 local importance를 표시함
cohort bar plot
여러 Explanation 객체를 입력하면 cohort 간 비교도 가능함
feature clustering
feature clustering을 적용하여 feature 간 중복 구조를 함께 시각화할 수 있음
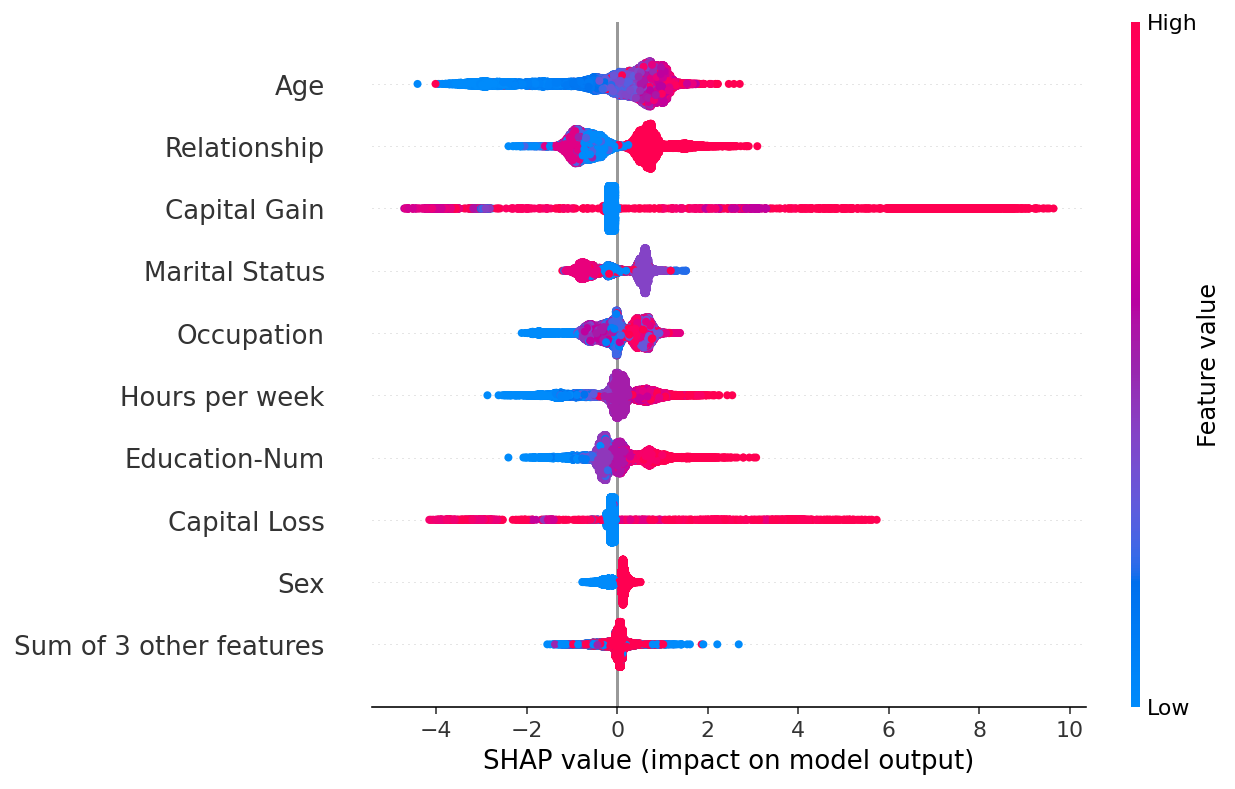
beeswarm plot
- 각 feature에 대해 모든 sample의 SHAP 값을 점으로 표현하는 plot
- feature importance와 SHAP value 분포를 동시에 보여주는 global summary plot
- x축은 SHAP value이며, 각 점은 하나의 sample을 의미함
- 색상은 해당 feature 값의 크기를 나타냄
- 점들이 수직으로 퍼지는 것은 SHAP value 분포를 나타냄
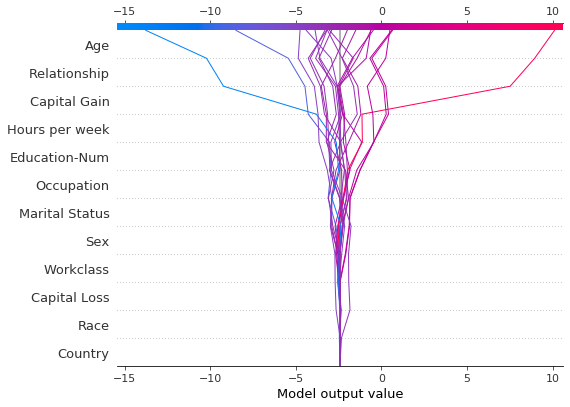
decision plot
- SHAP value가 누적되면서 prediction이 어떻게 변화하는지 보여주는 plot
- 여러 sample을 동시에 시각화하여 prediction 경로를 비교할 수 있음
- 각 선은 하나의 sample을 나타냄
- feature가 추가될 때마다 SHAP value가 누적되어 prediction이 변화함
heatmap plot
- SHAP value를 행렬 형태로 시각화한 plot
- sample 간 SHAP value 패턴을 기반으로 클러스터링하여 정렬함
- SHAP value 자체를 기준으로 supervised clustering을 수행함
- 유사한 설명 패턴을 가진 sample 그룹을 확인할 수 있음
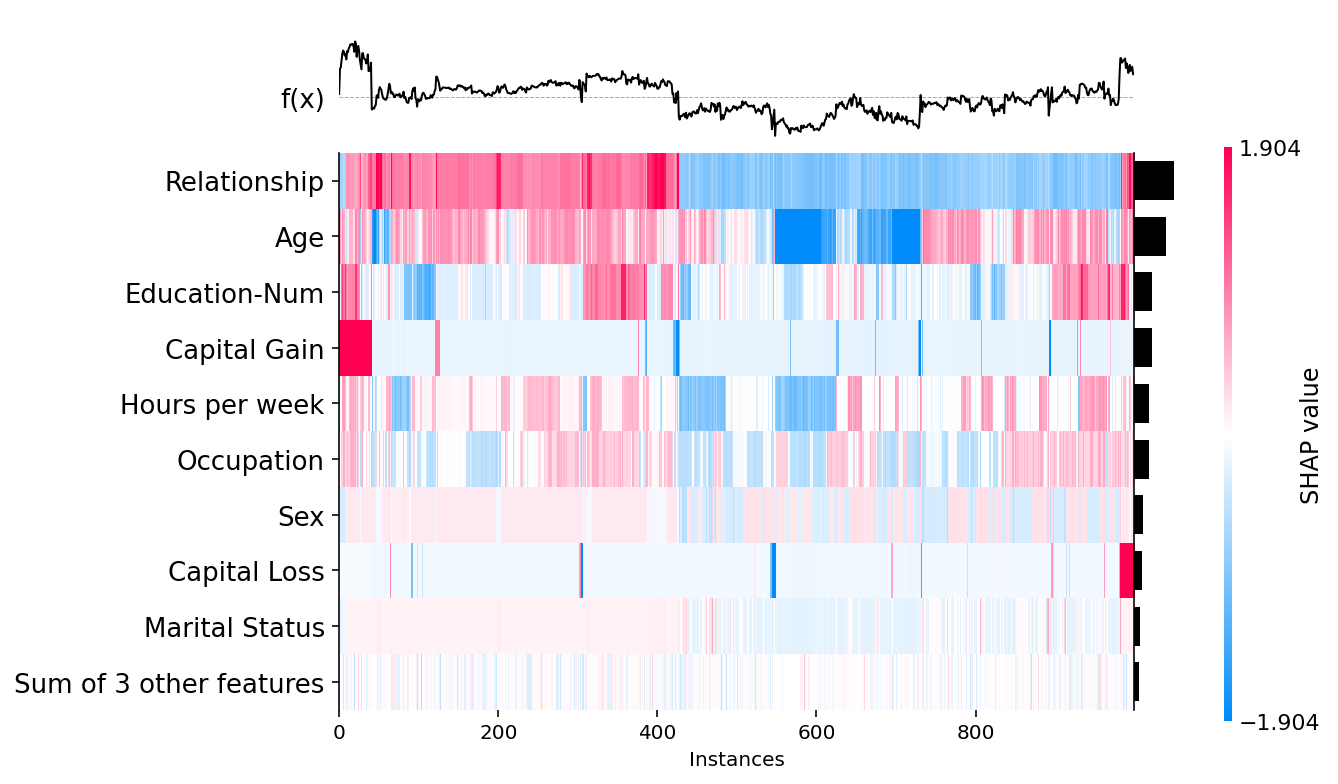
image plot
- 이미지 데이터에서 SHAP value를 시각화하는 plot
- 이미지의 특정 영역이 prediction에 얼마나 기여했는지를 표시함
- masking과 inpainting 등을 활용하여 feature importance를 계산함
- 이미지 영역 단위의 중요도를 시각적으로 표현함

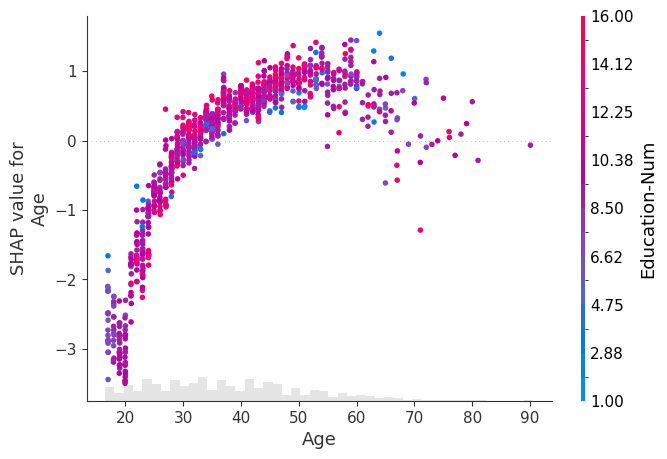
scatter plot
- 특정 feature 값과 해당 feature의 SHAP value 관계를 나타내는 plot
- SHAP dependence plot이라고도 함
- x축은 feature 값, y축은 SHAP value
- 색상은 다른 feature 값을 나타내며 interaction을 확인할 수 있음
- SHAP value의 분산을 통해 feature interaction을 분석할 수 있음
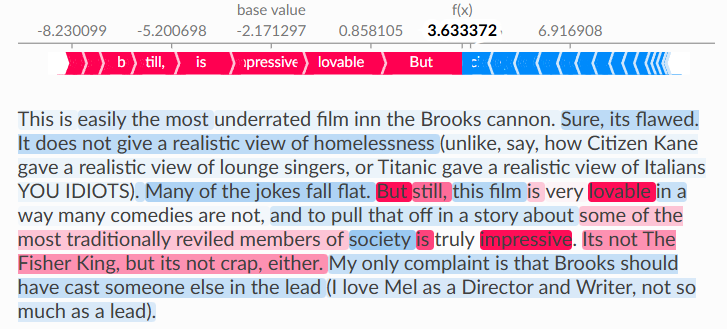
text plot
- 텍스트 데이터에서 SHAP value를 시각화하는 plot
- 토큰 단위로 SHAP value를 계산하여 표시함
- 각 단어 또는 토큰이 prediction에 미치는 영향을 시각적으로 표현함
violin summary plot
- SHAP value의 분포를 violin plot 형태로 표현하는 plot
- beeswarm plot과 유사하지만, 분포를 더 명확하게 보여줌
- feature별 SHAP value의 밀도 분포를 확인할 수 있음
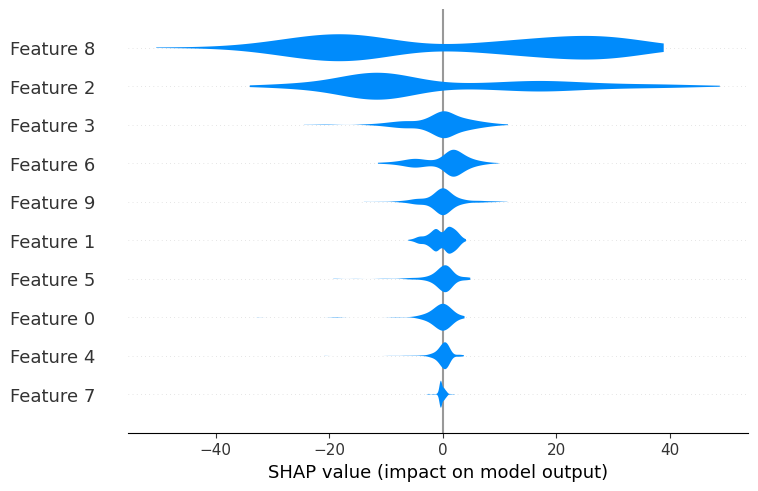
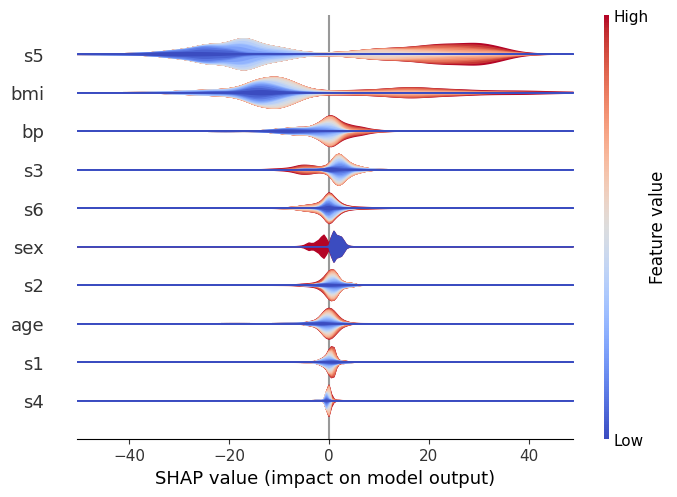
- layered violin plot
- violin plot의 확장 형태로, plot_type="layered_violin"으로 설정하여 사용할 수 있음
- feature 값의 크기(높음/낮음)에 따른 영향 방향을 함께 보여줌
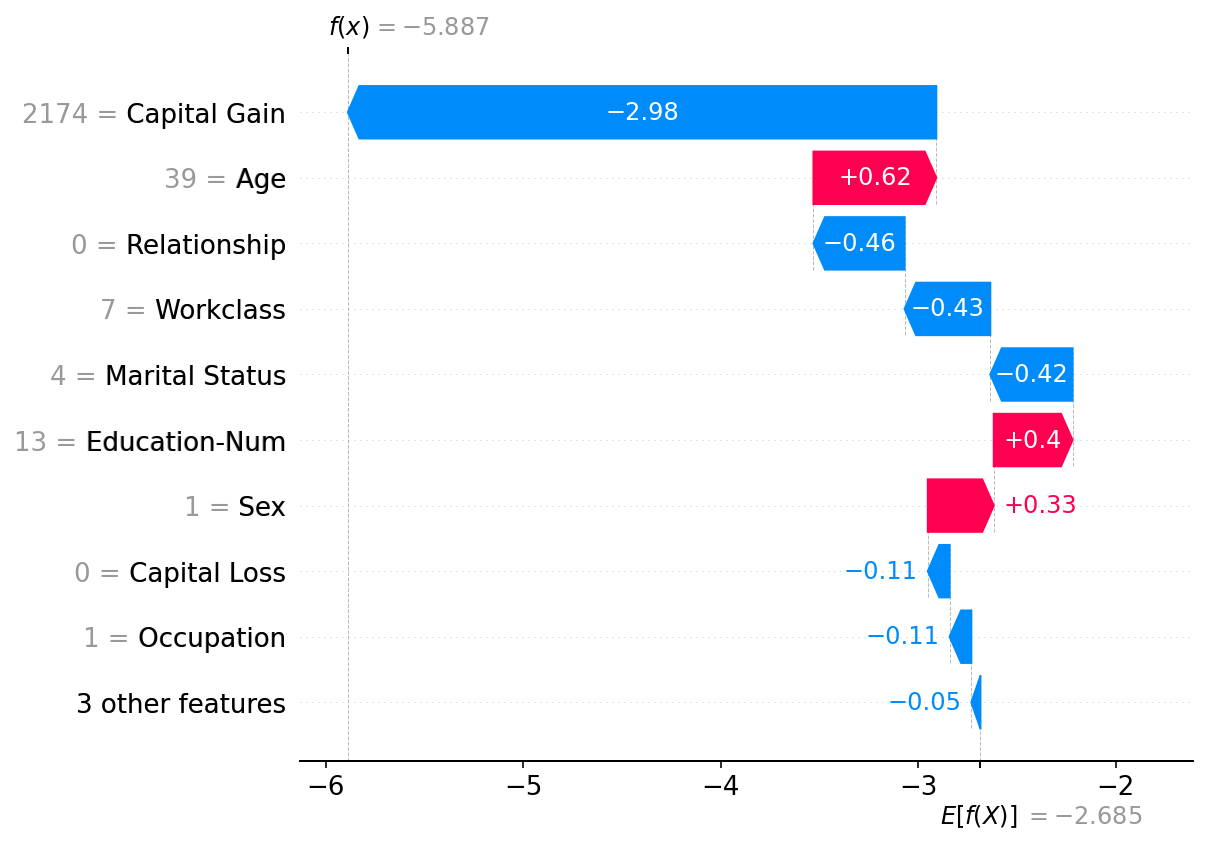
waterfall plot
- 단일 sample에 대해 SHAP value를 누적하여 보여주는 plot
- base value에서 시작하여 각 feature의 기여도를 순차적으로 더해 최종 prediction에 도달함
- feature는 영향력이 큰 순서로 정렬됨
- 각 feature가 prediction을 증가시키는지 감소시키는지 확인할 수 있음