
Thread Pool, Monitor, Fork-Join
Thread Pool
미리 일정 수의 스레드를 생성해두고, 작업이 들어오면 스레드가 작업을 처리하도록 하는 구조
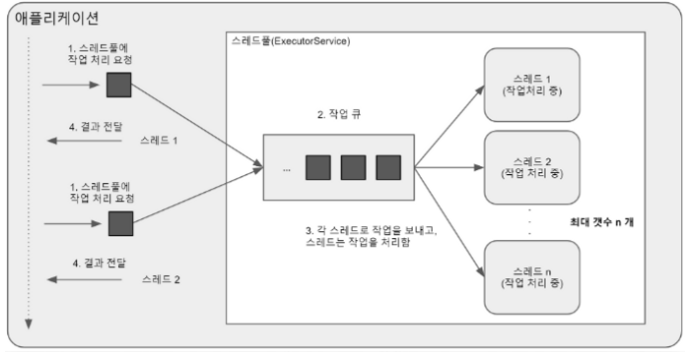
과정
- 스레드의 최대 개수를 제한하고 미리 생성한다.
- 사용자로부터 들어온 요청을 작업 큐에 넣는다.
- 작업 큐에 들어 있는 작업을 스레드 풀의 스레드가 맡아 처리한다.
- 작업이 끝난 스레드는 다시 3번 과정을 진행한다.
장점
- 스레드를 재사용할 수 있기 때문에 새로운 스레드 생성에 드는 비용을 줄일 수 있다.
- 사용할 스레드 개수를 제한하기 때문에 스레드가 무한정 생성되는 것을 방지하여 성능을 안정화할 수 있다.
단점
- 필요 이상의 개수의 스레드를 미리 만들어놓을 경우 메모리 낭비가 발생한다.
Java에서의 사용
ThreadPoolExecutor를 제공한다.
예시: Java의Executors.newFixedThreadPool(n)
Monitor
세마포어에서 발전된 형태로, 하나의 객체에 대해 동기화(synchronized) 를 통해 임계 구역(Critical Section)을 제어하는 구조
큐
두 가지 큐를 사용한다.
- entry queue
- critical section에 진입을 기다리는 큐
- mutex에 의해 관리된다.
- waiting queue
- 조건이 충족되기를 기다리는 큐
- condition variable에 의해 관리된다.
특징
- 한 번에 하나의 스레드만 접근 가능
- Java에서는
synchronized블록이 대표적인 모니터 구현
Fork-Join
큰 작업을 여러 작은 작업으로 분할(fork)하고, 각 작업을 병렬로 처리한 후 결과를 합치는(join) 방식
특징
- Java의
ForkJoinPool사용 - 분할정복법 (Divide and Conquer) 알고리즘에 적합하다.
- 하나의 작업을 작은 단위로 나누어 여러 스레드가 동시에 처리할 수 있게 만든다.
fork(): 프로세스(작업)을 여러 개로 쪼개서 새롭게 생성하는 작업join(): 포크해서 생성된 프로세스/스레드의 결과를 합치는 작업- 순차 처리(fork-join을 사용하지 않은 경우)보다 무조건 빠른 것은 아니다.
❓ Thread Pool에서 스레드 개수 정하는 기준
💡 CPU-bound 작업 (연산 위주)
- CPU 코어 수 + 1~2
💡 IO-bound 작업 (네트워크/DB 처리 등)
- CPU 코어 수 * 2~10
- 네트워크 요청(이미지 다운로드), 파일 저장, DB 처리 등 I/O 바운드 작업이 많음
→ 스레드 개수를 더 크게 설정하는 것이 유리하다.
스레드 개수를 결정하는 가장 기본적인 공식은 다음과 같다.
최적 스레드 개수 : (CPU 코어 수 * (1 + (대기 시간 / 처리 시간)))적절한 스레드 개수 결정하는 방법
1. 공식적인 계산법
최적 스레드 개수 = (응답 시간 * 요청 빈도) / 병렬 작업 수2. 직접 테스트 (Thread Dump & Monitoring Tools 활용)
스레드 개수를 직접 조정해보면서 실제로 얼마나 효율적으로 작동하는지 성능 테스트를 해볼 수도 있다.
- JVisualVM (Java VisualVM)
- JVM 성능을 모니터링하고, 스레드 사용량을 분석한다.
- JConsole
- Spring Boot에서 실행되는 현재 스레드 개수, CPU 사용량을 실시간으로 확인할 수 있다.
- Spring Actuator + Micrometer + Prometheus + Grafana 조합
- Spring Actuator와 Micrometer를 설정하면 현재 실행 중인 스레드 개수와 서버 부하를 확인할 수 있다.
결론
최적의 스레드 개수는 고정값이 아니라 테스트와 모니터링을 통해 조정하는 것이 중요하다.
대용량 데이터를 효과적으로 처리하려면 스레드 개수 최적화, 스레드 풀 활용, 비동기 처리, 데이터 분할 처리, 메시지 큐 활용과 같은 기법을 조합하는 것이 중요하다.
❓ 정렬 작업 : 어떤 전략이 가장 안전하고 빠를까
📌 안전성과 성능 모두 고려할 때: 병렬 정렬 (Parallel Sort)
특징
- 내부적으로 Fork-Join을 사용한다.
- 데이터의 크기가 클수록 효율적이다.
전략 비교
| 전략 | 안정성 | 성능 | 비고 |
|---|---|---|---|
| Arrays.sort (TimSort) | 안정적 | 중간~좋음 | 객체 배열에 적합 |
| Arrays.parallelSort() | 불안정 | 매우 빠름 (대용량) | 기본형 배열에 효과적 |
| Merge Sort | 안정적 | 병렬화 가능 | 메모리 사용 많음 |
| Quick Sort | 불안정 | 빠름 | 평균 성능 우수, 최악 O(n²) |
✅ 결론
- 안정성이 중요하다면:
TimSort기반Arrays.sort()(객체용) - 대용량 데이터 + 성능 우선:
Arrays.parallelSort()+ 병렬 처리 환경 - 병렬 처리 + 커스터마이징 필요: Fork-Join으로 직접 구현
캐시
캐시 메모리와 메모리 계층성
📌 캐시 메모리 (Cache Memory)
- CPU와 메인 메모리 (RAM) 사이에 위치하는 고속 임시 저장소
- 자주 접근하는 데이터나 명령어를 빠르게 제공하기 위해 사용된다.
📌 메모리 계층 구조 (Memory Hierarchy)
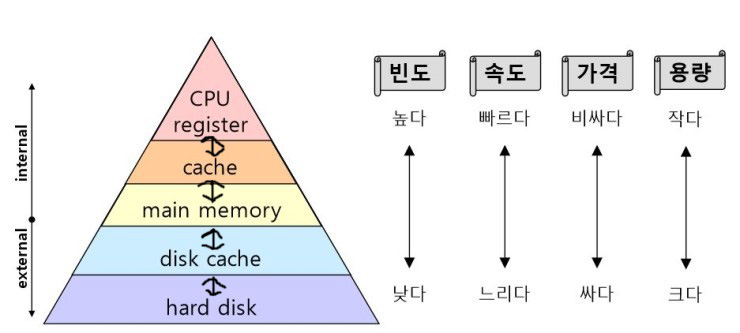
레지스터 < 캐시 (L1 < L2 < L3) < RAM < SSD/HDD
속도 : <- 빠름
용량 : <- 작음
가격 : <- 비쌈❓ 캐시 메모리는 어디에 위치해 있나요?
- L1, L2 캐시 메모리는 CPU 내부에 존재하며, 해당 캐시가 소속된 코어의 고유 메모리로서 사용된다.
- L3 캐시는 CPU 외부에 위치하며, 여러 코어들이 공유하여 사용한다.
- CPU ↔ 캐시 간 접근 속도는 나노초(ns) 단위이며, RAM은 수십~수백 ns로 훨씬 느리다.
❓ L1, L2 캐시
| 구분 | L1 캐시 | L2 캐시 |
|---|---|---|
| 위치 | CPU Core 내부 | CPU Core 내부 또는 인접한 외부 |
| 용량 | 작음 (16~128KB) | 중간 (256KB~1MB) |
| 속도 | 매우 빠름 | 빠름 (L1보다 느림) |
| 종류 | 보통 분리: 명령어 캐시 + 데이터 캐시 | 통합 캐시 가능 |
| 역할 | 즉시 필요한 데이터 제공 | L1에 없는 데이터를 백업 |
❓ 캐시에 올라오는 데이터는 어떻게 관리되나요?
Mapping 방식 (어디에 저장할지)
- Direct-mapped, Set-associative, Fully-associative
교체 정책 (Replacement Policy)
- LRU (Least Recently Used): 가장 오랫동안 사용되지 않은 데이터 제거
- FIFO (First In First Out): 가장 먼저 들어온 데이터 제거
- Random: 임의 블록 제거
쓰기 정책 (Write Policy)
- Write-through : 캐시와 RAM 동시에 갱신 → 데이터 일관성 보장
- Write-back : 캐시에만 갱신, 나중에 RAM에 반영 → 속도 빠름, 복잡함
❓ 캐시간의 동기화는 어떻게 이루어지나요?
대표적인 기술 : Cache Coherency (캐시 일관성)
멀티 코어 환경에서는 여러 캐시가 같은 데이터를 각각 저장할 수 있으므로, 동기화가 필요하다.
MESI 프로토콜
- Modified, Exclusive, Shared, Invalid
- 각 캐시 라인 상태를 관리하며, 변경되면 다른 코어에 알린다.
예를 들어, 한 코어가 데이터를 수정하면, 다른 코어의 해당 캐시 라인은 Invalid 상태가 되어 무효화되는 것이다.
❓ 캐시 메모리의 Mapping 방식
캐시는 CPU 주소를 특정 캐시 라인에 할당해야 한다. 이를 매핑 방식이라고 한다.
1️⃣ Direct Mapping
- 하나의 메모리 블록은 하나의 캐시 라인에만 저장하는 방식
- 구현이 간단하지만, 충돌 가능성이 크다.
2️⃣ Fully-Associative Cache
- 어떤 블록이든 어떤 캐시라인에도 저장이 가능하다.
- 유연하지만, 탐색 속도가 느리고 복잡하다.
3️⃣ Set-Associative Cache (N-way)
- 캐시를 N개의 set으로 나누고 각 set에 여러 line을 허용하는 방식
- 예 : 4-way Set Associative -> 한 Set에 4개 블록 저장 가능
❓ 캐시의 지역성
시간 지역성 (Temporal Locality)
- 최근에 사용된 데이터는 다시 사용될 가능성이 높다.
- 예 : 반복문에서 변수
i를 계속 사용하는 것
공간 지역성 (Spatial Locality)
- 인접한 주소의 데이터가 함께 접근될 가능성이 높다.
- 예 : 배열을 순차적으로 접근할 때
❓ 이차원 배열을 가로/세로로 탐색했을 때의 성능 차이
int arr[1000][1000];- 이차원 배열은 메모리에 행 우선으로 저장된다.
🔸 가로 탐색 (행 우선)
for (int i = 0; i < 1000; i++)
for (int j = 0; j < 1000; j++)
sum += arr[i][j];메모리에 arr[i][j]는 행(row) 순서대로 연속 저장
💡 공간 지역성 활용 → 캐시 적중률 높음
🔸 세로 탐색 (열 우선)
for (int j = 0; j < 1000; j++)
for (int i = 0; i < 1000; i++)
sum += arr[i][j];연속된 메모리 주소가 아님 → 캐시 적중률 낮음
💡 반복적으로 캐시 미스 → 성능 저하
📌 결론: 행 우선 탐색이 더 빠름 (공간 지역성 때문)
❓ 캐시의 공간 지역성은 어떻게 구현될 수 있을까요? (힌트: 캐시는 어떤 단위로 저장되고 관리될까요?)
캐시는 데이터를 블록 단위로 저장한다.
데이터 블록 단위 저장
- 캐시 메모리에 데이터를 저장할 때, 연속적인 데이터 블록 단위로 저장한다.
- 배열의 특정 요소를 접근했다면, 해당 요소와 주변 요소들도 함께 캐시에 저장한다.
- 이 덕분에 이후에 인접 데이터 접근 시 캐시 미스 줄어든다. -> 접근 속도 향상
- 캐시 블록(Cache Line): 일반적으로 64 bytes
- CPU가 주소 100번지를 읽으면, 100~163번지까지 미리 캐시에 적재 → 공간 지역성 활용
메모리의 연속할당 방식
연속할당은 하나의 프로세스가 메모리 내에서 연속된 공간을 차지해야 하는 방식이다.
할당할 공간을 선택하는 방식에 따라 세 가지 알고리즘이 있다.
1️⃣ First-Fit (최초 적합)

- 방식 : 앞에서부터 탐색하여 처음으로 맞는 빈 공간에 할당
- 장점 : 빠르다 (탐색을 멈추는 조건이 빠름)
- 단점 : 작은 조각(단편화)이 앞쪽에 계속 남을 수 있다.
- 적용 예시 : 성능이 중요할 때 사용할 수 있다.
2️⃣ Best-Fit (최적 적합)

- 방식 : 가장 딱 맞는 크기의 공간을 찾아서 할당
- 장점 : 낭비되는 공간(단편화)이 가장 적을 수 있다.
- 단점
- 작은 빈 공간이 많이 생겨 장기적으로 단편화가 심해질 수 있다.
- 탐색 시간이 길다. (전체 공간을 다 확인해야 한다.)
- 적용 예시 : 메모리 낭비를 최소화하려는 경우 사용할 수 있다.
3️⃣ Worst-Fit (최악 적합)

- 방식 : 가장 큰 빈 공간에 할당
- 장점 : 큰 공간을 쪼개 사용하므로, 나머지 공간도 유용하게 쓸 수도 있다.
- 단점 : 비효율적일 수 있고, 큰 공간이 너무 잘게 쪼개져 단편화 발생 가능
- 적용 예시 : 메모리 요청이 큰 프로세스 위주인 환경에서 고려할 수 있다.
-> 예 : 자주 큰 데이터를 다루는 시스템
💡 결론
가장 실용적이고 성능 좋은 방식: ✅ First-Fit
Worst-Fit 사용 시점
- 빈 공간이 너무 많은 상황에서, 큰 작업 위주로 처리될 것이 예상된다면 고려
- 하지만 대부분의 OS에서는 거의 사용되지 않음
Thrashing
페이지 부재(Page Fault)가 너무 자주 발생해서, CPU는 일만 시키지 못하고 계속 메모리 교체 작업만 하느라 바쁜 상태
즉, 프로그램 실행보다 페이지를 디스크와 메모리 사이에서 계속 교체(Swap-in/Swap-out) 하느라 시간을 낭비하는 상태이다.
❓ 페이지란
프로세스의 논리 주소 공간을 일정 단위로 자른 파편이다. 메모리의 물리 주소 공간을 나눈 것은 프레임이라고 부른다.
Thrashing의 증상
- CPU 사용률이 급격히 떨어진다.
- 페이지 폴트 (Page Fault) 빈도 급증
- 디스크 I/O 폭증 -> 성능 저하
Thrashing 완화 방법
| 방법 | 설명 |
|---|---|
| 프로세스 수 줄이기 | 과도한 멀티태스킹을 줄이면, 각 프로세스가 충분한 프레임을 확보 |
| 작업 집합(Working Set) 알고리즘 사용 | 각 프로세스가 일정 시간 동안 실제로 사용하는 페이지 집합을 추적하고, 그 집합만 메모리에 유지 |
| 페이지 폴트 빈도(Page Fault Frequency, PFF) 조절 | 페이지 폴트가 너무 많으면 프레임 증가, 너무 적으면 감소 |
| 적절한 페이지 교체 알고리즘 사용 (LRU 등) | 효율적인 알고리즘은 자주 쓰는 페이지를 유지해서 Thrashing을 줄임 |
| 가상 메모리 과도한 사용 제한 | 스왑 공간 의존 줄이고, 메모리 확장 고려 |
