
오늘 배운 것
EntityManager (엔티티 매니저)
엔티티 매니저는 Spring 애플리케이션의 엔티티 객체의 생명주기를 관리하며 이를 통해 데이터베이스 레코드와 객체 간의 매핑 및 조작을 보다 쉽게 수행할 수 있게 도와주는 객체이다. EntityManager은 영속성 컨텍스트(Persistence Context)를 통해 엔티티 객체의 상태를 관리한다. 영속성 컨텍스트는 일종의 1차 캐시 역할을 하여, DB와의 불필요한 트랜잭션을 줄이고, 애플리케이션의 성능을 향상시킨다. 또한, EntityManager은 트랜잭션 관리를 담당하고 있다. 즉, 트랜잭션의 시작(BEGIN), 커밋(COMMIT), 롤백(ROLLBACK)을 제어한다.
영속성 컨텍스트 (Persistence Context)
엔티티 객체의 상태를 추적하고, 해당 엔티티가 언제, 어떻게 데이터베이스와 상호작용할지 결정한다.
특징
- 영속성 컨텍스트는 EntityManager에 의해 관리된다.
EntityManager가 엔티티를 생성, 삭제, 수정하는 작업들은 모두 영속성 컨텍스트에서 이루어진다. - 기본적으로 세션(Session)이라고도 불리며, 이 세션은 엔티티 객체를 캐싱하는 역할을 한다.
- 동일한 엔티티를 여러 번 조회할 때 반복적으로 DB에 접근하지 않도록 한다.
- 트랜잭션이 시작되면 영속성 컨텍스트가 생성되며, 트랜잭션이 종료될 때까지 유지된다.
- 1차 캐시로도 작동한다.
- 같은 엔티티가 동일한 영속성 컨텍스트 내에서 여러 번 조회될 때, DB에 다시 접근하지 않고 캐시된 엔티티를 반환함으로써 성능을 최적화한다.
영속성 컨텍스트의 엔티티 관리
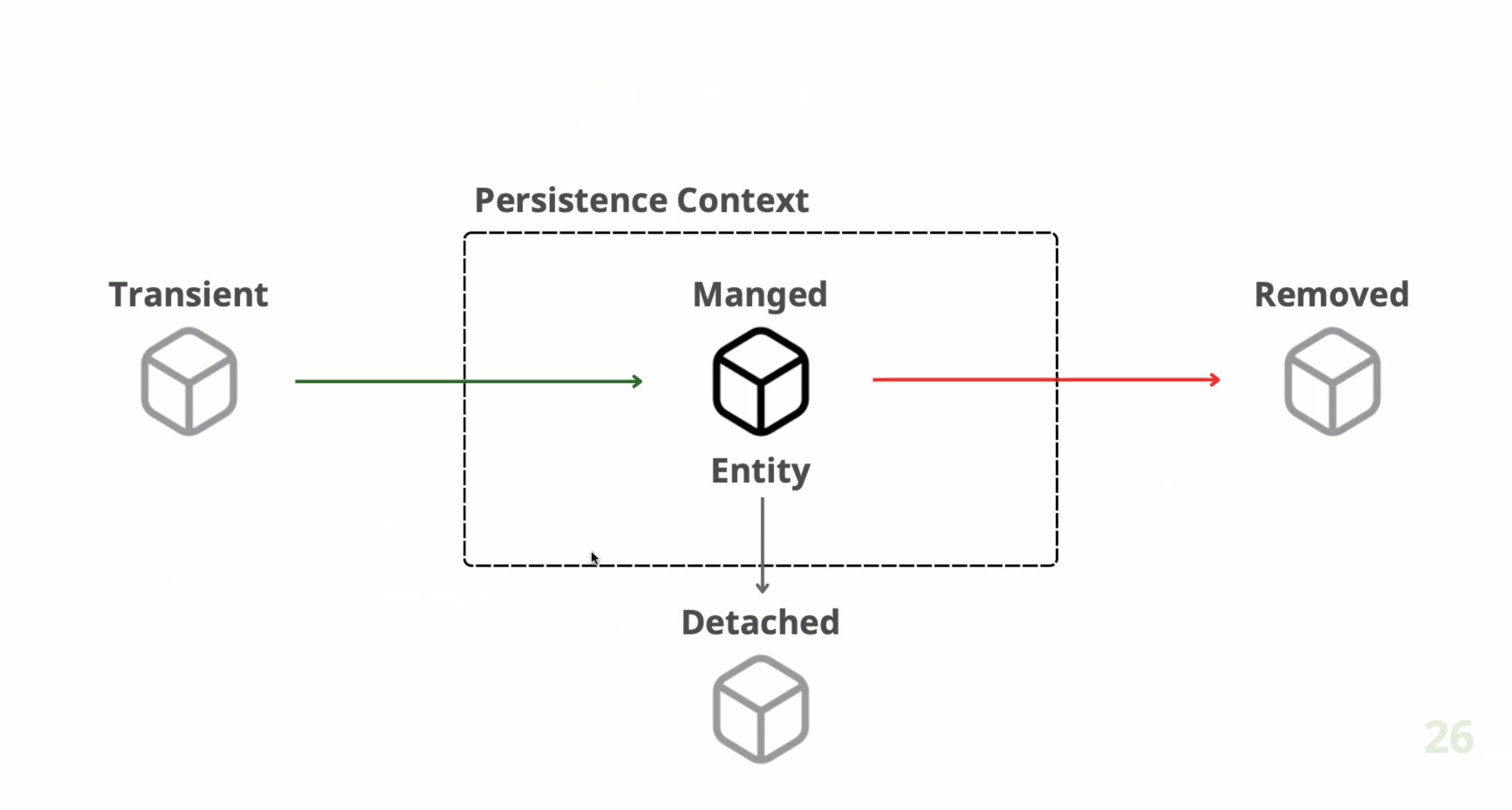
1️⃣ 비영속(새로운 상태) (new/transient)
비영속 상태의 엔티티 객체는 아직 영속성 컨텍스트에 등록되지 않은 상태이다. 그렇기 때문에 영속 컨테이너에 의해 관리되지 않을뿐더러 데이터베이스와도 연관이 없다.
엔티티가 비영속 상태에 있을 경우, 해당 인스턴스를 DB에 추가하기 위해서는 영속성 컨텍스트에 병합(merge)되거나 저장(persist)되어야 한다. 만일 병합이나 저장이 수행되면 데이터베이스의 식별자와 매핑되어 식별자 값을 가진다. (비영속 상태에서는 식별자 값을 가지지 않는다.)
2️⃣ 영속(관리) (managed)
영속 상태의 엔티티 객체는 영속성 컨텍스트에 의해 관리되고 있는 상태이다. 영속성 컨텍스트는 영속 상태의 엔티티의 변경 사항을 추적 (Dirty Checking)하며, 트랜잭션이 커밋될 때 변경 사항을 DB에 자동으로 반영한다.
3️⃣ 준영속(detached)
준영속 상태의 엔티티는 더 이상 영속성 컨텍스트에 의해 관리되지 않는 상태이다. 준영속 상태의 엔티티는 대개 해당 엔티티 인스턴스가 영속성 컨텍스트의 생명주기를 벗어나거나 명시적으로 분리된 경우에 해당한다.
준영속 상태의 엔티티 인스턴스는 필드의 변화가 일어난 후 커밋이 발생하더라도 영속성 컨텍스트의 관리를 받고 있지 않기 때문에 DB에 변경사항이 반영되지 않는다. (더티 체킹이 일어나지 않는다.) 준영속 상태의 엔티티는 영속 컨테이너에 들어온 적이 있으므로 반드시 식별자 값을 가진다.
4️⃣ 삭제(removed)
삭제 상태의 엔티티는 영속성 컨텍스트 뿐만 아니라 데이터베이스에서도 삭제를 하기 위한 상태이다. 삭제 상태에서 엔티티는 트랜잭션이 커밋될 때 실제 데이터베이스에서도 데이터가 삭제된다.
영속성 컨텍스트의 기능
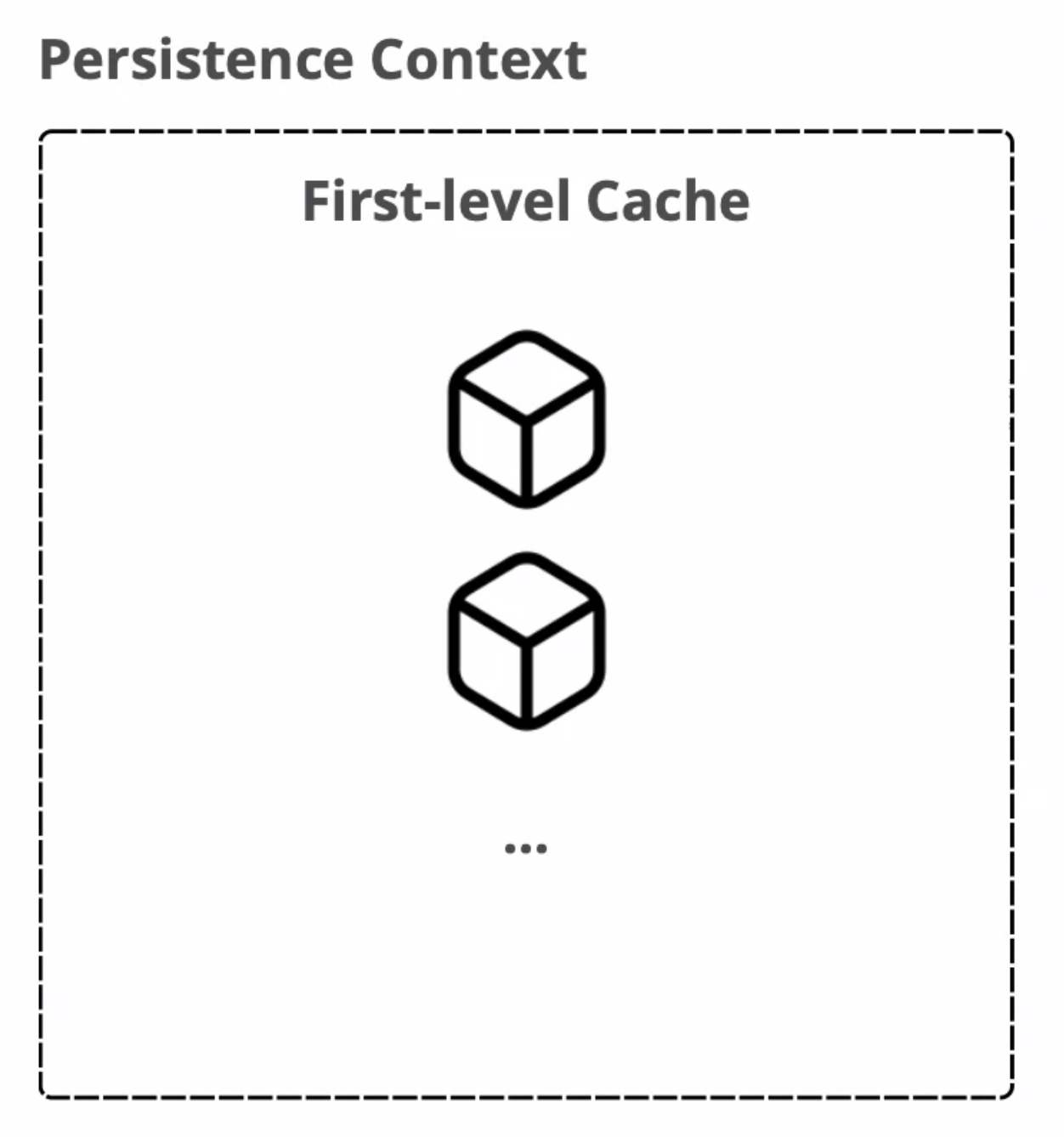
1️⃣ First-level Cache (1차 캐시)
1차 캐시는 트랜잭션이 시작하고 종료될 때까지 유효하다. 1차 캐시에 저장된 데이터는 아직 DB에 저장된 데이터가 아니다. Map 형태로 되어있고, key에는 식별자(기본키)값이 저장되어있고, value에는 Entity 클래스의 객체를 저장한다.
@Id
식별자로, 테이블의 기본키를 정의하는 필드이다.
1차 캐시의 장점
- 1차 캐시에 있는 데이터에 접근하게 되면, 다시 DB까지 가지 않아도 되고 1차 캐시에서 데이터에 접근할 수 있다.
- 같은 엔티티가 동일한 영속성 컨텍스트 내에서 여러 번 조회될 때, DB에 다시 접근하는 쿼리를 사용하지 않고 캐시된 엔티티를 반환함으로써 성능을 최적화한다.
2️⃣ Write-Behind Storage/Cache (쓰기 지연 저장소)
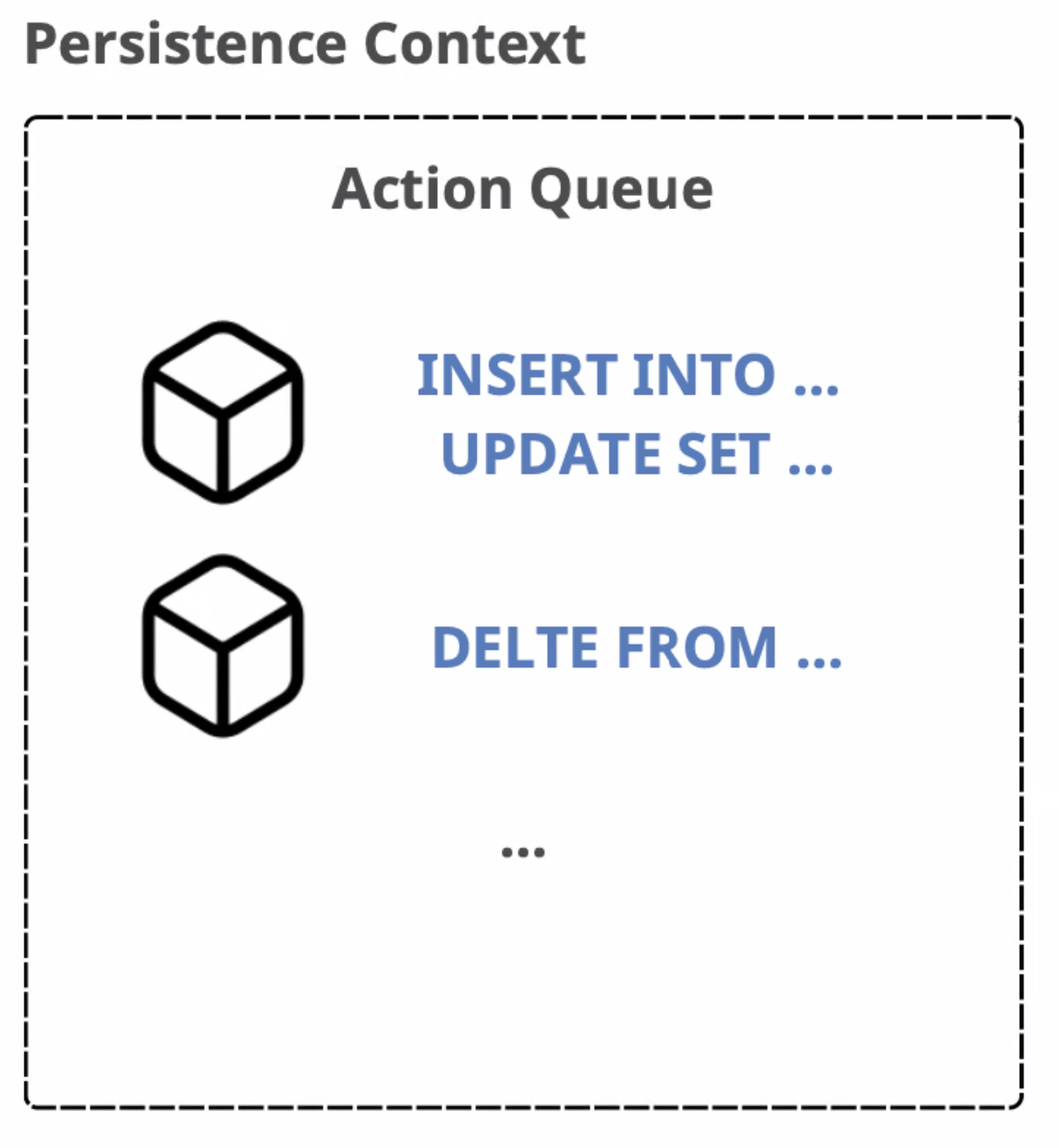
- 내부에 Action Queue가 존재한다.
Action Queue: Hibernate (JPA 구현체) 내부에서 관리하는 일종의 SQL 실행 작업 리스트 (나중에 실행할 SQL 작업들을 쌓아두는 대기열)
- SQL 명령을 모아서 일괄적으로 데이터베이스에 적용한다.
- JPA의 영속성 컨텍스트에서 변경된 Entity 상태를 메모리에 임시로 저장하는 구조를 의미한다.
- 트랜잭션이
COMMIT될 때, 그 쿼리들을 하나씩 DB에 날려 실제 데이터베이스에 반영된다.
=>Transactional Write Behind
3️⃣ Dirty Checking (변경 감지)
Dirty Checking는 영속성 컨텍스트에 의해 관리되고 있는 엔티티 객체의 상태 변화를 영속성 컨텍스트가 자동으로 감지하고, 이를 데이터베이스에 반영하는 것을 의미한다.
JPA에서 엔티티의 상태가 변경될 때마다 UPDATE SQL이 쓰기 지연 저장소에 저장된다면, 비효율적인 상황이 발생할 수 있다. 이러한 문제를 방지하기 위해 JPA가 더티 채킹을 제공한다.
트랜잭션이 COMMIT될 때, JPA는 현재 상태와 최초 상태를 비교하여 변경된 부분만을 포함하는 UPDATE SQL을 생성한다. 이 UPDATE SQL은 쓰기 지연 저장소에 저장된 후, 데이터베이스에 전송되면서 실제 상태가 업데이트된다.
더티 체킹은 기본적으로 엔티티 객체의 상태를 추적하기위해 스냅샷을 사용한다.
스냅샷
영속성 컨텍스트에 의해 관리되는 각 엔티티의 초기 상태를 복사한 것이다. 엔티티가 처음 영속성 컨텍스트에 의해 관리될 때, 해당 엔티티의 모든 필드 값들이 스냅샷으로서 저장된다.
이후, 엔티티 객체의 상태가 변경되면 영속성 컨텍스트는 가장 최신의 상태와 스냅샷을 비교하여 어떤 필드가 변경되었는지 검사한다. 이 때, 변경된 필드가 있으면 해당 엔티티는 변경(Dirty)상태로 간주된다.
flush()
JPA가 관리 중인 엔티티 변경사항을 DB에 반영하는 것이다.
즉, 쓰기 지연 저장소(Action Queue) 에 쌓아둔 쿼리들 (INSERT, UPDATE, DELETE)을 실제 DB에 SQL로 날려주는 작업이 flush()
em.persist(player); // SQL 안 날라감!
em.flush(); // 여기서 INSERT SQL 날라감!flush는 DB에 SQL을 보내긴 하지만, 트랜잭션을 커밋하지는 않는다. 그래서 rollback이 가능하며, SQL 날렸어도 커밋 전이면 취소할 수 있다.
매핑
| 구분 | 어노테이션 |
|---|---|
| 객체와 테이블 매핑 | @Entity, @Table |
| 기본 키 매핑 | @Id |
| 필드 - 컬럼 매핑 | @Column |
| 연관관계 매핑 | @ManyToOne, @OneToMany, @ManyToMany, @OneToOne |
@Entity
엔티티는 @Entity을 통해 선언 가능하다.
@Entity
public class Student {
...
}-
@Entity는 추가된 클래스가 데이터베이스의 테이블에 매핑될 객체임을 알리는 역할을 수행한다.
-
기본 생성자가 반드시 존재해야 한다.
-
접근제어자는
public,protected만 가능하다. -
final,enum,interface,inner클래스는 지원하지 않는다. -
데이터베이스에 저장될 필드가 있다면 필드에도
final을 붙일 수 없다.
@Table
해당 엔티티 객체가 데이터베이스에서 어떤 테이블에 매핑되어야 하는지를 지정할 수 있으며, 만일 @Table을 추가하지 않는다면, 클래스의 이름을 기반으로 테이블 이름을 유추하여 데이터베이스의 테이블과의 매핑을 수행한다.
<article> 테이블
| 번호 | 제목 |
|---|---|
| 1 | 첫 번째 공지사항 |
| 2 | Spring은 즐거워요 |
@Entity
@Table(name="article")
public class Post {
...
}Post 클래스로 article 테이블을 찾아야 하기 때문에 @Table로 article 테이블을 찾아야 한다고 알려줄 수 있다.
@Id
엔티티 클래스의 기본키를 설정할 때 쓰는 어노테이션이다.
@Entity
@Table(name="article")
public class Post {
@Id
private Long id;
}auto_increment와 상등한GeneratedValue를 통해 자동으로 생성할 수 있다. (IDENTITY 전략)- 수동으로 값을 설정할 수도 있다.
🔎 생성전략 (Generation Strategy)
1️⃣ 식별자 전략 (jakarta.persistence.GenerationType.IDENTITY)
식별자 전략은 데이터베이스의 자동 증가 컬럼을 사용하여 기본키 값을 생성하는 전략이다.
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;MySQL, MariaDB, SQLServer와 같은 auto_increment가 있는 DBMS에서 주로 사용되며, 기본키 값을 데이터베이스에서 삽입 후 반환받아 사용하는 방식으로서 기본키의 생성이 데이터베이스에 전적으로 의존되는 방법이다.
2️⃣ 시퀀스 전략 (jakarta.persistence.GenerationType.SEQUENCE)
시퀀스 전략은 기본키 값을 데이터베이스 시퀀스 객체를 사용하여 자동으로 생성하는 전략이다. @SequenceGenerator를 통해 시퀀스의 이름과 시작 값 등을 자세히 정의하는 것도 가능하다.
// sequence를 찾아주거나 생성해줄 수 있도록 sequence 명세를 적어준다.
@SequenceGenerator(
name="CUSTOM_SEQ_GENERATOR", // JPA 내부에서 쓸 시퀀스 생성기 이름
sequenceName="POST_SEQ", // 실제 DB에 있는 시퀀스 이름
initialValue=1,allocationSize=1
)
@GeneratedValue(strategy=GenerationType.SEQUENCE
, generator="CUSTOM_SEQ_GENERATOR")PostgreSQL, OracleDB와 같은 RDBMS에서 주로 사용되며, 데이터베이스가 제공하는 시퀀스 기능을 통해 엔티티의 기본키 값을 생성한다.
3️⃣ 테이블 전략 (jakarta.persistence.GenerationType.TABLE)
테이블 전략은 기본키 값을 생성하기 위해 데이터베이스의 특정 테이블을 사용하는 전략이다. 시퀀스가 없지만 시퀀스를 사용하고 싶을 때 사용하는 방법이다.
<cst_sequence> table
| SEQUENCE_NAME | NEXT_VAL |
|---|---|
| MEMBER_SEQ | 1 |
@TableGenerator(
name="MEMBER_SEQ_GENERATOR",
table="CST_SEQUENCE"
pkColumnName="MEMBER_SEQ", allocationSize = 1
)
public class Member {
@Id
@GeneratedValue(strategy=GenerationType.TABLE
, generator="MEMBER_SEQ_GENERATOR")
private Long id;@TableGenerator를 통하여 기본키 값을 생성할 테이블과 관련된 설정을 직접 정의할 수 있다.
4️⃣ 자동 증가 전략 (jakarta.persistence.GenerationType.AUTO)
자동 증가 전략은 데이터베이스 제품에 따라 기본키가 자동으로 생성되는 전략이다. Hibernate는 이 전략을 사용하여 데이터베이스의 기본키 생성 규칙을 자동으로 결정하며, 데이터베이스가 기본키를 생성하는 방식을 따르게 된다.
@GeneratedValue(strategy=GenerationType.AUTO)기본키 생성 방식에 대해 고려할 필요가 전혀 없으며, 데이터베이스의 기본키 자동 증가 기능을 활용하여 새로운 레코드가 삽입될 때마다 고유한 값을 생성한다. 그러나 가능하면 명시적으로 표현하는 것이 좋기 때문에 고려하여 사용하는 것이 권장된다.
@Column
클래스의 필드가 매핑될 데이터베이스 컬럼의 이름을 명시적으로 지정할 수 있도록 하는 어노테이션이다. 기본적으로 클래스의 필드 이름을 기반으로 데이터베이스의 테이블 컬럼과 매핑을 수행한다. camel case, snake case 같은 차이는 JPA가 알아서 바꿔준다.
@Column(nullable = false, length = 50)
private String name;테이블 컬럼의 데이터 타입과 제약 조건을 정의할 때에도 사용된다. 다양한 속성을 통해 해당 필드가 데이터베이스에서 어떠한 제약조건이 추가되어있는지 힌팅으로 제공할 수 있다.
속성
insertable: true라면, 데이터가 저장되면 필드에 있는 값을 같이 저장해달라는 것이고, false라면, 읽기 전용 필드가 되어버린다.updatable: true -> 수정한다 / false -> 변경 감지가 안된다. 하지만, 값은 insert할 수 있다. 즉, 처음 쓴 이후로는 읽기 전용이 된다.nullable: 이 컬럼에 NULL이 들어갈 수 있는지 없는지 알 수 있다. (기본값 : true)NOT NULL의 유효성 검사까지 된다고 생각하지만, 그렇지 않다. DDL을 구성할 때만 적용된다.- 유효성 검사는 Spring Validation에서 따로 진행한다.
unique: 테이블의UNIQUEconstraint랑 같다. 겹치는 값이 들어갈 수 없다.- 테이블에 있는
UNIQUE는 두 개 이상의 컬럼에 UNIQUE 제약조건이 필요할 때 붙인다. - 컬럼에 붙일 때는, 특정 컬럼에만 적용하고 싶을 때 붙인다.
- 테이블에 있는
columnDefinition: 위의 속성 외에 컬럼에 대한 정보를 주고 싶을 때 사용할 수 있다. DDL auto를 쓸 때 객체의 필드 자료형을 보고 DB 자료형을 잡아주는데, 자료형을 정해주고 싶을 때 사용할 수 있다. (예를 들어, 객체에서 문자열은 다String형, 하지만 DB에서는 다VARCHAR만 쓴다.)
@Enumerated
필드에 붙이는 어노테이션으로, 자바의 enum타입과 매핑할 때 사용한다.
EnumType.ORDINAL
public enum Role {
USER, ADMIN
}
@Entity
public class Member {
@Enumberated(EnumType.ORDINAL)
private Role roleType;
}<member> 테이블
| 번호 | 회원등급 |
|---|---|
| 1 | 0 |
| 2 | 1 |
특징
- DB에는 enum의 순서(index) 가 저장되기 때문에 저장공간이 작다.
- 하지만, ❌ enum 순서 바뀌면 대참사 발생한다.
EnumType.STRING
@Entity
public class Member {
@Enumberated(EnumType.STRING)
private Role roleType;
}<member> 테이블
| 번호 | 회원등급 |
|---|---|
| 1 | USER |
| 2 | ADMIN |
특징
- DB에는 enum의 이름(문자열) 이 저장된다.
- enum 순서 바뀌어도 안전하다.
- ❌ 문자열이 DB에 저장되니 저장 공간 조금 더 크다.
- 오타가 있거나 enum 이름을 바꾸면 문제가 발생한다.
@Transient
데이터베이스와 따로 매핑을 수행하지는 않고, 임시 컬럼으로 사용할 때 필드에 붙이는 어노테이션이다.
DB에는 저장하지 않지만, 자바 객체 안에서는 쓰고 싶은 필드에 붙이는 어노테이션이다.
- 계산된 값을 담고 싶을 때, 뷰 렌더링용 데이터 따로 들고 있을 때, 폼 입력값을 임시로 담아둘 때 등과 같은 상황에 사용할 수 있다.
연관 관계
연관관계란 엔티티와 엔티티 객체간의 맺고 있는 관계(Relationship)를 의미한다. 데이터베이스에서의 테이블간의 관계(외래키와 같은)와 상등한 개념이다.
방향 (Direction)
데이터베이스에서는 참조할 때 방향이 중요하지 않다. 하지만, 객체에서는 방향성이 중요하다.
예를 들어, 데이터베이스에서는 JOIN 할 때 선수 테이블 기준으로 삼성팀을 찾을 때, 팀 테이블 기준으로 삼성팀이 선수를 찾을 때 방향이 중요하지 않다.
하지만, 객체 입장으로 봤을 때는 선수 객체 입장에서는 Team을 필드로 가지고 있기 때문에 쉽게 찾을 수 있지만, 팀 객체 입장에서는 선수를 찾을 방법이 없다. 그렇기 때문에, 객체 입장에서는 방향이 중요하다 !
다중성 (Multiplicity)
객체나 테이블 간 관계에서 개수(1:1, 1:N, N:1, N:M) 를 의미한다.
| 관계 | 예시 설명 |
|---|---|
| 1:1 | 주민등록증 ↔ 사람 |
| 1:N | 팀 1개 ↔ 선수 여러 명 |
| N:1 | 여러 선수 ↔ 팀 1개 |
| N:M | 학생 여러 명 ↔ 수업 여러 개 (다대다 매핑 시 연결 테이블 필요) |
DB 설계뿐 아니라 엔티티 설계에서도 반드시 다중성을 고려해야 한다.
연관관계 주인
연관관계를 맺고 있는 두 엔티티 간의 연관 관계에서 어느 엔티티가 외래 키를 관리하고, 데이터베이스에 그 관계를 저장할 것인지를 결정하는 주체이다.
JPA에서 외래키를 실제로 관리하는 쪽
즉, DB에 어떤 값이 저장될지를 결정하는 쪽
- 항상 외래키를 가지고 있는 엔티티가 주인이다.
- 주인이 아닌 쪽은 mappedBy를 사용해서 읽기 전용으로 관계를 매핑한다.
- JPA에서는 @JoinColumn 붙는 쪽이 주인이다.
✅ 1:N 관계에서는?
N쪽이 외래키를 가짐 → N쪽이 주인!
그래서 @ManyToOne 쪽이 항상 주인!
실습
JDBC를 이용한 DB 연결
MySQL 연결 설정
public static class MysqlDbConnectionConstant {
public static final String URL = "jdbc:mysql://localhost:3306/{데이터베이스이름}";
public static final String USERNAME = "{사용자이름}";
public static final String PASSWORD = "{사용자비밀번호}";
}H2 연결 설정
public static class H2DbConnectionConstant {
public static final String URL = "jdbc:h2:./{데이터베이스이름}";
public static final String USERNAME = "sa";
public static final String PASSWORD = "";
}- 데이터베이스를 만들기 위해
{데이터베이스이름}.mv.db파일을 미리 생성해도 되고, 데이터베이스가 없을 경우 알아서 DB 파일을 만들어준다. - 이 db파일은 git에 올리고 싶지 않다 ! ->
.gitignore파일에{db파일이름}.mv.db를 입력해둔다.
연결
public static Connection getConnection() {
try {
Connection connection = DriverManager.getConnection(
MysqlDbConnectionConstant.URL
, MysqlDbConnectionConstant.USERNAME
, MysqlDbConnectionConstant.PASSWORD);
// Connection connection = DriverManager.getConnection(
// H2DbConnectionConstant.URL
// ,H2DbConnectionConstant.USERNAME
// ,H2DbConnectionConstant.PASSWORD);
log.info("Connection = {}", connection);
return connection;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}SQL 실행
@Test
@DisplayName("INSERT INTO TEST")
void insert_into_test() throws Exception {
String sql = "INSERT INTO member (username, password) VALUES ('%s', '%s')".formatted("user1", "user1");
Connection conn = ConnectionUtil.getConnection();
Statement stmt = conn.createStatement();
int resultRows = stmt.executeUpdate(sql); // 몇 줄이 반영되었는지 반환해준다.
log.info("resultRows = {}", resultRows);
stmt.close();
conn.close();
}String에 SQL문을 입력한다.- 마지막으로 생성한 것부터
.close()해줘야 한다. (지금의 경우,stmt->conn)
✅ Statement란?
Statement는 SQL 문을 DB에 보내서 실행하는 역할을 하는 객체이다.
Connection 객체에서 .createStatement() 메서드로 생성한다.
이걸로 SQL 쿼리를 실행할 수 있고, 실행 결과도 받아올 수 있다.
✅ executeUpdate() vs executeQuery()
| 메서드 | 사용 용도 | 반환값 | 예시 |
|---|---|---|---|
executeUpdate() | 데이터 변경용 SQL (INSERT, UPDATE, DELETE, DDL 등) | 반영된 행 수 (int) | stmt.executeUpdate("INSERT INTO ...") |
executeQuery() | 데이터 조회용 SQL (SELECT) | 결과 집합 (ResultSet) | stmt.executeQuery("SELECT * FROM ...") |
느낀 점
왜 벌써 월요일이지..? 주말이 어디갔을까 ㅠ 어제 일찍 잤는데 요새 자다가 계속 깨서 많이 잤지만 개운하지 않았다. 슬프군.. 오늘 내가 어려워하는 게 나왔다. 엔티티 짤 때마다 연관관계 설정하는 게 어려웠는데, 이번 기회에 감 제대로 잡아야 할 듯.. 이론 이해는 했는데.. 실습은 항상 다르니까 ㅎ 실습하면서 더 제대로 이해해야겠다. 오늘은 수업 들으면서 놓치는 것들이 있었다. 내일은 더 집중해서 들을 수 있도록 해야겠다 ..
실습하면서 MySQL 아이디 비번을 까먹어서 혼자 DB 연결 못하고 헤맸다. 그래서 이 때 좀 놓쳤는데.. 뭘까 뭘까 이러면서 DBeaver도 보고 했는데 여러 username 중에서 happy 있길래.. 혹시나 해서 강사님이랑 똑같은 username과 비번을 입력하니 되더라는.. ㅎㅎㅎㅎ 그래서 마지막에 호다다닥 따라잡았다.
아 그리고 오늘 수업 듣는 자세가 너무 안 좋았는지 (모니터에 얼굴 박을 뻔 막이래) 머리가 또 너무 아프다 .. whyrano 🐢
내일은 더 빡집중해서 바른 자세로 ! 놓치지말고 수업 듣자 !! 파이팅 !!
