Docker Container로 띄운 서비스를 어떻게 관리해야 할까?
Traffic에 따라 Scaling up, down을 어떻게 자동화할까?
Container의 상태를 어떻게 추적, 관리할까?
...Docker Container의 상태를 관리하는 도구가 여러가지가 있다.
Docker swarm: 간단한 설정, 다양한 기능 제공 X
MESOS: 어려운 설정, 다양한 기능 제공 O
Kubernetes: 어려운 설정, 다양한 기능 제공 O그 중 Kubernetes에 대해 알아보도록 하겠다.
Kubernetes Basics
Kubernetes(이하 k8s)를 사용함으로써 다양한 이점을 얻을 수 있다.
- HW Failure가 SW Failure에 영향을 주지 않도록 할 수 있다.
- Load Balancing
- Container들을 체계적으로 관리할 수 있다.
- ...
k8s Architecture
k8s의 주요 컨셉을 살펴보자
Node
- k8s가 설치된 물리적(또는 가상) 머신
- k8s에 의해 launch된 container들이 위치하는 곳 ==
Worker Node - worker node들을 관리하는 node ==
master node (아래에서 다룸)
만약 한 개의 Node만 운영하면 어떻게 될까? Node에 장애가 발생하면 서비스가 죽을것이다.
그렇기 때문에 Node는 2개 이상 유지해야 한다.
Cluster
- 여러 Node들로 구성된 일종의 Group
Cluster에 속한 Node들 중 하나가 죽더라도, 다른 Node들은 여전히 살아있으므로 서비스는 계속 작동할 것이다.
그리고 Cluster에 여러 Node를 유지함으로써 Load balancing을 할 수 있을 것이다.
Master Node
- Cluster와, Cluster에 속한 Node들을 관리, 모니터링하는 Node
- Master Node도 Cluster에 속한다.
- Cluster에 속한 다른 Worker Node의 상태를 모니터링하고, Failure가 발생한 Node의 workload를 다른 node로 옮긴다 ==
Orchestration
k8s Components
- node에 k8s를 설치한다 == k8s를 구성하는 여러 service들을 설치한다.
API Server
- k8s 기능을 사용하기위한 인터페이스 역할
- k8s 기능을 사용 == 클러스터와의 interaction
etcd
- 클러스터를 관리하기 위해 필요한 모든 데이터를 저장하기 위한 distributed reliable key value store
- 클러스터에 존재하는 node 데이터를 ectd에 분산 방식으로 저장한다.
- etcd는 Master node들 사이에서 발생하느 conflict를 예방하기 위한 Lock을 지원한다.
kubelet
- 클러스터에 속한 각 node에서 작동하는 agent
- agent
- 컨테이너가 node에서 정상적으로 작동하도록 함
container runtime
- container를 구동시키는 underlying SW
- Docker, rkt, cri-o 등이 SW에 해당
controller
- k8s의 orchestration의 핵심
- node, container, end point의 정상 작동 여부를 확인 -> 새로운 컨테이너 생성 여부를 결정
scheduler
- 여러 node들 사이의 work, container를 분산하는 역할
- 새로 생성된 컨테이너를 찾으면 특정 node에 할당함
기본 동작 원리
- Worker Node에는
- 컨테이너를 작동시키기 위한
Container Runtime(Ex. Docker)을 가지고 있음 - Master Node와 통신하기 위한
Kubelet Agent를 가지고 있음
- 컨테이너를 작동시키기 위한
- Master Node에는
- Master Node가 Master로서의 기능을 지원하기 위한
Kube API Server를 가지고 있음- Worker Node의 kubelet Agent와, Master Node의 kube API Server가 서로 통신하는 것
- Worker Node의 상태를 Master Node로 전송
- Master Node로 부터 명령을 받아 Worker Node를 조작
- Worker Node의 kubelet Agent와, Master Node의 kube API Server가 서로 통신하는 것
- Node들의 정보를 저장, 관리하기 위한
etcd를 가지고 있음 - Node를 관리하기 위한
Controller,Scheduler를 가지고 있음
- Master Node가 Master로서의 기능을 지원하기 위한
Pods
k8s는 컨테이너를 workder node에 직접적으로 배포하지 않는다.
대신, container를 pod라 불리는 k8s object 단위로 encapsulate한뒤 배포한다.
Pod란
- single instance of an application
- smallest object that can be created in k8s

- 파이썬으로 만든 서버를 Container로 만든 뒤, 이를
Pod로 캡슐화한뒤 Worker Node에 배포한다. - 서버를 Scale up해야 하는 상황이라면, 한 Pod에 동일한 Container를 추가하지 않는다.
- 대신, 동일한 구성의 Pod를 배포하는 단위로 Scaling을 진행한다.
- Pod를 배포하려는 Node의 capacity를 초과한다면, 새로운 Node를 생성한 뒤 Pod를 배포한다.
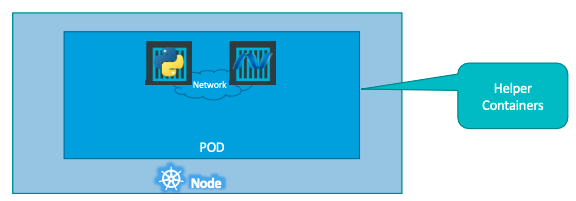
3. 파이썬 서버가 아닌, 다른 서비스 Container는 동일한 Pod에 배포할 수 있다.
- 같은 Pod에 배포된 Container들은 저장공간, 네트워크 등의 자원을 공유한다.
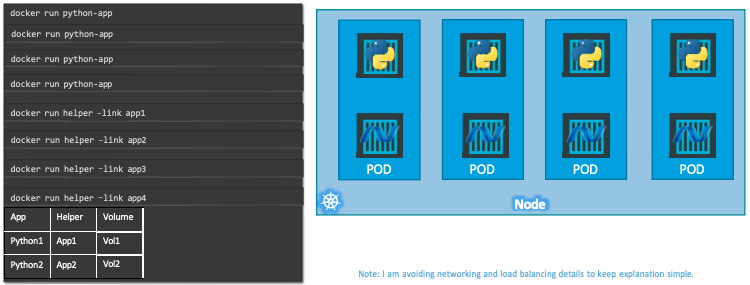
파이썬 서버 컨테이너를 일일이 배포하는 방식으로 서비스를 운영해도 문제는 없다.
그런데, 서버 작동을 위한 helper container가 추가되거나, Scaling을 위해 서버 Container가 추가되는 경우에는 관리가 복잡해진다.
- 서버 container - helper container 간 자원 매핑 등
- 서버 container 제거할 때, 연관된 helper container도 같이 제거
- ...
k8s는 Pod Object 단위로 Container들을 관리하도록하여, 위의 불편함을 개선한다.
kubectl로 pod 다루기
# 단순히 Docker container run 하기
docker run container_name
# pod를 생성하여 Docker Container run 하기
kubectl run pod-name --image IMAGE_NAME
# Pods 목록 확인
kubectl get pods
# Pods 목록 확인 + wide
kubectl get pods -o wide
# Pods 디테일 확인
kubectl describe pod pod-name
# Pods 제거
kubectl delete pod pod-name
# cluster 목록 확인
kubectl config get-clusters
# Pod 접속
kubectl -it exec POD_NAME -n NAMESPACE_NAME -- /bin/bash기본적으로 Docker Image는 Docker hub (public image repository)에서 가져온다.
설정을 통해 이미지를 불러올 주소를 지정할 수 있다.
Pods with YAML based Configuration
k8s은 Pod를 비롯한 Object를 생성하기 위해 YAML을 사용할 수 있다.
기본적으로 4개의 Required Top level Property를 가진다.
# pod-definition.yaml
apiVersion: v1
# Object를 생성하는 k8s API 버전을 지정하는 부분
# 생성하는 Object에 따라 적합한 API 버전을 사용해야 함
kind: Pod
# 생성하려는 Object의 종류를 지정하는 부분
metadata:
# 생성하는 Object에 대한 정보를 명시하는 부분
# k8s이 제공하는 child만 사용 가능
name: myapp-pod
# Object의 이름을 명시
labels:
# dictionary 형태로, 원하는 형태의 key, value label을 명시 가능
# label을 가지고 pod를 필터링, 검색할 때 사용할 수 있음
app: myapp
type: front-end
spec:
# 생성하는 Object에 따라, k8s에 추가로 제공해야 하는 정보를 명시하는 부분
containers:
# containers 속성은 list 형식
- name: nginx-container
image: nginx위처럼 yaml형식으로 정의한 내용를 가지고 pod를 생성할 수 있다.
kubectl craete -f pod-definition.yaml
# kubectl apply -f pod-definition.yamlReplication Controller
여러 개의 Pod을 운영함으로써 High Availability, Load Balancing, Scaling의 이점을 얻을 수 있다.
Replication Controller는 Definition file에 명시한 내용에 따라 Pod을 관리한다.
Pod 개수를 몇 개 유지하라
...Replication Controller는 같은 Cluster에 위치한 여러 (Worker) Node에 걸쳐 사용된다.
# Replication Controller Definition file
# rc-definition.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: myapp-rc
labels:
app: myapp
type: front-end
spec:
# Replication Controller에서 생성할 Pod들을 정의하기 위한 Template 부분
template:
# 위에서 작성한 pod-definition.yaml과 동일한 형식, 내용을 사용한다
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
# 몇 개의 pod replica를 만들 것인가
replicas: 3# Replication Controller, Pod를 생성
kubectl create -f rc-definition.yaml
# Replication Controller 목록 확인
kubectl get replicationcontrollerReplicaSet
ReplicaSet은 Replication Controller와 동일한 목적을 가지나 차이점이 있다.
# ReplicaSet Definition file
# replicaset-definition.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myrs
labels:
app: rs
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
replicas: 3
selector:
matchLabels:
type: front-end# ReplicaSet을 생성
kubectl create -f rs-definition.yaml
# ReplicaSet 목록 확인
kubectl get replicasetselector
ReplicaSet에 Pod definition이 들어있는데, 굳이
selector써서 자기가 만든 Pod들을 구분하려고 하는건가?
Replication Controller는 기본적으로, 자기에 정의된 Pod만을 관리(개수, 상태 등)하는 반면, ReplicaSet은 자기 밖에서 만들어진 Pod도 관리할 수 있기 때문이다.
`Replication Controller`도 `selector`필드를 사용할 수는 있지만 필수는 아님ReplicaSet은 자기가 만들지는 않았지만, 관리해야할 Pod를 식별할 수 있어야하는데, 이때 selector와 label 필드가 사용되는 것이다.
# ReplicaSet의 selector
spec:
...
# 나는 pod가 어디에서 생성되었는지 상관 없이, label이 'type: front-end'인 pod를 관리할거야
selector:
matchLabels:
type: front-end
# Pod의 label 정보
metadata:
name: mypod-fe
labels:
type: front-end미리 만들어진 Pod가 3개가 있는데, ReplicaSet의 desired replica가 5라면, ReplicaSet은 2개의 Pod만 생성한다.
Scaling
ReplicaSet을 통해 3개의 Pod를 운영하는 상황에서, Pod를 6개로 늘리고 싶으면 어떻게 할까
여러 방법이 있다.
definition.yaml 수정하고 replace하기
ReplicaSet의 definition file의 replicas필드를 수정하고 replace한다.
kubectl replace -f replicaset-definition.yaml
scale 명령 사용하기
definition file을 전달하기
kubectl scale --replicas=6 -f replicaset-definition.yaml
type, name을 전달하기
kubectl scale --replicas=6 -f replicaset my-replicaset-name
Deployments
Deployment는 말 그대로 배포와 관련한 편의성을 제공하기 위한 k8s Object이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: myrs
labels:
app: rs
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
replicas: 3
selector:
matchLabels:
type: front-endDeployment는 ReplicaSet과 동일한 definition file구조를 가진다.
kubectl create 0f dp-definition.yaml을 통해 Deployment를 생성하면 자동으로 ReplicaSet이 생성되고, ReplicaSet이 생성됨에 따라 자동으로 Pod가 생성된다.
배포와 관련한 편의성
Deployment가ReplicaSet보다 더 큰 개념인건 알겠는데, 무슨 장점이 있는것일까
Rollout and Versionning
kubectl create dp.yaml을 수행하면 rollout이 트리거된다. 그리고 rollout은 새로운 deployment revision을 생성한다.
새로운 App 버전이 나와서 Container가 변경되면, rollout이 또 트리거되어 새로운 revision이 생성된다.
revision 기록은 계속 누적되고, 이를 통한 버저닝이 가능하다.
# 특정 deployment의 rollout 상태 확인하기
kubectl rollout status deployment/my-deployment-name
# 특정 deployment의 rollout history 확인하기
kubeclt rollout history deployment/my-deployment-name
kubeDeployment Strategy
Deployment에 속한 Pod들을 Update하려고 한다.
- 기존 Pod delete
- 신규 Pod create
위와 같은 Recreate전략은 '삭제-생성' 간격동안 서비스를 제공할 수 없다.
Deployment는 대신에 기본값으로 RollingUpdate전략을 사용한다.
RollingUpdate
Recreate전략을 수행할 경우 replicaset은 다음의 흐름으로 작동한다.
- replicaset의
replicas값을 0으로 설정 -> pod all delete - replicaset의
replicas값을 5으로 설정 -> pod all create
RollingUpdate전략을 수행할 경우 replicaset은 다음의 흐름으로 작동한다.
- replicaset-2의 Pod + 1
- replicaset-1의 Pod -1
- replicaset-2가 desired state가 될 때 까지 1,2 반복
Rollback
kubectl rollout undo deployment/myapp-deployment
롤백 역시 RollingUpdate기반으로 작동한다.
- replicaset-1의 Pod + 1 (이전 버전 Pod 생성)
- replicaset-2의 Pod -1 (현재 버전 Pod 제거)
- replicaset-1이 desired state가 될 때 까지 1,2 반복
Deployment update
deployment의 definition file을 변경하고 이를 반영하자
apply 명령 사용하기
- definition file 내용 변경하기 (Ex. replica 개수, pod image 등)
kubectl apply -f dp-definition.yaml수행
그러면 deployment는 기본적으로 rolling update 방식으로 업데이트를 수행할 것이다.
set 명령 사용하기
특정 필드의 값만 지정하여 업데이트 할 수 있다.
kubectl set image deployment/my-dp-name nginx-continaer=nginx:1.9.1
변경사항이 definition file에 영구적으로 반영되지 않는 다는 점을 주의해야 한다 (ReplicaSet도 마찬가지)
Services
네트워킹과 관련한 기능을 지원하는 k8s object
세 종류의 타입이 있다.
NodePort
Node에 속한 Pod와 Node의 port를 연결하여 Pod가 accessible하게 만드는 기능
- TargetPort
Service가 요청을 전달하려는 Pod의 포트
- Port
Service의 포트
- NodePort
- 외부에서 Pod에 접근하기 위한 Node의 포트
Service는 마치 Node의 가상 서버이다. 클러스터 내부에서 서비스는 고유한 IP(ClusterIP)를 갖는다.
apiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:ㄹ
type: NodePort
ports: # 여러 port를 지정할 수 있다
- targetPort: 80 # optional: 따로 설정하지 않으면 port과 같은 번호를 사용
port: 80 # mandatory
nodePort: 30008 # optional: 따로 설정하지 않으면 30000 ~ 32767값으로 자동 설정
# 어떤 Pod와 포트를 매핑시킬지 selector를 통해 지정
selector:
app: myapp
type: front-end
## pod-definition.yaml
...
metadat:
labels:
app: myapp
type: front-end
...# 생성
kubectl create -f service-definition.yaml
# 조회
kubectl get services
# Node의 IP, Port를 통해 Pod에 접근 가능함
curl http://NODE_IP_ADD:NODE_PORT한 Node에 여러 Pod
한 Node에 여러 Pod이 있는 경우는 어떻게 할까
Pod가 여러 개인 경우에도 별도로 설정 없이, Pod가 1개인 경우처럼 Service의 selector로 Pod의 Label과 매핑하면 알아서 포트 작업을 진행한다.
별도의 설정 없이 Service가 LoadBalancer 기능을 수행한다.
기본 LoadBalance 알고리즘은 'random'
Service definition의 'Algorithm'필드를 통해 방식을 변경할 수 있다.여러 Node에 여러 Pod
이 경우에도 별다른 설정 없이 없어도, 클러스터 내부의 여러 Node에 걸쳐 작동하는 서비스가 생성되고, 동일한 NodePort를 통해 접근할 수 있게 된다.
ClusterIP
각 계층의 서비스를 여러 Pod들로 지원하는 상황
Pod들은 상태에 따라 계속 생성, 제거를 반복한다. 그런 상황에서 계층간의 연결을 Pod의 IP로 하면 문제가 발생할 것이다.
즉, static한 IP를 가진 클러스터 역할이 필요한데, clusterIP 타입의 서비스로 해결할 수 있다.
apiVersion: v1
kind: Service
metadata:
name: back-end
spec:
type: ClusterIP # Service의 기본 type은 ClusterIP
ports:
- targetPort: 80 # Pod들의 포트
port: 80 # Service의 포트
selector: # Back-end 서버 Pod들의 Label로 식별
app: myapp
type: back-endLoadBalancer
1. 여러 Node에 분산된 Pod들로 구성된 서비스가 존재한다.
2. Node마다 IP 주소가 존재한다.
Q: 사용자는 어떤 IP(Node)로 요청을 보내야 하는가?apiVersion: v1
kind: Service
metadata:
name: back-end
spec:
type: LoadBalancer
ports:
- targetPort: 80 # Pod들의 포트
port: 80 # Service의 포트
nodePort: 30008 # Node의 포트클라우드 플랫폼 (Ex. AWS, GCP, ...)에서는 단순히 Service type을 LoadBalancer로 설정하면 알아서 로드밸런싱을 해준다.
on-premise 환경을 직접 구축해야 함Namespace
참고
