
(20220518) DataBricks Lakehouse Webinar를 정리한 내용입니다.
https://youtu.be/aopp39C5iws
자료링크 : https://tinyurl.com/db-lakehouse-webinar
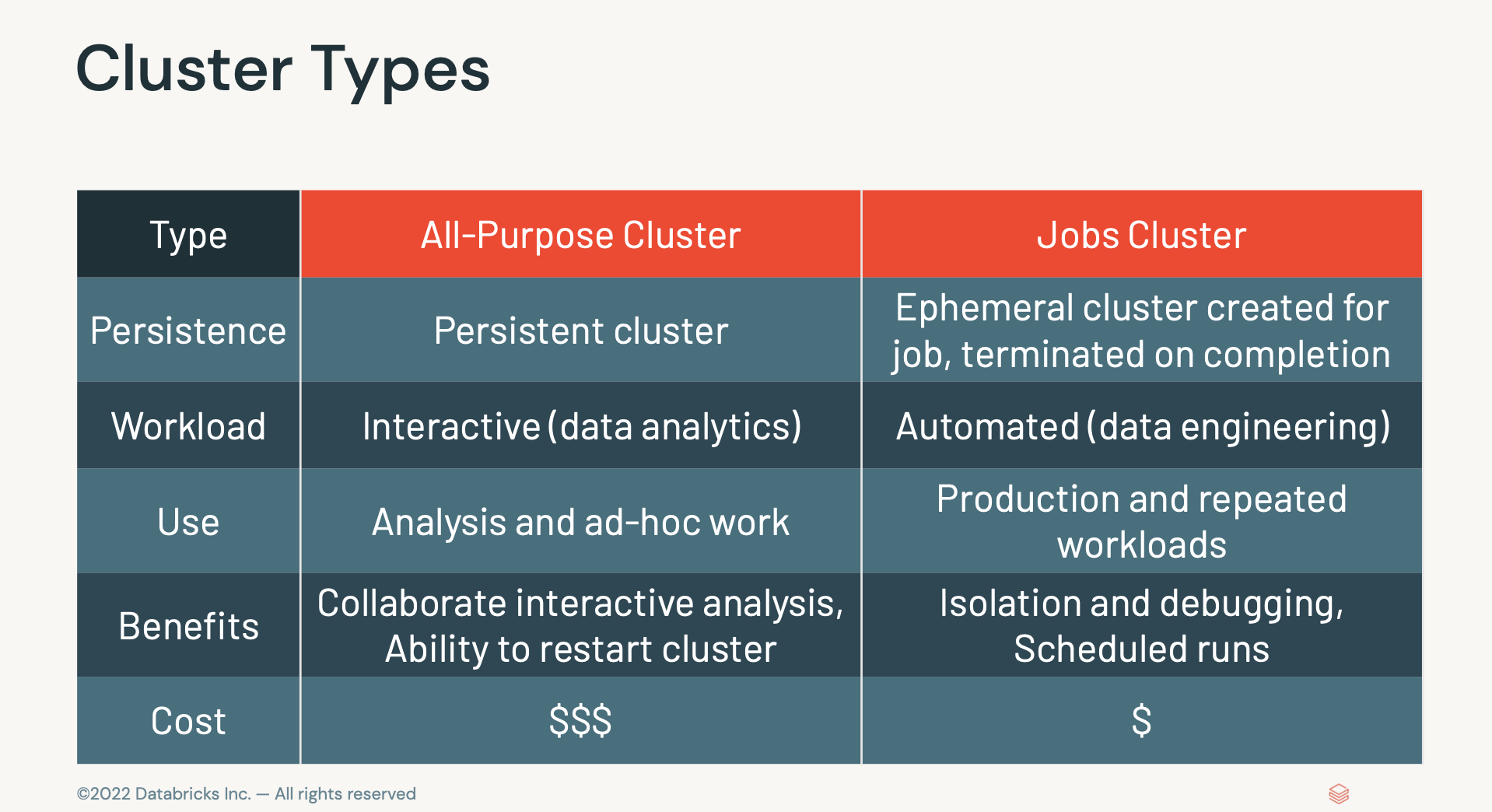
- All-purpose 다목적으로 분석가 뿐아니라 데이터 조직 전체가 사용하는 클러스터유형. (업무용 - 상시)
- Job : 주기적으로 실행해야하는 잡들. ETL용.(스케쥴 - 필요할때마다)
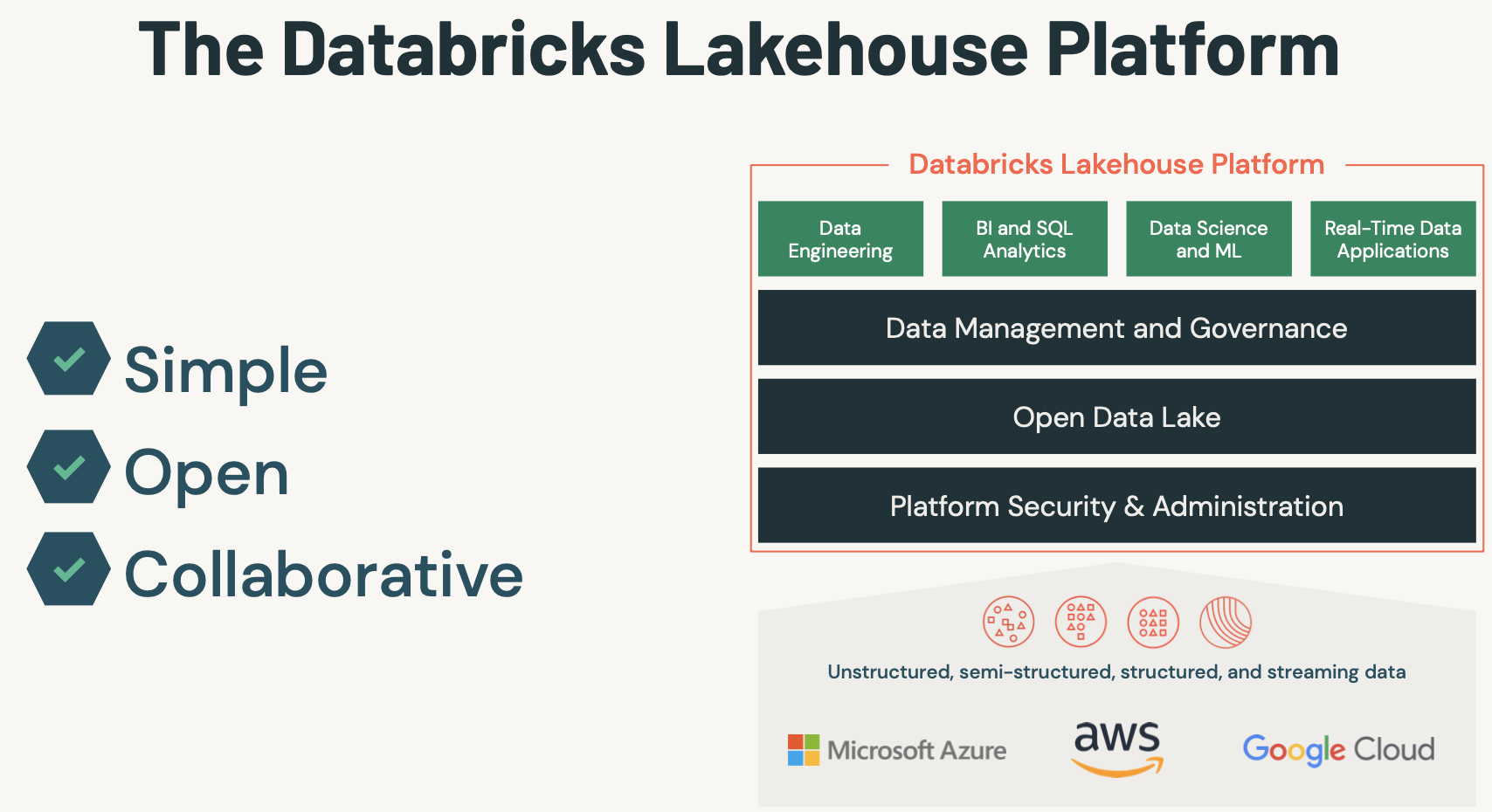
(챕터1) 데이터브릭스 시작
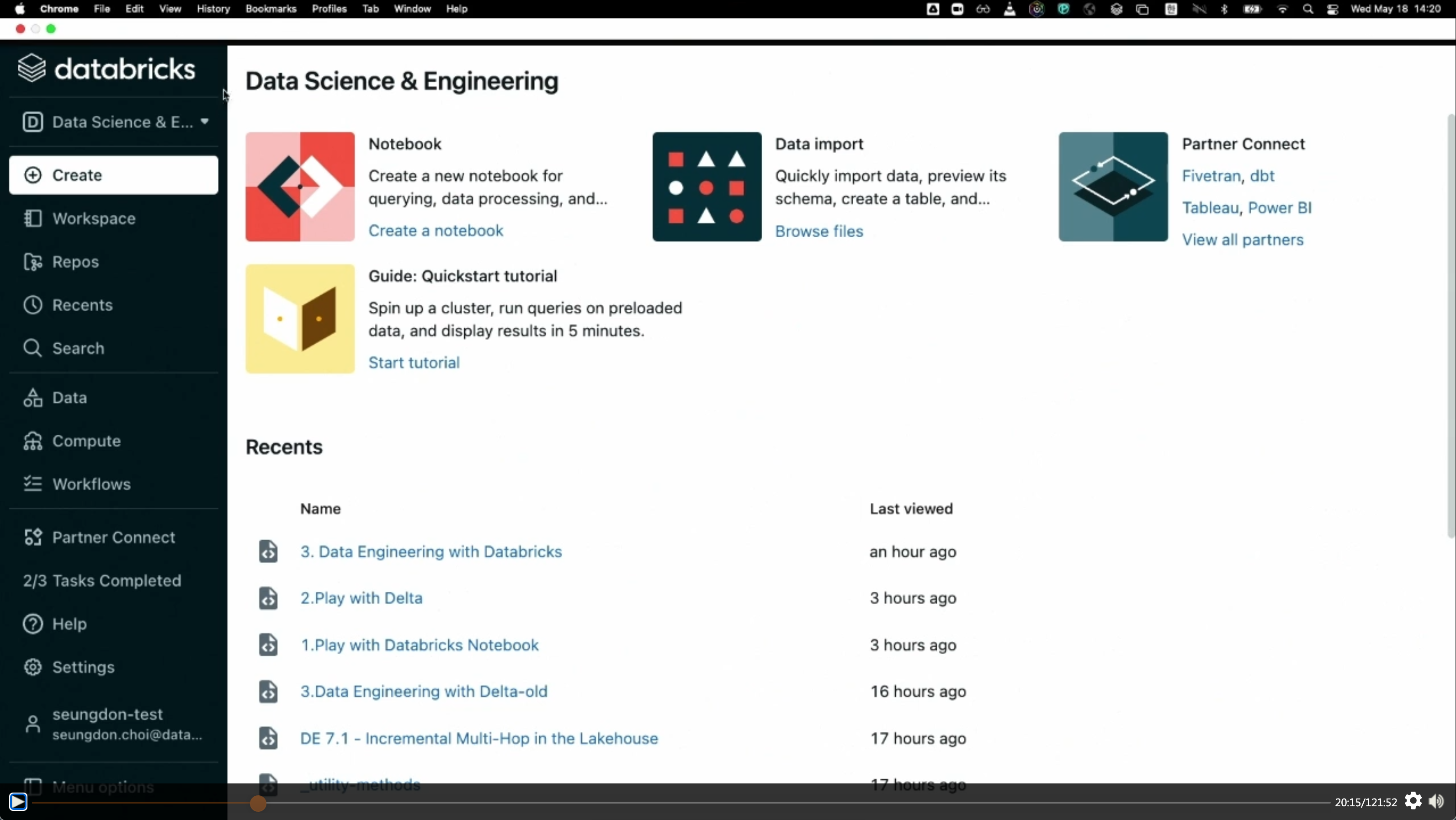
- 첫 화면은 다음과 같다.
COMPUTE 옵션
- 클러스터를 띄워야 이후 작업을 할 수 있음.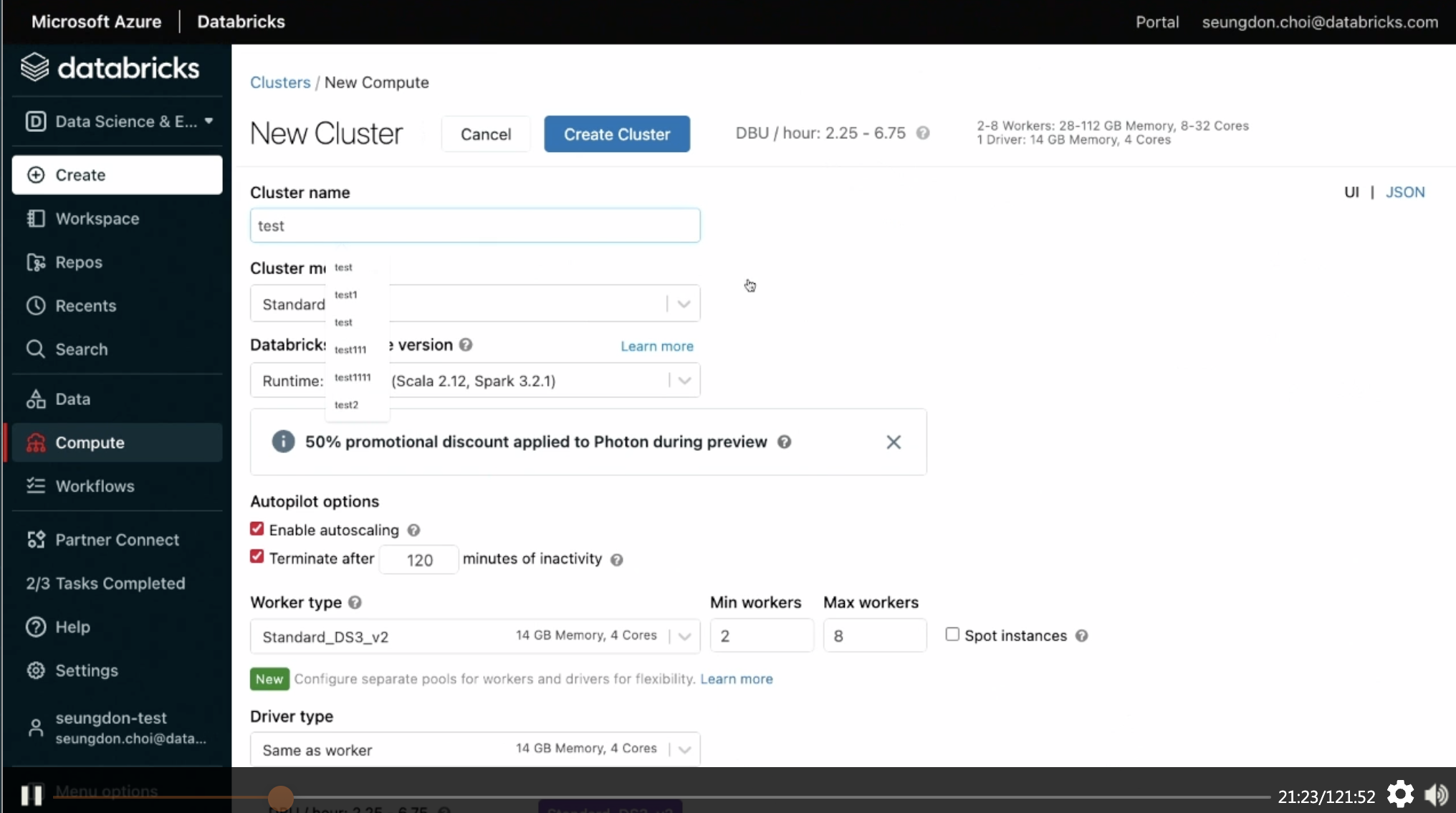
- ML을 할때 필요한 패키지를 다 깔아야 하는데,여기서는 ML옵션으로 다 쓸 수 있음.
- Photon:
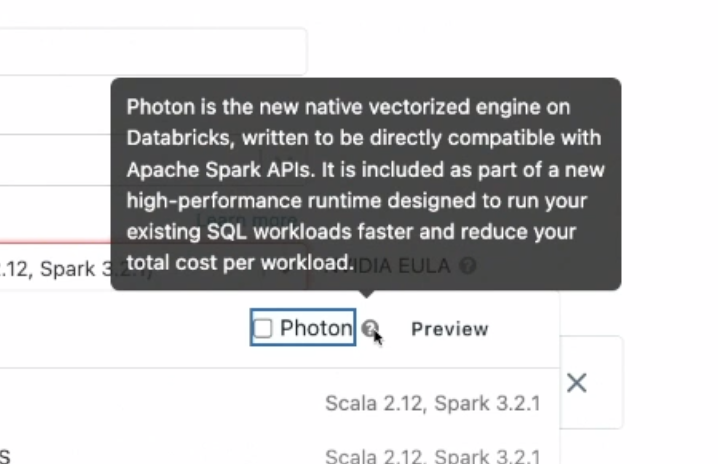
-
위 과정을 걸쳐서 만든 클러스터 리스트 'workshop'
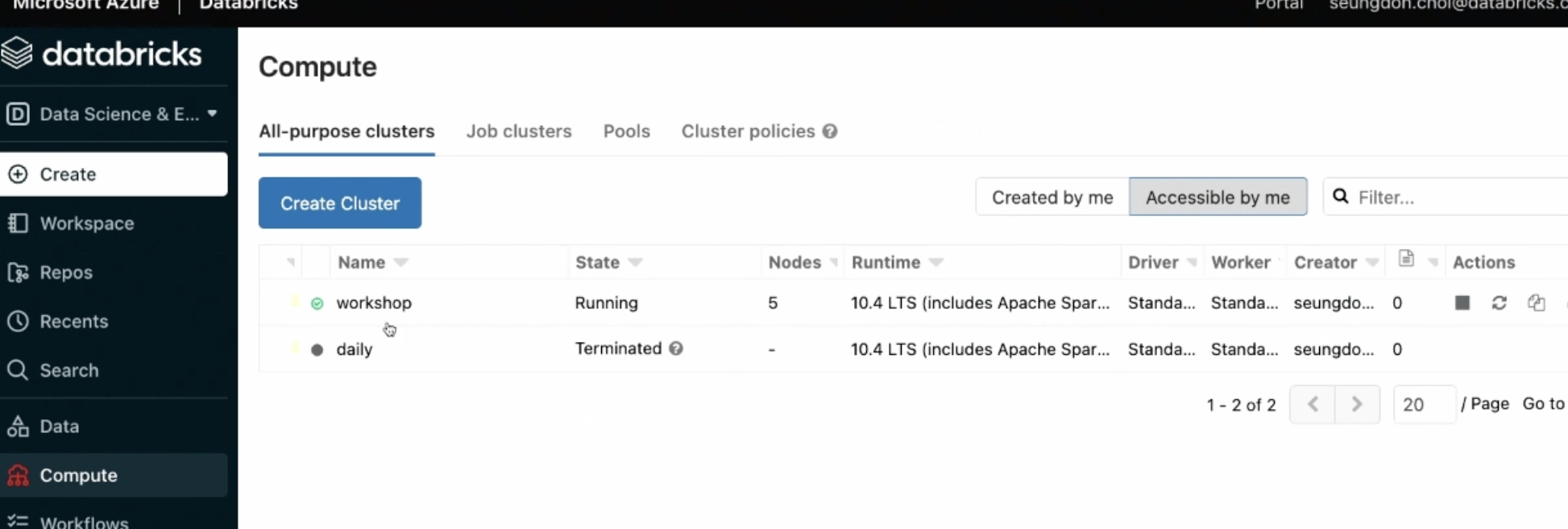
-
여러 유저별로 워크스페이스를 공유하고 권한을 할당할 수 있다.
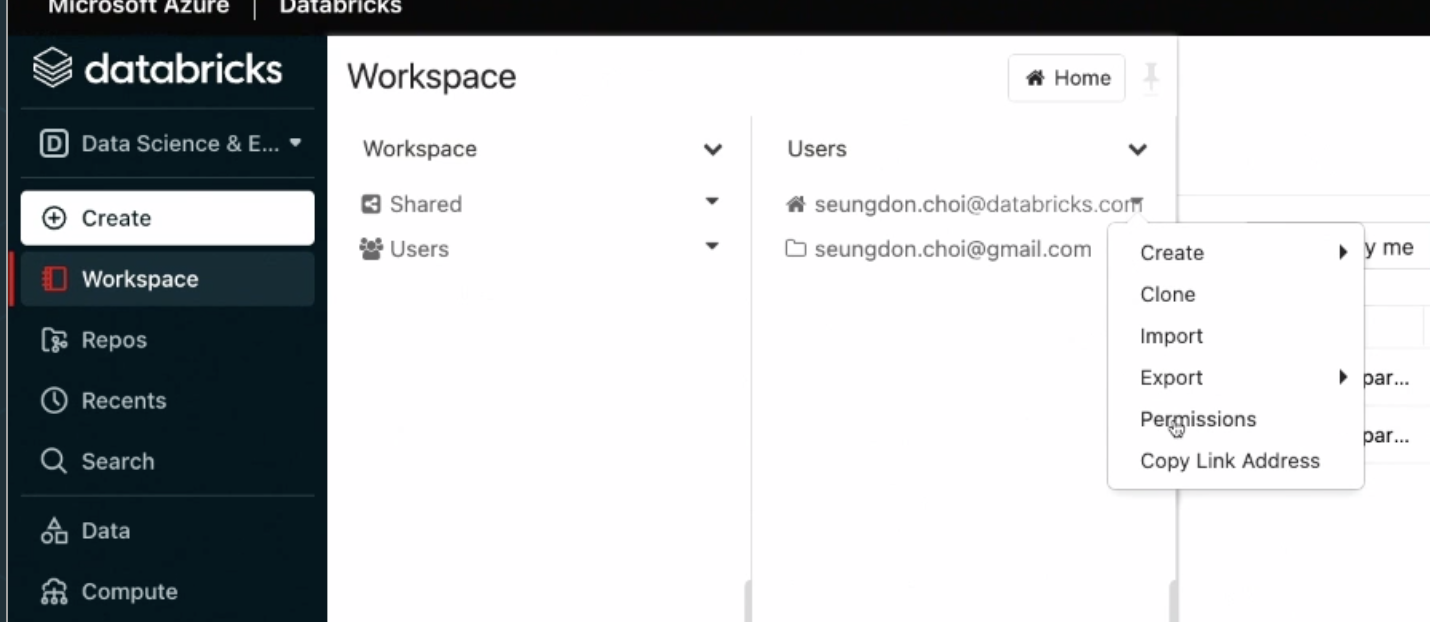
노트북 실습
-
데이터브릭스 만의 노트북 환경을 제공
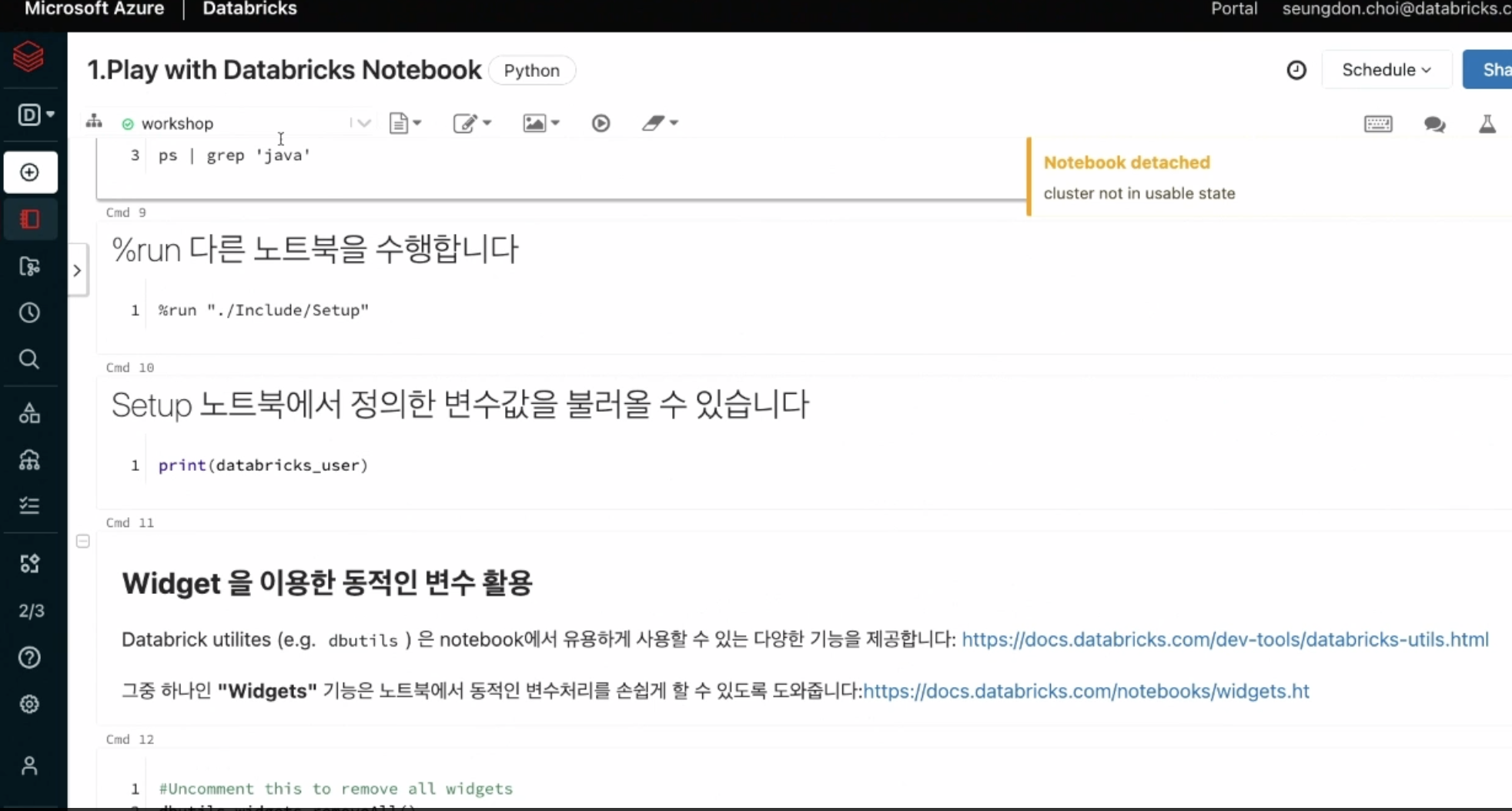
-
개발언어도 다양하게 제공 (파이썬,R, 스칼라, 쉘 등)
-
앞서 만들어둔 클러스터에 붙어서 실행됨.
-
위젯기능 제공
- dbutils 위젯을 만들 수 있음 -
DBFS를 활용해서 클라우드 object-storage.) S3, ADLS, Gen2, GCS) 등에 손쉽게 접근가능.
미니퀴즈

- 정답 B.
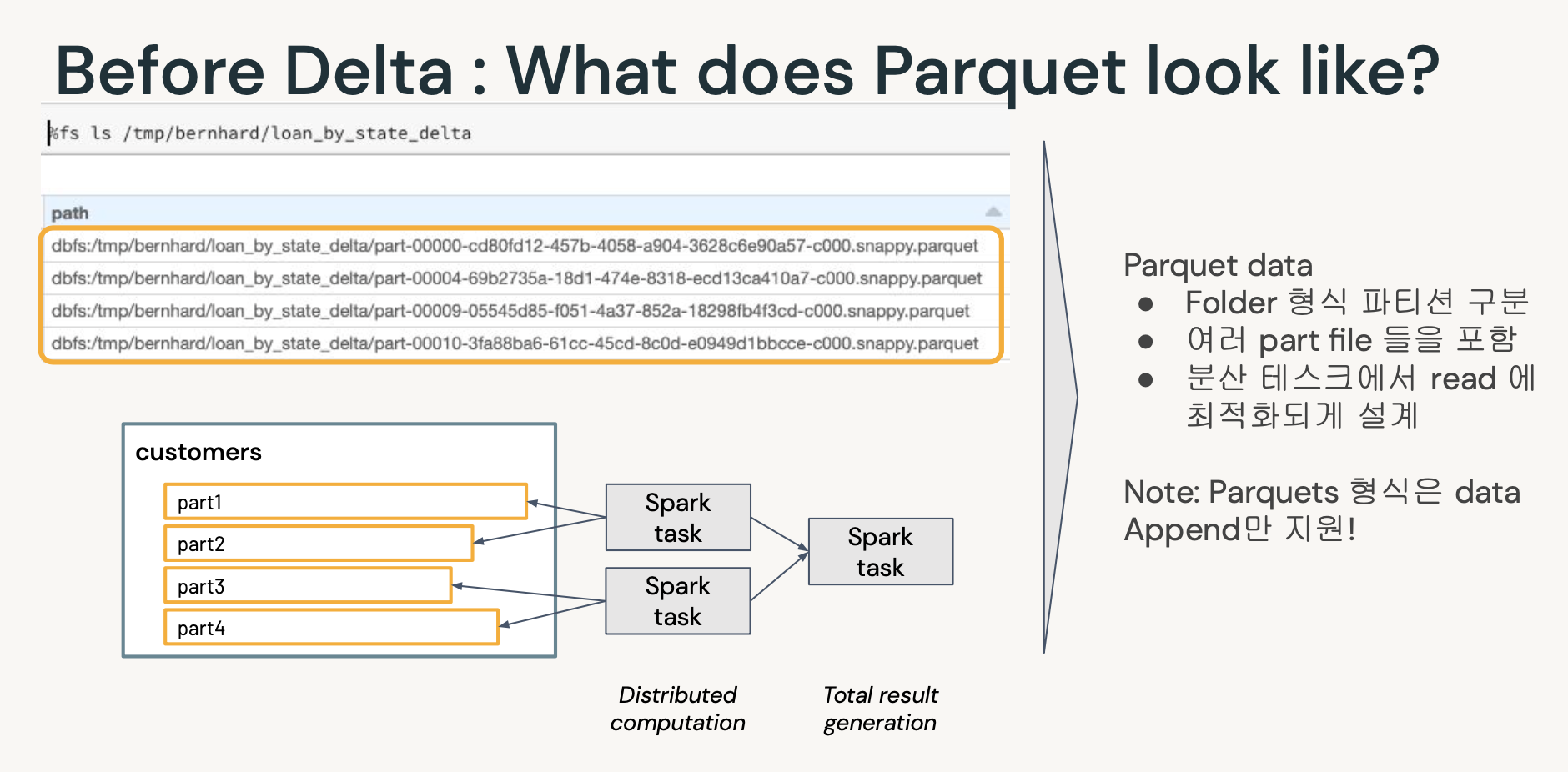
(챕터2)What is Delta Lake?

- Delta Lake 는 기존의 스토리지 시스템 위에 데이터 레이크 하우스를 구축할 수 있게 도와주는 오픈소스 프로젝트입니다.

$. ACID 지원으로 해결되는 많은 문제들
- 단일 테이블에 여러 트렌젝션이 동시 Write 힘듬
- 기존 데이터의 수정이 힘듬
- 중간에 실패한 Job - Corrupt Data
- 실시간 운영 힘듬(Batch중심)
- 과거데이터스냅샷유지비용증가
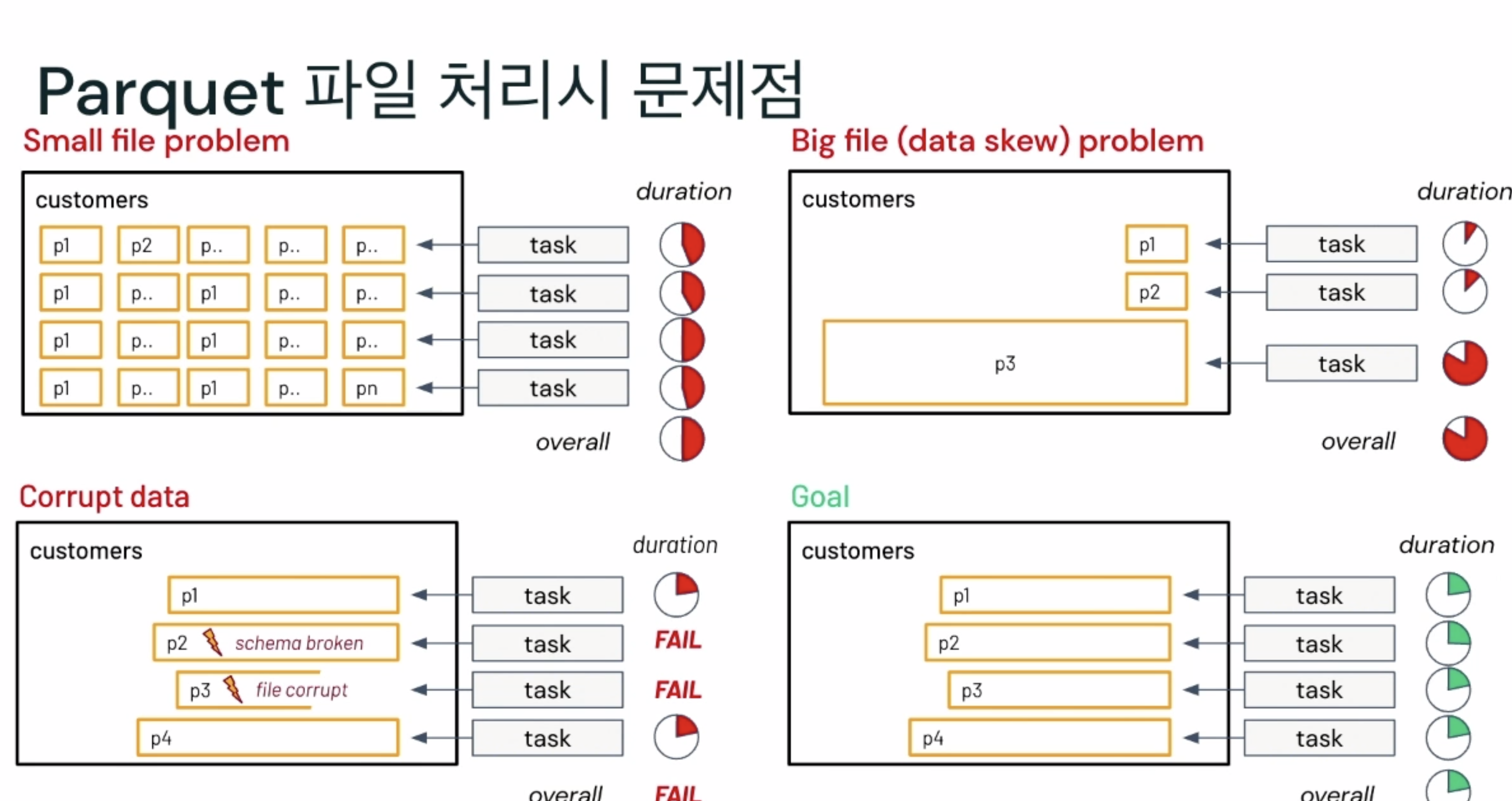
- 너무 쪼개져서 오래걸리는
- 한쪽에 쏠림
- 배치가 깨지거나.
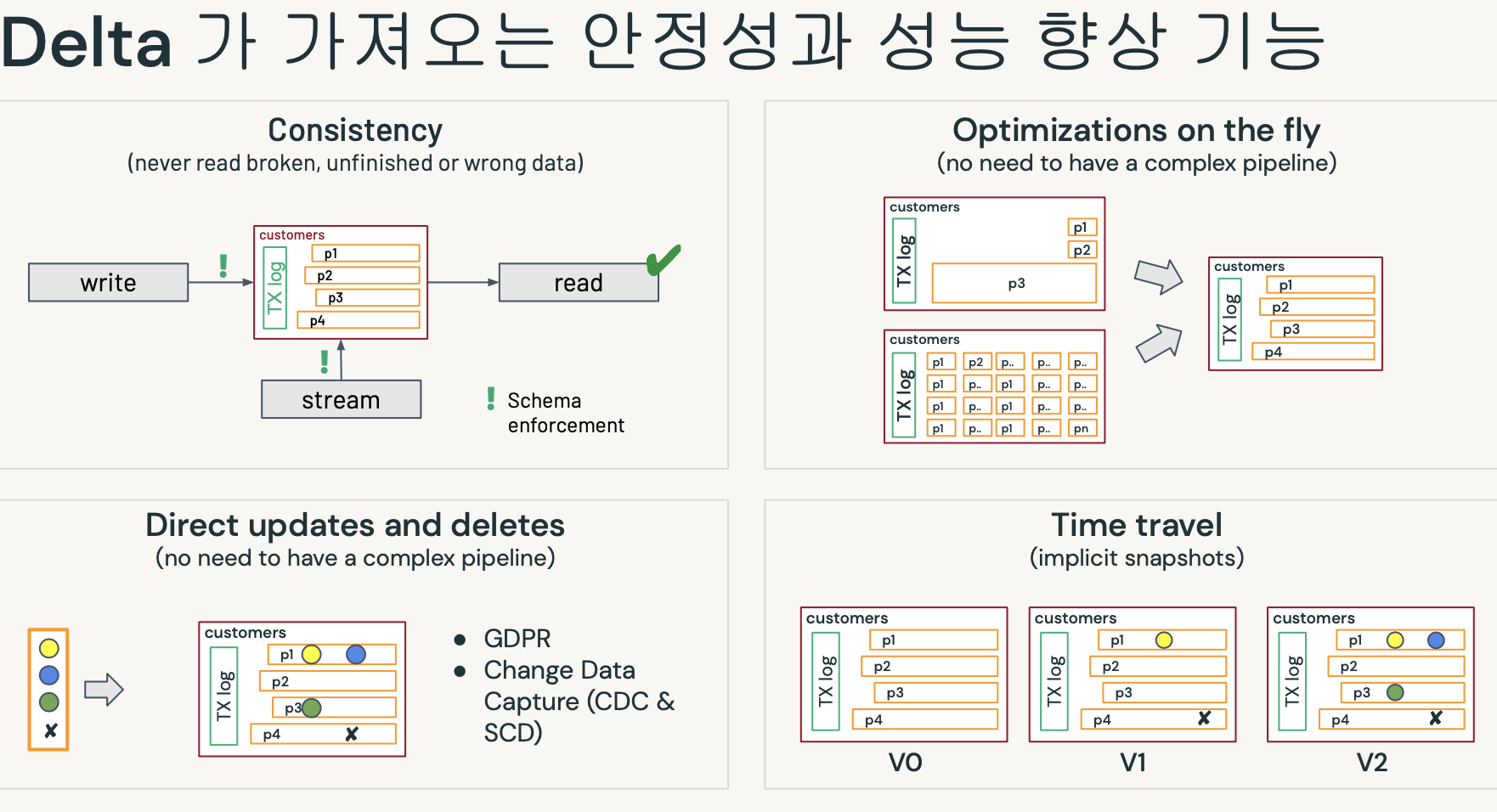
- 깨진 파일을 읽지 않음.
- 복잡한 파이프라인이 필요없음.
- 업데이트&삭제 모두 델타로 처리가능.
- 버전정보를 모두 갖고 있음.(롤백이 가능하다)
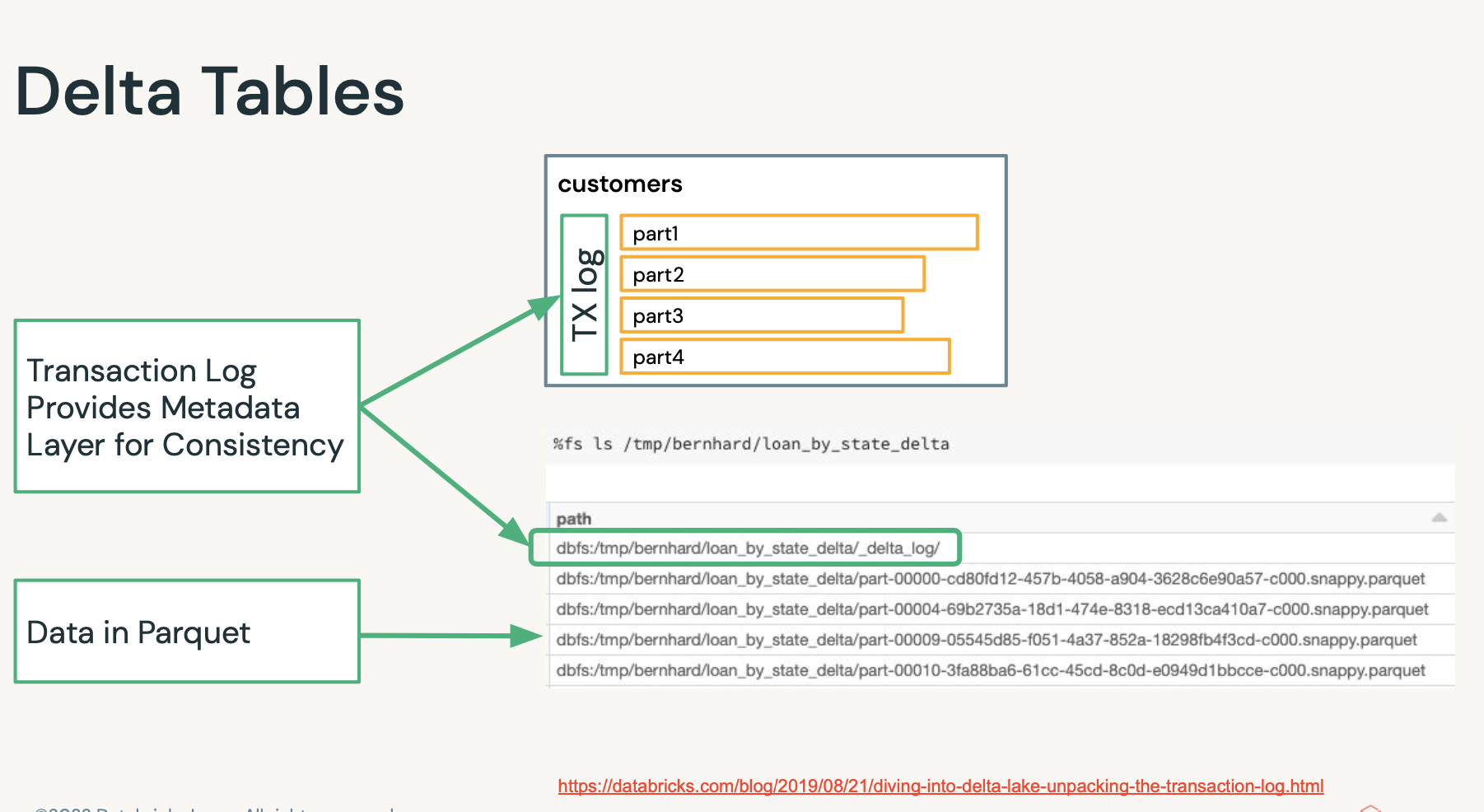
- 데이터자체는 파퀘이로 있다.
- 히든데이터로 메타정보를 갖고 있음.
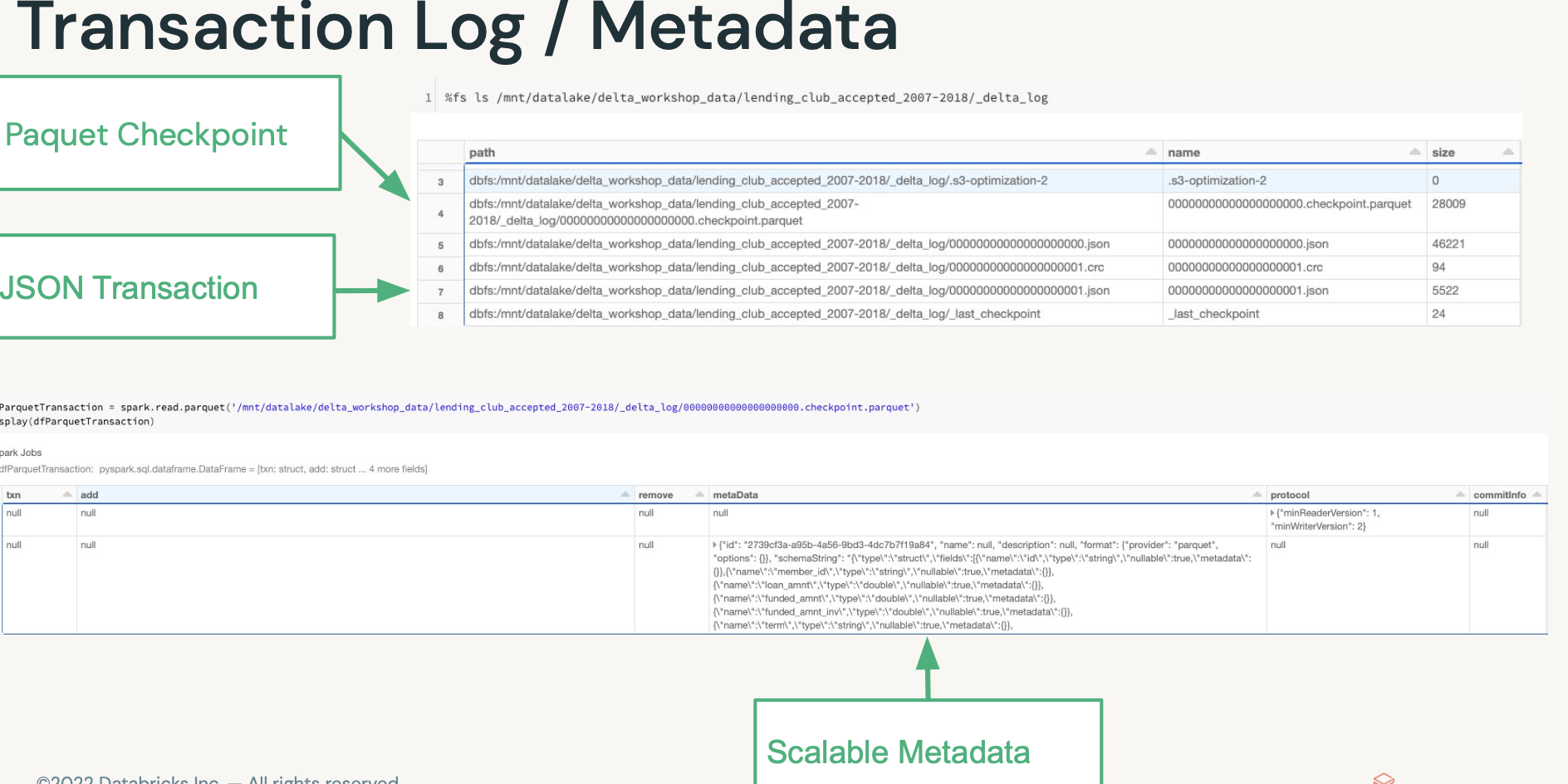
- 메타데이터가 너무 많으면, 관리포인트가 많고 성능저하 되지 않을까? -> 저런 델타로그도
모두 스파크로 처리되어서 빠르다.
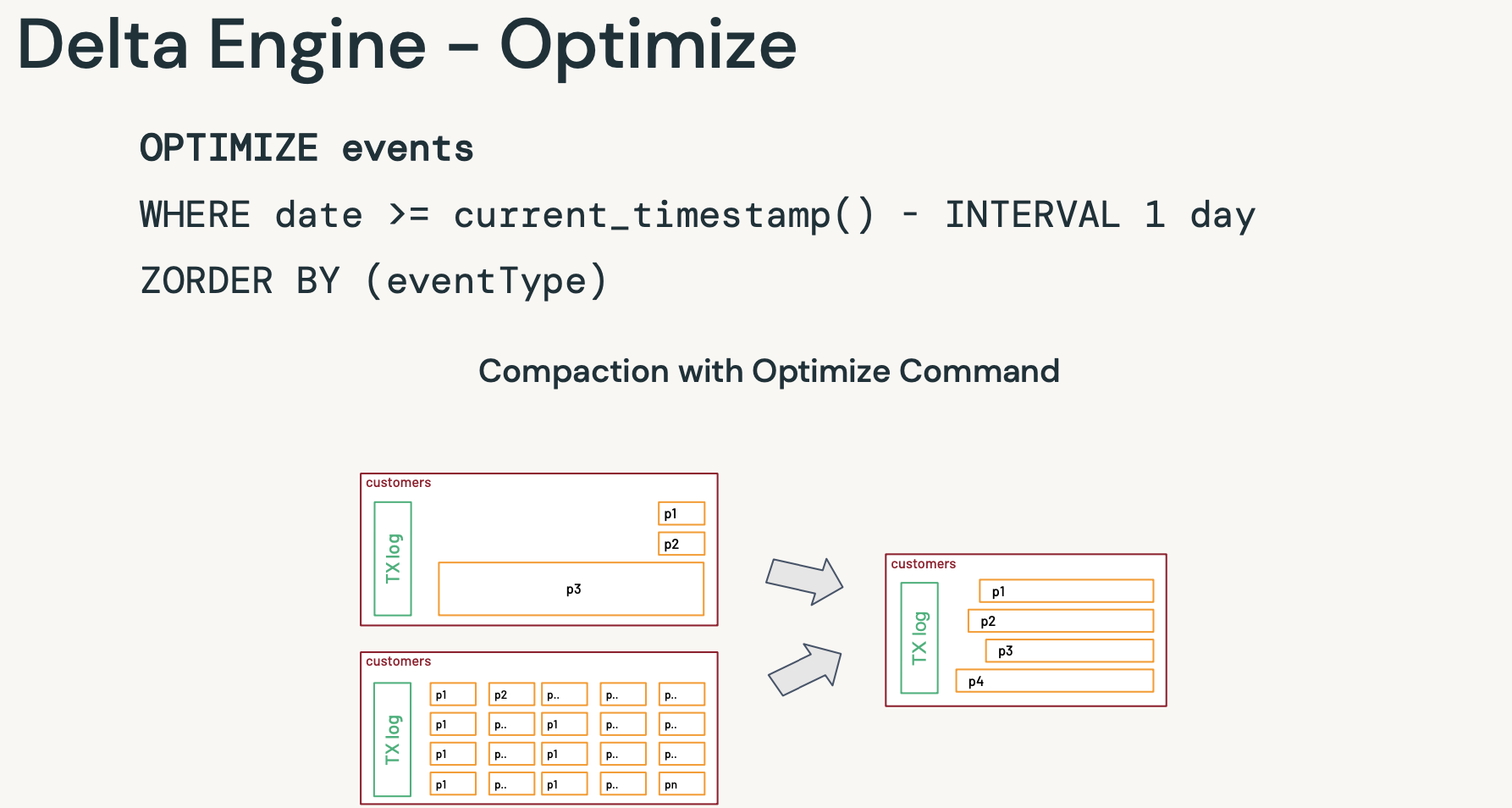
- 옵티마이즈(델타 엔진)
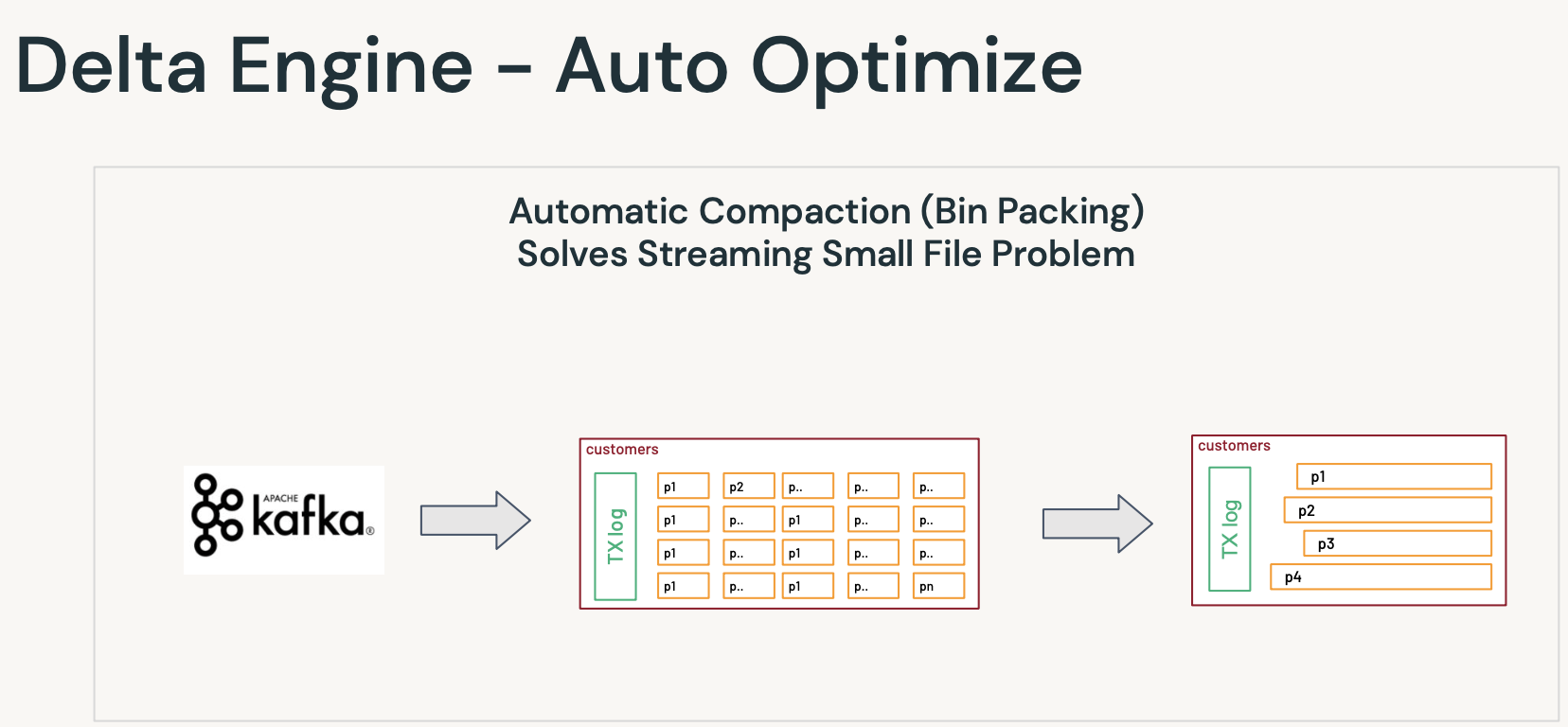
- 오토 옵티마이즈
- 빈패킹을 통해 자동으로 처리

- 필요한 데이터만 읽어옴.

- 그 외 기능.
- 캐싱.
- s3에서 읽어오는 것 보다 훨씬 더 빠르게.- 블룸필터.
- 등등등
- 요약하면 이렇다.
데모 2. Play with Delta
미니퀴즈

- 답 3번.
(챕터3)데이터엔지니어

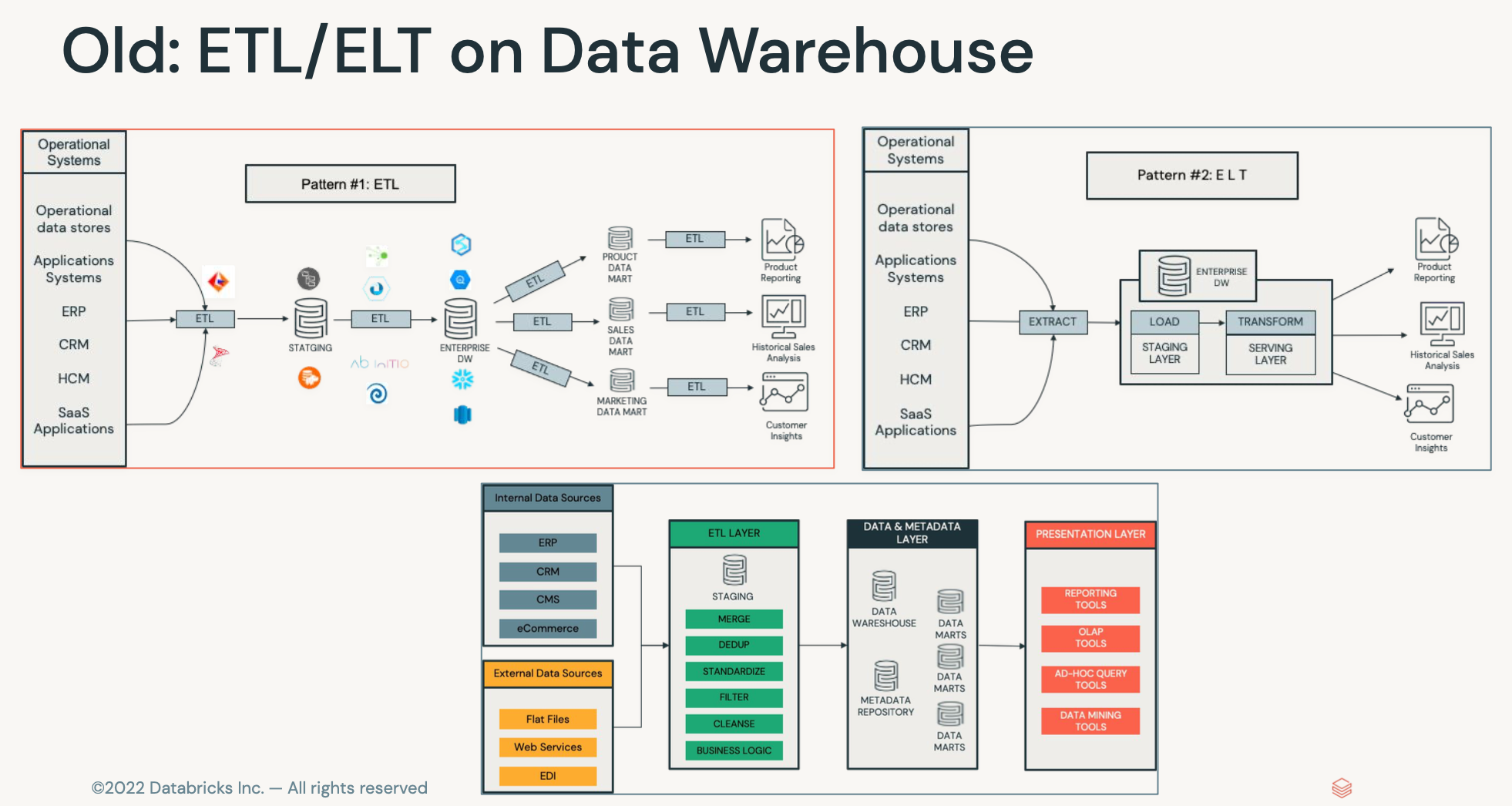
- 전통적인 웨어하우스
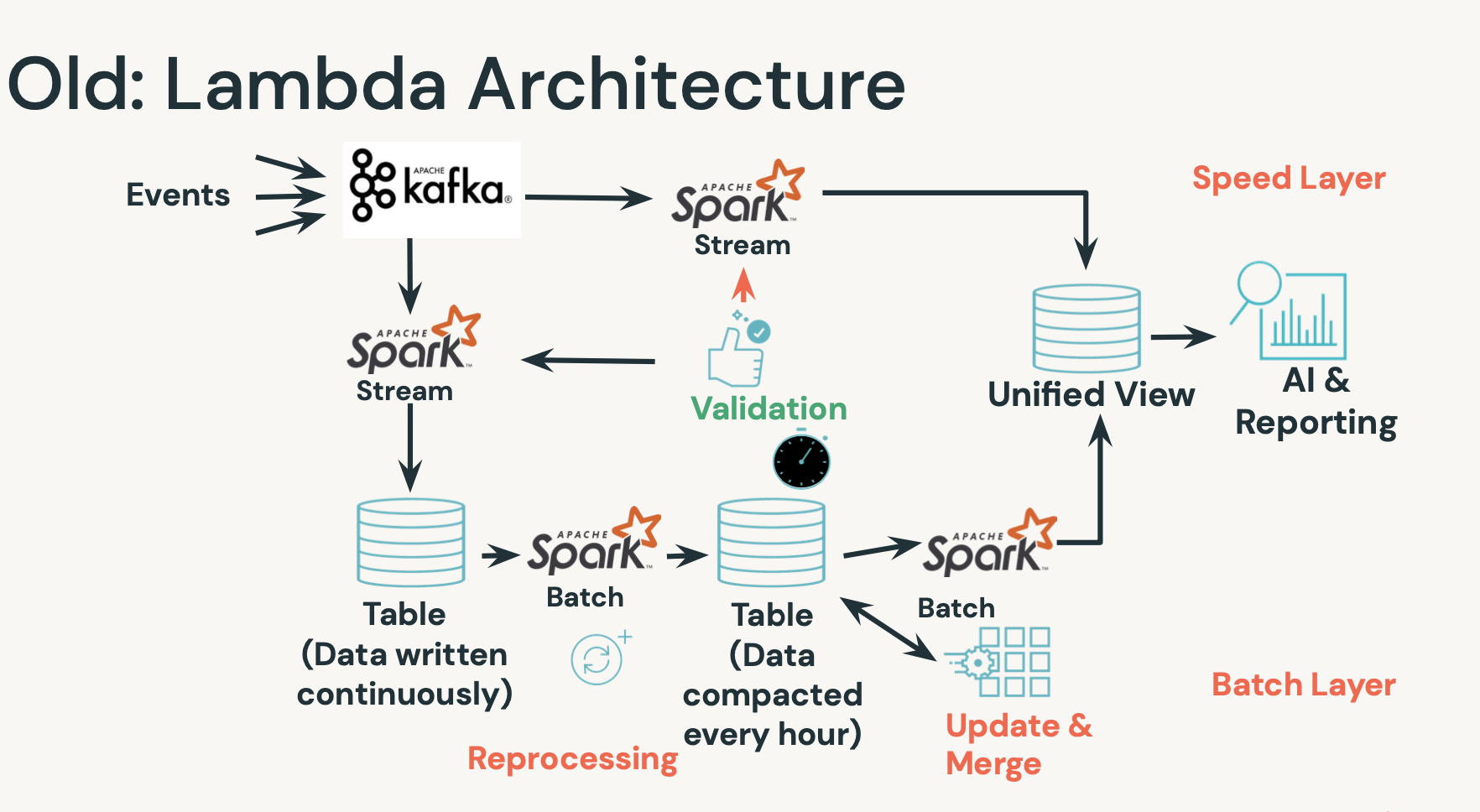
- 스피드 레이어를 따로 둬서, 지속적으로 계속 업데이트를 해야함.
- 배치레이어 별로도 만들어서
- 한군데에서 모으는 업데이트&머지 하는 작업.
- 리프로세싱.
그러다보니 중간에 깨지거나 문제가 생기면 다시 작업. 복잡도가 많았음.
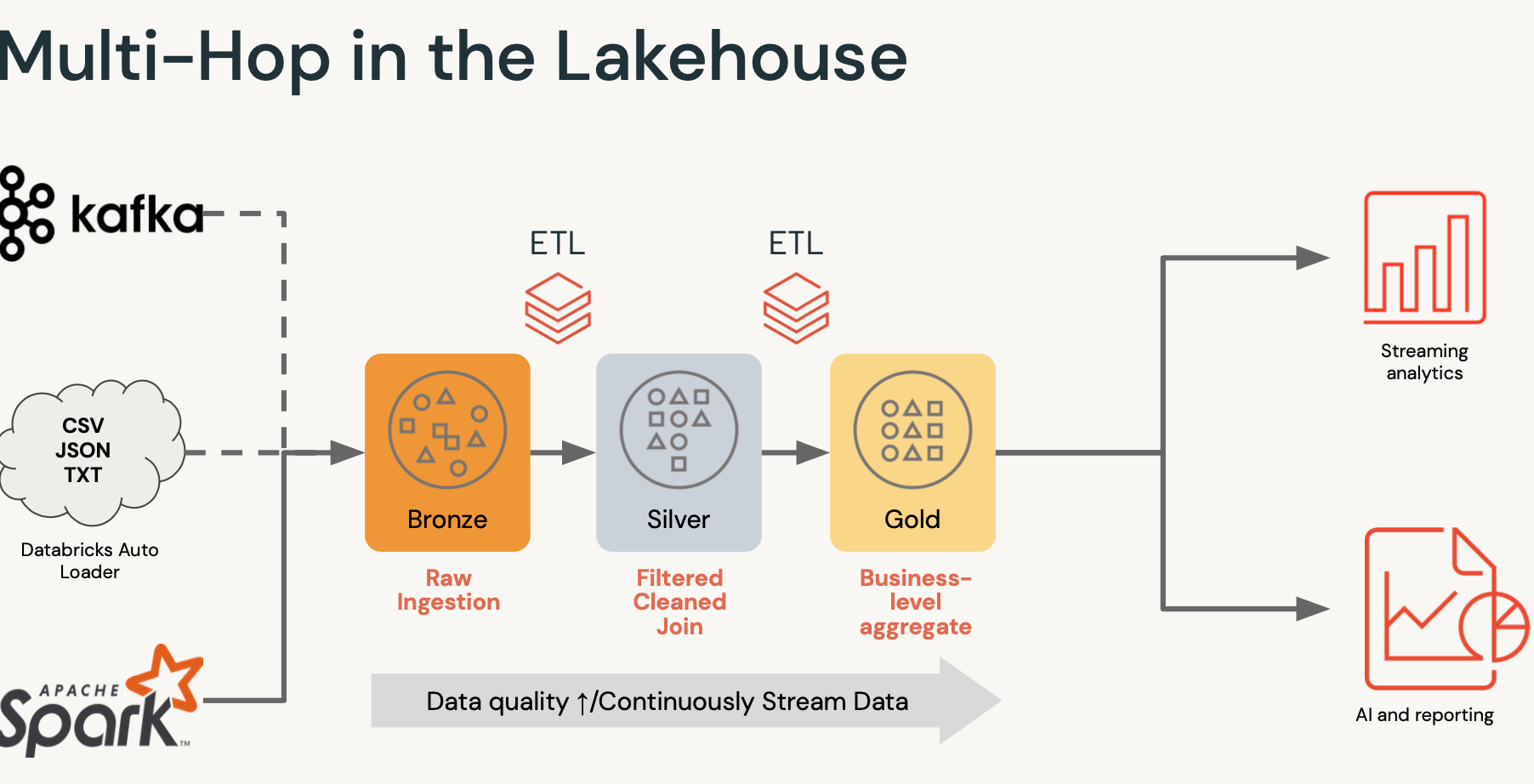
- 브론즈,실버,골드 : 단순하게 단계stage라고 생각하면 됨
- 브론즈 : 로우데이터를 불러옴.
- 실버 : 클랜징하거나 조인하는 작업.
- 골드 : 목적별로 데이터를 집계.
골드로 갈수록 데이터 품질이 점점 나아짐.
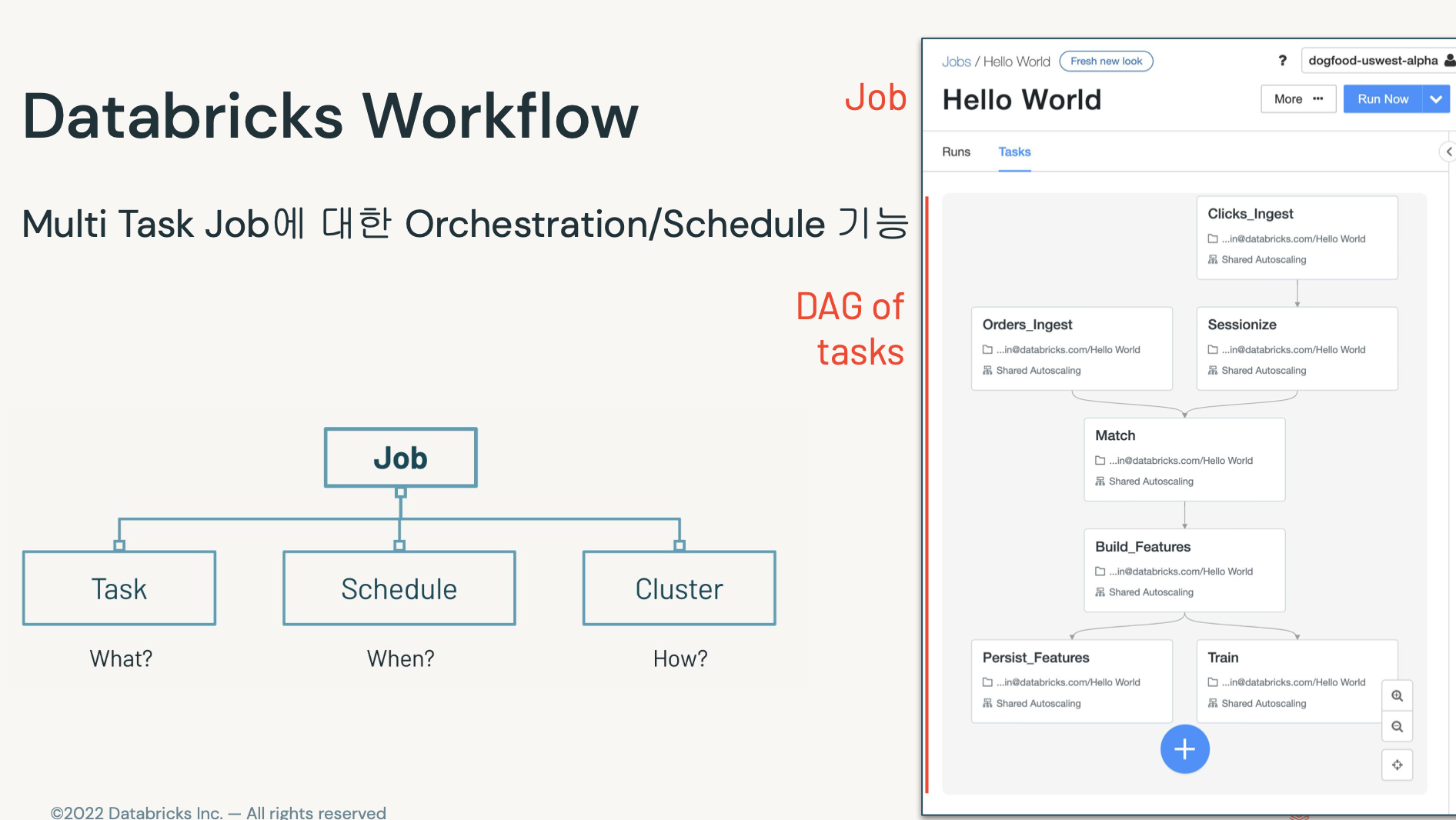
- 오케스트레이션 엔진. (에어플로우 같은거)
- 잡에 태스크, 스케쥴 를 데이터브릭스에서 설정가능.
- 기존에 에어플로우 쓰고 있다며 그거 써도 됨 ㅇㅇ
데모 Databricks Workflow / 3. Incremental Multihop datapipeline
-
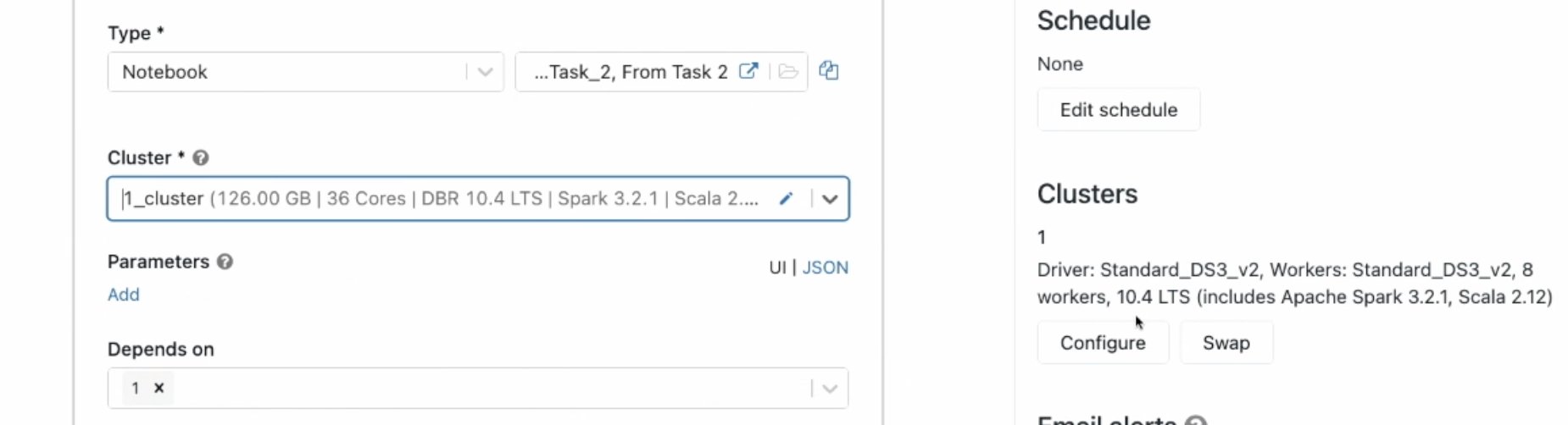
새로운 잡클러스터를 사용. 워크스페이스를 쓰면 비쌈. 필요할때만 쓰는걸로..
-
큰 작업이면 큰 자원으로 설정.
-
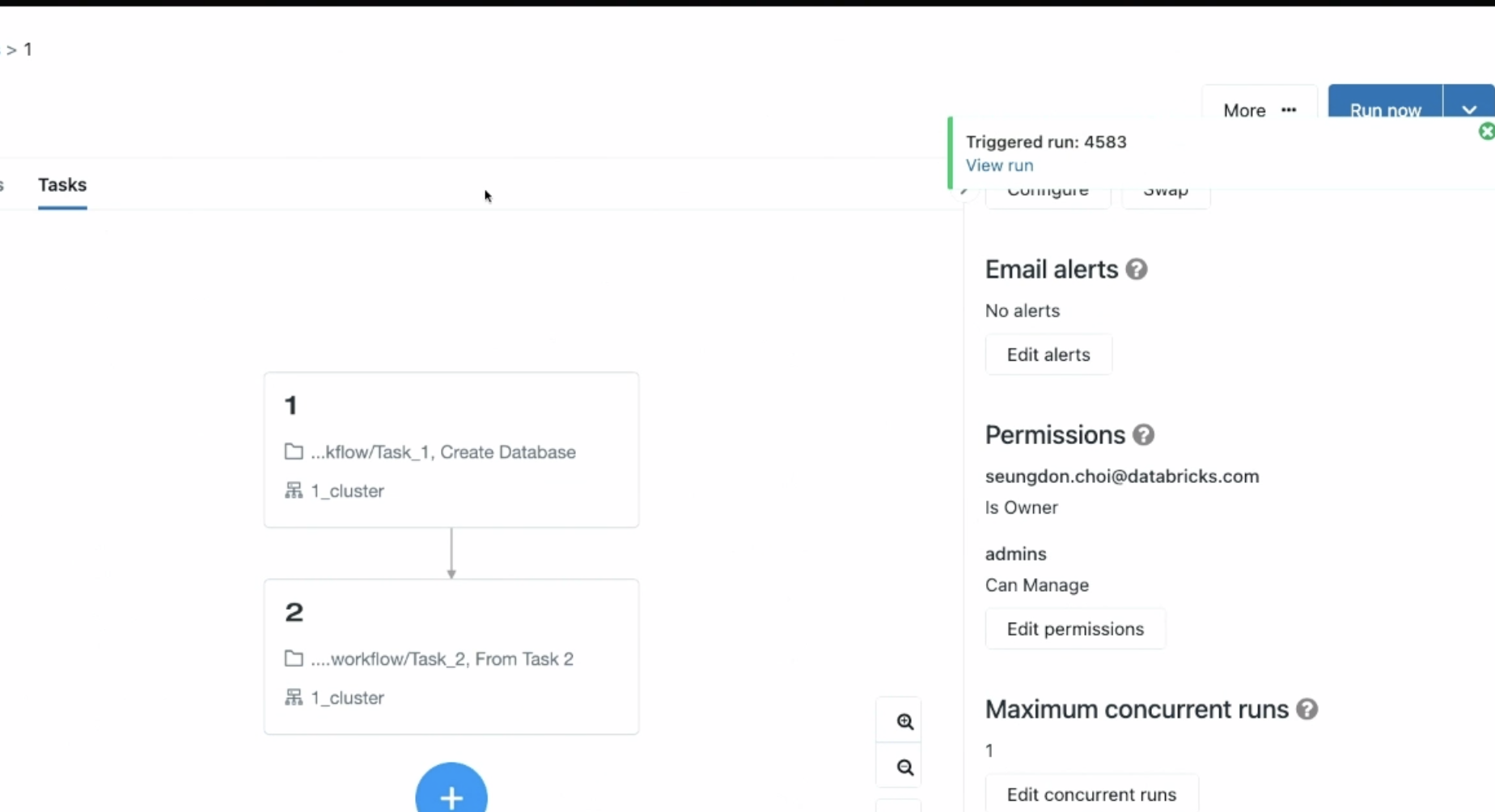
잡을 실행.
-
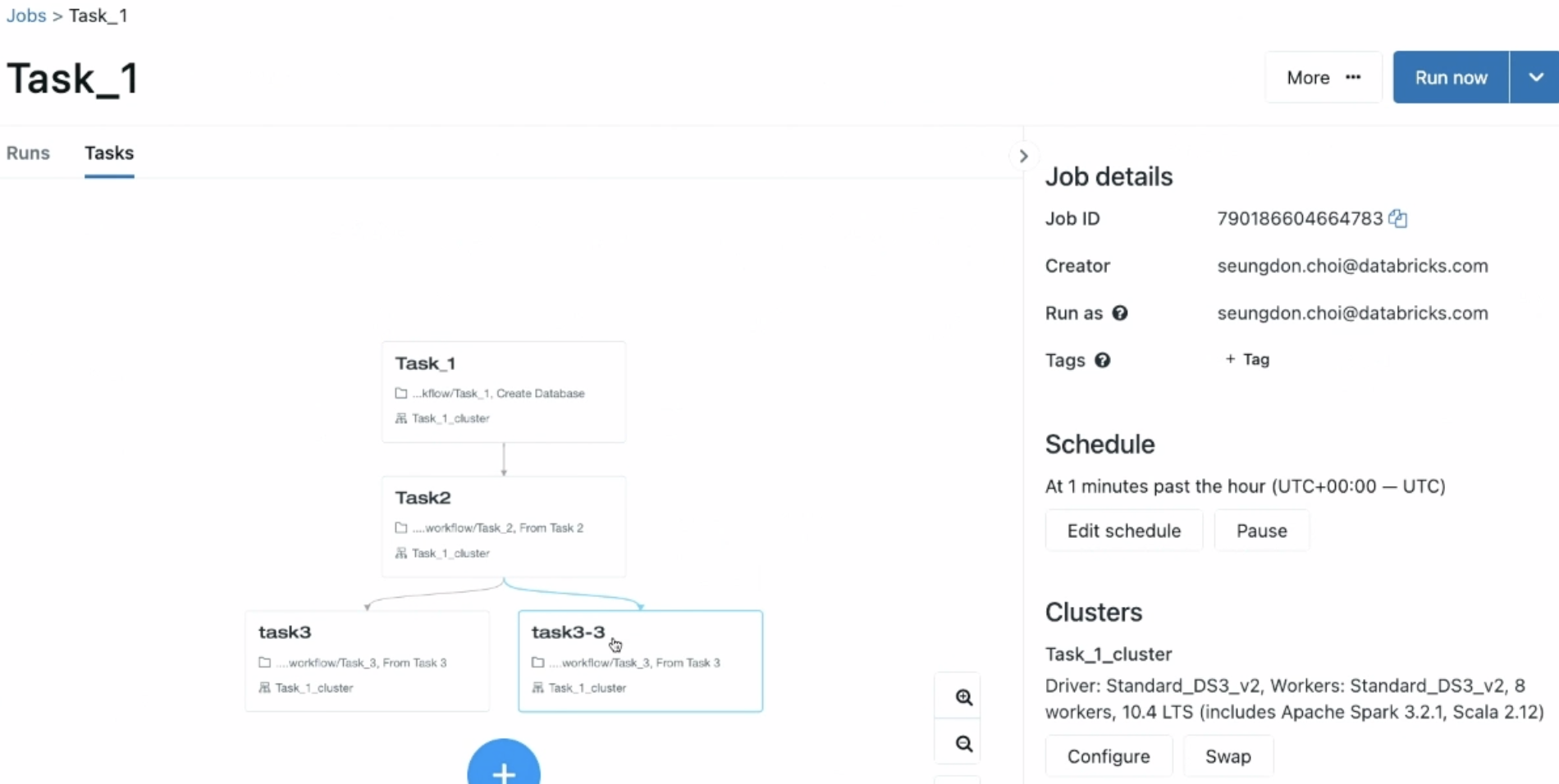
예시
-
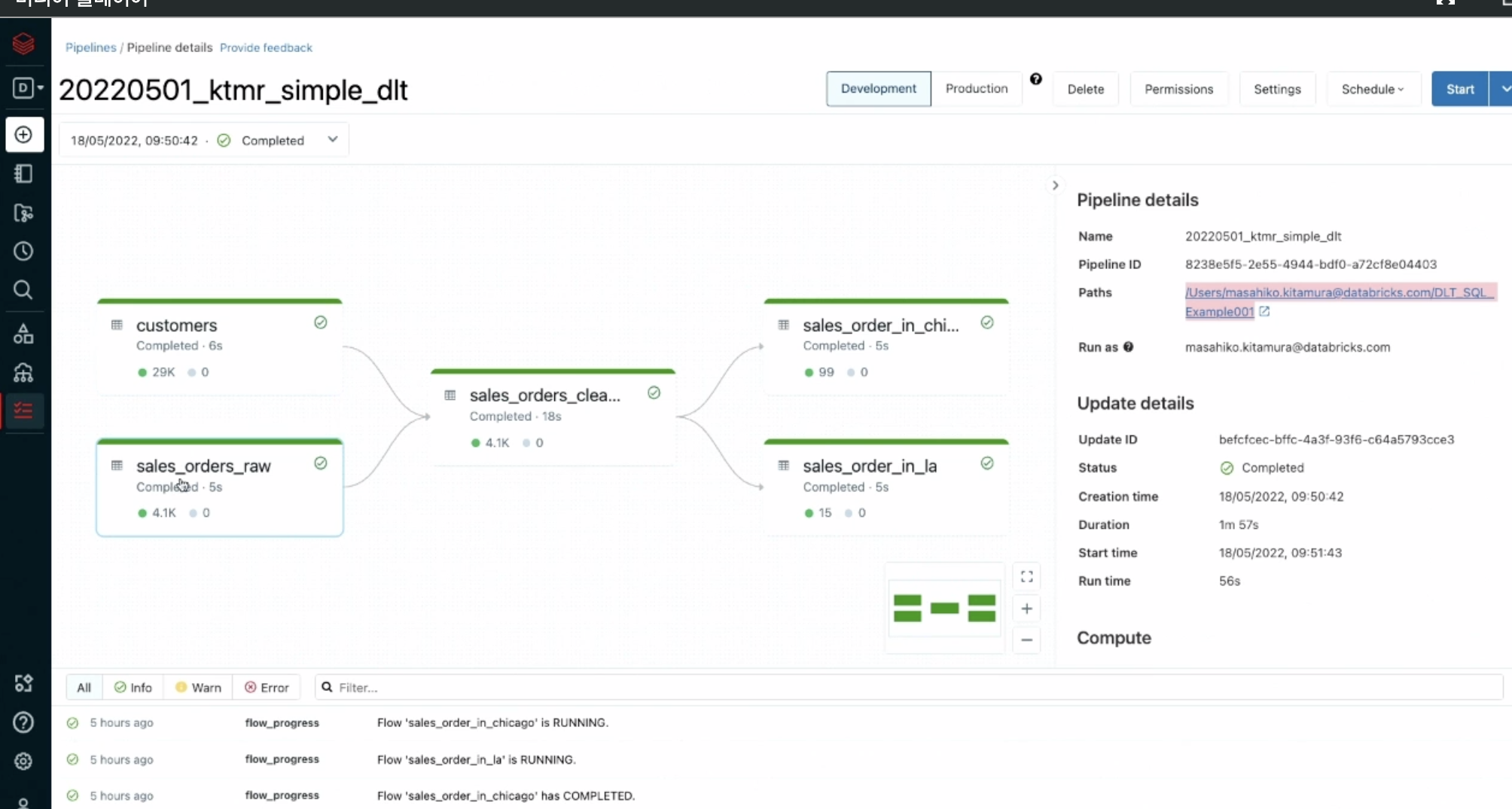
에러가 나면 한눈에 볼 수 있고, 얼마나 걸리는지 확인.
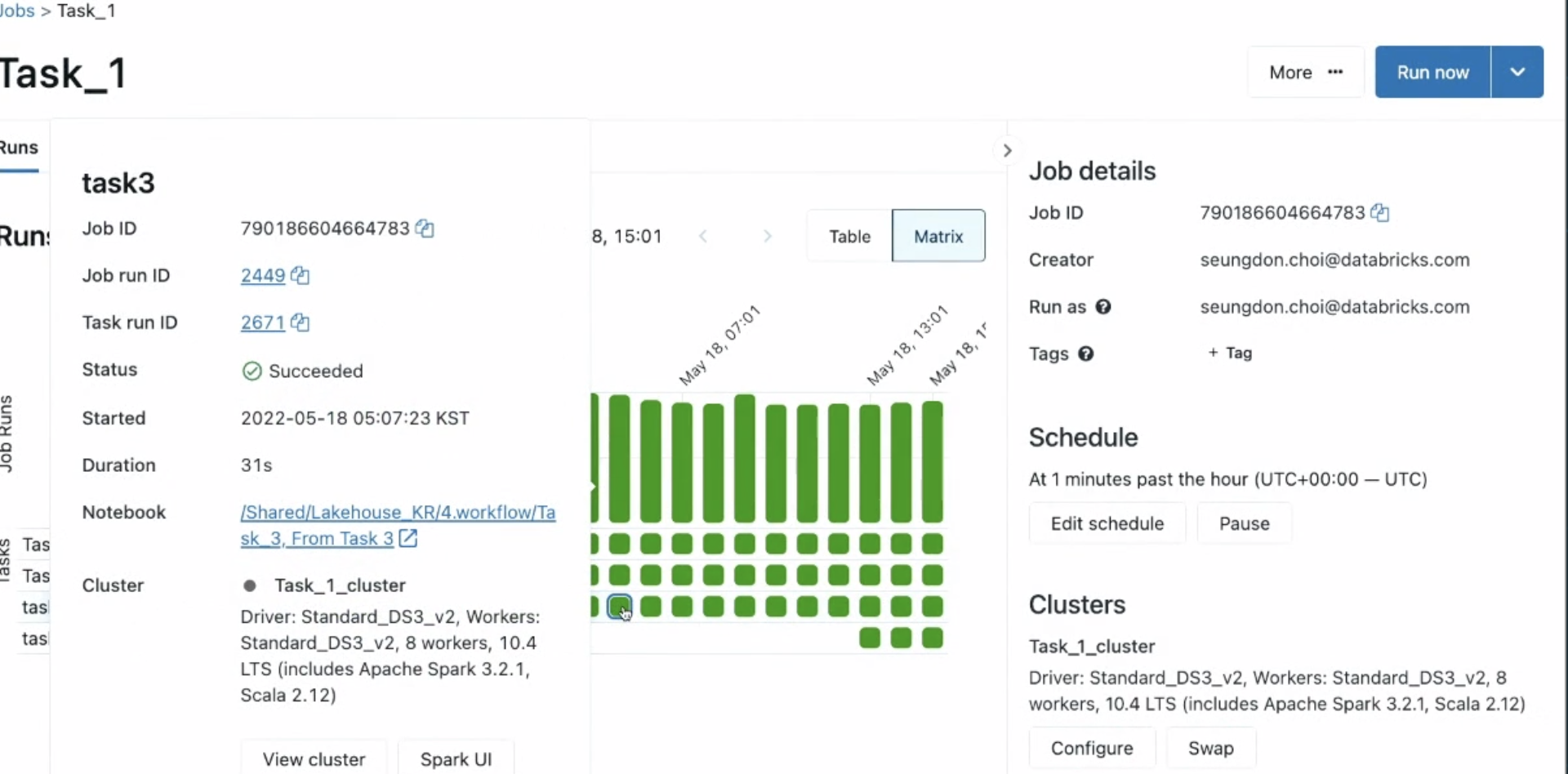

- 최근에 나온 따끈따끈한 기능
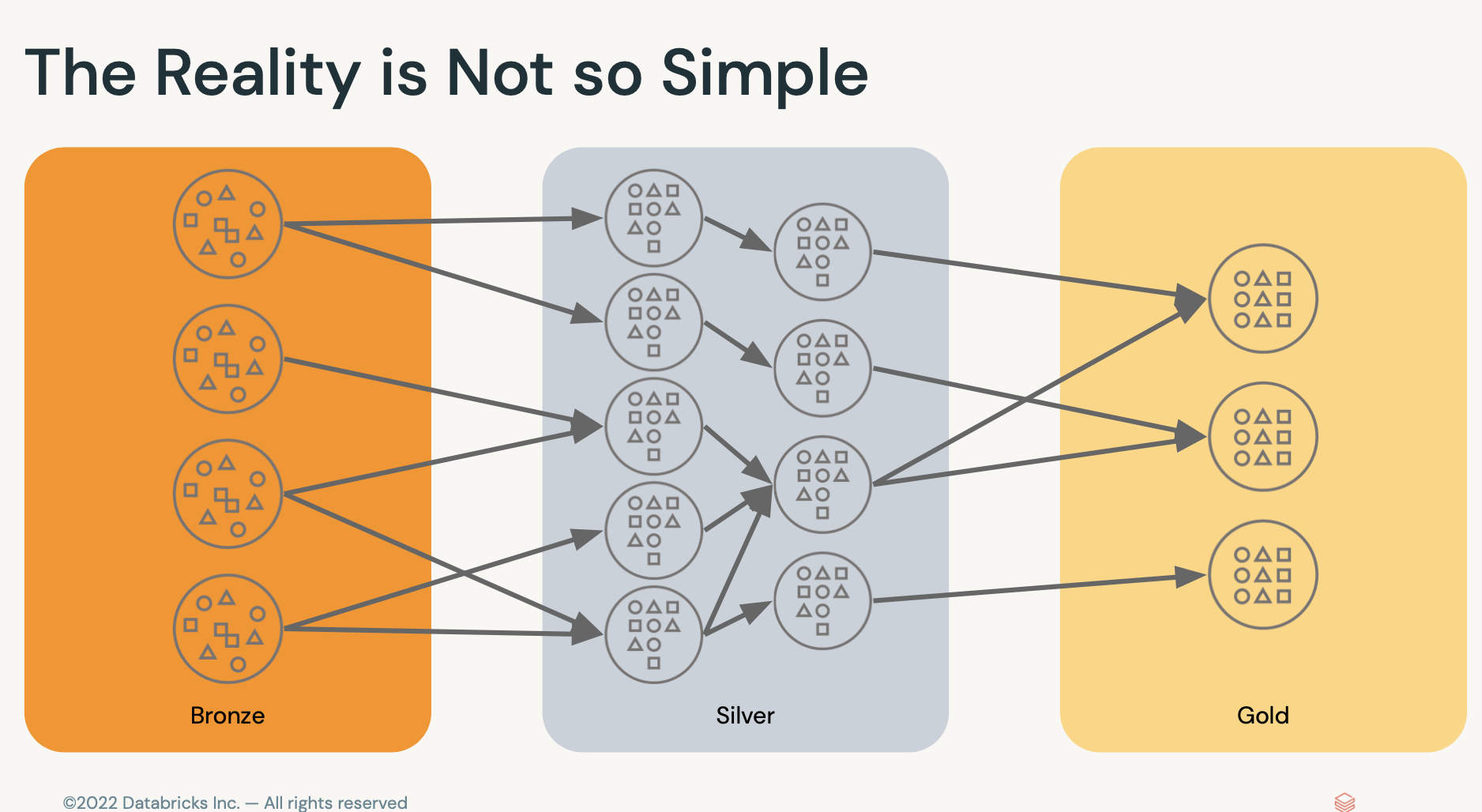
- 실제 현업에서는 관리하기가 쉽지 않다.
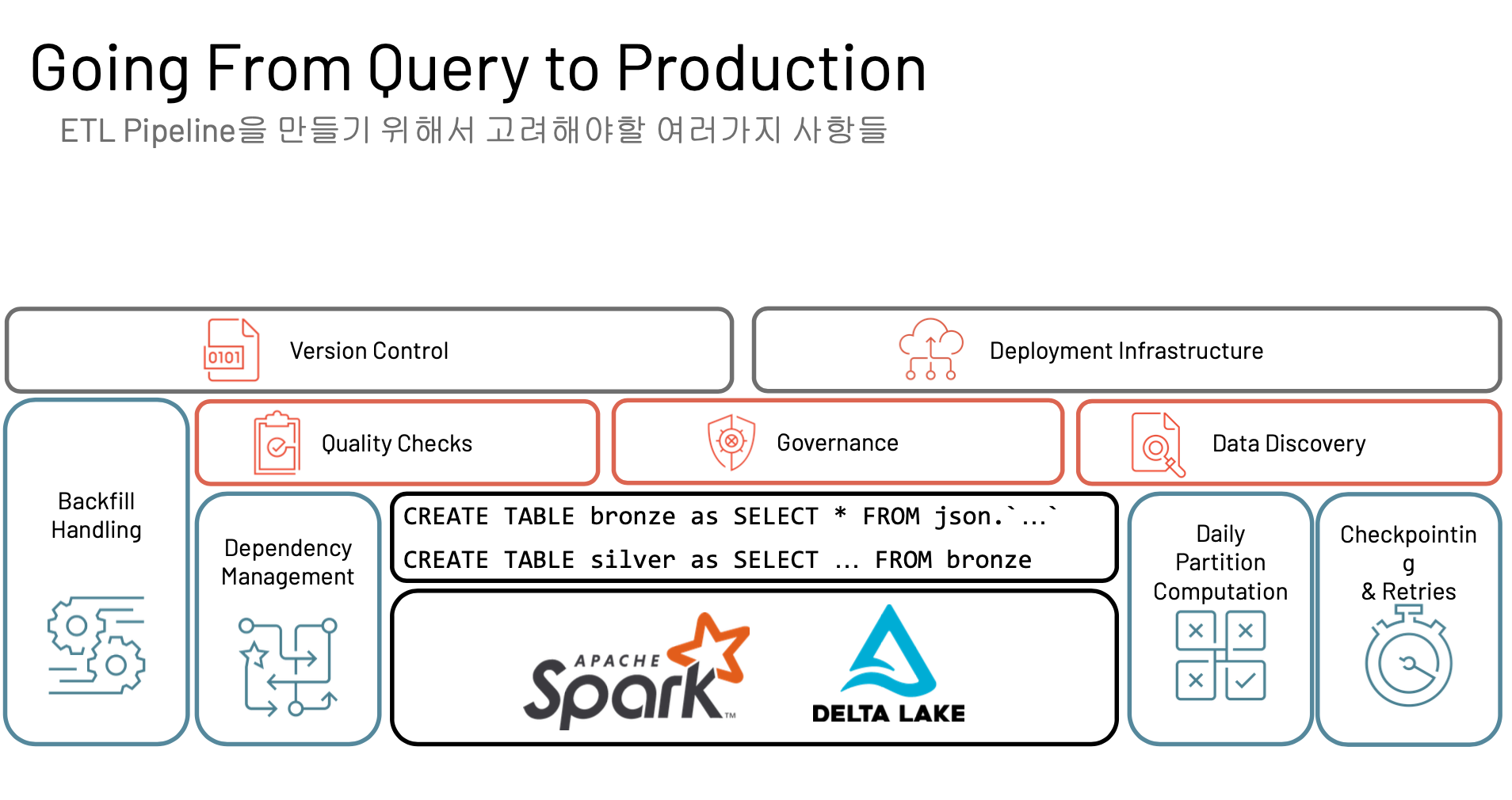
- 데이터의 리니지, 체크포인트
- 퀄리티체크
- 버전컨트롤
- 클러스터 자원관리
..
추상적으로 만든 기능. 델타라이브테이블이 알아서 해줌.

- 오토스케일링도 해줌.
https://github.com/databricks/delta-live -tables-notebooks (접근안됌)
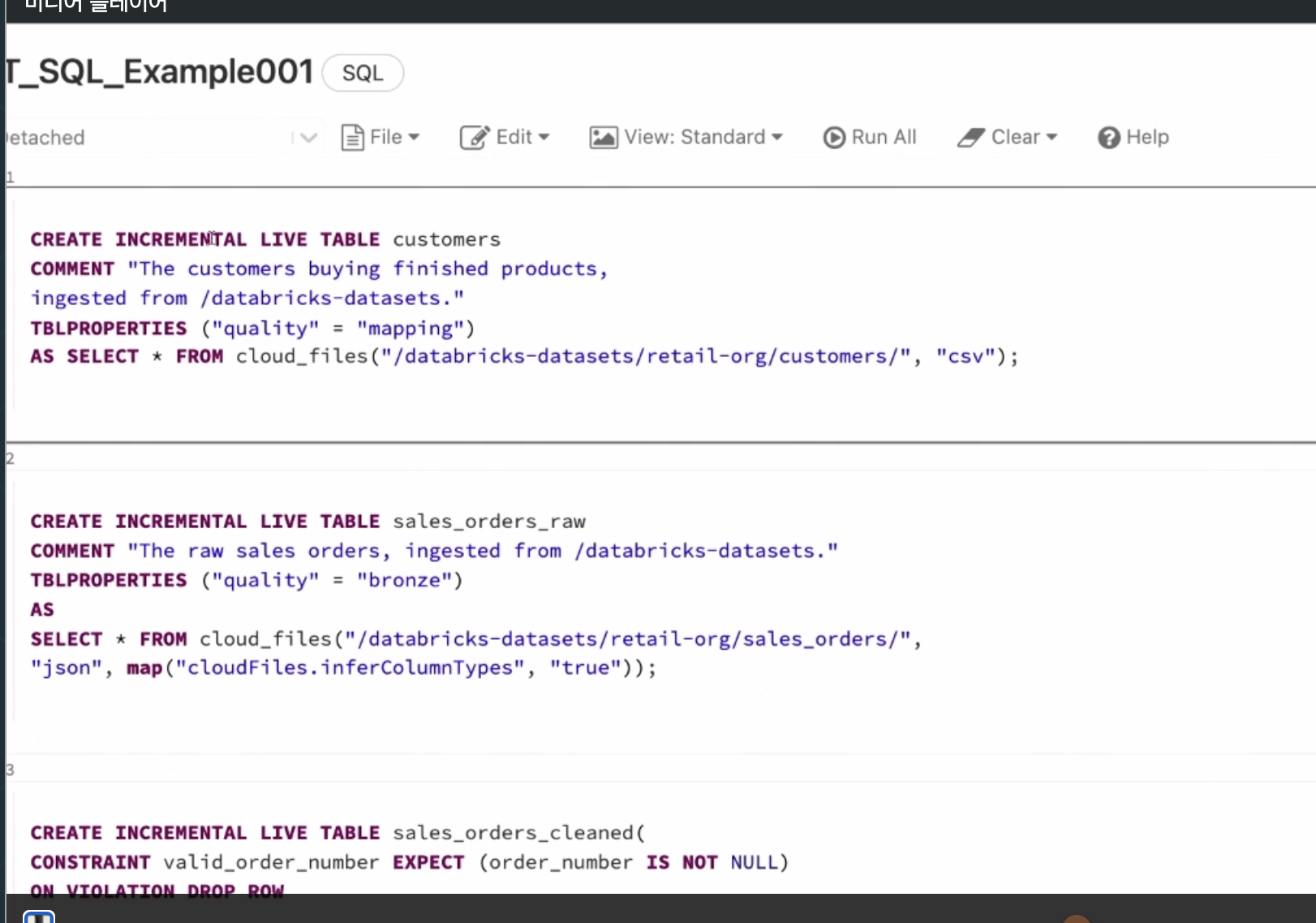
- 파이프라인 옵션에서 확인가능.
- 델타라이브 테이블은 다음과 같음. (영상에서 91:00)

(챕터4) 데이터브릭스 SQL

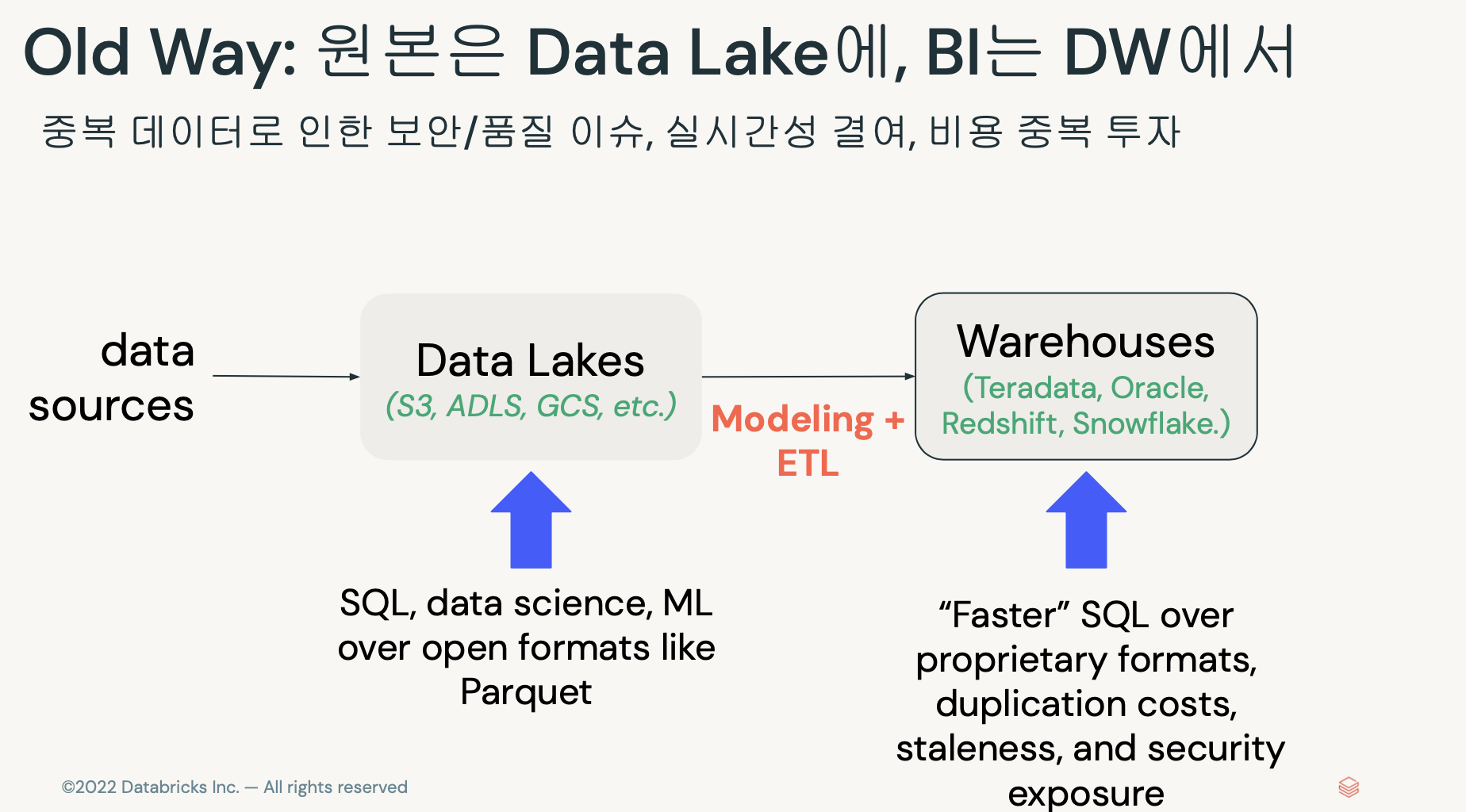
- 데이터레이크와 웨어하우스에 모두 들어가는 중복이슈.

- 여기서 두개의 장점을 합친.
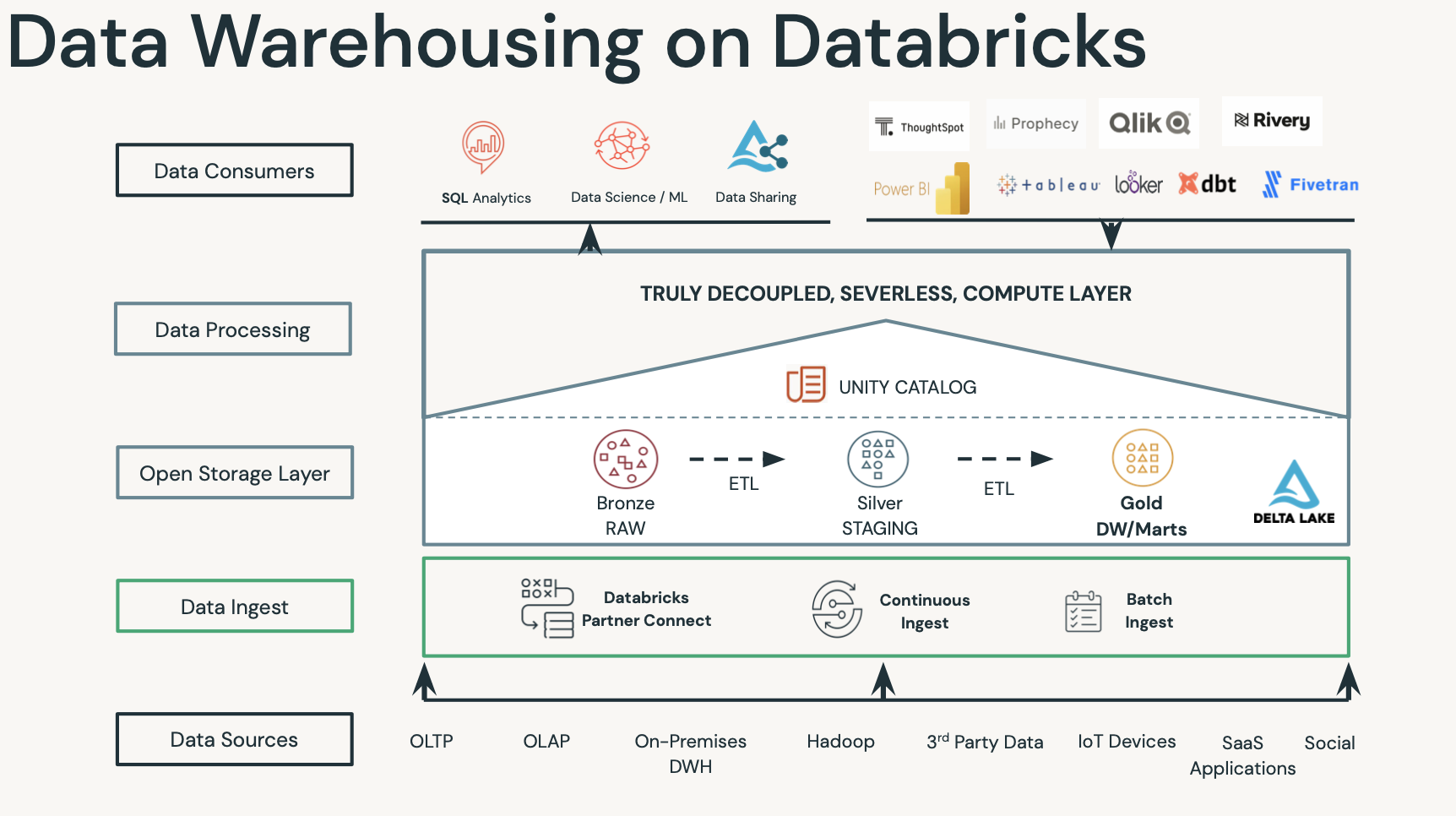
- 데이터브릭스 생태계.

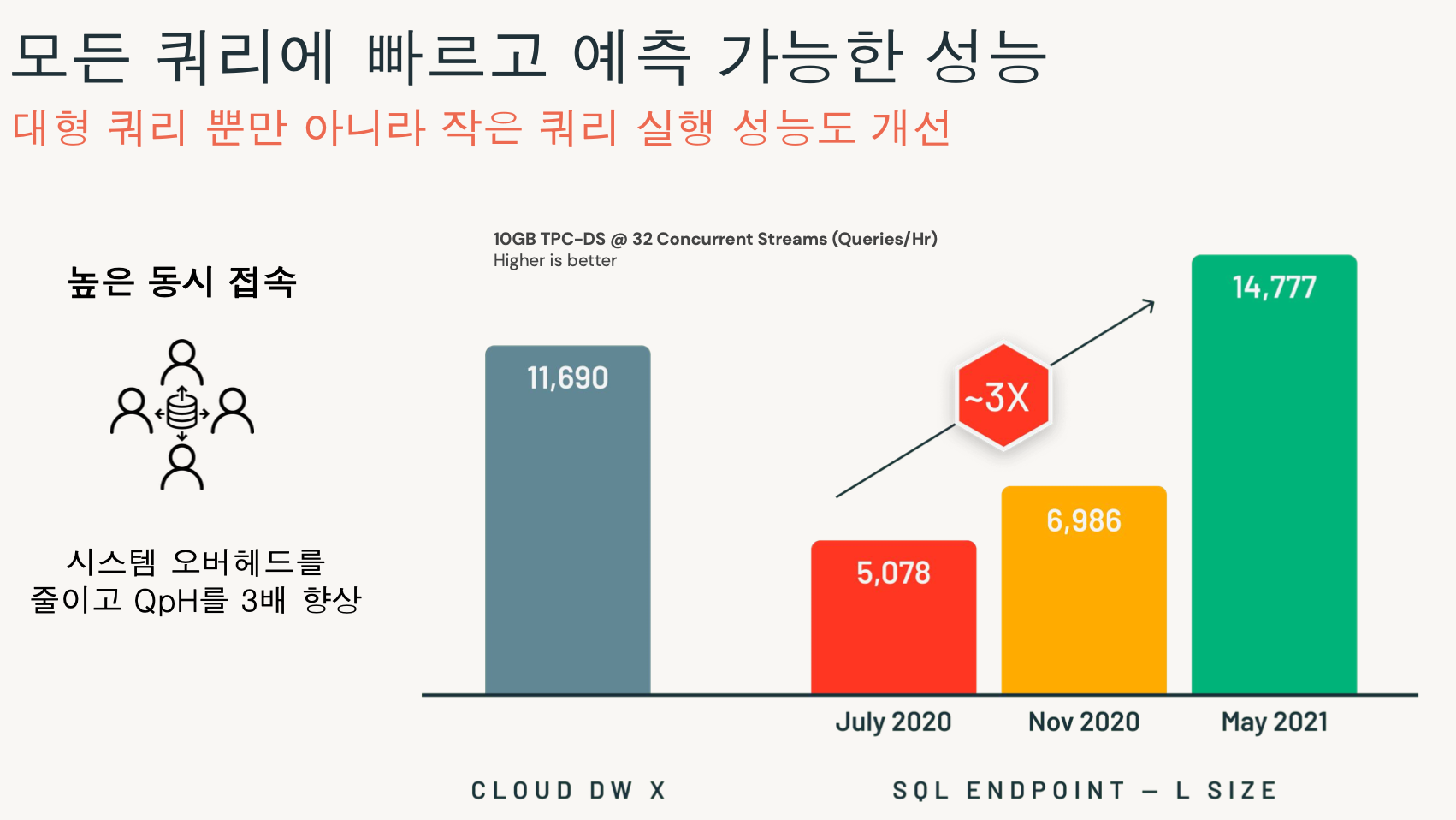
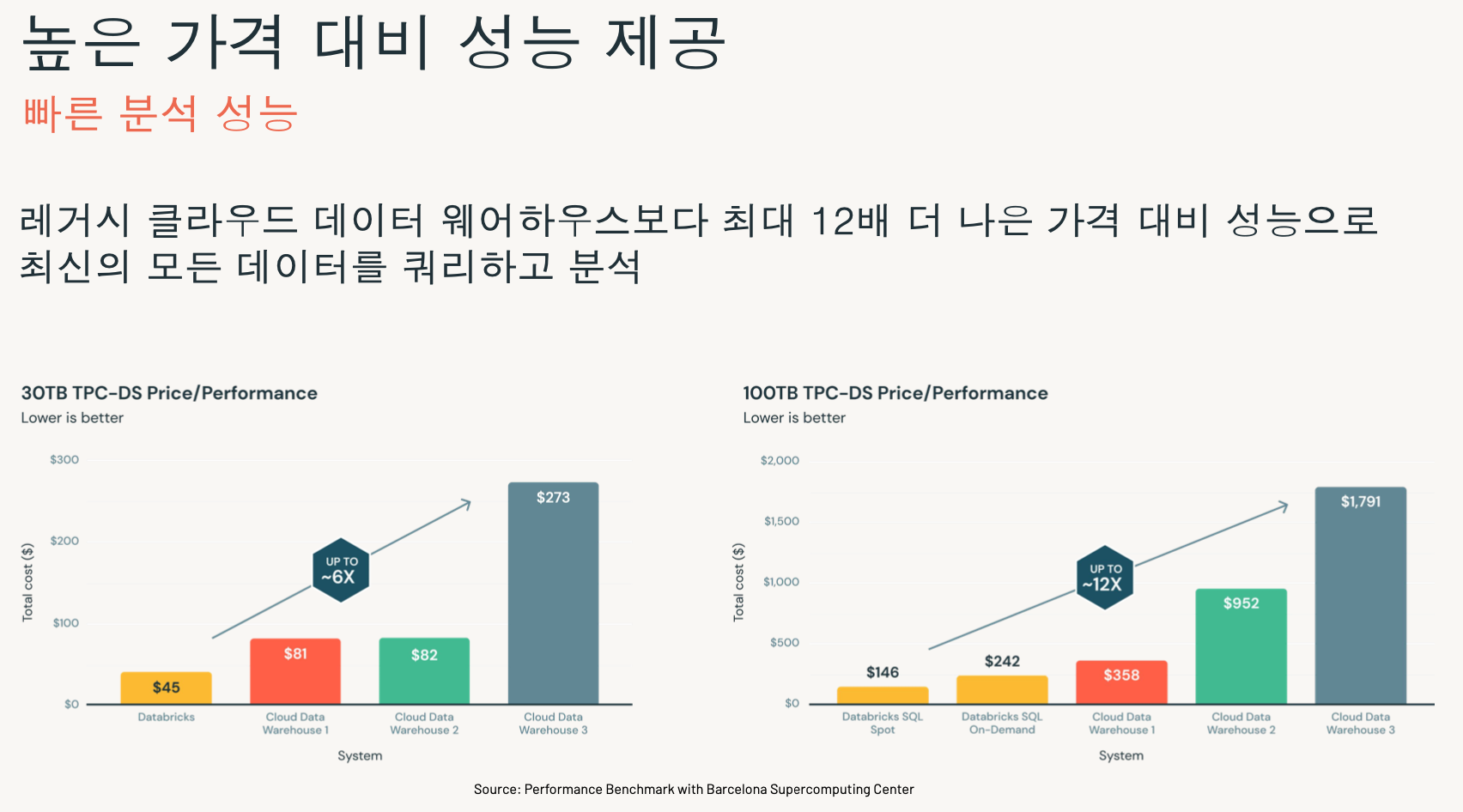


- 데모
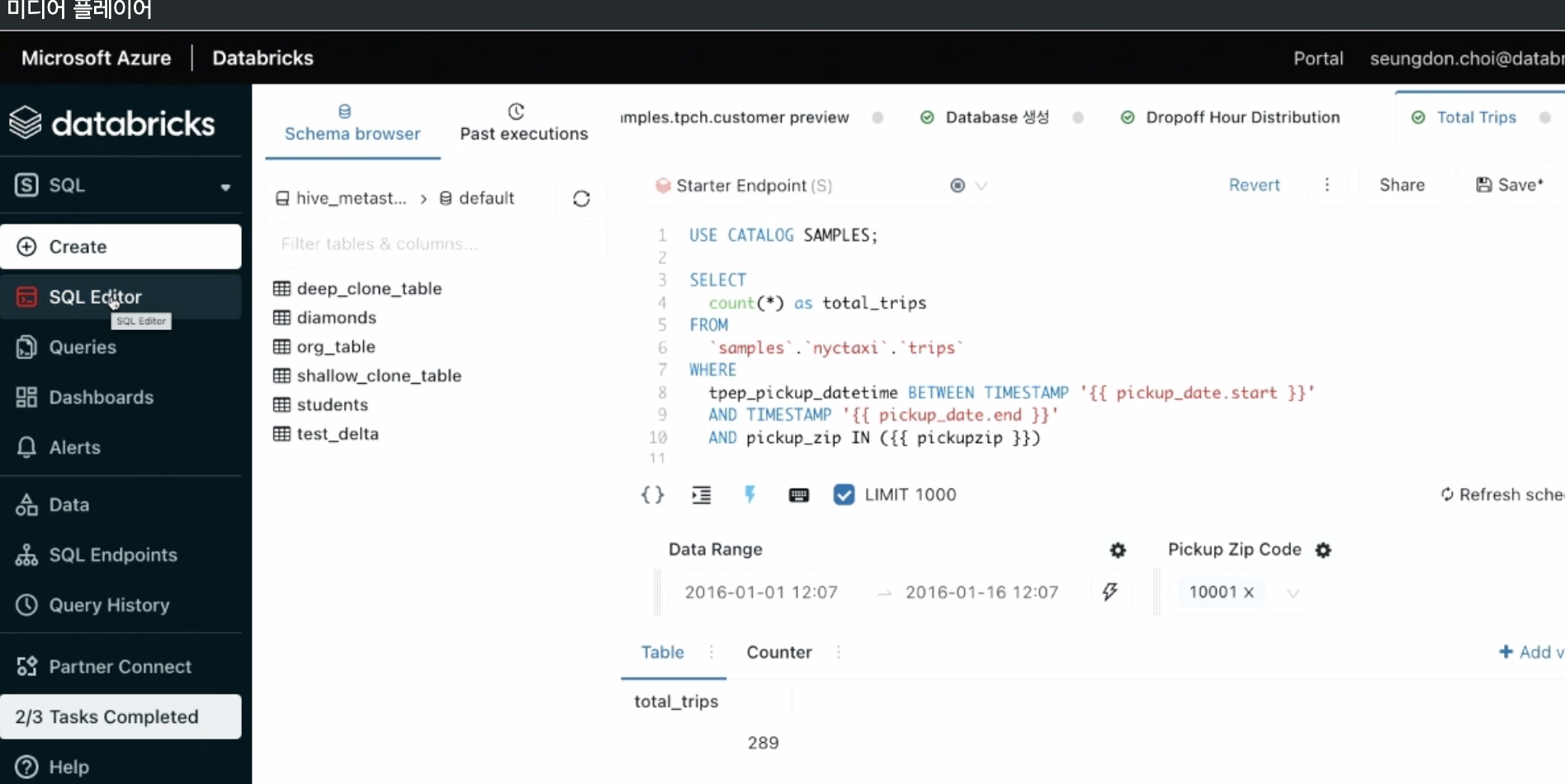
SQL 엔드포인트
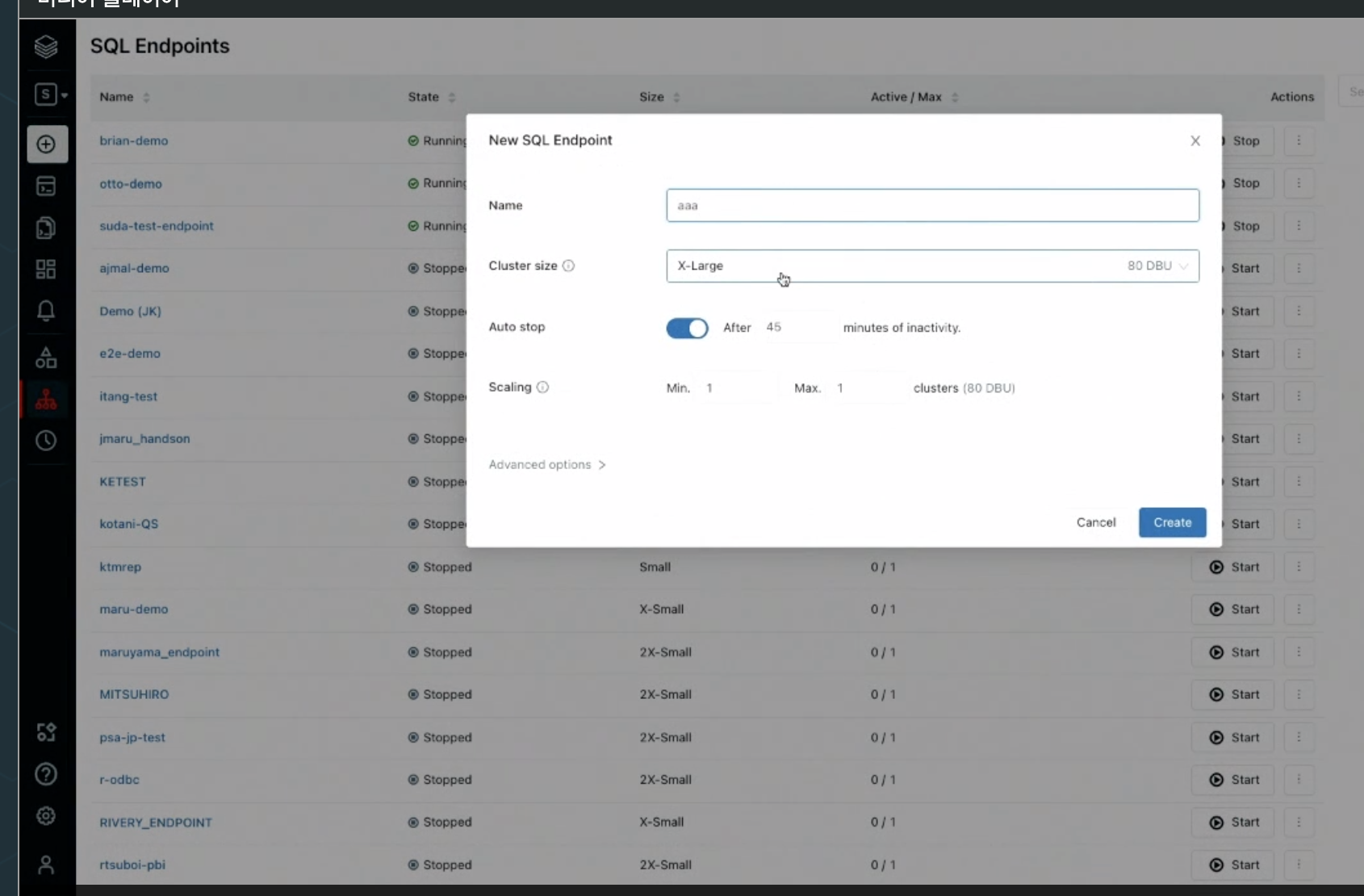
- 커넥팅
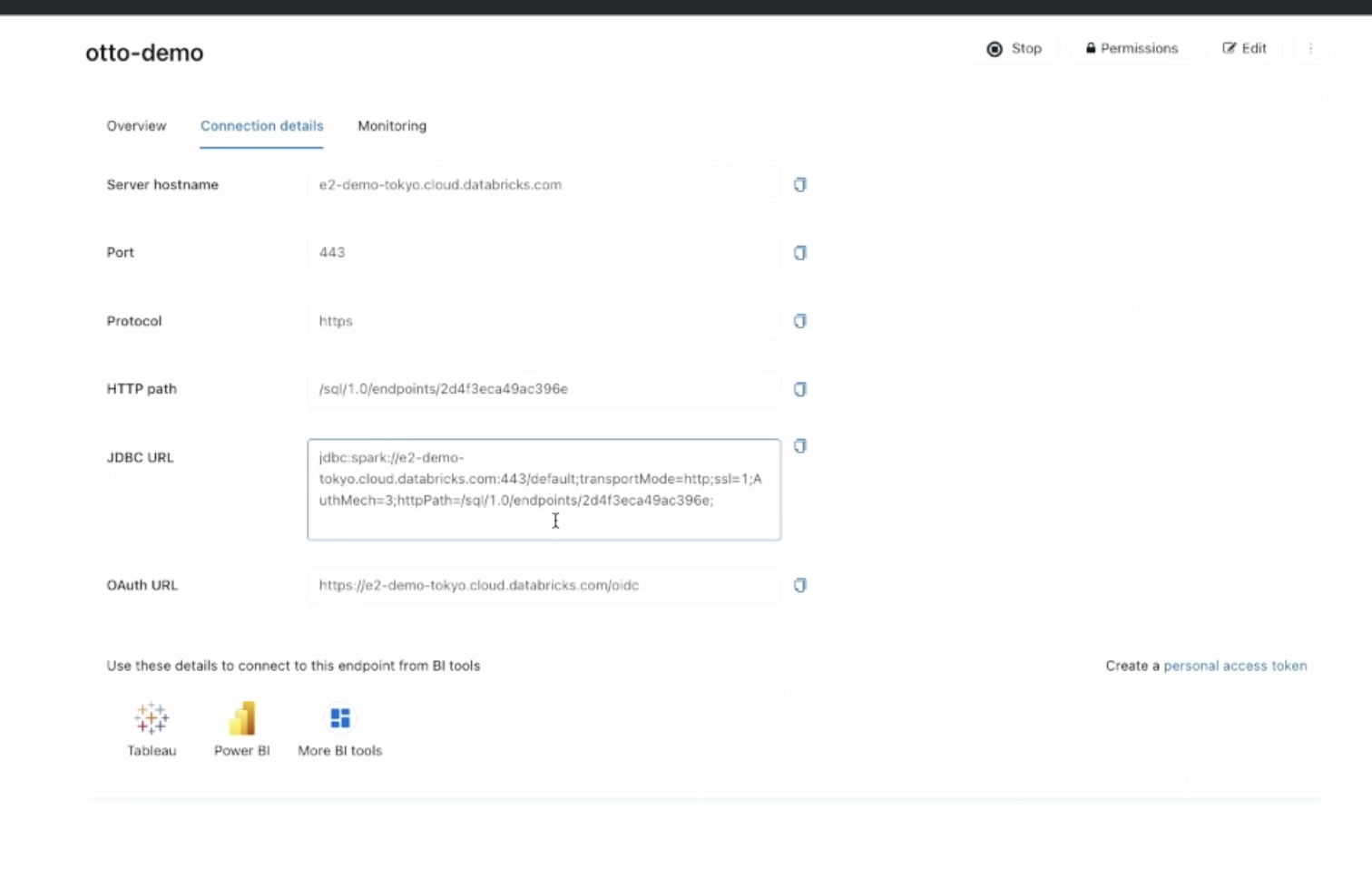
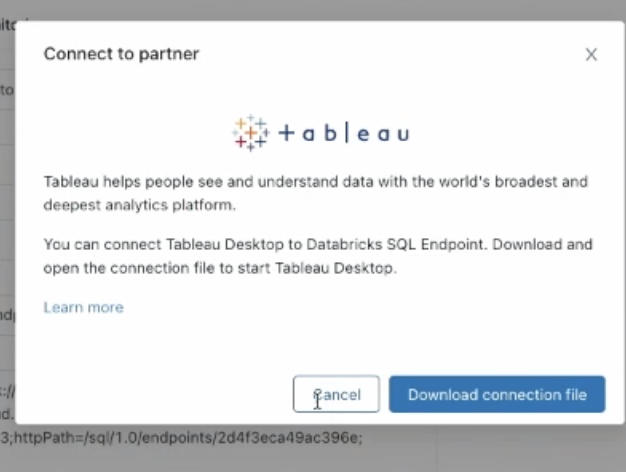
- 외부 BI연결
- 동시성
- SQL에디터 (리대시)
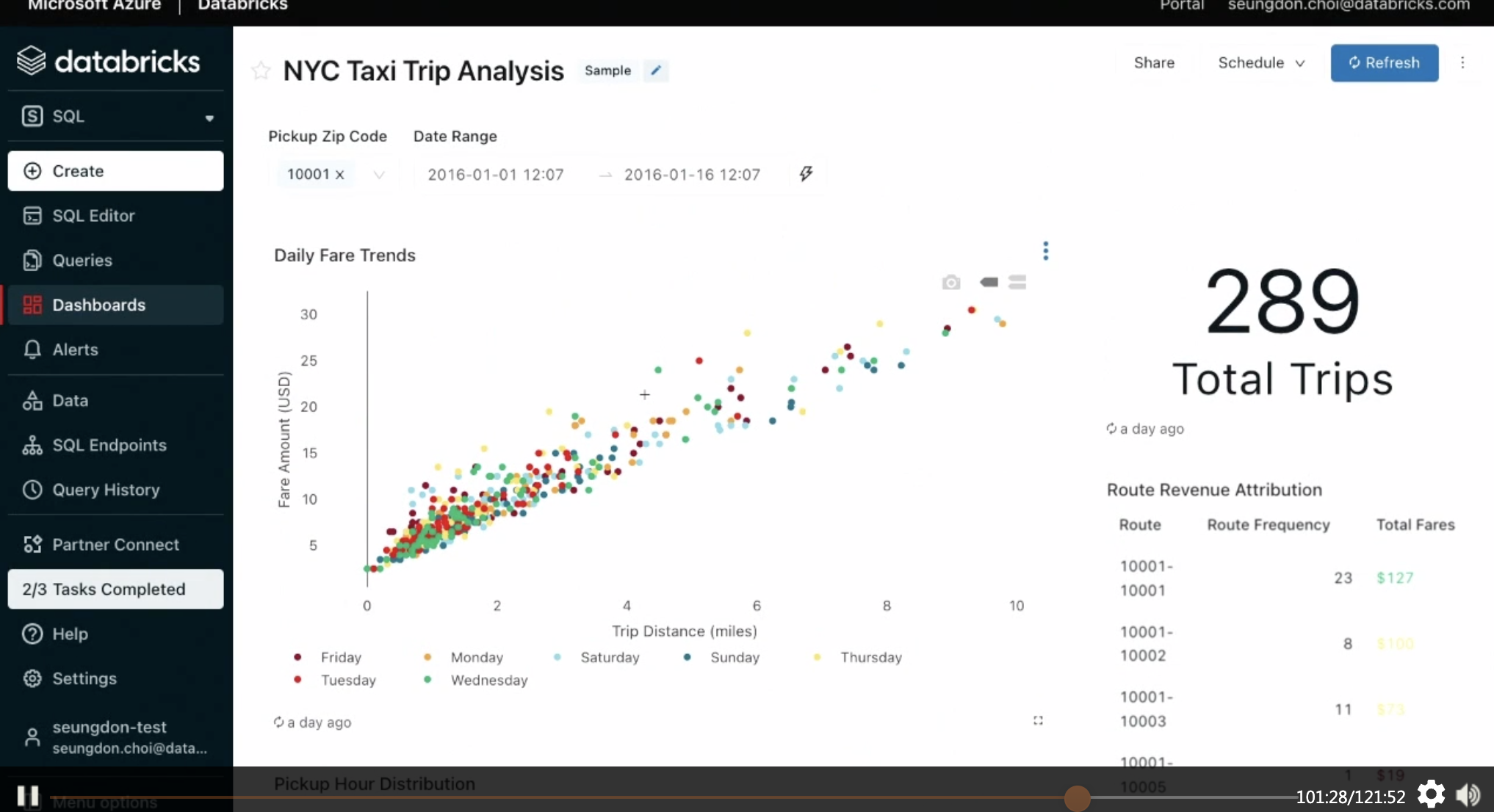
- 샘플 대시보드.
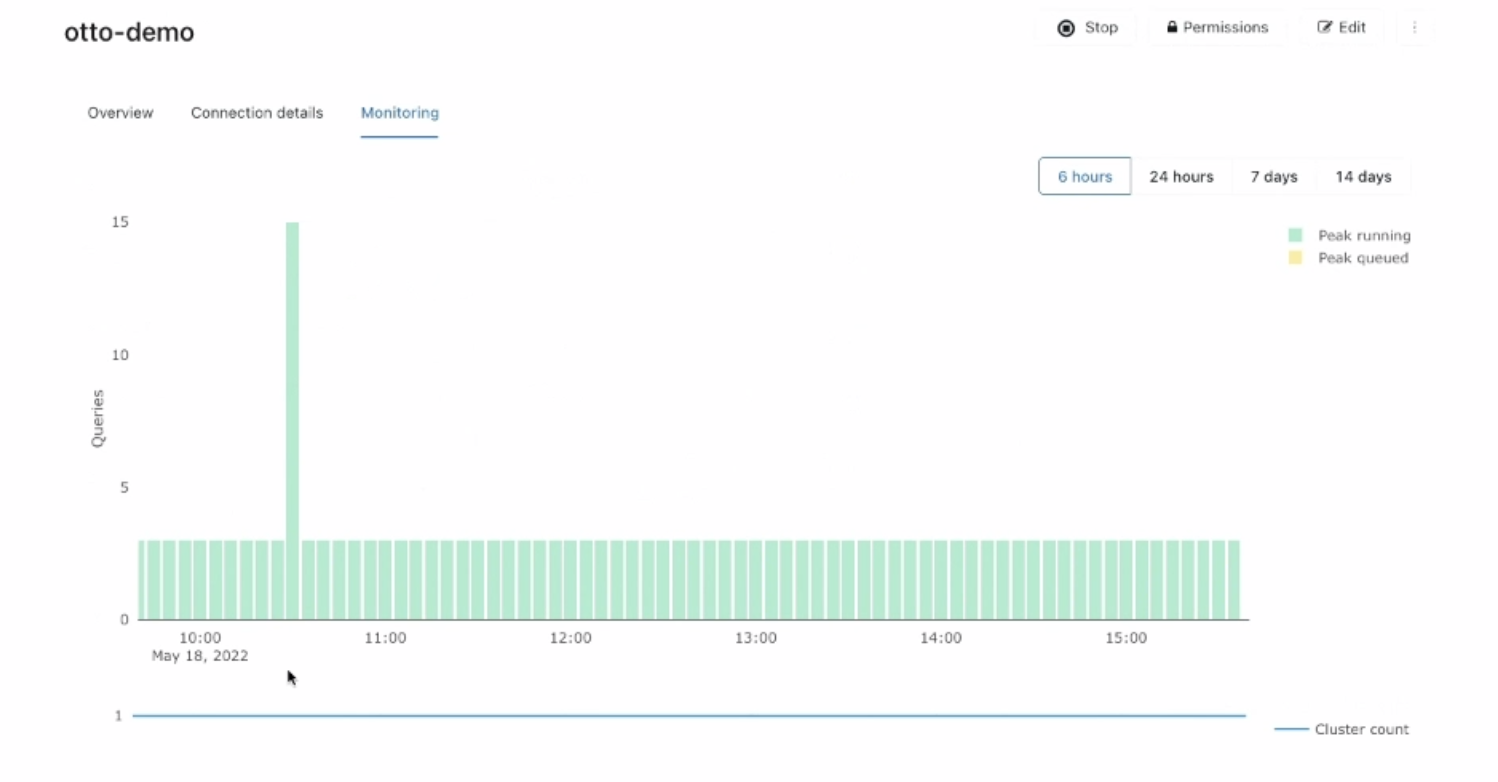
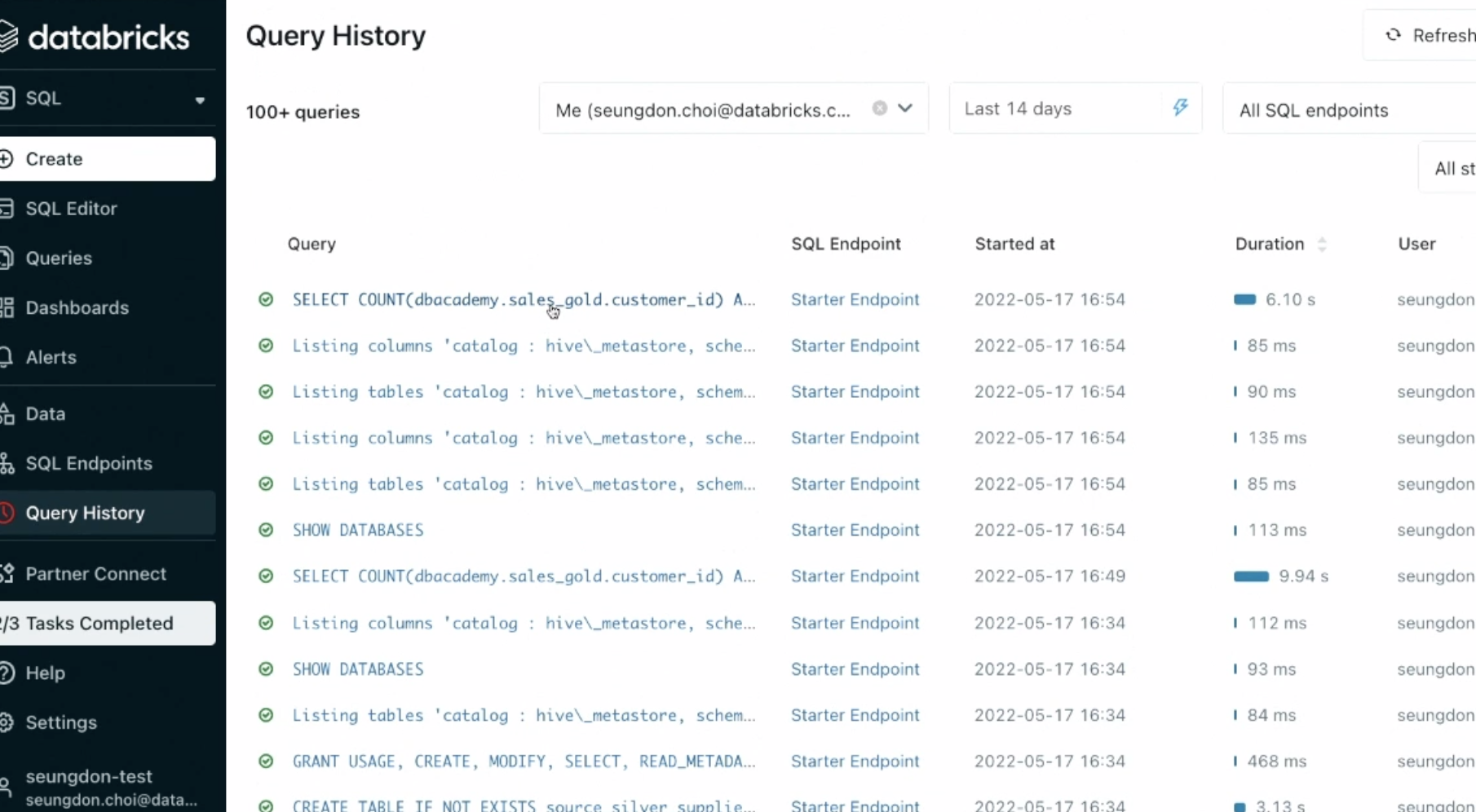
- 쿼리 히스토리 & 성능이슈



미니퀴즈

- 정답 4번.

성장하고 싶은 데이터분석가.