알고리즘 2
9장
재귀적 해법
- 관계 중심으로 파악하여 문제를 간명하게 볼 수 있다.
- 잘못 사용하는 경우 심한 중복 호출이 발생한다
- 쿽정렬, 병합 정렬 등에 사용됨
- 피보나치, 행렬 곱셈 최적 순서 구하는 등에 사용시 치명적임
동적 프로그래밍의 적용 조건
다음 조건을 만족해야 한다
최적 부분 구조
- 큰 문제의 최적 솔루션에 작은 문제의 최적 솔루션이 포함됨
재귀 호출시 중복
- 재귀적 해법으로 풀 경우 같은 문제에 대한 재귀 호출이 심하게 중복됨
예시 1
10장 그래프 알고리즘
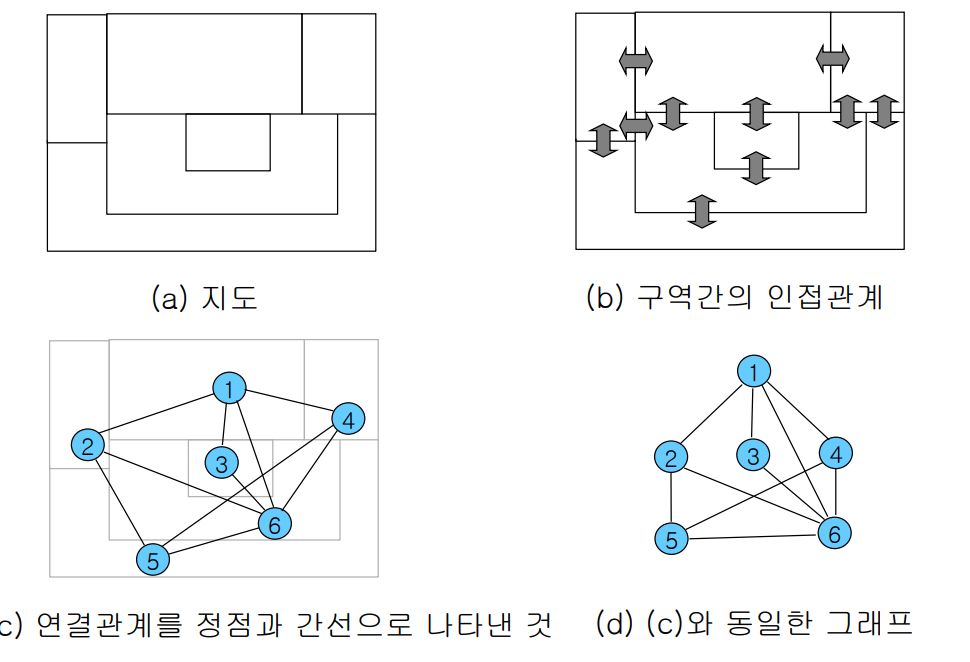
그래프
- 현상이나 사물을 정점, 간선으로 표현한 것
- G = (V, E)
V는 정점 집합, E는 간선 집합 - 두 정점이 간선으로 연결되어 있는 경우 인접하다고 한다
인접행렬
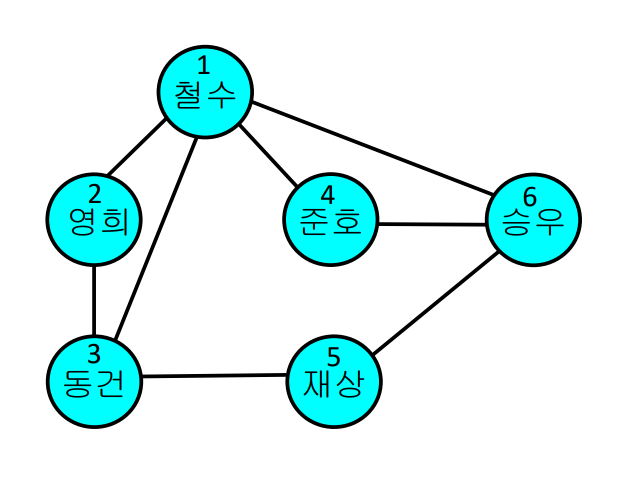
N * N 행렬로 표현
- 원소 (i, j) = 1 : 정점 사이에 간선이 있음
- 원소 (i, j) = 0 : 정점 사이에 간선이 없음
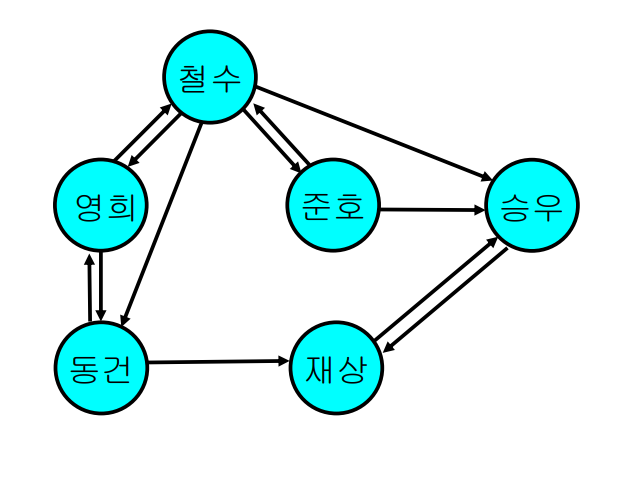
유향 그래프의 경우
- 원소 (i, j)는 두 정점 사이에 간선의 존재 여부를 나타냄
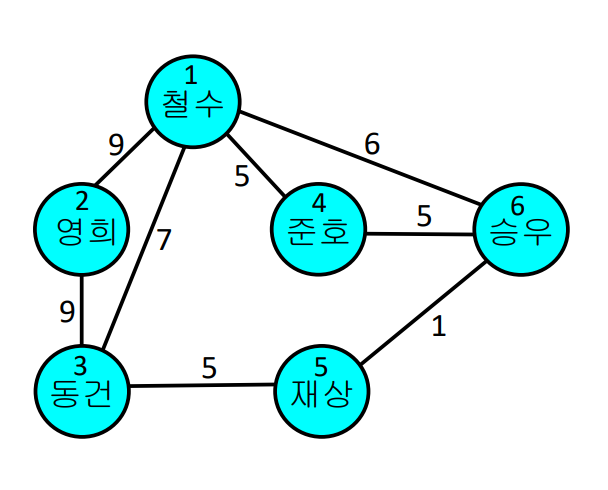
가중치 있는 그래프의 경우
- 원소 (i, j)는 1대신 가중치를 가짐
인접 리스트
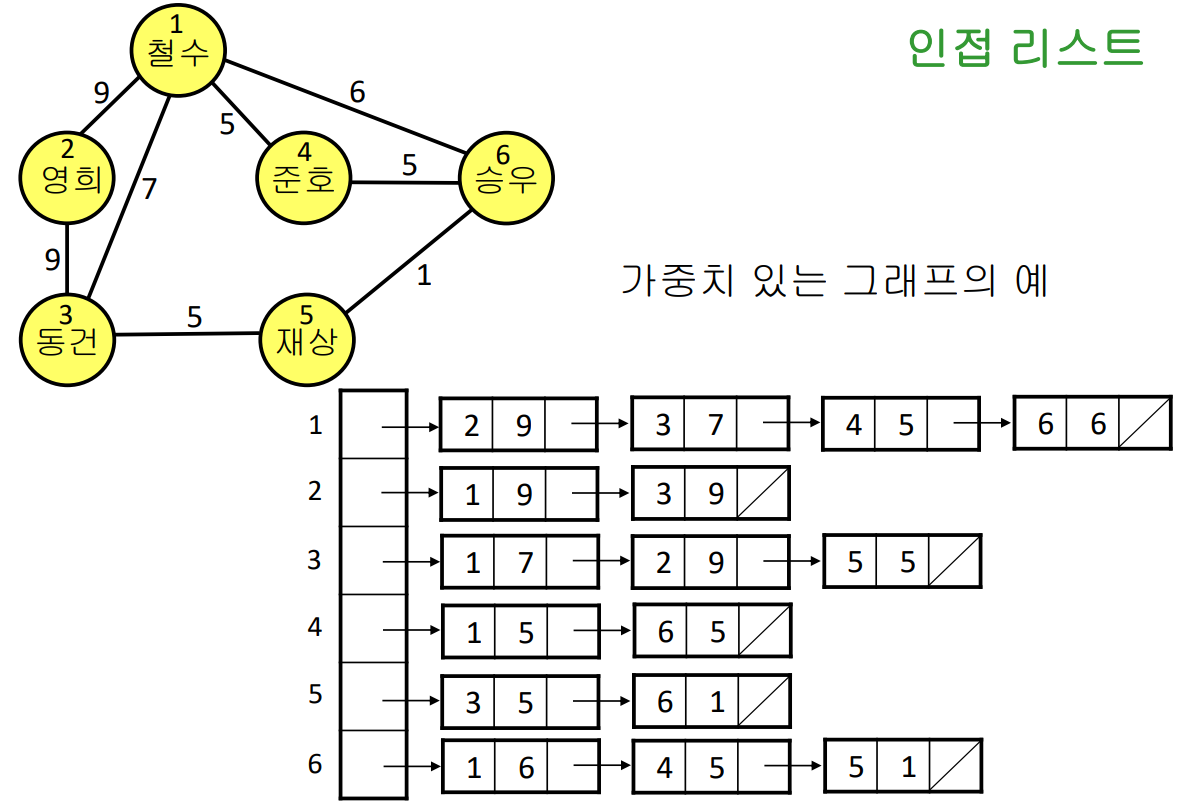
- N개의 연결 리스트로 표현
- i번째 리스트는 정점 i에 인접한 정점들을 리스트로 연결해 놓음
- 가중치가 있을 경우, 리스트에 가중치도 보관한다
인접 배열
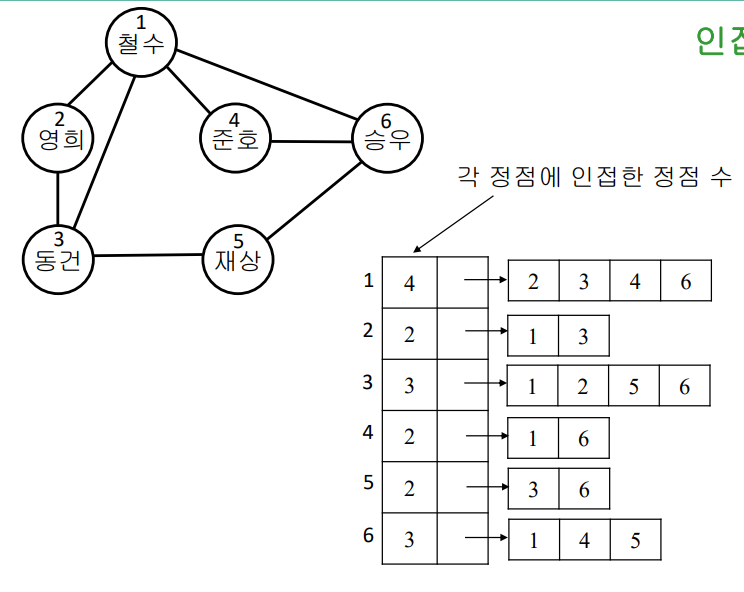
- N개의 연결 배열로 표현
- i번째 배열은 정점 i에 인접한 정점들의 집합
- 가중치가 있을 경우, 리스트에 가중치도 보관한다
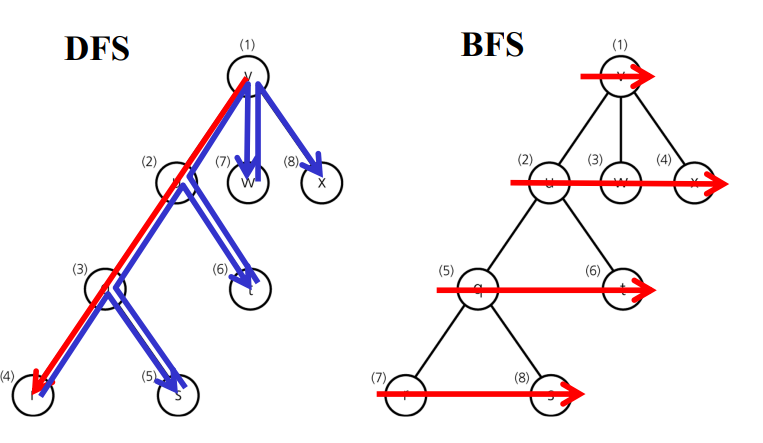
그래프에서 모든 정점 방문하기
BFS : 너비 우선 탐색
DFS : 깊이 우선 탐색
최소신장트리
조건 : 무향 연결 그래프(모든 정점간에 경로가 존재해야 한다)여야 함
트리
- 싸이클이 없는 연결 그래프
- n개의 정점을 가진 트리는 항상 n-1개의 간선을 가진다
그래프 G의 신장트리
- G의 정점들과 간선들로만 구성된 트리
G의 최소 신장 트리
- G의 신장 트리들 중 간선의 합이 최소인 신장 트리
프림 알고리즘, 크루스칼 알고리즘 등이 존재
위상 정렬
- 싸이클이 없는 유향 그래프
위상정렬
- 모든 정점을 일렬로 나열하되, 정점 X에서 정점 Y로 가는 간선이 있으면 X는 Y보다 반드시 앞에 존재하여야 함
최단 경로
조건
- 간선 가중치가 있는 유향 그래프
- 무향 그래프는 각 간선에 대해 양쪽으로 유향 간선이 있는 유향 그래프로 생각 가능
두 정점 사이의 최단 경로
- 간선의 가중치 합이 최소인 경로
- 간선 가중치의 합이 음인 싸이클이 없다고 가정한다
단일 시작점 최단 경로
- 다익스트라 알고리즘 : 음의 가중치를 허용하지 않음
- 벨만-포드 알고리즘 : 음의 가중치를 허용함
- 싸이클이 없는 경우
모든 쌍 최단 경로
- 모든 정점 쌍 사이의 최단 경로를 구함
- 플로이드-워샬 알고리즘
11장 그리디 알고리즘
- 눈앞의 이익을 취하고 보는 알고리즘
- 현재 시점에 가장 이득이 되어 보이는 해를 선택
- 대부분 최적해랑 거리가 먼 알고리즘 (이진 트리의 최적합 경로 찾기 등)
최적해를 보장하는 경우
- 프림, 크루스칼 알고리즘
- 회의실 배정 문제
-> 종료시간이 가장 이른 회의순으로 배정하는 방법 - 매트로이드
매트로이드
유한 집합 S의 부분 집합들의 집합인 𝐼(즉, 𝐼 ⊆ 2𝑆)가 다음 성질을
만족하면 매트로이드
- 𝐴 ∈ 𝐼이고 𝐵 ⊆ 𝐴이면 𝐵 ∈ 𝐼이다 (상속성)
- 𝐴, 𝐵 ∈ 𝐼이고 |A| ⊆ |𝐵|이면 𝐴 ∪ {𝑥} ∈ 𝐼인 𝑥 ∈ 𝐵 − 𝐴가 존재한다
(증강성 또는 교환성)
12장 문자열 매칭
- 텍스트 문자열이 패턴 문자열을 포함하는지 알아본다
원시적인 매칭의 작동 원리
- 한칸씩 이동하면서 매칭되는지 확인
오토마타를 이용한 매칭
오토마타
- 문제 해결 절차를 상태의 전이로 나타낸것
- 매칭이 진행된 상태들간의 관계를 오토마타로 표현한다

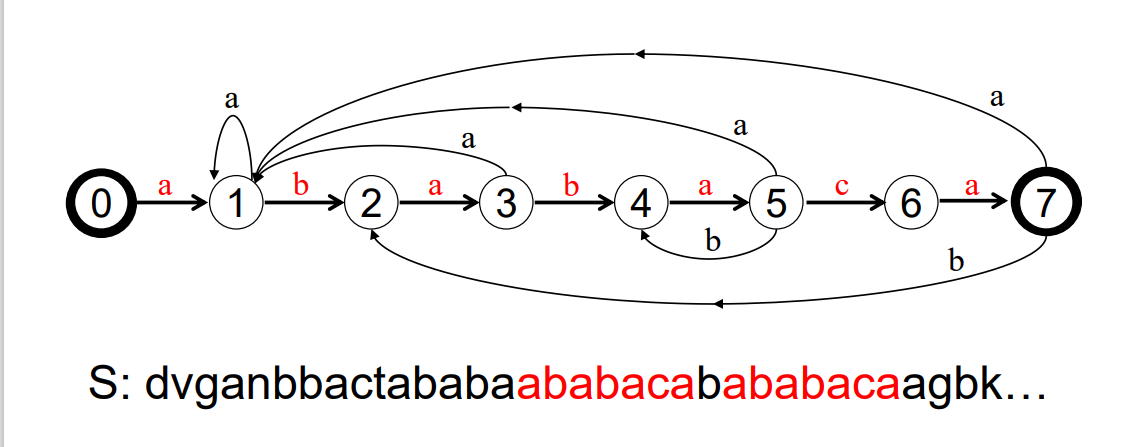
라빈-카프 알고리즘
문자열 패턴을 수치로 바꾸어 문자열의 비교를 수치 비교로 대신한다
수치화
- 가능한 문자 집합의 크기에 따라 진수가 결정된다

수치화 작업의 부담
- A[i…i+m-1]에 대응되는 수치의 계산

문제점
- 문자 집합의 m의 크기에 따라 ai가 매우 커질 수 있다.
- 컴퓨터의 레지스터의 용량을 초과하거나, 오버플로우가 발생한다
해결책
- 나머지 연산을 통해 ai의 크기를 제한한다.

KMP 알고리즘
- 오토마타 매칭과 동기가 유사함
- 매칭을 실패했을때 돌아갈 상태를 준비한다는 것도 유사함
- 오토마타 매칭보다 준비 작업이 단순하다
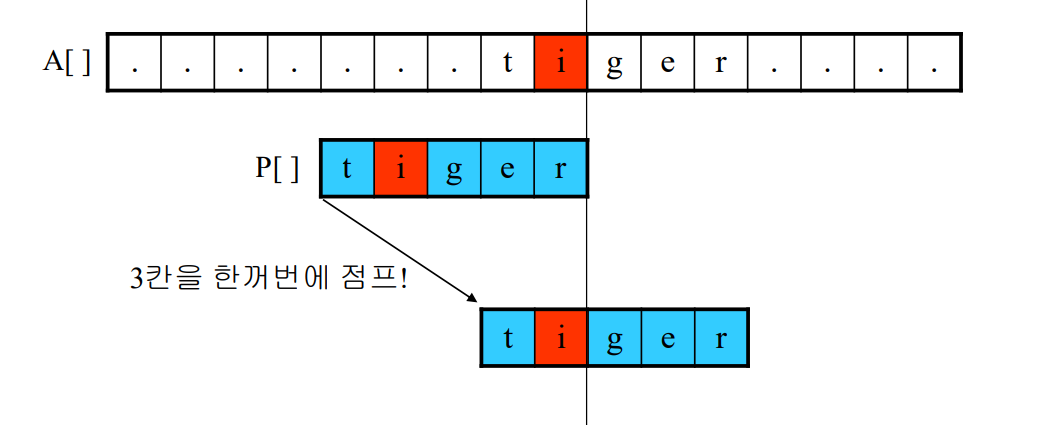
보이어-무어 알고리즘
- 앞의 알고리즘과 달라 텍스트 문자를 다 보지 않아도 된다
- 찾는 문자열의 맨 오른쪽부터 탐색
상황 1 : 텍스트의 b와 패턴의 r을 비교하여 실패했다
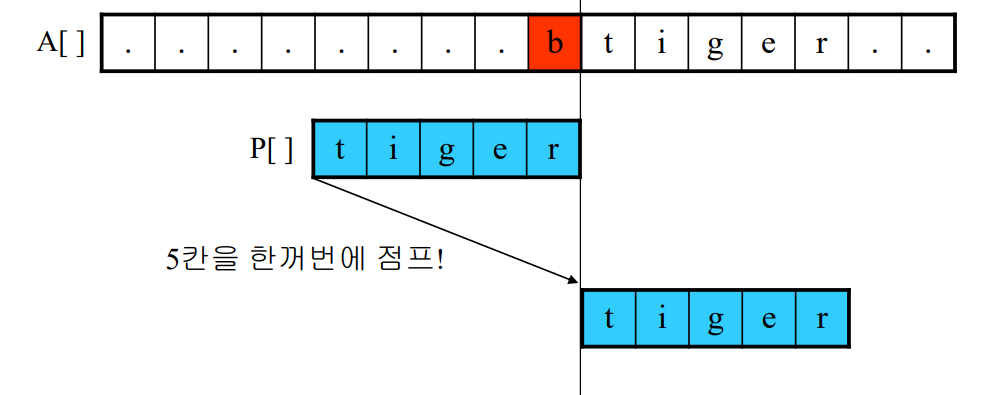
상황 2 : 텍스트의 i와 패턴의 r을 비교하여 실패했다
NP 완비 이론
np-완비 문제
- 풀수 있으나, 현실적인 시간내에 풀 수 없는 문제들
np-완비 이론
- Y/N의 대답을 요구하는 문제에 국한
- 최적화 문제와 밀접한 관계를 가지고 잇음
- 문제를 현실적인 시간에 풀수 있는가에 대한 이론
P
- polynmoial
- 다항식 시간 안에 yes/no 대답이 가능한 경우
NP
- Nondeterministic polynmoial
- yse라는 대답이 나오는 해를 제공했을 때,
이건이 Yes 대답을 내는 해라는 사실을 다항식 시간 안에 확인이 가능한 경우
np-완비/하드
np-하드는 다음 성질을 만족하는 경우
- 모든 np 문제가 L로 다항식 시간에 변환 가능하다
np-완비
- L은 NP이다
- L은 NP-하드이다
ex)
- 최단 경로의 경우, 간단히 구할 수 있으나
최장 경로의 경우 간단히 구할 수 없다
-> np 완비 문제
np 이론의 유용성
- 어떤 문제가 np-완비/하드임이 확인 될 경우,
쉬운 알고리즘을 찾는 것이 아닌 주어진 시간 안에 최대한 좋은 해를 찾는 알고리즘 개발에 집중 가능
14장 상태공간 트리의 탐색
상태공간트리
- 문제 해결 과정의 중간 상태를 각각 한 노드로 나타낸 트리
백트래킹
- DFS 또는 그와 같은 스타일의 탐색을 총칭한다
- 미로 찾기 문제, 지도 색칠하기 문제 등
미로 찾기 문제 알고리즘

색칠 문제
- 인접한 정점은 같은 색을 칠할 수 없을 때, k개의 색상을 사용해서 전체 그래프를 칠할 수 있는가?
한정 분기
- 분기를 한정시켜 쓸데없는 시간 낭비를 줄이는 방법
백트레킹과 공통점
- 경우들을 차례로 나열하는 방법이 필요
차이점
- 백트래킹 : 더이상 진행이 안되는 경우 돌아온다
- 분기한정 : 최적해를 찾을 가능성이 없으면 분기는 하지 않음
A* 알고리즘
최적 우선탐색에 목적점에 이르는 잔여추정 거리를 고려하는 알고리즘
- 정점 x로부터 목적점에 이르는 잔여거리의 추정치 h(x)는 실제치보
다 크면 안된다
최적 우선 탐색
- 각 정점이 매력함수 값 g(x)를 가지고 있다
- 방문하지 않응 정점 중 g(x)값이 가장 매력적인 것부터 방문한다
ex)다익스트라 알고리즘
- 시작점부터 다른 모든 정점에 이르는 최단 경로를 탐색
- A* 알고리즘에서는 목적점이 하나이다
선택 알고리즘
평균선형시간 선택 알고리즘
수행시간은 분할의 균형에 영향을 받는다

분할 알고리즘을 사용하여 i번째 값을 찾을 수 있다
- 기준 원소를 5로 하고, 3번째로 작은 원소 탐색시

- 5가 5번째로 작은 원소 이므로, 3번째로 작은 원소는 5의 왼쪽에 위치
-> 따라서 5의 왼쪽에 있는 원소를 기준으로 다시 분할

이것을 반복하여 i번째로 작은 원소를 탐색
최악의 경우 선형시간 선택 알고리즘
- 최악의 경우 분할의 균형이 어느 정도 보장되도록 한다
- 분할 균형을 유지하기위한 오버헤드가 지나치게 크면 안됨
-
전체 원소를 5개씩의 원소를 가진 그룹들로 나눈다.(이때 꼭 5개일 필요는 없다)
-
각 그룹에서 중앙값을 찾는다. -> 상수시간 * O(n/5) = O(n)
-
중앙값들의 중앙값을 구한다. 이때 구하는 방법은 이 알고리즘을 자가 호출하여 구한다. 짝수이면 두 중앙값 중 임의로 선택한다. -> T(ceil(n/5))
-
이렇게 구한 M을 기준원소로 삼아 전체 원소를 분할한다.(M보다 작은 원소는 왼쪽에, 큰 원소는 오른쪽에)
-
분할된 그룹 중 적절한 그룹을 선택하여 재귀적으로 반복한다. -> 최악의 경우에도 T(7n/10 + 2)
