문제
| 시간 제한 | 메모리 제한 | 제출 | 정답 | 맞힌 사람 | 정답 비율 |
|---|---|---|---|---|---|
| 2 초 | 128 MB | 280832 | 109467 | 65040 | 37.659% |
문제 설명
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
출력
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
예제 입력 1
4 5 1
1 2
1 3
1 4
2 4
3 4예제 출력 1
1 2 4 3
1 2 3 4예제 입력 2
5 5 3
5 4
5 2
1 2
3 4
3 1예제 출력 2
3 1 2 5 4
3 1 4 2 5예제 입력 3
1000 1 1000
999 1000예제 출력 3
1000 999
1000 999문제 풀이 아이디어
내가 정리한 DFS/BFS
나의 첫 DFS/BFS 문제였으므로 위의 벨로그 포스팅을 참고하여 이 문제를 풀이하였다.
초기 코드
from collections import deque
import sys
input = sys.stdin.readline
n, m, v = map(int, input().split())
graph = [[] for x in range(n+1)] # 빈 그래프 생성
visited_dfs = [False] * (n+1) # 각 노드의 방문 정보 저장
visited_bfs = [False] * (n+1) # 각 노드의 방문 정보 저장
for _ in range(m):
a, b = map(int, input().split())
graph[a].append(b)
def dfs(graph, v, visited):
visited[v] = True # 현재 노드 방문 처리
print(v, end = ' ') # 현재 노드 출력, 구분자는 공백
for i in graph[v]: # 현재 노드와 인접한 노드에 대해 반복문 실행
if not visited[i]: # 인접한 노드가 방문 노드가 아닐 때
dfs(graph, i, visited) # dfs 재귀함수 실행
def bfs(graph, start, visited):
queue = deque([start])
visited[start] = True
while queue:
v = queue.popleft()
print(v, end = ' ')
for i in graph[v]:
if not visited[i]:
queue.append(i) # 방문하지 않은 인접한 노드를 append
visited[i] = True
dfs(graph, v, visited_dfs)
print()
bfs(graph, v, visited_bfs)틀렸다고 떴다 ...
이유가 멀까 .. 하고 열심히 손으로 그려서 실행과정을 써봄 ..
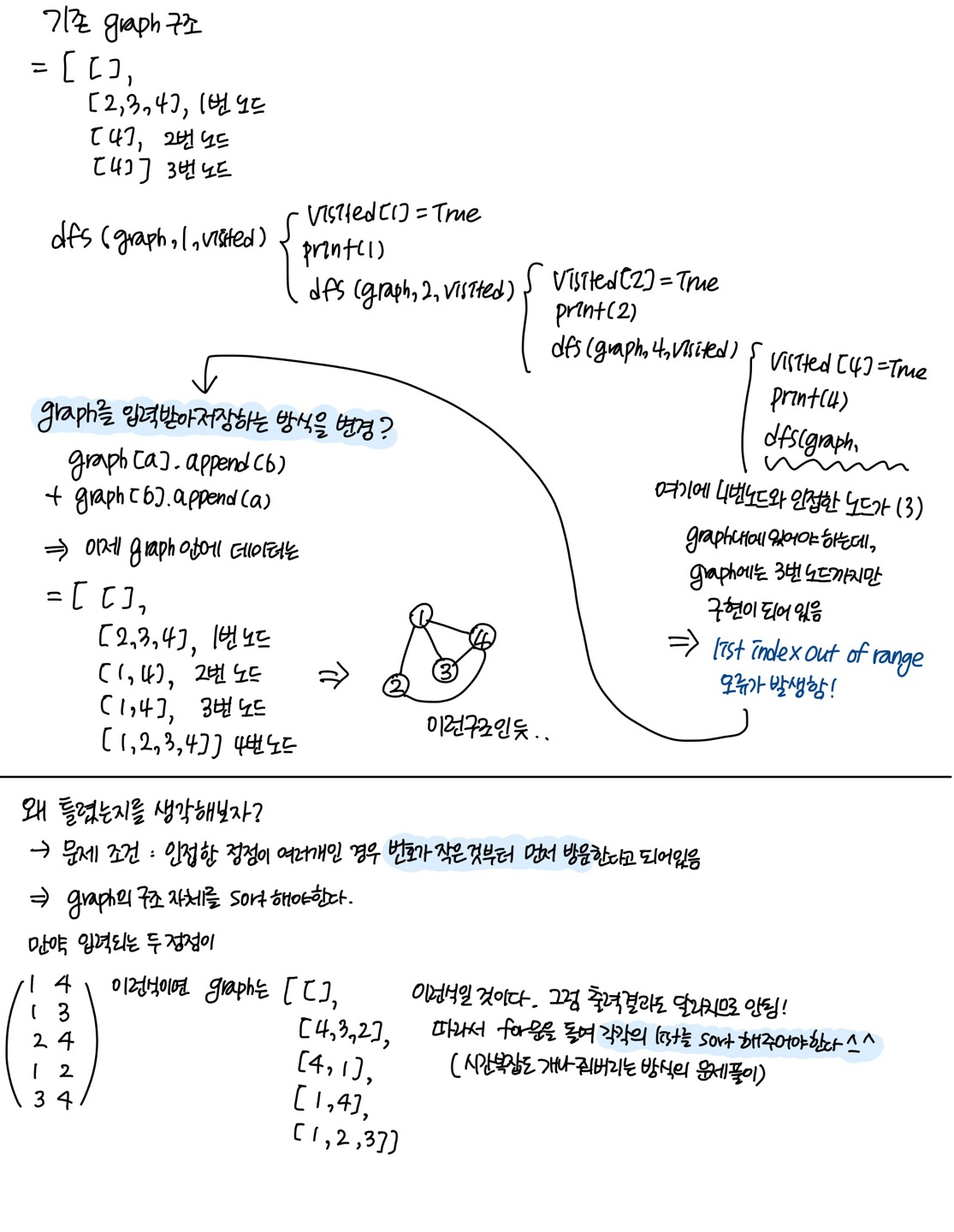
문제는 이렇게 두가지였다.
1) graph 저장 방식의 오류
[[],
[], # 1번 노드의 인접한 노드
[], # 2번 노드의 인접한 노드
[], # 3번 노드의 인접한 노드
...
[]] # 마지막 노드의 인접한 노드- 이런식으로 graph구조를 입력받길 원했는데,
graph[a].append(b)이 부분은 이를 충족하지 못했다.
graph[b].append(a)그래서 이 부분을 추가해줌
(이걸 놓친 건 진짜 바보인가 . . )
2) graph가 정렬되어 있지 않음
- 문제에서는 인접한 정점이 여러개인 경우 번호가 작은 것부터 가장 먼저 방문한다고 되어있음. 근데 나는 이걸 고려하지 않았음 ...
- 이는 입력받은 graph의 내부 리스트를 각각 sort해주는 것으로 해결해줌
그렇게 해서 완성된 나의 최종 코드
최종 코드
from collections import deque
import sys
input = sys.stdin.readline
n, m, v = map(int, input().split())
graph = [[] for x in range(n+1)] # 빈 그래프 생성
visited_dfs = [False] * (n+1) # 각 노드의 방문 정보 저장
visited_bfs = [False] * (n+1) # 각 노드의 방문 정보 저장
for _ in range(m):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
for i in graph:
i.sort()
def dfs(graph, v, visited):
visited[v] = True # 현재 노드 방문 처리
print(v, end = ' ') # 현재 노드 출력, 구분자는 공백
for i in graph[v]: # 현재 노드와 인접한 노드에 대해 반복문 실행
if not visited[i]: # 인접한 노드가 방문 노드가 아닐 때
dfs(graph, i, visited) # dfs 재귀함수 실행
def bfs(graph, start, visited):
queue = deque([start])
visited[start] = True
while queue:
v = queue.popleft()
print(v, end = ' ')
for i in graph[v]:
if not visited[i]:
queue.append(i) # 방문하지 않은 인접한 노드를 append
visited[i] = True
dfs(graph, v, visited_dfs)
print()
bfs(graph, v, visited_bfs)
근데 sys 쓴 코드(1번째)하고 안 쓴 코드(2번째)하고 시간이 이렇게까지 차이날 일인가? 둘다 시간제한에 걸리진 않지만 이 문제에서는 특히나 시간차이가 더 많이 나는 것 같다 . . . 왜지?
이후 다른 사람들은 어떻게 풀었는지 궁금해서 다른 사람들의 코드를 찾아봤다.
다른 풀이
이분의 포스팅에 나온 풀이가 대부분 사람들의 풀이 방식인 것 같다.
N,M,V = map(int,input().split())
#행렬 만들기
graph = [[0]*(N+1) for _ in range(N+1)]
for i in range (M):
a,b = map(int,input().split())
graph[a][b] = graph[b][a] = 1
#방문 리스트 행렬
visited1 = [0]*(N+1)
visited2 = visited1.copy()
#dfs 함수 만들기
def dfs(V):
visited1[V] = 1 #방문처리
print(V, end=' ')
for i in range(1, N+1):
if graph[V][i] == 1 and visited1[i] == 0:
dfs(i)
#bfs 함수 만들기
def bfs(V):
queue = [V]
visited2[V] = 1 #방문처리
while queue:
V = queue.pop(0) #방문 노드 제거
print(V, end = ' ')
for i in range(1, N+1):
if(visited2[i] == 0 and graph[V][i] == 1):
queue.append(i)
visited2[i] = 1 # 방문처리
dfs(V)
print()
bfs(V)-
크게는 dfs()함수와 bfs()함수를 구현하고 각각의 함수를 재귀함수, queue 자료구조를 이용해 만든 건 같지만, 안에 세부적인 구현방식이 다르다.
-
graph를 나와 달리 행렬구조로 생성하였다.
-
따라서 이어진 노드들은 graph[a][b] 값을 1로 하여 풀이하였다.
-
이 코드가 훨씬 간결한 것 같기도 . . .^_^(우선 sort를 안씀)
