1. List
list 변수는 여러 개의 값을 담을 수 있는 자료형입니다.
문자열과 마찬가지로 Sequence 자료형으로, 인덱싱(Indexing)과 슬라이싱(Slicing)이 가능하고
가변(Mutable) 자료형으로 데이터를 추가하거나 삭제도 가능합니다.
💡 Sequence는 여러 개의 데이터들이 연속적으로 이루어진 자료형이며 str, list, tuple이 해당됩니다. Mutable은 데이터를 변경할 수 있는 자료형이며 list, dict, set 등이 해당됩니다.
다음과 같이 list() 혹은 []를 이용하여 생성할 수 있습니다.
a = list()
print(type(a)) # <class 'list'>
a = []
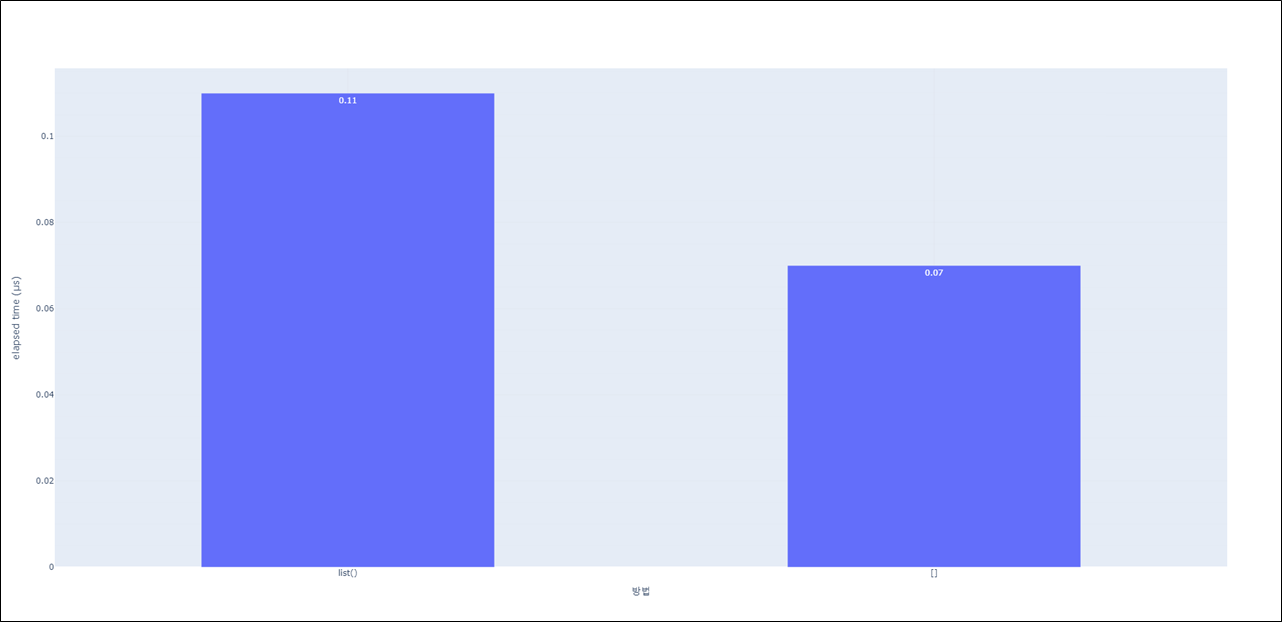
print(type(b)) # <class 'list'>list()를 사용하면 코드를 봤을 때 []보다는 이해하기 쉽지만
list()보다 []를 사용하면 성능 면에서 이점이 있습니다.
이번에는 [], list, 반복문을 이용하여 데이터와 함께 list를 생성해 봅니다.
a = [0,1,2,3,4,5,6,7,8,9]
print(a) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = list([0,1,2,3,4,5,6,7,8,9])
print(a) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = [i for i in range(10)]
print(a) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = []
for i in range(10):
a.append(i)
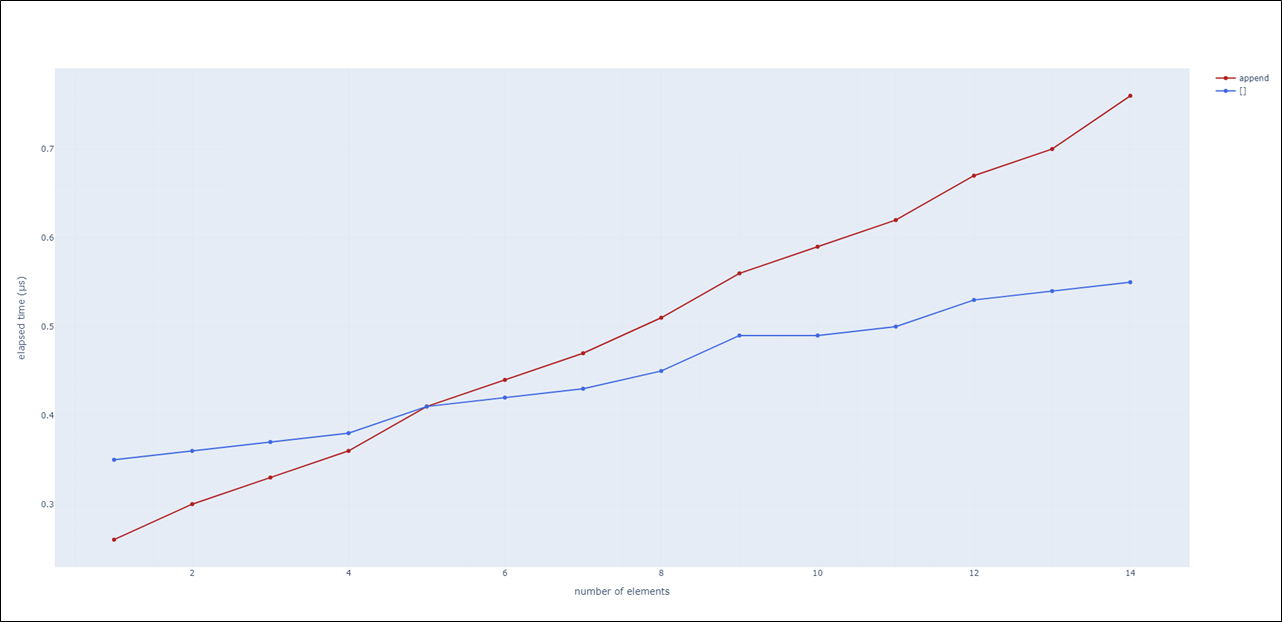
print(a) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]반복문 속 append를 이용하여 list를 생성하는 방법(10~12번 줄)과
한 줄 쓰기를 이용한 list를 생성하는 방법(7번 줄)의 성능을 확인해 보면
list의 크기가 커질수록 한 줄 쓰기를 이용한 방법의 성능이 좋아짐을 확인할 수 있습니다.
2. Operator
문자열처럼 덧셈(+) 기호를 이용하여 list를 이어붙이거나 곱셈(*) 기호를 이용하여 list를 반복하여 이어붙일 수 있습니다.
a = [0, 1, 3, 4]
b = [5, 6, 7, 8, 9]
print(f"{a+b}") # [0, 1, 3, 4, 5, 6, 7, 8, 9]
print(f"{a*3}") # [0, 1, 3, 4, 0, 1, 3, 4, 0, 1, 3, 4]💡 list + list가 아닌 list + 다른 자료형이면 TypeError가 발생합니다.
3. Indexing and Slicing
문자열처럼 Sequence 자료형이기 때문에 인덱싱(Indexing)과 슬라이싱(Slicing)이 가능합니다.
인덱싱(Indexing)은 문자열의 위치를 통해 데이터를 가져올 수 있습니다.
a = [0,1,2,3,4,5,6,7,8,9]
print(a[2]) # 2💡 인덱스는 0부터 시작하며, -1은 마지막을 의미합니다.
중첩된 list는 인덱스를 통해 데이터에 접근할 수 있습니다.
a = [0, 1, [2, 3, 4, [5, 6, 7], 8, 9]]
print(a[2][3][2]) # 7인덱싱이 1개의 데이터를 가져왔다면, 슬라이싱(Slicing)은 범위만큼 데이터를 가져올 수 있습니다.
슬라이싱 시 시작 인덱스 혹은 끝 인덱스에 빈 값을 주면 처음부터 혹은 끝부터라는 의미가 됩니다.
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[:5]) # [0, 1, 2, 3, 4]
print(a[-3:]) # [7, 8, 9]
print(a[2:7]) # [2, 3, 4, 5, 6]
print(a[::-1]) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
print(a[1:6:2]) # [1, 3, 5]💡 세 번째 인자는 step의 역할이 됩니다.
4. Functions
list와 관련하여 유용한 함수들이 존재합니다.
append 및 extend를 통해 단일 데이터를 추가할 수 있으며
특정 위치에 데이터를 추가하고자 한다면 insert를 이용할 수 있습니다.
a = [0,1,2,3,4]
a.append(5)
a.append([6, 7])
print(a) # [0, 1, 2, 3, 4, 5, [6, 7]]
a = [0,1,2,3,4]
b = [5, 6]
a.extend(b)
a.extend("WOW")
print(a) # [0, 1, 2, 3, 4, 5, 6, 'W', 'O', 'W']
a = [0,1,2,3,4]
a.insert(2, 5)
print(a) # [0, 1, 5, 2, 3, 4]💡 append는 데이터를 그대로 추가하지만 extend는 iterable 한 요소들을 하나씩 추가하는 차이가 있습니다.
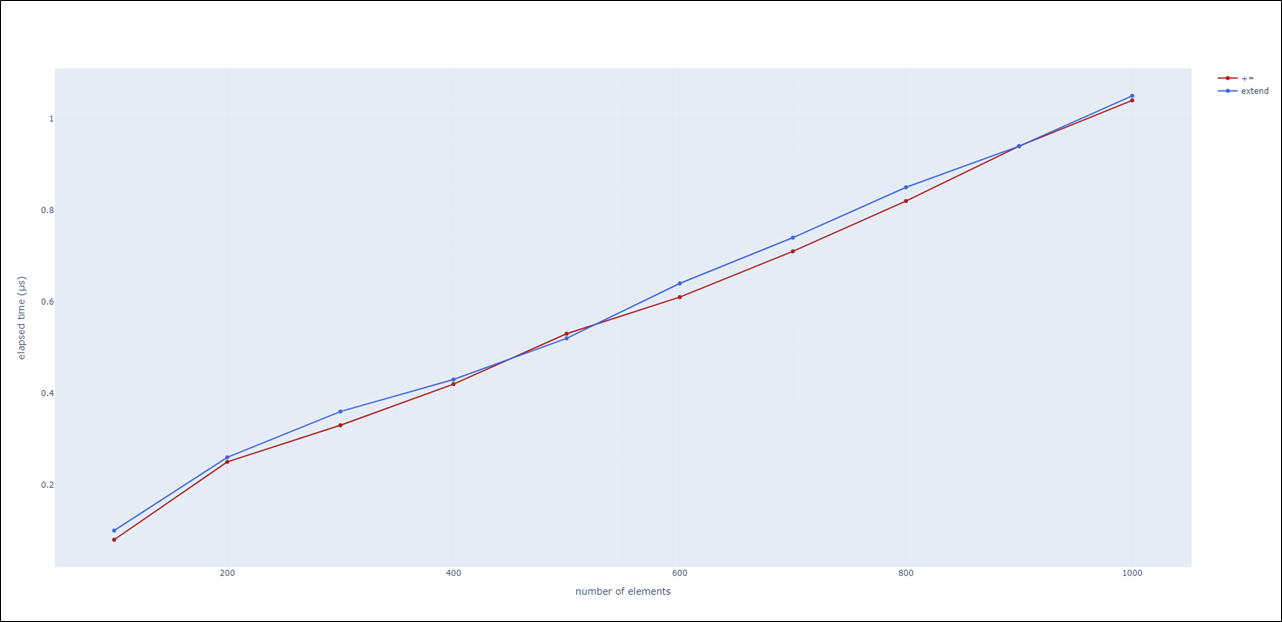
+=과 extend를 이용한 list 병합 시 성능은 비슷합니다.
데이터를 삭제 시 del, pop 혹은 remove를 사용합니다.
del과 pop은 list의 인덱스 번호를 통해 데이터를 삭제할 수 있으며,
remove는 데이터의 값과 일치하는 요소를 삭제합니다.
a = [i*2 for i in range(10)]
print(a) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
del a[0]
print(a) # [2, 4, 6, 8, 10, 12, 14, 16, 18]
a.remove(12)
print(a) # [2, 4, 6, 8, 10, 14, 16, 18]
a = [i*2 for i in range(10)]
print(a.pop(2)) # 4
print(a) # [0, 2, 6, 8, 10, 12, 14, 16, 18]💡 pop은 list에서 삭제된 요소가 반환됩니다.
index를 사용하면 list에서 찾는 데이터 중 제일 첫 번째로 나오는 위치를 반환합니다.
두 번째 인자 값은 찾기 시작하는 위치이며, 세 번째 인자 값은 마지막 위치입니다.
a = [1 if i % 2 == 0 else 0 for i in range(10)]
print(a) # [1, 0, 1, 0, 1, 0, 1, 0, 1, 0]
print(a.index(1)) # 0
print(a.index(1, 1, len(a))) # 2list의 데이터에서 중복된 데이터의 수를 구하고 싶다면 count를 사용합니다.
a = [1 if i % 2 == 0 else 0 for i in range(10)]
print(a) # [1, 0, 1, 0, 1, 0, 1, 0, 1, 0]
print(a.count(0)) # 5데이터를 내림차순으로 정렬하려면 sort를 사용하며
오름차순으로 정렬하려면 sort 후 reverse를 사용합니다.
a = [1,5,3,9,2,6,7,4,8,0]
a.sort()
print(a) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a.reverse()
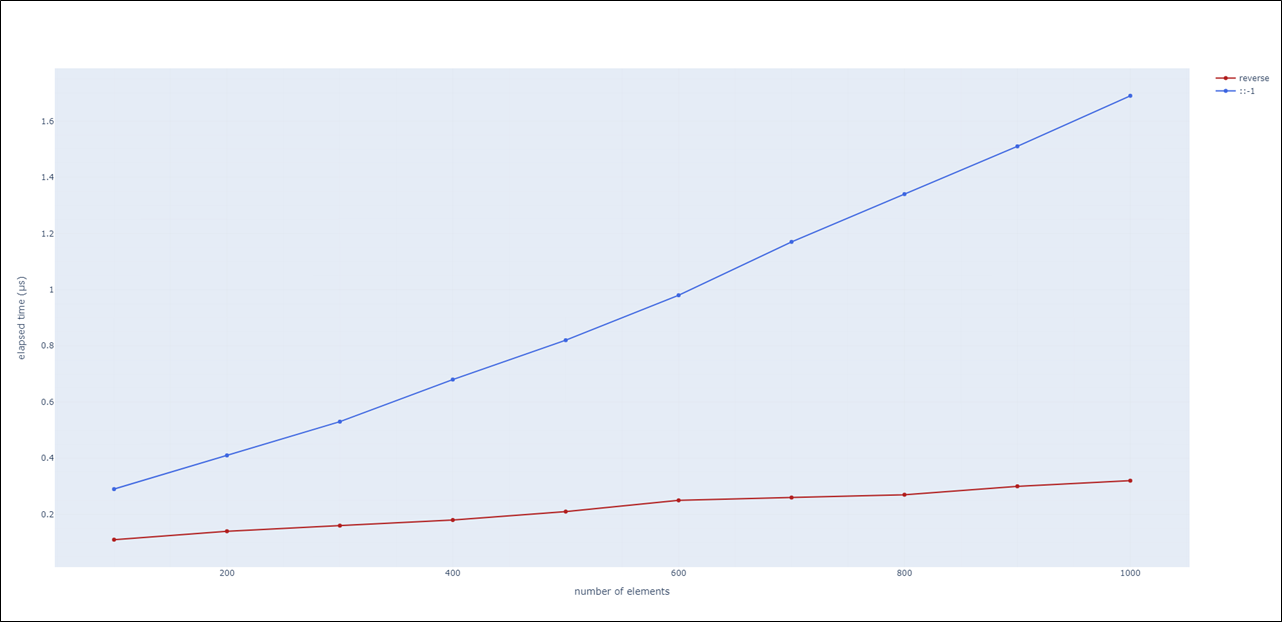
print(a) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]슬라이싱에서 ::-1을 주면 reverse와 같은 결과를 얻을 수 있지만, reverse의 성능이 좋습니다.