📒 배열(Array)
- 같은 타입의 변수들로 이루어진 유한 집합
- 배열을 구성하는 각각의 값을 배열 요소(element)라고 하며, 배열에서의 위치를 가리키는 숫자는 인덱스(index)라고 함
- 파이썬에서는 리스트 타입이 배열 기능을 제공
- 같은 종류의 데이터를 효율적으로 관리해야 하는 경우에 사용
- 같은 종류의 데이터를 순차적으로 저장
✅ 배열의 장단점
- 장점
- 빠른 접근이 가능
- 단점
- 미리 최대 길이를 지정해야 함
- 추가/삭제가 쉽지 않음
✅ 파이썬과 배열
1차원 배열
# 1차원 배열 : 리스트로 구현 시
data = [1,2,3,4,5,6,7,8]
print(data) # [1, 2, 3, 4, 5, 6, 7, 8]2차원 배열
# 2차원 배열 : 리스트로 구현 시
data = [[1,2,3],[4,5,6],[7,8,9]]
print(data) # [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(data[0]) # [1, 2, 3]
print(data[1]) # [4, 5, 6]
print(data[2]) # [7, 8, 9]
print(data[0][0]) # 1
print(data[0][1]) # 2
print(data[0][2]) # 3✅ 파이썬 배열 연산자
- A.append(obj)
배열 맨 뒤 원소로 obj를 추가
None Type - A+B
배열 A와 B를 연결하여 새로운 배열을 리턴
단, A와 B가 동일한 list 또는 tuple 타입이어야 함
+= 연산자도 사용 가능 - A*i
배열 A를 i 회 반복하여 새로운 배열을 리턴 - A.extend(list)
list로 입력한 리스트를 배열 맨 뒤에 붙임
파라미터는 리스트만 허용
None Type - A.insert(index,obj)
index로 지정한 위치에 새로운 원소 obj를 삽입
None Type - del A[index]
index로 지정한 위치의 원소를 삭제하고 나머지를 좌측으로 이동
del A[i:j]와 같이 범위를 지정해서 삭제할 수 있음 - A.pop(index)
index로 지정한 위치의 원소를 삭제하며 리턴하고, 나머지를 좌측으로 이동
A = [1,2,3]
B = [9,8,7]
print(A+B) # [1, 2, 3, 9, 8, 7]
print(A*3) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
print(A.pop(0)) # 1
A.append(15) # None Type
print(A) # [2, 3, 15]
A.extend([4,5,6]) # None Type
print(A) # [2, 3, 15, 4, 5, 6]
A.insert(3, 300) # None Type
print(A) # [2, 3, 15, 300, 4, 5, 6]None Type? => 값이 존재하지 않음(None Object)을 나타내는 Type. 즉, 배열 자체에 연산을 수행하지만 리턴 값이 없는 함수를 말함
- A.remove(obj)
배열에서 obj로 지정한 내용과 동일한 첫 항목을 찾아 삭제
None Type - A.reverse()
배열의 순서를 뒤집음
A = A[::-1]와 동일한 효과
None Type - A.sort()
배열을 오름차순으로 정렬
내림차순 정렬은sort(reverse=True)로 수행
None Type - A.index(obj)
배열에서 obj로 지정한 내용과 동일한 첫 항목을 찾아 그 인덱스를 리턴
찾지 못하면 오류 출력 - A.count(obj)
배열에서 obj로 지정한 내용과 동일한 항목을 찾아 그 개수를 리턴 - len(A)
배열의 항목 개수 리턴 - range(i,j)
i부터 j까지의 정수 등을 list 타입으로 리턴
range(j)는 range(0,j)의 의미로 사용 - A[i:j:k]
배열의 i 위치부터 j 위치까지 k 만큼씩 움직이며 각 원소를 추출하여 새로운 배열을 리턴
k가 음수면 역방향 진행을 의미 - ".join(A)
배열 A의 모든 원소를 하나의 스트링으로 합쳐서 리턴
모든 원소가 스트링일 때만 가능하고 다른 타입이 섞여있으면 오류 발생
join 앞의 스트링이 연결자 역할을 함
A = [1,2,3,0,3,4,7,5,5,10]
print(A.index(10)) # 9
print(A.count(5)) # 2
print(len(A)) # 10
print(A[0:9:2]) # [1, 3, 3, 7, 5]
A.remove(2)
print(A) # [1, 3, 0, 3, 4, 7, 5, 5, 10]
A.reverse()
print(A) # [10, 5, 5, 7, 4, 3, 0, 3, 1]
A.sort()
print(A) # [0, 1, 3, 3, 4, 5, 5, 7, 10]- a.split('sep')
스트링 a를 sep 기준으로 분리한 리스트를 리턴
None Type - list(a), tuple(a)
스트링 a에 있는 모든 문자를 분리한 list 또는 tuple을 리턴
list(), tuple()는 빈 배열 리턴 - obj in A
obj로 지정한 항목이 배열에 존재하면 True 리턴 - sum(A)
배열 A의 모든 항목을 더한 결과를 리턴
단, 모든 항목이 숫자 항목이어야 함 - max(A), min(A)
배열 중에서 가장 큰, 가장 작은 항목을 리턴 - all(A)
배열 내 모든 원소가 True이면 True리턴 - any(A)
배열 A가 빈 배열이 아니면 True - divmod(a,b)
a를 b로 나눈 몫과 나머지로 구성된 tuple을 리턴
a = "Lorem ipsum dolor sit amet, consectetur adipiscing elit"
A = [0, 1,3,4,5,2,4,3]
print(a.split(" ")) # ['Lorem', 'ipsum', 'dolor', 'sit', 'amet,', 'consectetur', 'adipiscing', 'elit']
print(list(a)) # ['L', 'o', 'r', 'e', 'm', ... , 'g', ' ', 'e', 'l', 'i', 't']
print(5 in A) # True
print(sum(A)) # 22
print(max(A)) # 5
print(min(A)) # 1
print(all(A)) # False
print(any(A)) # True
print(divmod(20,3)) # (6, 2)✅ 파이썬 리스트 시간 복잡도

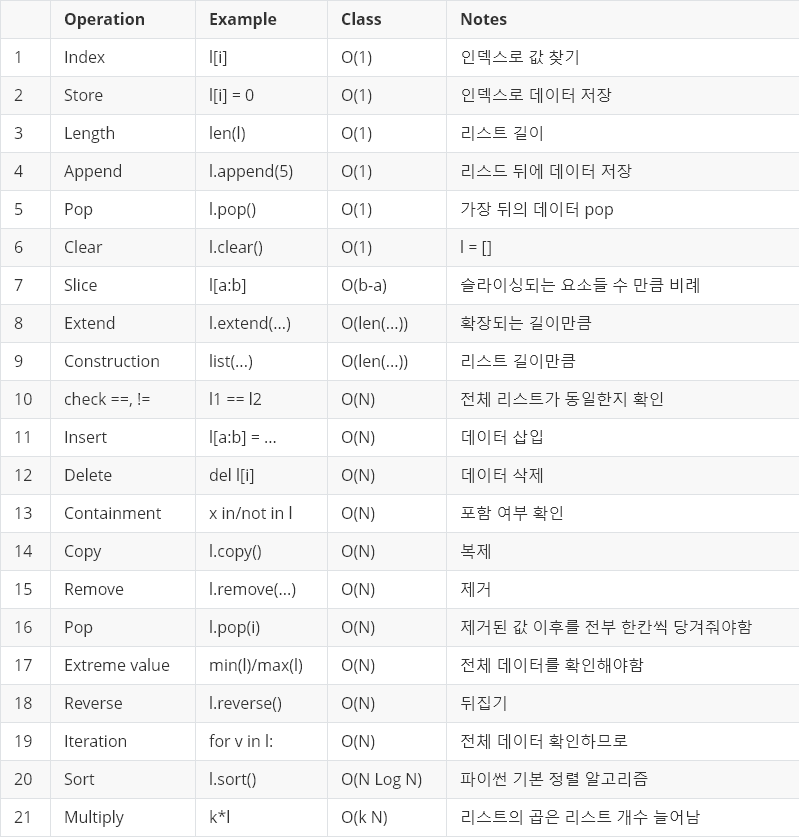
출처 : https://debugdaldal.tistory.com/158
✅ 파이썬 배열을 이용한 프로그래밍 연습
빈도수 출력하기
# 다음 단어 더미 데이터셋에서 's'가 몇 번 나왔는지 빈도수 출력
dataset = ['Lorem', 'ipsum', 'dolor', 'sit', 'amet,', 'consectetur',
'adipiscing', 'elit.', 'Sed', 'pretium', 'vestibulum', 'massa,',
'ac', 'pharetra', 'nisi', 'egestas', 'at.', 'Ut', 'et', 'est',
'interdum,', 'porttitor', 'metus', 'sit', 'amet,', 'maximus',
'enim.', 'Fusce', 'egestas', 'eros', 'blandit', 'convallis',
'ultrices.', 'Nulla', 'purus', 'lorem,', 'porttitor', 'id', 'auctor',
'id,', 'vestibulum', 'ut', 'metus.', 'Morbi', 'blandit', 'ultricies',
'elit', 'vel', 'fringilla.', 'Proin', 'imperdiet', 'vestibulum',
'sem,', 'id', 'vehicula', 'lorem', 'consectetur', 'sit', 'amet.',
'Ut', 'vitae', 'mauris', 'a', 'urna', 'tempus', 'imperdiet',
'elementum', 'ullamcorper', 'metus.', 'Praesent', 'non', 'mi', 'augue.',
'Curabitur', 'sed', 'venenatis', 'nibh,', 'vitae', 'dapibus', 'sem.']
# 's'의 빈도수를 나타내는 s_count
s_count = 0
# 반복가능한 객체(iterable 객체)의 element(data)를 반복문을 통해 리턴
for data in dataset:
# 각 element(data)의 길이만큼 반복문 실행
for index in range(len(data)):
# 스펠링을 하나씩 비교하며, 's'와 일치하면 s_count 1 증가
if data[index] == 's':
s_count += 1
print(s_count) # 36반복 가능한 객체(iterable)는 list, dictionary, set, string, tuple, range 등이 있다
가장 긴 단어 출력하기
# 공백을 포함한 한 문장을 입력받아서 가장 긴 단어를 출력
# 가장 긴 단어가 여러 개인 경우 모두 출력
# 이 문제에서의 단어란? 공백으로 분리하는 문자열
sentence = "Aliquam accumsan sollicitudin massa non vehicula nibh."
# 문장을 공백을 기준으로 나누어 배열에 넣어준다
arr = sentence.split(" ")
print(arr) # ['Aliquam', 'accumsan', 'sollicitudin', 'massa', 'non', 'vehicula', 'nibh.']
# 단어의 최대 길이를 0으로 초기화 시켜줌
maxLen = 0
result = []
# arr에 있는 모든 data를 반복
for data in arr:
# 만약 현재 단어의 길이가 maxLen보다 크다면
if(len(data) > maxLen):
# maxLen을 현재 단어 길이로 바꿔줌
maxLen = len(data)
print(maxLen) # 12
# 자료형 크기의 range를 이용하면 index로 접근할 수 있음
for index in range(len(arr)):
# arr에서 index번째 단어 길이가 maxLen과 같다면
if(len(arr[index]) == maxLen):
# result에 현재 단어(arr[index])를 추가시켜준다
result.append(arr[index])
print(result) # ['sollicitudin']append는 리스트 맨 마지막에 x 를 추가하는 함수
insert는 a 번째 위치에 b를 삽입하는 함수
입력값 1로 만드는 과정 출력하기
# 정수를 입력으로 받아,
# 짝수이면 2 로 나누고 , 홀수이면 3배 해서 1 을 더함
# 1이 될 때 까지의 과정을 반복한 배열을 출력하는 프로그램 작성
num = 30 # num에 30이라는 숫자를 넣어준다
arr = [] # 1이 될 때 까지의 과정을 arr에 넣을 것
arr.append(num) # 처음 num을 arr에 append 해 준다
print(arr) # [30]
# num가 1이 될 때 까지 반복
while (num != 1):
# num가 짝수이면
if(num % 2 == 0):
# num를 2로 나누고
num = num / 2
# num를 arr에 넣어준다
arr.append(int(num))
# num가 홀수이면
elif(num % 2 != 0):
# num를 3배한 후, 1을 더하고
num = num * 3 + 1
# num를 arr에 넣어준다
arr.append(int(num))
print(arr) # [30, 15, 46, 23, 70, 35, 106, 53, 160, 80, 40, 20, 10, 5, 16, 8, 4, 2, 1]int()를 이용해서 숫자나 문자열을 정수형 (Integer)으로 변환할 수 있음
배열에서 중복 값 찾기
# 숫자 배열문제
# 숫자들의 배열이 주어짐 이 배열은 길이 n을 가지며, 1부터 n-1까지의 숫자로 이루어져있음
# 모든 숫자가 배열에 단 한번씩만 나타남, 딱 하나의 수가 배열에 두번 등장
# 중복되는 숫자를 찾아내기
arr = [1,5,2,4,5,6,3]
# sort()함수를 통해 숫자의 배열을 정렬해 줌
arr.sort()
print(arr) # [1, 2, 3, 4, 5, 5, 6]
# 배열을 순차적으로 반복
for i in range(len(arr) -1):
# 현재값과 다음값이 같다면 리턴
if(arr[i] == arr[i+1]):
return arr[i] # 5👩💻 참고 링크
- https://www.fun-coding.org/Chapter04-array.html
- https://chancoding.tistory.com/43
- https://wikidocs.net/14
- http://www.tcpschool.com/c/c_array_oneDimensional
💕 피드백 환영 💕

더 높이